一条SQL语句提交后,db2都做了什么?
 somenzz
微信公众号「Python七号」和你一起精进。
somenzz
微信公众号「Python七号」和你一起精进。
一直在做 db2 数据仓库的运维工作,对一些常用操作已经非常熟悉,但是总感觉自己学到是仍然是操作的细节,而不是真正的知识。如果你问我,一条 SQL 语句提交后,db2 都做了哪些工作,我可能会有点慌,因为我不能肯定的回答出来。于是,我就搜索一些资料,结合自己的理解,总结一下关于 db2 体系结构,db2 内存模型,SQL语句的执行过程,希望对正在使用 db2 的你有所帮助。
为什么要学习架构?
如果仅满足于 select * from where 这种简单的查询,对于业务人员可能够用了,但对于程序员,这远远不够,系统初建成之后,应用的性能还可以,但随着数据的累积,一些查询会非常低效,会影响前端用户体验,如果不懂数据库架构和原理,是无法有效的调优的,也无法从根本上解决问题。相反如果了解数据库的架构,那么在最初设计数据库,设计表时就可以高瞻远瞩,把性能恶化从源头上消灭。
db2 体系结构
db2 是 c/s 架构,客户端发起 SQL 请求,服务器返回相应结果。 体系结构如下图所示:
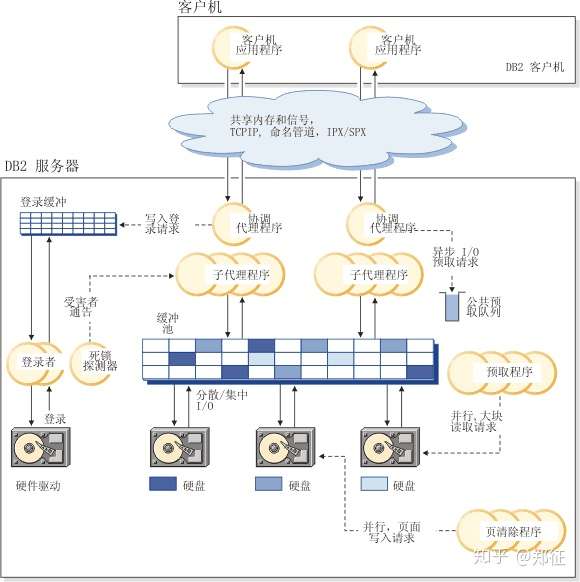
在本地连接 db2 服务时使用共享内存和信号通信,远程连接 db2 服务器,则使用协议(例如命名管道 (NPIPE) 或 TCP/IP)进行通信。
可以这样形象地理解:如果把数据库比作大型超市,那么客户机就是消费者,请求的数据即是商品,缓冲区就是超市的货架,整个超市的空间就是数据库所用的内存,而仓库是数据的最终存储,即磁盘。
上图中的圆圈或圆圈组表示引擎分派单元(EDU),你可以理解为导购员,在计算机中叫进程或线程。如果消费者请求的商品(数据)在超市的货架上(缓冲区)中,则称为缓冲区命中,直接从货架(缓冲区)将商品拿给消费者,购物结束(花费时间较少)。否则,服务员(预取程序)需要根据仓库清单(索引)去后台仓库(磁盘)为消费者查找并取出商品,商品仍会先放在超市的货架上,再拿给消费者(花费时间较长)。
与实际情况不同的是,消费者购完商品后,商品并不真正的从货架上移出,而仍保留,一旦有人购买相同的商品时,可以直接从货架上取走从而节省时间,这是因为数据只要不删除,是可以重复读取的。
还有一种情况就是:如果两个消费者都想买同一类型的商品,恰好空间有限,同时只能有一个人占据商品所在的空间,他要检查商品来确定要不要购买,那么另一个人只能等前者确定购或者不购(回退)之后才能占据相应空间来做同样的事情,这就是死锁等待,如果超过规定的时间(死锁等待时间 dlchktime)那么这个消费者可能要报警了,这就是 911 死锁。
以上任何一个环节都有可能造成购物时间过长,消费者等待,从而导致前端用户体验极差,也就是我们常见的数据库性能下降问题。
超市的内部空间设计的好不好,直接影响购物的整体流程,因此要想打造高效地超市,就要先对超市的内部空间设计要有足够的了解,这就是 db2 的内存模型。
db2 的内存模型
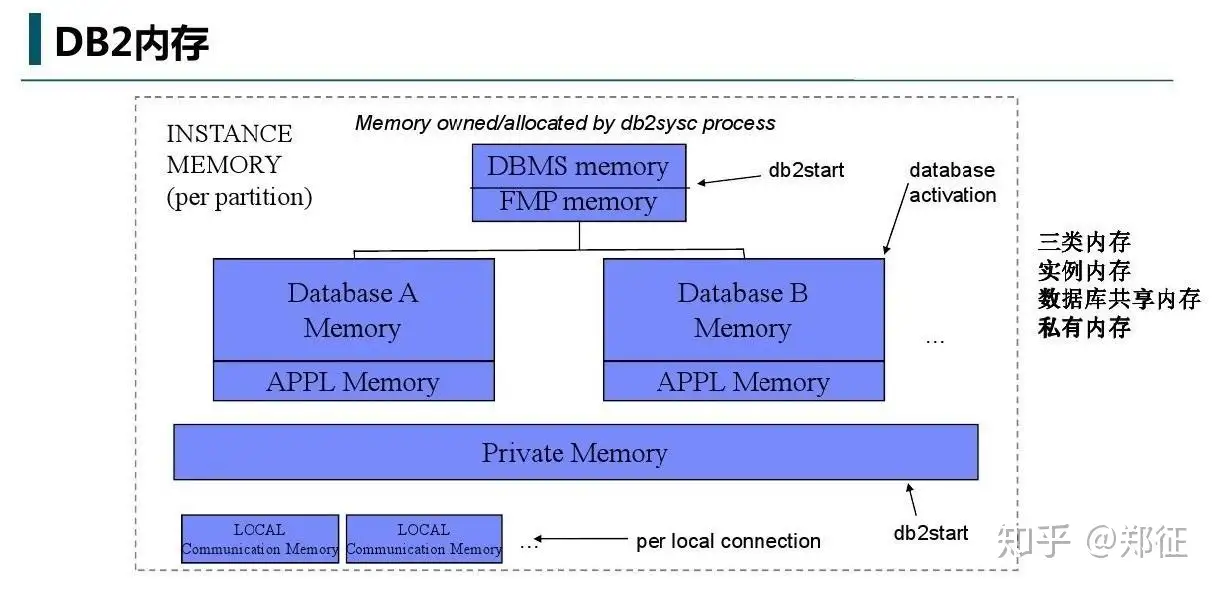
理解 DB2 如何使用内存,可以防止过度分配内存,并有助于对内存的使用进行调优,从而获得更好的性能。下图为官网提供的 db2 内存模型:
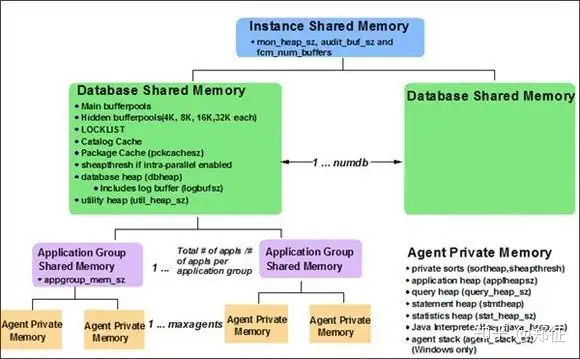
db2 在 4 种不同的内存集(memory set)内拆分和管理内存。如上图所示,从上到下依次为: 1. 实例共享内存(instance shared memory) 2. 数据库共享内存(database shared memory) 3. 应用程序组共享内存(application group shared memory) 4. 代理私有内存(agent private memory)
每种内存集由各种不同的内存池(亦称堆)组成,下面依次做介绍。
1、实例共享内存
首先要理解什么是实例,从 DB2 的体系结构方面来看,实例实际上就是DB2 的执行代码和数据库对象的中间逻辑层。实例可以看成是关于所有的数据库及其对象的逻辑集合,实例为数据库运行提供一个环境。一般地,我们会那一个数据库实例用户如 xxxx_inst 用户,然后使用这个用户来安装数据库,并使用这个实例用户来启动或停止数据库服务。
DB2 数据库和实例之间的区别:数据库是物理的,我们的表、索引存放在数据库中要占物理存储的;而实例是逻辑的,是共享内存、进程和一些配置文件(实例目录)的集合。
每个 DB2 实例都有一个实例共享内存。实例共享内存是在数据库管理器启动(db2start)时分配的,并随着数据库管理器的停止(db2stop)而释放。这种内存集用于实例级的任务,例如监控、审计和节点间通信。下面的数据库管理器配置(dbm cfg)参数控制着对实例共享内存以及其中个别内存池的限制: - 实例内存( INSTANCE_MEMORY)。 - 监视器堆( MON_HEAP_SZ):用于监控。 - Audit Buffer( AUDIT_BUF_SZ):用于 db2audit 实用程序。 - Fast Communication buffers (FCM_NUM_BUFFERS):用于分区之间的节点间通信。仅适用于分区的实例。 下面为某数据库通过 db2 get dbm cfg 输出的相应信息:
Database monitor heap size (4KB) (MON_HEAP_SZ) = AUTOMATIC(90)
Java Virtual Machine heap size (4KB) (JAVA_HEAP_SZ) = 2048
Audit buffer size (4KB) (AUDIT_BUF_SZ) = 0
Size of instance shared memory (4KB) (INSTANCE_MEMORY) = AUTOMATIC(7367929)
Agent stack size (AGENT_STACK_SZ) = 1024
Sort heap threshold (4KB) (SHEAPTHRES) = 0
...
No. of int. communication buffers(4KB)(FCM_NUM_BUFFERS) = AUTOMATIC(4096)INSTANCE_MEMORY 参数指定为实例管理预留的内存数量。默认值是 AUTOMATIC。这意味着 DB2 将根据监视器堆、审计缓冲区和 FCM 缓冲区的大小计算当前配置所需的实例内存数量。此外,DB2 还将分配一些额外的内存,作为溢出缓冲区。每当某个堆超出了其配置的大小时,便可以使用溢出缓冲区来满足实例共享内存区内任何堆的峰值需求。在这种情况下,个别堆的设置是软限制的,它们可以在内存使用的峰值期间进一步增长。
如果 INSTANCE_MEMORY 被设置为某一个数字,则采用 INSTANCE_MEMORY 与 MON_HEAP_SZ、AUDIT_BUF_SZ 和 FCM_NUM_BUFFERS 的和之间的较大者。这时,对实例内存就施加了一个硬性的限制,而不是软限制。当达到这个限制时,就会收到内存分配错误。出于这个原因,建议将 INSTANCE_MEMORY 的设置保留为 AUTOMATIC。
如果 instance_memory被设为 AUTOMATIC,则可以使用下面的命令来确定它的值:
$db2 attach to instance_name #(其中 instance_name是实例的名称)
$db2 get dbm cfg show detail | grep -i instance_memory
Size of instance shared memory (4KB) (INSTANCE_MEMORY) = AUTOMATIC(7367929) AUTOMATIC(7367929)
$ py
Python 3.6.1 (default, Jun 19 2017, 11:40:25) [C] on aix5
Type "help", "copyright", "credits" or "license" for more information.
>>> 7367929*4/1024/1024
28.10641860961914上面的输出表明有 28 GB 的内存被预留给实例共享内存集。
INSTANCE_MEMORY 参数只是设置了实例共享内存的限制。它并没有说出当前使用了多少内存。要查明一个实例的内存使用情况,可以使用 DB2 内存跟踪器工具 db2mtrk。例如,
$ db2mtrk -i -v
Tracking Memory on: 2018/11/28 at 21:39:20
Memory for instance
Other Memory is of size 107741184 bytes
Database Monitor Heap is of size 524288 bytes
FCMBP Heap is of size 74055680 bytes
Total: 182321152 bytes上面的例子表明,虽然预留给实例共享内存集的内存有 28 GB,但在 db2mtrk 运行时只用到了大约 173.875 MB。 注意:在某些情况下,db2mtrk 显示的大小会大于指定给配置参数的值。在这种情况下,赋予配置参数的值被作为一种软限制,内存池实际使用的内存可能会增长,从而超出配置的大小。
2、数据库共享内存
每个数据库有一个数据库共享内存集。数据库共享内存是在数据库被激活或者第一次被连接上的时候分配的。该内存集将在数据库处于非激活状态时释放(如果数据库先前是处于激活状态)或者最后一个连接被断开的时候释放。这种内存用于数据库级的任务,例如备份/恢复、锁定和 SQL 的执行。
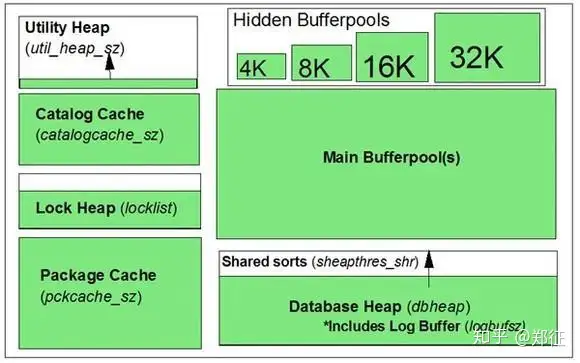
上图中完整的绿色方框意味着,在数据库启动的时候,该内存池是完全分配的,否则,就只分配部分的内存。例如,当一个数据库第一次启动时,不管 util_heap_sz 的值是多少,只有大约 16 KB 的内存被分配给实用程序堆。当一个数据库实用程序(例如备份、恢复、导出、导入和装载)启动时,才会按 util_heap_sz 指定的大小分配全额的内存。
主缓冲池(Main Bufferpool(s)):数据库缓冲池通常是数据库共享内存中最大的一块内存。DB2 在其中操纵所有常规数据和索引数据。 一个数据库必须至少有一个缓冲池,可以有多个缓冲池,这要视工作负载的特征、数据库中使用的数据库页面大小等因素而定。例如,页面大小为 8KB 的表空间只能使用页面大小为 8KB 的缓冲池。 可以通过 CREATE BUFFERPOOL 语句中的 EXTENDED STORAGE 选项“扩展”缓冲池。扩展的存储(ESTORE)充当的是从缓冲池中被逐出的页的辅助缓存,这样可以减少 I/O。ESTORE 的大小由 num_estore_segs 和 estore_seg_sz 这两个数据库配置参数来控制。如果使用 ESTORE,那么就要从数据库共享内存中拿出一定的内存,用于管理 ESTORE,这意味着用于其他内存池的内存将更少。 这时您可能要问,为什么要这么麻烦去使用 ESTORE?为什么不分配一个更大的缓冲池呢?答案跟可寻址内存(而不是物理内存)的限制有关。
隐藏的缓冲池(Hidden Bufferpools): 当数据库启动时,要分配 4 个页宽分别为 4K、8K、16K 和 32K 的小型缓冲池。这些缓冲池是“隐藏”的,因为在系统编目中看不到它们(通过 SELECT * FROM SYSCAT.BUFFERPOOLS 显示不出)。 如果主缓冲池配置得太大,则可能出现主缓冲池不适合可寻址内存空间的情况。(我们在后面会谈到可寻址内存。)这意味着 DB2 无法启动数据库,因为一个数据库至少必须有一个缓冲池。如果数据库没有启动,那么就不能连接到数据库,也就不能更改缓冲池的大小。由于这个原因,DB2 预先分配了 4 个这样的小型缓冲池。这样,一旦主缓冲池无法启动,DB2 还可以使用这些小型的缓冲池来启动数据库。(在此情况下,用户将收到一条警告(SQLSTATE 01626))。这时,应该连接到数据库,并减少主缓冲池的大小。
排序堆的阈值( sheapthres, sheapthres_shr): 如果没有索引满足所取的行的要求顺序,或者优化器断定排序的代价低于索引扫描,那么就需要进行排序。DB2 中有两种排序,一种是私有排序,一种是共享排序。私有排序发生在代理的私有代理内存(在下一节讨论)中,而共享排序发生在数据库的数据库共享内存中。 对于私有排序,数据库管理器配置参数 sheapthres 指定了私有排序在任何时刻可以消耗的内存总量在实例范围内的软限制。如果一个实例总共消耗的私有排序内存达到了这一限制,那么为额外传入的私有排序请求所分配的内存将大大减少。这样就会在 db2diag.log 中看到如下消息: "Not enough memory available for a (private) sort heap of size size of sortheap. Trying smaller size..." 如果启用了内部分区并行性(intra-partition parallelism)或者集中器(concentrator),那么当 DB2 断定共享排序比私有排序更有效时,DB2 就会选择执行共享排序。如果执行共享排序,那么就会在数据库共享内存中分配用于这种排序的排序堆。用于共享排序的最大内存量是由 sheapthres_shr 数据库参数指定的。这是对共享排序在任何时刻可以消耗的内存总量在数据库范围内的硬限制。当达到这个限制时,请求排序的应用程序将收到错误 SQL0955 (rc2)。之后,在共享内存总消耗量回落到低于由 sheapthres_shr 指定的限制之前,任何共享排序内存的请求都得不到允许。
下面的公式可以计算出数据库共享内存集大致需要多少内存: 数据库共享内存 = (主缓冲池 + 4 个隐藏的缓冲池 + 数据库堆 +实用程序堆 + locklist + 包缓存 + 编目缓存) + (estore 的页数 * 100 字节) + 大约 10% 的开销 对于启用了 intra_parallel 或集中器情况下的数据库,共享排序内存必须作为数据库共享内存的一部分预先分配,因而上述公式变为: 数据库共享内存 = (主缓冲池 + 4 个隐藏的缓冲池 + 数据库堆 +实用程序堆 + locklist + 包缓存 + 编目缓存 + sheapthres_shr) + (estore 的页数 * 100 字节) + 大约 10% 的开销。提示: 为了发现分配给主缓冲池的内存有多少,可以发出:
SELECT * FROM SYSCAT.BUFFERPOOLS虽然大多数内存池的大小是由它们的配置参数预先确定的,但下面两种内存池的大小在默认情况下却是动态的:
包缓存: pckcachesz = maxappls * 8
编目缓存: catalogcache_sz = maxappls * 4
活动应用程序的最大数量: maxappls = AUTOMATIC将 maxappls设为 AUTOMATIC的效果是,允许任意数量的连接数据库的应用程序。DB2 将动态地分配所需资源,以支持新的应用程序。因此,包缓存和编目的大小可以随着 maxappls的值而变化。 除了上述参数以外,还有一个参数也会影响数据库共享内存的数量。这个参数就是 database_memory。该参数的缺省值是 AUTOMATIC。这意味着 DB2 将根据以上列出的各内存池的大小来计算当前配置所需的数据库内存量。此外,DB2 还将为溢出缓冲区分配一些额外的内存。每当某个堆超出了其配置的大小时,便可以使用溢出缓冲区来满足实例共享内存区内任何堆的峰值需求。 如果 database_memory被设为某个数字,则采用 database_memory与各内存池之和这两者之间的较大者。 如果 database_memory被设为 AUTOMATIC,则可以使用以下命令来显示它的值:
db2 connect to dbnameuser useridusing pwd
db2 get db cfg for dbnameshow detail3、应用程序组共享内存
这种共享内存集仅适用于以下环境。(对于其他环境,这种内存集不存在。) - 多分区(multi-partitioned)数据库。 - 启用了内部并行(intra-parallel)处理的未分区(non-partitioned)数据库。 - 支持连接集中器的数据库。 注意:当 max_connections 的值大于 max_coordagents 的值时,连接集中器便被启用。这两个参数可以在数据库管理器配置中找到。(使用 GET DBM CFG 显示数据库管理器配置。)
在以上环境中,应用程序通常需要不止一个的代理来执行其任务。允许这些代理之间能够彼此通信(相互发送/接收数据)很有必要。为了实现这一点,我们将这些代理放入到一个称作应用程序组的组中。属于相同应用程序组的所有 DB2 代理都使用应用程序组共享内存进行通信。 应用程序组内存集是从数据库共享内存集中分配的。其大小由 appgroup_mem_sz 数据库配置参数决定。 多个应用程序可以指派给同一个应用程序组。一个应用程序组内可以容纳的应用程序数可以这样计算:
appgroup_mem_sz / app_ctl_heap_sz在应用程序组内,每个应用程序都有其自己的应用程序控制堆。此外,应用程序组共享内存中有一部分要预留给应用程序组共享堆。如下图所示:

考虑以下数据库配置:
- 最大应用程序内存集大小 (4KB) (APPGROUP_MEM_SZ) = 40000
- 最大应用程序控制堆大小 (4KB) (APP_CTL_HEAP_SZ) = 512
- 用于应用程序组堆的内存所占百分比 (GROUPHEAP_RATIO) = 70
可以计算出下面的值: - 应用程序组共享内存集是: 40000 页 * 4K/页 = 160 MB - 应用程序组共享堆的大小是: 40000 * 70% = 28000 4K 页 = 114MB - 该应用程序组内可容纳的应用程序数为: 40000/512 = 78 - 用于每个应用程序的应用程序控制堆为: (100-70)% * 512 = 153 4K 页 = 0.6MB
