缓冲流
原文:
docs.oracle.com/javase/tutorial/essential/io/buffers.html
到目前为止,我们看到的大多数示例都使用非缓冲的 I/O。这意味着每个读取或写入请求都直接由底层操作系统处理。这可能会使程序效率大大降低,因为每个这样的请求通常会触发磁盘访问、网络活动或其他相对昂贵的操作。
为了减少这种开销,Java 平台实现了缓冲 I/O 流。缓冲输入流从称为缓冲区的内存区域读取数据;只有当缓冲区为空时才调用本机输入 API。类似地,缓冲输出流将数据写入缓冲区,只有当缓冲区满时才调用本机输出 API。
一个程序可以使用我们已经多次使用的包装习惯将非缓冲流转换为缓冲流,其中非缓冲流对象传递给缓冲流类的构造函数。以下是您可能如何修改CopyCharacters示例中的构造函数调用以使用缓冲 I/O 的方式:
inputStream = new BufferedReader(new FileReader("xanadu.txt"));
outputStream = new BufferedWriter(new FileWriter("characteroutput.txt"));
有四个缓冲流类用于包装非缓冲流:BufferedInputStream和BufferedOutputStream创建缓冲字节流,而BufferedReader和BufferedWriter创建缓冲字符流。
刷新缓冲流
在关键点写出缓冲区而不等待其填满通常是有意义的。这被称为刷新缓冲区。
一些缓冲输出类支持自动刷新,可以通过可选的构造函数参数指定。启用自动刷新时,某些关键事件会导致缓冲区被刷新。例如,一个自动刷新的PrintWriter对象会在每次调用println或format时刷新缓冲区。查看格式化以获取更多关于这些方法的信息。
要手动刷新流,请调用其flush方法。flush方法对任何输出流都有效,但除非流是缓冲的,否则不会产生任何效果。
扫描和格式化
原文:
docs.oracle.com/javase/tutorial/essential/io/scanfor.html
编程 I/O 通常涉及将数据翻译成人类喜欢处理的整洁格式。为了帮助您完成这些任务,Java 平台提供了两个 API。扫描器 API 将输入分解为与数据位相关联的单个标记。格式化 API 将数据组装成格式整齐、易读的形式。
扫描
原文:
docs.oracle.com/javase/tutorial/essential/io/scanning.html
类型为Scanner的对象对于将格式化输入拆分为标记并根据其数据类型翻译单个标记非常有用。
将输入分解为标记
默认情况下,扫描器使用空白字符来分隔标记。(空白字符包括空格、制表符和行终止符。有关完整列表,请参考Character.isWhitespace的文档。)为了了解扫描的工作原理,让我们看看ScanXan,一个程序,它读取xanadu.txt中的单词并将它们逐行打印出来。
import java.io.*;
import java.util.Scanner;
public class ScanXan {
public static void main(String[] args) throws IOException {
Scanner s = null;
try {
s = new Scanner(new BufferedReader(new FileReader("xanadu.txt")));
while (s.hasNext()) {
System.out.println(s.next());
}
} finally {
if (s != null) {
s.close();
}
}
}
}
请注意,当ScanXan完成对扫描器对象的操作时,会调用Scanner的close方法。即使扫描器不是一个流,你也需要关闭它以表示你已经完成了对其底层流的操作。
ScanXan的输出如下所示:
In
Xanadu
did
Kubla
Khan
A
stately
pleasure-dome
...
要使用不同的标记分隔符,调用useDelimiter(),指定一个正则表达式。例如,假设您希望标记分隔符是逗号,后面可以跟随空白。您可以调用,
s.useDelimiter(",\\s*");
翻译单个标记
ScanXan示例将所有输入标记视为简单的String值。Scanner还支持所有 Java 语言的基本类型(除了char),以及BigInteger和BigDecimal。此外,数值可以使用千位分隔符。因此,在US区域设置中,Scanner可以正确地将字符串"32,767"读取为整数值。
我们必须提及区域设置,因为千位分隔符和小数符是与区域设置相关的。因此,如果我们没有指定扫描器应该使用US区域设置,下面的示例在所有区域设置中都不会正确工作。这通常不是您需要担心的事情,因为您的输入数据通常来自与您相同区域设置的源。但是,这个示例是 Java 教程的一部分,会分发到世界各地。
ScanSum示例读取一组double值并将它们相加。以下是源代码:
import java.io.FileReader;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.Scanner;
import java.util.Locale;
public class ScanSum {
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
try {
s = new Scanner(new BufferedReader(new FileReader("usnumbers.txt")));
s.useLocale(Locale.US);
while (s.hasNext()) {
if (s.hasNextDouble()) {
sum += s.nextDouble();
} else {
s.next();
}
}
} finally {
s.close();
}
System.out.println(sum);
}
}
这是示例输入文件,usnumbers.txt
8.5
32,767
3.14159
1,000,000.1
输出字符串为"1032778.74159"。在某些区域设置中,句号可能是不同的字符,因为System.out是一个PrintStream对象,该类不提供覆盖默认区域设置的方法。我们可以为整个程序覆盖区域设置,或者我们可以使用格式化,如下一主题中所述,格式化。
格式化
原文:
docs.oracle.com/javase/tutorial/essential/io/formatting.html
实现格式化的流对象是PrintWriter(字符流类)或PrintStream(字节流类)的实例。
注意:你可能需要的唯一PrintStream对象是System.out和System.err。(有关这些对象的更多信息,请参阅从命令行进行 I/O。)当您需要创建格式化输出流时,请实例化PrintWriter,而不是PrintStream。
像所有字节和字符流对象一样,PrintStream和PrintWriter的实例实现了一组用于简单字节和字符输出的标准write方法。此外,PrintStream和PrintWriter都实现了相同的一组方法,用于将内部数据转换为格式化输出。提供了两个级别的格式化:
-
print和println以标准方式格式化单个值。 -
format根据格式字符串几乎可以格式化任意数量的值,具有许多精确格式化选项。
print和println方法
调用print或println在使用适当的toString方法转换值后输出单个值。我们可以在Root示例中看到这一点:
public class Root {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.print("The square root of ");
System.out.print(i);
System.out.print(" is ");
System.out.print(r);
System.out.println(".");
i = 5;
r = Math.sqrt(i);
System.out.println("The square root of " + i + " is " + r + ".");
}
}
这是Root的输出:
The square root of 2 is 1.4142135623730951.
The square root of 5 is 2.23606797749979.
i和r变量被格式化两次:第一次使用print重载中的代码,第二次是由 Java 编译器自动生成的转换代码,也利用了toString。您可以以这种方式格式化任何值,但对结果的控制不多。
format方法
format方法根据格式字符串格式化多个参数。格式字符串由静态文本与格式说明符嵌入在一起组成;除了格式说明符外,格式字符串不会改变输出。
格式字符串支持许多功能。在本教程中,我们只涵盖了一些基础知识。有关完整描述,请参阅 API 规范中的格式字符串语法。
Root2示例使用单个format调用格式化两个值:
public class Root2 {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.format("The square root of %d is %f.%n", i, r);
}
}
这里是输出:
The square root of 2 is 1.414214.
像这个示例中使用的三个一样,所有格式说明符都以%开头,并以指定正在生成的格式化输出类型的 1 个或 2 个字符转换结尾。这里使用的三个转换是:
-
d将整数值格式化为十进制值。 -
f将浮点值格式化为十进制值。 -
n输出特定于平台的换行符。
这里有一些其他转换:
-
x将整数格式化为十六进制值。 -
s将任何值格式化为字符串。 -
tB格式化一个整数为本地特定的月份名称。
还有许多其他转换。
注意:
除了 %% 和 %n 之外,所有格式说明符都必须匹配一个参数。如果不匹配,就会抛出异常。
在 Java 编程语言中,\n 转义始终生成换行符(\u000A)。除非特别需要换行符,否则不要使用 \n。要获取本地平台的正确换行符,请使用 %n。
除了转换之外,格式说明符还可以包含几个额外元素,进一步定制格式化输出。这里是一个示例,Format,使用了每种可能的元素类型。
public class Format {
public static void main(String[] args) {
System.out.format("%f, %1$+020.10f %n", Math.PI);
}
}
这是输出结果:
3.141593, +00000003.1415926536
所有附加元素都是可选的。下图显示了更长格式说明符如何分解为元素。
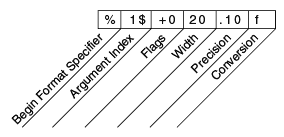
格式说明符的元素。
元素必须按照所示顺序出现。从右边开始,可选元素包括:
-
精度。对于浮点值,这是格式化值的数学精度。对于
s和其他一般转换,这是格式化值的最大宽度;如果需要,值将被右截断。 -
宽度。格式化值的最小宽度;如果需要,将填充值。默认情况下,值左侧用空格填充。
-
标志 指定额外的格式选项。在
Format示例中,+标志指定数字应始终带有符号格式,0标志指定0为填充字符。其他标志包括-(右侧填充)和,(使用本地特定的千位分隔符格式化数字)。请注意,某些标志不能与其他标志或某些转换一起使用。 -
参数索引 允许您显式匹配指定的参数。您还可以指定
<来匹配与上一个格式说明符相同的参数。因此,示例可以这样说:System.out.format("%f, %<+020.10f %n", Math.PI);
命令行 I/O
程序通常从命令行运行并在命令行环境中与用户交互。Java 平台通过标准流和控制台两种方式支持这种交互。
标准流
标准流是许多操作系统的特性。默认情况下,它们从键盘读取输入并将输出写入显示器。它们还支持文件和程序之间的 I/O,但该功能由命令行解释器控制,而不是程序。
Java 平台支持三个标准流:标准输入,通过 System.in 访问;标准输出,通过 System.out 访问;以及标准错误,通过 System.err 访问。这些对象会自动定义,无需打开。标准输出和标准错误都用于输出;将错误输出单独处理允许用户将常规输出重定向到文件并仍能读取错误消息。有关更多信息,请参考您的命令行解释器文档。
你可能期望标准流是字符流,但出于历史原因,它们是字节流。System.out 和 System.err 被定义为 PrintStream 对象。虽然技术上是字节流,但 PrintStream 利用内部字符流对象来模拟许多字符流的特性。
相比之下,System.in 是一个没有字符流特性的字节流。要将标准输入作为字符流使用,需要将 System.in 包装在 InputStreamReader 中。
InputStreamReader cin = new InputStreamReader(System.in);
控制台
比标准流更高级的替代方案是控制台。这是一种类型为 Console 的单一预定义对象,具有标准流提供的大部分功能,以及其他功能。控制台特别适用于安全密码输入。控制台对象还通过其 reader 和 writer 方法提供真正的字符流输入和输出流。
在程序可以使用控制台之前,必须通过调用 System.console() 尝试检索控制台对象。如果控制台对象可用,则此方法将返回它。如果 System.console 返回 NULL,则不允许控制台操作,可能是因为操作系统不支持它们或者因为程序在非交互环境中启动。
控制台对象通过其readPassword方法支持安全密码输入。该方法通过两种方式帮助安全密码输入。首先,它抑制回显,因此密码不会在用户屏幕上可见。其次,readPassword返回一个字符数组,而不是一个String,因此密码可以被覆盖,一旦不再需要,即从内存中删除。
Password示例是一个用于更改用户密码的原型程序。它演示了几种Console方法。
import java.io.Console;
import java.util.Arrays;
import java.io.IOException;
public class Password {
public static void main (String args[]) throws IOException {
Console c = System.console();
if (c == null) {
System.err.println("No console.");
System.exit(1);
}
String login = c.readLine("Enter your login: ");
char [] oldPassword = c.readPassword("Enter your old password: ");
if (verify(login, oldPassword)) {
boolean noMatch;
do {
char [] newPassword1 = c.readPassword("Enter your new password: ");
char [] newPassword2 = c.readPassword("Enter new password again: ");
noMatch = ! Arrays.equals(newPassword1, newPassword2);
if (noMatch) {
c.format("Passwords don't match. Try again.%n");
} else {
change(login, newPassword1);
c.format("Password for %s changed.%n", login);
}
Arrays.fill(newPassword1, ' ');
Arrays.fill(newPassword2, ' ');
} while (noMatch);
}
Arrays.fill(oldPassword, ' ');
}
// Dummy change method.
static boolean verify(String login, char[] password) {
// This method always returns
// true in this example.
// Modify this method to verify
// password according to your rules.
return true;
}
// Dummy change method.
static void change(String login, char[] password) {
// Modify this method to change
// password according to your rules.
