Python数据分析numpy、pandas、matplotlib
一、基础
1.1 notebook的一些配置
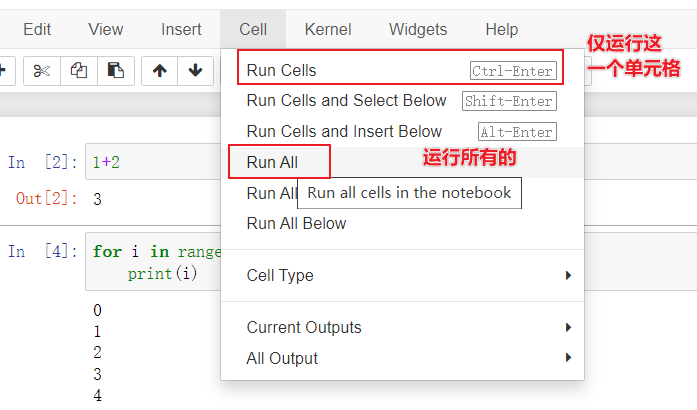
快捷键:
ctrl+enter 执行单元格程序并且不跳转到下一行
esc + L 可以显示行号
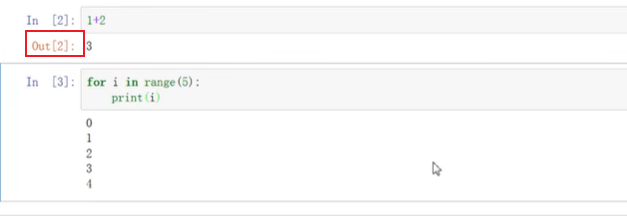
结果是打印的而没有返回任何的值就没有out
1.2 列表基础知识回顾
b=[1,2.3,'a','b']
b #列表中的元素允许各个元素不一样
list('abcde') #利用list生成列表
#[1, 2, 3, 4, 5, 1, 2.3, 'a', 'b']
a+b #将两个链表链接在一起
# [1, 2, 3, 4, 5, 1, 2.3, 'a', 'b']
| 方法 | 作用 | 举例 |
|---|---|---|
| append方法 | 在末尾增加一个数 | a.append(6) |
| insert方法 | insert(索引号,值) | a.insert(1,10) |
| pop | 1.pop方法,默认是删除最后一个元素,在里面写数字的话是写索引号2. | a.pop()/a.pop(1) |
b=[1,2,3,4,5,6,7,8,9]
#b=[a:b:i] #间隔取值,前面区间仍然是左闭右开,后面为步长,同样也适用于负数的情况
b[2:9:3]
#[3, 6, 9]
a[0:3] #数据切片,左闭右开区间
a[-1] #-1表示倒数第一个数
a[-3:-1] #负索引切片
a[:3]
a[-3:] #不写的话默认从左边第一个开始或者取到右边最后一个
1.3 元组基础知识回顾
另一种有序列表叫元组:tuple,用()来表示。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出演员的名字:
a = (1,2,3,4,5)
#a.pop() #报错,'tuple' object has no attribute 'pop'
a #用途:作为一个常量防止数据被篡改
(1, 2, 3, 4, 5)
1.4字典 dict
Python用{key:value}来生成Dictionary
字典里面的数据可以是任何数据类型,也可以是字典
mv = {"name":"肖申克的救赎","actor":"罗宾斯","score":9.6,"country":"USA"}
mv["name"]# '肖申克的救赎'
mv.keys()# dict_keys(['name', 'actor', 'score', 'country'])
mv.values() # dict_values(['肖申克的救赎', '罗宾斯', 9.6, 'USA'])
mv.items()# dict_items([('name', '肖申克的救赎'), ('actor', '罗宾斯'), ('score', 9.6), ('country', 'USA')])
1.5集合set
Python用{}来生成集合,集合不含有相同元素
s = {2,3,4,2}#自动删除重复数据
len(s)
s.add(1) #如果加入集合中已有元素没有任何影响
s1 = {2,3,5,6}
s & s1 #取交集 {2, 3}
s | s1 #取并集 {1, 2, 3, 4, 5, 6}
s - s1 #差集 {1, 4}
#s.remove(5) #删除集合s中一个元素,注意只能删除一次
#s.pop() #随机删除任意一个元素,删完后报错
#s.clear() #一键清空
1.6 可变与不可变对象
可变对象可以对其进行插入,删除等操作,不可变对象不可以对其进行有改变的操作。Python中列表,字典,集合等都是可变的,元组,字符串,整型等都是不可变的。
1.7 列表表达式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式
list(range(1,11)) #range(1,11)迭代器,左闭右开,只有一个参数从0开始,两个参数是区间,三个参数最后一个数是跨度,不写的时候默认跨度为1
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[x**2 for x in range(1,10)] #列表生成平方
[i for i in range(1,100) if i%10 == 0]
[str(x) for x in range(1,10)]
[int(x) for x in list("123456789")]
二、numpy
导入
NumPy是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多。NumPy(Numeric Python)提供了许多高级的数值编程工具。Numpy的一个重要特性是它的数组计算,是我们做数据分析必不可少的一个包。
导入python库使用关键字import,后面可以自定义库的简称,但是一般都将Numpy命名为np,pandas命名为pd。
导入的方法有以下几种:
import numpy
import numpy as np #推荐写法
from numpy import * #不是很建议这种写法,因为不用加前缀的话有可能会与其他函数名称起冲突,因而报错
2.1 Numpy的数组对象及其索引
数组上的数学操作
假设我们想将列表中的每个元素增加1,但列表不支持这样的操作:
a = [1,2,3,4]
#a+1 #报错
[x+1 for x in a] # [2, 3, 4, 5]
与另一个数组相加,得到对应元素相加的结果:
b = [2,3,4,5]
a+b #并不是我们想要的结果 [1, 2, 3, 4, 2, 3, 4, 5]
[x+y for(x,y) in zip(a,b)] #都需要利用到列表生成式
>>> a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)]
这样的操作比较麻烦,而且在数据量特别大的时候会非常耗时间。
如果我们使用Numpy,就会变得特别简单
产生数组
从列表产生数组:
l = [1,2,3,4]
a = np.array(l) # array([1, 2, 3, 4])
从列表传入:
a = np.array([1,2,3,4])
生成全0数组:
a = np.zeros(4) # 括号内传个数,默认浮点数 array([0., 0., 0., 0.])
