@
目录- FastTester: 快速生成测试用例进行测试
FastTester: 快速生成测试用例进行测试
简介
利用日常功能测试(实际也调用API)通过代理获取到API的请求与响应信息,将这些请求信息进行流量回放/锲约测试或快速生成用例,
可通过人工进行修改参数化提取、变量引用、断言等形成API自动化测试用例!
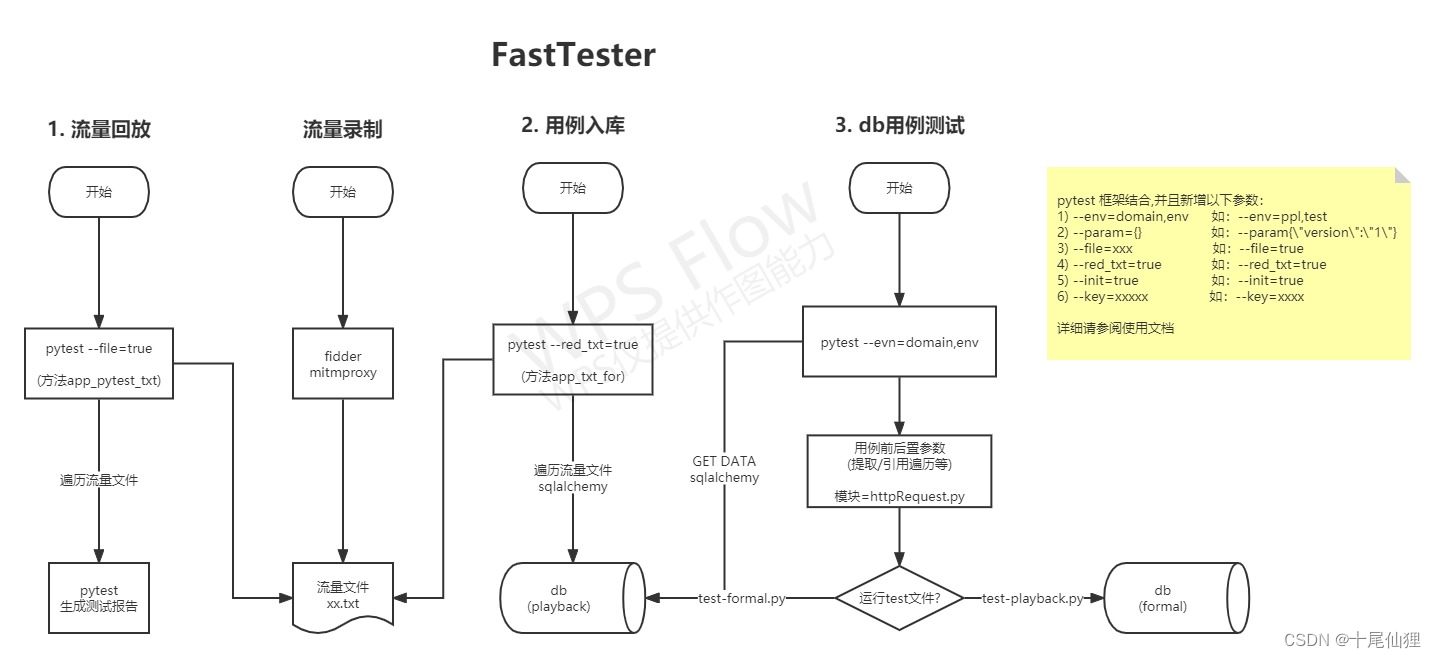
流程图(设计思路)
~_~ 不会画太粗糙了
快速开始
1.clone
github:git clone https://github.com/git-gsxl/FastTester.git
gitee:git clone https://gitee.com/qq772262624/FastTester.git
2.pip install:pip install -r requirements.txt -i https://pypi.douban.com/simple
3、demo运行测试:
cd tests
pytest
# Windows 可直接运行:`startCollect.cmd`

一、接口用例集合获取
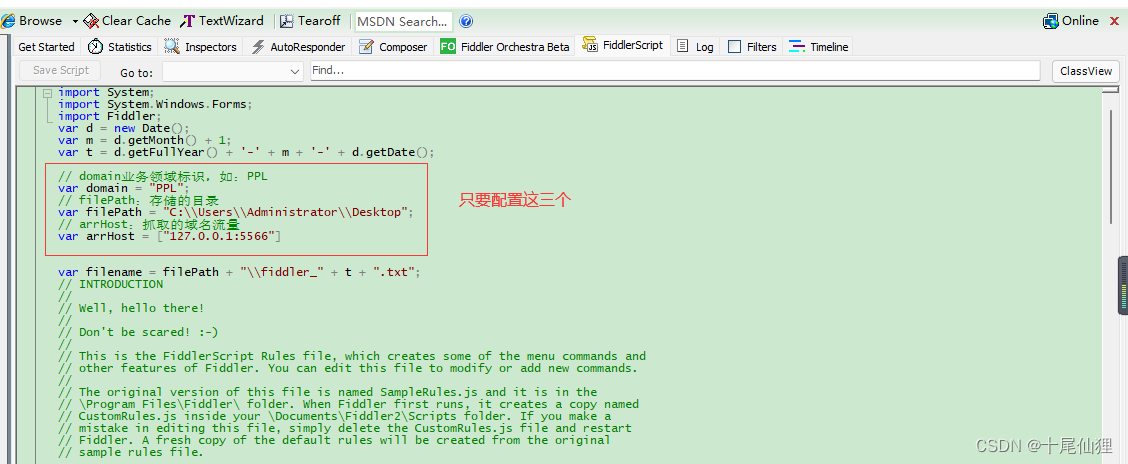
方式一:Fiddler
1、将项目下utils/httpCat/fiddler.txt复制文本粘贴,FiddlerScript
2、更改为符合自己业务领域配置,是项目绝对路径app目录,注意要用两个扛\\
方式二:mitmproxy
1、将项目下utils/httpCat/config.ini过滤域名改为自己需要配置的域名以及业务领域

2、需要配置代理证书等,详看mitmproxy使用文档
3、运行文件:startCollect.cmd
如出现报错请检查 pip install -r requirements.txt 是否已安装? 或 pip install mitmproxy==5.0.0
结合以上两种方式
1、你会得到:xxx.txt 文件

2、如需要用例入库,则执行命令行:
cd test
pytest --red_txt=true
另外可能需要进行数据库连接配置model/dbBase.py,默认为sqlite
二、执行测试
命令行参数说明(部分可在pytest.ini下默认配置),与pytest框架一致,并且新增以下参数:
-
--env:查询业务领域=ppl及环境=test的用例
如:--env=ppl,test -
--param:附加将version参数替换为1或追加
如:--param={\"version\":\"1\"} -
--file:读取app目录下所有txt文件进行流量回放,详细使用看流量回放
如:--file=true -
--red_txt:读取txt文件进行用例入库
如:--red_txt=true -
--init:db表结构初始化,一般不需要用到
如:--init=true -
--key:企微或钉钉群推送的key
如:--key=xxxx
方式1:流量回放,只回放API响应码为200
cd tests
1)方式1:默认为app目录下全部txt文件(以下2-3不存在文件时亦是):pytest --file=1
2)方式2:指定app目录下的文件:pytest --file=fiddler_2022-7-31.txt
3)方式3:绝对路径指定文件(注意win下需要\\):pytest --file=E:\\fiddler_2022-7-31.txt
4)方式4:相对路径指定文件:pytest --file=./fiddler_2022-7-31.txt
方式2:经过用例入库,执行db用例测试
cd tests
pytest test_playback.py --env=domain,env --param={\"version\":\"1\"}
ps:Windows可以默认ini参数直接一键运行并生成报告:testStart.cmd
(支持替换变量,存储变量,引用变量,响应断言)
三、后置处理器介绍:http_collect
参数提取器,默认是取第1个值(支持提取response与headers接口的返参)
Jsonpath语法请参考:https://goessner.net/articles/JsonPath
1.Jsonpath 区分大小写
