Gewe 个微框架
GeWe(个微框架)是一个创新性的软件开发框架,专注于IPAD协议,为个人微信号以及企业信息安全提供了强大的功能和保障。GeWe的设计旨在简化开发过程,使开发者能够高效、灵活地构建和定制通信协议,以满足不同应用场景的需求。
灵活可扩展:GeWe框架采用灵活可扩展的设计理念,为开发者提供了丰富的选项和配置,确保协议能够适应不同的应用场景和需求。
高效数据传输:通过优化传输算法和数据压缩机制,GeWe框架构建的IPAD协议能够更快地传输数据,提高用户体验并节省带宽资源。
安全性与隐私保护:GeWe框架重视安全性和隐私保护,提供了一系列的加密和身份验证机制,确保数据在传输过程中得到保护,防止未经授权的访问。
丰富的功能模块:GeWe框架提供了丰富的功能模块,包括消息处理、好友管理、群组操作等,使个人微信号具备更多功能和扩展性。
友好的开发接口:GeWe框架提供简洁友好的开发接口,使得开发者能够轻松地扩展个人微信号的功能,如开发自动回复机器人、定时任务等。
GeWe框架是一个功能强大、灵活可扩展的软件开发框架,为个人和企业提供了丰富的功能和保障。通过利用GeWe框架,开发者可以高效地构建和定制通信协议,满足不同的应用需求。同时,GeWe框架也重视安全性和隐私保护,确保数据在传输过程中的安全性。
官方文档网站:http://doc.geweapi.com/

注意:Gewe 详细接口调用请自行测试
登陆微信 Pad 协议
注册登陆 gewe 后台:http://manager.geweapi.com/#/login?redirect=%2Faccount%2Findex

登陆微信 Pad 协议:http://manager.geweapi.com/#/account/wechat

项目结构预览
基于百度智能云、Gewe Pad 端、本地电脑端内网穿透实现。
详细流程图预览

源码结构

源码结构说明
.env 环境变量设置
audio_api 百度智能云合成语音 / 识别语音
bot.py 监听 gewe 消息回调(主函数)
download_msg.py 请求 gewe 下载语音消息
ffmpeg.exe 音频处理工具
mp3_to_silk mp3格式 -> silk格式
send_msg 请求 gewe 发送语音消息
silk_to_pcm silk格式 -> pcm格式
silk_v3_decoder.exe silk 解码操作
silk_v3_encoder.exe silk 编码操作
util.py 工具类
配置环境变量
.env 环境变量配置
APP_ID=百度云语音合成、识别 APP_ID
API_KEY=百度云语音合成、识别 API_KEY
SECRET_KEY=百度云语音合成、识别 SECRET_KEY
QIANFAN_API_KEY=百度云千帆大模型 API_KEY
QIANFAN_SECRET_KEY=百度云千帆大模型 SECRET_KEY
X_GEWE_TOKEN=GEWE Token
GEWE_APP_ID=GEWE 设备号
百度智能云千帆大模型
百度智能云使用参考博客:https://wrist.blog.csdn.net/article/details/134628415
一站式企业级大模型平台,提供先进的生成式AI生产及应用全流程开发工具链。直接调用ERNIE-Bot 4.0及其他主流大模型,并提供可视化开发工具链,支持数据闭环管理、专属大模型定制、大模型训练调优、插件编排等功能。
千帆大模型链接地址:https://cloud.baidu.com/product/wenxinworkshop
chat_api.py
import json
import os
import requests
API_KEY = os.getenv("QIANFAN_API_KEY")
SECRET_KEY = os.getenv("QIANFAN_SECRET_KEY")
payload = {
"user_id": "python",
"messages": [],
"system": "每次回答不允许换行,并且不超过50个字。",
"disable_search": False,
"enable_citation": False
}
def get_access_token(): # 这里是获取token一般不用管
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
def chat_answer(text):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions?access_token=" + get_access_token()
headers = {
'Content-Type': 'application/json'
}
payload["messages"] = [
{
"role": "user",
"content": text
}
]
json_payload = json.dumps(payload)
# 发送请求
response = requests.request("POST", url, headers=headers, data=json_payload)
result = response.json().get("result") # 提取并打印AI的回复
return result
ffmpeg 下载安装
FFmpeg是一套开源的计算机程序,用于处理数字音频、视频,以及将其转化为流。它以其强大的音视频处理能力、广泛的格式支持和跨平台特性,成为了多媒体处理领域的重要工具。
ffmpeg 基本功能
音视频编解码:FFmpeg支持各种音频和视频编解码器,包括常见的H.264、H.265、AAC、MP3等,使其能够处理各种媒体格式。
格式转换:可以将不同格式的音频和视频文件相互转换,例如将MP4转换为AVI、将WAV转换为MP3等。
流媒体处理:支持从网络摄像头、文件、或其他来源捕获音视频流,也能将处理后的流推送到服务器或其他设备。
图像处理:支持图像处理,如提取视频帧,合成图片和视频等。
剪辑和编辑:可以对音视频进行剪辑和编辑,包括裁剪、剪切、拼接等操作。
字幕处理:支持字幕的添加、移除和编辑,可以将字幕嵌入到视频中或者从视频中提取字幕。
音频处理:提供了丰富的音频处理功能,包括音频的剪辑、混音、音量调节等。
实时视频处理:能够处理实时的音视频流,适用于直播、视频会议等场景。
下载安装 FFmpeg
下载地址:https://github.com/BtbN/FFmpeg-Builds/releases
ffmpeg 工具 bin 目录
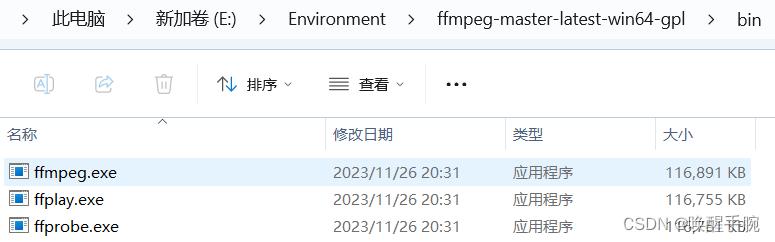
配置 ffmpeg/bin 系统环境变量

silk 编译器下载安装
Windows 用户可以直接使用提供的 silk_v3_decoder.exe 和 silk_v3_encoder.exe 工具进行转换。对于 macOS 和 Linux 用户,需要下载项目代码并运行 converter.sh 脚本进行转换。转换过程需要依赖 gcc 和 ffmpeg 库。
下载地址:https://github.com/kn007/silk-v3-decoder

silk_v3_encoder.exe 和 silk_v3_decoder.exe
silk_v3_encoder.exe
功能:用于将音频编码为Silk v3格式。可能用于需要将音频数据转换为Silk v3编码以进行存储、传输或与其他使用此编码格式的系统进行交互的场景。作为Silk-V3-Decoder项目的一部分,silk_v3_encoder.exe(如果存在并可用)可能支持多种操作系统,但具体兼容性信息在参考文章中未明确提及。
silk_v3_decoder.exe
功能:解码 Silk v3 音频文件,如微信amr、aud文件和QQ slk文件。将这些文件转换为其他音频格式,如mp3。支持批量转换。
高性能:针对Silk v3编码进行了优化,提供快速的解码速度。
跨平台支持:适用于多种操作系统,包括Windows、macOS和Linux。但图形界面可能仅限于Windows版本。
简单易用:提供了清晰简洁的接口和API,降低了学习和使用的门槛。
开源与持续维护:该项目遵循MIT许可证,并在GitCode或其他代码托管平台上进行托管,接受社区贡献和反馈。
微信 silk 音频处理
mp3_to_silk.py 实现将 mp3 文件转换成 silk 文件
import math
import subprocess
import time
from pydub import AudioSegment
def get_mp3_duration(mp3_file):
# 使用 pydub 读取 mp3 并获取时长
audio = AudioSegment.from_mp3(mp3_file)
duration_seconds = len(audio) / 1000.0
return duration_seconds
def convert_mp3_to_pcm(mp3_file, pcm_file):
# 使用 ffmpeg 将 mp3 转换为 pcm
command = f"ffmpeg -y -i {mp3_file} -f s16le -ar 24000 -ac 1 -acodec pcm_s16le {pcm_file}"
try:
subprocess.run(command, shell=True, check=True)
print(f"Converted {mp3_file} to {pcm_file}")
except subprocess.CalledProcessError as e:
print(f"Failed to convert {mp3_file} to {pcm_file}: {e}")
def convert_pcm_to_silk(pcm_file, silk_file):
# 使用 silk_v3_encoder.exe 将 PCM 转换为 SILK
command = f"silk_v3_encoder.exe {pcm_file} {silk_file} -tencent"
result = subprocess.run(command, shell=True)
if result.returncode == 0:
print(f"Converted {pcm_file} to {silk_file}")
else:
print(f"Failed to convert {pcm_file} to {silk_file}: {result.stderr}")
def transfrom_silk(file_name):
# 获取 mp3 文件时长
duration = get_mp3_duration(f"mp3/{file_name}.mp3")
print(f"Duration of {file_name}.mp3: {duration} seconds")
# 记录开始时间
start_time = time.time()
# 转换流程
convert_mp3_to_pcm(f"mp3/{file_name}.mp3", f"./pcm/{file_name}.pcm")
convert_pcm_to_silk(f"./pcm/{file_name}.pcm", f"./silk/{file_name}.silk")
# 记录结束时间
end_time = time.time()
# 计算并打印转换所花的总时间
total_time = end_time - start_time
print(f"Total time taken for conversion: {total_time} seconds")
return {"fileName": file_name, "voiceDuration": math.ceil(duration) * 1000}
silk_to_pcm.py 实现将 silk 文件转换成 mp3 文件
import subprocess
def convert_silk_to_pcm(silk_file, pcm_file):
# 使用 silk_v3_decoder.exe 将 silk 转换为 pcm
command = f"silk_v3_decoder.exe {silk_file} {pcm_file}"
try:
subprocess.run(command, shell=True, check=True)
print(f"Converted {silk_file} to {pcm_file}")
except subprocess.CalledProcessError as e:
print(f"Failed to convert {silk_file} to {pcm_file}: {e}")
def transfrom_pcm(file_name):
# 转换流程
convert_silk_to_pcm(f"silk/{file_name}.silk", f"pcm/{file_name}.pcm")
保存语音消息
保存语音消息 download_msg.py
import json
import os
import dotenv
dotenv.load_dotenv(".env")
import requests
headers = {
'X-GEWE-TOKEN': os.getenv("X_GEWE_TOKEN"),
'User-Agent': 'Apifox/1.0.0 (https://apifox.com)',
'Content-Type': 'application/json'
}
def download_audio_msg(msgId: int, xml: str):
data = {
"appId": os.getenv("GEWE_APP_ID"),
"msgId": msgId,
"xml": xml
}
print(json.dumps(data))
response = requests.post("http://api.geweapi.com/gewe/v2/api/message/downloadVoice", json=data, headers=headers)
if response.ok:
data = response.json()
if data['ret'] == 200:
print("Gewe download audio msg successfully.")
print(data['data']['fileUrl'])
return data['data']['fileUrl']
else:
print("Gewe download audio msg in error.")
return False
else:
return False
def download_image_msg(xml: str):
data = {
"appId": "wx_HtqjtTglwIKjQHSsSUYDi",
"type": 2,
"xml": xml
}
print(json.dumps(data))
response = requests.post("http://api.geweapi.com/gewe/v2/api/message/downloadImage", json=data, headers=headers)
if response.ok:
data = response.json()
if data['ret'] == 200:
print("Gewe download audio msg successfully.")
print(data['data']['fileUrl'])
return data['data']['fileUrl']
else:
print("Gewe download audio msg in error.")
return False
else:
return False
def download_audio_file(fileUrl: str, file_name: str):
# 定义保存文件的本地路径和文件名
local_filename = f'./silk/{file_name}.silk'
# 使用requests库的get方法获取文件内容
response = requests.get(fileUrl, stream=True)
# 检查请求是否成功
if response.status_code == 200:
# 打开文件以二进制写入模式
with open(local_filename, 'wb') as f:
# 逐块写入文件,通常使用1024字节的块大小
for chunk in response.iter_content(1024):
f.write(chunk)
print(f"文件已成功下载到 {local_filename}")
else:
print(f"请求失败,状态码: {response.status_code}")
百度云语音合成、识别
百度云语音合成、识别参考博客:https://wrist.blog.csdn.net/article/details/139551206
百度智能云语音识别:采用国际领先的流式端到端语音语言一体化建模算法,将语音快速准确识别为文字,支持手机应用语音交互、语音内容分析、机器人对话等场景。百度短语音识别可以将 60 秒以下的音频识别为文字。适用于语音对话、语音控制、语音输入等场景。

百度云语音合成、识别 audio_api
import os
import time
import requests
from aip import AipSpeech
import dotenv
dotenv.load_dotenv(".env")
APP_ID = os.getenv("APP_ID")
API_KEY = os.getenv("API_KEY")
SECRET_KEY = os.getenv("SECRET_KEY")
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def create_audio(text: str, file_name: str):
url = "https://tsn.baidu.com/text2audio"
# pcm
# payload = f'tex={text}&tok=' + get_access_token() + '&cuid=naAUL3Evzwj8A79l1kFHvRz1oUWZfOmo&ctp=1&lan=zh&spd=5&pit=5&vol=5&per=0&aue=4'
# mp3
payload = f'tex={text}&tok=' + get_access_token() + '&cuid=naAUL3Evzwj8A79l1kFHvRz1oUWZfOmo&ctp=1&lan=zh&spd=5&pit=5&vol=5&per=5003&aue=3'
response = requests.get(url=f"{url}?{payload}", data=payload, stream=True)
# 检查请求是否成功
if response.status_code == 200:
# 打开文件以二进制写入模式
with open(f"mp3/{file_name}.mp3", 'wb') as file:
# 分块读取并写入文件
for chunk in response.iter_content(1024):
if chunk:
file.write(chunk)
else:
print(f"请求失败,状态码:{response.status_code}")
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
# 读取文件
def get_file_content(file_name):
"""
read pcm file
:param file_name:
:return:
"""
with open(f"./pcm/{file_name}.pcm", 'rb') as fp:
return fp.read()
def recognize_audio(file_name):
"""
recognize pcm by baidu speech-api
:param file_name:
:return:
"""
# 识别本地文件
time.sleep(1)
result = client.asr(get_file_content(file_name), 'pcm', 16000, {
'dev_pid': 1537,
})
return result['result'][0]
natapp 内网穿透
内网穿透(NAT穿透)是一种网络技术,主要用于实现内部网络(通常指局域网或私有网络)与外部网络(如互联网)之间的通信。内网穿透指的是通过一定技术手段,将内部网络中的计算机或服务暴露给公网,实现内网与公网之间的互通。它的核心目标是使原本只能在内网内部访问的资源能够被外部网络的用户所访问。
内网穿透原理
内网穿透技术通过将公网地址映射到内网中的某个计算机或服务的地址,实现了内外网之间的通信。在实现过程中,可能涉及NAT(网络地址转换)技术,该技术可以将私有(保留)地址转化为合法的IP地址。
UDP内网穿透技术是其中一种实现方式,它利用路由器上的NAT系统,使一个普通的内网节点在需要时将自己的服务器端口自动呈现在公网上,并且能够让系统内其他节点正确获取这个地址。
内网穿透实现方法
反向代理是内网穿透的一种常见实现方法。通过反向代理服务器,外部网络用户可以访问内部网络资源,而无需直接访问内部网络。端口映射(也称为端口转发)是另一种实现方式,它将外部网络的请求转发到内部网络的特定端口上。
内网穿透工具 natapp 官方地址:https://natapp.cn/

选择合适版本下载
购买隧道配置信息

本地创建 config.ini 配置文件
[default]
authtoken= # 对应一条隧道的authtoken
clienttoken= # 对应客户端的clienttoken,将会忽略authtoken,若无请留空,
log=none # log 日志文件,可指定本地文件, none=不做记录,stdout=直接屏幕输出 ,默认为none
loglevel=ERROR # 日志等级 DEBUG, INFO, WARNING, ERROR 默认为 DEBUG
http_proxy= # 代理设置 如 http://10.123.10.10:3128 非代理上网用户请务必留空
本地 natapp.exe 和 config.ini 放在同目录

启动内网穿透

发送语音消息
消息模块发送语音消息必须要是 https 协议的文件,不能是本地 file 协议的文件,所以我们需要通过内网穿透,让我们的图片能够在公网访问,这样 gewe 才能进行发送。
发送语音消息 send_msg.py
import os
import requests
import dotenv
dotenv.load_dotenv(".env")
headers = {
'X-GEWE-TOKEN': os.getenv("X_GEWE_TOKEN"),
'User-Agent': 'Apifox/1.0.0 (https://apifox.com)',
'Content-Type': 'application/json'
}
def send_audio_msg(toWxid: str, voice_file: str, voiceDuration: int):
data = {
"appId": "wx_XqQOb78UPUFngK2ni2R9u",
"toWxid": toWxid,
"voiceUrl": f"http://edgehacker.natapp1.cc/silk/{voice_file}.silk",
"voiceDuration": voiceDuration
}
response = requests.post("http://api.geweapi.com/gewe/v2/api/message/postVoice", json=data, headers=headers)
if response.ok:
data = response.json()
if data['ret'] == 200:
print("Gewe sends audio msg successfully.")
return True
else:
print("Gewe sends audio msg in error.")
return False
else:
return False
Gewe 配置回调监听
我们需要登录API后台系统, 点击“访问控制-填写回调地址” ,将您的消息接收地址设置成功,后续此Toekn下登录的所有微信机器人,收到消息都会自动转发到您设置的回调接口地址。
Gewe 配置回调监听:http://manager.geweapi.com/#/account/access

开发者需要提供的回调接口要求?
微信消息是POST application/json请求您设置的回调接口地址。(您可以直接打印请求body体,可详细看到所有消息参数)
消息回调接口必须在3秒内响应,否则平台将放弃本次请求结果,回调接口可直接返回空字符串
机器人通过接口发送的消息不会有回调,因为回调是接收消息,发送不属于接收,但是手机微信发送的消息也会有,因为这属于消息多端同步,IM的原理
配置成功后,会接收一条包含文字“验证回调地址是否可用”的JSON回调
注意:回调接口必须发布到公网,也就是第三方可以访问的(临时测试可用内网穿透一类的,但是网速不稳定可能丢消息),若是显示回调验证失败,您可以用Apifox访问您的回调接口验证是否可访问。
Flask 服务接收微信消息
工具类 util.py
from datetime import datetime
def generate_timestamp():
# 获取当前时间
now = datetime.now()
# 格式化时间字符串为 'yyyyMMddHHmmssSS'
timestamp = now.strftime('%Y%m%d%H%M%S%f')[:-4]
return timestamp
def at_extract_content(text):
# 找到最后一个空格的索引
last_space_index = text.rfind(" ")
if last_space_index != -1:
# 返回空格后面的内容
return text[last_space_index + 1:]
return ""
def audio_extract_content(text):
result = text.split('\n', 1)[1]
return result
监听消息服务器 bot.py
import os
import time
from xml import etree
from flask import Flask, send_from_directory, request
import audio_api
import audio_to_text
import baidu_audio_to_text
import chat_api
import download_msg
import send_msg
import mp3_to_silk
import silk_to_pcm
import util
app = Flask(__name__)
@app.route('/silk/<filename>')
def serve_mp3(filename):
# 指定 audios 目录的路径
directory = 'silk'
# 检查文件是否存在
if not filename.endswith('.silk') or not os.path.isfile(os.path.join(directory, filename)):
return 'File not found', 404
# 使用 send_from_directory 发送文件
return send_from_directory(directory, filename, as_attachment=False)
@app.route('/messages', methods=['POST'])
def gewe_message():
msg = request.get_json()
PushContent = msg['Data']['PushContent']
if PushContent.endswith("在群聊中发了一段语音"):
FromUserName = msg['Data']['FromUserName']['string']
file_name = util.generate_timestamp()
MsgId = msg['Data']['MsgId']
Content = util.audio_extract_content(msg['Data']['Content']['string'])
fileUrl = download_msg.download_audio_msg(MsgId, Content)
download_msg.download_audio_file(fileUrl, file_name)
silk_to_pcm.transfrom_pcm(file_name)
result = baidu_audio_to_text.recognize_audio(file_name)
print(result)
result = chat_api.chat_answer(result)
print(result)
audio_api.create_audio("nova", result, file_name)
silk_data = mp3_to_silk.transfrom_silk(file_name)
send_msg.send_audio_msg(FromUserName, file_name, silk_data['voiceDuration'])
if PushContent.endswith("[语音]"):
FromUserName = msg['Data']['FromUserName']['string']
file_name = util.generate_timestamp()
MsgId = msg['Data']['MsgId']
Content = msg['Data']['Content']['string']
fileUrl = download_msg.download_audio_msg(MsgId, Content)
download_msg.download_audio_file(fileUrl, file_name)
silk_to_pcm.transfrom_pcm(file_name)
result = baidu_audio_to_text.recognize_audio(file_name)
result = chat_api.chat_answer(result)
audio_api.create_audio("nova", result, file_name)
silk_data = mp3_to_silk.transfrom_silk(file_name)
send_msg.send_audio_msg(FromUserName, file_name, silk_data['voiceDuration'])
return "success"
if __name__ == '__main__':
app.run(debug=True, port=80)
程序运行演示
控制台执行运行
python bot.py
执行效果预览
发送语音泡自动智能回复消息!!!
