MySQL知识点(一)
目录一、B树和B+树之间的区别是什么?
首先附上数据结构可视化工具网址
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
1、B树
这里的 B 是 Balance(平衡)的缩写。它是一种多路的平衡搜索树。
它跟普通的平衡二叉树的不同是,B树的每个节点可以存储多个数据,而且每个节点不止有两个子节点,最多可以有上千个子节点。
B树中每个节点都存放着索引和数据,数据遍布整个树结构,搜索可能在非叶子节点结束,最好的情况是O(1)。
一般一棵 B 树的高度在 3 层左右,3 层就可满足 百万级别的数据量
2、B+树
B+树是B树的一种变种,它与 B树 的 区别 是:
叶子节点保存了完整的索引和数据,而非叶子节点只保存索引值,因此它的查询时间固定为 log(n)
叶子节点中有指向下一个叶子节点的指针,叶子节点类似于一个单链表
正因为叶子节点保存了完整的数据以及有指针作为连接,B+树可以增加了区间访问性,提高了范围查询,而B树的范围查询相对较差
B+树更适合外部存储。因为它的非叶子节点不存储数据,只保存索引。
二、Innodb中的B+树是怎么产生的?
往数据库中添加一些无序的数据,查询语句后发现数据顺序按照a字段排序,可是在查询时并没有使用order by 字段,所以只能是在插入时已经排好序。
想要解决这个问题我们要从Innodb引擎是怎样搭建B+树的
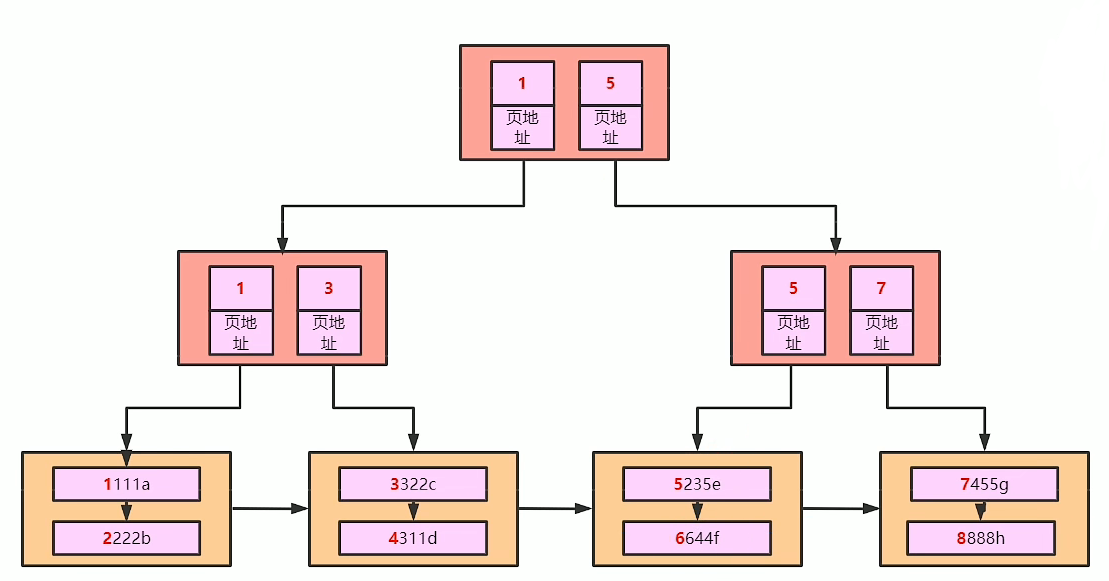
Innodb引擎中,最小的存储单元就是一页,一页为16kb
现假设一个页仅能存下三条记录,随着用户记录不断插入,InnoDB不断申请新的索引页,最终结构如下图所示:

现在我们要查询id=10的记录,InnoDB会怎么做呢?很遗憾,只能从页1开始一个页一个页的往后找。InnoDB会先将页1从磁盘加载到内存,然后遍历用户记录,判断是否存在id=10的记录,没有找到则继续加载页2,然后重复前面的过程,这就是「全表扫描」。当然,这个查找的过程也可以偷懒。首先,页内的记录无需全部遍历,通过Page Directory使用二分法即可快速查找。其次,找到第一条id>10的记录就不用再往后找了,因为记录是按照id排好序的,后面的记录id也肯定也比10大。
尽管可以偷点懒,但可惜的是效果微乎其微,内存的读写速度和CPU的算力已经非常快了,整个过程最耗时的操作其实是将页从磁盘加载到内存里,这需要发起系统调用来读取磁盘数据。这些页在物理上可能还不是连续的,机械硬盘随机读的效率是非常低的,如果每次检索数据都要全表扫描一次,这是完全不能接受的。
有没有发现?索引页本身其实和页内记录的分组很像,页内的记录是有序的,页与页之间也是有序的。于是,InnoDB直接借鉴了Page Directory的设计,将每个索引页内最小的主键值提取出来,给所有的索引页再建立一个目录。目录项最少要记录主键值+页号,例如上图中的记录,先给页1创建一个目录项,存储主键值1和页号1;再给页2创建一个目录项,存储主键值4和页号2;以此类推。这些目录项存在哪里呢?有没有发现目录项和用户记录也很像?只是用户记录存储的是用户自定义的列数据,而目录项存储的是主键值+页号。所以,InnoDB直接使用索引页来存储目录项,把目录项和用户记录同等对待,只在记录头信息里通过record_type属性做区分,0是用户记录,1是目录项记录 ,除此之外两者结构完全一样。存放目录项记录的页类型和存放用户记录的页类型也是一样的,都是0x45BF。目录项之间也是有序的单向链表,也可以通过Page Directory快速查找等等。

现在我们再来看一下,有索引的情况下,InnoDB通过主键查找记录的流程。先将B+树的根节点页面加载到内存,通过Page Directory使用二分法快速定位到分组,遍历组内的目录项, 通过页号定位到第二层页节点,将该节点页加载到内存,重复前面的过程,直到定位到叶子节点页,最终获取到记录。加载数据页的个数,其实就是B+树的高度,而且InnoDB B+树有个特点,就是根节点一旦确定就不会改变,这样InnoDB就可以将根节点页做缓存了,进一步减少页的加载次数。
三、高度为3的B+树能存多少条数据?
前面我们说到了Innodb引擎中,最小的存储单元就是一页,一页为16kb,磁盘存储数据最小的单元为扇区,一个扇区的大小为512字节,而文件系统的最小单元是块,一个块的大小是4k,因此Innodb的所有数据文件,他的大小始终都是16384B的整数倍。
数据表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?假设一行数据的大小是1k,那么一个页可以存放16行这样的数据。
但是除了有 存放数据的页 以外,还有 存放键值+指针(索引)的页 ,即B+树中的非叶子节点,该页存放键值和指向数据页的指针,这样的页由N个(键值+指针)组成。当然它也是排好序的。 这样的数据组织形式,我们称为「索引组织表」。索引组织表通过非叶子节点的「二分查找法」以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据。
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,没有子页节点,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数。
那么现在我们需要计算出非叶子节点能存放多少指针,也就是存放多少索引?
我们假设主键ID为 bigint 类型,长度为8字节,而 指针大小在InnoDB源码中设置为6字节 ,这样一共14字节。
我们一个页中能存放多少这样的单元,其实就代表有多少指针,即 16384/14=1170。一个页能存放1170个索引
那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170(根存的记录指针数据)✖1170(下一级每个节点存的记录指针数据)✖16(每个叶子阶段存的数据条数)=21902400 条这样的记录,即2100w量级。
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。
在查找数据时一次页的查找代表一次 IO ,所以通过主键索引查询通常只需要1-3次 IO 操作即可查找到数据,即使一个是千万量级的表,也是很快的。
四、Innodb引擎是如何支持范围查找能走索引的?
select * from t1 where a > 6是先执行a=6的操作,先找到a=6之后,再把a>6之后的所有数据全部返回就可以了。如果是<,就需要返回6之前的数据。
为了方便查找,Innodb引擎在每页之间添加了双向链表,如下图所示
五、为什么要遵守最左前缀原则才能利用到索引?