生成全1的数组:
np.ones(5) #括号内传个数,默认浮点数
np.ones(5,dtype="bool") #可以自己指定类型,np.zeros函数同理
np.ones(5,dtype="bool") #可以自己指定类型,np.zeros函数同理 array([ True, True, True, True, True])
可以使用 fill 方法将数组设为指定值
a = np.array([1,2,3,4])
a.fill(5) #让数组中的每一个元素都等于5
与列表不同,数组中要求所有元素的 dtype 是一样的,如果传入参数的类型与数组类型不一样,需要按照已有的类型进行转换。
a.fill(2.5) #自动进行取整 array([2, 2, 2, 2])
如果非要全部fill成为浮点型的话,需要先进行类型转换
a = a.astype("float") #强制类型转换
a.fill(2.5)
a
还可以使用一些特定的方法生成特殊的数组
生成整数序列:
a = np.arange(1,10) #左闭右开区间,和range的使用方式同理
生成等差数列:
a = np.linspace(1,10,21) #右边是包括在里面的,从a-b一共c个数的等差数列,其实np.arange好像也可以做...
生成随机数
np.random.rand(10) # 括号内是需要的随机数个数
np.random.randn(10) #标准正态分布
np.random.randint(1,20,10) #生成随机整数,从1-20中随机10个
数组属性
查看数组中的数据类型:
a.dtype
查看形状,会返回一个元组,每个元素代表这一维的元素数目:
a.shape
或者使用:
np.shape(a)
要看数组里面元素的个数:
a.size
查看数组的维度:
a.ndim
索引和切片
和列表相似,数组也支持索引和切片操作。
索引第一个元素:
a = np.array([0,1,2,3])
a[0]
切片,支持负索引:
a = np.array([11,12,13,14,15])
a[1:3] #左闭右开,从0开始算 array([12, 13])
a[1:-2] #等价于a[1:3]
a[-4:3] #仍然等价a[1:3]
省略参数:
a[-2:] #从倒数第2个取到底
a[::2] #从头取到尾,间隔2
假设我们记录一部电影的累计票房:
ob = np.array([21000,21800,22240,23450,25000])
ob2 = ob[1:]-ob[:-1]
ob2

多维数组及其属性
array还可以用来生成多维数组:
a = np.array([[0,1,2,3],[10,11,12,13]])
事实上我们传入的是一个以列表为元素的列表,最终得到一个二维数组。
查看形状:
a.shape
查看总的元素个数:
a.size
多维数组索引
对于二维数组,可以传入两个数字来索引:
# array([[ 0, 1, 2, 3],
# [10, 11, 12, 13]])
a[1,3] # 第二行第四个
其中,1是行索引,3是列索引,中间用逗号隔开。事实上,Python会将它们看成一个元组(1,3),然后按照顺序进行对应。
可以利用索引给它赋值:
a[1,3] = -1
事实上,我们还可以使用单个索引来索引一整行内容:
# array([ 5, 6, 7, -1])
a[1]
Python会将这单个元组当成对第一维的索引,然后返回对应的内容。
a[:,1] # array([ 1, 11])
多维数组切片
多维数组,也支持切片操作:
a = np.array([[0,1,2,3,4,5],[10,11,12,13,14,15],[20,21,22,23,24,25],[30,31,32,33,34,35],[40,41,42,43,44,45],[50,51,52,53,54,55]])
# 得到第一行的第4和第5两个元素
a[0][3:5]
# 得到最后两行的最后两列
a[4:,4:]
# 得到第三列:
a[:,2]
每一维都支持切片的规则,包括负索引,省略
[lower:upper:step]
例如,取出3,5行的奇数列:
a[2:5:2,::2]
切片是引用
切片在内存中使用的是引用机制
引用机制意味着,Python并没有为b分配新的空间来存储它的值,而是让b指向了a所分配的内存空间,因此,改变b会改变a的值:

而这种现象在列表中并不会出现:

这样做的好处在于,对于很大的数组,不用大量复制多余的值,节约了空间。
缺点在于,可能出现改变一个值改变另一个值的情况。
一个解决方法是使用copy()方法产生一个复制,这个复制会申请新的内存:
花式索引
切片只能支持连续或者等间隔的切片操作,要想实现任意位置的操作。需要使用花式索引 fancy slicing。
一维花式索引
与range函数类似,我们可以使用arange函数来产生等差数组。
花式索引需要指定索引位置:

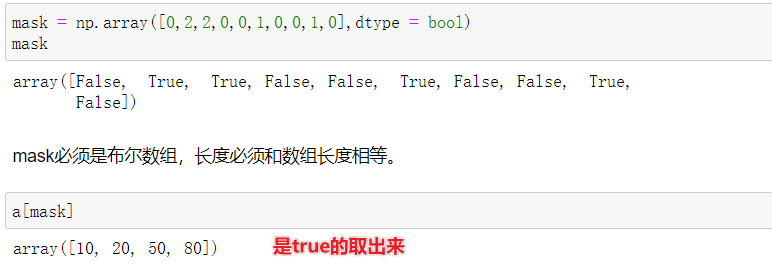
还可以用布尔数组来花式索引,mask必须是布尔数组,长度必须和数组长度相等。
二维花式索引
对于二维花式索引,我们需要给定行和列的值:
a = np.array([
[0,1,2,3,4,5],
[10,11,12,13,14,15],
[20,21,22,23,24,25],
[30,31,32,33,34,35],
[40,41,42,43,44,45],
[50,51,52,53,54,55]])
返回的是一条次对角线上的5个值。
a[(0,1,2,3,4),(1,2,3,4,5)]
行取01234行,列依次取第1,2,3,4,5个元素
返回的是最后三行的1,3,5列。
a[3:,[0,2,4]]
也可以使用mask进行索引:
mask = np.array([1,0,1,0,0,1],dtype = bool)
a[mask,2]
与切片不同,花式索引返回的是原对象的一个复制而不是引用。
“不完全”索引
只给定行索引的时候,返回整行:
y = a[:3]
# array([[ 0, 1, 2, 3, 4, 5],
# [ 1, 1, 1, 1, 1, 1],
# [20, 21, 22, 23, 24, 25]])
这时候也可以使用花式索引取出第2,3,5行:
con = np.array([0,1,1,0,1,0],dtype = bool)
a[con]
where语句
where(array)
where函数会返回所有非零元素的索引。
一维数组
先看一维的例子:
a = np.array([0,12,5,20])
判断数组中的元素是不是大于10:
a>10
# array([False, True, False, True])
数组中所有大于10的元素的索引位置:
np.where(a>10)
# (array([1, 3], dtype=int64),)
注意到where的返回值是一个元组。返回的是索引位置,索引[1,3]大于10的数
也可以直接用数组操作,这样可以得到具体的元素
a[np.where(a>10)]
# array([12, 20])
2.2数组类型
具体如下:

类型转换
a = np.array([1.5,-3],dtype = float)
# array([ 1.5, -3. ])
asarray 函数
a = np.array([1,2,3])
np.asarray(a,dtype = float)
# array([1., 2., 3.])
astype方法
astype 方法返回一个新数组:
a = np.array([1,2,3])
a.astype(float)
# array([1., 2., 3.])
a #a本身并没有发生变化--拷贝
2.3数组操作
我们以豆瓣10部高分电影为例
##电影名称
mv_name = ["肖申克的救赎","控方证人","美丽人生","阿甘正传","霸王别姬","泰坦尼克号","辛德勒的名单","这个杀手不太冷","疯狂动物城","海豚湾"]
##评分人数
mv_num = np.array([692795,42995,327855,580897,478523,157074,306904,662552,284652,159302])
##评分
mv_score = np.array([9.6,9.5,9.5,9.4,9.4,9.4,9.4,9.3,9.3,9.3])
##电影时长(分钟)
mv_length = np.array([142,116,116,142,171,194,195,133,109,92])
数组排序
sort函数
这个函数并不会改变原来的数组
np.sort(mv_num)
# array([ 42995, 157074, 159302, 284652, 306904, 327855, 478523, 580897,662552, 692795])
argsort函数
argsort返回从小到大的排列在数组中的索引位置:
order = np.argsort(mv_num)
# array([1, 5, 9, 8, 6, 2, 4, 3, 7, 0], dtype=int64)
查看评分人数最少的电影:
mv_name[order[0]]
求和
两种方式都可以:
np.sum(mv_num)
mv_num.sum()
最大值
np.max(mv_length)
mv_length.max()
最小值
np.min(mv_score)
mv_score.min()
均值
np.mean(mv_length)
mv_length.mean()
标准差
np.std(mv_length)
mv_length.std()
相关系数矩阵
np.cov(mv_score,mv_length)
2.4 多维数组操作
数组形状
a = np.arange(6)
# array([0, 1, 2, 3, 4, 5])
a.shape(n行,m列)可以生成一个n行m列的一个数组
a.shape=(2,3)
# array([[0, 1, 2],[3, 4, 5]])
与之对应的方法是reshape,但它不会修改原来数组的值,而是返回一个新的数组:
a.reshape(2,3)
# array([[0, 1, 2],[3, 4, 5]])
a #没变
转置
a = a.reshape(2,3)
#array([[0, 1, 2],[3, 4, 5]])
数组连接
有时候我们需要将不同的数组按照一定的顺序连接起来:
concatenate((a0,a1,...,aN),axis = 0)
注意,这些数组要用()包括到一个元组中去。
除了给定的轴外,这些数组其他轴的长度必须是一样的。
x = np.array([[0,1,2],[10,11,12]])
y = np.array([[50,51,52],[60,61,62]])
默认沿着第一维进行连接:
z = np.concatenate((x,y))
#array([[ 0, 1, 2],
# [10, 11, 12],
# [50, 51, 52],
# [60, 61, 62]])
沿着第二维进行连接:
z = np.concatenate((x,y),axis = 1)
#array([[ 0, 1, 2, 50, 51, 52],
# [10, 11, 12, 60, 61, 62]])
注意到这里x和y的形状是一样的,还可以将它们连接成三维的数组,但是concatenate不能提供这样的功能,不过可以这样:
z = np.array((x,y))
#array([[[ 0, 1, 2],
# [10, 11, 12]],
# [[50, 51, 52],
# [60, 61, 62]]])
事实上,Numpy提供了分别对应这三种情况的函数:
-
vstack
np.vstack((x,y)) #array([[ 0, 1, 2], # [10, 11, 12], # [50, 51, 52], # [60, 61, 62]]) -
hstack
np.hstack((x,y)) #array([[ 0, 1, 2, 50, 51, 52], # [10, 11, 12, 60, 61, 62]]) -
dstack
np.dstack((x,y)) '''array([[[ 0, 50], [ 1, 51], [ 2, 52]], [[10, 60], [11, 61], [12, 62]]])'''
2.5 Numpy内置函数
可以查阅:
https://blog.csdn.net/nihaoxiaocui/article/details/51992860?locationNum=5&fps=1
2.6 数组属性方法总结
| 调用方法 | 作用 |
|---|---|
| 1 | 基本属性 |
| a.dtype | 数组元素类型float32,uint8,... |
| a.shape | 数组形状(m,n,o,...) |
| a.size | 数组元素数 |
| a.itemsize | 每个元素占字节数 |
| a.nbytes | 所有元素占的字节 |
| a.ndim | 数组维度 |
| - | - |
| 2 | 形状相关 |
| a.flat | 所有元素的迭代器 |
| a.flatten() | 返回一个1维数组的复制 |
| a.ravel() | 返回一个一维数组,高效 |
| a.resize(new_size) | 改变形状 |
| a.swapaxes(axis1,axis2) | 交换两个维度的位置 |
| a.transpose(* axex) | 交换所有维度的位置 |
| a.T | 转置,a.transpose() |
| a.squeeze() | 去除所有长度为1的维度 |
| - | - |
| 3 | 填充复制 |
| a.copy() | 返回数组的一个复制 |
| a.fill(value) | 将数组的元组设置为特定值 |
| - | - |
| 4 | 转化 |
| a.tolist() | 将数组转化为列表 |
| a.tostring() | 转换为字符串 |
| a.astype(dtype) | 转换为指定类型 |
| a.byteswap(False) | 转换大小字节序 |
| a.view(type_or_dtype) | 生成一个使用相同内存,但使用不同的表示方法的数组 |
| - | - |
| 5 | 查找排序 |
| a.nonzero() | 返回所有非零元素的索引 |
| a.sort(axis=-1) | 沿某个轴排序 |
| a.argsort(axis=-1) | 沿某个轴,返回按排序的索引 |
| a.searchsorted(b) | 返回将b中元素插入a后能保持有序的索引值 |
| - | - |
| 6 | 元素数学操作 |
| a.clip(low,high) | 将数值限制在一定范围内 |
| a.round(decimals=0) | 近似到指定精度 |
| a.cumsum(axis=None) | 累加和 |
| a.cumprod(axis=None) | 累乘积 |
| - | - |
| 7 | 约简操作 |
| a.sum(axis=None) | 求和 |
| a.prod(axis=None) | 求积 |
| a.min(axis=None) | 最小值 |
| a.max(axis=None) | 最大值 |
| a.argmin(axis=None) | 最小值索引 |
| a.argmax(axis=None) | 最大值索引 |
| a.ptp(axis=None) | 最大值减最小值 |
| a.mean(axis=None) | 平均值 |
| a.std(axis=None) | 标准差 |
| a.var(axis=None) | 方差 |
| a.any(axis=None) | 只要有一个不为0,返回真,逻辑或 |
| a.all(axis=None) | 所有都不为0,返回真,逻辑与 |
2.7 作业
import numpy as np
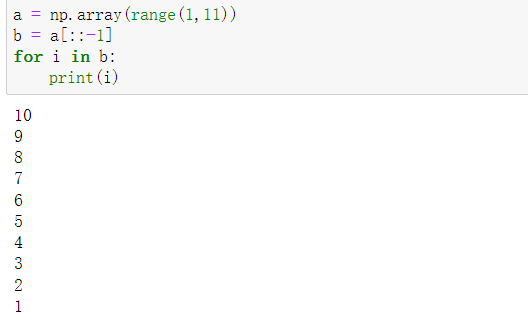
(1)创建一个1到10的数组,然后逆序输出。
a = np.array(range(1,11))
b = a[::-1]
for i in b:
print(i)
(2)创建一个长度为20的全1数组,然后变成一个4×5的二维矩阵并转置。
b =np.ones(20,dtype=int)
print(type(b))
b2 = b.reshape(4,5)
b2
b2.T
(3)创建一个3x3x3的随机数组。 (提示: np.random.random)

a = np.random.random(27)
a1 = a.reshape(3,3,3)
a1
或者
a = np.random.random((3,3,3))
(4)从1到10中随机选取10个数,构成一个长度为10的数组,并将其排序。获取其最大值最小值,求和,求方差。
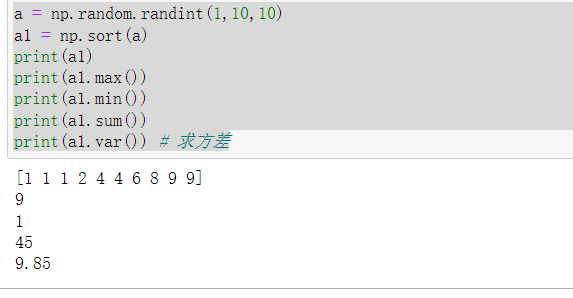
a = np.random.randint(1,10,10)
a1 = np.sort(a)
print(a1)
print(a1.max())
print(a1.min())
print(a1.sum())
print(a1.var()) # 求方差
(5)从1到10中随机选取10个数,构成一个长度为10的数组,选出其中的奇数。

a = np.random.randint(1,10,10)
print(a)
a1 = a[np.where(a%2==1)]
print(a1)
(6)生成0到100,差为5的一个等差数列,然后将数据类型转化为整数。
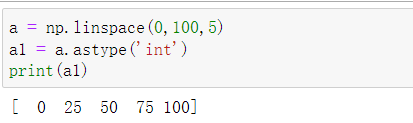
a = np.linspace(0,100,5)
a1 = a.astype('int')
print(a1)
(7)从1到10中随机选取10个数,大于3和小于8的取负数。

a = np.random.randint(1,10,10)
print(a)
index = np.where((a>3)&(a<8) )
a[index] = -a[index]
print(a)
(8)在数组[1, 2, 3, 4, 5]中相邻两个数字中间插入1个0。

a = np.array([1,2,3,4,5])
print(a)
# 插入之后1 0 2 0 3 0 4 0 5
b = np.zeros(len(a)*2-1)
print(b)
b[::2] = a
print(b)
或者

a = np.array([5,6,7,8,9])
np.insert(a,[1,2,3,4],[0,0,0,0])
在索引
[1, 2, 3, 4]的位置插入值[0, 0, 0, 0]
(9)新建一个5乘5的随机二位数组,交换其中两行?比如交换第一二行。
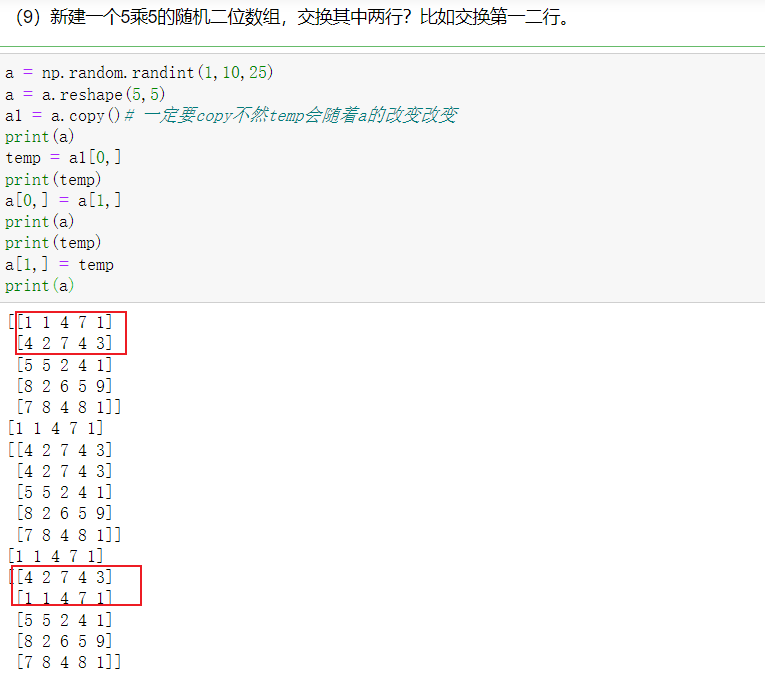
a = np.random.randint(1,10,25)
a = a.reshape(5,5)
a1 = a.copy()# 一定要copy不然temp会随着a的改变改变
print(a)
temp = a1[0,]
print(temp)
a[0,] = a[1,]
print(a)
print(temp)
a[1,] = temp
print(a)
或者

a = np.random.randint(1,10,(5,5))
a[[0,1],:] = a[[1,0],:]
a
(10)把一个10*2的随机生成的笛卡尔坐标转换成极坐标。
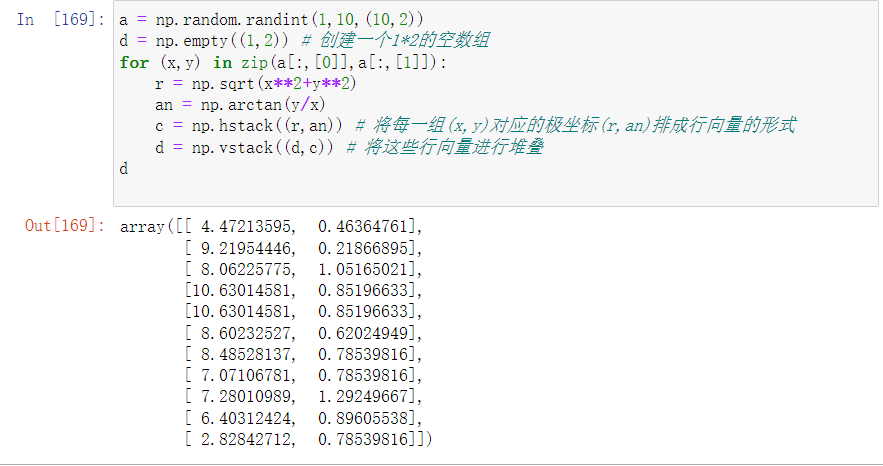
a = np.random.randint(1,10,(10,2))
d = np.empty((1,2)) # 创建一个1*2的空数组
for (x,y) in zip(a[:,[0]],a[:,[1]]):
r = np.sqrt(x**2+y**2)
an = np.arctan(y/x)
c = np.hstack((r,an)) # 将每一组(x,y)对应的极坐标(r,an)排成行向量的形式
d = np.vstack((d,c)) # 将这些行向量进行堆叠
d
(11)创建一个长度为10并且除了第五个值为1其余的值为2的向量。

a = np.ones(10,dtype='int')
a.fill(2)
a[4] = 1
a
(12)创建一个长度为10的随机向量,并求其累计和。
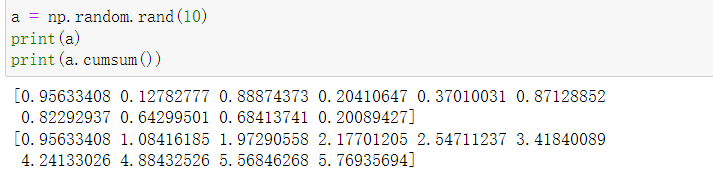
a = np.random.rand(10)
print(a)
print(a.cumsum())
(13)将数组中的所有奇数替换成-1。

a = np.arange(10)
print(a)
index = np.where(a%2==1)
a[index] = -1
print(a)
(14)构造两个4乘3的二维数组,按照3种方法进行连接?
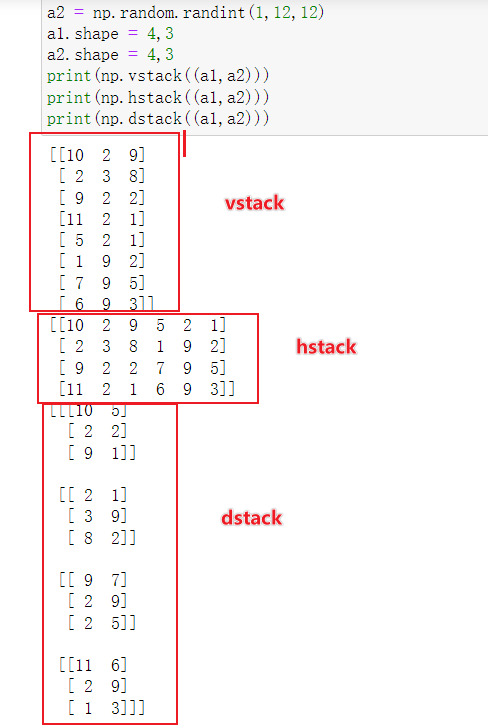
a1 = np.random.random(12)
a2 = np.random.random(12)
a1.shape = 4,3
a2.shape = 4,3
print(a1)
print(a2)
print(np.vstack((a1,a2)))
print(np.hstack((a1,a2)))
print(np.dstack((a1,a2)))
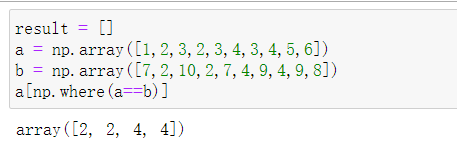
(15)获取数组 a 和 b 中的共同项(索引位置相同,值也相同)。 a = np.array([1,2,3,2,3,4,3,4,5,6]),b = np.array([7,2,10,2,7,4,9,4,9,8])
result = []
a = np.array([1,2,3,2,3,4,3,4,5,6])
b = np.array([7,2,10,2,7,4,9,4,9,8])
a[np.where(a==b)]
(16)从数组 a 中提取 5 和 10 之间的所有项。a=np.array([7,2,10,2,7,4,9,4,9,8])
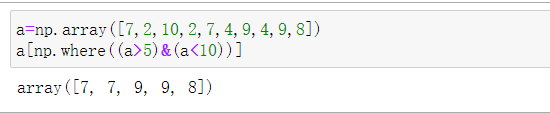
a=np.array([7,2,10,2,7,4,9,4,9,8])
a[np.where((a>5)&(a<10))]
三、pandas
3.1 pandas的基本介绍
Python Data Analysis Library 或 Pandas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
import pandas as pd
import numpy as np
3.2 pandas的基本数据结构
pandas有两种常用的基本结构:
- Series
- 一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很接近。Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
- DataFrame
- 二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
3.2.1 series类型
一维Series可以用一维列表初始化:
s = pd.Series([1,3,5,np.nan,6,8])#index = ['a','b','c','d','x','y'])设置索引,np.nan设置空值
print(s)
'''
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
'''
默认情况下,Series的下标都是数字(可以使用额外参数指定),类型是统一的。
索引——数据的行标签
s.index #从0到6(不含),1为步长
# RangeIndex(start=0, stop=6, step=1)
值
s.values
# array([ 1., 3., 5., nan, 6., 8.])
s[3]
#nan
切片操作
s[2:5] #左闭右开
'''
2 5.0
3 NaN
4 6.0
dtype: float64
'''
s[::2]
'''
0 1.0
2 5.0
4 6.0
dtype: float64
'''
索引赋值
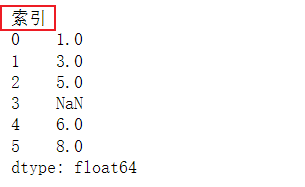
s.index.name = '索引'
s.index = list('abcdef')
'''
a 1.0
b 3.0
c 5.0
d NaN
e 6.0
f 8.0
dtype: float64
'''
s['a':'c':2] #依据自己定义的数据类型进行切片,不是左闭右开了
'''
a 1.0
c 5.0
dtype: float64
'''
3.2.2 DataFrame类型
DataFrame则是个二维结构,这里首先构造一组时间序列,作为我们第一维的下标:
date = pd.date_range("20180101", periods = 6)
print(date)
'''
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04','2018-01-05', '2018-01-06'],
dtype='datetime64[ns]', freq='D')
'''
然后创建一个DataFrame结构:
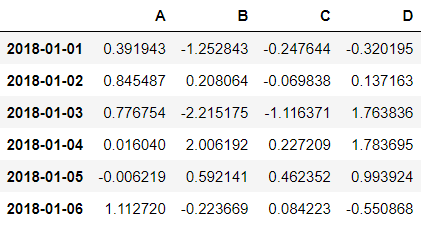
df = pd.DataFrame(np.random.randn(6,4), index = date, columns = list("ABCD")) # 结果如上图
默认情况下,如果不指定index参数和columns,那么它们的值将从用0开始的数字替代。
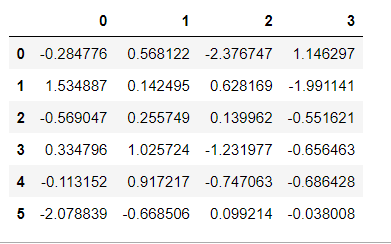
df = pd.DataFrame(np.random.randn(6,4)) # 结果如上图
除了向DataFrame中传入二维数组,我们也可以使用字典传入数据:
df2 = pd.DataFrame({'A':1.,'B':pd.Timestamp("20181001"),'C':pd.Series(1,index = list(range(4)),dtype = float),'D':np.array([3]*4, dtype = int),'E':pd.Categorical(["test","train","test","train"]),'F':"abc"}) #B:时间戳,E分类类型
'''
A B C D E F
0 1.0 2018-10-01 1.0 3 test abc
1 1.0 2018-10-01 1.0 3 train abc
2 1.0 2018-10-01 1.0 3 test abc
3 1.0 2018-10-01 1.0 3 train abc
'''
df2.dtypes #查看各个列的数据类型
'''
A float64
B datetime64[ns]
C float64
D int32
E category
F object
dtype: object
'''
字典的每个key代表一列,其value可以是各种能够转化为Series的对象。
与Series要求所有的类型都一致不同,DataFrame只要求每一列数据的格式相同。
查看数据
头尾数据
head和tail方法可以分别查看最前面几行和最后面几行的数据(默认为5):
df.head()
最后3行:
df.tail(3)
下标,列标,数据
下标使用index属性查看:
df.index
'''
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04','2018-01-05', '2018-01-06'],dtype='datetime64[ns]', freq='D')
'''
列标使用columns属性查看:
df.columns
'''
Index(['A', 'B', 'C', 'D'], dtype='object')
'''
数据值使用values查看:
df.values
'''
array([[ 0.39194344, -1.25284255, -0.24764423, -0.32019526],
[ 0.84548738, 0.20806449, -0.06983781, 0.13716277],
[ 0.7767544 , -2.21517465, -1.11637102, 1.76383631],
[ 0.01603994, 2.00619213, 0.22720908, 1.78369472],
[-0.00621932, 0.59214148, 0.46235154, 0.99392424],
[ 1.11272049, -0.22366925, 0.08422338, -0.5508679 ]])
'''
3.2.3 读取数据及其数据操作
我们将以豆瓣的电影数据作为我们深入了解Pandas的一个示例。
df = pd.read_excel(r"C:\Users\19127\Desktop\poststu\pre\python\课程中用到的数据\豆瓣电影数据.xlsx",index_col = 0)
#csv:read_csv;绝对路径或相对路径默认在当前文件夹下。r告诉编译器不需要转义
#具体其它参数可以去查帮助文档 ?pd.read_excel
行操作
df.iloc[0]
'''
名字 肖申克的救赎
投票人数 692795.0
类型 剧情/犯罪
产地 美国
上映时间 1994-09-10 00:00:00
时长 142
年代 1994
评分 9.6
首映地点 多伦多电影节
Name: 0, dtype: object
'''
df.iloc[0:5] #左闭右开
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港
'''
也可以使用loc
df.loc[0:5] #不是左闭右开
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港
5 泰坦尼克号 157074.0 剧情/爱情/灾难 美国 2012-04-10 00:00:00 194 2012 9.4 中国大陆
'''
添加一行
dit = {"名字":"复仇者联盟3","投票人数":123456,"类型":"剧情/科幻","产地":"美国","上映时间":"2018-05-04 00:00:00","时长":142,"年代":2018,"评分":np.nan,"首映地点":"美国"}
s = pd.Series(dit)
s.name = 38738
'''
名字 复仇者联盟3
投票人数 123456
类型 剧情/科幻
产地 美国
上映时间 2018-05-04 00:00:00
时长 142
年代 2018
评分 NaN
首映地点 美国
Name: 38738, dtype: object
'''
df = df.append(s) #覆盖掉原来的数据重新进行赋值
df[-5:]
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
