开发nodejs RESETful api 创建项目流程
1. 安装 vm-windows、node.js 和 npm
安装 Node.js 时, 建议使用版本管理器,因为版本变更速度非常快。 你可能需要根据所使用的不同项目的需要在多个 Node.js 版本之间进行切换。 Node 版本管理器(通常称为 nvm)是安装多个版本的 Node.js 的最常见方法,但仅适用于 Mac/Linux,在 Windows 上不受支持。 相反,我们建n议安装 nvm-windows,然后使用它来安装 Node.js 和 Node Package Manager (npm)
请注意:
重要
在安装版本管理器之前,始终建议从操作系统中删除 Node.js 或 npm 的任何现有安装,因为不同的安装类型可能会导致出现奇怪和混淆的冲突。 这包括删除可能保留的任何现有的 Node.js 安装目录(例如,“C:\Program Files\nodejs”)。 NVM 生成的符号链接不会覆盖现有的(甚至是空的)安装目录。 有关删除先前安装的帮助,请参阅如何从 Windows 中完全删除 node.js
-
请遵循 windows-nvm 存储库上的安装说明。 建议使用安装程序,但如果对需求有更深入的了解,可能需要考虑手动安装。 安装程序将指向最新版本发布页面
-
下载最新版本的 nvm-setup.zip 文件。
-
下载完成后,打开 zip 文件,然后打开 nvm-setup.exe 文件
-
Setup-NVM-for-Windows 安装向导将引导你完成安装步骤,包括选择将在其中安装 nvm-windows 和 Node.js 的目录)
-
安装完成后。 打开 PowerShell(建议使用提升的管理员权限打开),尝试使用 windows-nvm 来列出当前安装的 Node 版本(此时应为无):
nvm ls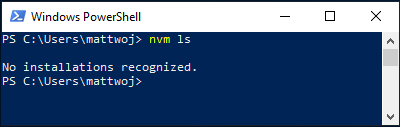
-
安装 Node.js 的当前版本(用于测试最新的功能改进,但比 LTS 版本更容易出现问题):
nvm install latest -
要安装 Node.js 的最新稳定 LTS 版本(建议),首先通过
nvm list available查找当前的 LTS 版本号,然后使用nvm install <version>安装 LTS 版本号(将<version>替换为版本号nvm install 12.14.0))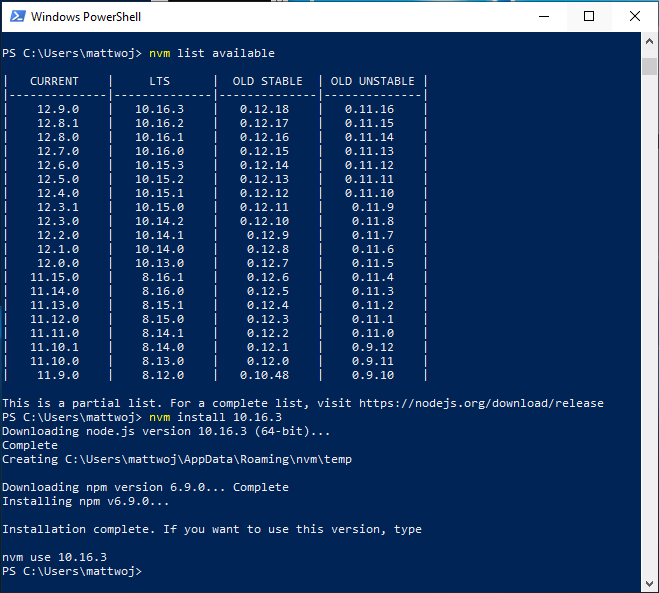
-
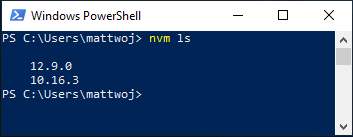
出安装的 Node 版本:
nvm ls。现在应会看到刚安装的两个版本
-
在安装所需的 Node.js 版本后,通过输入
nvm use <version>(请将<version>替换为版本号,即nvm use 12.9.0)来选择要使用的版本。
2. 使用 Express 创建Nodejs Web RESETful api 应用
Express 是简约、灵活、流畅的 Node.js 框架,可便于更轻松地开发 Web 应用,以处理 GET、PUT、POST 和 DELETE 等多种类型的请求。 Express 随附一个应用生成器,可用于自动创建应用的文件体系结构。
-
打开命令行(命令提示符、Powershell 或你喜欢的任何工具)。
-
创建新项目文件夹
mkdir ExpressProjects并输入以下目录:cd ExpressProjects -
使用
npm install -g express-generator命令全局安装express-generator脚手架 -
创建项目:
# 创建项目 express --no-view demo-api # 进入项目目录 cd demo-api # 安装依赖包 npm i # 启动项目 npm start我们使用了
--no-view参数,它的意思是不需要任何视图模板,因为我们这个项目专门做后端接口的- 你现在可以打开 Web 浏览器并转到
localhost:3000来查看这个正在运行的应用
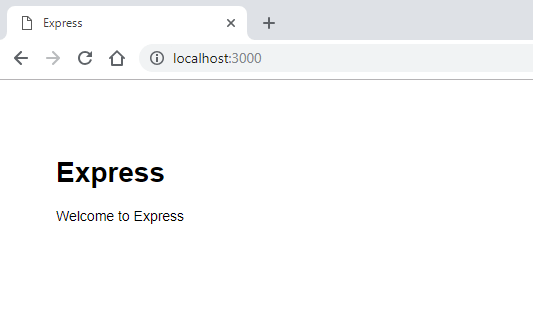
- 你现在可以打开 Web 浏览器并转到
3. nodemon 监听修改
当我们修改代码后,你不重启服务,它根本就不会生效就需要安装nodemon来实现热更新
npm i nodemon
然后打开项目根目录下的package.json,将start这里修改为
"scripts": {
"start": "nodemon ./bin/www"
}
改完后,我们再次启动服务
npm start
当我们再次修改项目后 无需重启 修改后的api 可以直接生效
4.使用Docker安装数据库MySql
-
安装Docker
进入Docker官网后,Get Started | Docker,直接下载安装。window需要进入进入控制面板,找到启动或关闭 Windows 功能,确认Hyper-v与适用于 Linux 的 Windows 子系统勾选上了

如果还是不能启动Docker,还有可能是Linux 子系统版本太老了。可以打开PowerShell,运行命令更新
wsl --update
完成后重启电脑 再次启动Docker -
使用 docker compose 安装mysql
在你的项目目录中创建一个名为docker-compose.yml的文件。这个文件将定义你的服务、网络和卷。services: mysql: image: mysql:8.3.0 command: --default-authentication-plugin=mysql_native_password --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci environment: - MYSQL_ROOT_PASSWORD=colin1234 - MYSQL_LOWER_CASE_TABLE_NAMES=0 ports: - "3306:3306" volumes: - ./data/mysql:/var/lib/mysql
导航到包含 docker-compose.yml 文件的目录,然后运行以下命令
docker-compose up -d
这样,MySQL就会自动下载好,并启动起来了
5. 创建数据库
我们先来创建数据库。打开客户端软件,并连接上去。选择,新增数据库

设置数据库名字为demo_api_development
字符集,也就是编码的选择,这里默认使用了utf8mb4``utf8是一种能非常好的支持世界各国语言的编码。后面的mb4可以让数据库正确的存储emoji表情符号,所以我们就用这个
排序规则,意思是,对文本数据进行比较和排序时,该如何处理顺序和规则。这里选择utf8mb4_general_ci,它的意思是:不区分大小写,不区分重音符号。

点击确定数据库创建完成
6. 使用 Sequelize ORM
Sequelize 中文文档是一个基于 promise 的 Node.js ORM, 目前支持 Postgres, MySQL, MariaDB, SQLite 以及 Microsoft SQL Server. 它具有强大的事务支持, 关联关系, 预读和延迟加载,读取复制等功能
ORM对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,在数据库和编程语言之间建立一种映射关系。从效果上说,它其实是创建了一个可在编程语言里使用的--“虚拟对象数据库”。
- 安装sequelize的命令行工具
npm i -g sequelize-cli
- 安装当前项目所依赖的
sequelize包和对数据库支持依赖的mysql2
npm i sequelize mysql2
3. 在项目根目录中初始化
sequelize init
初始化完成后项目中会生成sequelize所需的目录和文件
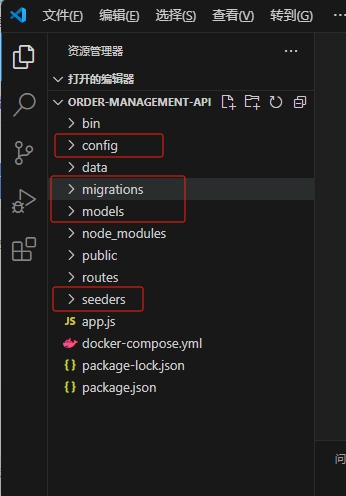
.
├── config
│ └── config.json
├── migrations
├── models
│ └── index.js
└── seeders
在编辑器中,也可以看到项目中新增了这些东西,现在一一看看,它们是用来干嘛的
-
config:这里放的也就是
sequelize所需要的连接数据库的配置文件。 -
migrations:是迁移的意思,如果你需要对数据库做新增表、修改字段、删除表等等操作,就需要在这里添加迁移文件了。而不是像以前那样,使用客户端软件来直接操作数据库
-
models:模型文件,当我们使用
sequelize来执行增删改查时,直接对模型进行操作每个模型都对应数据库中的一张表 -
seeders,是存放的种子文件。需要添加测试数据到数据表时。用命令行执行种子文件数据表中会自动填充进一些用来测试内容
7. sequelize连接数据库、模型、迁移、种子
- 数据库连接配置,首先打开项目目录下的
config/config.json文件,这里是连接数据库的配置,当我们配置好这个文件之后Node项目就会自动连接到数据库
{
"development": {
"username": "root",
"password": null,
"database": "database_development",
"host": "127.0.0.1",
"dialect": "mysql"
},
"test": {
"username": "root",
"password": null,
"database": "database_test",
"host": "127.0.0.1",
"dialect": "mysql"
},
"production": {
"username": "root",
"password": null,
"database": "database_production",
"host": "127.0.0.1",
"dialect": "mysql"
}
}
- 生成模型和迁移文件
通过sequelize命令来生成模型,每个模型都对应一个数据库中的数据表, 在代码中对模型进行操作及操作数据库
sequelize model:generate --name User --attributes username:string,password:string
打开models/user.js。可以看到,在模型文件夹中,出现了一个叫做User的模型,它里面有username和password类型都是字符串,根据上面的命令生成。
// models/user.js
'use strict';
const {
Model
} = require('sequelize');
module.exports = (sequelize, DataTypes) => {
class User extends Model {
/**
* Helper method for defining associations.
* This method is not a part of Sequelize lifecycle.
* The `models/index` file will call this method automatically.
*/
static associate(models) {
// define association here
}
}
User.init({
username: DataTypes.STRING,
password: DataTypes.STRING
}, {
sequelize,
modelName: 'User',
});
return User;
};
打开migrations文件夹,里面出现了一个由当前时间,加上create-user命名的文件,这个就是User模型对应的迁移文件
// migrations/20240915073618-create-user.js文件
'use strict';
/** @type {import('sequelize-cli').Migration} */
module.exports = {
async up(queryInterface, Sequelize) {
await queryInterface.createTable('Users', {
id: {
allowNull: false,
autoIncrement: true,
primaryKey: true,
type: Sequelize.INTEGER
},
username: {
type: Sequelize.STRING
},
password: {
type: Sequelize.STRING
},
createdAt: {
allowNull: false,
type: Sequelize.DATE
},
updatedAt: {
allowNull: false,
type: Sequelize.DATE
}
});
},
async down(queryInterface, Sequelize) {
await queryInterface.dropTable('Users');
}
};
它的作用就是用来创建、修改表的,在up部分。我们通过createTabel创建了一个叫做Users的表
注意,我们执行生成模型的命令中,模型名字是单数:User表的名字一定是复数形式,也就是Users这是sequelize的命名规则,不能搞错。
可以看到Users表里面的字段有,比方说id、username、password、createAt、updataAt,其中字段createdAt和updatedAt是sequelize帮我们自动添加的
我们在username和password中添加约束,让用户名和密码不能为空
username: {
allowNull: false,
type: Sequelize.STRING.
},
password: {
allowNull: false,
type: Sequelize.STRING
},
down部分,里面写的是dropTable,也就是删除当前的表。当我们创建表,建完后发现有错误,也可以通过相关命令来删除当前表。
- 运行迁移
sequelize db:migrate
当我们运行上面的迁移命令时,sequelize 就会根据上面的迁移文件自动在数据库中创建对应的Users表,
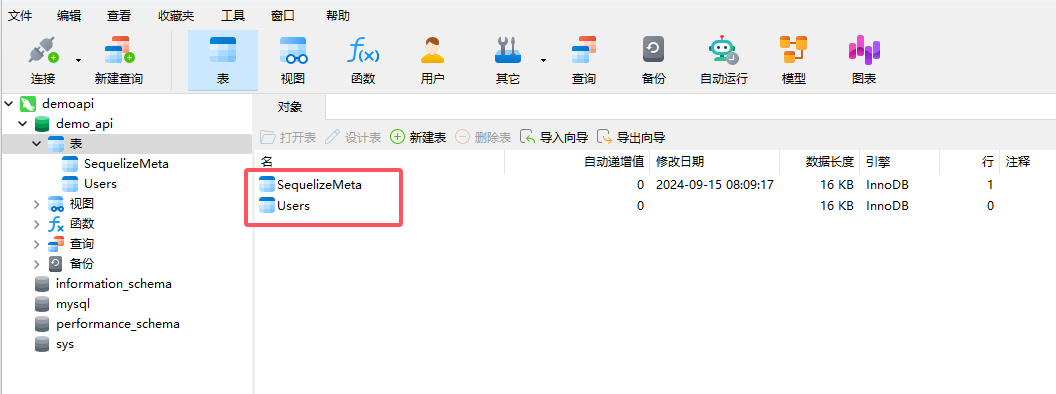
SequelizeMeta是我们运行迁移命令时,自动生成的。这张表里记录已经运行迁移的记录,当你再次运行sequelize db:migrate时,已经运行过的迁移文件,就不会重复再次执行了
如果当我们运行迁移后发现Users表的字段设置不正确可以通过命令sequelize db:migrate:undo命令撤销最近的一次迁移
- 种子文件
有了数据表之后,下一步要填充一些在开发中用来测试的数据,我希望数据库里有 100 条用户数据,这时候就要用到种子文件,运行命令:
sequelize seed:generate --name user
我们的项目目录下seeders文件夹中就会生成一个xxx-user.js的种子文件
'use strict';
/** @type {import('sequelize-cli').Migration} */
module.exports = {
async up (queryInterface, Sequelize) {
/**
* Add seed commands here.
*
* Example:
* await queryInterface.bulkInsert('People', [{
* name: 'John Doe',
* isBetaMember: false
* }], {});
*/
},
async down (queryInterface, Sequelize) {
/**
* Add commands to revert seed here.
*
* Example:
* await queryInterface.bulkDelete('People', null, {});
*/
}
};
其中up部分就是生成表数据使用的函数,down部分就是删除表数据的函数,我们稍加修改
'use strict';
/** @type {import('sequelize-cli').Migration} */
module.exports = {
async up(queryInterface, Sequelize) {
const users = [];
const counts = 100;
for (let i = 1; i <= counts; i++) {
const user = {
username: `admin${i}`,
password: `123456`,
createdAt: new Date(),
updatedAt: new Date(),
};
users.push(user);
}
await queryInterface.bulkInsert('Users', users, {});
},
async down(queryInterface, Sequelize) {
await queryInterface.bulkDelete('Users', null, {});
}
};
修改完成后我们运行命令,其中xxx-user为种子文件名
sequelize db:seed --seed xxx-user
运行完成后,我们在数据库客户端中刷新一下,我们的100条用户数据已经被通过上面的种子文件插入到数据库中了:
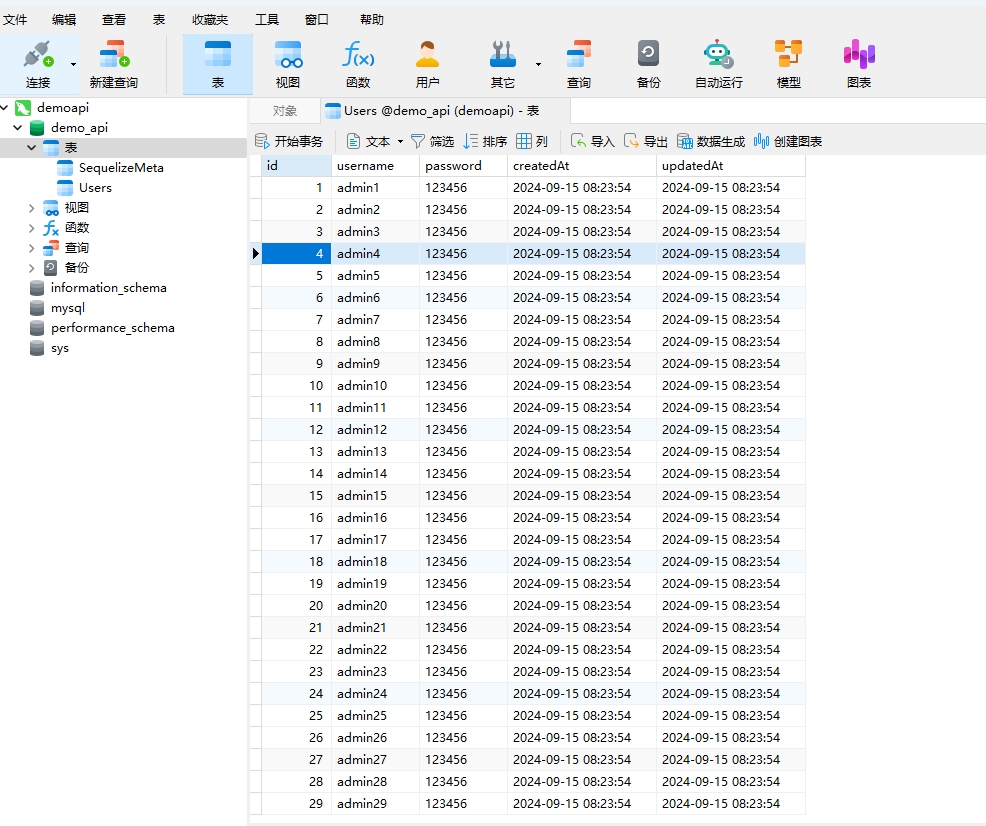
8.到此项目搭建大功告成了
至此我们可以使用搭建好的项目,开发接口了
在路由routers/users.js文件中修改代码
var express = require('express');
var router = express.Router();
//导入上面sequelize生成的模型
const { User } = require("../models")
/* GET users listing. */
router.get('/', async function (req, res, next) {
// 使用模型 查找所有User,返回刚才用种子文件生成的100条用户数据
const users = await User.findAll()
res.json({
success: true,
data: {
userlist: users //接口返回100条用户数据
}
});
});
module.exports = router;
在项目目录中npm start启动项目,在浏览器中输入users路由对应的路径请求接口试试看,成功返回数据库中的100条user数据
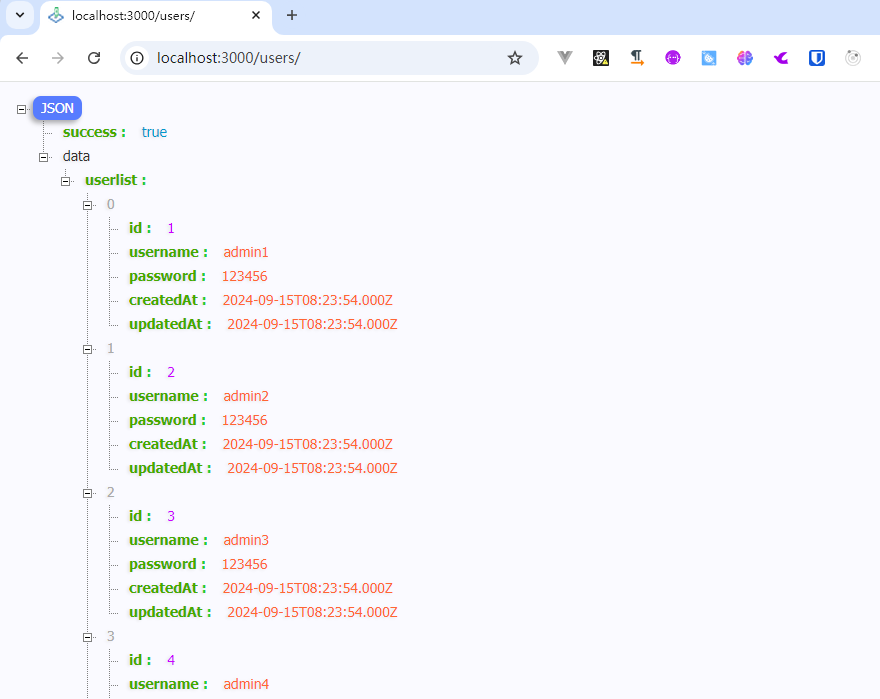
9. 总结
以上面搭建的项目为基础,当我们要实际开发设计好数据表后,通过命令
# 修改生成模型 的指令为设计好的数据表字段 运行下面命令生成 模型 和 迁移文件
sequelize model:generate --name Order --attributes orderNum:string,product:string
# 运行迁移命令 自动创建模型对应的数据表
sequelize db:migrate
# 恢复上一次迁移:回滚
sequelize db:migrate:undo
# 撤销所有迁移
sequelize db:migrate:undo:all
# 生成种子文件
sequelize seed:generate --name order
# 修改种子文件up函数、down函数
#使用下面命令 运行种子文件 会将测试数据自动插入数据库
sequelize db:seed --seed xxx-order
# 撤销最近一次运行种子
sequelize db:seed:undo
# 撤销所有运行的种子
sequelize db:seed:undo:all
更多迁移操作中文文档
标签:Node,文件,nodejs,安装,数据库,RESETful,js,api,sequelize From: https://www.cnblogs.com/yaxi-blog/p/18415398