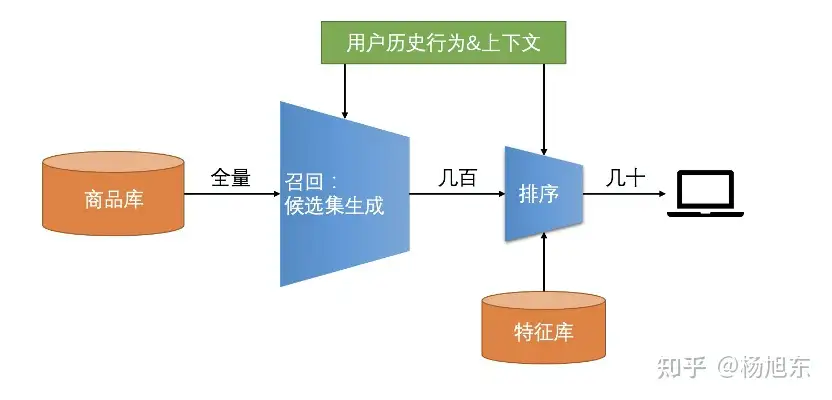
粗略来看,推荐算法可以简单地分为召回和排序两个阶段。召回模块负责从海量的物品库里挑选出用户可能感兴趣的物品子集,过滤之后通常返回几百个物品。排序模块负责对召回阶段返回的物品集个性化排序,通常返回几十个物品组成的有序列表。
总结起来,召回和排序有如下特点:
- 召回层:候选集规模大、模型和特征简单、速度快,尽量保证用户感兴趣数据多召回。
- 排序层:候选集不大,目标是保证排序的精准,一般使用复杂和模型和特征。
使用排序模块的三个原因:
- 多路召回的候选集缺乏统一的相关性度量,不同类型的召回物品不可比;
- 召回阶段通常只计算候选物品的相关性,对业务指标(如转化率、dwell time、GMV等)缺乏直接有效的度量;
- 当有多个业务关心的指标时,召回模块通常无能为力。
比如,在电商场景业务通常比较关心总成交额(GMV)这一指标,通过目标拆解:GMV = 流量 × CTR × CVR × price,我们发现流量和price通常不是算法能够控制的,那么算法需要干预的是CTR和CVR,也就是点击率和转化率。我们可以分别训练一个点击率预估模型和一个转化率预估模型,或者只训练一个多目标模型同时建模点击率预估和转化率预估。有了预估的CTR和CVR之后,我们就可以按照如下公式来对候选商品排序: