阳光高考项目
项目要求
爬取各大高校基本信息和招生简章(招生简章要求存储为pdf格式并且入库)
数据库表设计
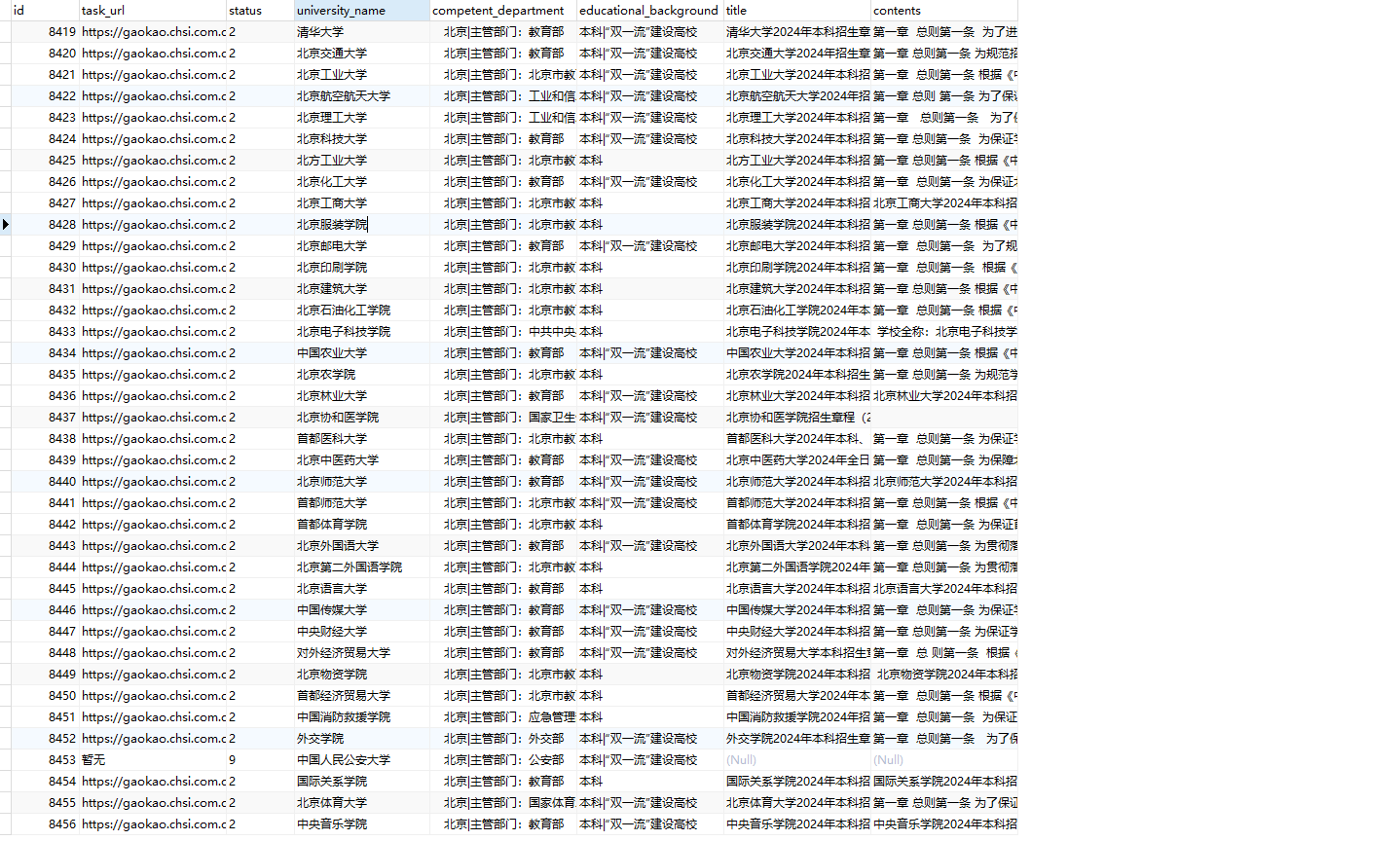
- id
- task_url
- status:0(未抓取),1(抓取中),2(抓取完毕),3(错误),4(更新中),5(数据更新成功),6(数据未更新,保持原样),9(暂无),8(暂无)
- 3:错误,是因为此div下根本没p标签,所以根本等不到导致超时错误await page.waitForXPath('//div[@class="content zszc-content UEditor"]//p'),可以单独处理,总共4个
- 特殊的能等待到的,有的是多个p标签、有的是多个div标签、有的是表格,都已经做了单独的处理
- university_name
- competent_department
- educational_background
- title
- contents
阳光简章1
由于两次页面跳转,会将之前的page对象销毁,无法进行item的循环爬取,所以应先根据item循环抓取task_url和必要数据入库
后续再读取task_url进行爬取
源码:
import asyncio # 协程
from pyppeteer import launch
from pyppeteer_stealth import stealth # 消除指纹
from lxml import etree # xpath解析数据
import pymysql
width, height = 1366, 768 # 设置浏览器宽度和高度
conn = pymysql.connect(user='root', password='123456', db='sunshine')
cursor = conn.cursor()
async def main():
# 设置启动时是否开启浏览器可视,消除控制条信息
browser = await launch(headless=False, args=['--disable-infobars']) # 设置浏览器和添加属性
# 开启一个页面对象
page = await browser.newPage()
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
# 消除指纹
await stealth(page) # <-- Here
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
# 访问第一页
await page.goto(
'https://gaokao.chsi.com.cn/zsgs/zhangcheng/listVerifedZszc--method-index,ssdm-,yxls-,xlcc-,zgsx-,yxjbz-,start-0.dhtml')
await page.waitForXPath('//li[@class="ivu-page-item"]/@title') # 根据xpaath来等待某个节点出现
# 获取最大页
max_page_1 = await page.xpath('//li[@class="ivu-page-item"]/@title')
max_page = await (await max_page_1[-1].getProperty("textContent")).jsonValue()
# print(max_page)
for pp in range(int(max_page)):
print(pp*100)
await page.goto('https://gaokao.chsi.com.cn/zsgs/zhangcheng/listVerifedZszc--method-index,ssdm-,yxls-,xlcc-,zgsx-,yxjbz-,start-{}.dhtml'.format(pp*100))
# 爬取单页数据
await asyncio.sleep(2)
# 等待元素出现 根据CSS选择器的语法等待某个节点出现,跟pyquery语法差不多
await page.waitForSelector('div.info-box')
# 拉滚动条
# arg1: 文档向右滚动的像素数 arg2: 文档向下滚动的像素数
await page.evaluate('window.scrollBy(200, document.body.scrollHeight)')
# 等待最后一个商品出现
await asyncio.sleep(2)
# 解析单页数据
div_list = await page.xpath('//div[@class="info-box"]')
for i in div_list:
university_name_1 = await i.xpath('div[1]/a')
competent_department_1 = await i.xpath('a[1]')
educational_background_1 = await i.xpath('a[2]')
# 大学名称
university_name = await (await university_name_1[0].getProperty("textContent")).jsonValue()
# 接管部门
competent_department = await (await competent_department_1[0].getProperty("textContent")).jsonValue()
# 教育背景
educational_background = await (await educational_background_1[0].getProperty("textContent")).jsonValue()
educational_background = educational_background.replace('\n', '')
educational_background = educational_background.replace(' ', '')
# 简章url
# zszc-link text-decoration-none no-info
# zszc-link text-decoration-none
task_url_1 = await i.xpath('a[@class=\"zszc-link text-decoration-none\" and not(contains(@class, \"no-info\"))]/@href')
if len(task_url_1) > 0:
task_url = await (await task_url_1[0].getProperty("textContent")).jsonValue()
task_url = "https://gaokao.chsi.com.cn{}".format(task_url)
sql = 'insert into tasks(task_url,status,university_name,competent_department,educational_background)' \
' values(\"{}\", \"0\", \"{}\", \"{}\", \"{}\")'.format(task_url.strip(), university_name.strip(),
competent_department.strip(), educational_background.strip())
else:
task_url = "暂无"
sql = 'insert into tasks(task_url,status,university_name,competent_department,educational_background)' \
' values(\"{}\", \"9\", \"{}\", \"{}\", \"{}\")'.format(task_url.strip(), university_name.strip(),
competent_department.strip(), educational_background.strip())
# strip去空格: xpath获取到的数据左右可能有空格, 占用数据库空间
# print(1, university_name.strip(), 2, conpetent_department.strip(), 3, educational_background.strip(), 4,
# task_url.strip())
# print(sql)
cursor.execute(sql)
conn.commit()
await asyncio.sleep(100)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
阳光简章2
源码:
import asyncio # 协程
import multiprocessing
import time
from pyppeteer import launch
from pyppeteer_stealth import stealth # 消除指纹
from lxml import etree # xpath解析数据
import pymysql
from pymysql.converters import escape_string
import os
width, height = 1366, 768 # 设置浏览器宽度和高度
r = redis.Redis(host="127.0.0.1", port=6379, db=1)
MAX_RETRIES = 3
# 章节页面保存成pdf或者word 并存入数据库
# 多进程或者多协程提高抓取速度
# 断点续抓
# 增量爬虫
async def main():
conn = pymysql.connect(user='root', password='123456', db='sunshine')
cursor = conn.cursor()
# 设置启动时是否开启浏览器可视,消除控制条信息
global retries
browser = await launch(headless=True, args=['--disable-infobars']) # 设置浏览器和添加属性
# 开启一个页面对象
page = await browser.newPage()
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
# 消除指纹
await stealth(page) # <-- Here
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
# 访问某个页面
allline = get_count()
for i in range(allline):
retries = 0 # 重置重试次数
result = get_task()
url = result[1]
id = result[0]
while retries < MAX_RETRIES:
await page.goto(url)
# 智能等待: 不能百分百确定一定有这个链接, 所以错误处理
try:
await page.waitForXPath('//a[@class="zszc-zc-title"]/@href')
except:
sql = 'update tasks set status=\"8\" where id = {}'.format(id)
cursor.execute(sql)
conn.commit()
continue
# info_url
info_url_1 = await page.xpath('//a[@class="zszc-zc-title"]/@href')
info_url = await (await info_url_1[0].getProperty("textContent")).jsonValue()
info_url = "https://gaokao.chsi.com.cn{}".format(info_url)
