目录
一、EFAK概述和安装
关于EFAK的概述和安装,可以参考我这篇文章:大数据Hadoop之——Kafka 图形化工具 EFAK(EFAK环境部署)
在讲EFAK使用之前,这里先讲一下listeners 和 advertised.listeners的用法,其实企业里还是会配置着两个参数的。
二、listeners和advertised.listeners配置详解
kafka 0.9.x以后的版本新增了
advertised.listeners配置,kafka 0.9.x以后的版本不要使用 advertised.host.name 和 advertised.host.port 已经deprecated
host.name 和 port 为 deprecated,使用listeners代替。
listeners:就是主要用来定义Kafka Broker的Listener的配置项,listeners是kafka真正bind的地址。advertised.listeners:参数的作用就是将Broker的Listener信息发布到Zookeeper中,是暴露给外部的listeners,如果没有设置,会用listeners。listener.security.protocol.map:配置监听者的安全协议的,主要有以下几种协议:- PLAINTEXT => PLAINTEXT 不需要授权,非加密通道
- SSL => SSL 使用SSL加密通道
- SASL_PLAINTEXT => SASL_PLAINTEXT 使用SASL认证非加密通道
- SASL_SSL => SASL_SSL 使用SASL认证并且SSL加密通道
inter.broker.listener.name:专门用于Kafka集群中Broker之间的通信。
listener.security.protocol.map=EXTERNAL:PLAINTEXT,INTERNAL:PLAINTEXT
# 外网访问192.168.0.113:19092,内网访问:192.168.0.113:19093,当kafka部署在k8s时候就很有用
listeners=EXTERNAL://192.168.0.113:19092,INTERNAL://192.168.0.113:19093
inter.broker.listener.name=INTERNAL
# 如果advertised.listeners没配置就使用listeners的配置
#advertised.listeners=EXTERNAL://192.168.0.113:19092,INTERNAL://192.168.0.113:19093
使用场景
- 只有内网:比如在公司搭建的 kafka 集群,只有内网中的服务可以用,这种情况下,只需要用 listeners 就行。示例如下:
# listeners=<协议名称>://<内网ip>:<端口>
listeners=EXTERNAL://192.168.0.113:19092
- 内外网:在 k8s 中或者 在类似阿里云主机上部署 kafka 集群,这种情况下是 需要用到 advertised_listeners。示例如下:
listeners=INSIDE://0.0.0.0:9092,OUTSIDE://<公网 ip>:端口(或者 0.0.0.0:端口)
advertised.listeners=INSIDE://localhost:9092,OUTSIDE://<宿主机ip>:<宿主机暴露的端口>
listener.security.protocol.map=INSIDE:SASL_PLAINTEXT,OUTSIDE:SASL_PLAINTEXT
kafka_inter_broker_listener_name:inter.broker.listener.name=INSIDE
三、KSQL使用
KSQL是一个用于Apache kafka的流式SQL引擎,KSQL在内部使用Kafka的Streams API,KSQL降低了进入流处理的门槛,提供了一个简单的、完全交互式的SQL接口,用于处理Kafka的数据,可以让我们在流数据上持续执行 SQL 查询,KSQL支持广泛的强大的流处理操作,包括聚合、连接、窗口、会话等等。官方文档:https://www.rittmanmead.com/blog/2017/10/ksql-streaming-sql-for-apache-kafka/
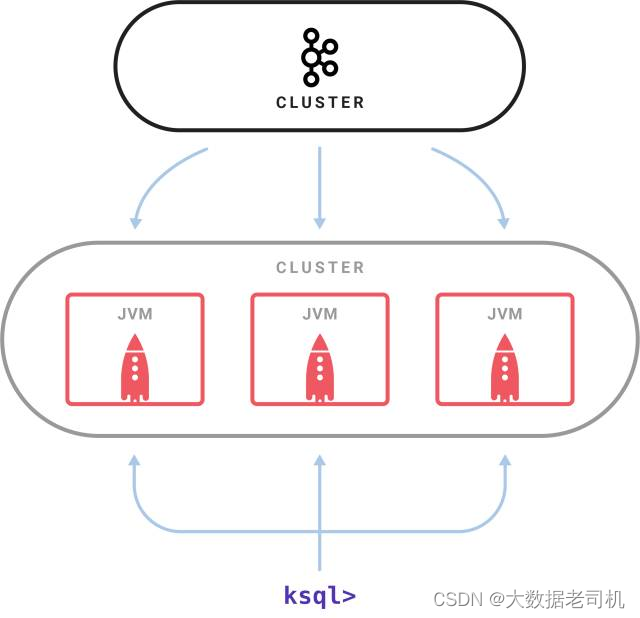
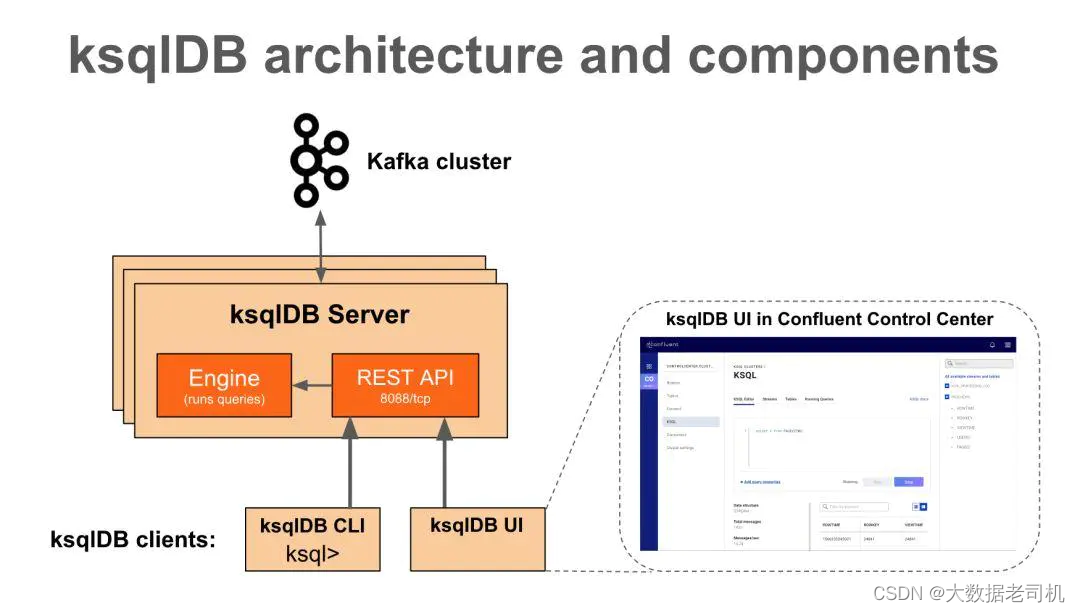
1)KSQL架构
GitHub地址:https://github.com/confluentinc/ksql
2)Confluent安装(ZK/KAFKA/KSQL)
ksql支持kafka0.11之后的版本,在confluent的V3和V4版本中默认并没有加入ksql server程序,当然V3和V4是支持ksql的,在V5版本之后已经默认加入ksql了,这里选择最新版本7.1。其实Confluent 就是kafka的增加版,包含了kafka和zk。
下载地址:https://packages.confluent.io/archive/
1、下载confluent
$ cd /opt/bigdata/hadoop/software
$ wget https://packages.confluent.io/archive/7.1/confluent-7.1.1.tar.gz
$ tar -xf confluent-7.1.1.tar.gz -C /opt/bigdata/hadoop/server/
2、配置环境变量
$ vi /etc/profile
export CONFLUENT_HOME=/opt/bigdata/hadoop/server/confluent-7.1.1
export PATH=$CONFLUENT_HOME/bin:$PATH
$ source /etc/profile
3、创建log和data目录
$ mkdir $CONFLUENT_HOME/etc/kafka/zookeeper_data $CONFLUENT_HOME/etc/kafka/zookeeper_logs $CONFLUENT_HOME/etc/kafka/logs
3、配置zk和kafka
- 配置zk
$ cat > $CONFLUENT_HOME/etc/kafka/zookeeper.properties <<-EOF
# 配置主要修改如下:
#数据目录
dataDir=/opt/bigdata/hadoop/server/confluent-7.1.1/etc/kafka/zookeeper_data
#日志目录
# dataLogDir=/opt/bigdata/hadoop/server/confluent-7.1.1/etc/kafka/zookeeper_logs
#心跳间隔时间,zookeeper中使用的基本时间单位,毫秒值。每隔2秒发送一个心跳
tickTime=2000
#leader与客户端连接超时时间。表示5个心跳间隔
initLimit=5
#Leader与Follower之间的超时时间,表示2个心跳间隔
syncLimit=2
#客户端连接端口,默认端口2181
clientPort=12181
admin.enableServer=false
# admin.serverPort=8080
# zookeeper集群配置项,server.1,server.2,server.3是zk集群节点;hadoop-node1,hadoop-node2,hadoop-node3是主机名称;2888是主从通信端口;3888用来选举leader
server.1=hadoop-node1:2888:3888
server.2=hadoop-node2:2888:3888
server.3=hadoop-node3:2888:3888
EOF
- 配置kafka
$ cat > $CONFLUENT_HOME/etc/kafka/server.properties <<-EOF
#broker的全局唯一编号,不能重复
broker.id=0
listener.security.protocol.map=EXTERNAL:PLAINTEXT,INTERNAL:PLAINTEXT
# broker 服务器要监听的地址及端口 . 默认是 localhost:9092 ,0.0.0.0的话 ,表示监听本机的所有ip地址.本机配置:
# localhost : 只监听本机的地址请求, 客户端也只能用 localhost 来请求
# 127.0.0.1 : 同localhost, 在请求上可能有与区分 , 看client的请求吧 . 客户端也只能用127.0.0.1来请求
# 192.168.0.1 : 你的局域网不一定是 192.168 段的.所以一般不选这个
# 0.0.0.0 : 本机的所有地址都监听 , 包含 localhost , 127.0.0.1, 及不同网卡的所有ip地址 , 都监听 .
listeners=EXTERNAL://0.0.0.0:19092,INTERNAL://0.0.0.0:19093
# 是暴露给外部的listeners,如果没有设置,会用listeners,参数的作用就是将Broker的Listener信息发布到Zookeeper中,注意其它节点得修改成本身的hostnaem或者ip,不支持0.0.0.0
advertised.listeners=EXTERNAL://hadoop-node1:19092,INTERNAL://hadoop-node1:19093
inter.broker.listener.name=INTERNAL
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka数据的存储位置
log.dirs=/opt/bigdata/hadoop/server/confluent-7.1.1/etc/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop-node1:12181,hadoop-node2:12181,hadoop-node3:12181
#zookeeper连接超时时间
zookeeper.connection.timeout.ms=60000
EOF
3、把confluent copy到其它节点
$ scp -r $CONFLUENT_HOME hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r $CONFLUENT_HOME hadoop-node2:/opt/bigdata/hadoop/server/
【温馨提示】其它几点修改以下三点:
- 记得要修改
broker.id,把hadoop-node2上的broker.id设置1,把hadoop-node2上的broker.id设置2; - 设置环境变量
$ vi /etc/profile
export CONFLUENT_HOME=/opt/bigdata/hadoop/server/confluent-7.1.1
export PATH=$CONFLUENT_HOME/bin:$PATH
$ source /etc/profile
advertised.listeners地址修改成本机地址
4、设置zk myid
# 在hadoop-node1配置如下:
$ echo 1 > $CONFLUENT_HOME/etc/kafka/zookeeper_data/myid
# 在hadoop-node2配置如下:
$ echo 2 > $CONFLUENT_HOME/etc/kafka/zookeeper_data/myid
# 在hadoop-node3配置如下:
$ echo 3 > $CONFLUENT_HOME/etc/kafka/zookeeper_data/myid
5、修改ksql-server.properties文件
$ vi $CONFLUENT_HOME/etc/ksqldb/ksql-server.properties
#修改对应的kafka的bootstrap server
bootstrap.servers=hadoop-node1:19092,hadoop-node2:19092,hadoop-node3:19092
6、开启Kafka JMX监控
# 在kafka-server-start文件中添加export JMX_PORT="9988",端口自定义就行
$ vi $CONFLUENT_HOME/bin/kafka-server-start
7、启动服务(zk,kafka,ksql)
先停掉之前的kafka和zk
$ $KAFKA_HOME/bin/zookeeper-server-stop.sh
$ $KAFKA_HOME/bin/kafka-server-stop.sh
启动zk(必须先启动zk再启动kafka)
$ cd $CONFLUENT_HOME
$ bin/zookeeper-server-start -daemon etc/kafka/zookeeper.properties
启动kafka
$ cd $CONFLUENT_HOME
$ bin/kafka-server-start -daemon etc/kafka/server.properties
启动KSQL server
# 默认端口8088,可以修改listeners字段来修改port
$ cd $CONFLUENT_HOME
$ ./bin/ksql-server-start ./etc/ksqldb/ksql-server.properties
# 后台启动
$ ./bin/ksql-server-start -daemon ./etc/ksqldb/ksql-server.properties
启动ksql cli端
$ cd $CONFLUENT_HOME
$ ./bin/ksql http://0.0.0.0:8088
【温习提示】其实也可以使用外部的zk和kafka
3)KSQL简单使用
1、table和stream概述
stream:stream是一个无序的数据结构,stream中发生的事件是不可改变的,已经被认定为事实,新的事件加入到这个stream中,现有的事实都不会改变。Streams可以从Kafka的topic创建出来,也可以从现有streams中派生出来。streams的基础数据在Kafka的broker里的topic持久保存(持久化)。table:table是stream的一个视图,表示不断变化的事实的集合。 它相当于传统的数据库表,但通过流式语义(如窗口)进行了丰富。 table中的事实是可变的,这意味着可以将新事实插入表中,同时可以更新或删除现有事实。 可以从Kafka主题创建table,也可以从现有streams和tables中派生。 在这两种情况下,table的基础数据都在Kafka的broker里的topic中持久存储(持久化)。
2、通过ksql-datagen工具创建topic和data
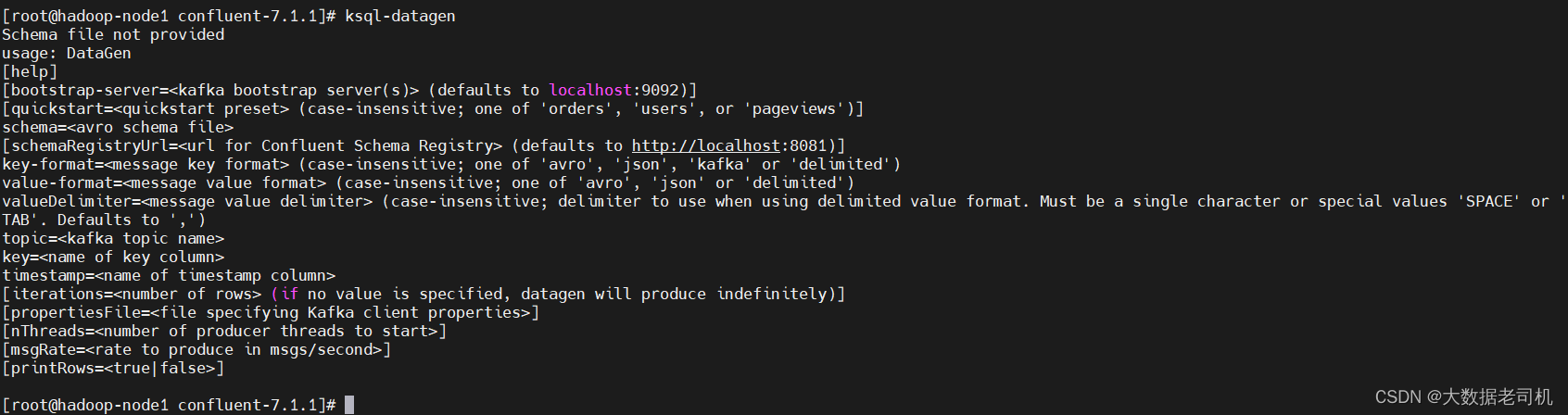
confluent自带了一个ksql-datagen工具,可以创建和产生相关的topic和数据,ksql-datagen可以指定的参数如下:
$ ksql-datagen
$ cd $CONFLUENT_HOME
$ ./bin/ksql-datagen quickstart=pageviews format=delimited topic=pageviews maxInterval=500 bootstrap-server=hadoop-node1:19092
ps:以上命令会源源不断在stdin上输出数据,就是工具自己产生的数据,如下样例
[1653124249561L] --> ([ 1653124249561L | 'User_3' | 'Page_82' ]) ts:1653124249561
[1653124249561L] --> ([ 1653124249561L | 'User_9' | 'Page_24' ]) ts:1653124249561