38734 1935年 57.0 喜剧/歌舞 美国 1935-03-15 00:00:00 98 1935 7.6 美国
38735 血溅画屏 95.0 剧情/悬疑/犯罪/武侠/古装 中国大陆 1905-06-08 00:00:00 91 1986 7.1 美国
38736 魔窟中的幻想 51.0 惊悚/恐怖/儿童 中国大陆 1905-06-08 00:00:00 78 1986 8.0 美国
38737 列宁格勒围困之星火战役 Блокада: Фильм 2: Ленинградский ме... 32.0 剧情/战争 苏联 1905-05-30 00:00:00 97 1977 6.6 美国
38738 复仇者联盟3 123456.0 剧情/科幻 美国 2018-05-04 00:00:00 142 2018 NaN 美国
'''
删除一行
df = df.drop([38738])
df[-5:]
列操作
df.columns
# Index(['名字', '投票人数', '类型', '产地', '上映时间', '时长', '年代', '评分', '首映地点'], dtype='object')
df["名字"][:5] #后面中括号表示只想看到的行数,下同
'''
0 肖申克的救赎
1 控方证人
2 美丽人生
3 阿甘正传
4 霸王别姬
Name: 名字, dtype: object
'''
df[["名字","类型"]][:5]
'''
名字 类型
0 肖申克的救赎 剧情/犯罪
1 控方证人 剧情/悬疑/犯罪
2 美丽人生 剧情/喜剧/爱情
3 阿甘正传 剧情/爱情
4 霸王别姬 剧情/爱情/同性
'''
增加一列
df["序号"] = range(1,len(df)+1) #生成序号的基本方式
df[:5]
'''名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点 序号
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节 1
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国 2
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利 3
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映 4
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港 5
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点 序号
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节 1
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国 2
2 美丽人生 327855.0 剧情/喜剧/爱情 意大利 1997-12-20 00:00:00 116 1997 9.5 意大利 3
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映 4
4 霸王别姬 478523.0 剧情/爱情/同性 中国大陆 1993-01-01 00:00:00 171 1993 9.4 香港 5
'''
删除一列
df = df.drop("序号",axis = 1) #axis指定方向,0为行1为列,默认为0
df[:5]
通过标签选择数据
df.loc[[index],[colunm]]通过标签选择数据
df.loc[1,"名字"]
# '控方证人'
df.loc[[1,3,5,7,9],["名字","评分"]] #多行跳行多列跳列选择
'''
名字 评分
1 控方证人 9.5
3 阿甘正传 9.4
5 泰坦尼克号 9.4
7 新世纪福音战士剧场版:Air/真心为你 新世紀エヴァンゲリオン劇場版 Ai 9.4
9 这个杀手不太冷 9.4
'''
条件选择
选取产地为美国的所有电影
df[df["产地"] == "美国"][:5] #内部为bool
'''
名字 投票人数 类型 产地 上映时间 时长 年代 评分 首映地点
0 肖申克的救赎 692795.0 剧情/犯罪 美国 1994-09-10 00:00:00 142 1994 9.6 多伦多电影节
1 控方证人 42995.0 剧情/悬疑/犯罪 美国 1957-12-17 00:00:00 116 1957 9.5 美国
3 阿甘正传 580897.0 剧情/爱情 美国 1994-06-23 00:00:00 142 1994 9.4 洛杉矶首映
5 泰坦尼克号 157074.0 剧情/爱情/灾难 美国 2012-04-10 00:00:00 194 2012 9.4 中国大陆
6 辛德勒的名单 306904.0 剧情/历史/战争 美国 1993-11-30 00:00:00 195 1993 9.4 华盛顿首映
'''
选取产地为美国的所有电影,并且评分大于9分的电影
df[(df.产地 == "美国") & (df.评分 > 9)][:5] #df.标签:更简洁的写法
选取产地为美国或中国大陆的所有电影,并且评分大于9分
df[((df.产地 == "美国") | (df.产地 == "中国大陆")) & (df.评分 > 9)][:5]
缺失值及异常值处理
缺失值处理方法:
| 方法 | 说明 |
|---|---|
| dropna | 根据标签中的缺失值进行过滤,删除缺失值 |
| fillna | 对缺失值进行填充 |
| isnull | 返回一个布尔值对象,判断哪些值是缺失值 |
| notnull | isnull的否定式 |
判断缺失值
df[df["名字"].isnull()][:10] # 判断名字列为空的
df[df["名字"].notnull()][:5] # 判断不为空
填充缺失值
df[df["评分"].isnull()][:10] #注意这里特地将前面加入的复仇者联盟令其评分缺失来举例
df["评分"].fillna(np.mean(df["评分"]), inplace = True) #使用均值来进行替代,inplace意为直接在原始数据中进行修改
df[-5:]
df1 = df.fillna("未知电影") #谨慎使用,除非确定所有的空值都是在一列中,否则所有的空值都会填成这个
#不可采用df["名字"].fillna("未知电影")的形式,因为填写后数据格式就变了,变成Series了
df1[df1["名字"].isnull()][:10]
删除缺失值
| df.dropna() 参数 |
|---|
| how = 'all':删除全为空值的行或列 |
| inplace = True: 覆盖之前的数据 |
| axis = 0: 选择行或列,默认是行 |
df2 = df.dropna()
df.dropna(inplace = True)
处理异常值
异常值,即在数据集中存在不合理的值,又称离群点。比如年龄为-1,笔记本电脑重量为1吨等,都属于异常值的范围。
df[df["投票人数"] < 0] #直接删除,或者找原始数据来修正都行
df[df["投票人数"] % 1 != 0] #小数异常值
df = df[df.投票人数 > 0]
df = df[df["投票人数"] % 1 == 0]
数据保存
数据处理之后,然后将数据重新保存到movie_data.xlsx
df.to_excel("movie_data.xlsx") #默认路径为现在文件夹所在的路径