一、介绍
新闻管理与推荐系统。本系统使用Python作为主要开发语言开发的一个新闻管理与推荐的网站平台。
网站前端界面采用HTML、CSS、BootStrap等技术搭建界面。后端采用Django框架处理用户的逻辑请求,并将用户的相关行为数据保存在数据库中。通过Ajax技术实现前后端的数据通信。
创新点:项目中使用基于用户的协同过滤推荐算法通过用户对文章的评分作为推荐数据基础,通过计算相似度实现对当前登录用户的个性化推荐。
主要功能有:
- 系统分为管理员和用户两个角色
- 用户可以登录、注册、查看文章、收藏文章、点赞文章、发布评论、对文章评分、查看个人收藏、编辑个人信息、个性化推荐等功能
- 管理员在后台系统中可以对用户和文章信息进行管理
二、系统效果图片展示
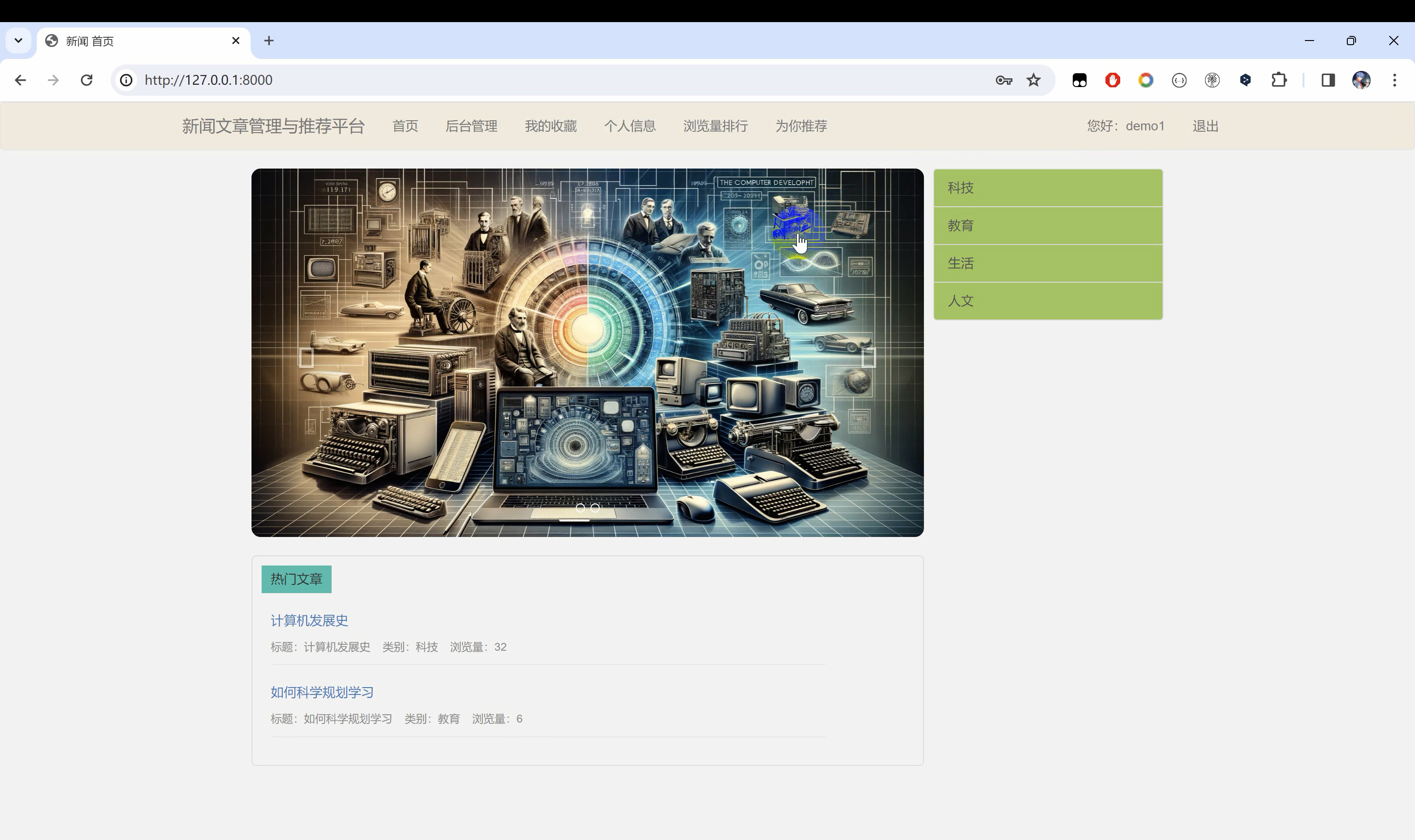
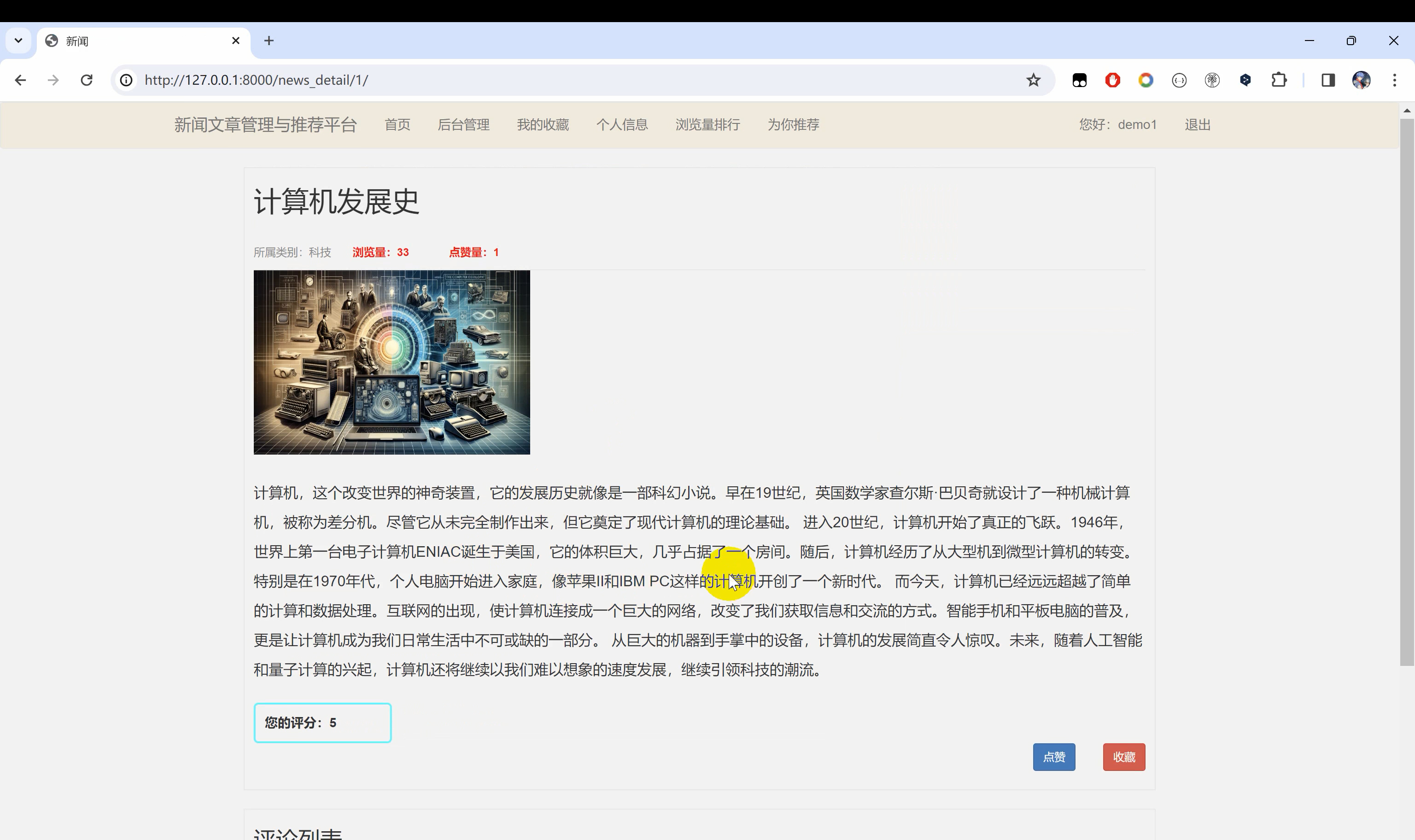
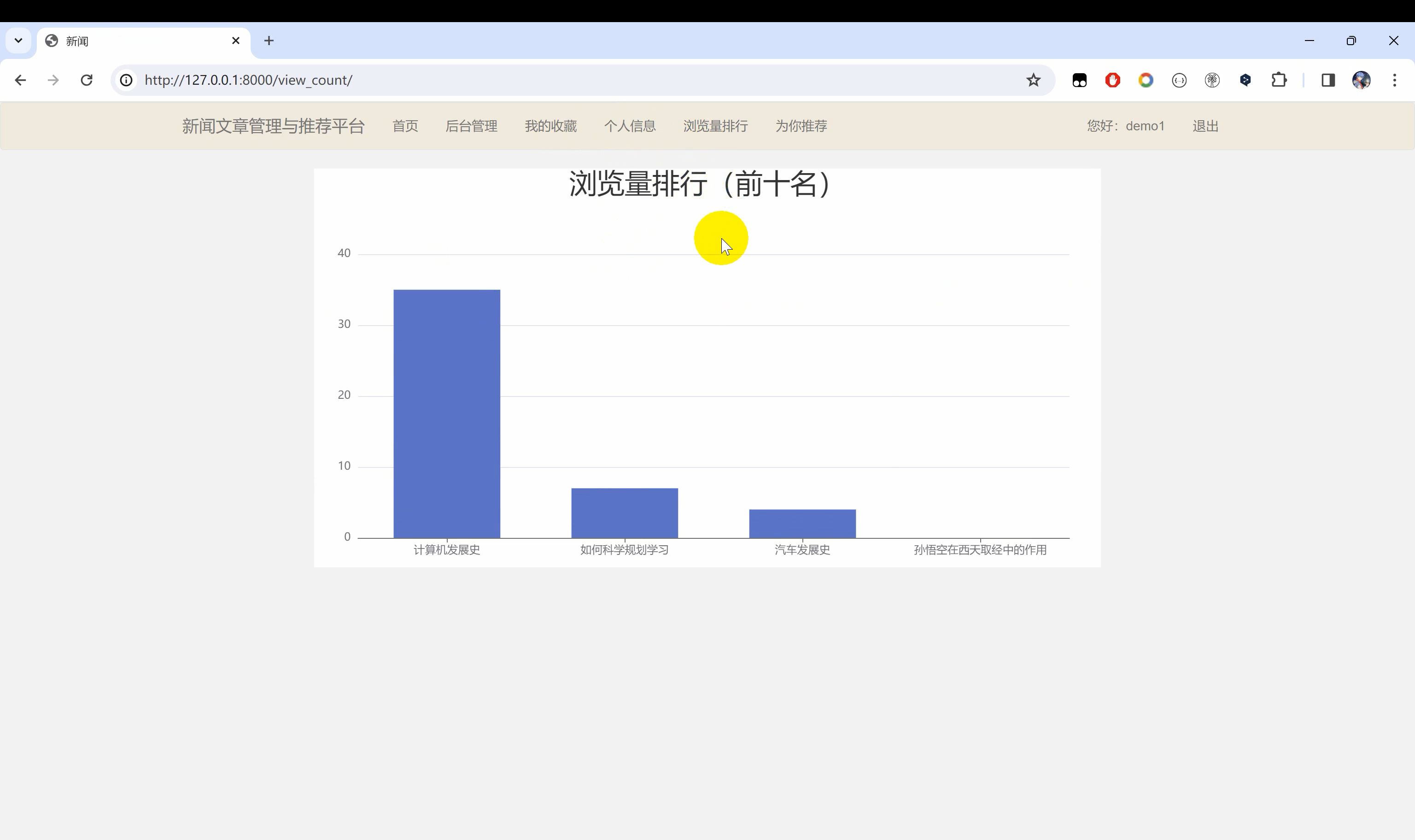
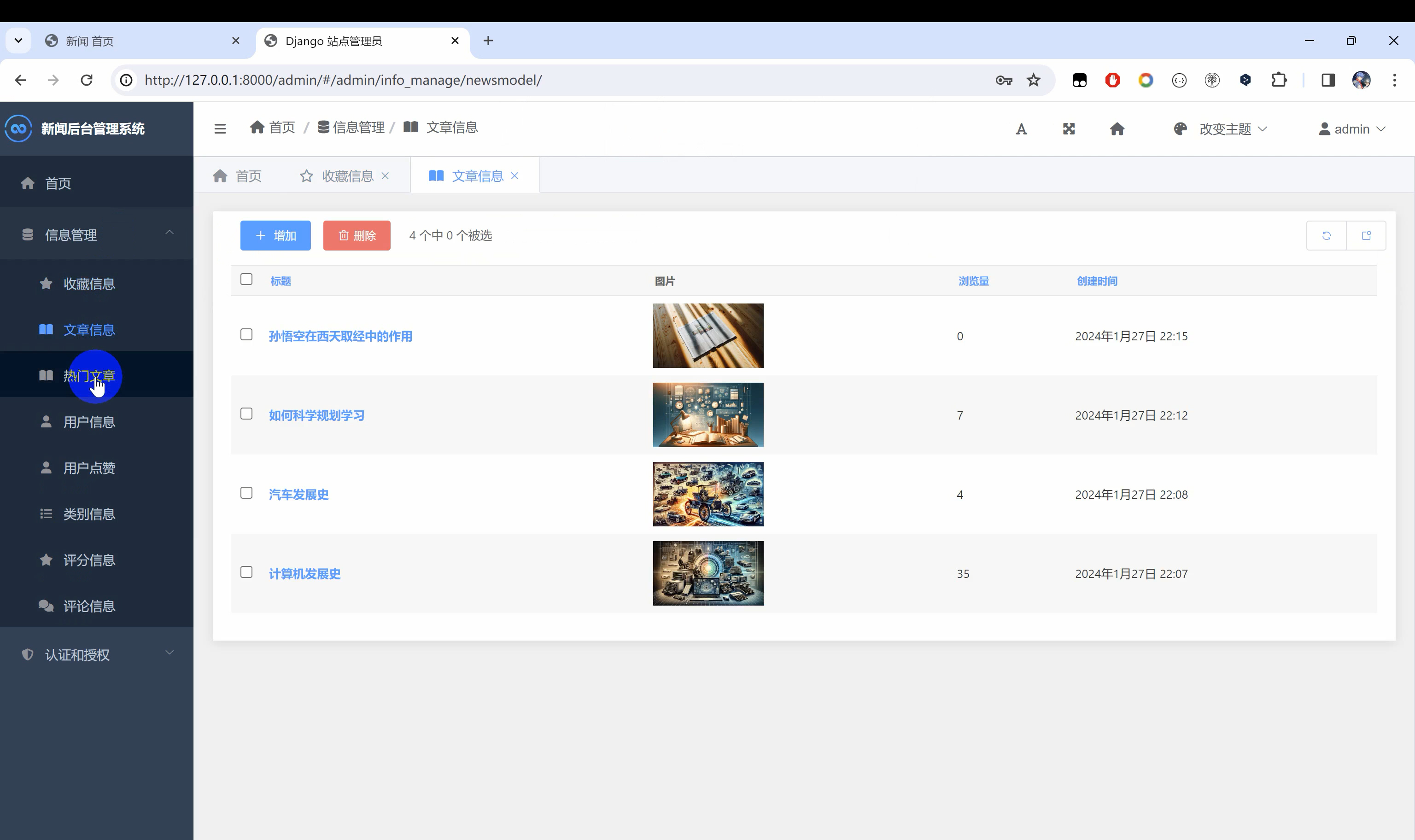
三、演示视频 and 代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/xl0zlgglmrw7wqdf
四、协同过滤推荐算法介绍
协同过滤是一种推荐算法,主要通过分析用户与其他用户之间的相似性以及用户对项目的历史行为来进行推荐。它可以分为两种主要类型:用户基协同过滤和物品基协同过滤。
用户基协同过滤:这种方法依据用户之间的相似性来进行推荐。算法首先计算用户之间的相似度,常用的相似度计算方法包括皮尔逊相关系数、余弦相似性等。基于一个用户的相似用户(邻居)的喜好,推断此用户可能喜欢的项目。
物品基协同过滤:与用户基协同过滤相反,这种方法依据物品之间的相似性来推荐物品。算法计算物品之间的相似度,然后根据用户之前对某物品的评价,推荐与之相似的其他物品。
下面,我们用Python实现一个简单的用户基协同过滤推荐系统。假设我们有一组用户对电影的评分数据,我们将使用皮尔逊相关系数来计算用户之间的相似性,并推荐电影。
import numpy as np
from scipy.stats import pearsonr
# 评分矩阵,行代表用户,列代表电影
ratings = np.array([
[5, 4, 1, 0, 0],
[4, 5, 2, 0, 0],
[0, 0, 0, 4, 5],
[0, 0, 0, 5, 4],
[0, 0, 5, 4, 0]
])
def recommend_movies(user_index, num_recommendations=2):
# 计算目标用户与其他用户的皮尔逊相关系数
similarities = []
for i in range(ratings.shape[0]):
if i != user_index:
sim = pearsonr(ratings[user_index], ratings[i])[0]
similarities.append((i, sim))
# 根据相似度排序
similarities.sort(key=lambda x: x[1], reverse=True)
# 从最相似的用户中获取推荐
top_users = similarities[:num_recommendations]
recommended_movies = []
for user, _ in top_users:
# 找出此用户评分高但目标用户未评分的电影
for movie_index in np.where(ratings[user] > 3)[0]:
if ratings[user_index][movie_index] == 0:
recommended_movies.append(movie_index)
return np.unique(recommended_movies)
# 对用户0推荐电影
recommended_movies = recommend_movies(0)
print("推荐的电影索引:", recommended_movies)
这段代码首先定义了一个评分矩阵,然后实现了一个推荐函数,它根据用户的相似性来推荐电影。我们使用了皮尔逊相关系数来衡量相似性,并推荐了相似用户高评分但目标用户未观看的电影。这只是一个非常基础的实现,实际应用中还需要考虑更多因素,如处理数据稀疏性、扩展到大规模数据集等。
标签:index,协同,Python,推荐,用户,Django,movies,过滤 From: https://www.cnblogs.com/shiqianlong/p/18262254