不要被 app_ctrl_heap_sz 参数迷惑。这个参数不是一个应用程序组内用于每个应用程序的各应用程序控制堆的大小。它只是在计算这个应用程序组内可容纳多少应用程序时用到的一个值。每个应用程序的实际应用程序控制堆大小都是通过 图 3中给出的公式计算的,这个公式就是 ((100 - groupheap_ratio)% * app_ctrl_heap_sz)。
因此,groupheap_ratio 越高,应用程序组共享堆就越大,从而用于每个应用程序的应用程序控制堆就越小。
4、代理私有内存
每个 DB2 代理进程都需要获得内存,以执行其任务。代理进程将代表应用程序使用内存来优化、构建和执行访问计划,执行排序,记录游标信息(例如位置和状态),收集统计信息,等等。为响应并行环境中的一个连接请求或一个新的 SQL 请求,要为一个 DB2 代理分配代理私有内存。
代理的数量受下面两者中的较低者限制:
- 所有活动数据库的数据库配置参数 maxappls 的总和,这指定了允许的活动应用程序的最大数量。
- 数据库管理器配置参数 maxagents 的值,这指定了允许的最大代理数。
代理私有内存集由以下内存池组成。这些内存池的大小由括号中的数据库配置参数指定:
- Application Heap ( applheapsz)
- Sort Heap ( sortheap)
- Statement Heap ( stmtheap)
- Statistics Heap ( stat_heap_sz)
- Query Heap ( query_heap_sz)
- Java Interpreter Heap ( java_heap_sz)
- Agent Stack Size ( agent_stack_sz) (仅适用于 Windows)
我们曾提到,私有内存是在一个 DB2 代理被“指派”执行任务时分配给该代理的。那么,私有内存何时释放呢?答案取决于 dbm cfg 参数 num_poolagents 的值。该参数的值指定任何时候可以保留的闲置代理的最大数目。如果该值为 0,那么就不允许有限制代理。只要一个代理完成了它的工作,这个代理就要被销毁,它的内存也要返回给操作系统。如果该参数被设为一个非零值,那么一个代理在完成其工作后不会被销毁。相反,它将被返回到闲置代理池,直到闲置代理的数目到达 num_poolagents 指定的最大值。当传入一个新的请求时,就要调用这些闲置代理来服务该新请求。这样就减少了创建和销毁代理的开销。
当代理变成闲置代理时,它仍然保留了其代理的私有内存。这样设计是为了提高性能,因为当代理被再次调用时,它便有准备好的私有内存。如果有很多的闲置代理,并且所有这些闲置代理都保留了它们的私有内存,那么就可能导致系统耗尽内存。为了避免这种情况,DB2 使用一个注册表变量来限制每个闲置代理可以保留的内存量。这个变量就是 DB2MEMMAXFREE。它的默认值是 8 388 608 字节。这意味着每个闲置代理可以保留最多 8MB 的私有内存。如果有 100 个闲置代理,那么这些代理将保留 800MB 的内存,因此它们很快就会耗尽 RAM。您可能希望降低或增加这一限制,这取决于 RAM 的大小。
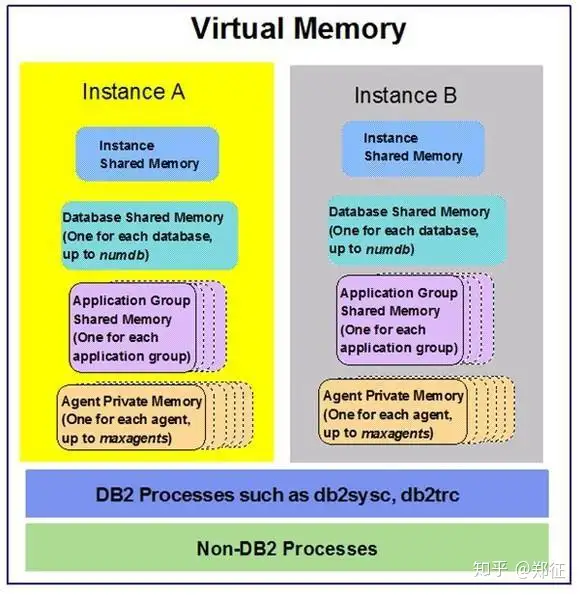
上述介绍了db2 实例共享内存、数据库共享内存和应用程序组共享内存以及代理私有内存,与其他非 db2 进程相比,他们在内存中的位置如下图所示:
db2 的主要线程
这些线程好比超市中的各种服务员,他们各司其职,相互配合,高效地为数据库服务。db2 数据库启动后,可以看到进程列表中有个 db2sysc 的进程,它是 db2 数据库服务的主进程。可以使用 "db2pd -edus" 显示工作线程。主要的工作线程及功能如下: - db2tcpcm TCP 监听 - db2ipccm IPC 监听 - db2pfchr 预读线程,从磁盘读页面到 bufferpool - db2pclnr 将修改后的数据页(脏页)写入磁盘 - db2loggw、db2loggr 日志写入、读取线程 - db2dlock 死锁检测线程
一条SQL语句提交后,db2都做了什么?
