ZooKeeper源码分析
1. 服务器构成
群首(leader),追随者(follower),观察者(observer)本质上都是服务器。在实现服务器主要抽象概念是请求处理器。请求处理器是对处理流水线上不同阶段的抽象,每个服务器实现一个请求处理器的序列。
zookeeper服务端有两种模式:单机的独立模式和集群的仲裁模式,所谓仲裁是指一切事件只要满足多数派同意就执行,不需要等到集群中的每个节点反馈才执行。
独立服务器
1)PrepRequestProcessor 接受客户端的请求并执行这个请求,处理结果则是生成一个事务。不过只有改变 ZooKeeper 状态的操作才会产生事务,对于读操作并不会产生任何事务。
2)SyncRequestProcessor 负责将事务持久化到磁盘上。实际上就是将事务数据按照顺序追加到事务日志中,并形成快照数据。
3)FinalRequestProcessor检查如果 Request 对象包含事务数据,该处理器就会接受对 ZooKeeper 数据树的修改,否则,该处理器会从数据树中读取数据并返回客户端。
群首服务器
在切换到仲裁模式时,服务器的流水线则有一些变化。
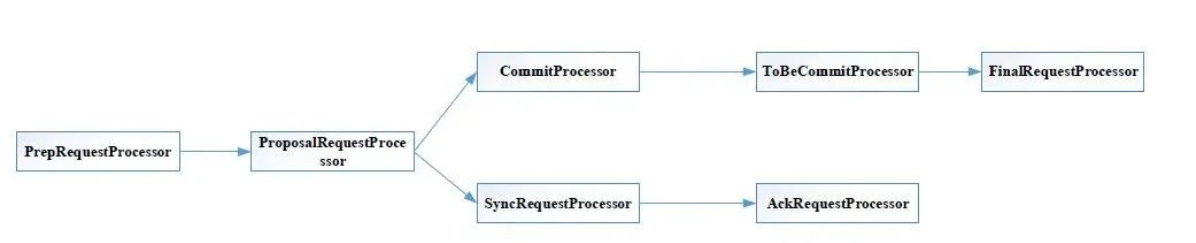
群首服务器流水线:
第一个处理器同样是 PrepRequestProcessor,而之后的处理器则为 ProposalRequestProcessor,该处理器会准备一个提议,并将该提议发送给跟随者,并且会把所有请求转发给 CommitRequestProcessor,对于写操作请求,还会把请求转发给 SyncRequestProcessor 处理器。
SyncRequestProcessor 和独立服务器的功能一样,是持久化事务到磁盘上,执行完后会触发 AckRequestProcessor 处理器,它仅仅生成确认消息并返回给自己。
CommitRequestProcessor 会将收到足够多的确认消息的提议进行提交。
追随者和观察者服务器
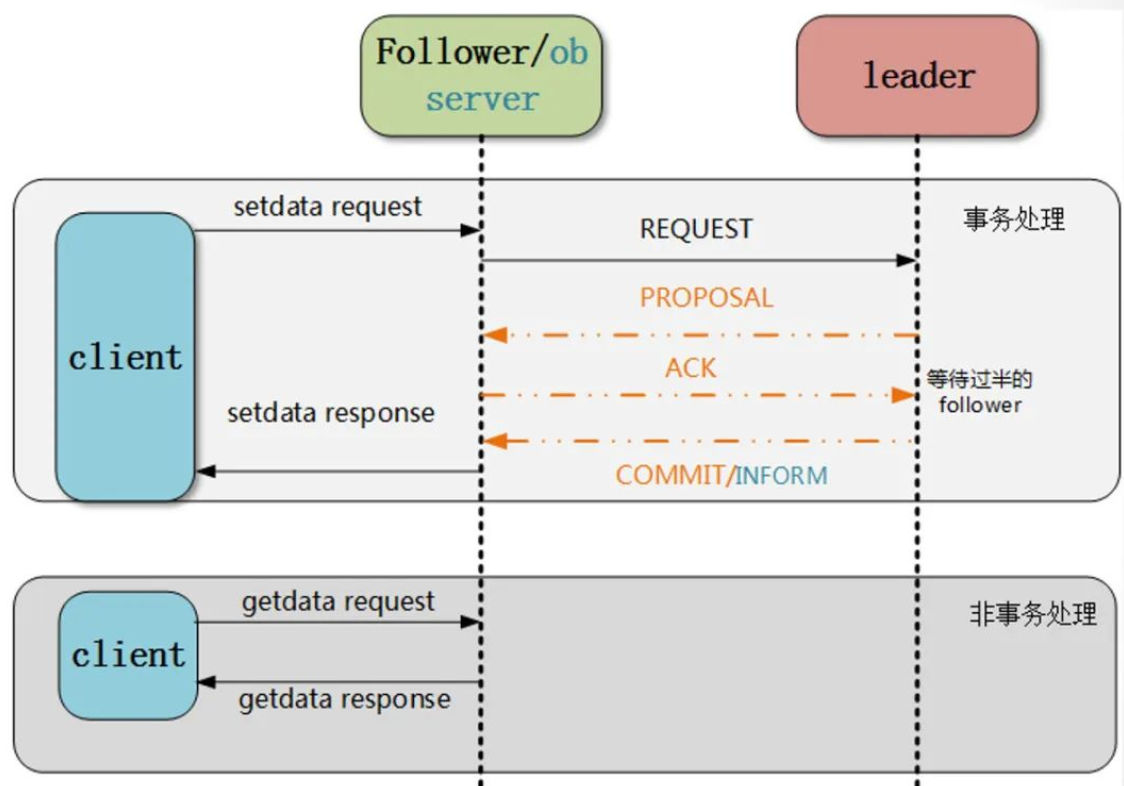
Follower 服务器是先从 FollowerRequestProcessors 处理器开始,该处理器接收并处理客户端请求。如果是 读请求 ,FollowerRequestProcessors 处理器之后转发请求给 CommitRequestProcessor,CommitRequestProcessor 会直接转发到 FinalRequestProcessor 处理器;如果是 写请求 ,FollowerRequestProcessors 会将写请求转发到 CommitRequestProcessor 和群首服务器,之后会转发到 FinalRequestProcessor,在转发到 FinalRequestProcessor 前会等待群首服务器提交事务。而群首接收到一个新的写请求时会生成一个提议,之后转发到追随者服务器(PROPOSAL消息),在收到提议后,追随服务器会发送这个提议到 SyncRequestProcessor,SendRequestProcessor 会向群首发送确认消息(ACK消息)。
当群首服务器接收到足够多确认消息来提交这个提议,群首就会发送提交事务消息给追随者(COMMIT消息),当收到提交的事务消息后,追随者才会通过 CommitRequestProcessor 处理器进行处理。为了保证执行的顺序,CommitRequestProcessor 处理器会在收到一个写请求处理器时暂停后续的请求处理。
对于观察者服务器不需要确认提议消息,因此观察者服务器并不需要发送确认消息给群首服务器,一般情况下,也不用持久化事务到磁盘。对于观察者服务器是否持久化事务到磁盘,以便加速观察者服务器的恢复速度,可以根据具体情况决定。
2. 本地存储
SyncRequestProcessor 处理器是用于处理提议写入的日志和快照。
日志和磁盘的使用
服务器通过事务日志来持久化事务。在接受一个提议时(收到PROPOSAL消息),一个服务器就会将提议的事务持久化到事务日志中,该事务日志保存在服务器本地磁盘中,事务将会按照顺序在末尾追加。写事务日志是写请求操作的关键,因此 ZooKeeper 必须有效处理写日志问题。在持久化事务到磁盘时,还有一个重要说明:现代操作系统通常会缓存脏页(Dirty Page),并将他们异步写入磁盘。然而,我们需要在继续之前,要确保事务已经被持久化。因此我们需要冲刷(Flush)事务到磁盘。
冲刷在这里就是指我们告诉操作系统把脏页写入到磁盘,并在操作完成后返回。同时为了提高 ZooKeeper 系统的运行速度,也会使用组提交和补白的。其中组提交是指一次磁盘写入时追加多个事务,可以减少磁盘寻址的开销。补白是指在文件中预分配磁盘存储块。
快照
快照是 ZooKeeper 数据树的拷贝副本,每一个服务器会经常以序列化整个数据树的方式来提取快照,并将这个提取的快照保存到文件。服务器在进行快照时不需要进行协作,也不需要暂停处理请求。因此服务器在进行快照时还会继续处理请求,所以当快照完成时,数据树可能又发生了变化,称为快照是模糊的,因为它们不能反映出在任意给定的时间点数据树的准确的状态。
3. 服务器与会话
会话(session)是 ZooKeeper 的一个重要的抽象。保证请求有序,临时 znode 节点,监控点都与会话密切相关。因此会话的跟踪机制对 ZooKeeper 来说也是非常重要的。
在独立模式下,单个服务器会跟踪所有的会话,而在仲裁模式下则由群首服务器来跟踪和维护。而追随者服务器仅仅是简单地把客户端连接的会话信息转发到群首服务器。
为了保证会话的存活,服务器需要接收会话的心跳信息。心跳的形式可以是一个新的请求或者显式的 ping 信息。两种情况下,服务器通过更新会话的过期时间来触发会话活跃,在仲裁模式下,群首服务器发送一个 PING 信息给它的追随者们,追随者们返回自从最新一次 PING 消息之后的一个 session 列表。群首服务器每半个时钟周期就会发送一个 ping 信息给追随者们。
4. 服务器与监视点
监视点是由读取操作所设置的一次性触发器,每个监视点有一个特定操作来触发,即通过监视点,客户端可以对指定的 znode 节点注册一个通知请求,在发生时就会收到一个单次的通知。监视点只会存在内存,而不会持久化到硬盘,当客户端与服务端的连接断开时,它的所有的监视点会从内存中清除。因为客户端也会维护一份监视点的数据,在重连之后,监视点数据会再次同步到服务端。
5. 客户端
在客户端库中有 2 个主要的类:ZooKeeper 和 ClientCnxn,写客户端应用程序时通过实例化 ZooKeeper 类来建立一个会话。一旦建立起一个会话,ZooKeeper 就会使用一个会话标识符来关联这个会话。这个会话标识符实际上是有服务端所生产的。
ClientCnxn 类管理连接到 server 的 socket 连接。该类维护一个可连接的 ZooKeeper 的服务列表,并当连接断掉的时候无缝地切换到其他服务器,当重连到一个其他的服务器时会使用同一个会话,客户端也会重置所有的监视点到刚连接的服务器上。
6. 群首选举
群首为集群中的服务器选择出来的一个服务器,并会一直被集群所认可。设置群首的目的是为了对客户端所发起的 ZooKeeper 状态更新请求进行排序,包括 create,setData 和 delete 操作。群首将每一个请求转换为一个事务,将这些事务发送给追随者,确保集群按照群首确定的顺序接受并处理这些事务。
每个服务器启动后进入 LOOKING 状态,开始选举一个新的群首或者查找已经存在的群首。如果群首已经存在,其他服务器就会通知这个新启动的服务器,告知哪个服务器是群首,于此同时,新服务器会与群首建立连接,以确保自己的状态与群首一致。如果群首中的所有的服务器均处于 LOOKING 状态,这些服务器之间就会进行通信来选举一个群首,通过信息交换对群首选举达成共识的选择。在本次选举过程中胜出的服务器将进入 LEADING 状态,而集群中其他服务器将会进入 FOLLOWING 状态。
具体看,一个服务器进入 LOOKING 状态,就会向集群中每个服务器发送一个通知信息,该消息中包括该服务器的投票(vote)信息,投票中包含服务器标识符(sid)和最近执行事务的 zxid 信息。
当一个服务器收到一个投票信息,该服务器将会根据以下规则修改自己的投票信息:
将接收的 voteId 和 voteZxid 作为一个标识符,并获取接收方当前的投票中的 zxid,用 myZxid 和 mySid 表示接收方服务器自己的值。
如果(voteZxid > myZxid)或者(voteZxid == myZxid 且 voteId >mySid),保留当前的投票信息。
否则,修改自己的投票信息,将 voteZxid 赋值给 myZxid,将 voteId 赋值给 mySid。
从上面的投票过程可以看出,只有最新的服务器将赢得选举,因为其拥有最近一次的 zxid。如果多个服务器拥有的最新的 zxid 值,其中的 sid 值最大的将会赢得选举。(因为有些事物可能没有同步到)
当一个服务器连接到仲裁数量的服务器发来的投票都一样时,就表示群首选举成功,如果被选举的群首为某个服务器自己,该服务器将会开始行使群首角色,否则就会成为一个追随者并尝试连接被选举的群首服务器。一旦连接成功,追随者和群首之间将会进行状态同步,在同步完成后,追随者才可以进行新的请求。
7. 序列化
对于网络传输和磁盘保存的序列化消息和事务,ZooKeeper 使用了 Hadoop 中的 Jute 来做序列化。
8. 服务端启动过程
分布式模式的启动主要经过 Leader 选举,集群数据同步,启动服务器。
分布式模式下的启动过程包括如下阶段:
- 解析 config 文件;
- 数据恢复;
- 监听 client 连接(但还不能处理请求);
- bind 选举端口监听 server 连接;
- 选举;
- 初始化 ZooKeeperServer;
- 数据同步;
- 同步结束,启动 client 请求处理能力。
zookeeper的启动入口:
ZooKeeperMain.java客户端主程序,ZooKeeperServer.java服务端单机主程序,QuorumPeerMain.java服务端分布式主程序
8.1 分布式服务启动
通过配置文件启动
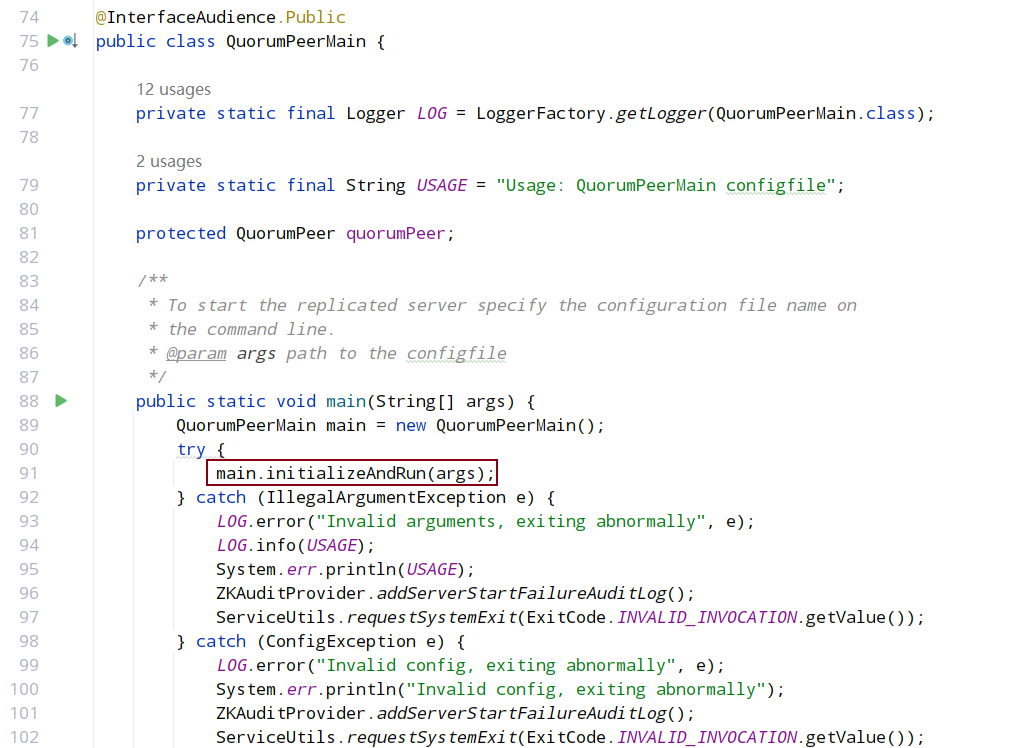
解析配置文件路径,并把文件读到内存,最后给属性赋值
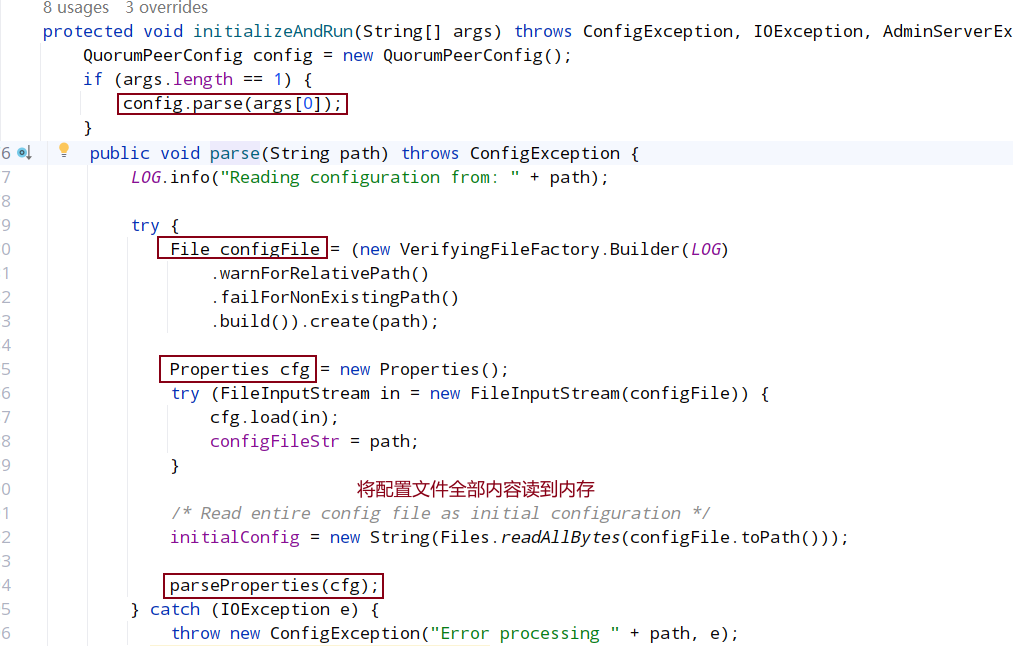
从property对象中解析配置键值对
选举算法只支持这一个
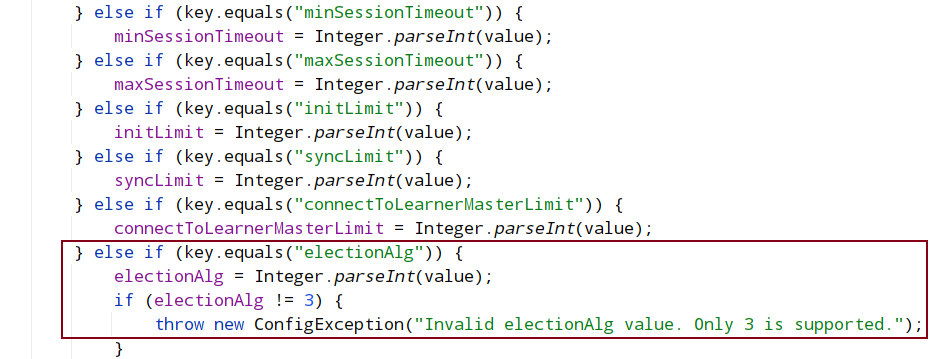
QuorumPeerMain类中的方法
DatadirCleanupManager 线程,由于 ZooKeeper 的任何一个变更操作都产生事务,事务日志需要持久化到硬盘,同时当写操作达到一定量或者一定时间间隔后,会对内存中的数据进行一次快照并写入到硬盘上的 snapshop 中,快照为了缩短启动时加载数据的时间从而加快整个系统启动。而随着运行时间的增长生成的 transaction log 和 snapshot 将越来越多,所以要定期清理,DatadirCleanupManager 就是启动一个 TimeTask 定时任务用于清理 DataDir 中的 snapshot 及对应的 transaction log。
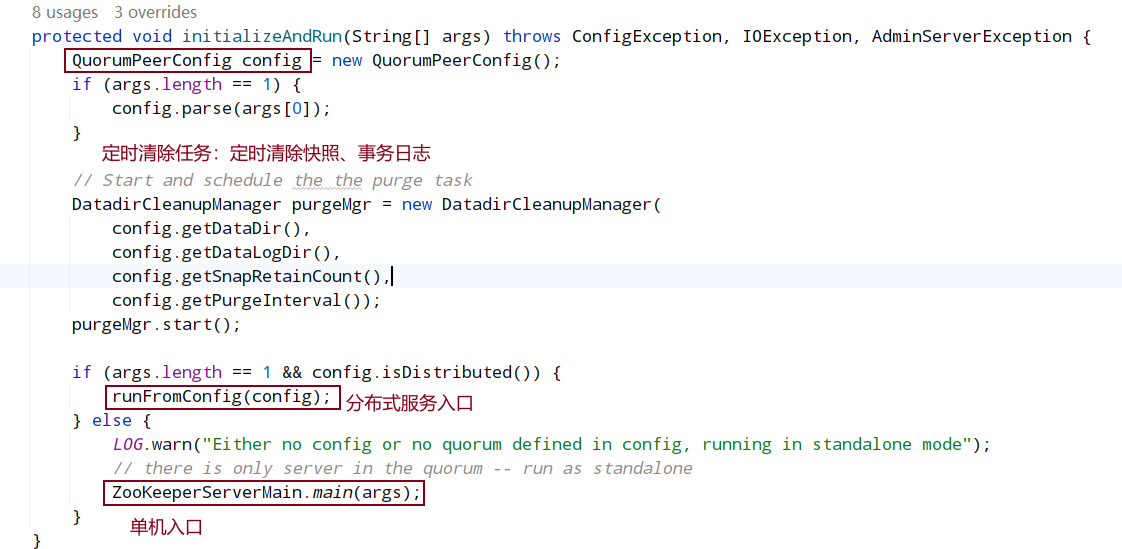
进入runFromConfig
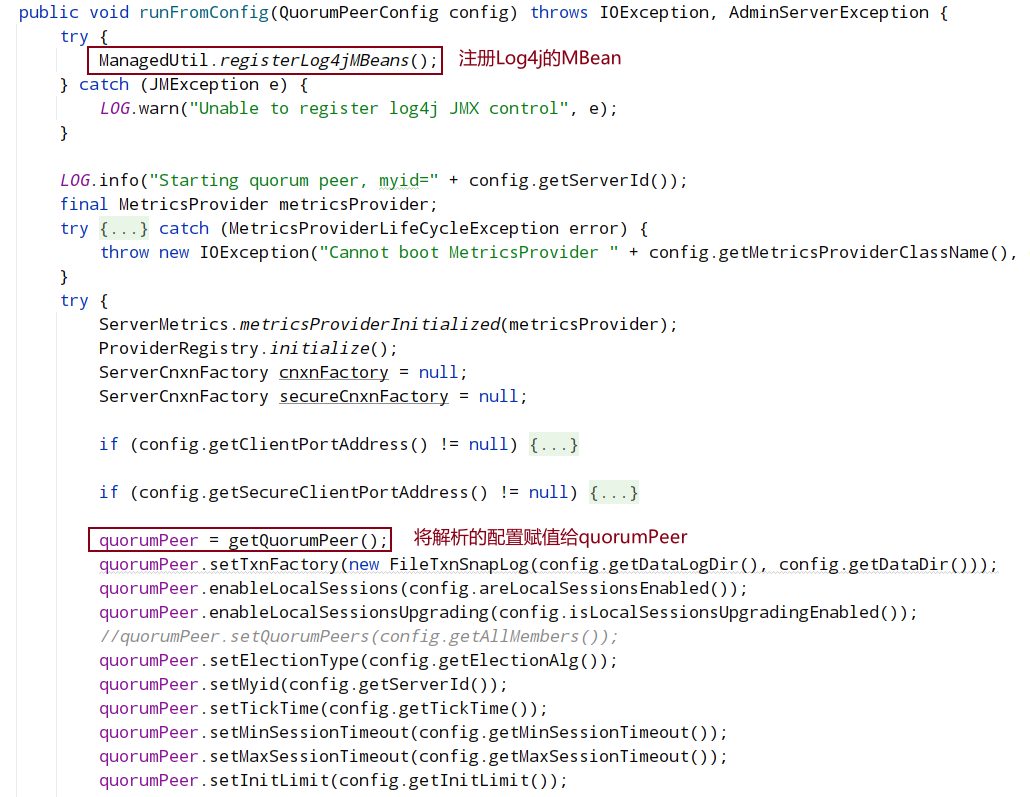
配置完之后,初始化并启动这个线程
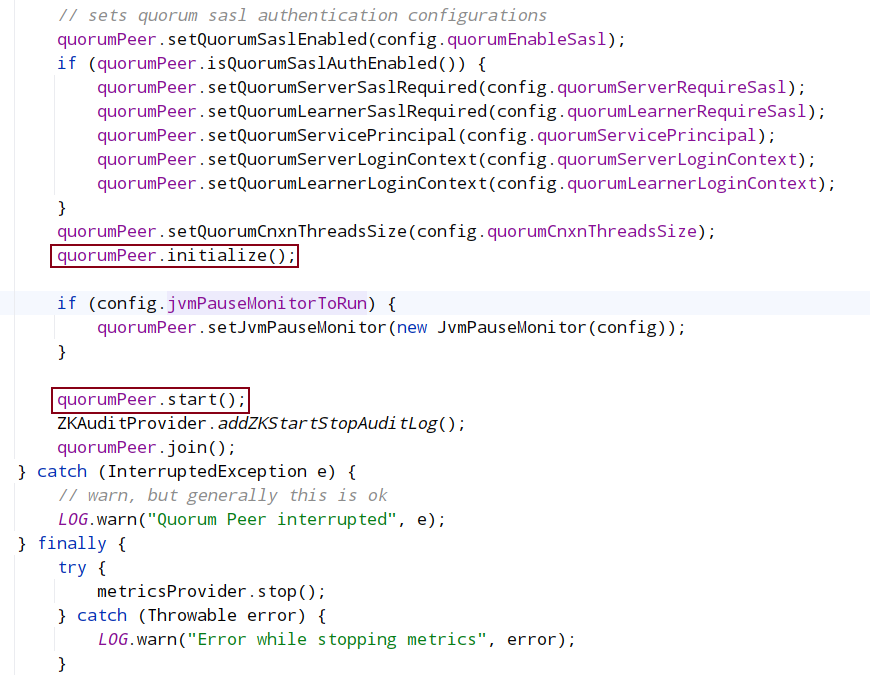
进入quorum.initialize()

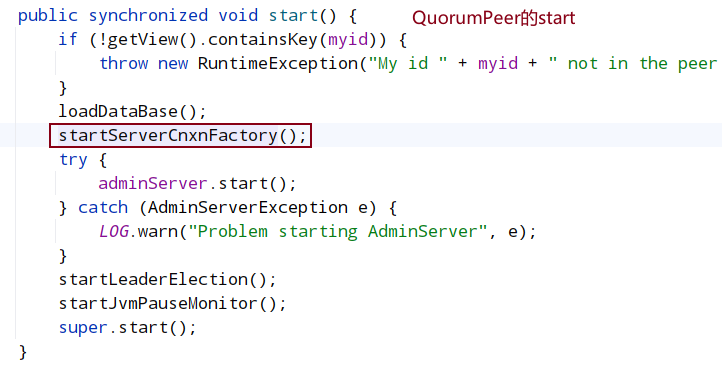
进入quorum.start()
这个方法包含5个start方法和一个loadDatabase方法

- getView()

- loadDatabase():构建dataTree

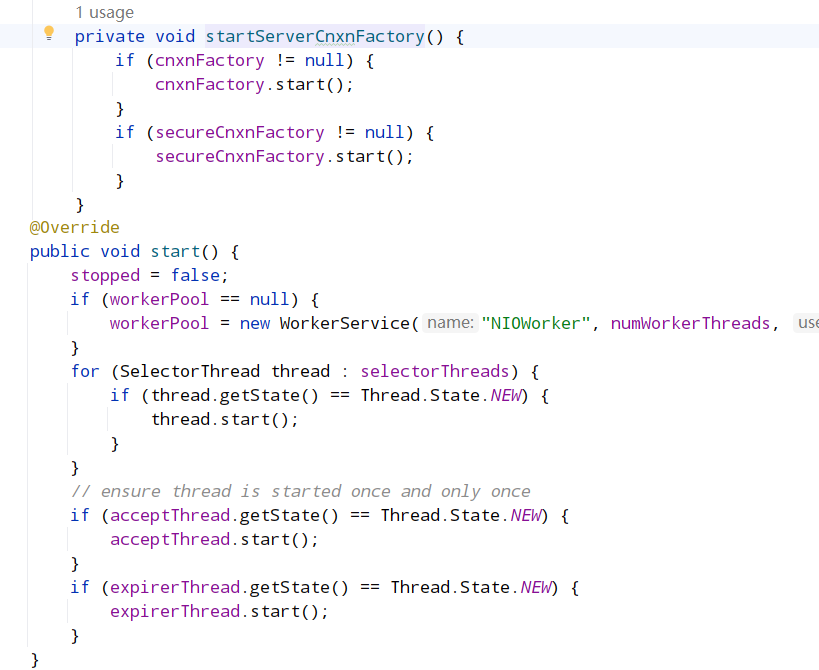
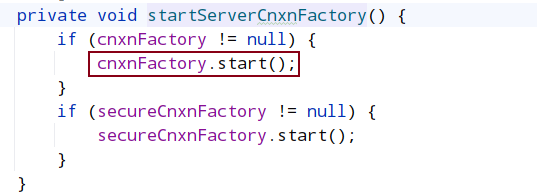
- startServerCnxnFactory()
ServerCnxn 这个类代表了一个客户端与一个 server 的连接,每个客户端连接过来都会被封装成一个 ServerCnxn 实例用来维护了服务器与客户端之间的 Socket 通道。
- adminServer.start()
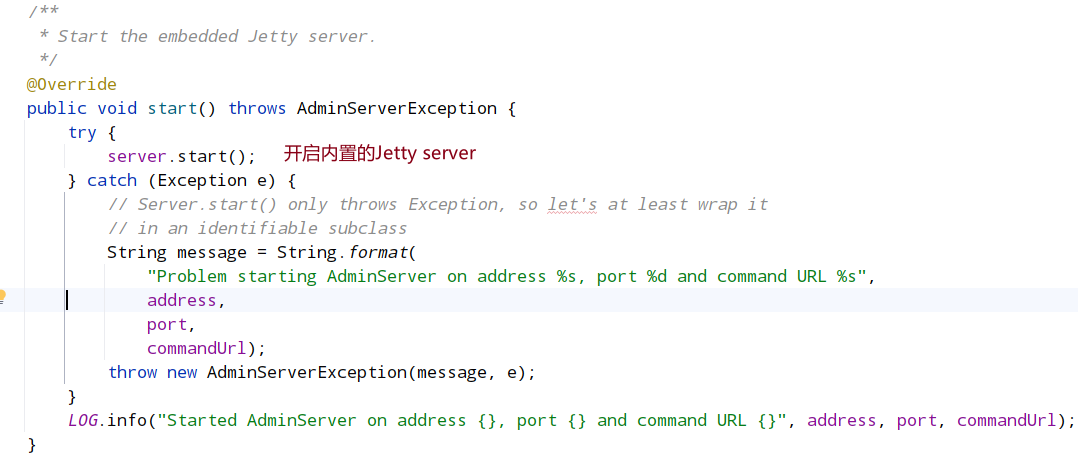
AdminServer是一个内置的Jettry服务,它提供了一个HTTP接口为四字母单词命令。默认的,服务被启动在8080端口,并且命令被发起通过URL "/commands/[command name]",例如,
http://localhost:8080/commands/stat。命令响应以JSON的格式返回。为了查看所有可用命令的列表,可以使用URL /commands (例如,http://localhost:8080/commands)。AdminServer默认开启,但是可以被关闭通过下面的方法:设置java系统属性zookeeper.admin.enableServer为false.

- startLeaderElection()
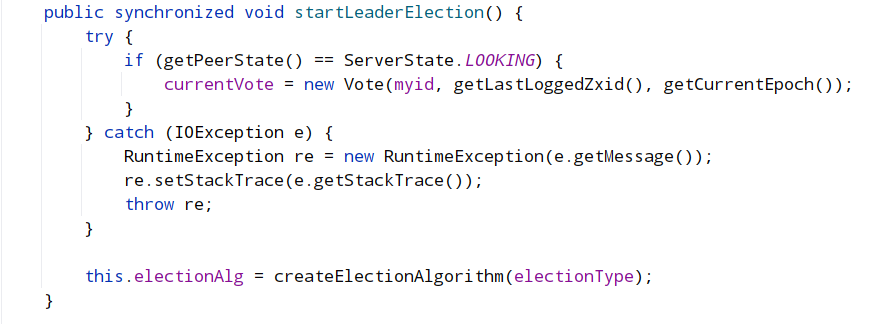
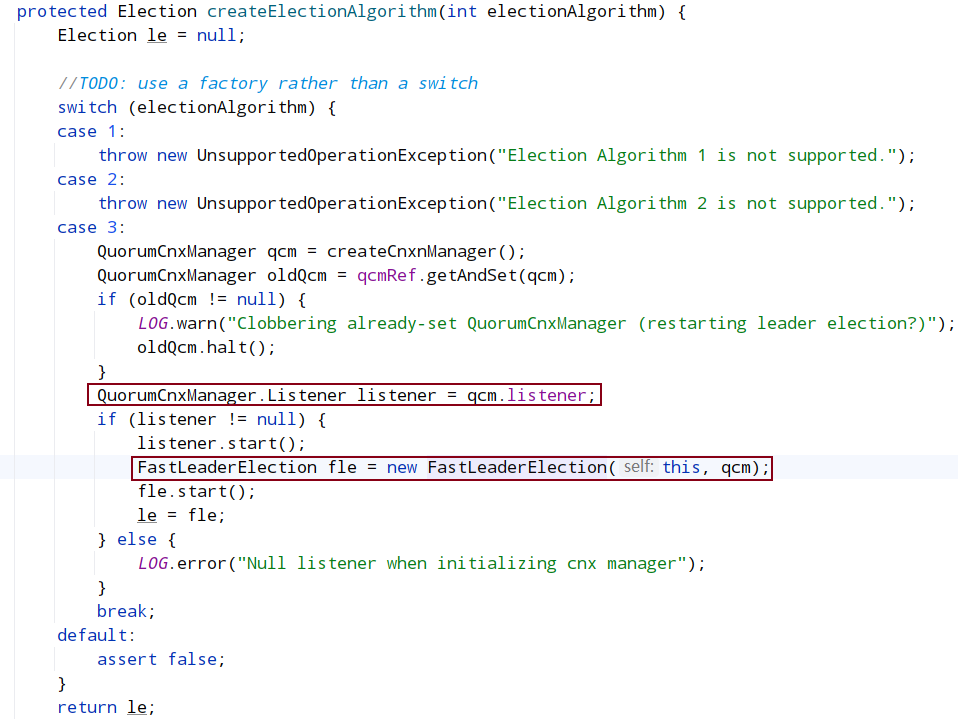
Leader 选举涉及到节点间的网络 IO,QuorumCnxManager 就是负责集群中各节点的网络 IO,QuorumCnxManager 包含一个内部类 Listener,Listener 是一个线程,这里启动 Listener 线程,主要启动选举监听端口并处理连接进来的 Socket;FastLeaderElection 就是封装了具体选举算法的实现。
QuorumPeer.createElectionAlgorithm() ——> QuorumCnxManager.Listener.start() ——> QuorumCnxManager.Listener.ListenerHandler.run() ——> QuorumCnxManager.Listener.ListenerHandler.acceptConnections()
-
listener:在选举端口监听- QuorumCnxManager负责处理选举时的连接与数据交换
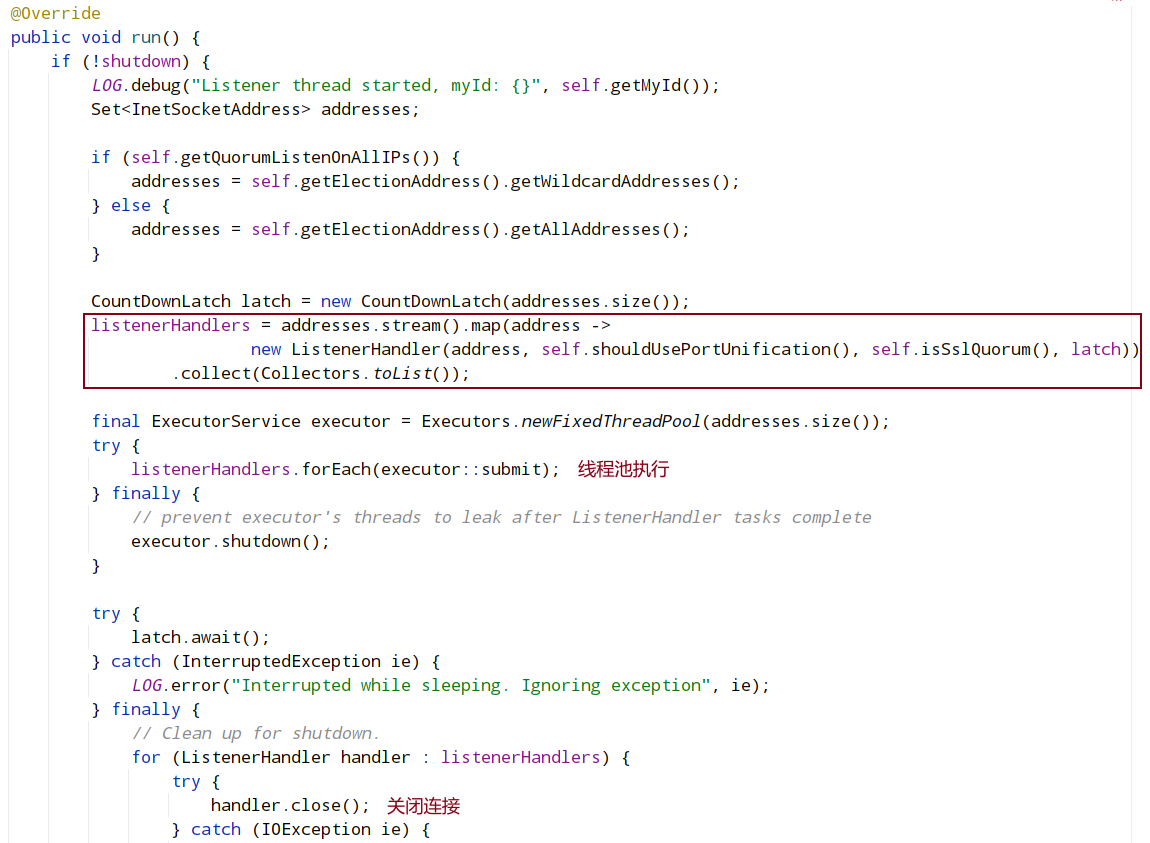
listenerHandler的run
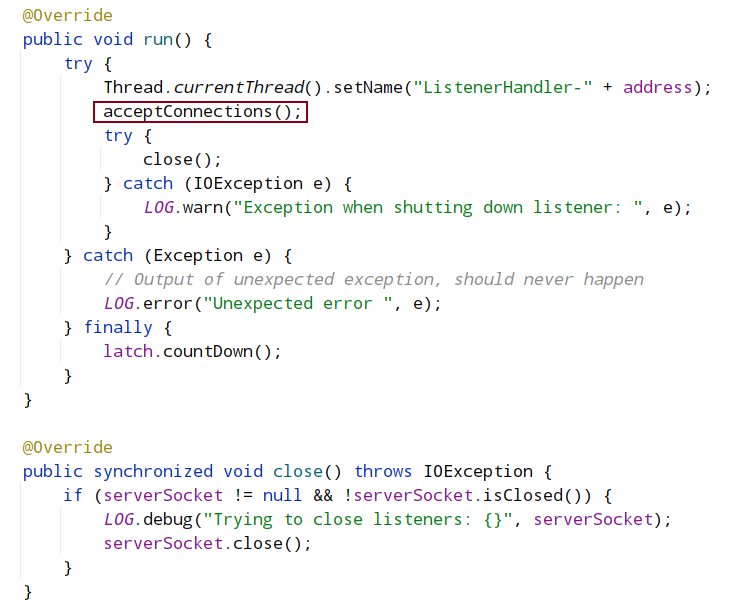
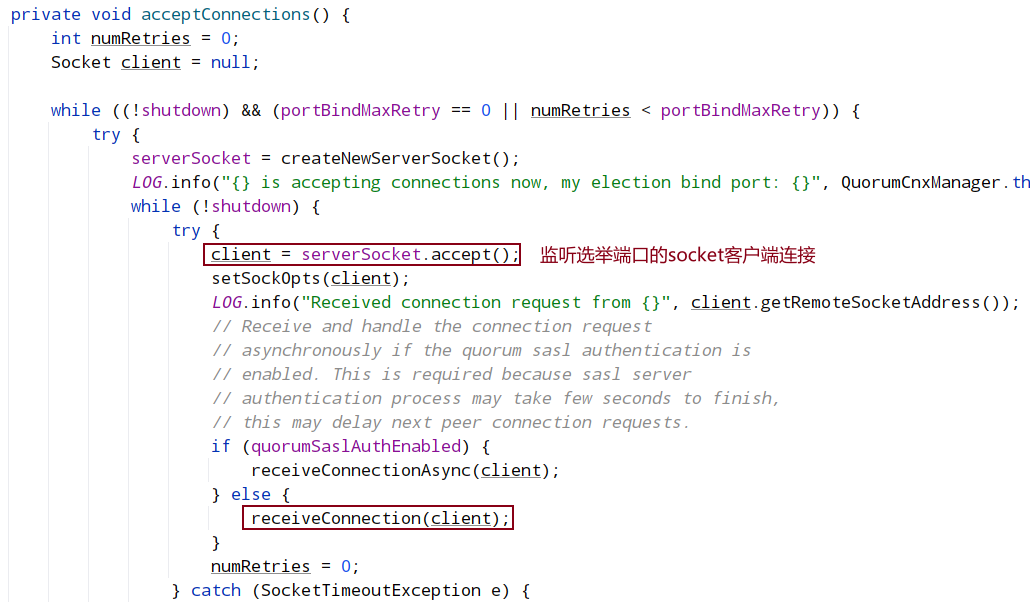
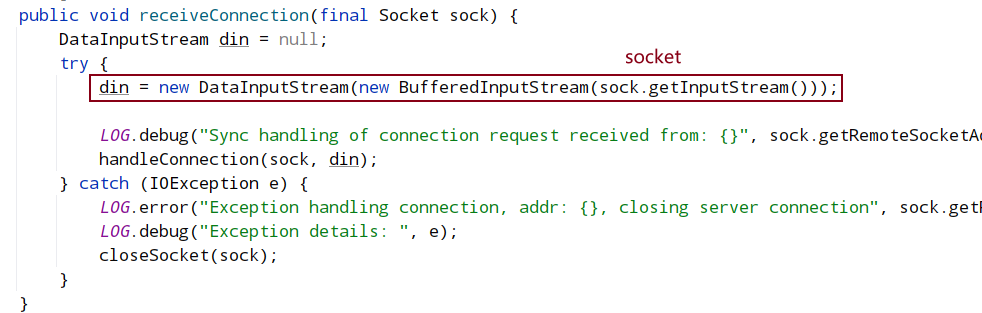
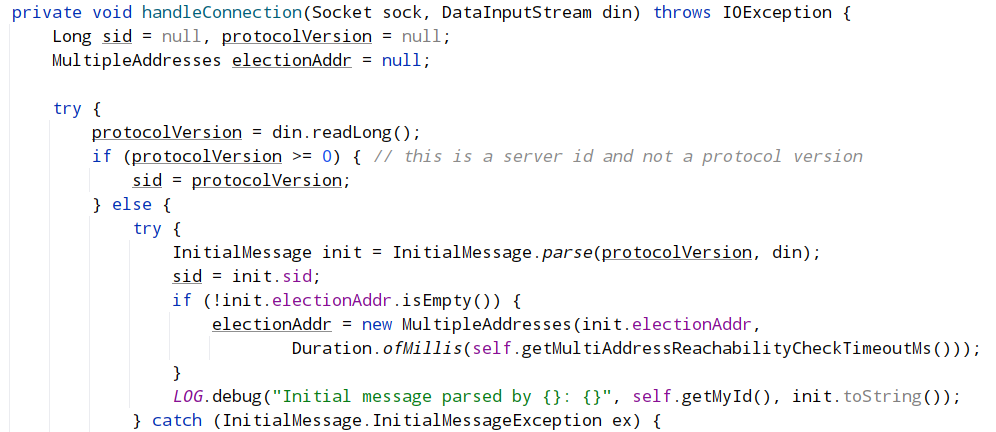
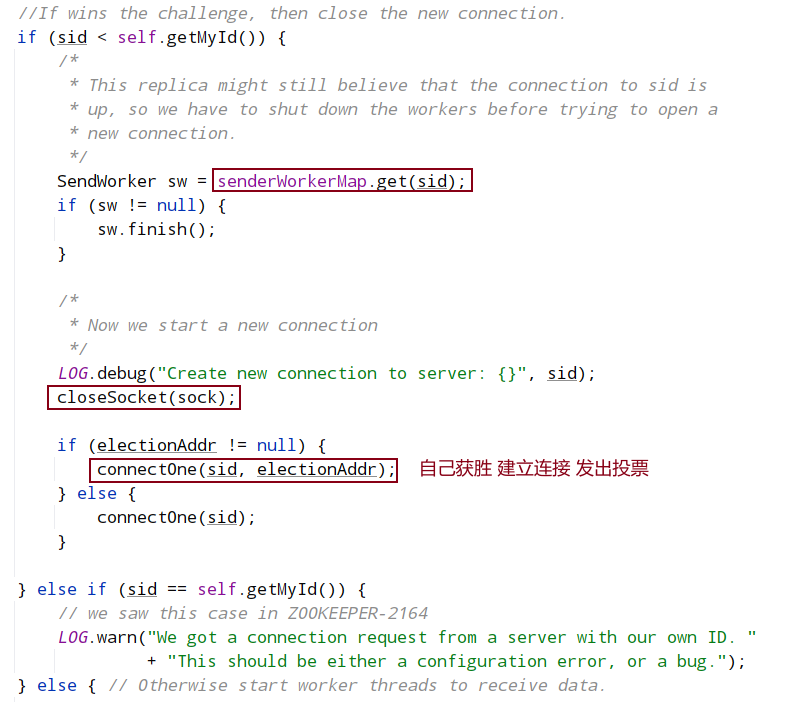
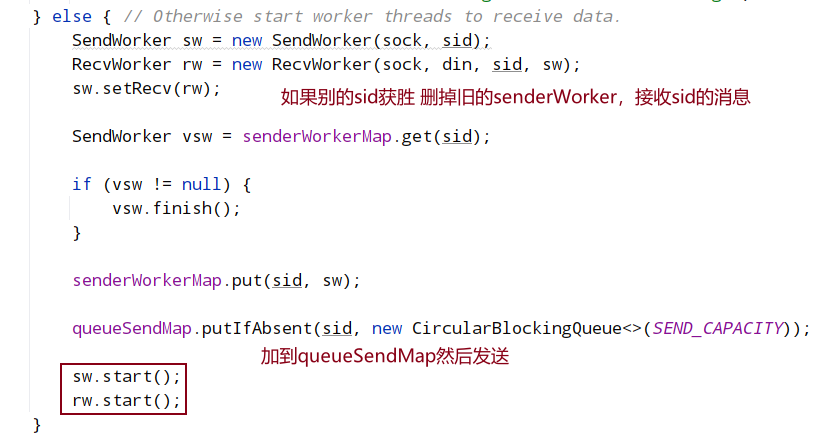
connectOne将在下面单独介绍
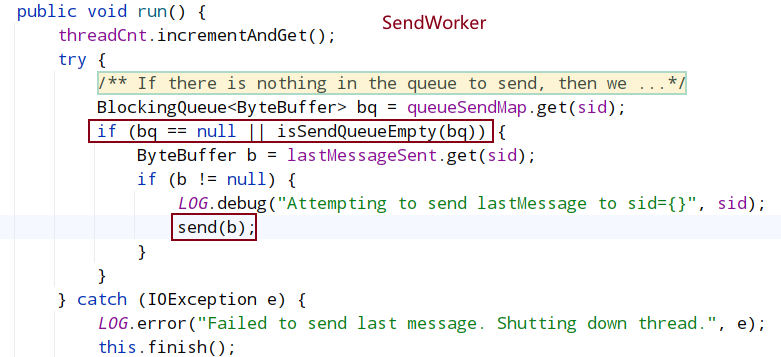
如果队列中没有要发送的内容,那么我们发送lastMessage以确保对等端接收到最后一条消息,对等方可以正确处理重复的消息。如果发送队列不是空的,那么我们有一个比lastMessage中存储的消息更新的消息。为了避免发送过时的消息,我们应该在发送队列中发送消息。
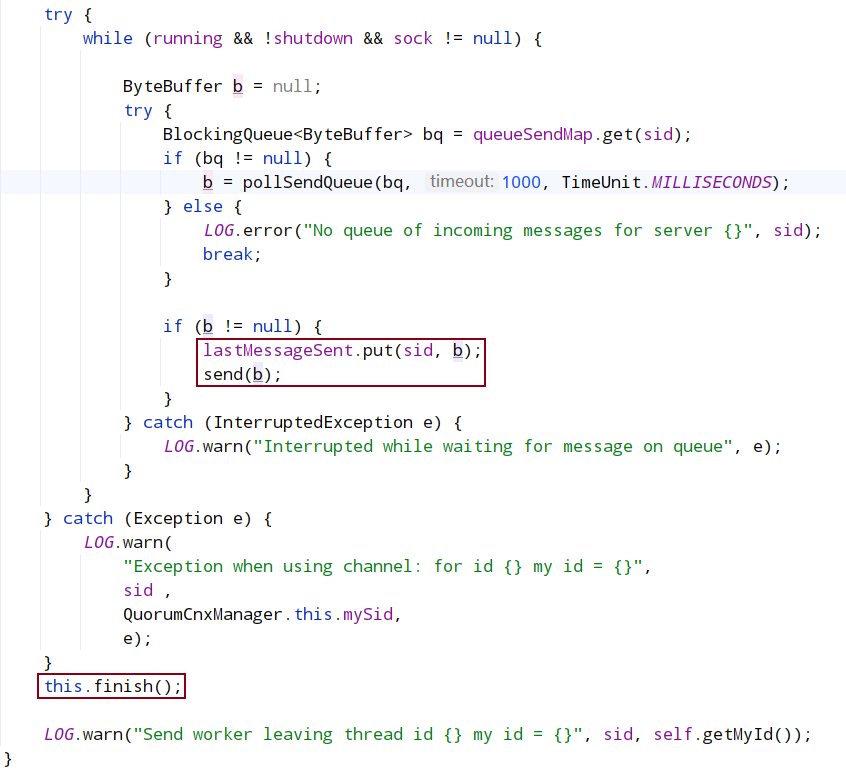

QuorumCnxManager结束
-
FastLeaderElection.start

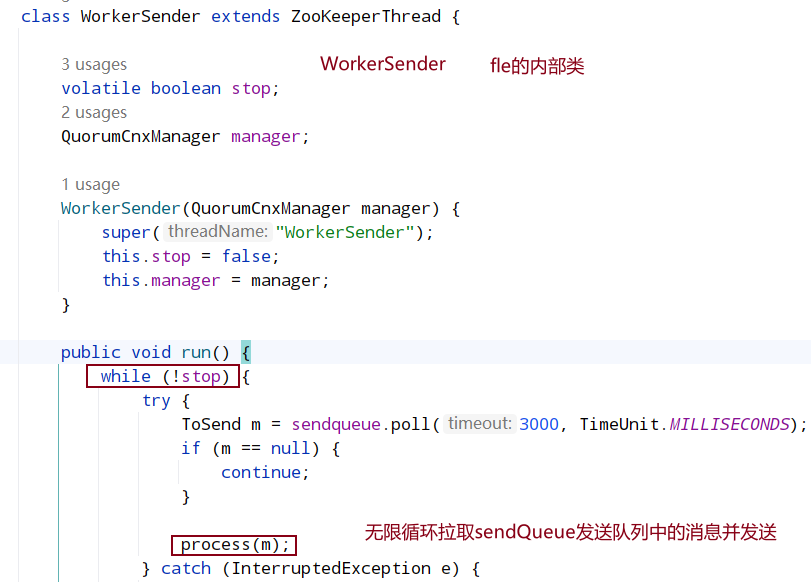
fle中的WorkerSender和WorkerRecvier阻塞从队列中拉取/加入消息,由QuorumCnxManager中的RecvWorker和SendWorker负责实现字节流写入与读取

-
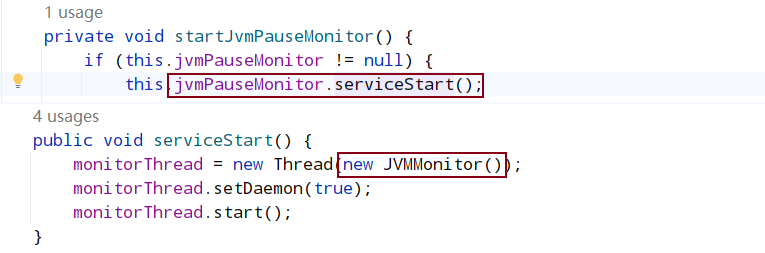
startJvmPauseMonitor()
JVMPauseMonitor开启一个内部守护线程,JVMMonitor是JVMPauseMonitor的内部类,他也是一个线程
JVM暂停监视器
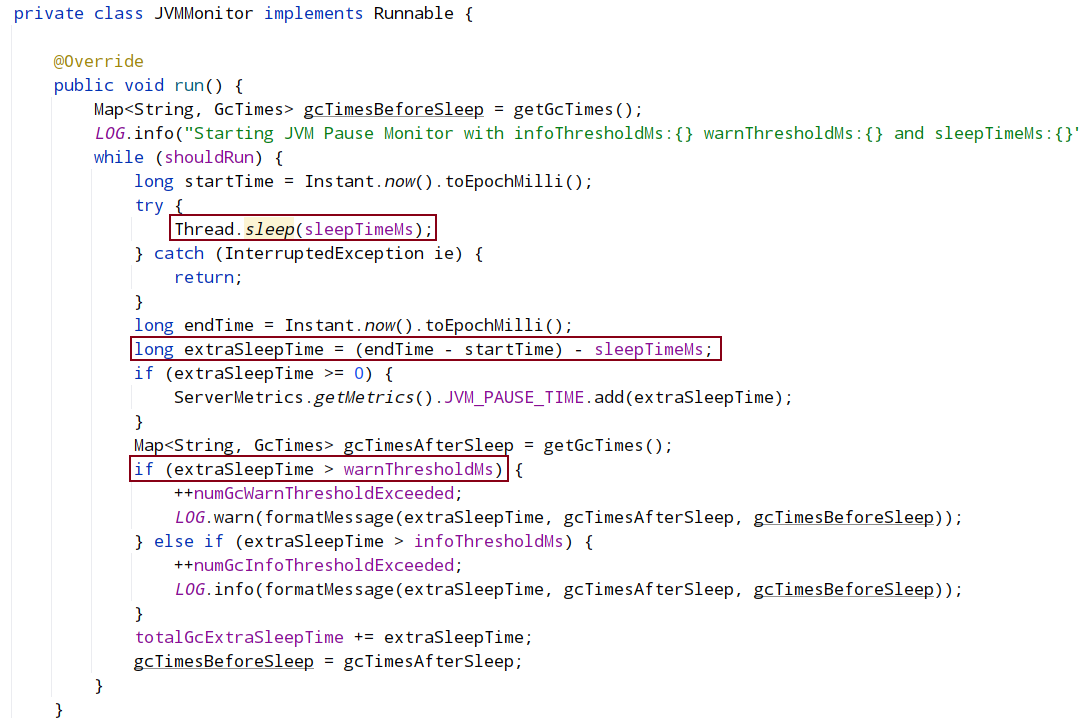
这是一个监视JVM暂停情况的服务。该服务建立一个简单的线程。在此线程中,在循环中运行sleep一段时间方法,如果sleep花费的时间比传递给sleep方法的时间长(执行sleep500ms但是实际上用了1000ms),就意味着JVM或者宿主机已经出现了停顿处理现象,可能会导致其它问题,如果这种停顿被监测出来达到一定的阈值,线程会打印相应级别的消息。还可以把额外sleep的时间进行metrics统计,外部的监控系统可以监控zookeeper的健康状态以及进行报警。
-
super.start :执行QuorumPeer的run方法。
QuorumPeer 线程进入到一个无限循环模式,不停的通过 getPeerState 方法获取当前节点状态,然后执行相应的分支逻辑。大致流程可以简单描述如下:
- 首先系统刚启动时 serverState 默认是 LOOKING,表示需要进行 Leader 选举,这时进入 Leader 选举状态中,会调用 FastLeaderElection.lookForLeader 方法,lookForLeader 方法内部也包含了一个循环逻辑,直到选举出 Leader 才会跳出 lookForLeader 方法,如果选举出的 Leader 就是本节点,则将 serverState=LEADING 赋值,否则设置成 FOLLOWING 或 OBSERVING。
- 然后 QuorumPeer.run 进行下一轮次循环,通过 getPeerState 获取当前 serverState 状态,如果是 LEADING,则表示当前节点当选为 LEADER,则进入 Leader 角色分支流程,执行作为一个 Leader 该干的任务;如果是 FOLLOWING 或 OBSERVING,则进入 Follower 或 Observer 角色,并执行其相应的任务。注意:进入分支路程会一直阻塞在其分支中,直到角色转变才会重新进行下一轮次循环,比如 Follower 监控到无法与 Leader 保持通信了,会将 serverState 赋值为 LOOKING,跳出分支并进行下一轮次循环,这时就会进入 LOOKING 分支中重新进行 Leader 选举。


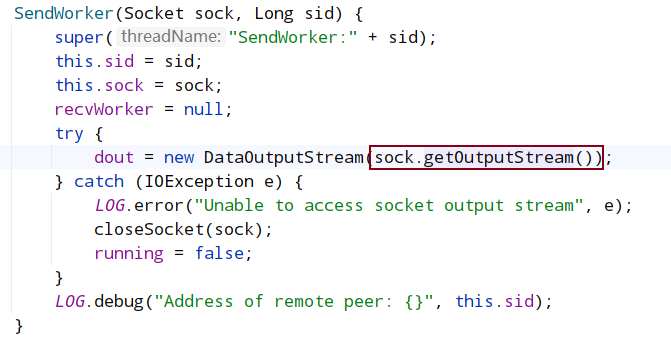
QuorumCnxManager 有一个内部类 Listener,初始化一个 ServerSocket,然后在一个 while 循环中调用 accept 接收客户端(注意:这里的客户端指的是集群中其它服务器)连接。当有客户端连接进来后,会将该客户端 Socket 封装成 RecvWorker 和 SendWorker,它们都是线程,分别负责和该 Socket 所代表的客户端进行读写。其中,RecvWorker 和 SendWorker 是成对出现的,每对负责维护和集群中的一台服务器进行网络 IO 通信。
FastLeaderElection 负责 Leader 选举核心规则算法实现,包含了两个内部类 WorkerSender 和 WorkerReceiver 线程。
FastLeaderElection 中进行选举时广播投票信息时,将投票信息写入到对端服务器大致流程如下:
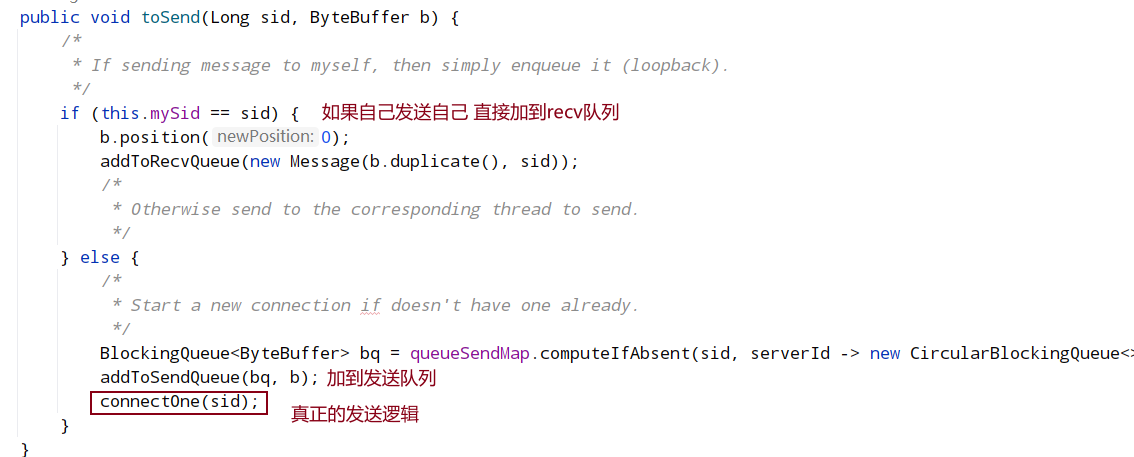
- 将数据封装成 ToSend 格式放入到 sendqueue;
- WorkerSender 线程会一直轮询提取 sendqueue 中的数据,当提取到 ToSend 数据后,会获取到集群中所有参与 Leader 选举节点(除 Observer 节点外的节点)的 sid,如果 sid 即为本机节点,则转成 Notification 直接放入到 recvqueue 中,因为本机不再需要走网络 IO;否则放入到 queueSendMap 中,key 是要发送给哪个服务器节点的 sid,ByteBuffer 即为 ToSend 的内容,queueSendMap 维护的着当前节点要发送的网络数据信息,由于发送到同一个 sid 服务器可能存在多条数据,所以 queueSendMap 的 value 是一个 queue 类型;
- QuorumCnxManager 中的 SendWorkder 线程不停轮询 queueSendMap 中是否存在自己要发送的数据,每个 SendWorkder 线程都会绑定一个 sid 用于标记该 SendWorkder 线程和哪个对端服务器进行通信,因此,queueSendMap.get(sid)即可获取该线程要发送数据的 queue,然后通过 queue.poll()即可提取该线程要发送的数据内容;
- 然后通过调用 SendWorkder 内部维护的 socket 输出流即可将数据写入到对端服务器。
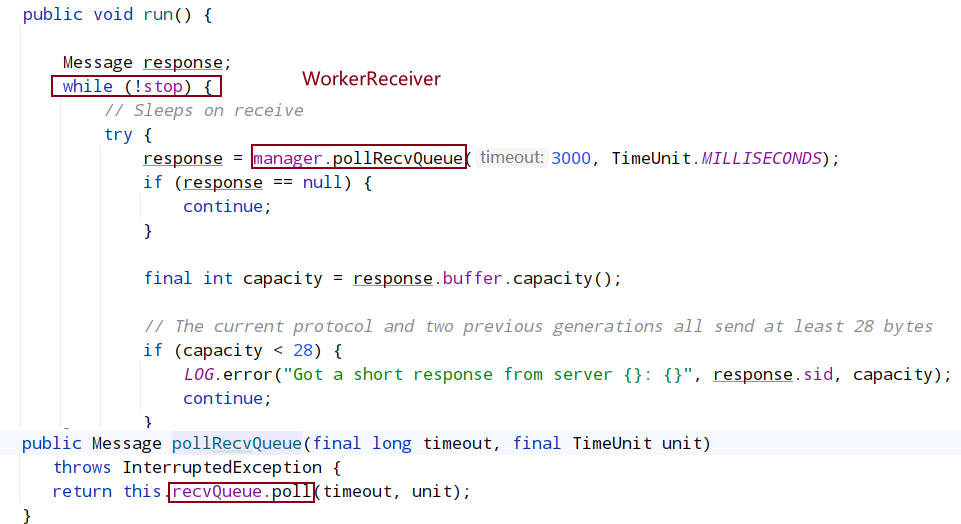
FastLeaderElection 中进行选举时广播投票信息时,从对端服务器读取投票信息的大致流程如下:
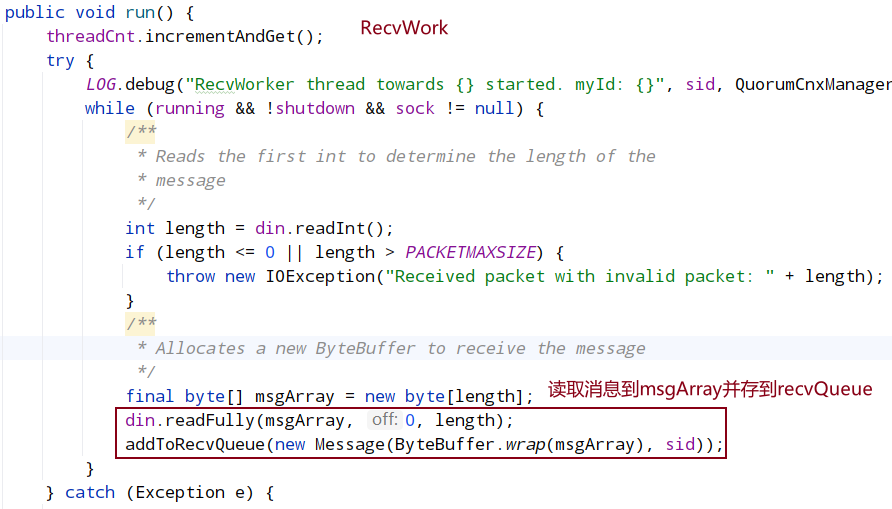
- QuorumCnxManager 中的 RecvWorker 线程会一直从 Socket 的输入流中读取数据,当读取到对端发送过来的数据时,转成 Message 格式并放入到 recvQueue 中;
- FastLeaderElection.WorkerReceiver 线程会轮询方式从 recvQueue 提取数据并转成 Notification 格式放入到 recvqueue 中;
- FastLeaderElection 从 recvqueu 提取所有的投票信息进行比较 最终选出一个 Leader。
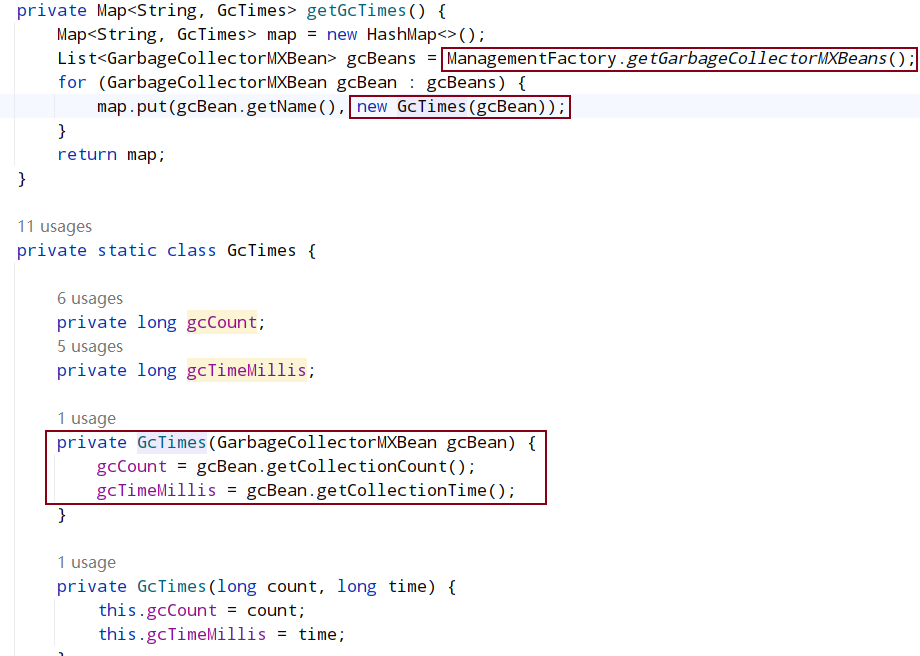
更新自己期望投票信息,即自己期望选哪个服务器作为 Leader(用 sid 代替期望服务器节点)以及该服务器 zxid、epoch 等信息,第一次投票默认都是投自己当选 Leader,然后调用 sendNotifications 方法广播该投票到集群中所有可以参与投票服务器,广播涉及到网络 IO 流程前面已讲解,这里就不再细说;
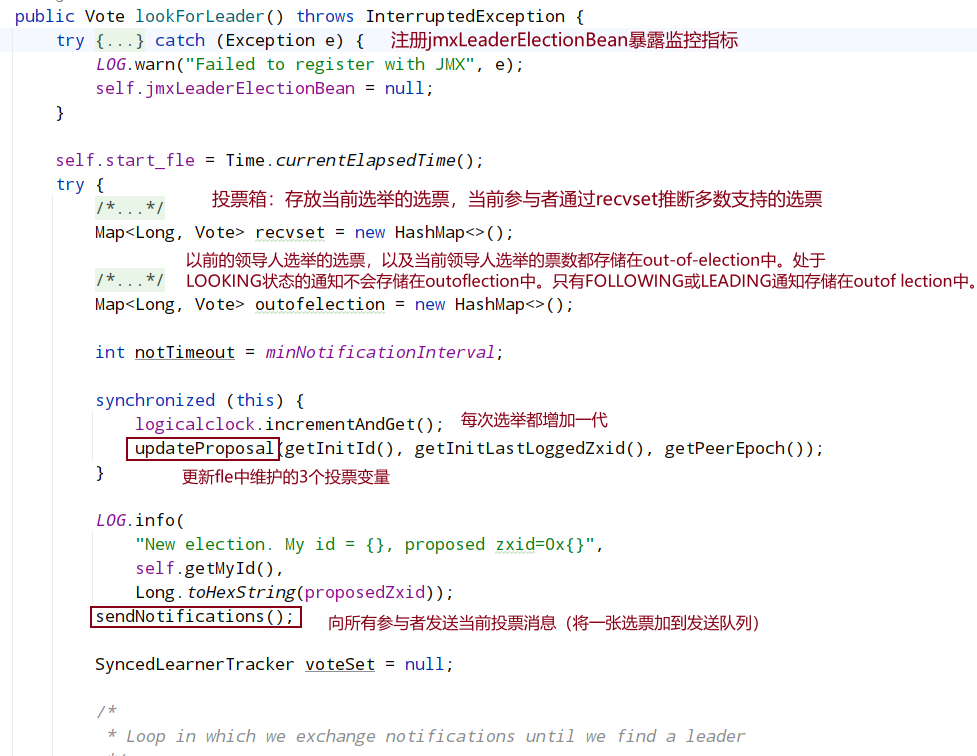
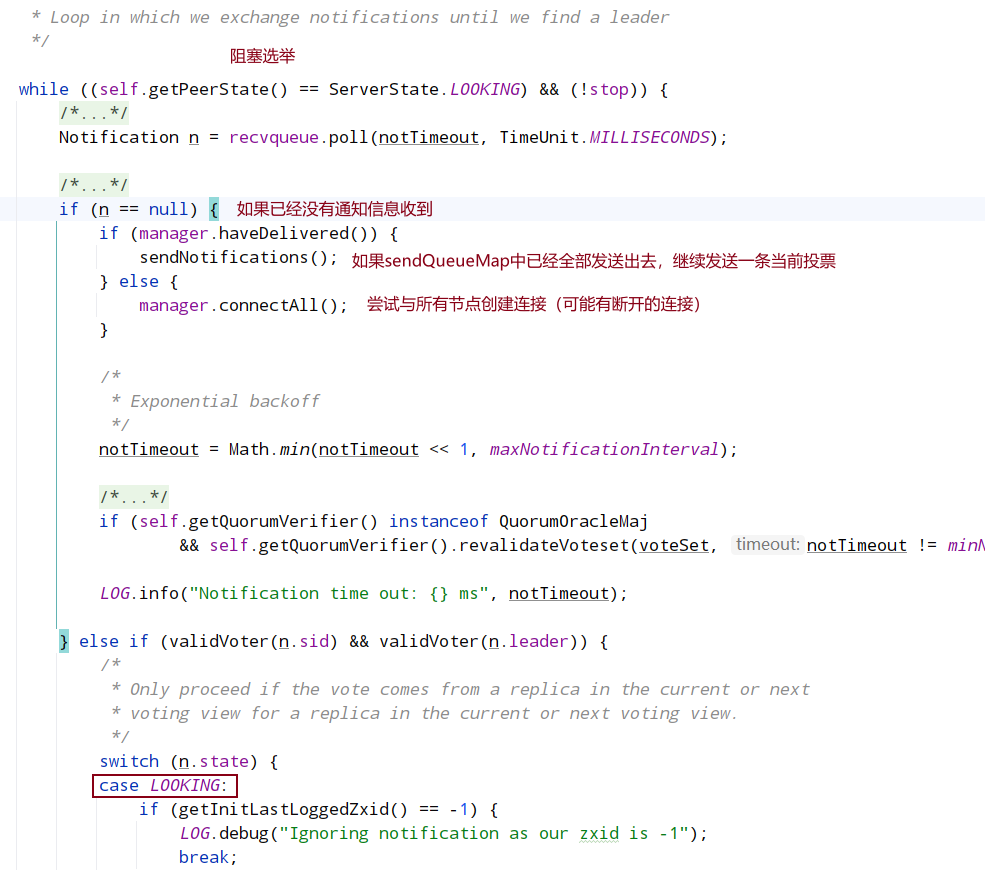
8.2 主要选举逻辑

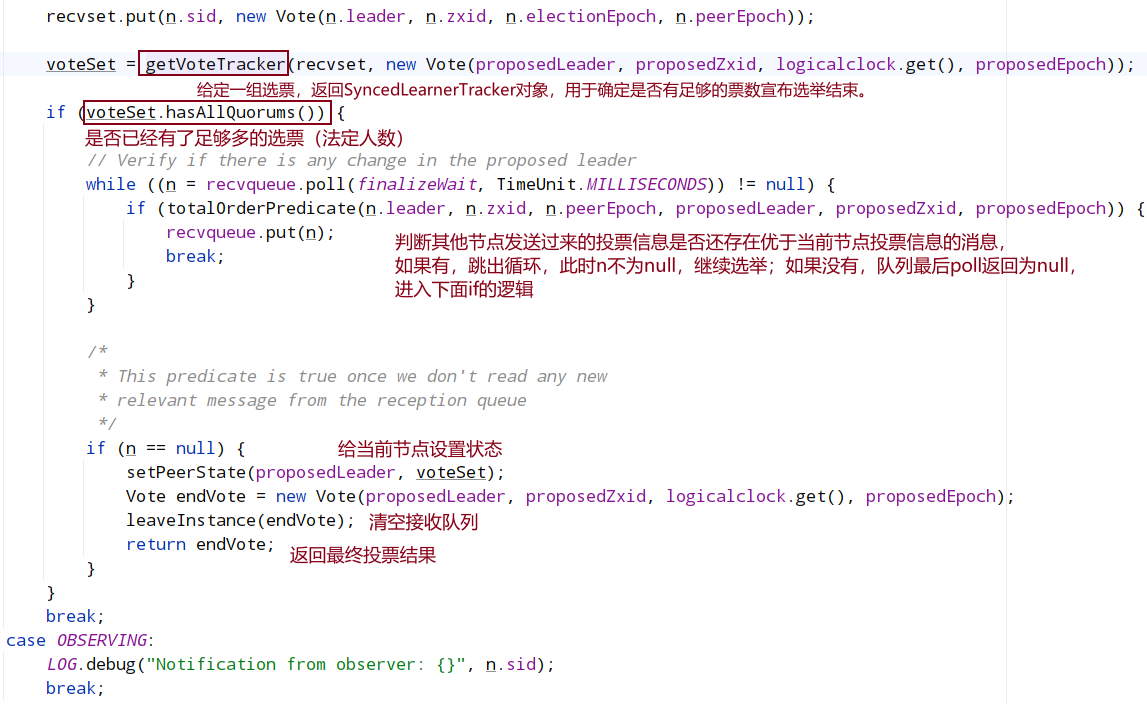
最后将新选票放入到recvset投票箱中,并判断投票箱中的投票是否有超过一半已经和自身的选票内容一致,如果未超过一半则再次重新进行上面选举流程,如果已经达到一半,则进行最后的判断,把recvqueue中的投票信息全部取出来进行判断,判断是否还存在优于当前自身选票的投票消息,如果有的话,则将当前选票重新放入recvqueue中,重新进行选举流程,没有的话则直接结束选举.
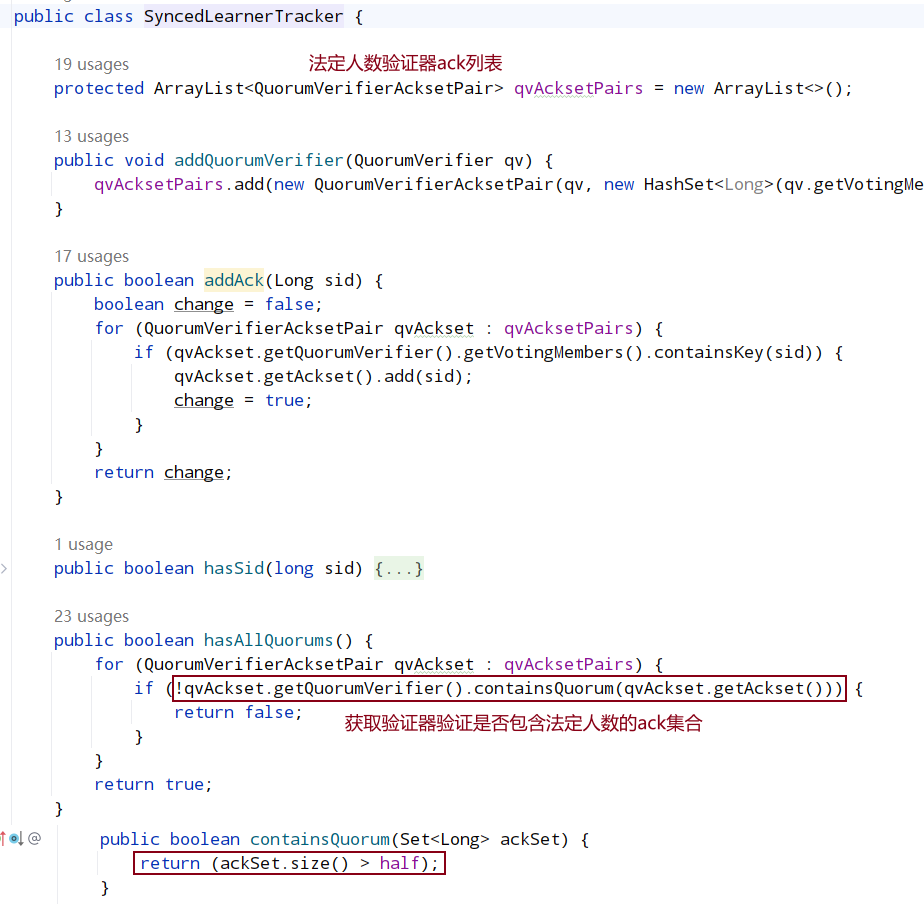
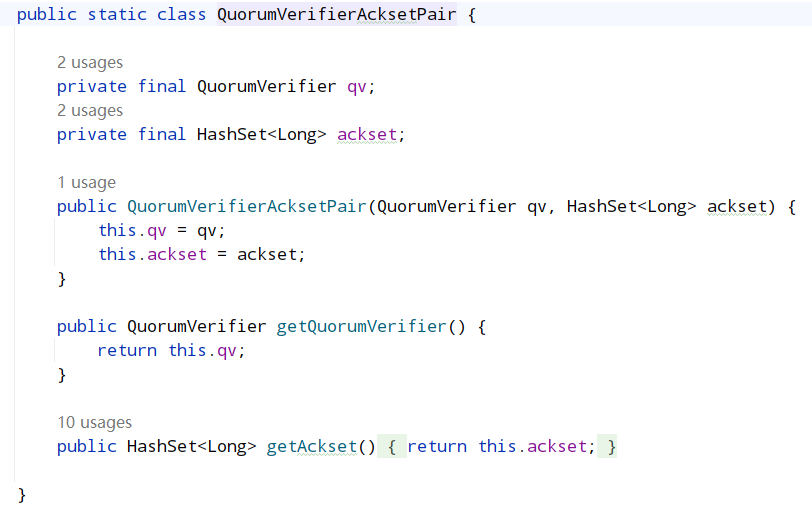
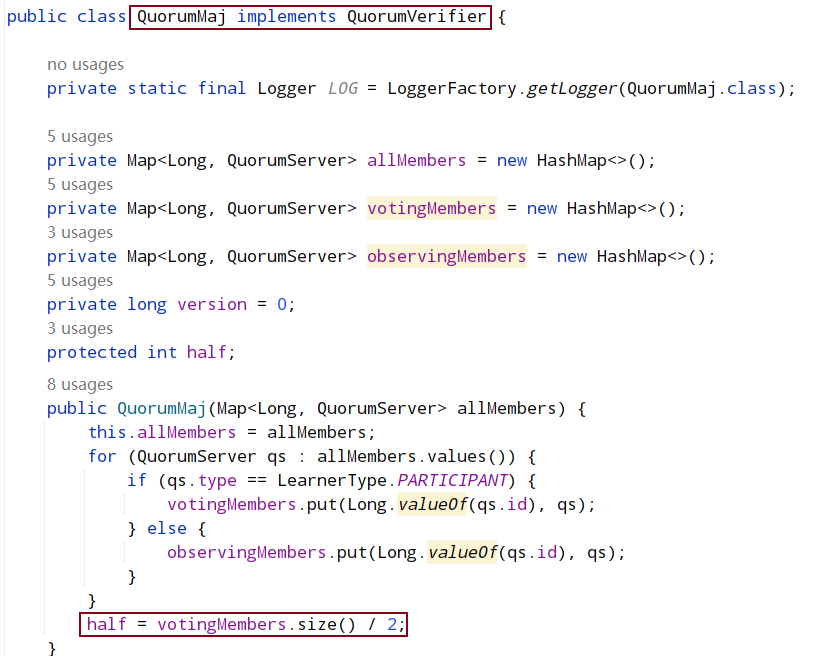
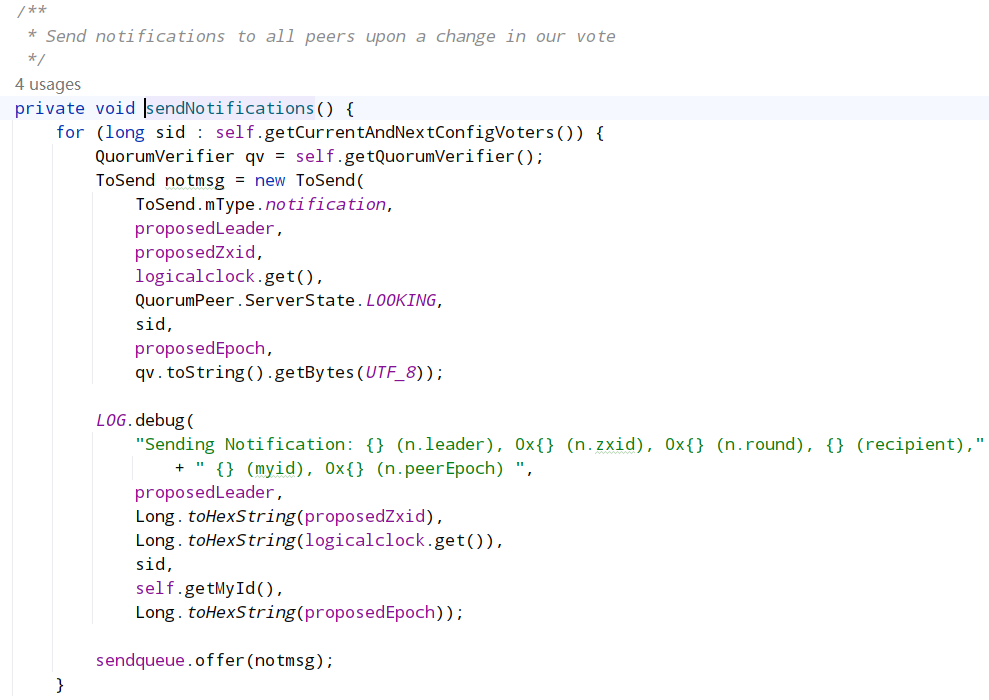
首先对之前提到的选举轮次 electionEpoch 进行判断,这里分为三种情况:
- 只有对方发过来的投票的 electionEpoch 和当前节点相等表示是同一轮投票,即投票有效,然后调用 totalOrderPredicate()对投票进行 PK,返回 true 代表对端胜出,则表示第一次投票是错误的(第一次都是投给自己),更新自己投票期望对端为 Leader,然后调用 sendNotifications()将自己最新的投票广播出去。返回 false 则代表自己胜出,第一次投票没有问题,就不用管。
- 如果对端发过来的 electionEpoch 大于自己,则表明重置自己的 electionEpoch,然后清空之前获取到的所有投票 recvset,因为之前获取的投票轮次落后于当前则代表之前的投票已经无效了,然后调用 totalOrderPredicate()将当前期望的投票和对端投票进行 PK,用胜出者更新当前期望投票,然后调用 sendNotifications()将自己期望头破广播出去。注意:这里不管哪一方胜出,都需要广播出去,而不是步骤 a 中己方胜出不需要广播,这是因为由于 electionEpoch 落后导致之前发出的所有投票都是无效的,所以这里需要重新发送
- 如果对端发过来的 electionEpoch 小于自己,则表示对方投票无效,直接忽略不进行处理
- 最后将新选票放入到recvset投票箱中,并判断投票箱中的投票是否有超过一半已经和自身的选票内容一致,如果未超过一半则再次重新进行上面选举流程,如果已经达到一半,则进行最后的判断,把recvqueue中的投票信息全部取出来进行判断,判断是否还存在优于当前自身选票的投票消息,如果有的话,则将当前选票重新放入recvqueue中,重新进行选举流程,没有的话则直接结束选举.
8.2.1 OBSERVING状态逻辑
进入这个分支,证明已经选举结束,进入观察者角色,将当前对等端设置为观察者,然后执行观察者的任务
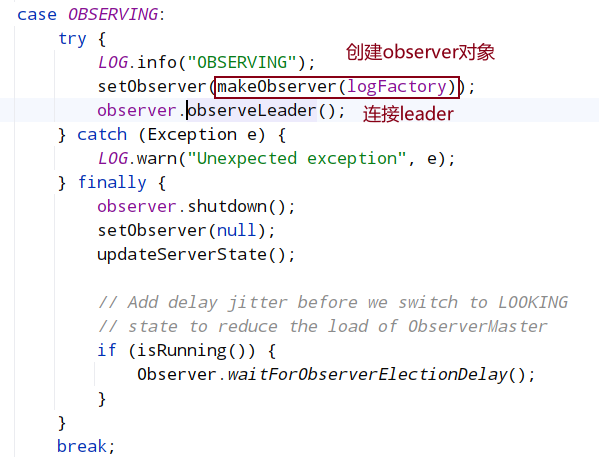
makeOberver
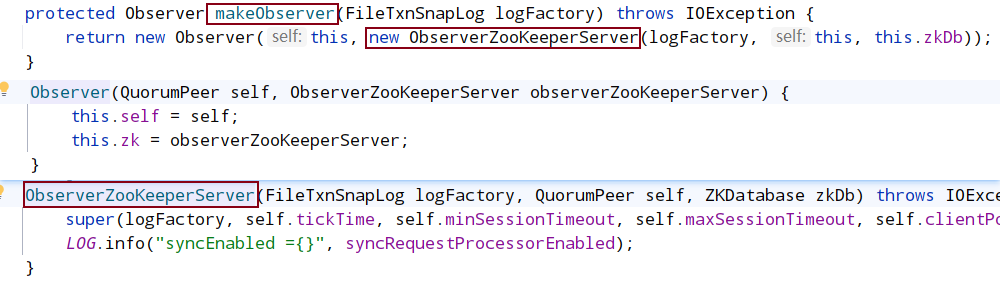
obsereLeader
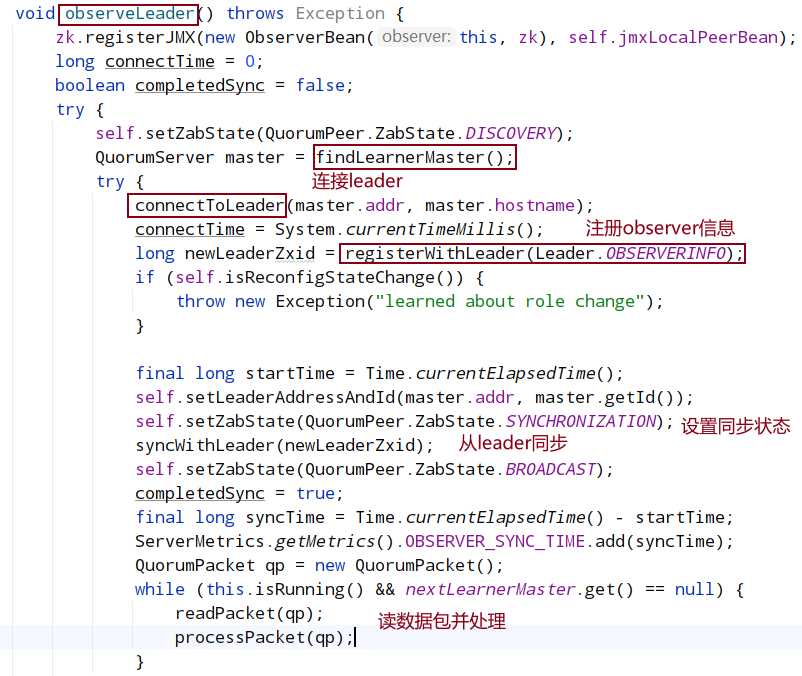
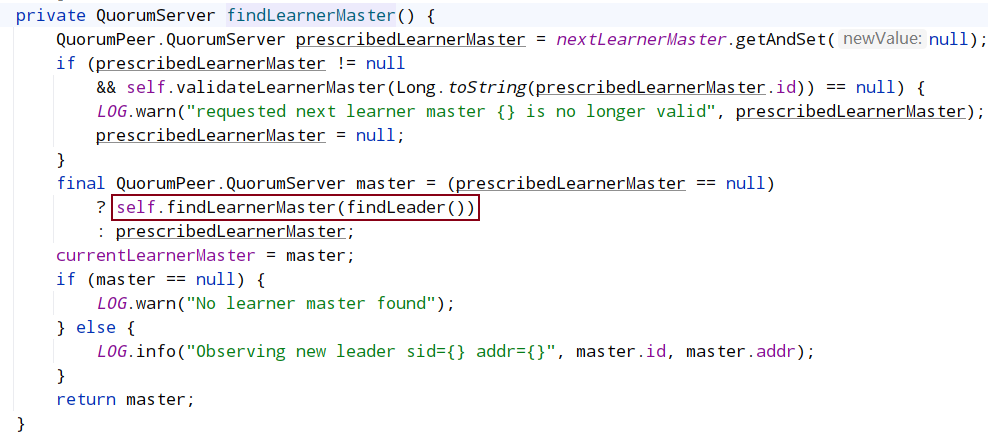
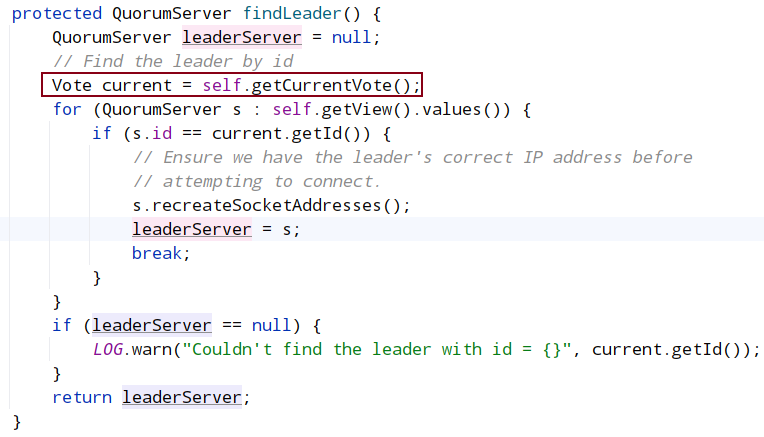
根据当前投票结果找出leader地址
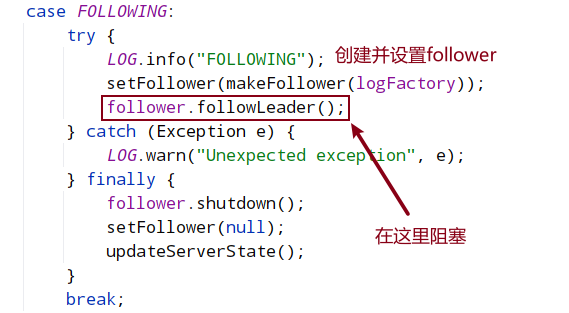
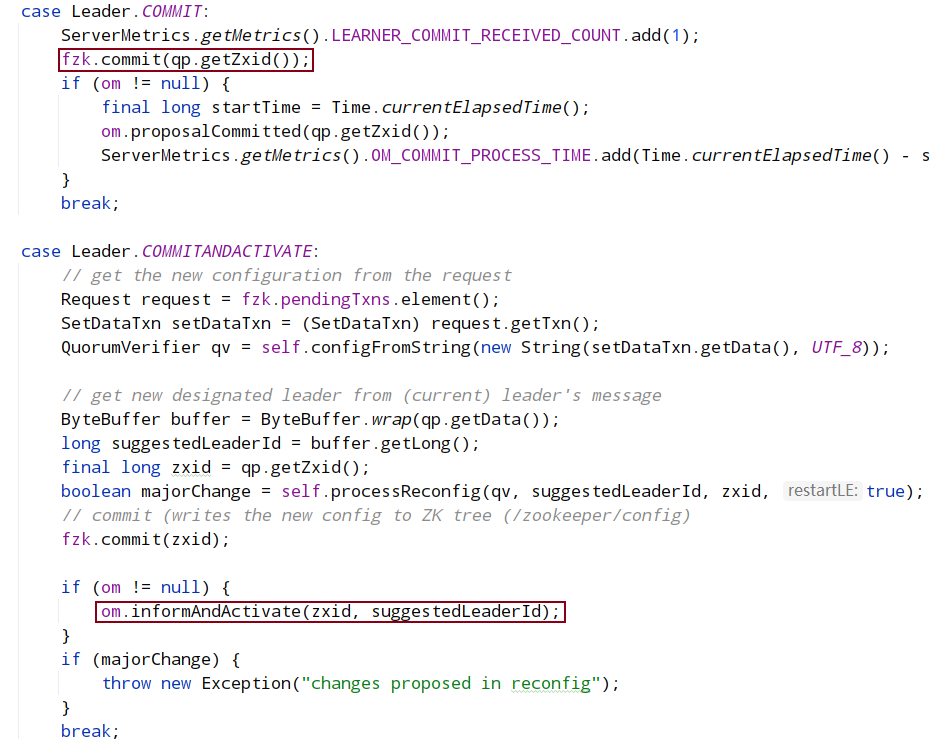
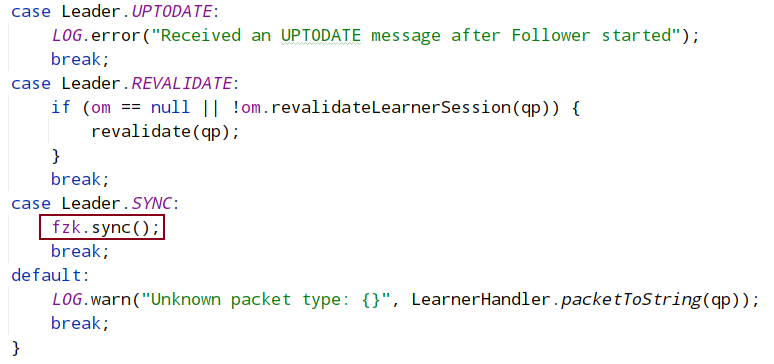
8.2.2 FOLLOWING状态逻辑
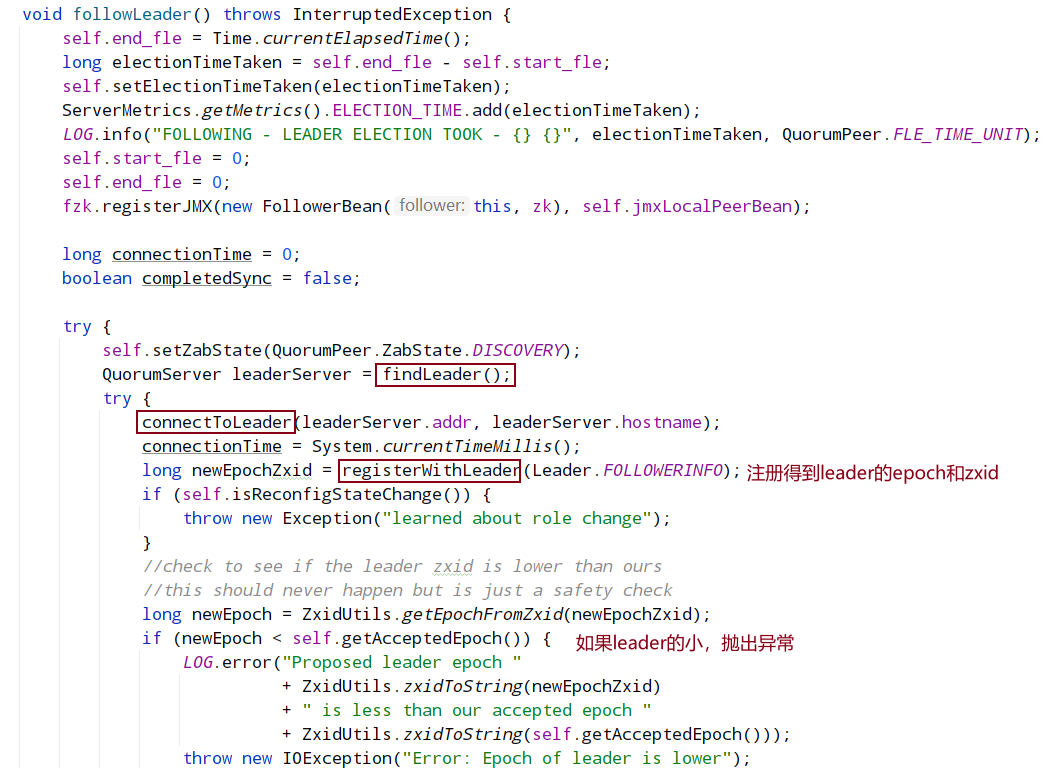
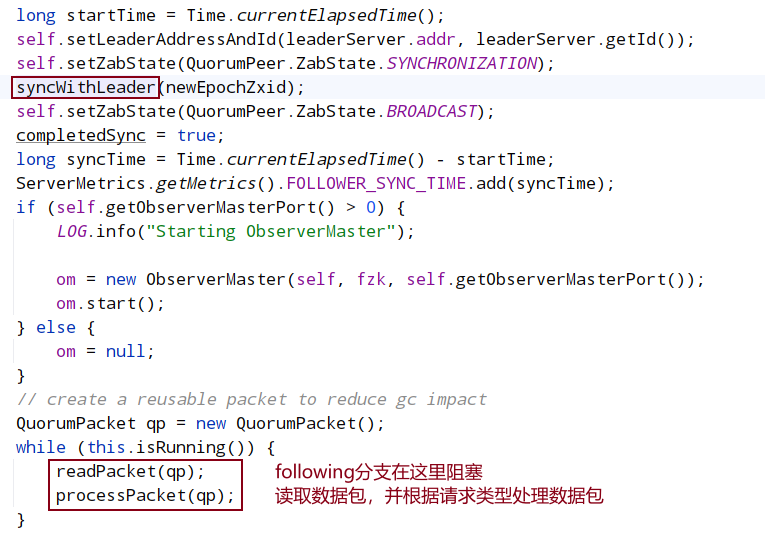
zabState在各节点初始化时为discovery,节点同步leader数据时为synchronization,节点准备就绪时为broadcast
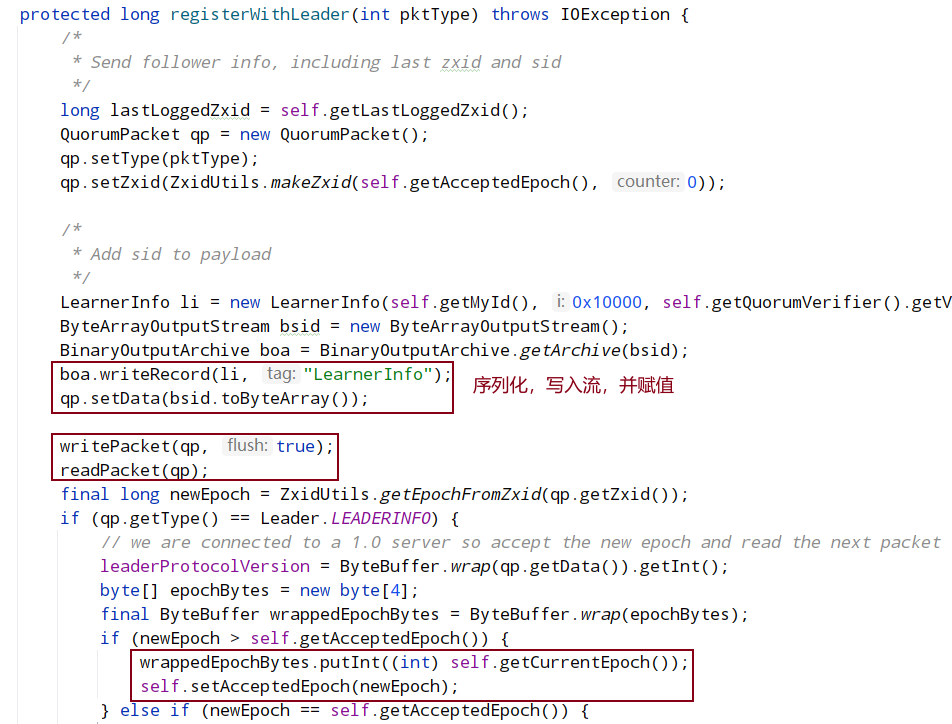
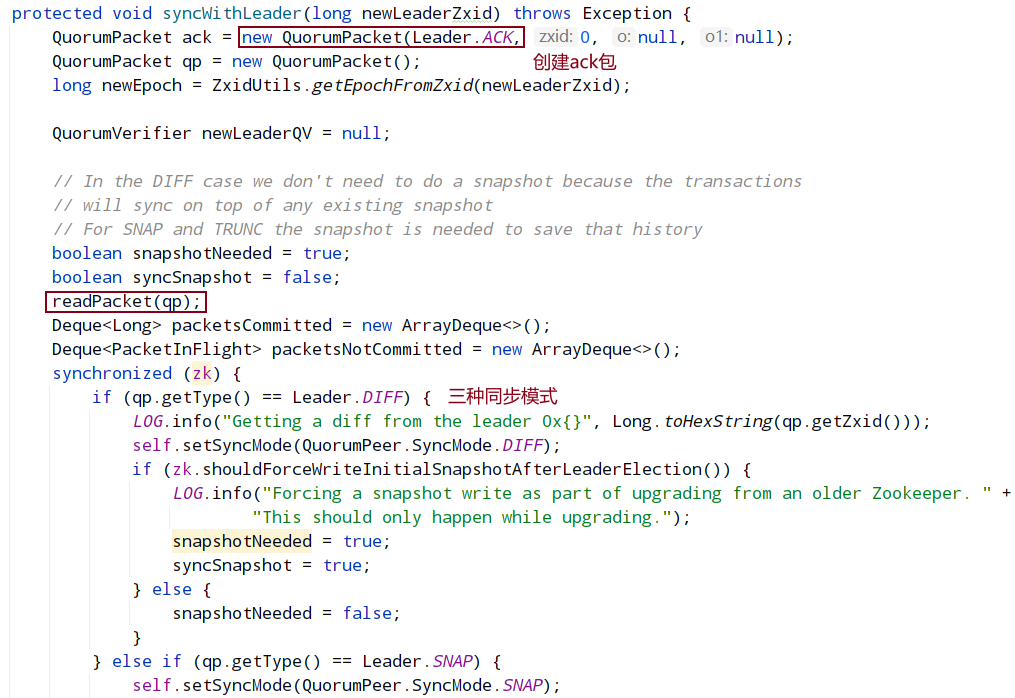
syncWithLeader:

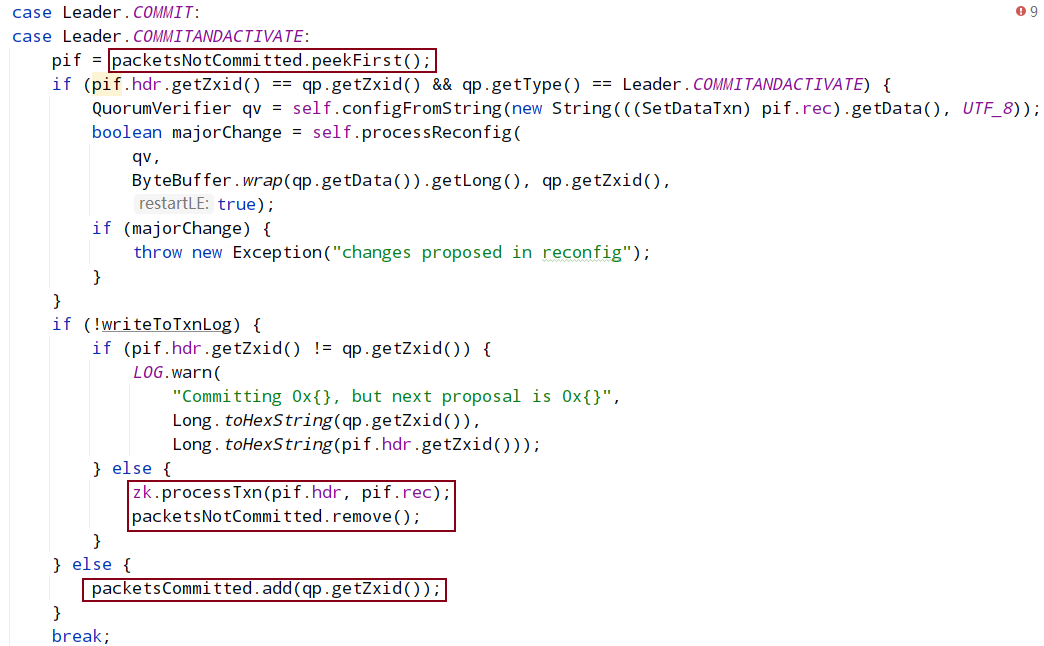
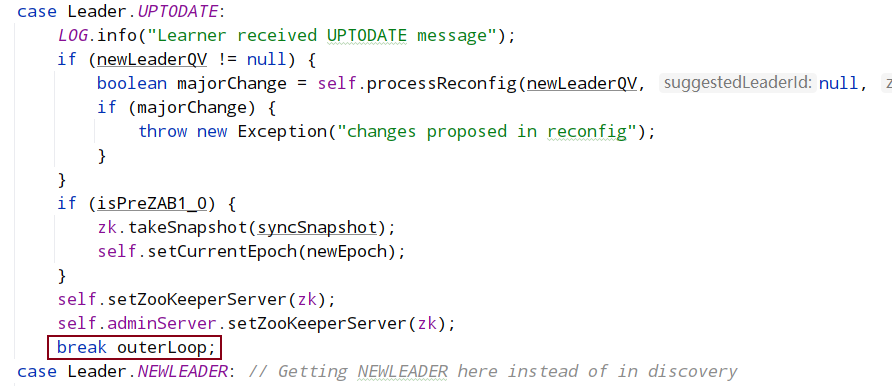
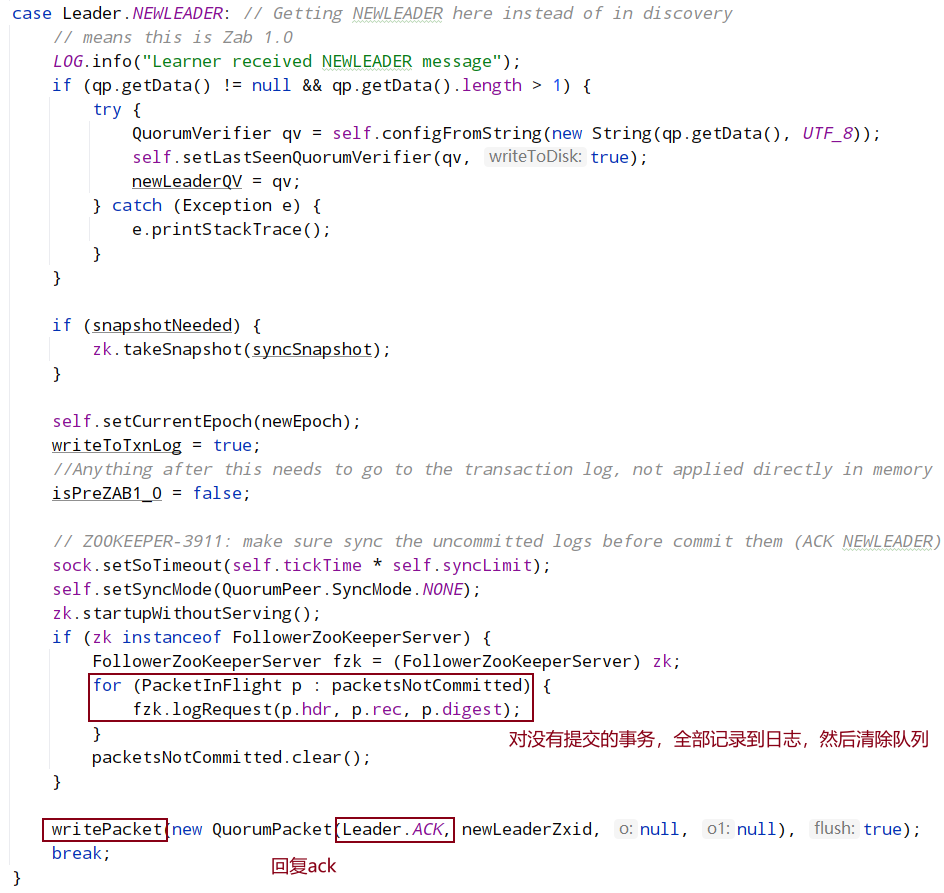
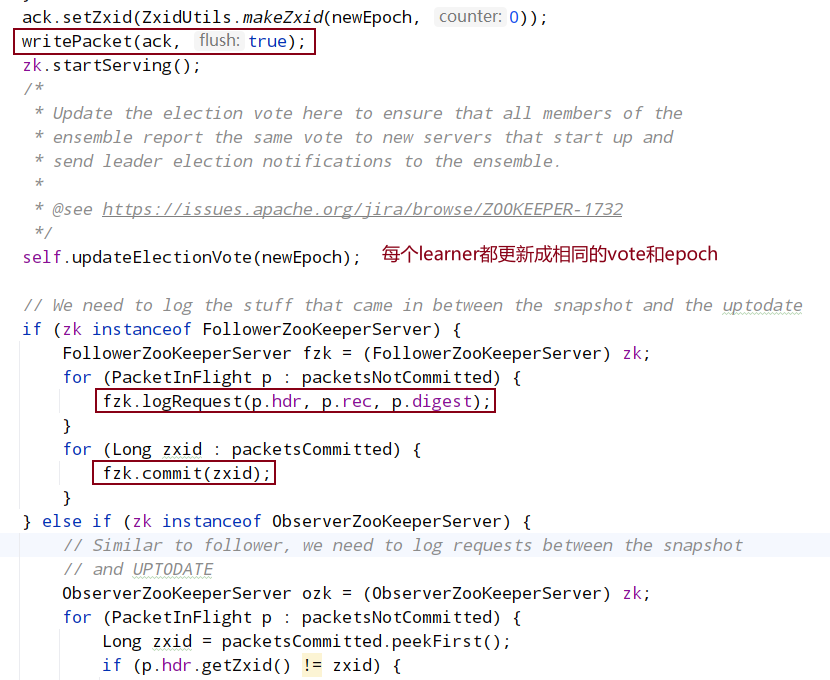
followLeader中的:
8.2.3 LEADING状态逻辑
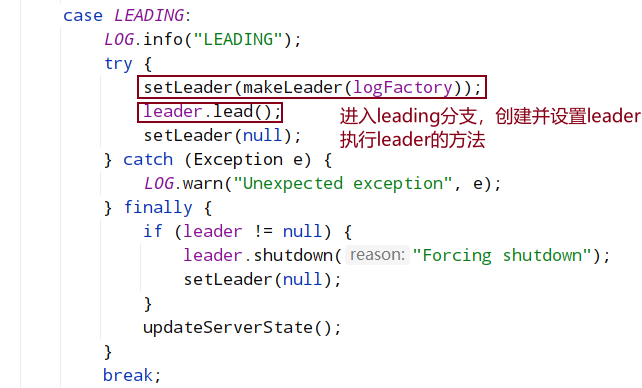
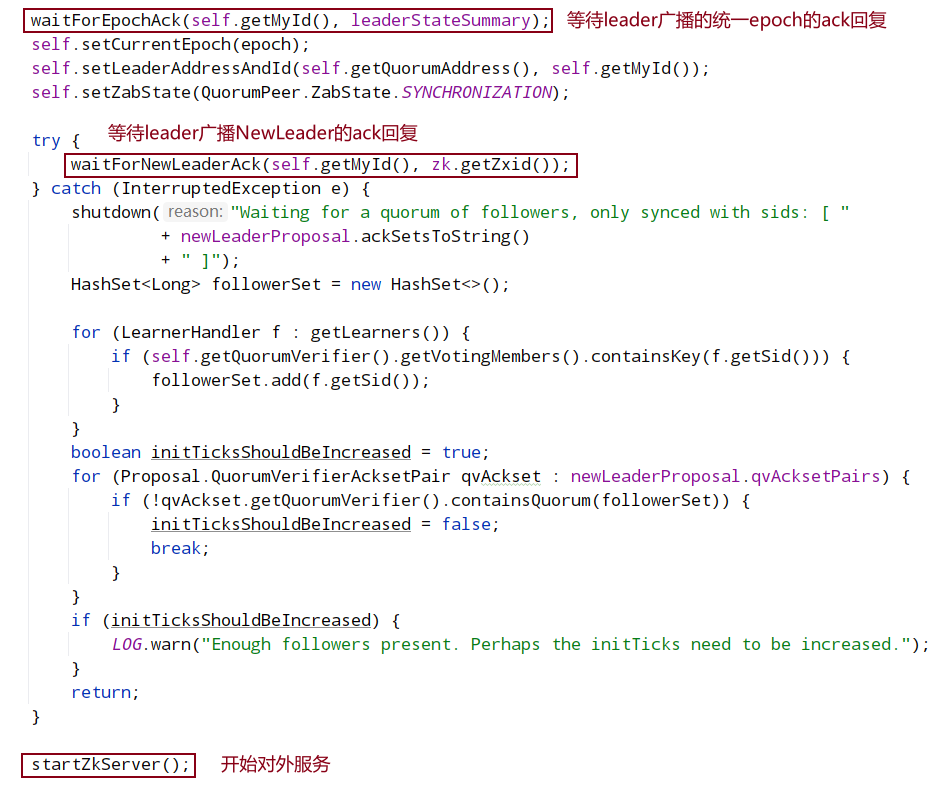
对于 Follower 和 Observer 而言,主要的初始化工作是要建立与 Leader 的连接并同步 epoch 信息,最后完成与 Leader 的数据同步。而 Leader 会启动 LearnerCnxAcceptor 线程,该线程会接受来自 Follower 和 Observer(统称为 Learner)的连接请求并为每个连接创建一个 LearnerHandler 线程,该线程会负责包括数据同步在内的与 learner 的一切通信。learnerHandler执行数据包的发送,会有个queuedPackets队列,执行sendPackets循环将数据包出队发送。
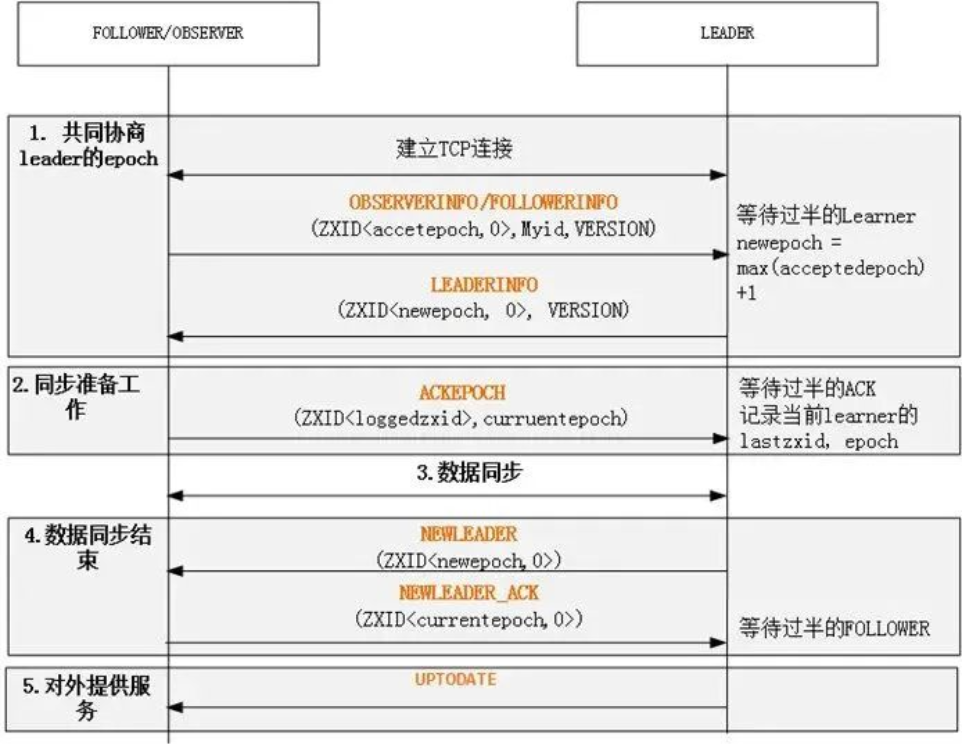
Learner(Follower 或 Observer)节点会主动向 Leader 发起连接,ZooKeeper 就会进入集群同步阶段,集群同步主要完成集群中各节点状态信息和数据信息的一致。选出新的 Leader 后的流程大致分为:计算 epoch、统一 epoch、同步数据、广播模式等四个阶段。其中其前三个阶段:计算 epoch、统一 epoch、同步数据就是这一节主要介绍的集群同步阶段的主要内容,这三个阶段主要完成新 Leader 与集群中的节点完成同步工作,处于这个阶段的 zk 集群还没有真正做好对外提供服务的能力,可以看着是新 leader 上任后进行的内部沟通、前期准备工作等,只有等这三个阶段全部完成,新 leader 才会真正的成为 leader,这时 zk 集群会恢复正常可运行状态并对外提供服务。
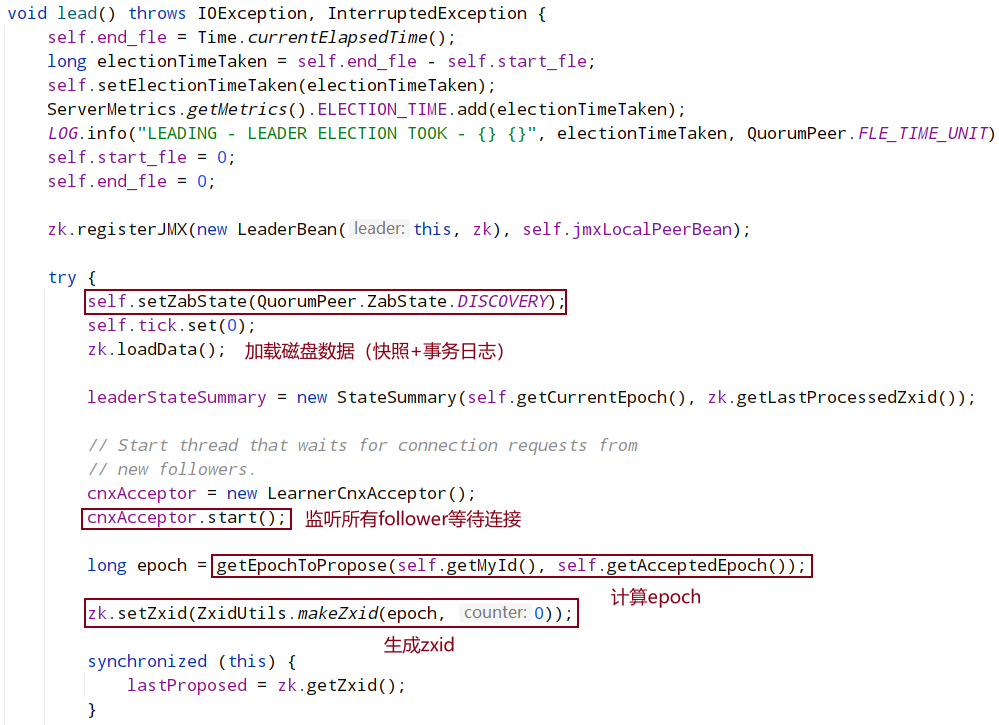
lead方法的流程:
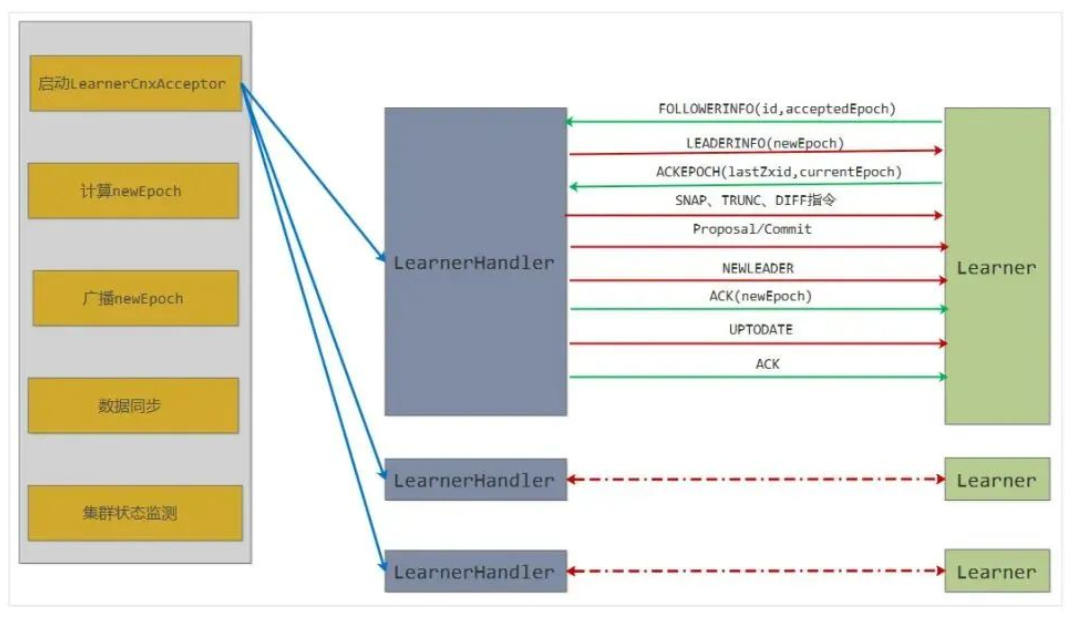
eader 分支大致可以分为 5 个阶段:启动 LearnerCnxAcceptor 线程、计算 newEpoch、广播 newEpoch、数据同步和集群状态监测。
Leader.lead()方法控制着 Leader 角色节点的主体流程,其实现较为简单,大致模式都是通过阻塞方法阻塞当前线程,直到该阶段完成 Leader 线程才会被唤醒继续执行下一个阶段;而每个阶段实现的具体细节及大量的网络 IO 操作等都在 LearnerHandler 中实现。比如计算 newEpoch,Leader 中只会判断 newEpoch 计算完成没,没有计算完成就会进入阻塞状态挂起当前 Leader 线程,直到集群中一半以上的节点同步了 epoch 信息后 newEpoch 正式产生才会唤醒 Leader 线程继续向下执行;而计算 newEpoch 会涉及到 Leader 去收集集群中大部分 Learner 服务器的 epoch 信息,会涉及到大量的网络 IO 通信等内容,这些细节部分都在 LearnerHandler 中实现。
配置中“server.0=10.80.8.3:2888:2999”这里的 2999 就是集群选举端口,2888就是集群同步端口;
启动 LearnerCnxAcceptor 线程
Leader 首先会启动一个 LearnerCnxAcceptor 线程,这个线程不停的循环 accept 接收 Learner 端的网络请求(这里的监听端口就是上面说的同步监听端口,而不是选举端口),Leader 选举结束后被分配为 Follower 或 Observer 角色的节点会主动向 Leader 发起连接,Leader 端接收到一个网络连接就会封装成一个 LearnerHandler 线程。
Leader 类可以看成一个总管,和每个 Learner 服务器的交互任务都会被分派给 LearnerHandler 这个助手完成,当 Leader 检测到一个任务被一半以上的 LearnerHandler 处理完成,即认为该阶段结束,进入下一个阶段。
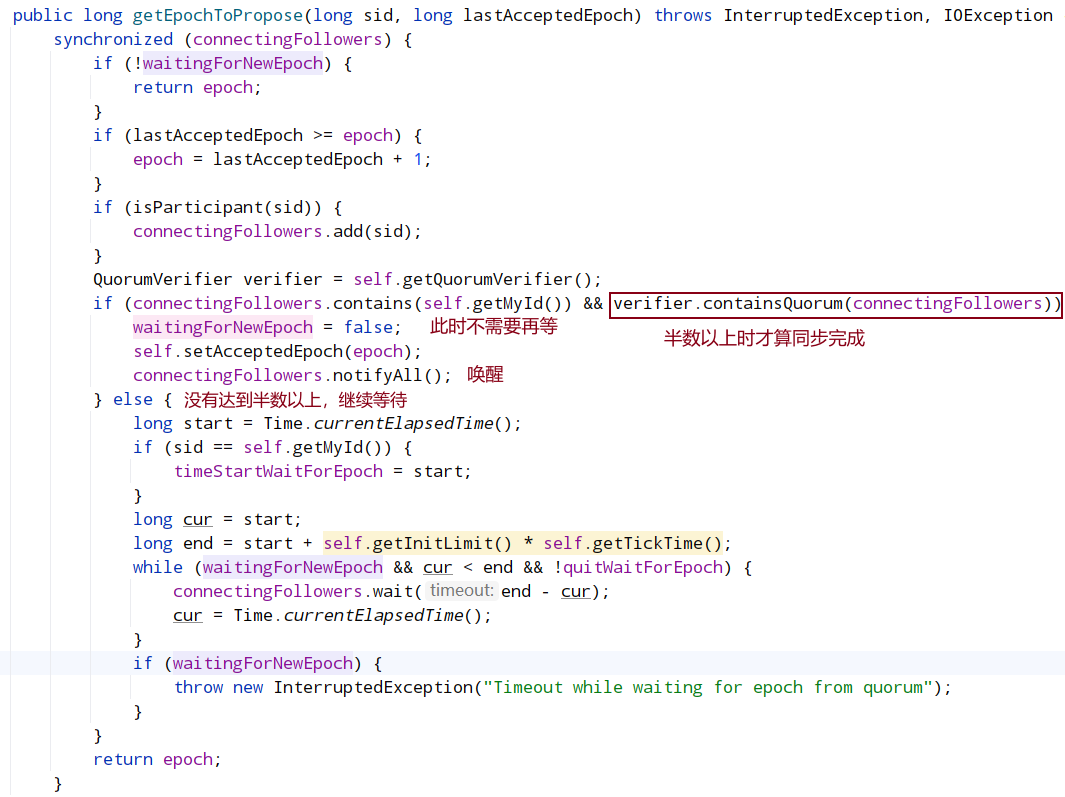
计算 epoch
epoch 在 ZooKeeper 中是一个很重要的概念,前面也介绍过了:epoch 就相当于 Leader 的身份编号,就如同身份证编号一样,每次选举产生一个新 Leader 时,都会为该 Leader 重新计算出一个新 epoch。epoch 被设计成一个递增值,比如上一个 Leader 的 epoch 是 1,假如重新选举新的 Leader 就会被分配 epoch+1。
epoch 作用:可以防止旧 Leader 活过来后继续广播之前旧提议造成状态不一致问题,只有当前 Leader 的提议才会被 Follower 处理。ZooKeeper 集群所有的事务请求操作都要提交由 Leader 服务器完成,Leader 服务器将事务请求转成一个提议(Proposal)并分配一个事务 ID(zxid)后广播给 Learner,zxid 就是由 epoch 和 counter(递增)组成,当存在旧 leader 向 follower 发送命令的时候,follower 发现 zxid 所在的 epoch 比当前的小,则直接拒绝,防止出现不一致性。
统一 epoch
newEpoch 计算完成后,该值只有 Leader 知道,现在需要将 newEpoch 广播到集群中所有的服务器节点上,让他们都更新下新 Leader 的 epoch 信息,这样他们在处理请求时会根据 epoch 判断该请求是不是当前新 Leader 发出的,可以防止旧 Leader 活过来后继续广播之前旧提议造成状态不一致问题,只有当前 Leader 的提议才会被 Follower 处理。
总结:广播 newEpoch 流程也比较简单,就是将之前计算出来的 newEpoch 封装到 LEADERINFO 数据包中,然后广播到集群中的所有节点,同时会收到 ACKEPOCH 回复数据包,当集群中一半以上的节点进行了回复则可以认为 newEpoch 广播完成,则进入下一阶段。同样,为避免线程一直阻塞,休眠线程依然会被添加超时时间,超时后仍未完成则抛出 InterruptedException 异常重新进入 Leader 选举状态。
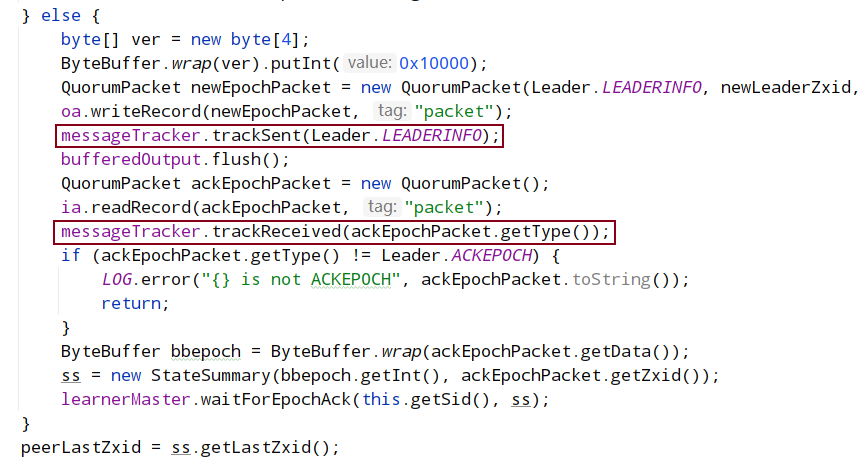
数据同步
之前分析过 Leader 的选举策略:lastZxid 越大越会被优先选为 Leader。lastZxid 是节点上最大的事务 ID,由于 zxid 是递增的,lastZxid 越大,则表示该节点处理的数据越新,即数据越完整。所以,被选为 Leader 的节点数据完整性越高,为了数据一致性,这时就需要其它节点和 Leader 进行数据同步保持数据一致性。
数据同步四种情况:
- DIFF,learner 比 leader 少一些数据;
- TRUNC,learner 数据比 leader 多;
- DIFF+TRUNC,learner 对 leader 多数据又少数据;
- SNAP,learner 比 leader 少很多数据。
8.3 请求处理器
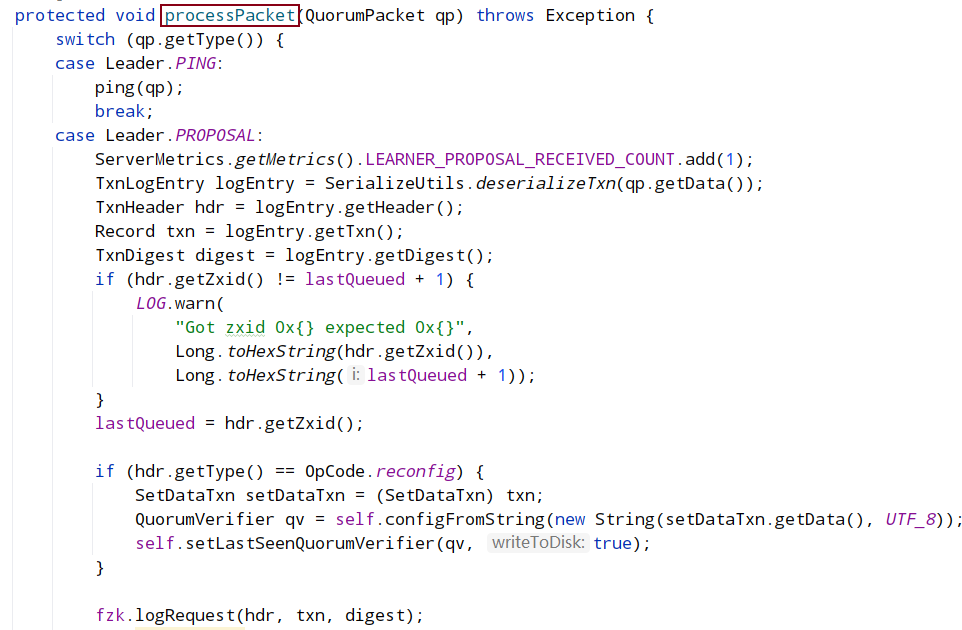
请求处理器是对处理流水线上不同阶段的抽象,每个服务器在初始化时实现一个请求处理器的序列。对于请求处理器,ZooKeeper 代码里有一个叫 RequestProcessor 的接口,这个接口的主要方法是processRequest,它接受一个 Request 参数,在一个请求处理器的流水线中,对于相邻处理器的请求的处理是通过队列实现解耦合。当一个处理器有一条请求需要下一个处理器进行处理时,它将这条请求加入队列中。然后,它将处于等待状态直到下一个处理器处理完此消息。本节主要看看各个服务器的请求处理器序列初始化和对队列的使用与处理,处理器的细节可以参考源码。
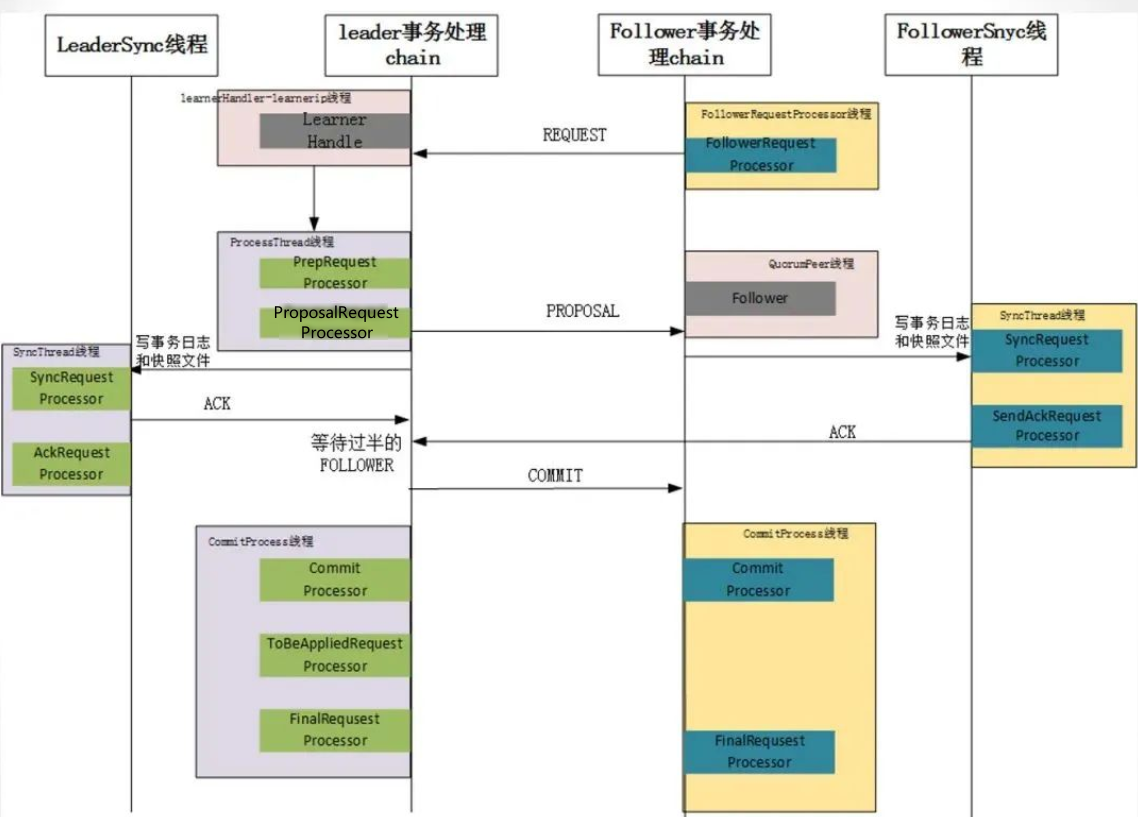
8.3.1 leader的请求处理器
leader.lead() —— startZkServer() —— zk.startup() —— ZooKeeper.startupWithServerState(State.RUNNING) —— setupRequestProcessors()
LeaderZooKeeperServer:
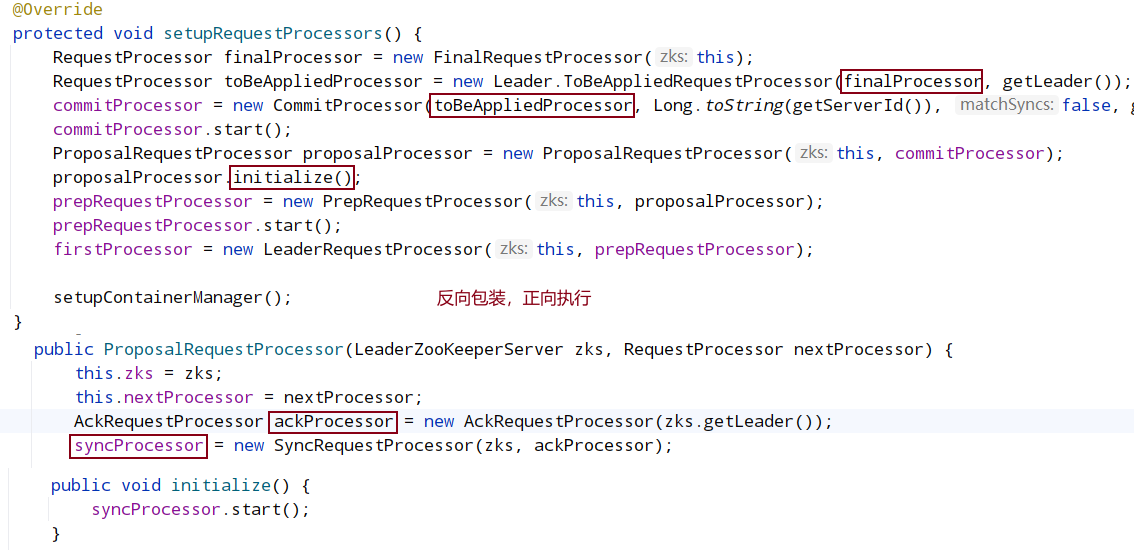

CommitProcessor.run:
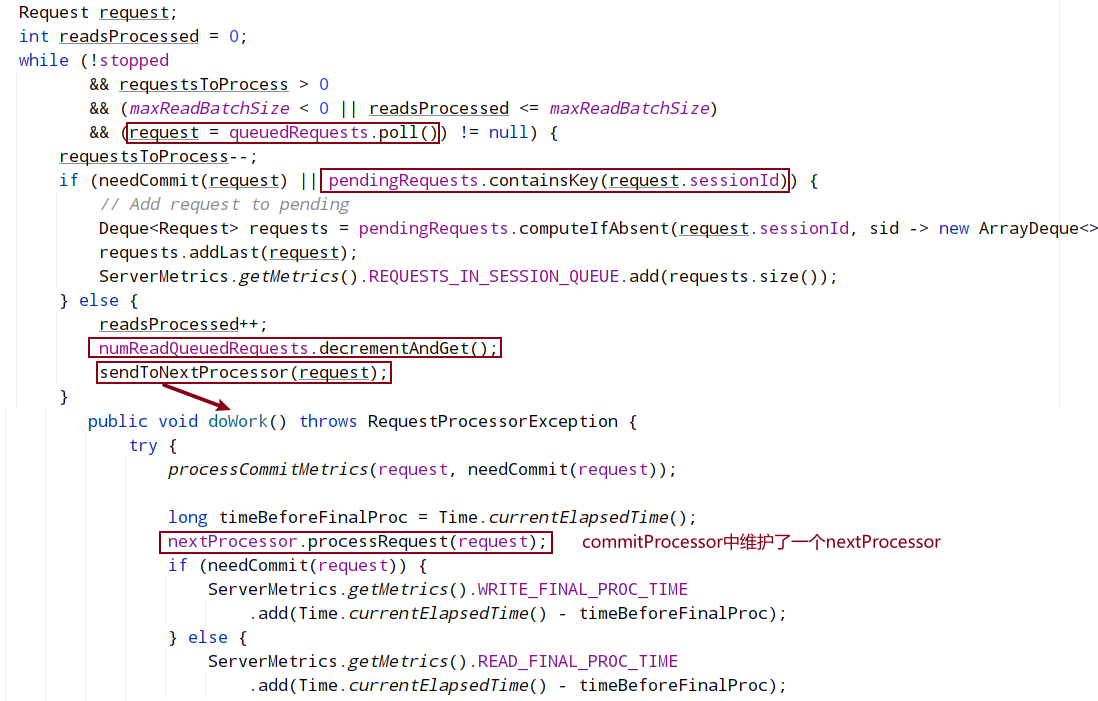
除了finalProcessor,每个processor都会存一个next指向下一个处理器

8.3.2 follower的请求处理器
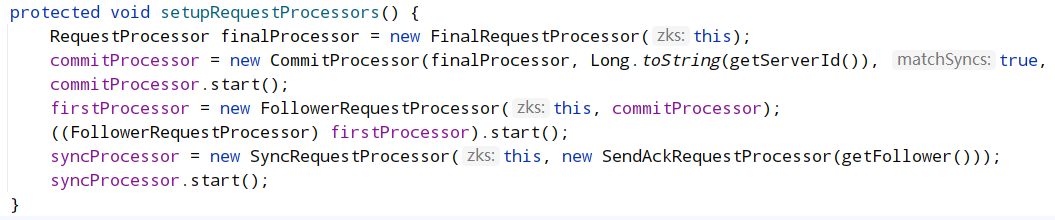
8.3.3 observer的请求处理器

9 客户端启动流程
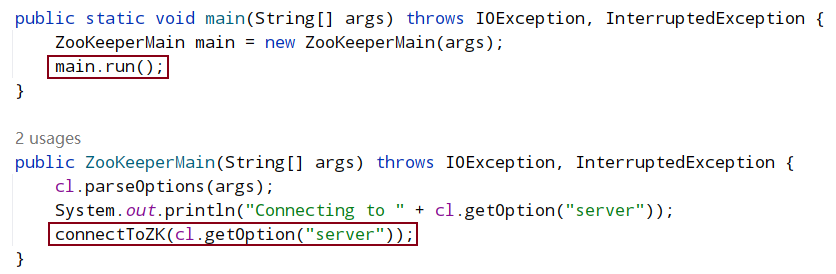
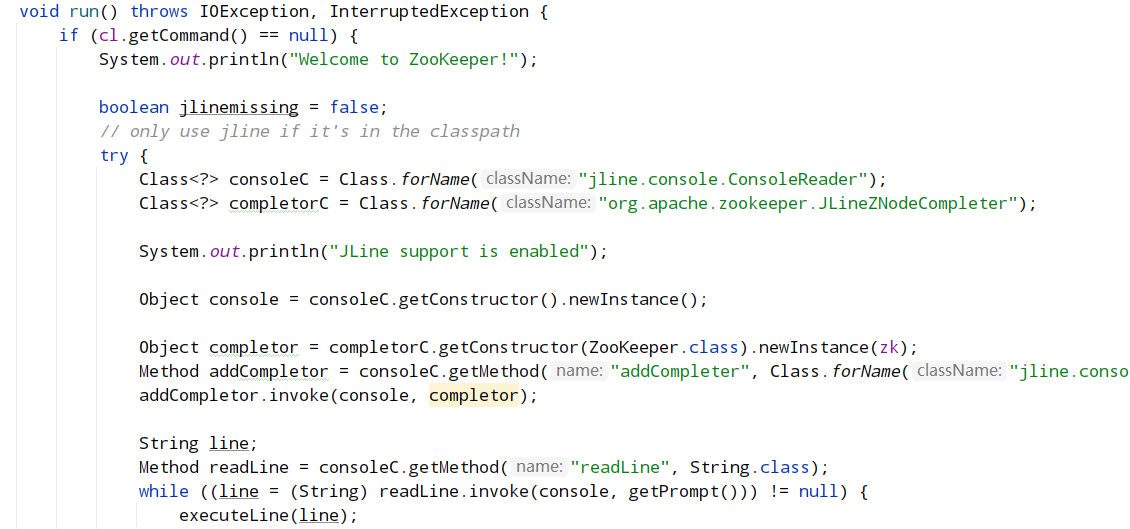
从整体看,客户端启动的入口时 ZooKeeperMain,在 ZooKeeperMain 的 run()中,创建出控制台输入对象(jline.console.ConsoleReader),然后它进入 while 循环,等待用户的输入。同时也调用 connectToZK 连接服务器并建立会话(session),在 connect 时创建 ZooKeeper 对象,在 ZooKeeper 的构造函数中会创建客户端使用的 NIO socket,并启动两个工作线程 sendThread 和 eventThread,两个线程被初始化为守护线程。
sendThread 的 run()是一个无限循环,除非运到了 close 的条件,否则他就会一直循环下去,比如向服务端发送心跳,或者向服务端发送我们在控制台输入的数据以及接受服务端发送过来的响应。
eventThread 线程负责队列事件和处理 watch。
客户端也会创建一个 clientCnxn,由 ClientCnxnSocketNIO.java 负责 IO 数据通信。
客户端入口方法:ZookeeperMain.main()
ZooKeeperAdmin继承ZooKeeper
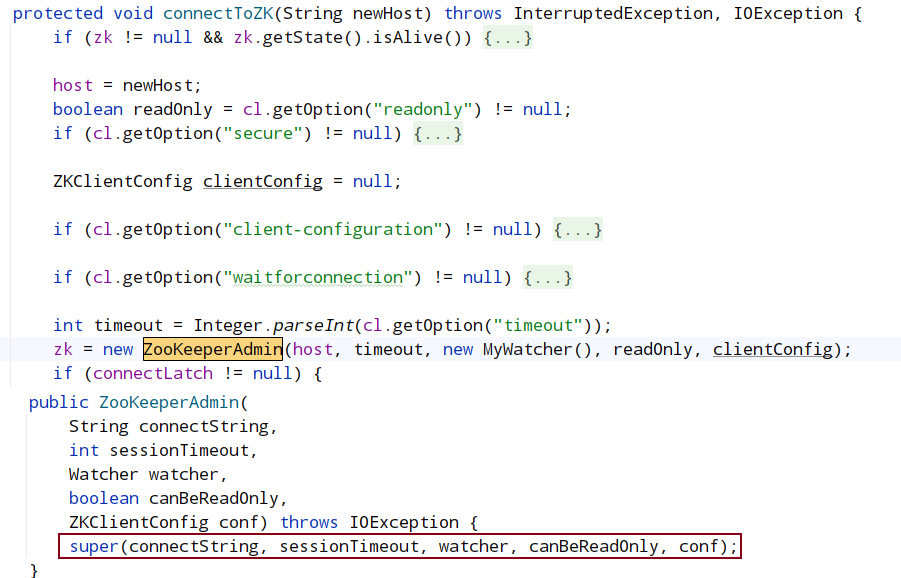
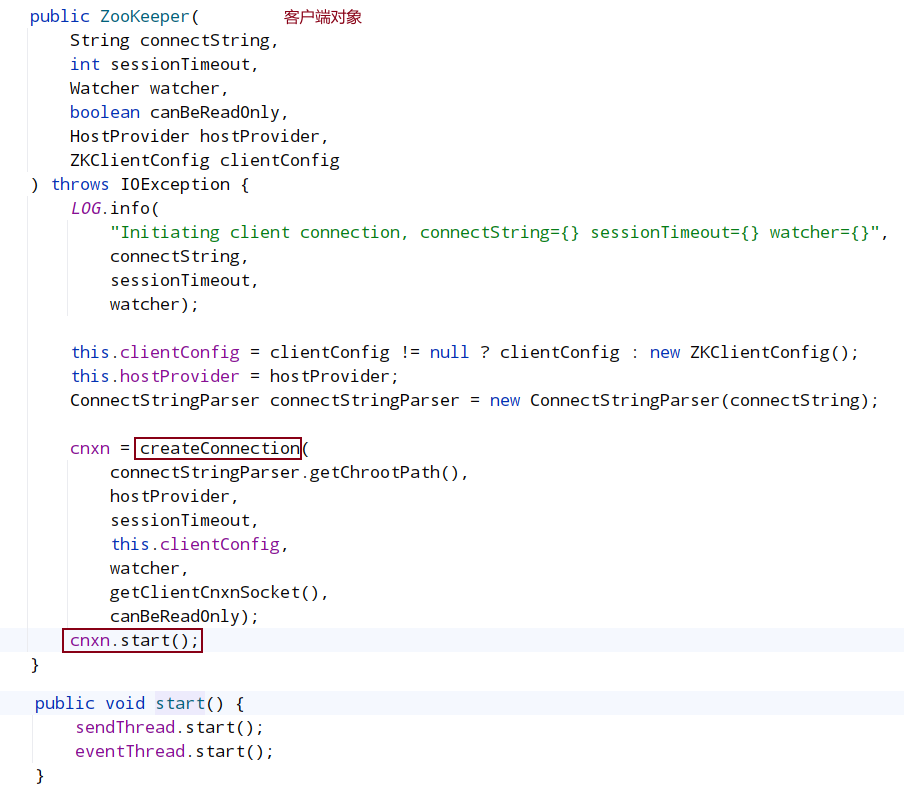
createConnection会返回一个ClientCnxn对象,ClientCnxn中有两个重要的数据结构:

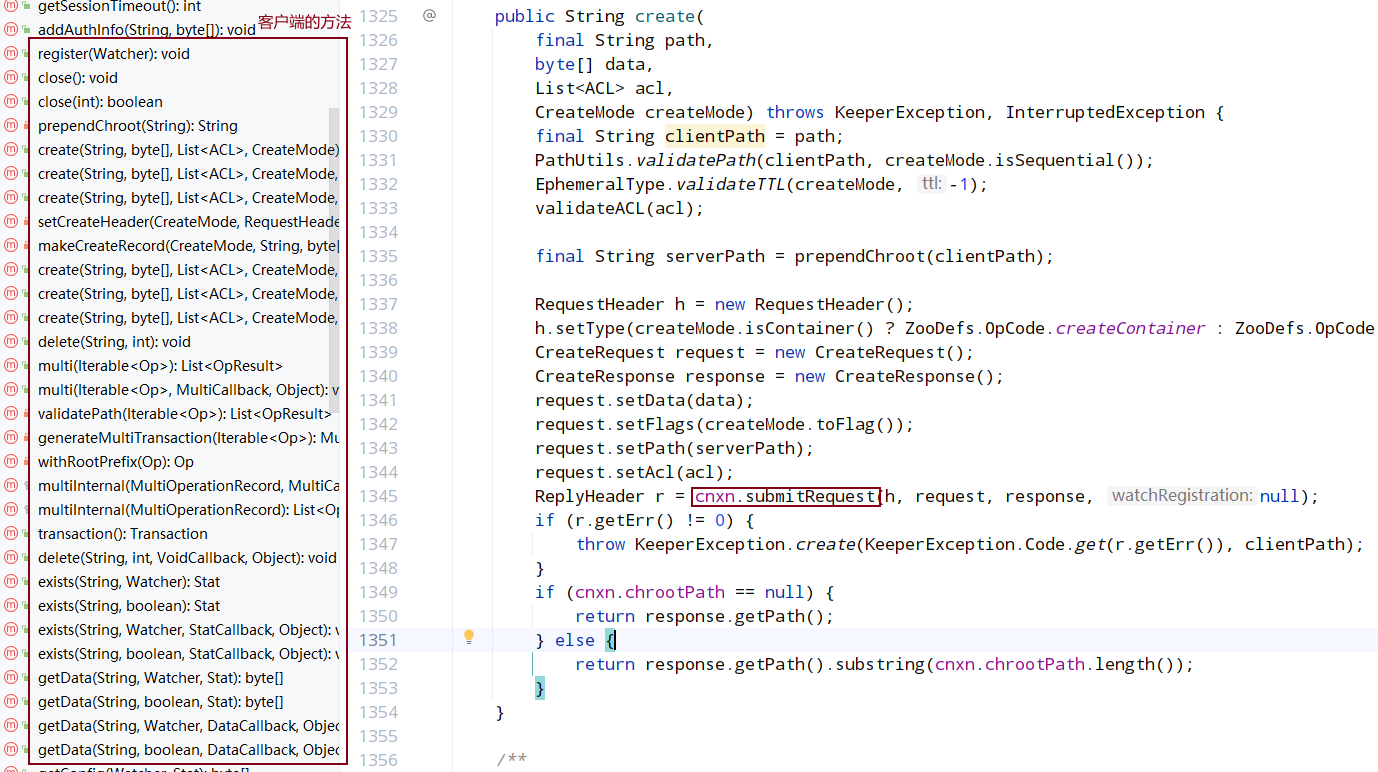
ZooKeeper 类会将用户的输入参数转换为对 ZK 操作,调用 cnxn.submitRequest()提交请求,在 ClientCnxn 中会把请求封装为 Packet 并写入 outgoingQueue,待 sendThread 线程消费发送给服务端,调用 cnxn.submitRequest()会阻塞,其中客户端等待是自旋锁。
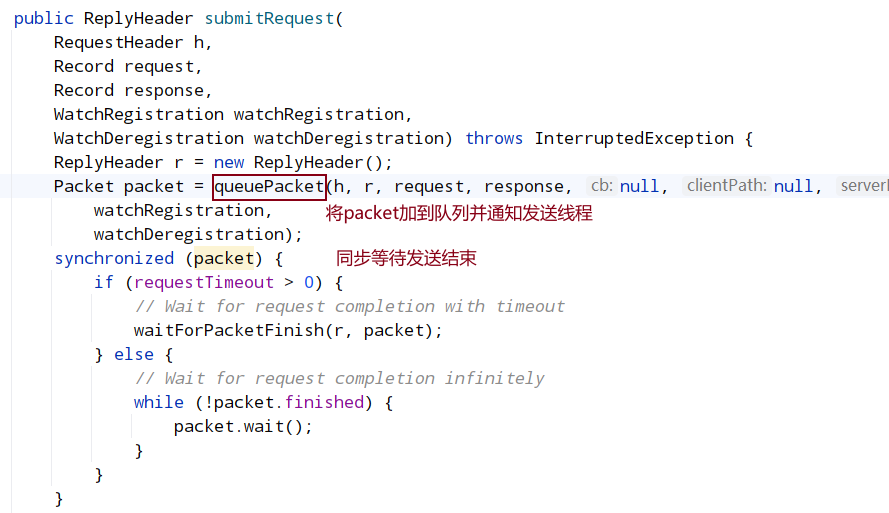
发送线程ClientCnxn.SendThread#run中,会循环执行doTransport
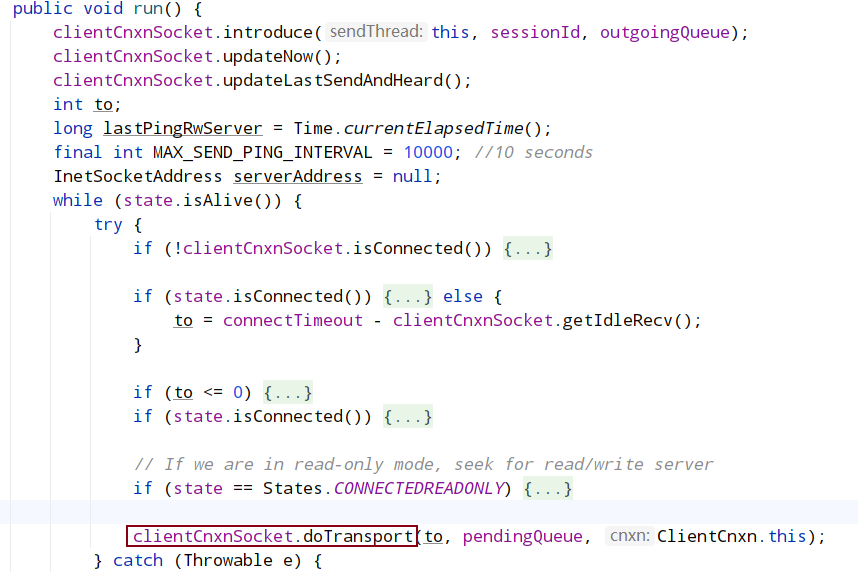
其实现ClientCnxnSocketNIO.doTransport 调用 dcIO()
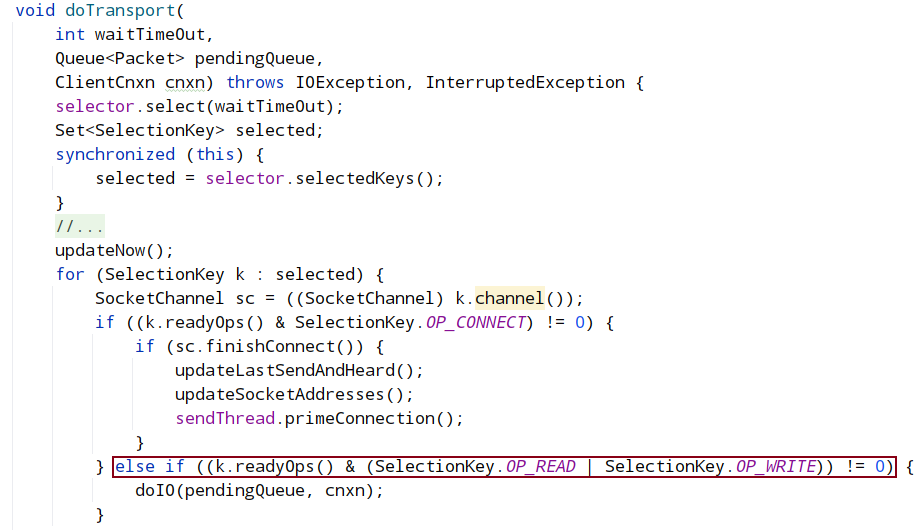
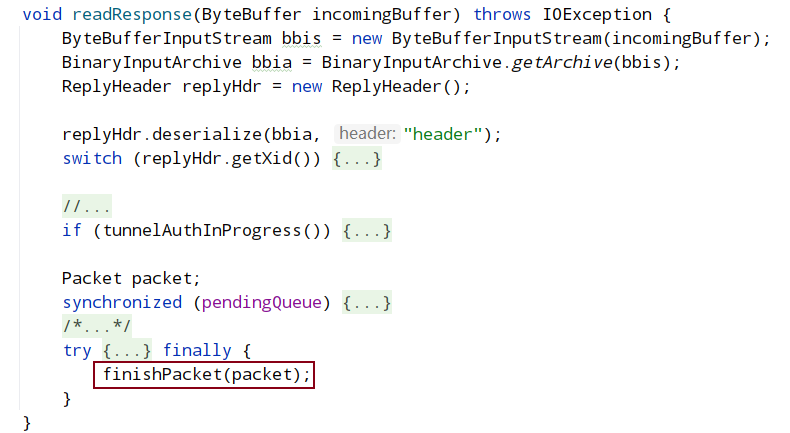
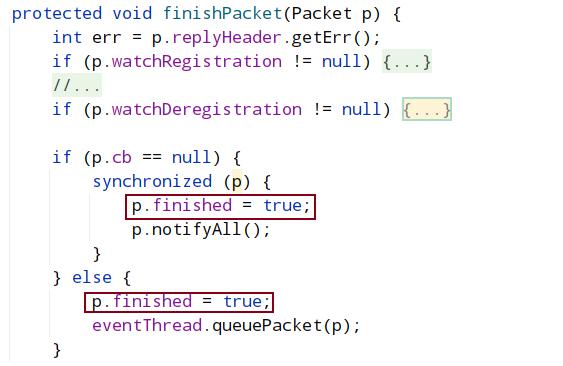
isReadable 逻辑中,会调用 sendThread.readResponse(), 在 sendThread.readResponse()函数中的 finally 中调用 finshPacket()设置 finished 为 true,进而客户端阻塞解除,返回读取结果。
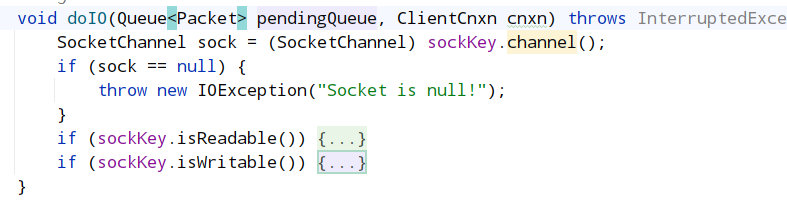
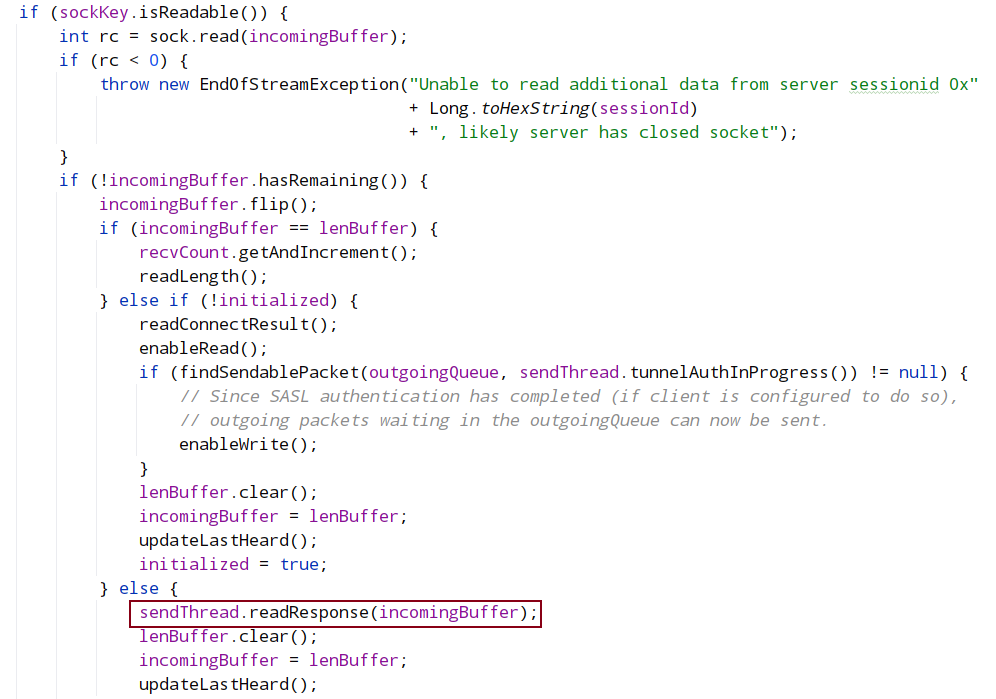
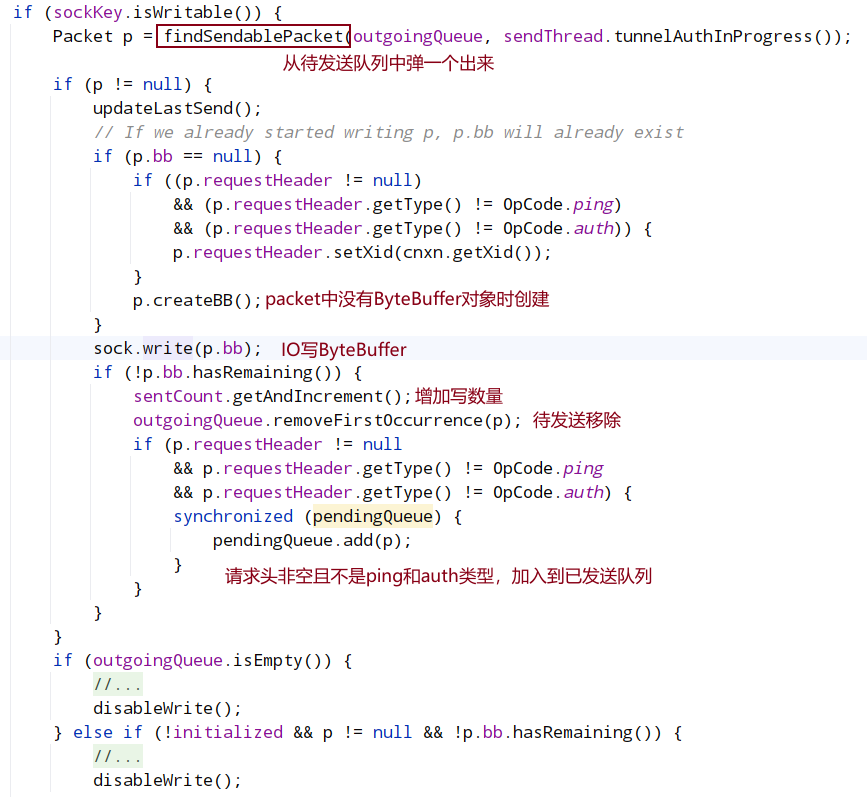
在doIO处理时,会根据 sockKey 判断客户端发出的读操作还是写操作,对于写操作
sun.nio.ch.SocketChannelImpl#write(java.nio.ByteBuffer):
10 服务端和客户端结合部分
10.1 会话(Session)
Client 建立会话的流程如下,
- 服务端启动,客户端启动;
- 客户端发起 socket 连接;
- 服务端 accept socket 连接,socket 连接建立;
- 客户端发送 ConnectRequest 给 server;
- server 收到后初始化 ServerCnxn,代表一个和客户端的连接,即 session,server 发送 ConnectResponse 给 client;
- client 处理 ConnectResponse,session 建立完成。
10.1.1 客户端
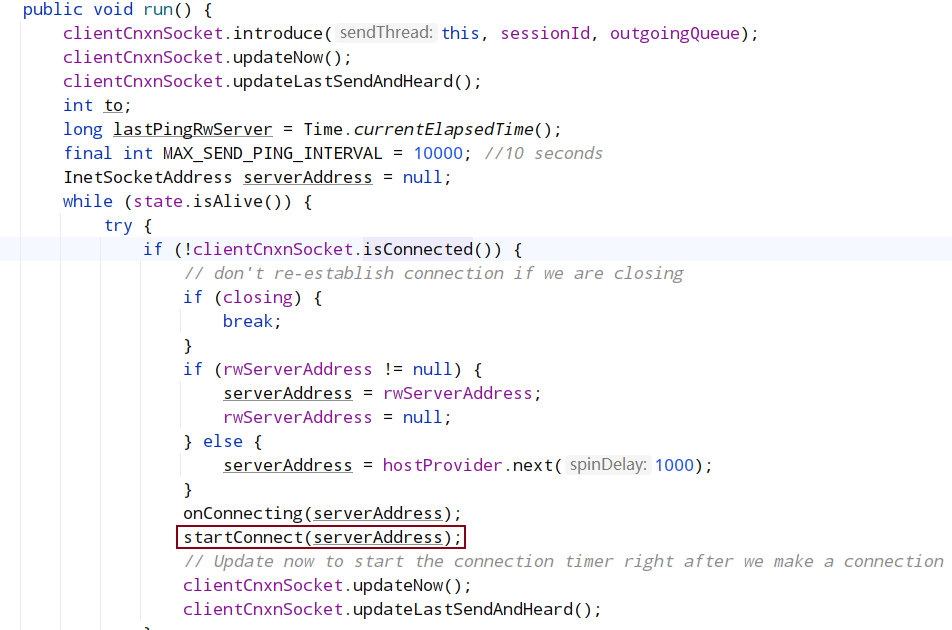
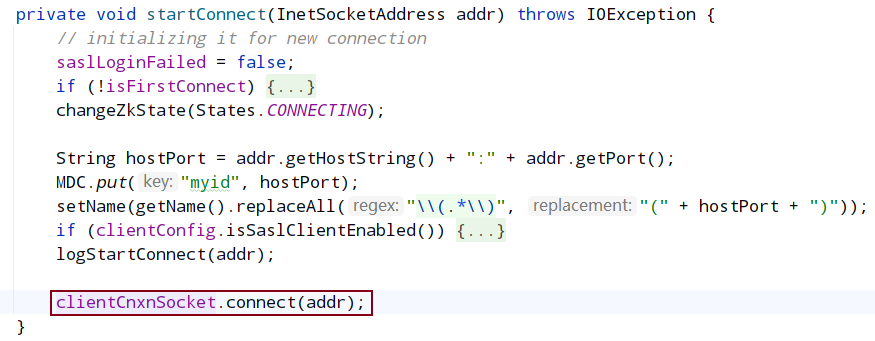
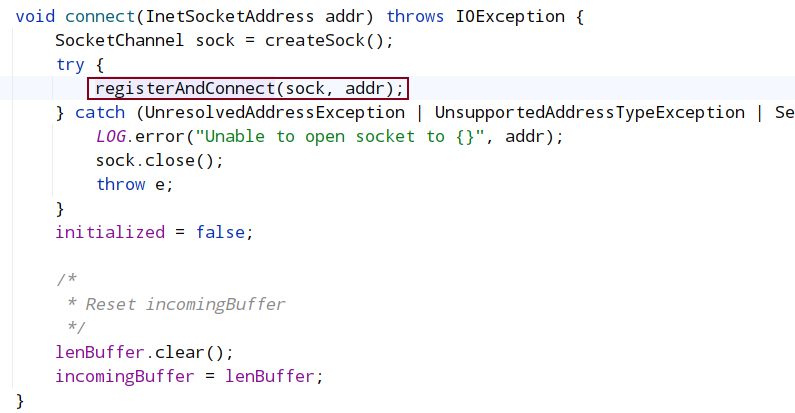
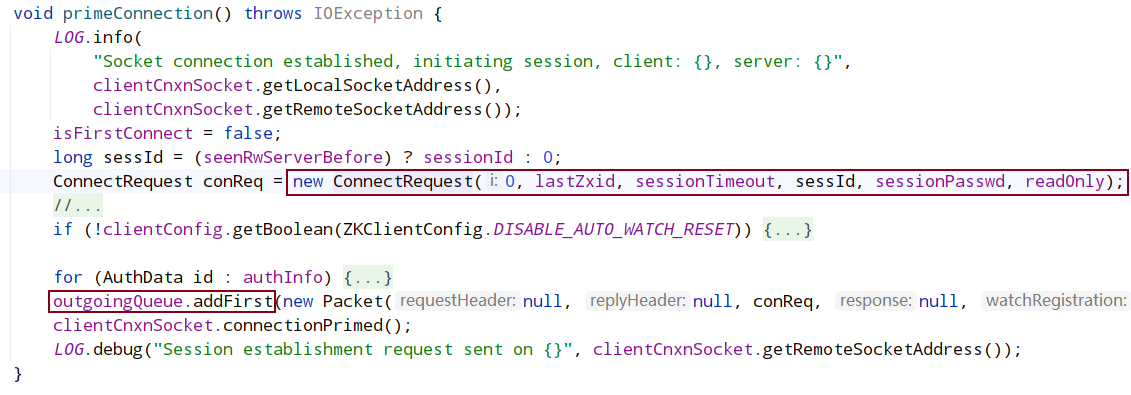
在 clientCnxn.java 中,run 是一个 while 循环,只要 client 没有被关闭会一直循环,每次循环判断当前 client 是否连接到 server,如果没有则发起连接,发起连接调用了 startConnect。

 10.1.2 服务端
10.1.2 服务端
server 在启动后,会暴露给客户端连接的地址和端口以提供服务。先看一下NIOServerCnxnFactory,主要是启动三个线程。
- AcceptThread:用于接收 client 的连接请求,建立连接后交给 SelectorThread 线程处理
- SelectorThread:用于处理读写请求
- ConnectionExpirerThread:检查 session 连接是否过期
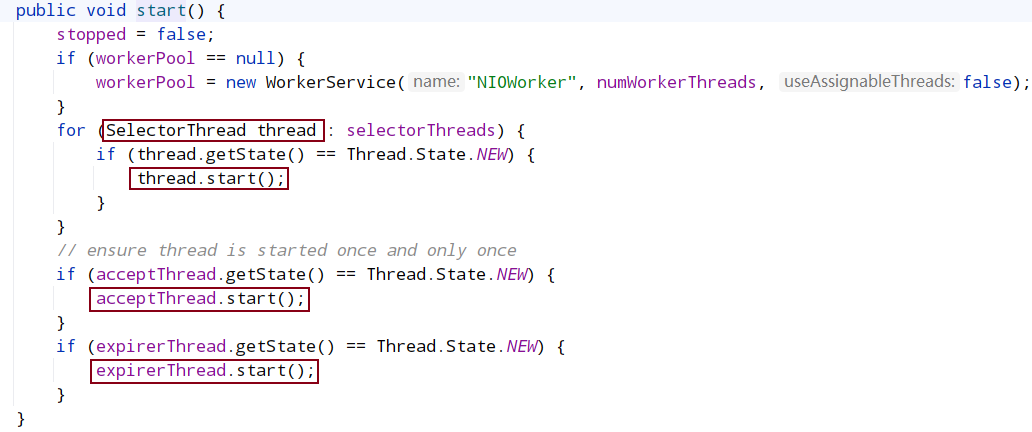
client 发起 socket 连接的时候,server 监听了该端口,AcceptThread 接收到 client 的连接请求,然后把建立连接的 SocketChannel 放入队列里面,交给 SelectorThread 处理。
SelectorThread 是一个不断循环的线程,每次循环都会处理刚刚建立的 socket 连接。
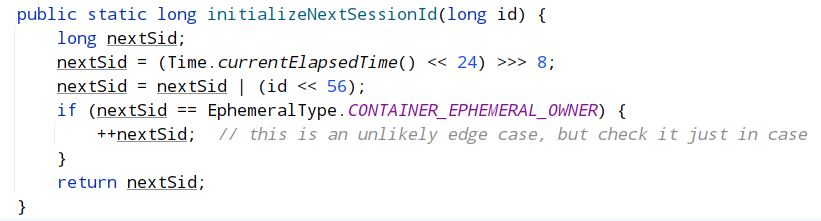
session生成算法:
10.2 监视器(Watcher)
ZooKeeper 可以定义不同类型的通知,如监控 znode 的数据变化,监控 znode 子节点的变化,监控 znode 的创建或者删除。ZooKeeper 的服务端实现了监视点管理器(watch manager)。
一个 WatchManager 类的实例负责管理当前已经注册的监视点列表,并负责触发他们,监视点只会存在内存且为本地服务端的概念,所有类型的服务器都是使用同样的方式处理监控点。
DataTree 类中持有一个监视点管理器来负责子节点监控和数据的监控。
在服务端触发一个监视点,最终会传播到客户端,负责处理传播的为服务端的 cnxn 对象(ServerCnxn 类),此对象表示客户端和服务端的连接并实现了 Watcher 接口。Watch.process 方法序列化了监视点事件为一定的格式,以便于网络传送。ZooKeeper 客户端接收序列化的监视点事件,并将其反序列化为监控点事件的对象,并传递给应用程序。
以getData为例说明
Watcher 接口的定义,如果设置了监视点,我们要实现 process 函数。
客户端watcher注册:
在客户端 GetData 时,如果注册 watch 监控点到服务端,在 watch 的 path 的 value 变化时,服务端会通知客户端该变化。
在客户端的 GetData 方法中(ZooKeeper 类的 GetData):
- 创建 WatchRegistration wcb= new DataWatchRegistration(watcher, clientPath),path 和 watch 封装进了一个对象;
- 创建一个 request,设置 type 、path、watch;
- request.setWatch(watcher != null),是否设置了watch。
- 调用 ClientCnxn.submitRequest(...) , 将请求包装为 Packet,queuePacket()方法的参数中存在创建的 path+watcher 的封装类 WatchRegistration,请求会被 sendThread 消费发送到服务端。
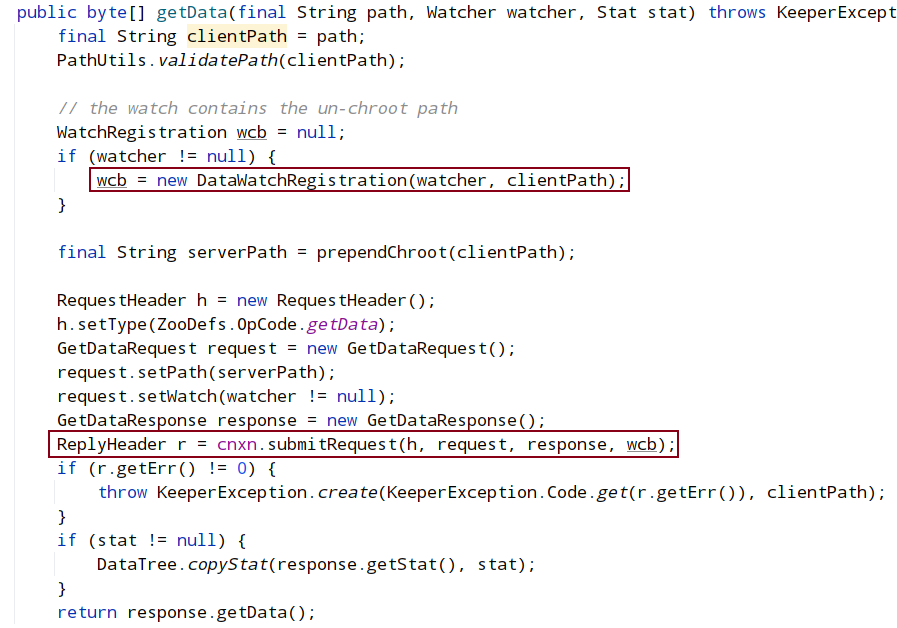
org.apache.zookeeper.ClientCnxn#submitRequest:
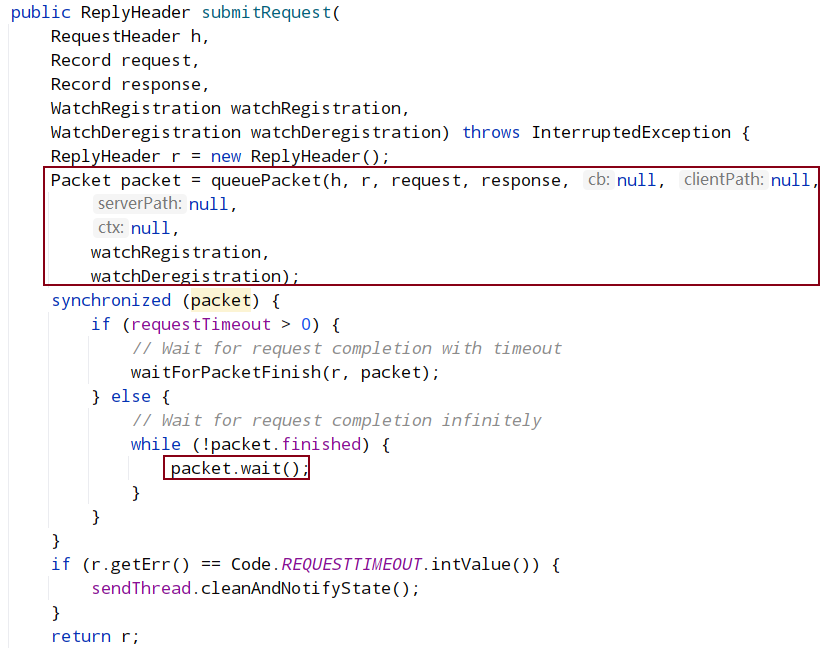
queuePacket方法就是创建Packet并赋值,然后将其加入待发送队列
在SendThread中会循环执行doTransport,也就是会循环执行到readResponse,其又会执行对应packet的finishPacket方法,在finishPacket中会注册watch,并且会置finished为true,使submitRequest方法停止阻塞
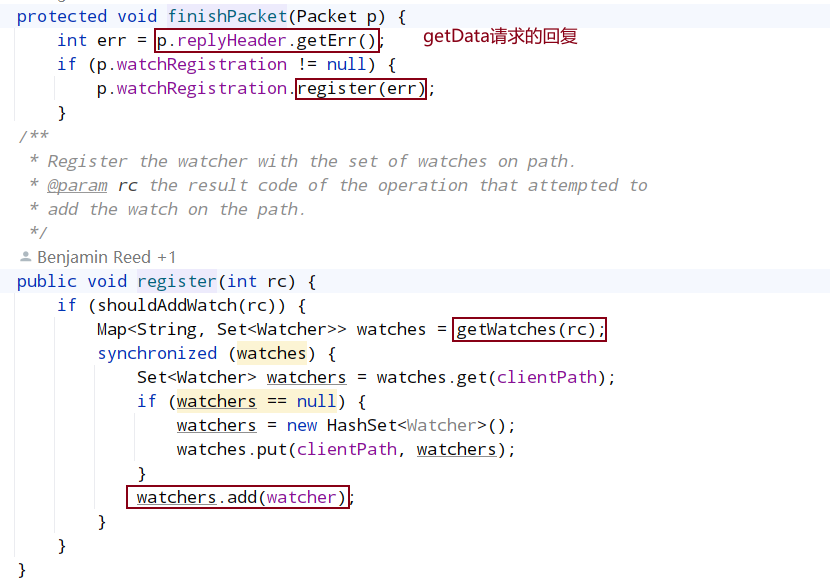
服务端watcher注册:
直接看 FinalRequestProcessor 处理器的 public void processRequest(Request request){}方法,看它针对 GetData()方式的请求做出了哪些动作。
zks.getZKDatabase().getData(getDataRequest.getPath(), stat, getDataRequest.getWatch() ? cnxn : null)
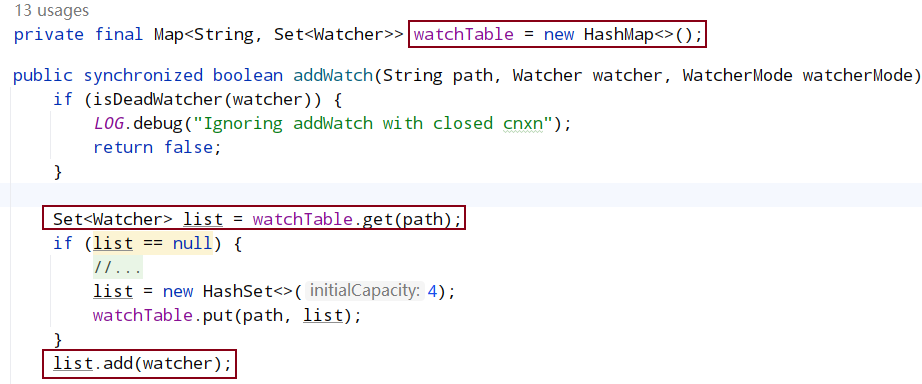
根据 watcher 的“有无”给服务端添加不同的 Watcher。服务端 GetData()函数,在服务端维护了一份 path+watcher 的 map,如果设置 watcher,服务端会保存该 path 的 watcher。
FinalRequestProcessor#processRequest:

ZKDatabase#getData:

DataTree#getData:
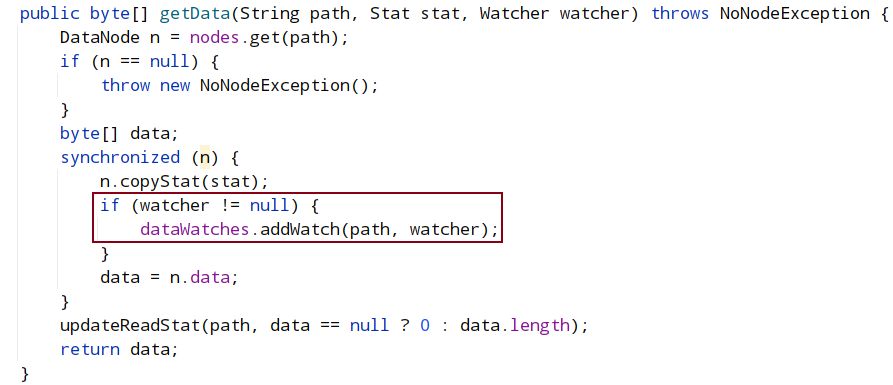
WatchManager#addWatch:
客户端watcher触发:
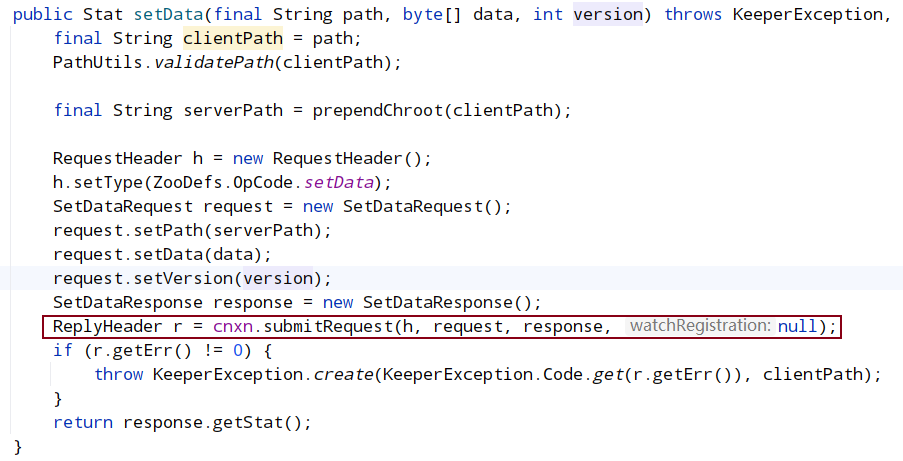
当在客户端输入set /path newValue时,会调用setData方法
服务端watcher触发:
从 SetData 的源码看,本次的 submitRequest 参数中,WatchRegistration=null,可以推断,服务端在 FinalRequestProcessor 中再处理时取出的 watcher=null,也就不会将 path+watcher 保存进 maptable 中,其他的处理过程和上面 GetData 类似。(因为getData也是在processRequest中将watch加入到maptable)
FinalRequestProcessor#processRequest:
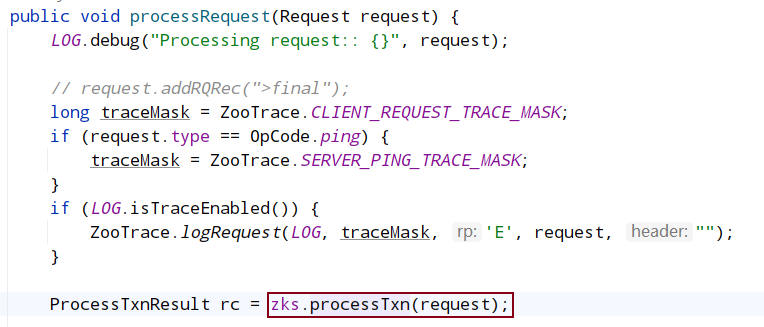
在服务端事务处理的processTxn方法中, 最终会调用到dataTree的processTxn方法,processTxn会将请求头的zxid,cxid,type,clientId原封不动的赋值给rc
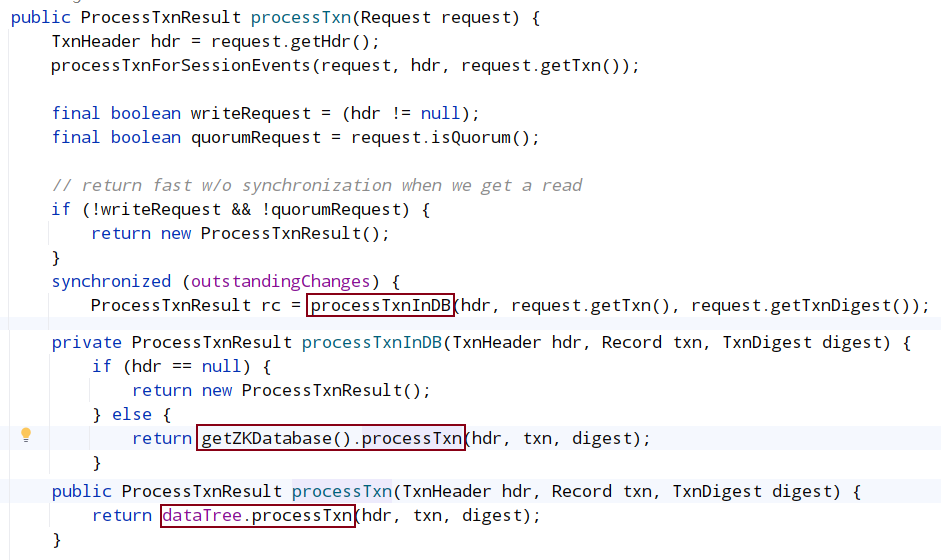
会调用到dataTree的SetData()函数,Set 数值后,会触发 watch 回调,即 triggerWatch()。
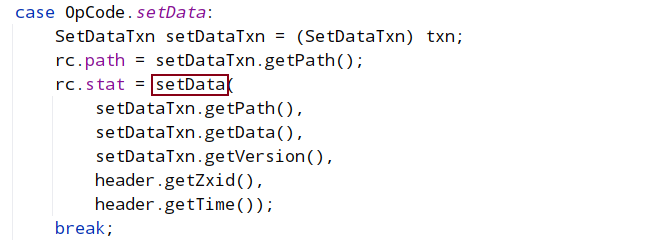
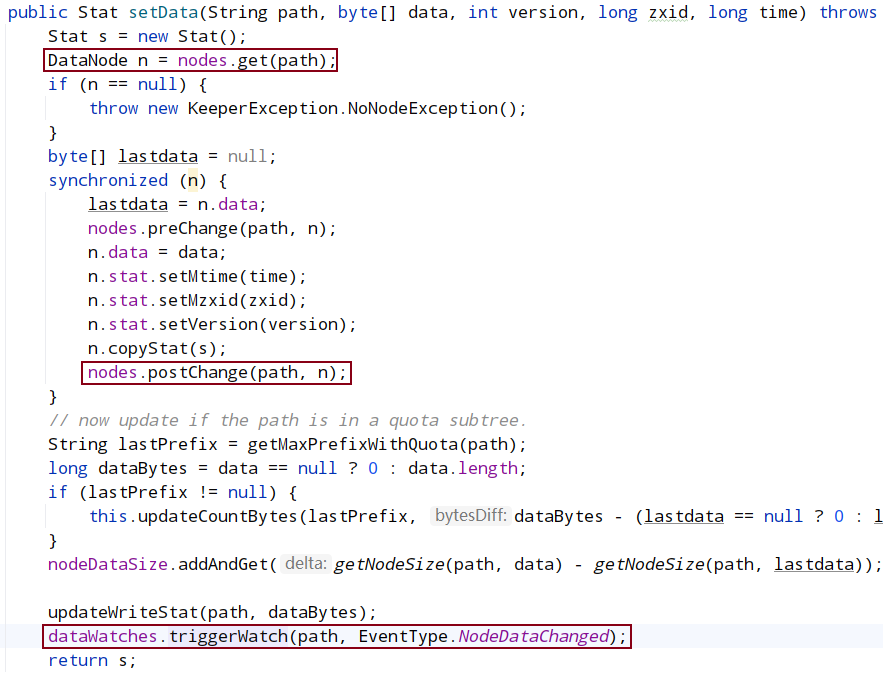
org.apache.zookeeper.server.watch.WatchManager#triggerWatch:


watcher的mode分为:STANDARD、PERSISTENT、PERSISTENT_RECURSIVE,默认为标准
从watchTable中取出path对应的watcher,并通过 cnxn 的 process()方法处理(NIOServerCnxn 类)通知到客户端。响应头设置为NOTIFICATION_XID,此处与客户端对应。
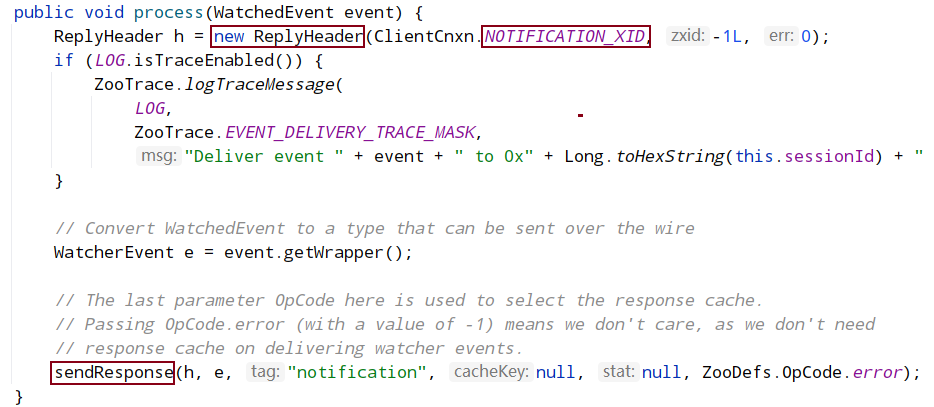
发送响应到客户端,触发服务端的watcher是手动发送响应,而不是加入到发送队列

客户端回调逻辑:
客户端使用 SendThread.readResponse() 方法来统一处理服务端的响应。
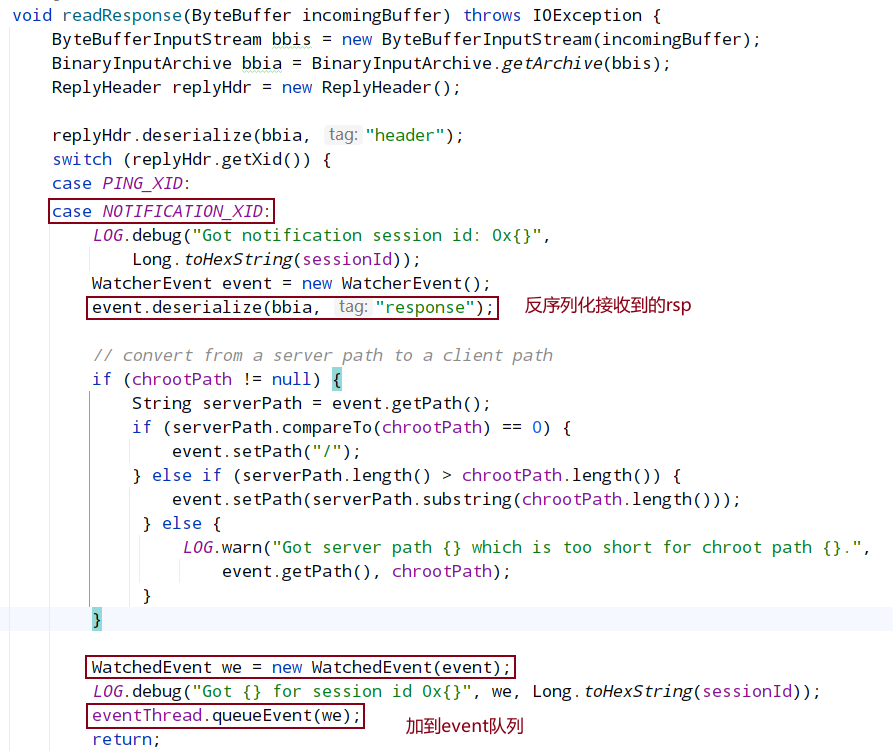
org.apache.zookeeper.ClientCnxn.EventThread#queueEvent:
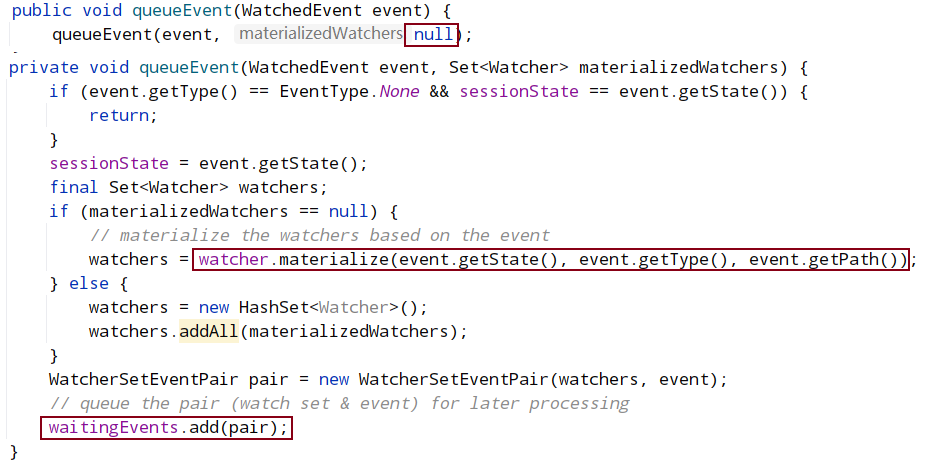
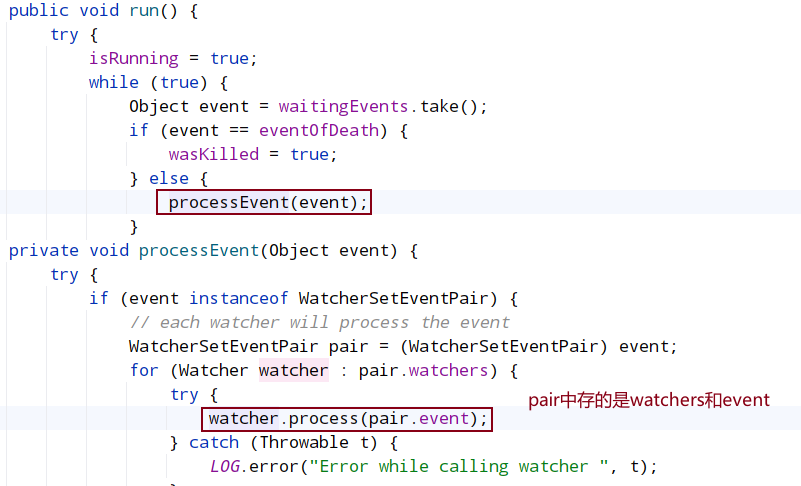
将查询到的Watcher存储到waitingEvents队列中,调用EventThread类中的run方法会循环取出在waitingEvents队列中等待的Watcher事件进行处理。
处理的过程就是调用watcher接口的process()接口:
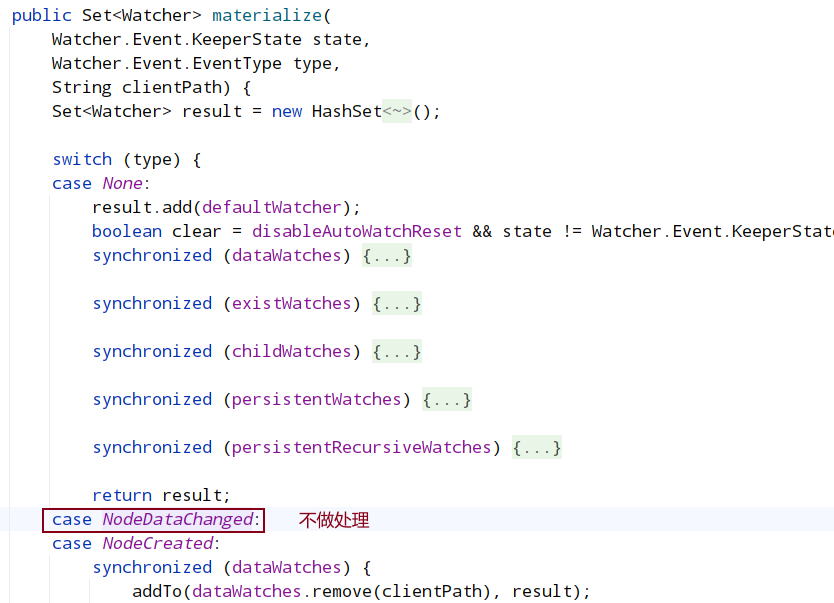
至此,zookeeper客户端和服务端的部分源码解读结束。
本博客内容仅供个人学习使用,禁止用于商业用途。转载需注明出处并链接至原文。
标签:请求,ZooKeeper,解读,源码,线程,服务器,Leader,服务端,客户端 From: https://www.cnblogs.com/zhaobo1997/p/18249543