[1653124249561L] --> ([ 1653124249561L | 'User_9' | 'Page_91' ]) ts:1653124249561
[1653124249561L] --> ([ 1653124249561L | 'User_2' | 'Page_61' ]) ts:1653124249561
ps:不过使用consumer消费出来的数据是如下样式:
1653124249561L,User_3,Page_82
1653124249561L,User_9,Page_24
1653124249561L,User_9,Page_91
1653124249561L,User_2,Page_61
创建users,数据格式为json
$ cd $CONFLUENT_HOME
$ ./bin/ksql-datagen quickstart=users format=json topic=users maxInterval=100 bootstrap-server=hadoop-node1:19092
ps:以上命令会源源不断在stdin上输出数据,就是工具自己产生的数据,如下样例:
['User_6'] --> ([ 1495933043739L | 'User_6' | 'Region_8' | 'OTHER' ]) ts:1653124467578
['User_3'] --> ([ 1489611795658L | 'User_3' | 'Region_7' | 'MALE' ]) ts:1653124467578
['User_5'] --> ([ 1496009798562L | 'User_5' | 'Region_2' | 'MALE' ]) ts:1653124467578
不过使用consumer消费出来的数据是如下样式:
{"registertime":1495933043739L,"userid":"User_6","regionid":"Region_8","gender":"OTHER"}
{"registertime":1489611795658L,"userid":"User_3","regionid":"Region_7","gender":"MALE"}
{"registertime":1496009798562L,"userid":"User_5","regionid":"Region_2","gender":"MALE"}
3、创建stream和table
- 创建stream
根据topic pageviews创建一个stream pageviews_original,value_format为DELIMITED
$ cd $CONFLUENT_HOME