}
}
Password类遵循以下步骤:
-
尝试检索控制台对象。如果对象不可用,则中止。
-
调用
Console.readLine提示并读取用户的登录名。 -
调用
Console.readPassword提示并读取用户的现有密码。 -
调用
verify确认用户有权限更改密码。(在这个例子中,verify是一个始终返回true的虚拟方法。) -
重复以下步骤,直到用户两次输入相同的密码:
-
两次调用
Console.readPassword提示并读取新密码。 -
如果用户两次输入相同的密码,调用
change进行更改。(同样,change是一个虚拟方法。) -
用空格覆盖两个密码。
-
-
用空格覆盖旧密码。
数据流
原文:
docs.oracle.com/javase/tutorial/essential/io/datastreams.html
数据流支持原始数据类型值(boolean、char、byte、short、int、long、float和double)以及String值的二进制 I/O。所有数据流都实现了DataInput接口或DataOutput接口。本节重点介绍了这些接口的最常用实现,DataInputStream和DataOutputStream。
DataStreams示例演示了通过写出一组数据记录,然后再次读取它们来演示数据流。每个记录包含与发票上的项目相关的三个值,如下表所示:
| 记录中的顺序 | 数据类型 | 数据描述 | 输出方法 | 输入方法 | 示例值 |
|---|---|---|---|---|---|
| 1 | double |
项目价格 | DataOutputStream.writeDouble |
DataInputStream.readDouble |
19.99 |
| 2 | int |
单位数量 | DataOutputStream.writeInt |
DataInputStream.readInt |
12 |
| 3 | String |
项目描述 | DataOutputStream.writeUTF |
DataInputStream.readUTF |
"Java T-Shirt" |
让我们来看看DataStreams中关键的代码。首先,程序定义了一些包含数据文件名称和将写入其中的数据的常量:
static final String dataFile = "invoicedata";
static final double[] prices = { 19.99, 9.99, 15.99, 3.99, 4.99 };
static final int[] units = { 12, 8, 13, 29, 50 };
static final String[] descs = {
"Java T-shirt",
"Java Mug",
"Duke Juggling Dolls",
"Java Pin",
"Java Key Chain"
};
然后DataStreams打开一个输出流。由于DataOutputStream只能作为现有字节流对象的包装器创建,DataStreams提供了一个带缓冲的文件输出字节流。
out = new DataOutputStream(new BufferedOutputStream(
new FileOutputStream(dataFile)));
DataStreams写出记录并关闭输出流。
for (int i = 0; i < prices.length; i ++) {
out.writeDouble(prices[i]);
out.writeInt(units[i]);
out.writeUTF(descs[i]);
}
writeUTF方法以修改后的 UTF-8 形式写出String值。这是一种只需要一个字节来表示常见西方字符的可变宽度字符编码。
现在DataStreams再次读取数据。首先,它必须提供一个输入流和变量来保存输入数据。与DataOutputStream一样,DataInputStream必须作为字节流的包装器构建。
in = new DataInputStream(new
BufferedInputStream(new FileInputStream(dataFile)));
double price;
int unit;
String desc;
double total = 0.0;
现在DataStreams可以读取流中的每个记录,并报告遇到的数据。
try {
while (true) {
price = in.readDouble();
unit = in.readInt();
desc = in.readUTF();
System.out.format("You ordered %d" + " units of %s at $%.2f%n",
unit, desc, price);
total += unit * price;
}
} catch (EOFException e) {
}
请注意,DataStreams通过捕获EOFException来检测文件结束条件,而不是测试无效的返回值。所有DataInput方法的实现都使用EOFException而不是返回值。
还要注意,DataStreams 中的每个专门的 write 都与相应的专门的 read 完全匹配。程序员需要确保输出类型和输入类型以这种方式匹配:输入流由简单的二进制数据组成,没有任何内容指示个别值的类型,或者它们在流中的位置。
DataStreams 使用了一种非常糟糕的编程技术:它使用浮点数来表示货币值。一般来说,浮点数对于精确值是不好的。对于十进制小数来说尤其糟糕,因为常见的值(比如0.1)没有二进制表示。
用于货币值的正确类型是java.math.BigDecimal。不幸的是,BigDecimal是一个对象类型,所以它不能与数据流一起使用。然而,BigDecimal 可以 与对象流一起使用,这将在下一节中介绍。
对象流
原文:
docs.oracle.com/javase/tutorial/essential/io/objectstreams.html
就像数据流支持原始数据类型的 I/O 一样,对象流支持对象的 I/O。大多数标准类支持其对象的序列化,但并非所有类都支持。那些实现了标记接口Serializable的类支持序列化。
对象流类是ObjectInputStream和ObjectOutputStream。这些类实现了ObjectInput和ObjectOutput,它们是DataInput和DataOutput的子接口。这意味着在对象流中也实现了数据流中涵盖的所有原始数据 I/O 方法。因此,对象流可以包含原始值和对象值的混合。ObjectStreams示例说明了这一点。ObjectStreams创建了与DataStreams相同的应用程序,但有一些变化。首先,价格现在是BigDecimal对象,以更好地表示分数值。其次,一个Calendar对象被写入数据文件,表示发票日期。
如果readObject()没有返回预期的对象类型,尝试将其强制转换为正确类型可能会抛出ClassNotFoundException。在这个简单的例子中,这种情况不会发生,所以我们不尝试捕获异常。相反,我们通过将ClassNotFoundException添加到main方法的throws子句中来通知编译器,我们已经意识到了这个问题。
复杂对象的输出和输入
writeObject和readObject方法使用起来很简单,但它们包含一些非常复杂的对象管理逻辑。对于像日历这样只封装原始值的类来说,这并不重要。但是许多对象包含对其他对象的引用。如果readObject要从流中重建一个对象,它必须能够重建原始对象引用的所有对象。这些额外的对象可能有它们自己的引用,依此类推。在这种情况下,writeObject遍历整个对象引用网络,并将该网络中的所有对象写入流中。因此,一次writeObject调用可能导致大量对象被写入流中。
这在下图中有所展示,其中调用writeObject来写入一个名为a的单一对象。这个对象包含对对象b和c的引用,而b包含对d和e的引用。调用writeobject(a)不仅写入a,还写入了重建a所需的所有对象,因此这个网络中的其他四个对象也被写入了。当a被readObject读回时,其他四个对象也被读回,并且所有原始对象引用都被保留。
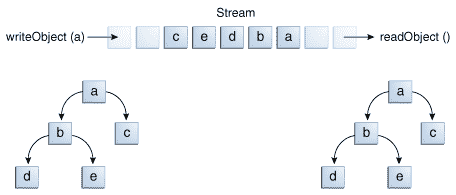
多个被引用对象的 I/O
你可能会想知道,如果同一流上的两个对象都包含对同一对象的引用会发生什么。当它们被读回时,它们会都指向同一个对象吗?答案是"是"。一个流只能包含一个对象的副本,尽管它可以包含任意数量的引用。因此,如果你明确地将一个对象两次写入流中,实际上只是写入了引用两次。例如,如果以下代码将对象ob两次写入流中:
Object ob = new Object();
out.writeObject(ob);
out.writeObject(ob);
每个writeObject都必须与一个readObject匹配,因此读取流的代码看起来会像这样:
Object ob1 = in.readObject();
Object ob2 = in.readObject();
这导致了两个变量,ob1和ob2,它们都是指向同一个对象的引用。
然而,如果一个单一对象被写入两个不同的流,它实际上会被复制 一个程序读取这两个流将看到两个不同的对象。
文件 I/O(具有 NIO.2 功能)
注意: 本教程反映了 JDK 7 版本中引入的文件 I/O 机制。Java SE 6 版本的文件 I/O 教程很简短,但您可以下载包含早期文件 I/O 内容的Java SE Tutorial 2008-03-14版本的教程。
java.nio.file包及其相关包java.nio.file.attribute为文件 I/O 和访问默认文件系统提供了全面支持。尽管 API 有许多类,但您只需关注其中的一些入口点。您会发现这个 API 非常直观和易于使用。
本教程首先询问什么是路径?然后介绍了该包的主要入口点 Path 类。解释了与语法操作相关的Path类中的方法。然后教程转向包中的另一个主要类Files类,其中包含处理文件操作的方法。首先介绍了许多 file operations 共有的一些概念。然后介绍了用于检查、删除、复制和移动文件的方法。
教程展示了在继续学习 file I/O 和 directory I/O 之前如何管理元数据。解释了随机访问文件并检查了与符号链接和硬链接相关的问题。
接下来,涵盖了一些非常强大但更高级的主题。首先演示了递归遍历文件树的能力,然后介绍了如何使用通配符搜索文件的信息。接下来,解释并演示了如何监视目录以进行更改。然后,给出了一些其他地方不适用的方法的关注。
最后,如果您在 Java SE 7 发布之前编写了文件 I/O 代码,有一个从旧 API 到新 API 的映射,以及关于File.toPath方法的重要信息,供希望利用新 API 而无需重写现有代码的开发人员参考。
什么是路径?(以及其他文件系统事实)
文件系统在某种介质上存储和组织文件,通常是一个或多个硬盘,以便可以轻松检索文件。今天大多数使用的文件系统将文件存储在树(或分层)结构中。树的顶部是一个(或多个)根节点。在根节点下面,有文件和目录(在 Microsoft Windows 中称为文件夹)。每个目录可以包含文件和子目录,子目录又可以包含文件和子目录,依此类推,可能深入到几乎无限的深度。
本节涵盖以下内容:
-
什么是路径?
-
相对还是绝对?
-
符号链接
什么是路径?
以下图显示了包含单个根节点的示例目录树。Microsoft Windows 支持多个根节点。每个根节点映射到一个卷,例如C:\或D:\。Solaris OS 支持单个根节点,用斜杠字符/表示。
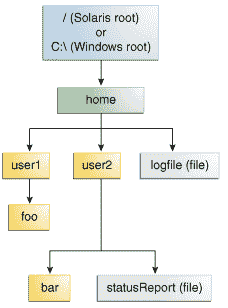 示例目录结构
示例目录结构
文件通过其在文件系统中的路径来标识,从根节点开始。例如,在前面的图中,Solaris OS 中的statusReport文件由以下表示:
/home/sally/statusReport
在 Microsoft Windows 中,statusReport由以下表示:
C:\home\sally\statusReport
用于分隔目录名称的字符(也称为分隔符)特定于文件系统:Solaris OS 使用正斜杠(/),而 Microsoft Windows 使用反斜杠(\)。
相对还是绝对?
路径可以是相对的或绝对的。绝对路径始终包含根元素和完整的目录列表,以定位文件。例如,/home/sally/statusReport是一个绝对路径。定位文件所需的所有信息都包含在路径字符串中。
相对路径需要与另一个路径结合才能访问文件。例如,joe/foo是一个相对路径。没有更多信息,程序无法可靠地定位文件系统中的joe/foo目录。
符号链接
文件系统对象通常是目录或文件。每个人都熟悉这些对象。但是一些文件系统也支持符号链接的概念。符号链接也称为symlink或soft link。
符号链接是一个特殊文件,用作指向另一个文件的引用。在大多数情况下,符号链接对应用程序是透明的,对符号链接的操作会自动重定向到链接的目标。(被指向的文件或目录称为链接的目标。)例外情况是当符号链接被删除或重命名时,链接本身被删除或重命名,而不是链接的目标。
在下图中,对用户来说,logFile看起来像是一个常规文件,但实际上它是指向dir/logs/HomeLogFile的符号链接。HomeLogFile是链接的目标。
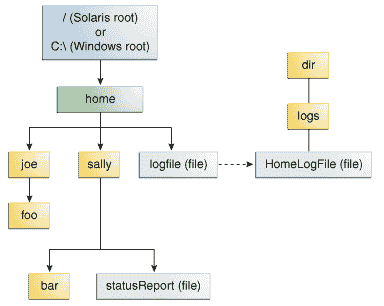 符号链接示例。
符号链接示例。
对用户来说,符号链接通常是透明的。读取或写入符号链接与读取或写入任何其他文件或目录相同。
解析链接这个短语意味着用文件系统中的实际位置替换符号链接。在这个例子中,解析logFile会得到dir/logs/HomeLogFile。
在现实场景中,大多数文件系统广泛使用符号链接。偶尔,粗心创建的符号链接可能会导致循环引用。循环引用发生在链接的目标指向原始链接的情况下。循环引用可能是间接的:目录a指向目录b,后者指向目录c,后者包含一个子目录指向目录a。当程序递归遍历目录结构时,循环引用可能会造成混乱。然而,这种情况已经考虑到,不会导致程序无限循环。
下一页将讨论 Java 编程语言中文件 I/O 支持的核心,即Path类。
Path 类
原文:
docs.oracle.com/javase/tutorial/essential/io/pathClass.html
Path类是 Java SE 7 版本中引入的主要入口点之一,属于java.nio.file包。如果您的应用程序使用文件 I/O,您将希望了解此类的强大功能。
版本说明: 如果您有使用java.io.File的 JDK7 之前的代码,您仍然可以通过使用File.toPath方法来利用Path类的功能。有关更多信息,请参阅旧版文件 I/O 代码。
正如其名称所示,Path类是文件系统中路径的程序表示。Path对象包含用于构建路径的文件名和目录列表,并用于检查、定位和操作文件。
一个Path实例反映了底层平台。在 Solaris 操作系统中,Path使用 Solaris 语法(/home/joe/foo),而在 Microsoft Windows 中,Path使用 Windows 语法(C:\home\joe\foo)。Path不是系统独立的。你不能比较来自 Solaris 文件系统的Path并期望它与来自 Windows 文件系统的Path匹配,即使目录结构相同,两个实例都定位到相同的相对文件。
与Path对应的文件或目录可能不存在。您可以创建一个Path实例并以各种方式操作它:您可以附加到它,提取它的部分,将其与另一个路径进行比较。在适当的时候,您可以使用Files类中的方法来检查与Path对应的文件的存在性,创建文件,打开文件,删除文件,更改其权限等。
下一页将详细讨论Path类。
Path 操作
原文:
docs.oracle.com/javase/tutorial/essential/io/pathOps.html
Path类包括各种方法,可用于获取有关路径的信息,访问路径的元素,将路径转换为其他形式或提取路径的部分。还有用于匹配路径字符串的方法以及用于删除路径中冗余的方法。本课程介绍了这些Path方法,有时称为语法操作,因为它们作用于路径本身,而不访问文件系统。
本节涵盖以下内容:
-
创建一个 Path
-
检索有关 Path 的信息
-
从 Path 中删除冗余
-
转换 Path
-
连接两个路径
-
在两个路径之间创建路径
-
比较两个路径
创建一个 Path
一个Path实例包含用于指定文件或目录位置的信息。在定义时,Path会提供一系列一个或多个名称。可能包括根元素或文件名,但都不是必需的。Path可能仅包含单个目录或文件名。
您可以通过使用Paths(注意复数形式)辅助类中的以下get方法之一轻松创建Path对象:
Path p1 = Paths.get("/tmp/foo");
Path p2 = Paths.get(args[0]);
Path p3 = Paths.get(URI.create("file:///Users/joe/FileTest.java"));
Paths.get方法是以下代码的简写:
Path p4 = FileSystems.getDefault().getPath("/users/sally");
以下示例假定您的主目录是/u/joe,则创建/u/joe/logs/foo.log,或者如果您在 Windows 上,则为C:\joe\logs\foo.log。
Path p5 = Paths.get(System.getProperty("user.home"),"logs", "foo.log");
检索有关路径的信息
你可以将Path看作将这些名称元素存储为序列。目录结构中最高的元素位于索引 0。目录结构中最低的元素位于索引[n-1],其中n是Path中名称元素的数量。可用于使用这些索引检索单个元素或Path的子序列的方法。
本课程中的示例使用以下目录结构。
示例目录结构
以下代码片段定义了一个Path实例,然后调用了几种方法以获取有关路径的信息:
// None of these methods requires that the file corresponding
// to the Path exists.