1)获取key的值:['key'] ----> {'key':'value'}
2)获取key的值并重新命名:[{'key':'name'}] ----> {'name':'value'}
3)获取key的值并指定取第n个:['key':n] ----> {'key':values[n]}
4)获取key的值并重新命名及指定取第n个:['key':['name',n]] ----> {'name':values[n]}
5)原生Jsonpath语法:['$.data.key'] ----> {'key':'value'}
6)原生Jsonpath语法并重新命名:[{'$.data.key':'name'}] ----> {'name':'value'}
7)原生Jsonpath语法并指定取第n个:[{'$.data.key':n}] ----> {'key':values[n]}
8)原生Jsonpath语法并重新命名及指定取第n个:[{'$.data.key':['name',n]}] ----> {'name':values[n]}
2.正则表达式
1)获取正则表达式的值并命名为env:[{'re':['env','http://(.+?)/']}] ----> {'env':'value'}
2)获取正则表达式的值并命名为env及取第n个值:[{'re':['env','http://(.+?)/', -1]}] ----> {'name':'value'}
四、断言使用介绍:http_assert
1.Jsonpath 断言
1.字符在里面:["msgId"]
`实际为:assert "msgId" in response.text`
2.变量在里面:["${msgId}"]
`实际为:assert "${msgId}" in response.text`
2.字符相等:[{"msgId":"123456"}]
`实际为:assert 123456 == json_path(result.json(), 'msgId')`
3.字符在里面or其它:[{"msgId":["123456","in"]}] 注:in 可以是== != not in
assert 123456 in response.get('msgId')
4.长度:1 == len(response.get('msgId')):[{"msgId":[1,"len"]}]
assert 1 == len(response.get('msgId'))
2.正则表达式断言
1.直接写正则表达式即可,如:[{'re':'http://(.+?)/'}]
五、变量引用
使用本系统且遵循Faker语法直接引用:${Faker语法}
ppl_开头,为自定义生成数据方法
Faker 更多请查阅官方文档:https://faker.readthedocs.io/en/stable/locales/zh_CN.html#faker-providers-address
1.号码相关:
1)手机号:${phone_number}
18520149907
2)身份证号码:${ssn}
410622198603154708
2.时间日期相关
1)当前日期时间:${ppl_now_datetime}
2022-07-02 12:56:58
2)当前时间戳:${ppl_time}
1656737818
3)当前日期:${ppl_now_date}
2022-07-02
4)当前时间:${ppl_now_time}
12:56:58
5)过去7天的日期时间:${ppl_datetime(-7)}
2022-06-25 00:00:00
6)未来7天的日期时间:${ppl_datetime(7)}
2022-07-09 23:59:59
7)随机年-月-日:${date}
1996-03-20
8)随机(时:分:秒):${time}
04:52:23
9)未来的日期时间:${future_datetime(end_date=+7d)}
2022-07-07 16:01:23
10)过去的日期时间:${past_datetime(end_date=-7d)}
2022-06-29 13:29:20
3.名字相关:
1)姓名:${name}
王凯
2)姓名(女):${name_female}
戴丽丽
