Part 1: Work Distribution and Scheduling
为了高性能优化目标:
- 在所有可执行资源上达到负载均衡
- 降低communication,避免stalls
- 减少额外的overhead
负载均衡
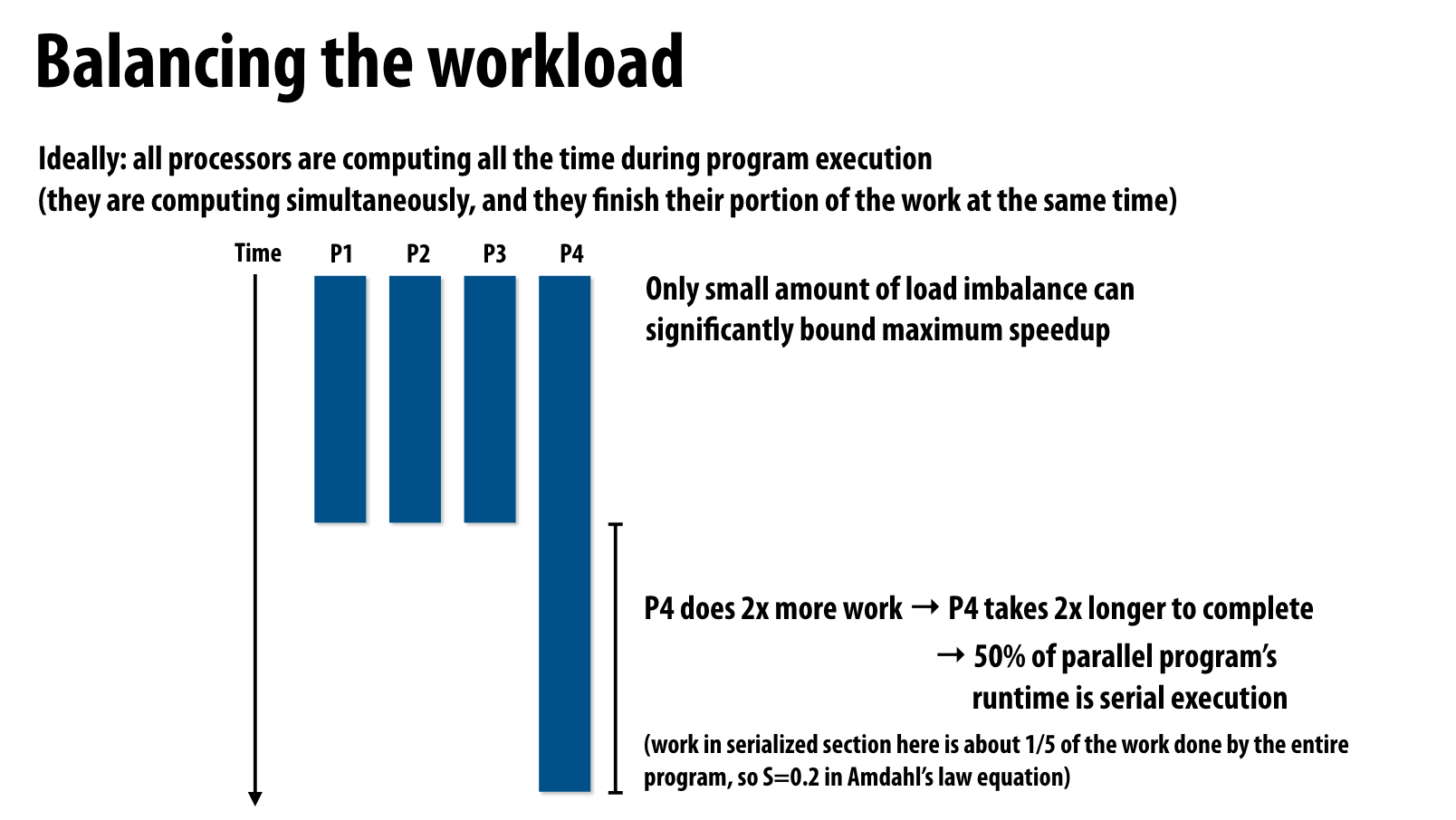
在assign1中我们已经深刻体会到了负载不均衡对于程序带来的深刻的影响,执行最慢的进程会拖累整体的执行时间。
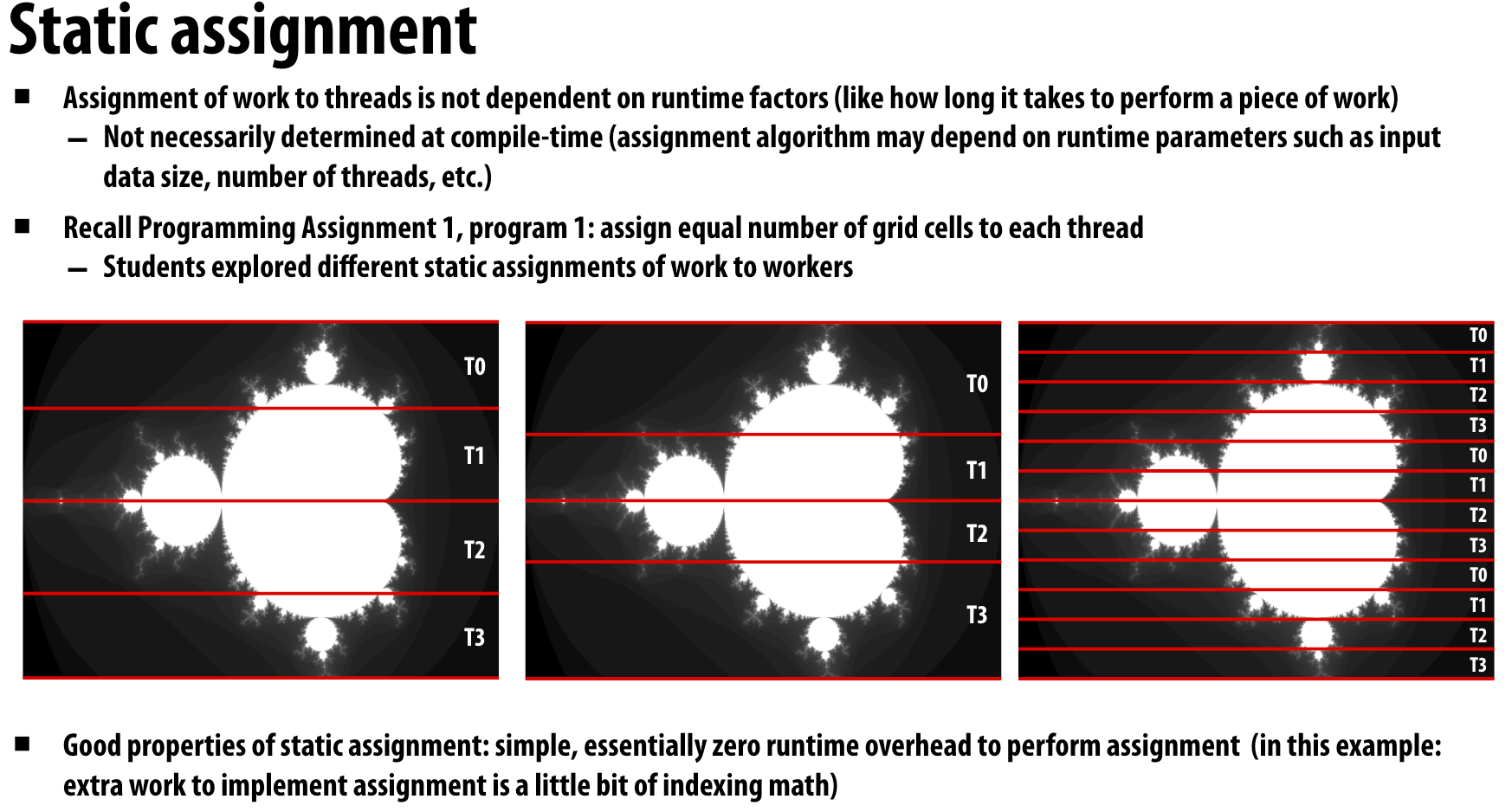
Static assignment
就是在code里面就数据进行切分,然后分配给不同线程或者worker,当我们已知执行数据的计算复杂度分布,使用静态assign的方式是可以good way
“Semi-static” assignment
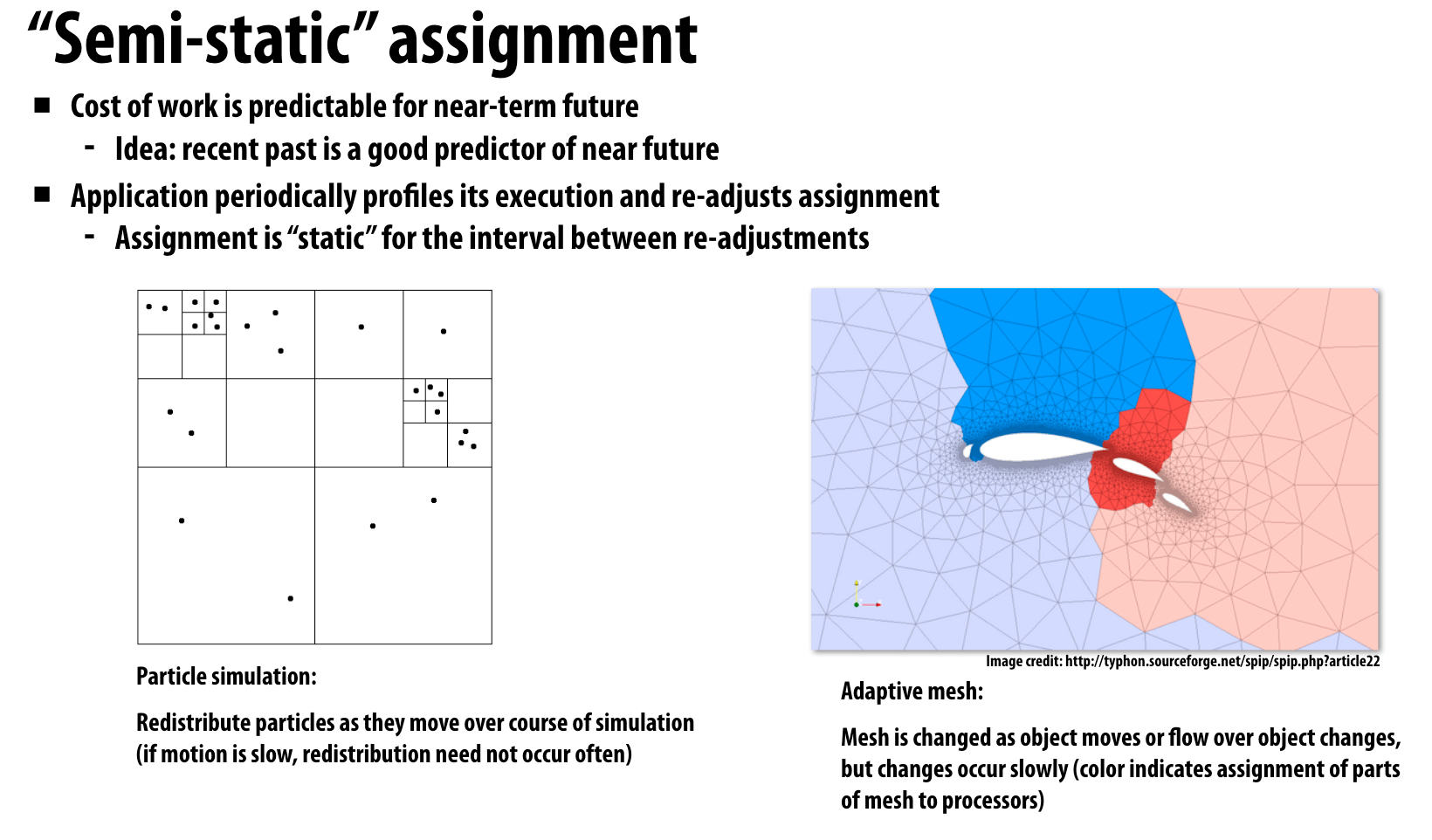
虽然数据的分布可能会变,但是在一段时间内我们可以假设数据分布变化不大,因此可以在一段时间内计算都使用相同的assign方式。但是过了一段时间数据分布可能会变,这时候需要再重新设计assign
Dynamic assignment
在执行过程中,动态确定assign