// Microsoft Windows syntax
Path path = Paths.get("C:\\home\\joe\\foo");
// Solaris syntax
Path path = Paths.get("/home/joe/foo");
System.out.format("toString: %s%n", path.toString());
System.out.format("getFileName: %s%n", path.getFileName());
System.out.format("getName(0): %s%n", path.getName(0));
System.out.format("getNameCount: %d%n", path.getNameCount());
System.out.format("subpath(0,2): %s%n", path.subpath(0,2));
System.out.format("getParent: %s%n", path.getParent());
System.out.format("getRoot: %s%n", path.getRoot());
这是 Windows 和 Solaris OS 的输出:
| 调用的方法 | Solaris OS 中的返回 | Microsoft Windows 中的返回 | 注释 |
|---|---|---|---|
toString |
/home/joe/foo |
C:\home\joe\foo |
返回Path的字符串表示。如果路径是使用Filesystems.getDefault().getPath(String)或Paths.get(后者是getPath的便利方法)创建的,则该方法会执行轻微的语法清理。例如,在 UNIX 操作系统中,它将修正输入字符串//home/joe/foo为/home/joe/foo。 |
getFileName |
foo |
foo |
返回文件名或名称元素序列的最后一个元素。 |
getName(0) |
home |
home |
返回与指定索引对应的路径元素。第 0 个元素是最靠近根的路径元素。 |
getNameCount |
3 |
3 |
返回路径中的元素数量。 |
subpath(0,2) |
home/joe |
home\joe |
返回Path的子序列(不包括根元素),由开始和结束索引指定。 |
getParent |
/home/joe |
\home\joe |
返回父目录的路径。 |
getRoot |
/ |
C:\ |
返回路径的根。 |
前面的示例显示了绝对路径的输出。在以下示例中,指定了相对路径:
// Solaris syntax
Path path = Paths.get("sally/bar");
or
// Microsoft Windows syntax
Path path = Paths.get("sally\\bar");
以下是 Windows 和 Solaris OS 的输出:
| 调用的方法 | Solaris OS 中返回 | Microsoft Windows 中返回 |
|---|---|---|
toString |
sally/bar |
sally\bar |
getFileName |
bar |
bar |
getName(0) |
sally |
sally |
getNameCount |
2 |
2 |
subpath(0,1) |
sally |
sally |
getParent |
sally |
sally |
getRoot |
null |
null |
从路径中删除冗余
许多文件系统使用“.”符号表示当前目录,“..”表示父目录。您可能会遇到路径包含冗余目录信息的情况。也许服务器配置为将其日志文件保存在“/dir/logs/.”目录中,您希望从路径中删除末尾的“/.`”符号。
以下示例都包含冗余:
/home/./joe/foo
/home/sally/../joe/foo
normalize方法会删除任何冗余元素,包括任何“.”或“directory/..”出现。前面两个示例都会规范化为/home/joe/foo`。
值得注意的是,normalize在清理路径时不会检查文件系统。这是一个纯语法操作。在第二个示例中,如果sally是一个符号链接,删除sally/..可能导致Path不再定位到预期的文件。
为了清理路径并确保结果定位到正确的文件,您可以使用toRealPath方法。该方法在下一节转换路径中描述。
转换路径
您可以使用三种方法来转换Path。如果需要将路径转换为可以从浏览器打开的字符串,可以使用toUri。例如:
Path p1 = Paths.get("/home/logfile");
// Result is file:///home/logfile
System.out.format("%s%n", p1.toUri());
toAbsolutePath方法将路径转换为绝对路径。如果传入的路径已经是绝对路径,则返回相同的Path对象。在处理用户输入的文件名时,toAbsolutePath方法非常有帮助。例如:
public class FileTest {
public static void main(String[] args) {
if (args.length < 1) {
System.out.println("usage: FileTest file");
System.exit(-1);
}
// Converts the input string to a Path object.