3)姓名(男):${name_male}
刘荣
4)姓:${last_name}
宋
5)名字:${first_name}
强
4.地址相关
1)地址:${address}
香港特别行政区大冶县上街钟街k座 664713
2)省:${province}
河北省
3)市:${city}
长春县
4)地区:${district}
白云
5)街道地址:${street_address}
武汉街D座
六、数据库config配置说明
默认使用sqlite,一般只需要连接sqlite更改1、账号环境配置信息即可

1.账号环境配置
1) gray:默认就好,一般会使用如:AB测试模型使用,定制化区分环境
2) Tester:登录获取token或cookie初始化,可配置多个登录信息,如下有两种例子:
collects:表示后置处理器 collect (使用详细查看第三点),用例提取token或cookie作为登录态
{
"gray":"gray",
"Tester":[
{
"https://app-xxx.com":{
"url":"api/user/login",
"json":{
"mobile":18888888888,
"Password":"mVs6NwvIFRgN0aaUo4KZOiW9QZWbKZjqVX1eW9Gr2s4rgZ5atS3ppY39ZlyE37Tb2/zo6YWJV6VJV="
},
"method":"POST",
"collects":["clienttoken"]}
},
{
"https://web-xxx.com":{
"url":"/api/index.php?r=data/login",
"data":"user=admin&password=4076f862096d1536b6cac6866e386655=",
"method":"POST",
"headers":{"content-Type":"application/x-www-form-urlencoded"},
"collects":["ppl_cookie"]
}
}
]
}
2.默认配置 (domain=default)
1) filter_path:过滤path为列表的,如登录/退出登录接口
2) filter_code:根据返回retCode字段,判断是否=0或='0',是则数据符合,否则跳过该数据
3) re_list:一般不需要使用,如AB测试模型时,则根据业务情况配置从response(uri/body/header)中正则匹配
4) db_pop:获取用例过滤:数据库字段转dict,去除非必要的字段,默认就好
5) filter_headers:过滤不必要的headers,默认就好
6) split_url_handle:path不需要特殊处理可默认,一般php接口可能需要处理,如下
例子:"split_url_handle":{".php":"path + '?r=' + query.pop('r')"}
表示:如果'.php'在path中,则运行path=eval("path+'?r='+query.pop('r')"
{
"filter_path":[
"/user/logout",
"/user/login"
],
"filter_code":{"retCode":[ 0, "0" ]},
"re_list":[],
"db_pop":[
"id","curl","response",
"_sa_instance_state",
"create_time","update_time"
],
"filter_headers":[
"content-length","accept-encoding","host","user-agent","accept",
"origin","referer","sec-ch-ua","connection","sec-fetch-dest",
"sec-fetch-mode","sec-fetch-site","pragma","accept-language",
"sec-ch-ua-mobile","sec-ch-ua-platform","postman-token",
"cache-control","x-requested-with","accept-encoding"
],
"split_url_handle":{}
}