# 访问info_url
await page.goto(info_url)
# 智能等待
try:
await page.waitForXPath('//div[@class="content zszc-content UEditor"]//p')
except Exception:
retries += 1
await asyncio.sleep(1)
continue
# title
title = await page.xpath('//h2[@class="zszc-content-title"]')
title = await (await title[0].getProperty("textContent")).jsonValue()
# 截图成为pdf
# 目前只支持无头模式的有头的不行
if not os.path.isdir('阳光/pdf'):
os.makedirs('阳光/pdf')
await page.pdf({'path': '阳光/pdf/{}.pdf'.format(title), 'format': 'a4'})
# contents
contents_p = await page.xpath('//div[@class="content zszc-content UEditor"]//p')
contents_list = '\n'.join([await (await x.getProperty("textContent")).jsonValue() for x in contents_p])
# 处理表格等特殊情况
if not contents_list.strip():
# content_div = await page.xpath('//table')[0].xpath('string(.)')
# content_list = await (await content_div[0].getProperty("textContent")).jsonValue()
# print(55555,content_list)
try:
content = etree.HTML(await page.content()).xpath('//table')[0]
contents = escape_string(etree.tostring(content, encoding='utf-8').decode())
except IndexError:
pass
try:
contents_div = await page.xpath('//div[@class="content zszc-content UEditor"]//div')
contents_list = '\n'.join(
[await (await x.getProperty("textContent")).jsonValue() for x in contents_div])
contents = escape_string(contents_list)
except Exception:
pass
# print(555555, content_list)
else:
# escape_string: 对文本中单双引号进行转义, 防止单双引号冲突
contents = escape_string(contents_list)
# print(title, contents_list)
print(title)
# 入库
sql = 'update tasks set title=\"{}\", contents=\"{}\", status=\"2\" where id={}'.format(title, contents, id)
cursor.execute(sql)
conn.commit()
break
if retries == 3:
sql = 'update tasks set status=\"3\" where id={}'.format(id)
cursor.execute(sql)
conn.commit()
# 关闭浏览器
await browser.close()
# 获取任务数目
def get_count():
conn = pymysql.connect(user='root', password='123456', db='sunshine')
cursor = conn.cursor()
sql = 'select count(*) from tasks where status=\"0\"'
cursor.execute(sql)
result = cursor.fetchone()
print(result)
return result[0]
# 获取一个任务
def get_task():
conn = pymysql.connect(user='root', password='123456', db='sunshine')
cursor = conn.cursor()
sql = 'select * from tasks where status=\"0\"'
cursor.execute(sql)
result = cursor.fetchone()
sql1 = 'update tasks set status=\"1\" where id={}'.format(result[0])
cursor.execute(sql1)
conn.commit()
return result
# 仅基于异步运行
def run_async():
asyncio.get_event_loop().run_until_complete(main())
# 多进程运行
def run_mutiprocess():
pool = multiprocessing.Pool(8)
for _ in range(8):
# multiprocessing.Pool 是为同步函数设计的, 如果必须使用 multiprocessing,确保每个进程内有自己的事件循环。
pool.apply_async(run_async)
print('Waiting for all subprocesses done...')
pool.close()
pool.join()
print('All subprocesses done.')
async def run_gather():
tasks = [main() for _ in range(8)]
await asyncio.gather(*tasks)
# 多协程运行
def run_coroutine():
asyncio.get_event_loop().run_until_complete(run_gather())
if __name__ == '__main__':
start_time = time.time()
# 仅基于异步
# run_async()
# 多进程
run_mutiprocess()
# 多协程
# run_coroutine()
end_time = time.time()
print("总共耗时: {}".format(end_time - start_time))
多进程
33 min
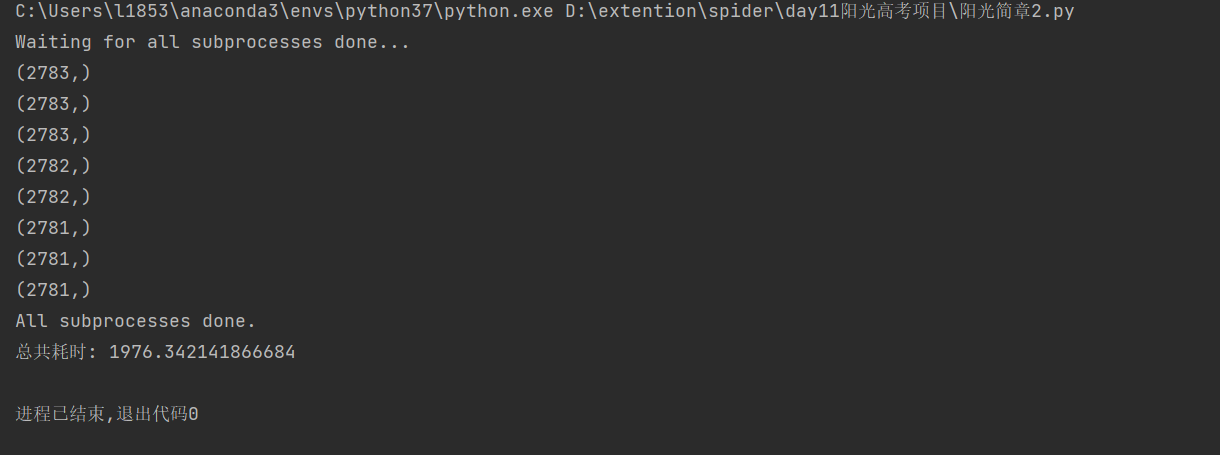
多协程
项目亮点
上面项目的面试点
status字段有1的必要性
多进程共享资源的问题:
如果没有1,则多进程爬取数据时存在多个进程抢占同一个资源的情况,而程序在爬取此task_url时将status字段设置为1则避免了这种情况的发生
异常处理
一般出现在智能等待(超时错误导致的一系列错误),设立重试机制,达到最大重试次数,将status字段设置为0,后续会重新进行抓取,防止异常发生导致程序终止
完善上面项目
断点续抓
人为中断程序,下次再此运行程序抓取数据能够保证继续抓取
# 完善项目: 断点续抓
async def crawler_resumpt():
conn = pymysql.connect(user='root', password='123456', db='sunshine')
cursor = conn.cursor()
sql = 'select * from tasks where status=\"1\" or status=\"0\" order by id'
cursor.execute(sql)
results = cursor.fetchall()
# 设置启动时是否开启浏览器可视,消除控制条信息
global retries
browser = await launch(headless=True, args=['--disable-infobars']) # 设置浏览器和添加属性
# 开启一个页面对象
page = await browser.newPage()
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
# 消除指纹
await stealth(page) # <-- Here
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
for result in results:
# 访问某个页面
retries = 0 # 重置重试次数
url = result[1]
id = result[0]
while retries < MAX_RETRIES:
await page.goto(url)
# 智能等待: 不能百分百确定一定有这个链接, 所以错误处理
try:
await page.waitForXPath('//a[@class="zszc-zc-title"]/@href')
except:
sql = 'update tasks set status=\"8\" where id = {}'.format(id)
cursor.execute(sql)
conn.commit()
continue
# info_url
info_url_1 = await page.xpath('//a[@class="zszc-zc-title"]/@href')
info_url = await (await info_url_1[0].getProperty("textContent")).jsonValue()
info_url = "https://gaokao.chsi.com.cn{}".format(info_url)
# 访问info_url
await page.goto(info_url)
# 智能等待
try:
await page.waitForXPath('//div[@class="content zszc-content UEditor"]//p')
except Exception:
retries += 1
await asyncio.sleep(1)
continue
# title
title = await page.xpath('//h2[@class="zszc-content-title"]')
title = await (await title[0].getProperty("textContent")).jsonValue()
# 截图成为pdf
# 目前只支持无头模式的有头的不行
if not os.path.isdir('阳光/pdf'):
os.makedirs('阳光/pdf')
await page.pdf({'path': '阳光/pdf/{}.pdf'.format(title), 'format': 'a4'})
# contents
contents_p = await page.xpath('//div[@class="content zszc-content UEditor"]//p')
contents_list = '\n'.join([await (await x.getProperty("textContent")).jsonValue() for x in contents_p])
# 处理表格特殊情况
if not contents_list.strip():
# content_div = await page.xpath('//table')[0].xpath('string(.)')
# content_list = await (await content_div[0].getProperty("textContent")).jsonValue()
# print(55555,content_list)
content = etree.HTML(await page.content()).xpath('//table')[0]
contents = escape_string(etree.tostring(content, encoding='utf-8').decode())
# print(555555, content_list)
else:
# escape_string: 对文本中单双引号进行转义, 防止单双引号冲突
contents = escape_string(contents_list)
# print(title, contents_list)
print(title)
# 入库
sql = 'update tasks set title=\"{}\", contents=\"{}\", status=\"2\" where id={}'.format(title, contents,
id)
cursor.execute(sql)
conn.commit()
break
if retries == 3:
sql = 'update tasks set status=\"0\" where id={}'.format(id)
cursor.execute(sql)
conn.commit()
# 关闭浏览器
await browser.close()
增量爬虫,指纹去重
指纹:将抓取数据拼接成字符串,并通过md5或sha1加密形成的密钥字符串即为指纹
将指纹和id存储在redis数据库的无序集合中
后续抓取数据时,构造密钥字符串,根据是否含有此密钥字符串进行去重,若有,则放弃数据更新,若无,则根据id进行数据更新
初始爬虫源码:
# 入库
sql = 'update tasks set title=\"{}\", contents=\"{}\", status=\"2\" where id={}'.format(title, contents, id)
cursor.execute(sql)
conn.commit()
# 指纹入库
data = title + contents
r.sadd("sunshine:key", encryption(data))
增量爬虫源码:
import asyncio # 协程
import multiprocessing
import time
from pyppeteer import launch
from pyppeteer_stealth import stealth # 消除指纹
from lxml import etree # xpath解析数据
import pymysql
from pymysql.converters import escape_string
import os
import redis
import hashlib
width, height = 1366, 768 # 设置浏览器宽度和高度
r = redis.Redis(host="127.0.0.1", port=6379, db=1)
MAX_RETRIES = 3
async def main():
conn = pymysql.connect(user='root', password='123456', db='sunshine2')
cursor = conn.cursor()
# 设置启动时是否开启浏览器可视,消除控制条信息
global retries, contents
browser = await launch(headless=True, args=['--disable-infobars']) # 设置浏览器和添加属性
# 开启一个页面对象
page = await browser.newPage()
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
# 消除指纹
await stealth(page) # <-- Here
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
# 访问某个页面
allline = get_count()
for i in range(allline):
retries = 0 # 重置重试次数
result = get_finished_task()
url = result[1]
id = result[0]
while retries < MAX_RETRIES:
await page.goto(url)
# 智能等待: 不能百分百确定一定有这个链接, 所以错误处理
try:
await page.waitForXPath('//a[@class="zszc-zc-title"]/@href')
except:
sql = 'update tasks set status=\"8\" where id = {}'.format(id)
cursor.execute(sql)
conn.commit()
continue
# info_url
info_url_1 = await page.xpath('//a[@class="zszc-zc-title"]/@href')
info_url = await (await info_url_1[0].getProperty("textContent")).jsonValue()
info_url = "https://gaokao.chsi.com.cn{}".format(info_url)
# 访问info_url
await page.goto(info_url)
# 智能等待
try:
await page.waitForXPath('//div[@class="content zszc-content UEditor"]//p')
except Exception:
retries += 1
await asyncio.sleep(1)
continue
# title
title = await page.xpath('//h2[@class="zszc-content-title"]')
title = await (await title[0].getProperty("textContent")).jsonValue()
# 截图成为pdf
# 目前只支持无头模式的有头的不行
if not os.path.isdir('阳光/pdf'):
os.makedirs('阳光/pdf')
await page.pdf({'path': '阳光/pdf/{}.pdf'.format(title), 'format': 'a4'})
# contents
contents_p = await page.xpath('//div[@class="content zszc-content UEditor"]//p')
contents_list = '\n'.join([await (await x.getProperty("textContent")).jsonValue() for x in contents_p])
# 处理表格等特殊情况
if not contents_list.strip():