$ ./bin/ksql http://0.0.0.0:8088
# 【温馨提示】value_format 有三种格式 JSON(json格式)、DELIMITED(原生格式)、AVRO(Avro 格式是 Hadoop 的一种基于行的存储格式)
CREATE STREAM pageviews_original (viewtime bigint, userid varchar, pageid varchar) WITH (kafka_topic='pageviews', value_format='DELIMITED');
# 查看表详情
DESCRIBE pageviews_original;
# 删表
DROP STREAM pageviews_original;
# 查看topic
SHOW topics;
# 查看STREAMS
SHOW STREAMS;
- 创建table
根据topic users创建一个table users_original,value_format为json,必须设置一个为主键,也可以指定副本很分区数,默认都是1,, PARTITIONS=1, REPLICAS=1
CREATE TABLE users_original (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR PRIMARY KEY) WITH (kafka_topic='users', value_format='JSON')

- 创建持久查询
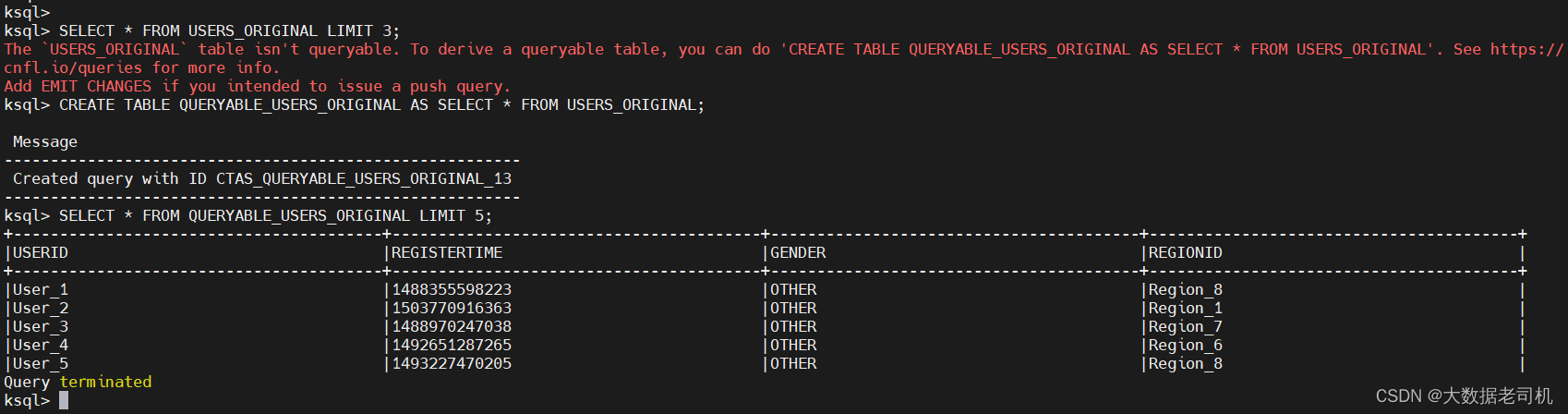
# 上面创建的表时不能直接查询数据的
SELECT * FROM USERS_ORIGINAL LIMIT 3;
CREATE TABLE QUERYABLE_USERS_ORIGINAL AS SELECT * FROM USERS_ORIGINAL;
# 查询数据
SELECT * FROM QUERYABLE_USERS_ORIGINAL LIMIT 5;
- Kafka Connect 接收器
CREATE SINK CONNECTOR es_sink WITH (
'connector.class' = 'io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
'key.converter' = 'org.apache.kafka.connect.storage.StringConverter',
'topics' = 'clicks_transformed',
'key.ignore' = 'true',
'schema.ignore' = 'true',
'type.name' = '',
'connection.url' = 'http://hadoop-node1:9200');
4、持久化查询
持久化查询可以源源不断的把查询出的数据发送到你指定的topic中去,查询的时候在select前面添加create stream关键字即可创建持久化查询。
# 生成数据
$ cd $CONFLUENT_HOME
$ ./bin/ksql-datagen quickstart=pageviews format=delimited topic=pageviews maxInterval=500 bootstrap-server=hadoop-node1:19092
# 先删除
DROP STREAM pageviews_original;
# 创建查询
CREATE STREAM pageviews_original (viewtime bigint, userid varchar, pageid varchar) WITH (kafka_topic='pageviews', value_format='DELIMITED');
# 直接查
select * from pageviews_original limit 10;
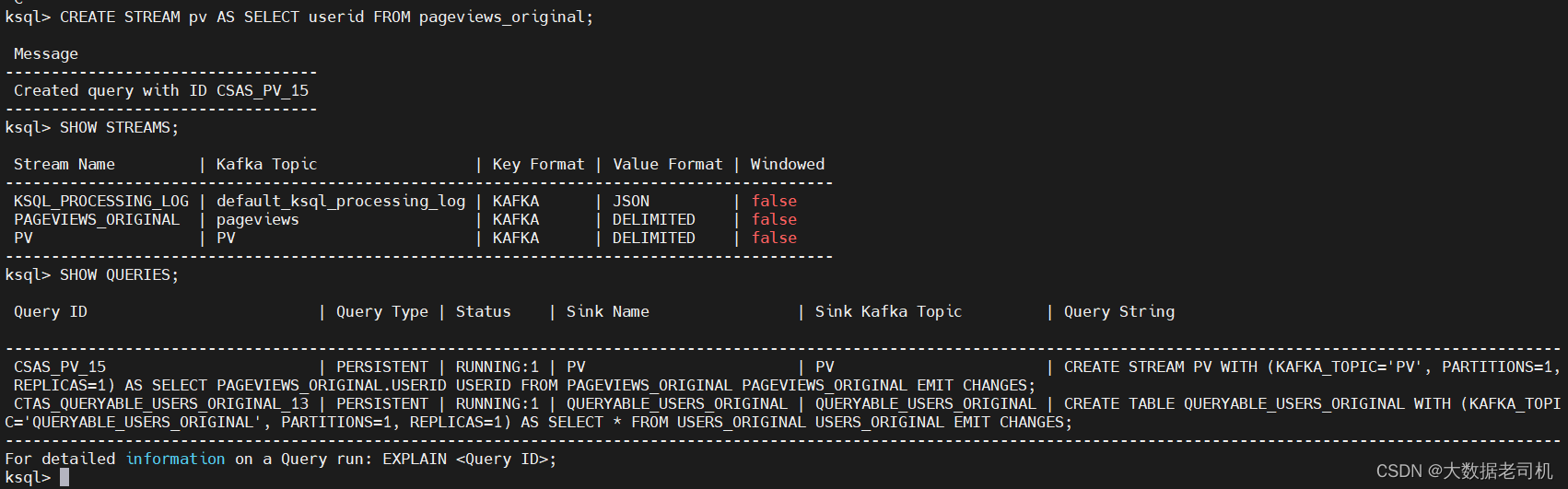
# 持久化查询,PO会对应一个topic
CREATE STREAM PO AS SELECT userid FROM pageviews_original EMIT CHANGES;
# 查询新stream
SHOW STREAMS;
# 查询执行任务
SHOW QUERIES;
消费新数据
$ kafka-console-consumer --bootstrap-server 192.168.0.113:19092 --from-beginning --topic PO
终止查询任务
SHOW QUERIES;
TERMINATE CSAS_PV_15;
四、Mock(生产者)
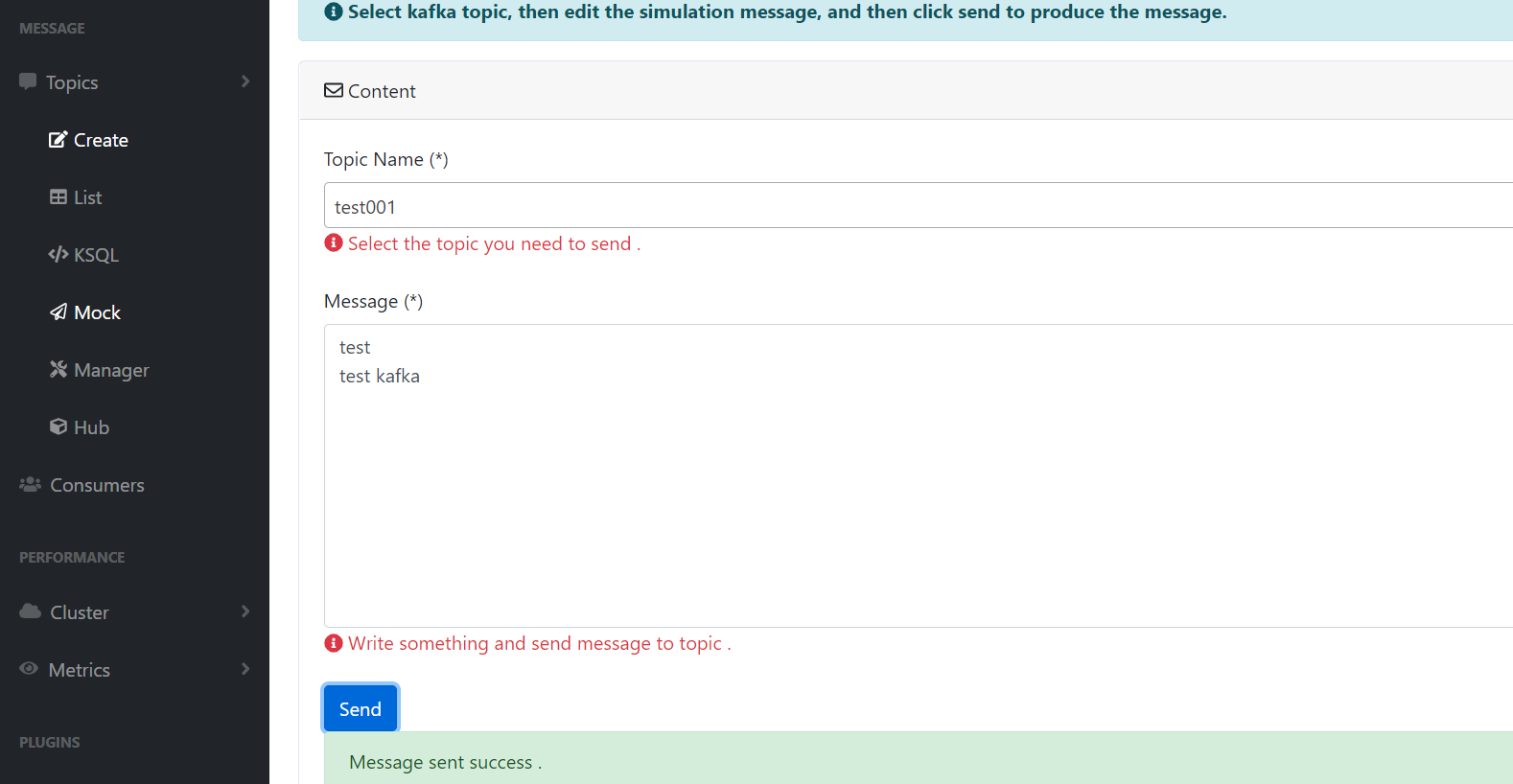
这个就是模拟测试的功能,就是推送数据到kafka topic,其实就是生产者。一般作为测试用。
消费数据
$ kafka-console-consumer.sh --bootstrap-server hadoop-node1:19092 --topic test001 --from-beginning

五、Manager
添加、查看、删除topic配置等功能,操作也很简单
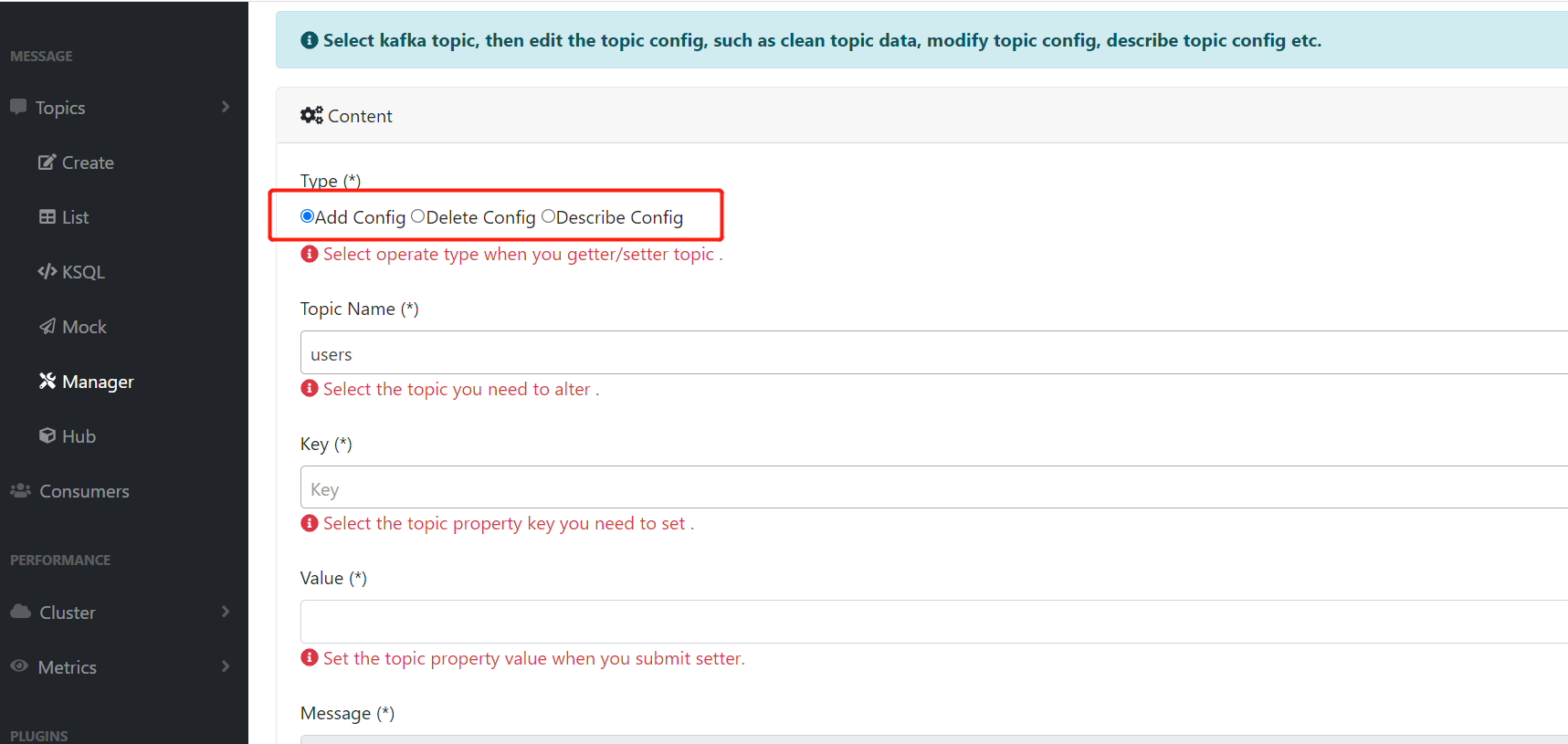
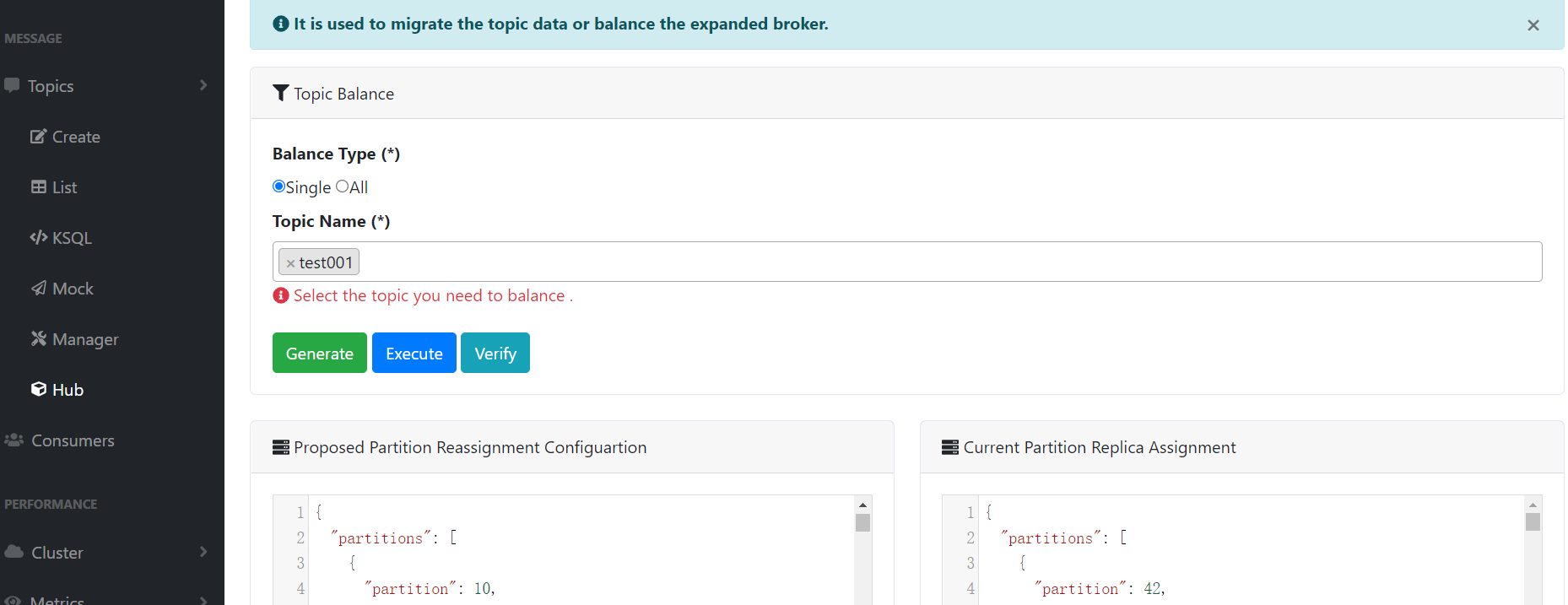
六、Hub
topic数据迁移或是数据平衡
关于EFAK和KSQL先到这里,有疑问的小伙伴,欢迎给我留言,后续会更新更多关于大数据的文章,请耐心等待~