前面说了那么多,都是为了做铺垫。先看下图select 语句的执行过程:
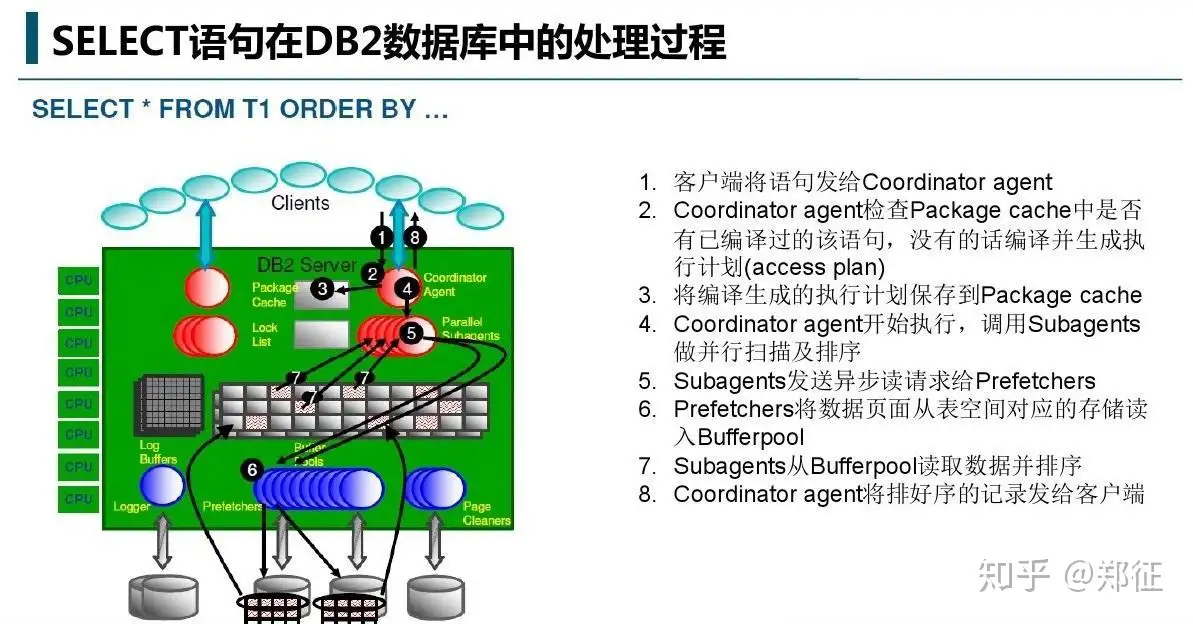
图中的文字还是太过简单,重述如下: (1)select语句通过网络传送给代理线程; (2)SQL语句经过重写及编译,将编译结果存放在 Package cache 中; (3)协调代理线程(coordinating agent)按照执行计划执行语句,将预取请求发送给预取线程; (4)预取线程在容器间并行执行异步I/O,将数据页放入缓冲池中(如果没有发生预取,也就是缓冲池命中,则略过第4步); (5)将容器中的数据页放入缓冲池中; (6)将需要排序的数据移动到排序堆中; (7)如果排序堆不够,则将排序数据放到临时表空间中; (8)排序完成的行被子代理送回客户端。 执行过程中要注意以下几个细节,这些细节也是影响性能的关键因素: (1)SQL语句的执行计划可能会极端影响性能; (2)如果发生预取,预取线程会从磁盘中取出连续的数据页,此时代理线程处于等待状态; (3)如果没发生预取,则协调代理会并行地从磁盘中取出数据。
到此为止,一条select语句就彻底执行完了,我们可以看到,一条最基本的查询语句在 DB2 中经过各个组件的协调,历经了 8 个步骤最终完成。在遇到一个性能问题时,任何一个环节都可能成为性能瓶颈。
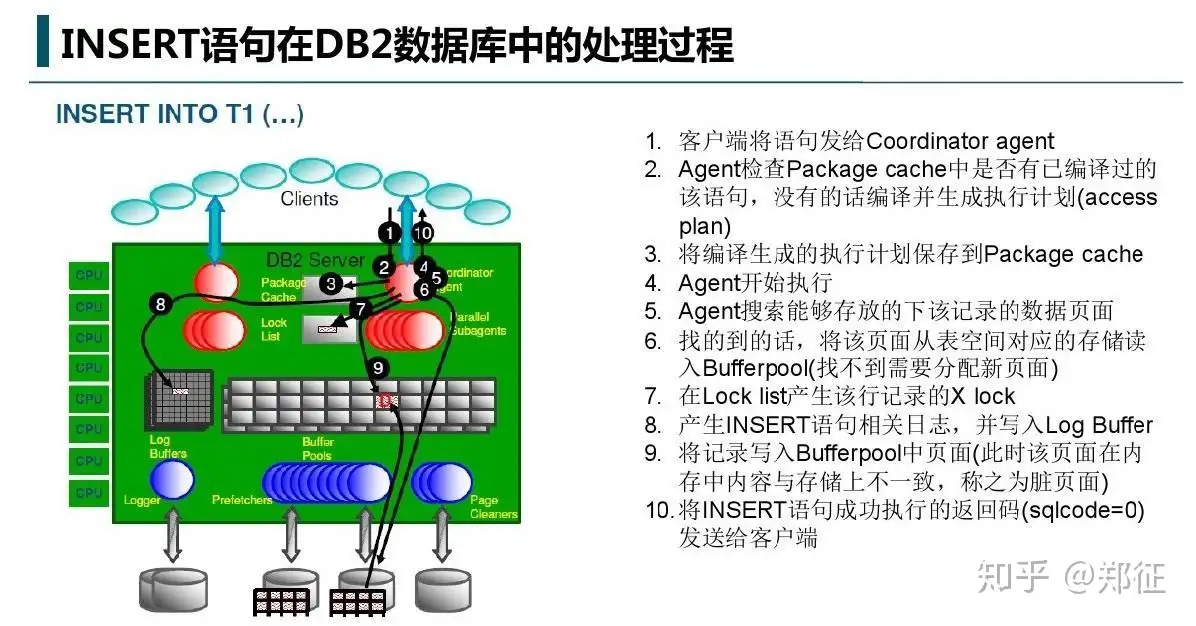
可以看出,insert 后,数据库在缓冲区写入成功,同时记录日志到 log buffer ,返回客户端写入成功,但并不急于写回磁盘,原因是写磁盘太慢了,影响性能。此时如果用记要查询新插入的数据,则缓冲区直接命中,效率也会非常高。当缓冲区不够用时,可以将脏页写回磁盘,从而释放缓冲区内存空间。基本上所有的数据库,如 oracle,mysql 都有这种机来避免频繁地读写磁盘。当然,使用更好的磁盘,如RAID10(一般都很贵)也可以提高数据库的性能。
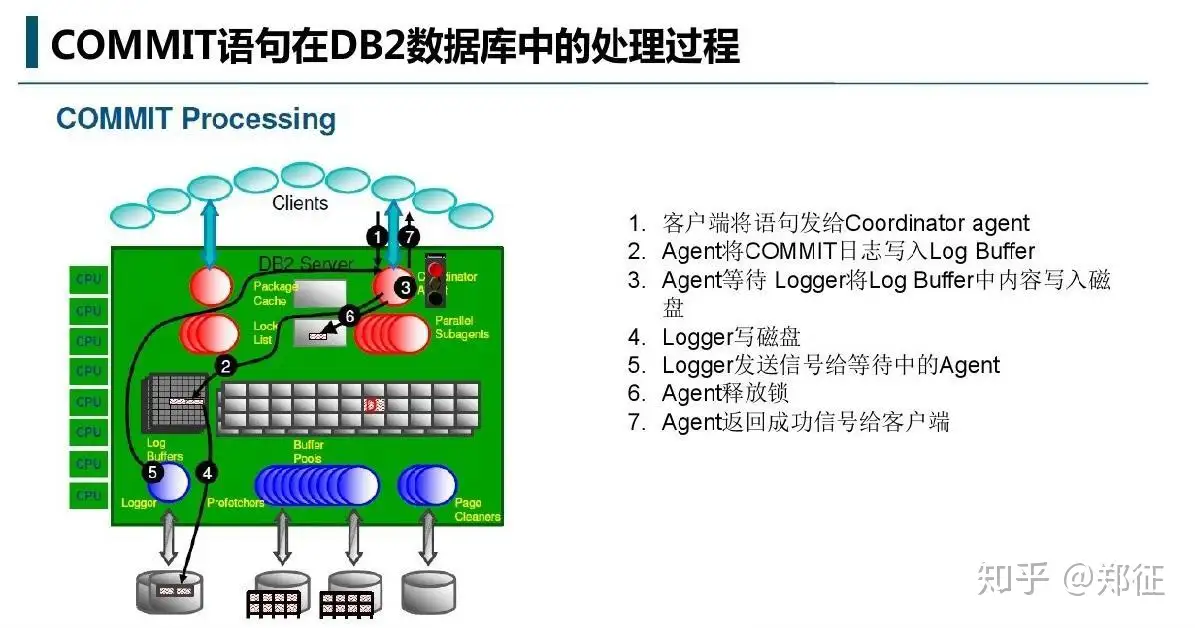
commit 语句就比较简单了,如上图所示。
小结:db2 还是很强大的,IBM 也不愧是数据库理论诞生的公司,本文参考官网详细地介绍了 db2 的内存模型,也简单介绍了体系结构和 SQL 语句地执行过程,了解这些有助于运维工程师根据内存使用情况对数据库调优。后续会介绍 db2 的锁,索引等,敬请关注。
公众号 somenzz 坚持原创,和你一起学习技术。
标签:语句,db2,数据库,代理,应用程序,内存,SQL,共享内存 From: https://www.cnblogs.com/yaoyangding/p/16942420.html