# content_div = await page.xpath('//table')[0].xpath('string(.)')
# content_list = await (await content_div[0].getProperty("textContent")).jsonValue()
# print(55555,content_list)
try:
content = etree.HTML(await page.content()).xpath('//table')[0]
contents = escape_string(etree.tostring(content, encoding='utf-8').decode())
except IndexError:
pass
try:
contents_div = await page.xpath('//div[@class="content zszc-content UEditor"]//div')
contents_list = '\n'.join(
[await (await x.getProperty("textContent")).jsonValue() for x in contents_div])
contents = escape_string(contents_list)
except Exception:
pass
# print(555555, content_list)
else:
# escape_string: 对文本中单双引号进行转义, 防止单双引号冲突
contents = escape_string(contents_list)
# print(title, contents_list)
print(title)
# 入库
data = title + contents
if not is_crawlered(data):
print("数据更新...")
sql = 'update tasks set title=\"{}\", contents=\"{}\", status=\"5\" where id={}'.format(title, contents,
id)
cursor.execute(sql)
conn.commit()
else:
print("数据已爬取过...")
sql = 'update tasks set status=\"6\" where id={}'.format(id)
cursor.execute(sql)
conn.commit()
break
if retries == 3:
sql = 'update tasks set status=\"3\" where id={}'.format(id)
cursor.execute(sql)
conn.commit()
# 关闭浏览器
await browser.close()
# 获取任务数目
def get_count():
conn = pymysql.connect(user='root', password='123456', db='sunshine2')
cursor = conn.cursor()
sql = 'select count(*) from tasks where status=\"2\"'
cursor.execute(sql)
result = cursor.fetchone()
print(result)
return result[0]
# md5加密
def encryption(data):
md5 = hashlib.md5()
md5.update(data.encode("utf-8"))
return md5.hexdigest()
# 获取一个已完成的任务
def get_finished_task():
conn = pymysql.connect(user='root', password='123456', db='sunshine2')
cursor = conn.cursor()
sql = 'select * from tasks where status=\"2\"'
cursor.execute(sql)
result = cursor.fetchone()
sql1 = 'update tasks set status=\"4\" where id={}'.format(result[0])
cursor.execute(sql1)
conn.commit()
return result
# 去重
def is_crawlered(data):
res = r.sadd("sunshine:key", encryption(data))
return res == 0
# 仅基于异步运行
def run_async():
asyncio.get_event_loop().run_until_complete(main())
# 多进程运行
def run_mutiprocess():
pool = multiprocessing.Pool(8)
for _ in range(8):
# multiprocessing.Pool 是为同步函数设计的, 如果必须使用 multiprocessing,确保每个进程内有自己的事件循环。
pool.apply_async(run_async)
print('Waiting for all subprocesses done...')
pool.close()
pool.join()
print('All subprocesses done.')
async def run_gather():
tasks = [main() for _ in range(4)]
await asyncio.gather(*tasks)
# 多协程运行
def run_coroutine():
asyncio.get_event_loop().run_until_complete(run_gather())
if __name__ == '__main__':
start_time = time.time()
# 仅基于异步
# run_async()
# 多进程
run_mutiprocess()
# 多协程
# run_coroutine()
end_time = time.time()
print("总共耗时: {}".format(end_time - start_time))
更多精致内容:

