第一章-Java基础篇
1、你是怎样理解OOP面向对象 难度系数:⭐
面向对象是利于语言对现实事物进行抽象。面向对象具有以下特征:
- 继承:继承是从已有类得到继承信息创建新类的过程
- 封装:封装是把数据和操作数据的方法绑定起来,对数据的访问只能通过已定义的接口
- 多态性:多态性是指允许不同子类型的对象对同一消息作出不同的响应
2、重载与重写区别 难度系数:⭐
- 重载发生在本类,重写发生在父类与子类之间
- 重载的方法名必须相同,重写的方法名相同且返回值类型必须相同
- 重载的参数列表不同,重写的参数列表必须相同
- 重写的访问权限不能比父类中被重写的方法的访问权限更低
- 构造方法不能被重写
3、接口与抽象类的区别 难度系数:⭐
- 抽象类要被子类继承,接口要被类实现
- 接口可多继承接口,但类只能单继承
- 抽象类可以有构造器、接口不能有构造器
- 抽象类:除了不能实例化抽象类之外,它和普通Java类没有任何区别
- 抽象类:抽象方法可以有public、protected和default这些修饰符、接口:只能是public
- 抽象类:可以有成员变量;接口:只能声明常量
篇幅限制下面就只能给大家展示小册部分内容了。这份面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取
4、深拷贝与浅拷贝的理解 难度系数:⭐
深拷贝和浅拷贝就是指对象的拷贝,一个对象中存在两种类型的属性,一种是基本数据类型,一种是实例对象的引用。
- 浅拷贝是指,只会拷贝基本数据类型的值,以及实例对象的引用地址,并不会复制一份引用地址所指向的对象,也就是浅拷贝出来的对象,内部的类属性指向的是同一个对象
- 深拷贝是指,既会拷贝基本数据类型的值,也会针对实例对象的引用地址所指向的对象进行复制,深拷贝出来的对象,内部的类执行指向的不是同一个对象
5、sleep和wait区别 难度系数:⭐
- sleep方法
属于Thread类中的方法
释放cpu给其它线程 不释放锁资源
sleep(1000) 等待超过1s被唤醒
- wait方法
属于Object类中的方法
释放cpu给其它线程,同时释放锁资源
wait(1000) 等待超过1s被唤醒
wait() 一直等待需要通过notify或者notifyAll进行唤醒
wait 方法必须配合 synchronized 一起使用,不然在运行时就会抛出IllegalMonitorStateException异常
-
#### 锁释放时机代码演示 -
public static void main(String[] args) { -
Object o = new Object(); -
Thread thread = new Thread(() -> { -
synchronized (o) { -
System.out.println("新线程获取锁时间:" + LocalDateTime.now() + " 新线程名称:" + Thread.currentThread().getName()); -
try { -
//wait 释放cpu同时释放锁 -
o.wait(2000); -
//sleep 释放cpu不释放锁 -
//Thread.sleep(2000); -
System.out.println("新线程获取释放锁锁时间:" + LocalDateTime.now() + " 新线程名称:" + Thread.currentThread().getName()); -
} catch (InterruptedException e) { -
throw new RuntimeException(e); -
} -
} -
}); -
thread.start(); -
try { -
Thread.sleep(100); -
} catch (InterruptedException e) { -
throw new RuntimeException(e); -
} -
System.out.println("主线程获取锁时间:" + LocalDateTime.now() + " 主线程名称:" + Thread.currentThread().getName()); -
synchronized (o){ -
System.out.println("主线程获取释放锁锁时间:" + LocalDateTime.now() + " 主线程名称:" + Thread.currentThread().getName()); -
} -
}
![]()
Java
6、什么是自动拆装箱 int和Integer有什么区别 难度系数:⭐
基本数据类型,如int,float,double,boolean,char,byte,不具备对象的特征,不能调用方法。
- 装箱:将基本类型转换成包装类对象
- 拆箱:将包装类对象转换成基本类型的值
java为什么要引入自动装箱和拆箱的功能?主要是用于java集合中,List<Inteter> list=new ArrayList<Integer>();
list集合如果要放整数的话,只能放对象,不能放基本类型,因此需要将整数自动装箱成对象。
实现原理:javac编译器的语法糖,底层是通过Integer.valueOf()和Integer.intValue()方法实现。
区别:
- Integer是int的包装类,int则是java的一种基本数据类型
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- Integer的默认值是null,int的默认值是0
7、==和equals区别 难度系数:⭐
- ==
如果比较的是基本数据类型,那么比较的是变量的值
如果比较的是引用数据类型,那么比较的是地址值(两个对象是否指向同一块内存)
- equals