创建一个bcd的联合索引 create index idx_t1_bcd on t1(b,c,d),那么他也会生成一个B+树,那么这个b+树是怎么生成的呢? 我们主键索引所对应的B+树是按照主键锁对应的元素进行排序,然后生成B+树。那么bcd索引所对应的B+树也是一个道理,也就是把这几条数据按照bcd三个字段进行排序就可以了。但是叶子节点呢?叶子节点如果存放全部数据的话,每次增删改查数据都要对着两个B+树进行操作,相当的麻烦,所有在联合索引的叶子节点上,不存放其他元素的值,只存bcd三个字段的值和主键的索引。是因为我们如果借用bcd所有来查询,查到的元素只有bcd,还需要一个主键,进行回表操作,根据主键值在主键B+树查找完整的信息。
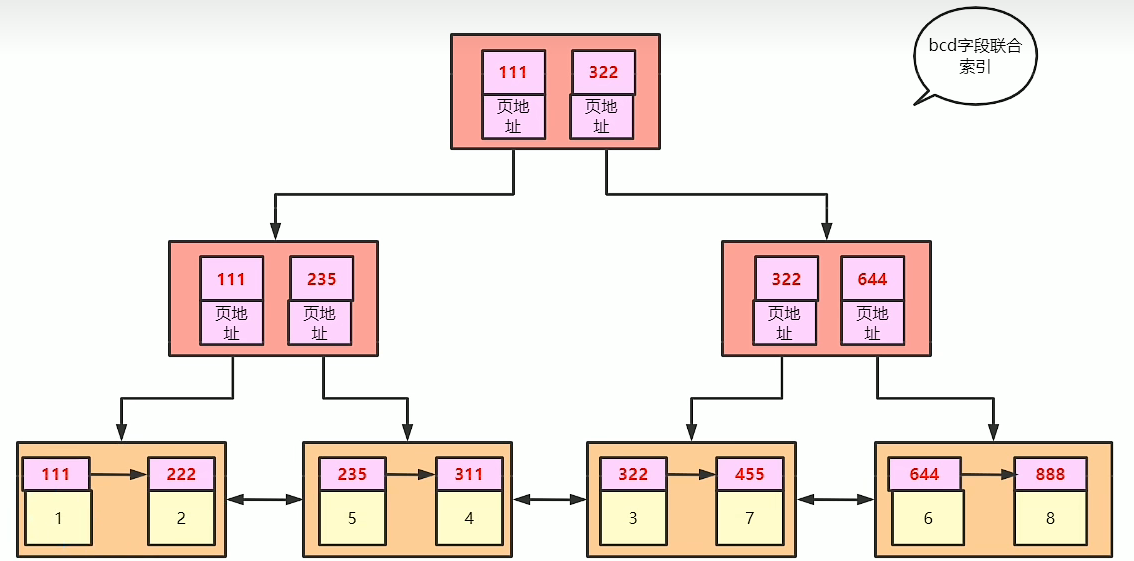
最左前缀原则:where的条件,和你给的索引顺序无关(底层会给你优化排序),但必须包含最左侧的字段。比如这个查询就会使索引失效 select * from t1 where c = 1 and t = 1,没有用到a字段。这种情况就 相当于给的条件是 * 1 1,想要走bcd的索引,然后跟111和322比较,看往左走还是往右走。
这是没办法比较的,因为条件的最左边字段没给。但如果条件是b=1 and d=1是能走的,这就好比 1 * 1,这是可以比较的,数据一定在左边,因为左边的a比右边的a小。
六、范围查找导致索引失效原理分析?
假如还是bcd来联合索引,这次的查询条件explain select * from t1 where b > 1,索引是会失效,走到是全表扫描。因为查到b=1后,还需要拿着主键的索引去回表查询,后面的数据过多是很麻烦的,所用的时间还不如全表扫描。
七、覆盖索引的底层原理?
explain select b from t1 where b > 1;这个是能够走索引的,因为这个只需要查到b,以bcd为索引的B+树是包含b的值,所以不需要回表查询。这就叫覆盖索引,sql里面所查询的字段正好就在当前sql当前所利用的索引,上面有这个字段,不用回表。
八、索引扫描底层原理?
explain select b from t1这个sql也是能够走bcd索引的。如果是走全表扫描,是从主键索引的叶子节点去遍历,把每条数据的b字段给取出来。b字段的值即会存在主键索引当中,还会存在bcd索引的B+树中。如果是在bcd的叶子节点去遍历,遍历的数据没有主键索引的数据完整,但都包含b字段的值,查询的速度肯定是不完整的数据比完整的快,所以走的会是bcd索引
九、order by为什么会导致索引失效?
explain select * from t order by b,c,d;这个sql是无法走索引的,因为联合字段的B+树是按照索引字段进行排序的,可我们要查的是* ,bcd存放的数据不完整,需要回表查询,存了几条数据就需要回几次表。而全表扫描是在内存中进行的,内存的操作要比io快得多。
十、MySQL中的数据类型转换需要注意哪些?
在varchar类型中,不是数字的字符如果转换为数字的话会统统转成0,比如'123' = 123 , 'abc' = 0
十一.对字段进行操作导致索引失效原理
只要对字段进行的操作都会导致索引失效,比如select * from t1 where a+1 = 1,改b+树,它会该字段,该字段,其他查询就不能继续走这个索引,所以索引的字段万万不能改变。