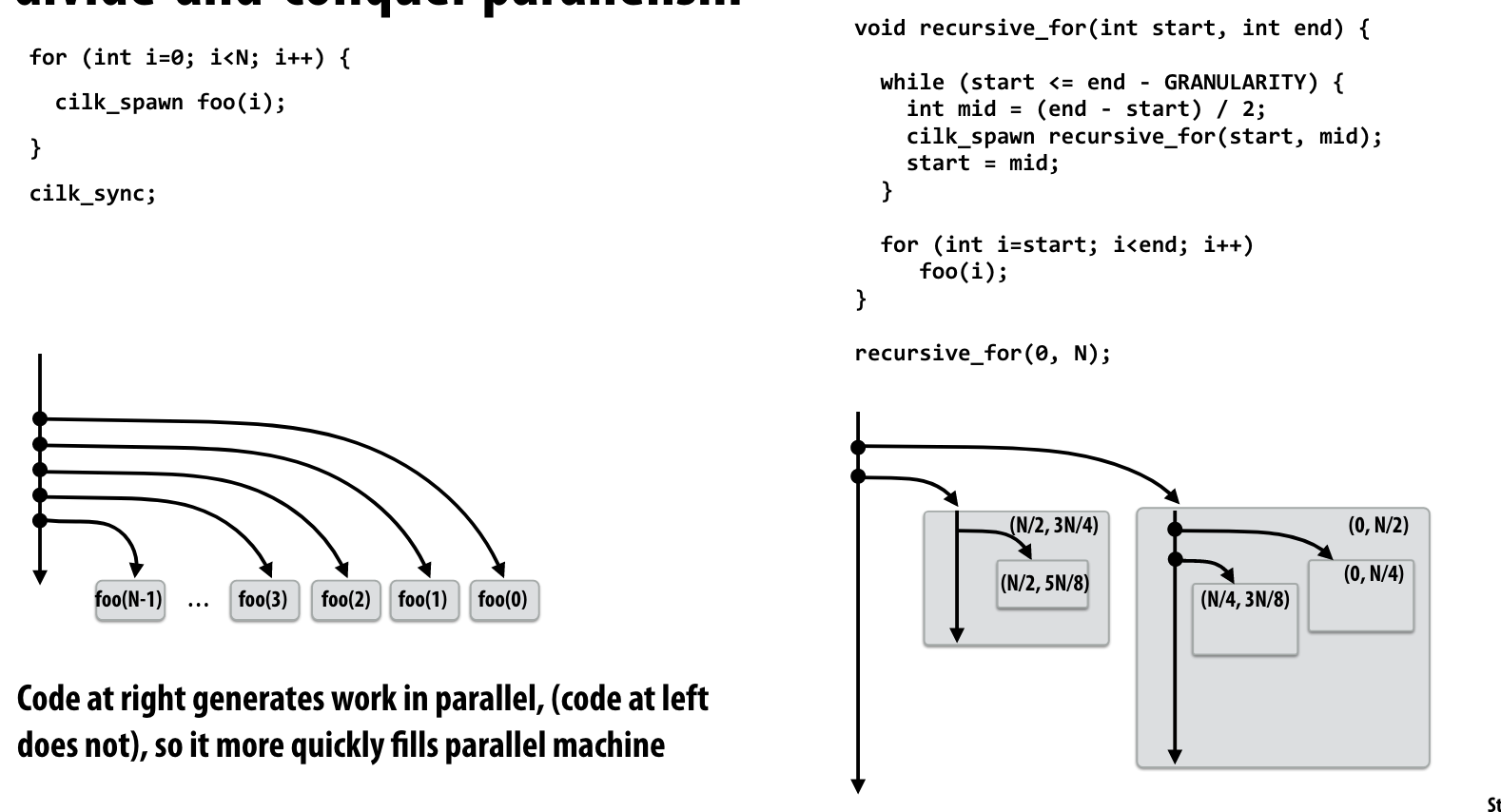
Increasing task granularity
如果线程一直在进入临界区,就会导致程序执行大部分时间都在等待临界区资源的释放。我们可以让程序执行更多任务后,再进入临界区分配。
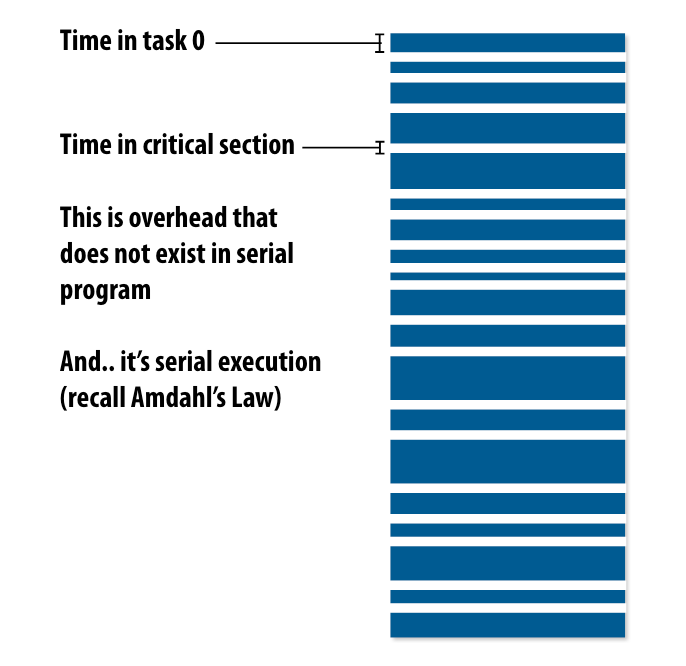
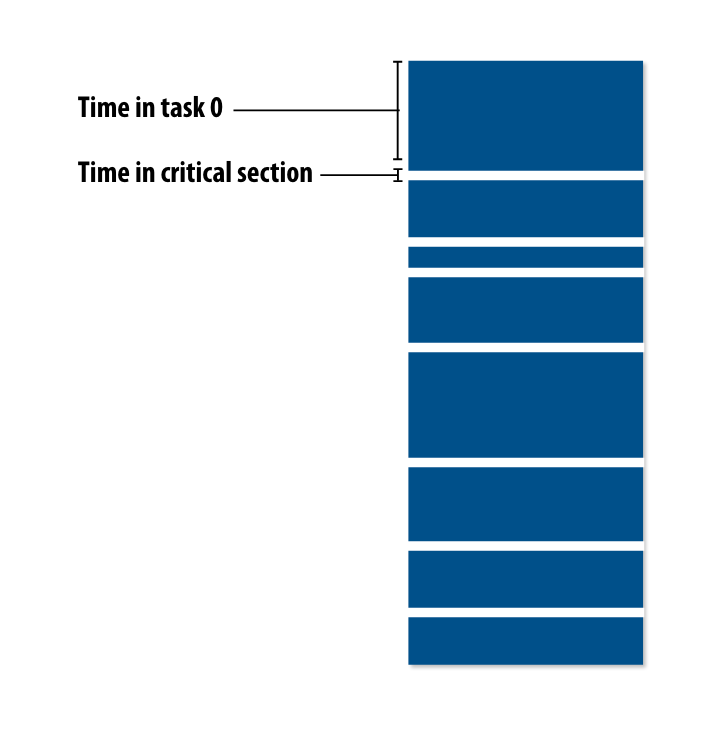
- task size应该比处理器数量多很多
- task数量越少,对于assign的overhead越小
- assign的粒度是一个trade-off
Smarter task scheduling
更加合理地进行task分配
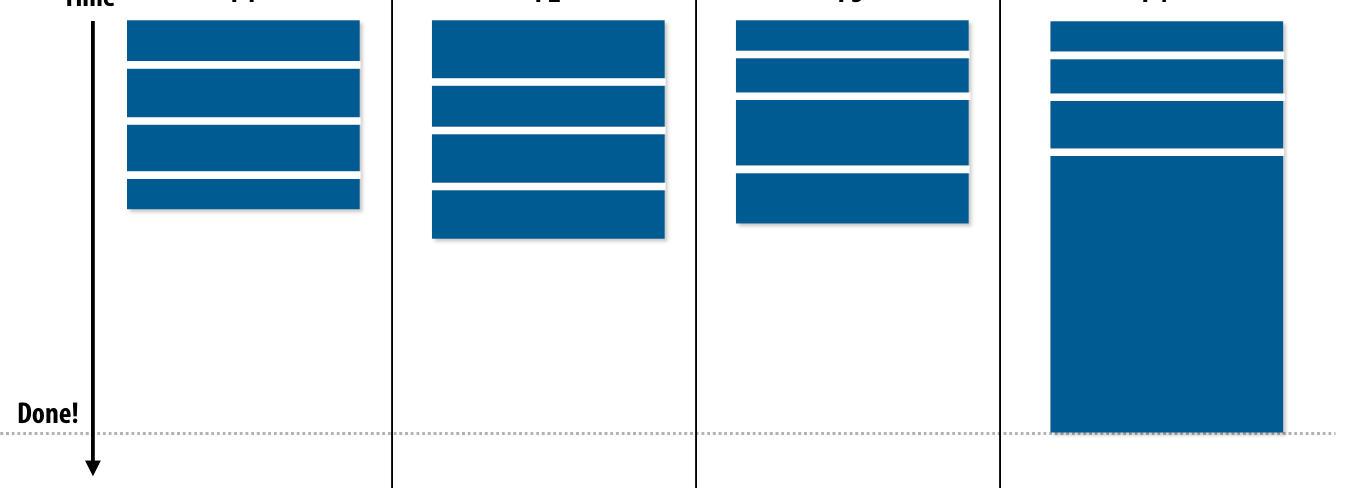
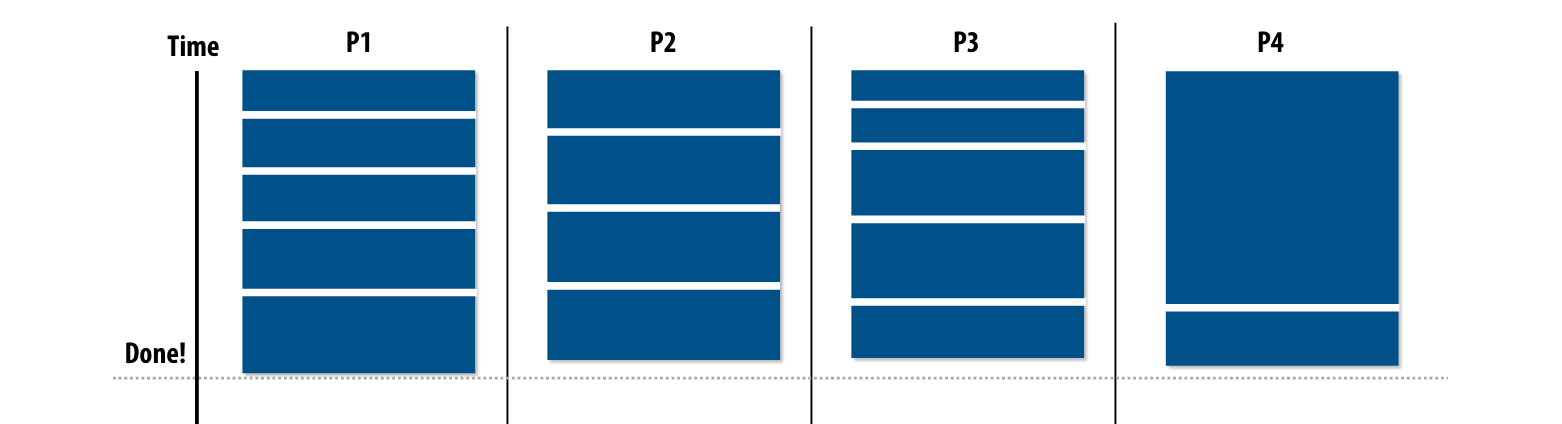
distributed queues
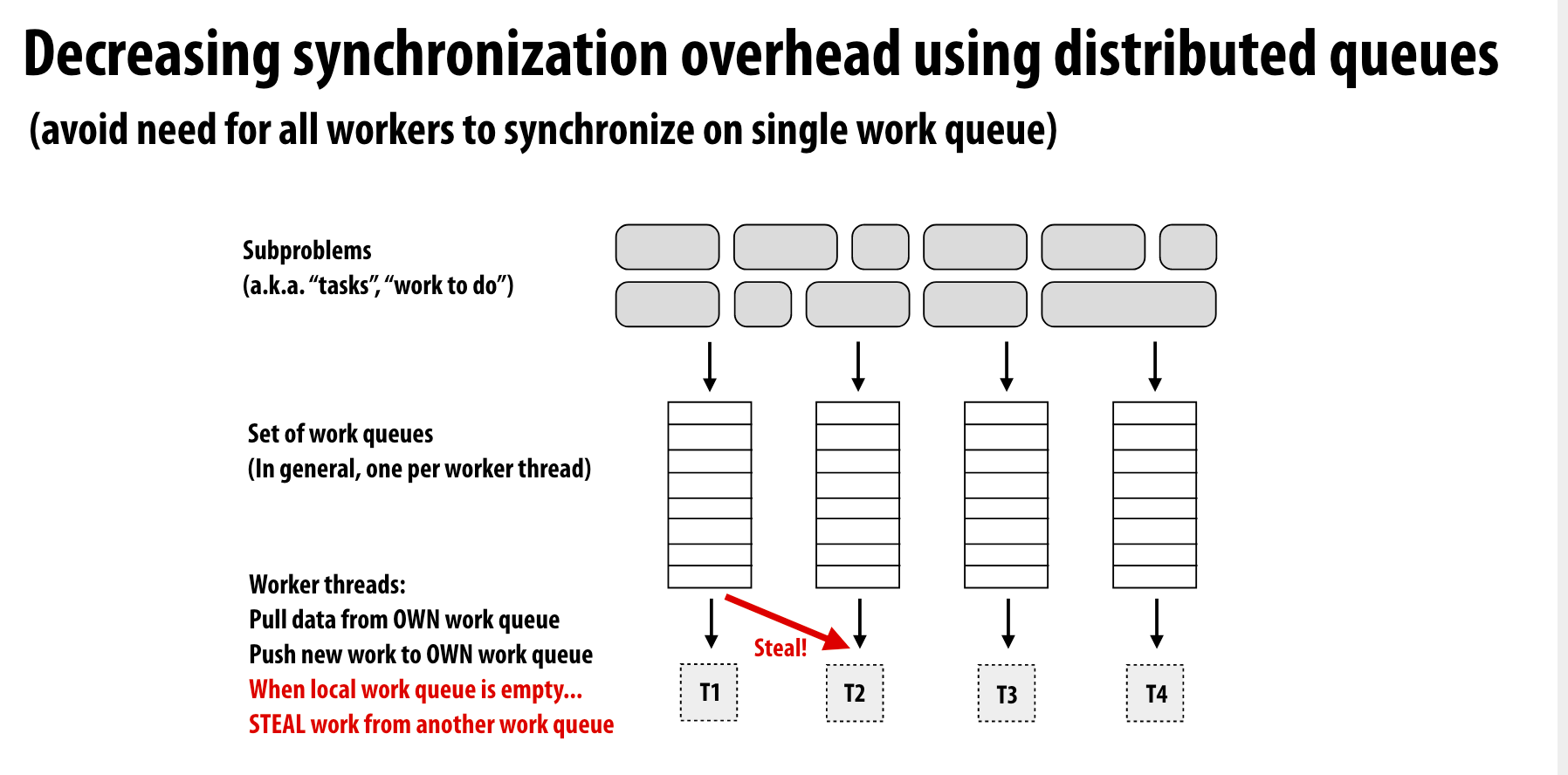
当一个线程的执行队列为空后,会从另一个队列中窃取任务
Scheduling fork-join parallelism
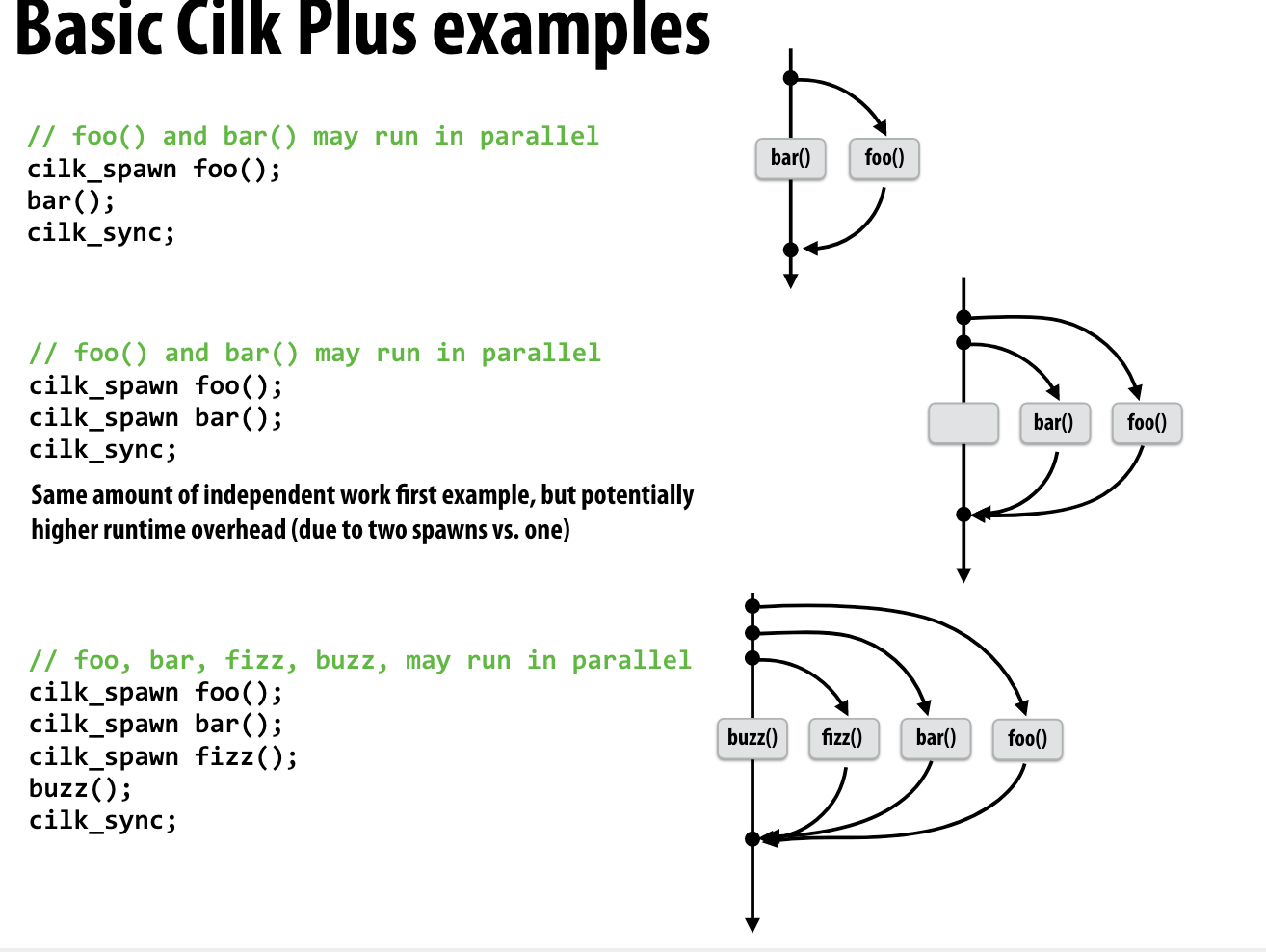