如果没重写equals方法比较的是两个对象的地址值
如果重写了equals方法后我们往往比较的是对象中的属性的内容
equals方法是从Object类中继承的,默认的实现就是使用==
8、String能被继承吗 为什么用final修饰 难度系数:⭐
- 不能被继承,因为String类有final修饰符,而final修饰的类是不能被继承的。
- String 类是最常用的类之一,为了效率,禁止被继承和重写。
- 为了安全。String 类中有native关键字修饰的调用系统级别的本地方法,调用了操作系统的 API,如果方法可以重写,可能被植入恶意代码,破坏程序。Java 的安全性也体现在这里。
9、String buffer和String builder区别 难度系数:⭐
- StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,
- 只是StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
- 在单线程程序下,StringBuilder效率更快,因为它不需要加锁,不具备多线程安全而StringBuffer则每次都需要判断锁,效率相对更低
10、final、finally、finalize 难度系数:⭐
- final:修饰符(关键字)有三种用法:修饰类、变量和方法。修饰类时,意味着它不能再派生出新的子类,即不能被继承,因此它和abstract是反义词。修饰变量时,该变量使用中不被改变,必须在声明时给定初值,在引用中只能读取不可修改,即为常量。修饰方法时,也同样只能使用,不能在子类中被重写。
- finally:通常放在try…catch的后面构造最终执行代码块,这就意味着程序无论正常执行还是发生异常,这里的代码只要JVM不关闭都能执行,可以将释放外部资源的代码写在finally块中。
- finalize:Object类中定义的方法,Java中允许使用finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在销毁对象时调用的,通过重写finalize() 方法可以整理系统资源或者执行其他清理工作。
11、Object中有哪些方法 难度系数:⭐
- protected Object clone()--->创建并返回此对象的一个副本。
- boolean equals(Object obj)--->指示某个其他对象是否与此对象“相等
- protected void finalize()--->当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。
- Class<? extendsObject> getClass()--->返回一个对象的运行时类。
- int hashCode()--->返回该对象的哈希码值。
- void notify()--->唤醒在此对象监视器上等待的单个线程。
- void notifyAll()--->唤醒在此对象监视器上等待的所有线程。
- String toString()--->返回该对象的字符串表示。
- void wait()--->导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法。
void wait(long timeout)--->导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll()方法,或者超过指定的时间量。
void wait(long timeout, int nanos)--->导致当前的线程等待,直到其他线程调用此对象的 notify()
12、说一下集合体系 难度系数:⭐
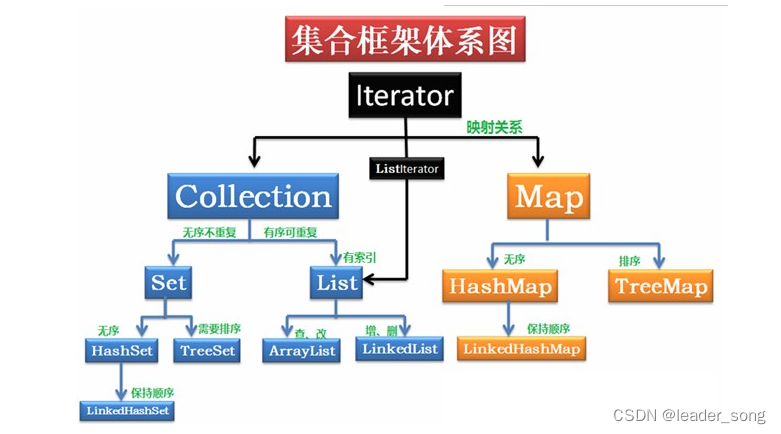
13、ArrarList和LinkedList区别 难度系数:⭐
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
- 对于随机访问get和set,ArrayList效率优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
14、HashMap底层是 数组+链表+红黑树,为什么要用这几类结构 难度系数:⭐⭐
- 数组 Node<K,V>[] table ,哈希表,根据对象的key的hash值进行在数组里面是哪个节点
- 链表的作用是解决hash冲突,将hash值取模之后的对象存在一个链表放在hash值对应的槽位
- 红黑树 JDK8使用红黑树来替代超过8个节点的链表,主要是查询性能的提升,从原来的O(n)到O(logn),
- 通过hash碰撞,让HashMap不断产生碰撞,那么相同的key的位置的链表就会不断增长,当对这个Hashmap的相应位置进行查询的时候,就会循环遍历这个超级大的链表,性能就会下降,所以改用红黑树
15、HashMap和HashTable区别 难度系数:⭐
- 线程安全性不同
HashMap是线程不安全的,HashTable是线程安全的,其中的方法是Synchronized,在多线程并发的情况下,可以直接使用HashTable,但是使用HashMap时必须自己增加同步处理。
- 是否提供contains方法
HashMap只有containsValue和containsKey方法;HashTable有contains、containsKey和containsValue三个方法,其中contains和containsValue方法功能相同。
- key和value是否允许null值
Hashtable中,key和value都不允许出现null值。HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
- 数组初始化和扩容机制
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
16、线程的创建方式 难度系数:⭐
- 继承Thread类创建线程
- 实现Runnable接口创建线程
- 使用Callable和Future创建线程 有返回值
- 使用线程池创建线程
-
#### 代码演示 -
import java.util.concurrent.*; -
public class threadTest{ -
public static void main(String[] args) throws ExecutionException, InterruptedException { -
//继承thread -
ThreadClass thread = new ThreadClass(); -
thread.start(); -
Thread.sleep(100); -
System.out.println("#####################"); -
//实现runnable -
RunnableClass runnable = new RunnableClass(); -
new Thread(runnable).start(); -
Thread.sleep(100); -
System.out.println("#####################"); -
//实现callable -
FutureTask futureTask = new FutureTask(new CallableClass()); -
futureTask.run(); -
System.out.println("callable返回值:" + futureTask.get()); -
Thread.sleep(100); -
System.out.println("#####################"); -
//线程池 -
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 2, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10)); -
threadPoolExecutor.execute(thread); -
threadPoolExecutor.shutdown(); -
Thread.sleep(100); -
System.out.println("#####################"); -
//使用并发包Executors -
ExecutorService executorService = Executors.newFixedThreadPool(5); -
executorService.execute(thread); -
executorService.shutdown(); -
} -
} -
class ThreadClass extends Thread{ -
@Override -
public void run() { -
System.out.println("我是继承thread形式:" + Thread.currentThread().getName()); -
} -
} -
class RunnableClass implements Runnable{ -
@Override -
public void run(){ -
System.out.println("我是实现runnable接口:" + Thread.currentThread().getName()); -
} -
} -
class CallableClass implements Callable<String> { -
@Override -
public String call(){ -
System.out.println("我是实现callable接口:"); -
return "我是返回值,可以通过get方法获取"; -
} -
}
![]()
Java
篇幅限制下面就只能给大家展示小册部分内容了。这份面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取
17、线程的状态转换有什么(生命周期) 难度系数:⭐
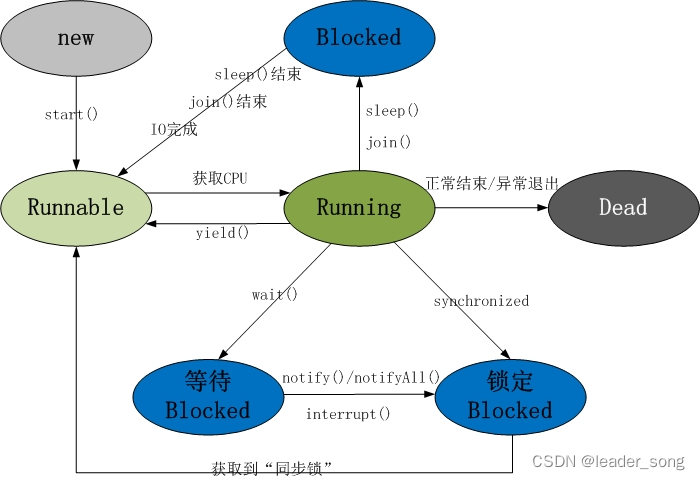
- 新建状态(New) :线程对象被创建后,就进入了新建状态。例如,Thread thread = new Thread()。
- 就绪状态(Runnable): 也被称为“可执行状态”。线程对象被创建后,其它线程调用了该对象的start()方法,从而来启动该线程。例如,thread.start()。处于就绪状态的线程,随时可能被CPU调度执行。
- 运行状态(Running):线程获取CPU权限进行执行。需要注意的是,线程只能从就绪状态进入到运行状态。
- 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
- 等待阻塞 -- 通过调用线程的wait()方法,让线程等待某工作的完成。
- 同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态。
- 其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
- 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
18、Java中有几种类型的流 难度系数:⭐
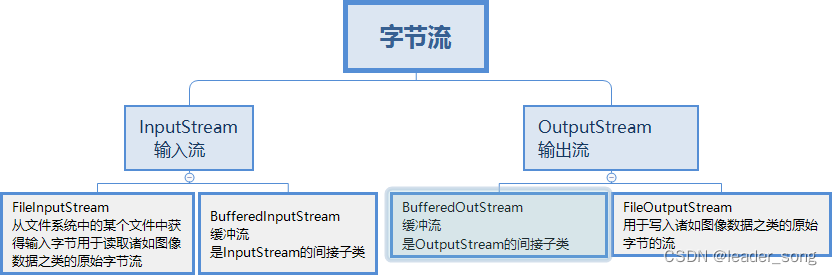

19、请写出你最常见的5个RuntimeException 难度系数:⭐
- java.lang.NullPointerException
空指针异常;出现原因:调用了未经初始化的对象或者是不存在的对象。
- java.lang.ClassNotFoundException
指定的类找不到;出现原因:类的名称和路径加载错误;通常都是程序试图通过字符串来加载某个类时可能引发异常。
- java.lang.NumberFormatException
字符串转换为数字异常;出现原因:字符型数据中包含非数字型字符。
- java.lang.IndexOutOfBoundsException
数组角标越界异常,常见于操作数组对象时发生。
- java.lang.IllegalArgumentException
方法传递参数错误。
- java.lang.ClassCastException
数据类型转换异常。
20、谈谈你对反射的理解 难度系数:⭐
- 反射机制
所谓的反射机制就是java语言在运行时拥有一项自观的能力。通过这种能力可以彻底了解自身的情况为下一步的动作做准备。
Java的反射机制的实现要借助于4个类:class,Constructor,Field,Method;其中class代表的时类对 象,Constructor-类的构造器对象,Field-类的属性对象,Method-类的方法对象。通过这四个对象我们可以粗略的看到一个类的各个组成部分。
- Java反射的作用
在Java运行时环境中,对于任意一个类,可以知道这个类有哪些属性和方法。对于任意一个对象,可以调用它的任意一个方法。这种动态获取类的信息以及动态调用对象的方法的功能来自于Java 语言的反射(Reflection)机制。
- Java 反射机制提供功能
在运行时判断任意一个对象所属的类。
在运行时构造任意一个类的对象。
在运行时判断任意一个类所具有的成员变量和方法。
在运行时调用任意一个对象的方法
21、什么是 java 序列化,如何实现 java 序列化 难度系数:⭐
- 序列化是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
- 序 列 化 的 实 现 : 将 需 要 被 序 列 化 的 类 实 现 Serializable 接 口 , 该 接 口 没 有 需 要 实 现 的 方 法 , implements Serializable 只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用 ObjectOutputStream 对象的 writeObject(Object obj)方法就可以将参数为 obj 的对象写出(即保存其状态),要恢复的话则用输入流。
22、Http 常见的状态码 难度系数:⭐
- 200 OK //客户端请求成功
- 301 Permanently Moved (永久移除),请求的 URL 已移走。Response 中应该包含一个 Location URL, 说明资源现在所处的位置
- 302 Temporarily Moved 临时重定向
- 400 Bad Request //客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized //请求未经授权,这个状态代码必须和 WWW-Authenticate 报头域一起使用
- 403 Forbidden //服务器收到请求,但是拒绝提供服务
- 404 Not Found //请求资源不存在,eg:输入了错误的 URL
- 500 Internal Server Error //服务器发生不可预期的错误
- 503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
23、GET 和POST 的区别 难度系数:⭐
- GET 请求的数据会附在URL 之后(就是把数据放置在 HTTP 协议头中),以?分割URL 和传输数据,参数之间以&相连,如:login.action?name=zhagnsan&password=123456。POST 把提交的数据则放置在是 HTTP 包的包体中。
- GET 方式提交的数据最多只能是 1024 字节,理论上POST 没有限制,可传较大量的数据。其实这样说是错误的,不准确的:“GET 方式提交的数据最多只能是 1024 字节",因为 GET 是通过 URL 提交数据,那么 GET 可提交的数据量就跟URL 的长度有直接关系了。而实际上,URL 不存在参数上限的问题,HTTP 协议规范没有对 URL 长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE 对URL 长度的限制是2083 字节(2K+35)。对于其他浏览器,如Netscape、FireFox 等,理论上没有长度限制,其限制取决于操作系统的支持。
- POST 的安全性要比GET 的安全性高。注意:这里所说的安全性和上面 GET 提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的 Security 的含义,比如:通过 GET 提交数据,用户名和密码将明文出现在 URL 上,因为(1)登录页面有可能被浏览器缓存,(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用 GET 提交数据还可能会造成 Cross-site request forgery 攻击。
- Get 是向服务器发索取数据的一种请求,而 Post 是向服务器提交数据的一种请求,在 FORM(表单)中,Method
- 默认为"GET",实质上,GET 和 POST 只是发送机制不同,并不是一个取一个发!
24、Cookie 和Session 的区别 难度系数:⭐
- Cookie 是 web 服务器发送给浏览器的一块信息,浏览器会在本地一个文件中给每个 web 服务器存储 cookie。以后浏览器再给特定的 web 服务器发送请求时,同时会发送所有为该服务器存储的 cookie
- Session 是存储在 web 服务器端的一块信息。session 对象存储特定用户会话所需的属性及配置信息。当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去
- Cookie 和session 的不同点
无论客户端做怎样的设置,session 都能够正常工作。当客户端禁用 cookie 时将无法使用 cookie
在存储的数据量方面:session 能够存储任意的java 对象,cookie 只能存储 String 类型的对象
第二章-Java高级篇
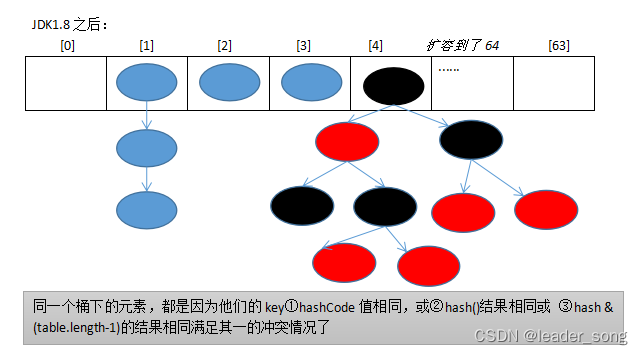
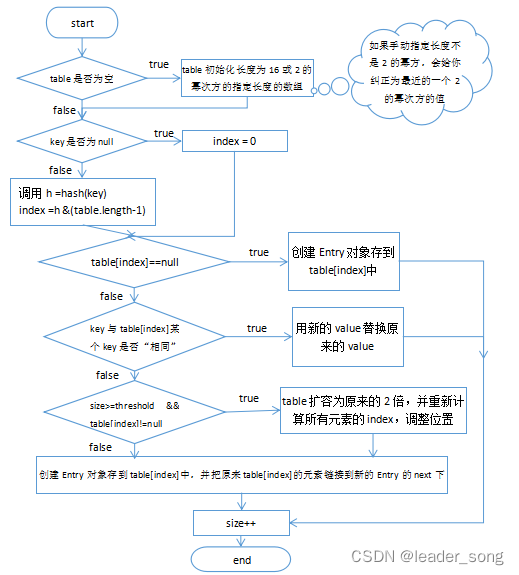
1、HashMap底层源码 难度系数:⭐⭐⭐
HashMap的底层结构在jdk1.7中由数组+链表实现,在jdk1.8中由数组+链表+红黑树实现,以数组+链表的结构为例。
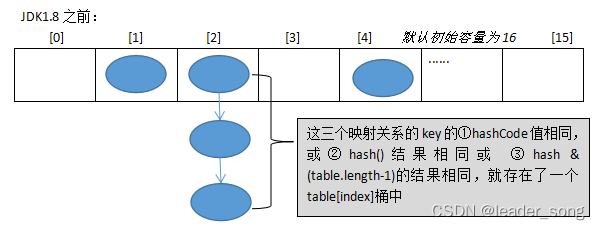
JDK1.8之前Put方法:
JDK1.8之后Put方法:
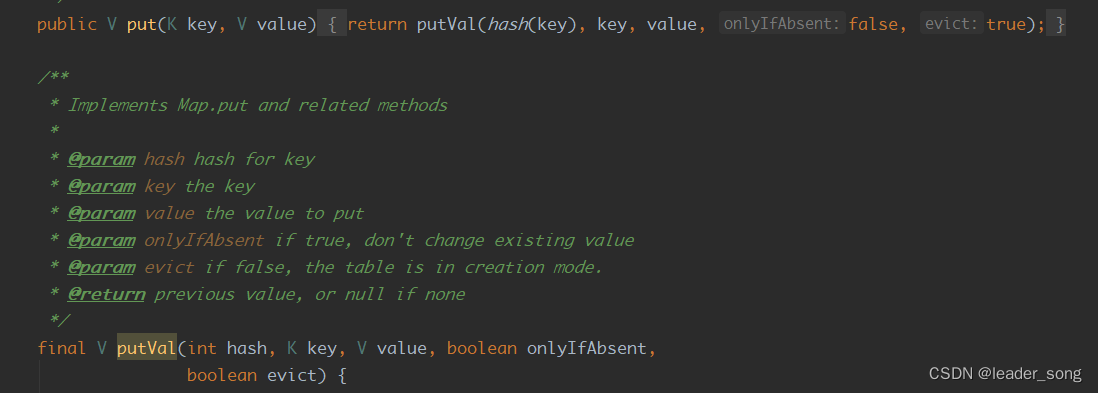
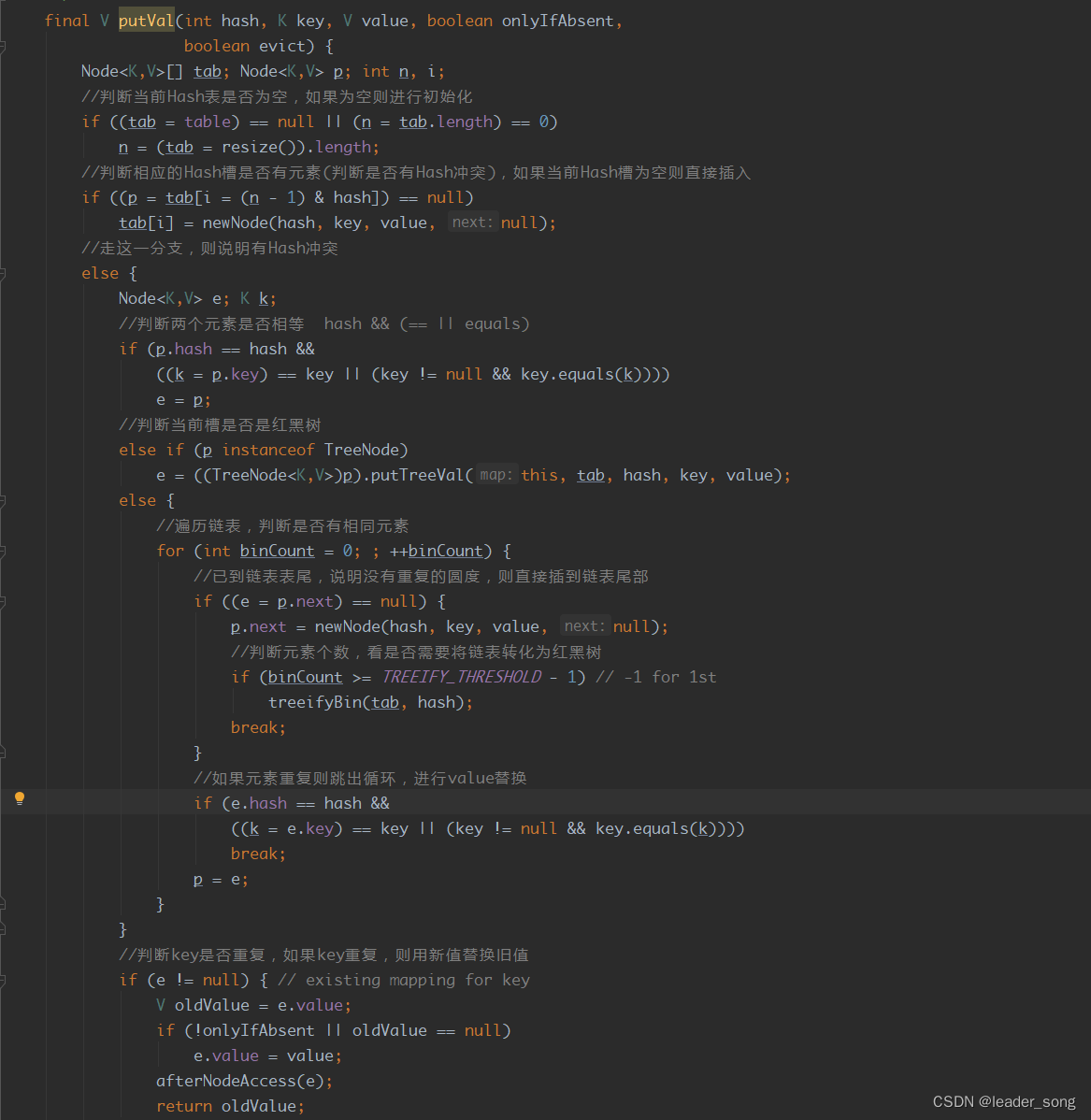
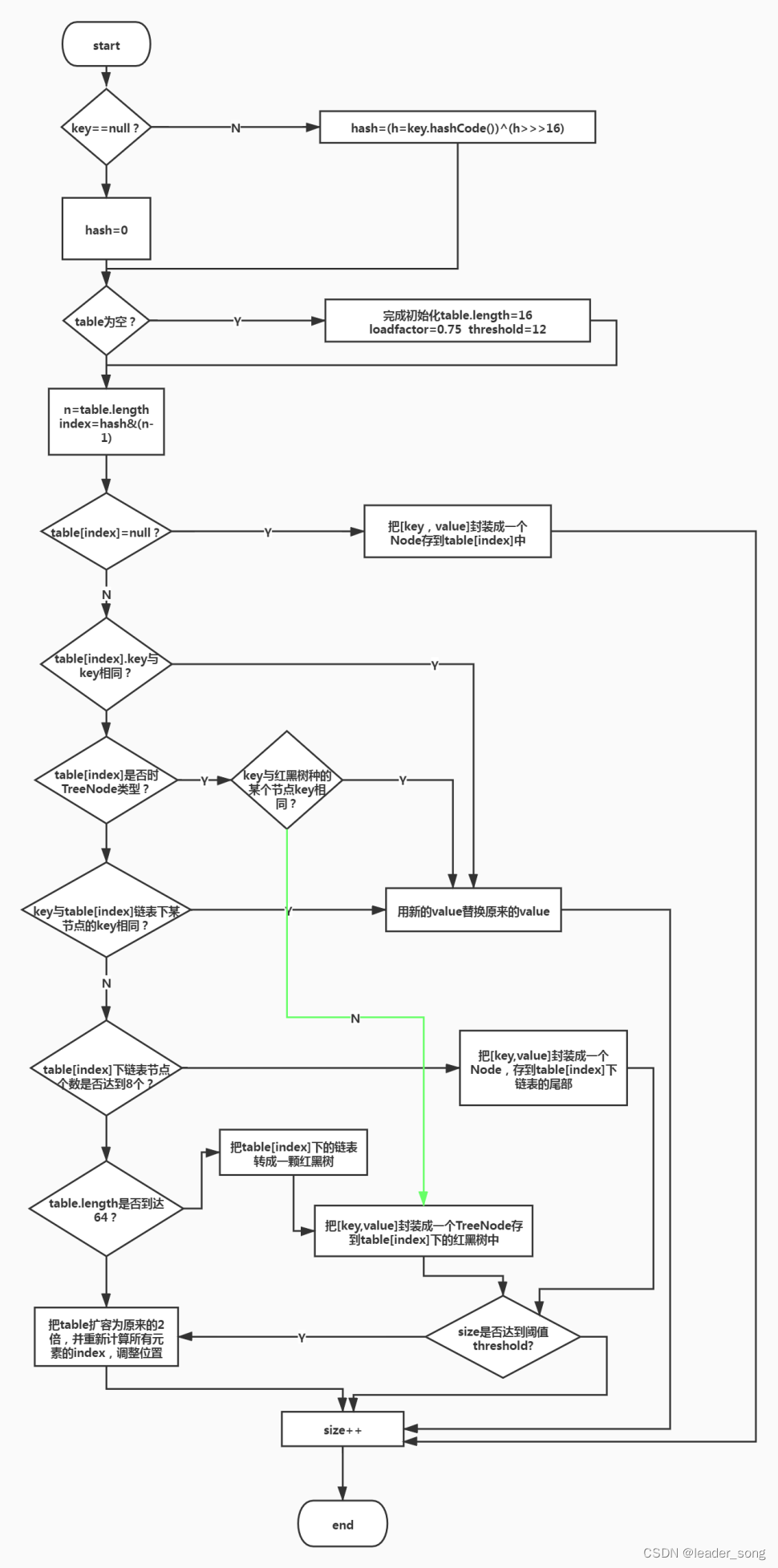
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
补充:将链表转换成红黑树前会判断,即使阈值大于8,但是数组长度小于64,此时并不会将链表变为红黑树。而是选择进行数组扩容。
这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡 。同时数组长度小于64时,搜索时间相对要快些。所以综上所述为了提高性能和减少搜索时间,底层在阈值大于8并且数组长度大于64时,链表才转换为红黑树。具体可以参考 treeifyBin方法。
当然虽然增了红黑树作为底层数据结构,结构变得复杂了,但是阈值大于8并且数组长度大于64时,链表转换为红黑树时,效率也变的更高效。
注意:可以结合百度hashmap源码解析进行更深入的了解。
史上最详细的 JDK 1.8 HashMap 源码解析_程序员囧辉的博客-CSDN博客
2、JVM内存分哪几个区,每个区的作用是什么 难度系数:⭐⭐
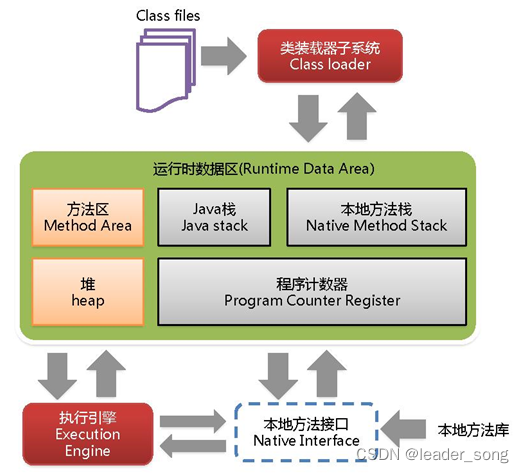
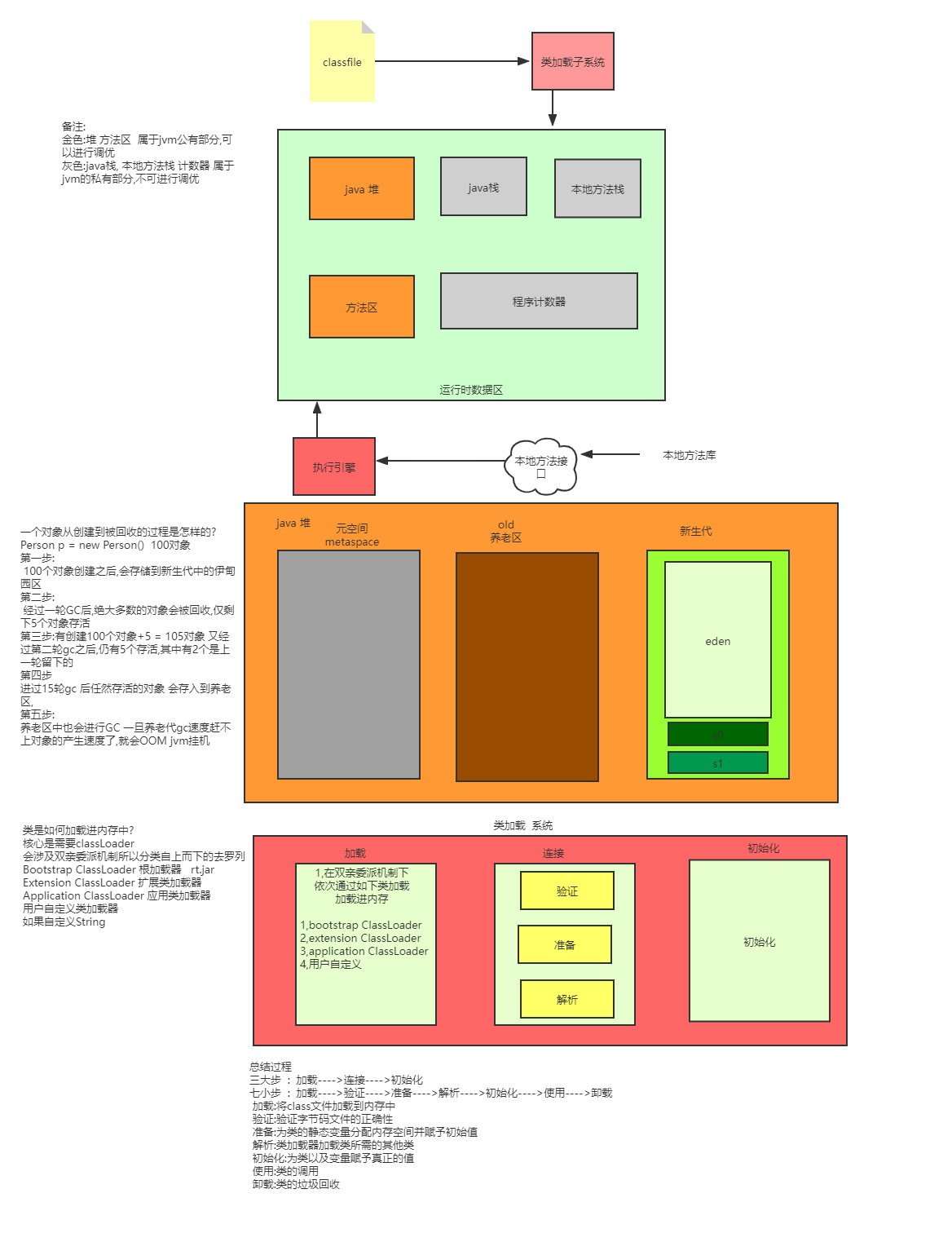
java虚拟机主要分为以下几个区
- 方法区
- 有时候也成为永久代,在该区内很少发生垃圾回收,但是并不代表不发生GC,在这里进行的GC主要是对方法区里的常量池和对类型的卸载
- 方法区主要用来存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据。
- 该区域是被线程共享的。
- 方法区里有一个运行时常量池,用于存放静态编译产生的字面量和符号引用。该常量池具有动态性,也就是说常量并不一定是编译时确定,运行时生成的常量也会存在这个常量池中。
- 虚拟机栈
- 虚拟机栈也就是我们平常所称的栈内存,它为java方法服务,每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口等信息。
- 虚拟机栈是线程私有的,它的生命周期与线程相同。
- 局部变量表里存储的是基本数据类型、returnAddress类型(指向一条字节码指令的地址)和对象引用,这个对象引用有可能是指向对象起始地址的一个指针,也有可能是代表对象的句柄或者与对象相关联的位置。局部变量所需的内存空间在编译器间确定
- 操作数栈的作用主要用来存储运算结果以及运算的操作数,它不同于局部变量表通过索引来访问,而是压栈和出栈的方式
- 每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接.动态链接就是将常量池中的符号引用在运行期转化为直接引用。