cilk_spawn foo(args) 相当于fork出一个线程来执行foo
cilk_sync 相当于c++ Thread中的join操作
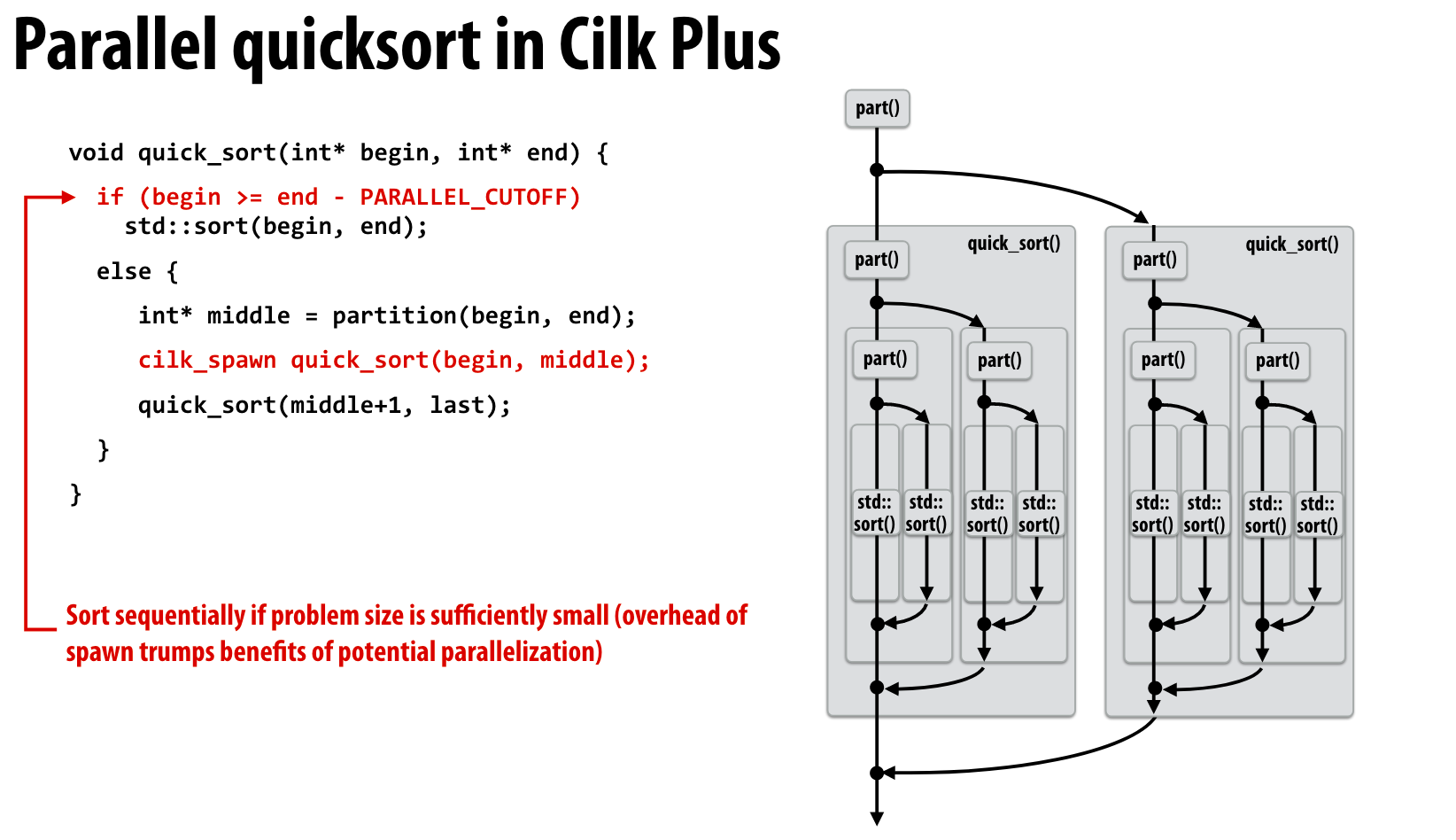
quick sort的并行
执行spawn code or follow code
这里教授提了一个问题,我觉得很有意思。一个正在执行的线程,如果遇到cilck_spawn,那么他是继续执行当前线程下面的代码,让新的线程执行执行spawn code,还是自己执行spawn code让新的线程执行follow code?
Run continuation first or Run child first?
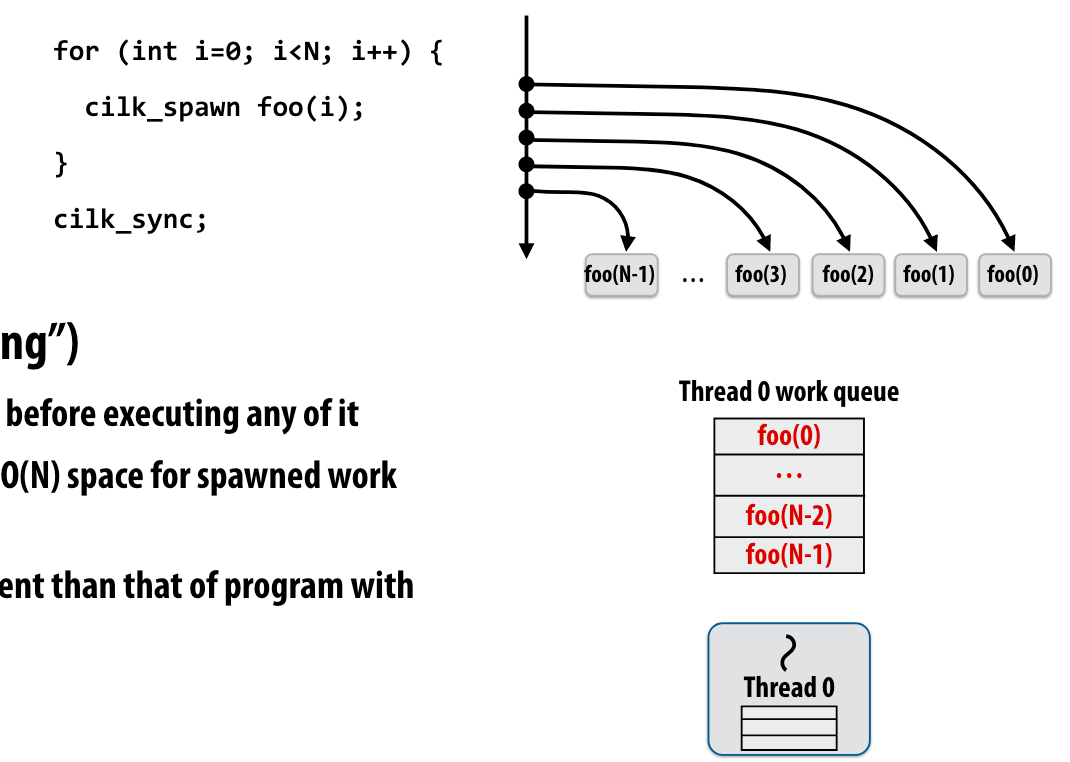
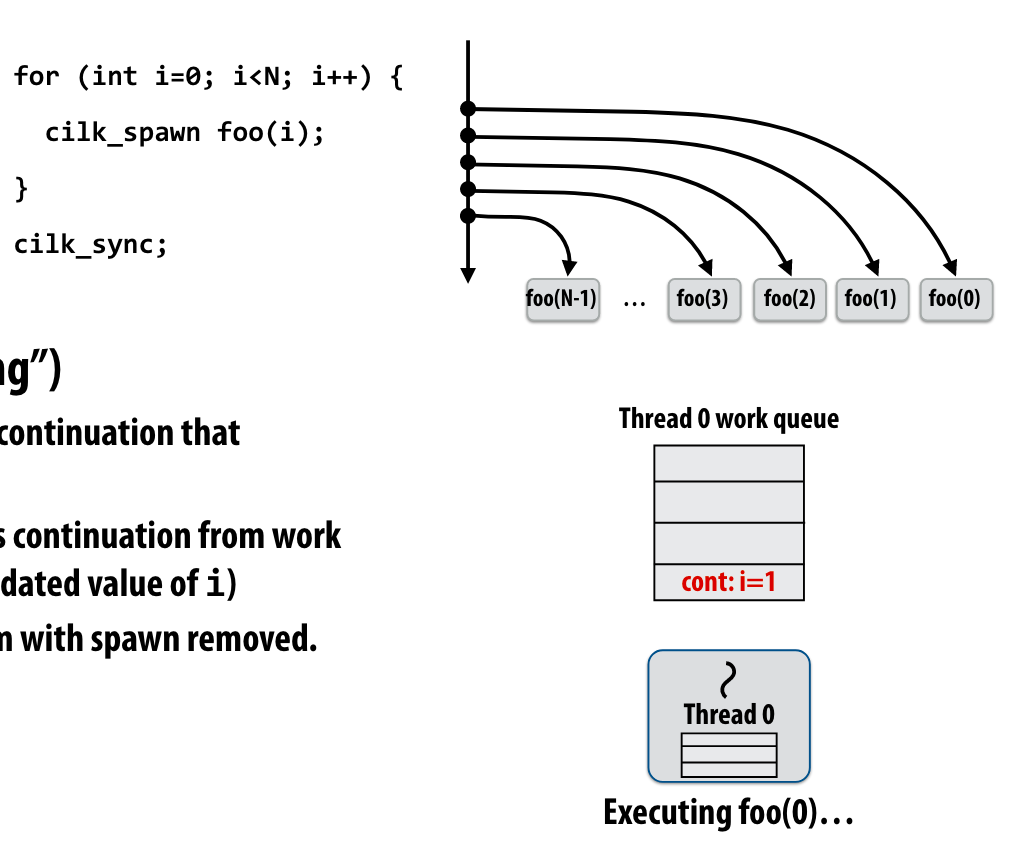
这里教授用quick sort举例子,说明了,child first的执行方式是更好的

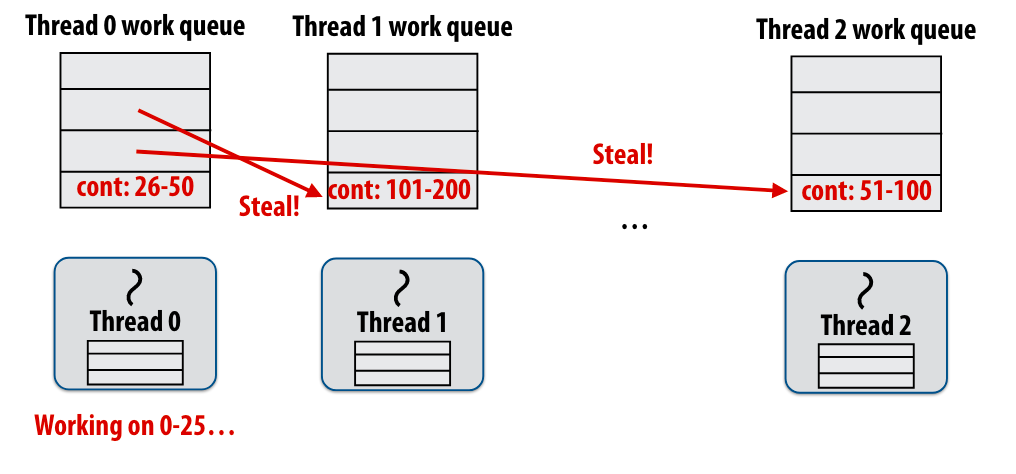
通过child first,我们的task queue的队列深度可以维持在较小的程度,不至于因为一直cilck_spawn导致爆掉。
Part II: Locality, Communication, and Contention
Shared address space
还是之前提到的例子
这里使用了share mem的方式
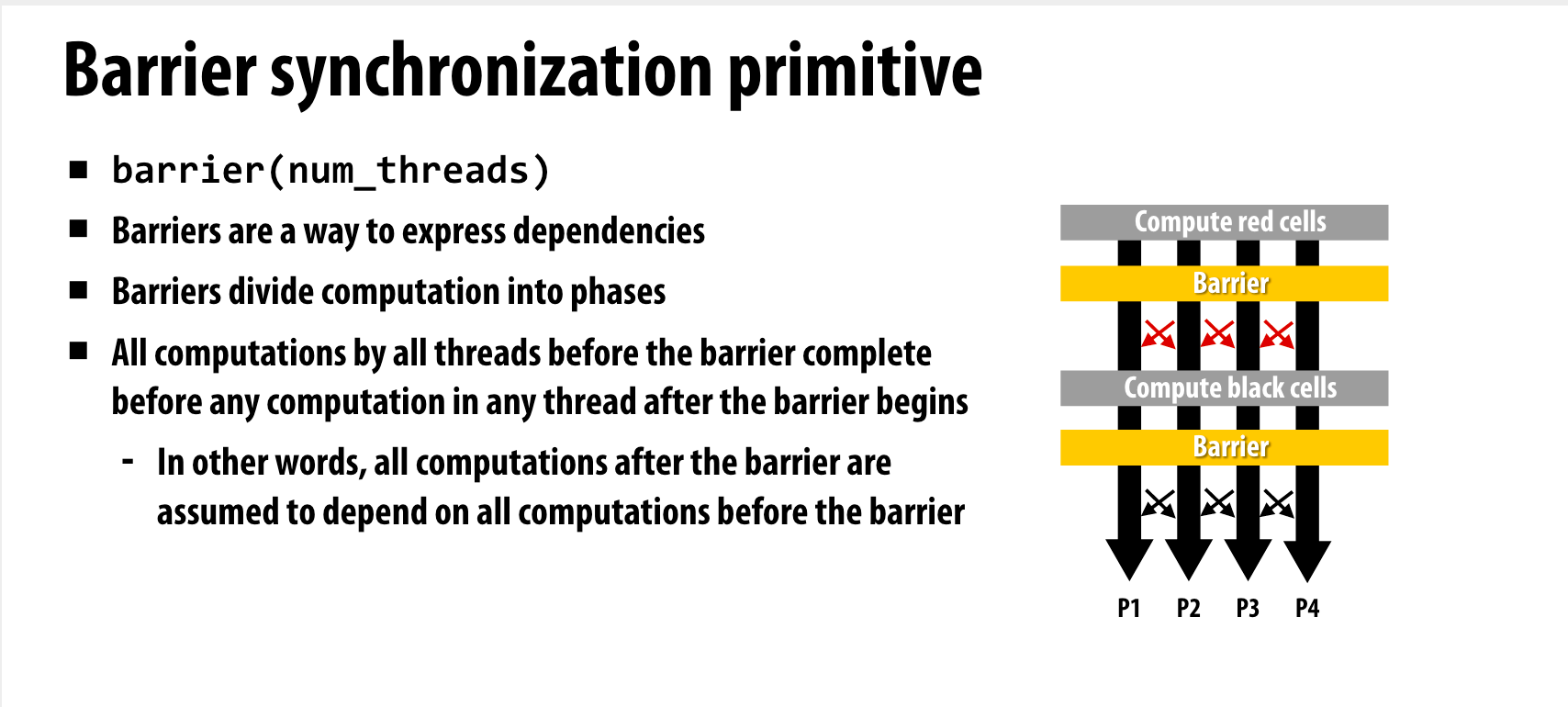
教授举了一个降低barrier的例子


相当于把diff这个依赖给去除了
Message passing
不同于share mem来解决问题,这里使用message passing的方式

这里有一个概念,就是communication-to-computation ratio:
\[amount of communication (e.g., bytes)\\ ------------------ \\ amount of computation (e.g., instructions) \]“Arithmetic intensity” = 1 / communication-to-computation ratio
计算和communication的比值应该是越大越好。
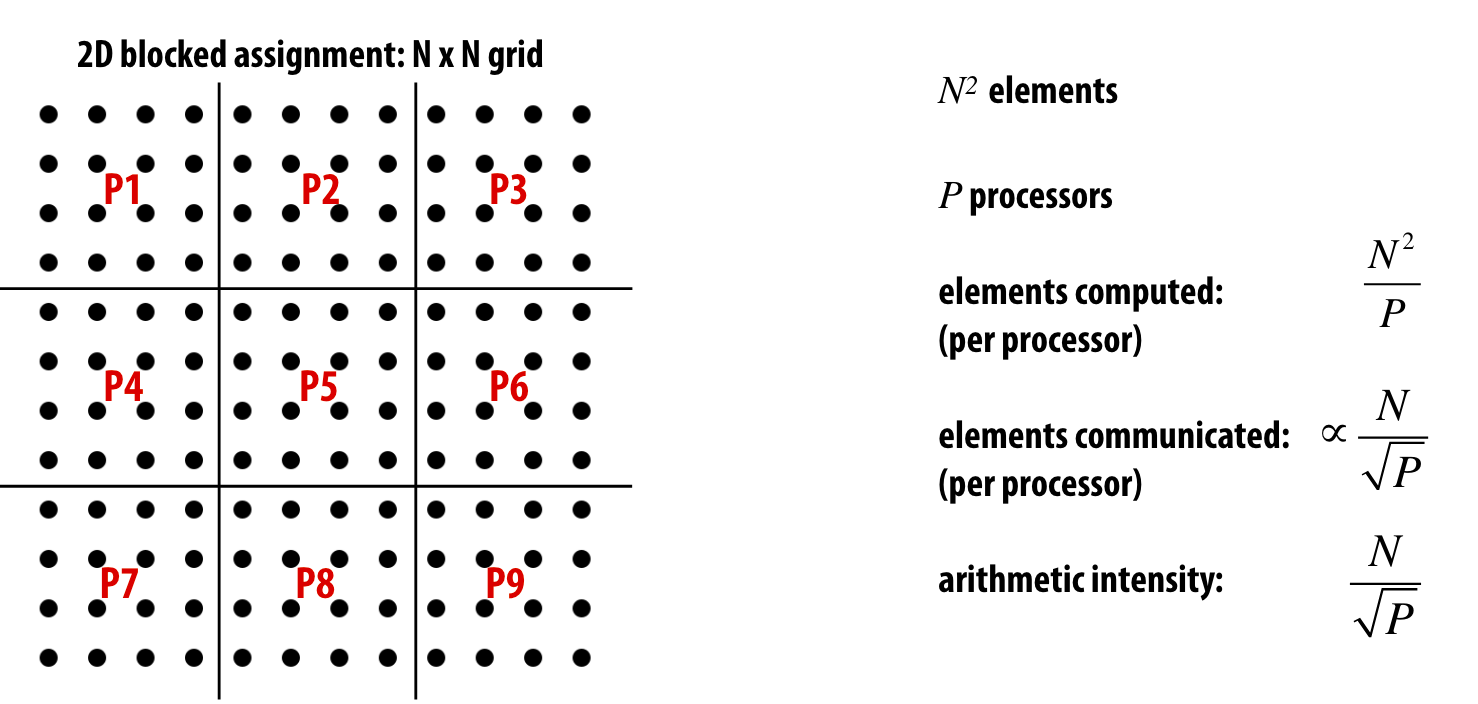
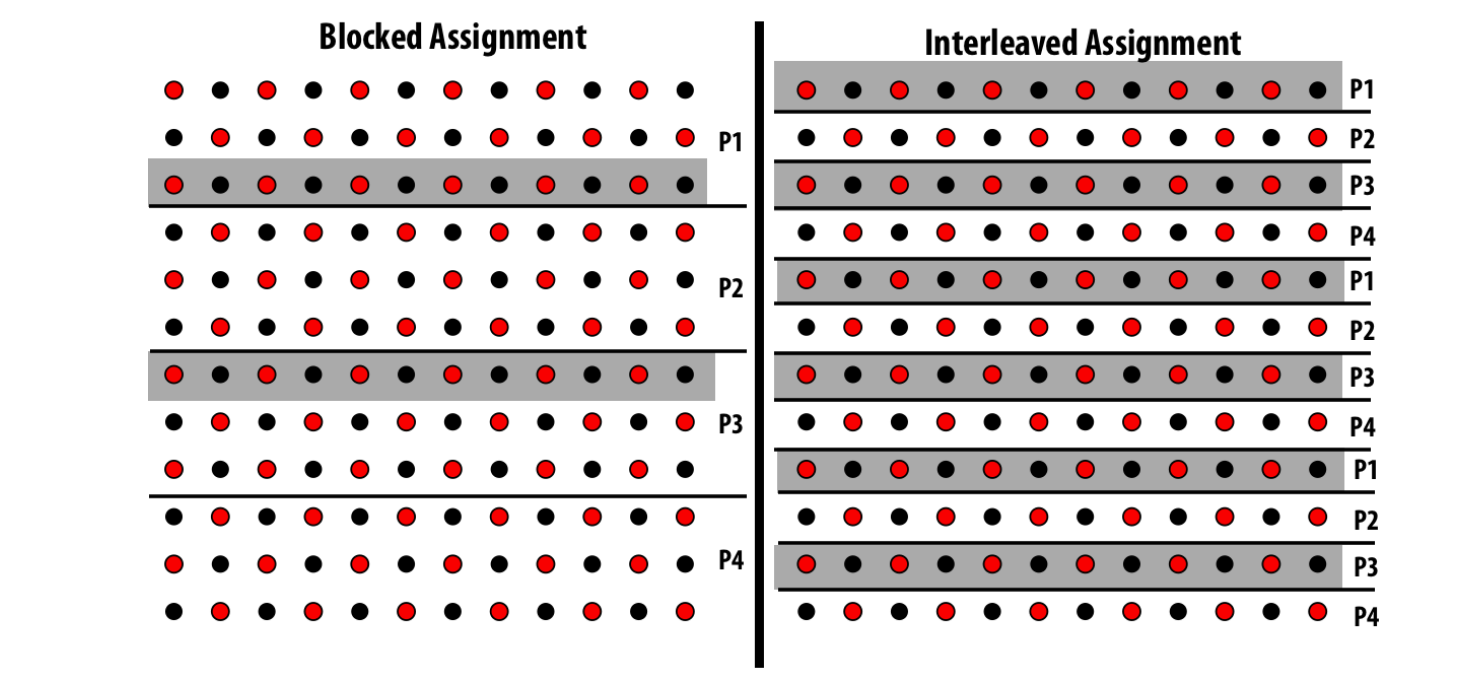
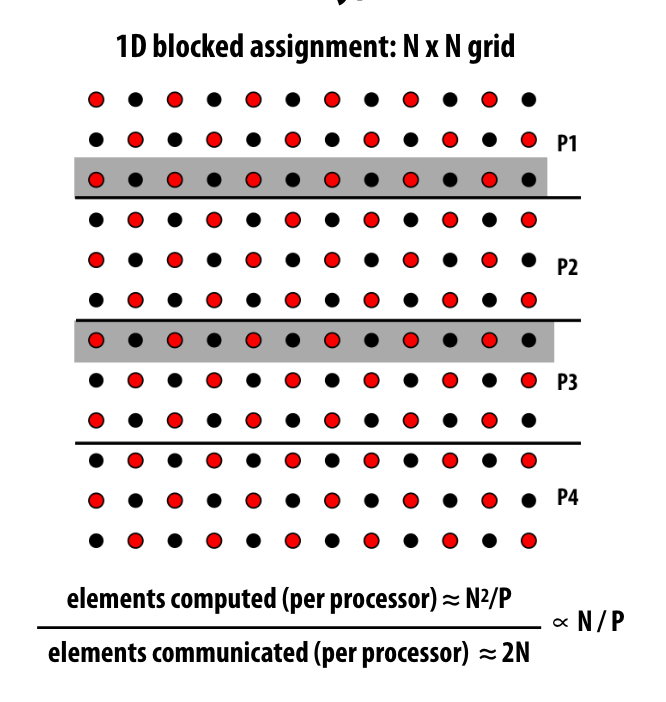
如果是block assign的方式, 计算和交流比 为 N / p
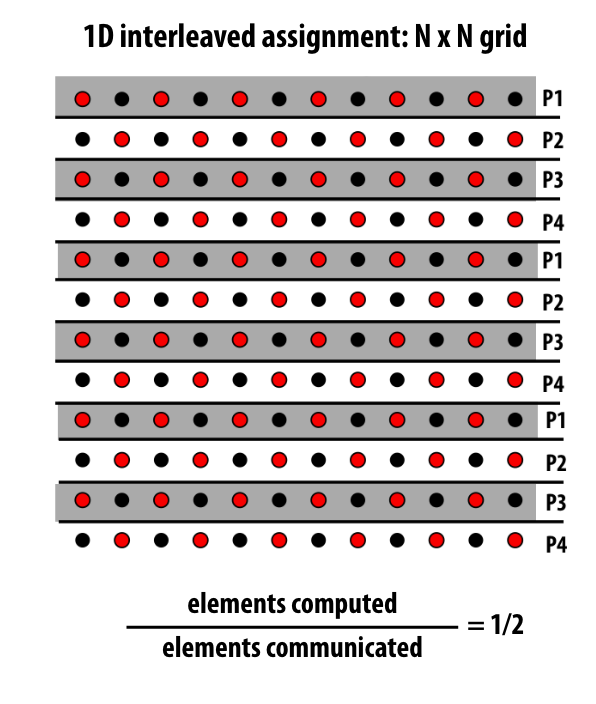
如果是inter leaf的方式,计算和交流比为 1 / 2
如果是方阵形式进行数据切分,计算与交流比为\(\frac{N}{\sqrt{P}}\):