Path inputPath = Paths.get(args[0]);
// Converts the input Path
// to an absolute path.
// Generally, this means prepending
// the current working
// directory. If this example
// were called like this:
// java FileTest foo
// the getRoot and getParent methods
// would return null
// on the original "inputPath"
// instance. Invoking getRoot and
// getParent on the "fullPath"
// instance returns expected values.
Path fullPath = inputPath.toAbsolutePath();
}
}
toAbsolutePath方法转换用户输入并返回一个Path,在查询时返回有用的值。此方法不需要文件存在即可工作。
toRealPath方法返回现有文件的真实路径。该方法一次执行多个操作:
-
如果向该方法传递
true,并且文件系统支持符号链接,则该方法会解析路径中的任何符号链接。 -
如果
Path是相对路径,则返回绝对路径。 -
如果
Path包含任何多余的元素,则返回一个删除了这些元素的路径。
如果文件不存在或无法访问,则此方法会抛出异常。您可以在需要处理这些情况时捕获异常。例如:
try {
Path fp = path.toRealPath();
} catch (NoSuchFileException x) {
System.err.format("%s: no such" + " file or directory%n", path);
// Logic for case when file doesn't exist.
} catch (IOException x) {
System.err.format("%s%n", x);
// Logic for other sort of file error.
}
连接两个路径
您可以使用resolve方法组合路径。您传入一个部分路径,即不包括根元素的路径,并将该部分路径附加到原始路径。
例如,考虑以下代码片段:
// Solaris
Path p1 = Paths.get("/home/joe/foo");
// Result is /home/joe/foo/bar
System.out.format("%s%n", p1.resolve("bar"));
or
// Microsoft Windows
Path p1 = Paths.get("C:\\home\\joe\\foo");
// Result is C:\home\joe\foo\bar
System.out.format("%s%n", p1.resolve("bar"));
将绝对路径传递给resolve方法会返回传入的路径:
// Result is /home/joe
Paths.get("foo").resolve("/home/joe");
创建两个路径之间的路径
在编写文件 I/O 代码时,通常需要能够构造从文件系统中的一个位置到另一个位置的路径。您可以使用relativize方法来实现这一点。该方法构造一个源自原始路径并以传入路径指定的位置结束的路径。新路径是相对于原始路径的。
例如,考虑两个定义为joe和sally的相对路径:
Path p1 = Paths.get("joe");
Path p2 = Paths.get("sally");
在没有其他信息的情况下,假定joe和sally是兄弟姐妹,即在树结构中处于同一级别的节点。要从joe导航到sally,你需要先向上导航一级到父节点,然后再向下导航到sally:
// Result is ../sally
Path p1_to_p2 = p1.relativize(p2);
// Result is ../joe
Path p2_to_p1 = p2.relativize(p1);
考虑一个稍微复杂的例子:
Path p1 = Paths.get("home");
Path p3 = Paths.get("home/sally/bar");
// Result is sally/bar
Path p1_to_p3 = p1.relativize(p3);
// Result is ../..
Path p3_to_p1 = p3.relativize(p1);
在这个例子中,这两个路径共享相同的节点home。要从home导航到bar,你首先向下导航一级到sally,然后再向下导航一级到bar。从bar到home的导航需要向上移动两级。
如果只有一个路径包含根元素,则无法构造相对路径。如果两个路径都包含根元素,则构造相对路径的能力取决于系统。
递归Copy示例使用relativize和resolve方法。
比较两个路径
Path类支持equals,使您能够测试两个路径是否相等。startsWith和endsWith方法使您能够测试路径是否以特定字符串开头或结尾。这些方法易于使用。例如:
Path path = ...;
Path otherPath = ...;
Path beginning = Paths.get("/home");
Path ending = Paths.get("foo");
if (path.equals(otherPath)) {
// *equality logic here*
} else if (path.startsWith(beginning)) {
// *path begins with "/home"*
} else if (path.endsWith(ending)) {
// *path ends with "foo"*
}
Path类实现了Iterable接口。iterator方法返回一个对象,使你能够遍历路径中的名称元素。返回的第一个元素是在目录树中最接近根的元素。以下代码片段遍历一个路径,打印每个名称元素:
Path path = ...;
for (Path name: path) {
System.out.println(name);
}
Path类还实现了Comparable接口。你可以使用compareTo比较Path对象,这对于排序很有用。
你也可以将Path对象放入Collection中。查看 Collections trail,了解更多关于这一强大功能的信息。
当你想要验证两个Path对象是否定位到同一文件时,可以使用isSameFile方法,如 Checking Whether Two Paths Locate the Same File 中所述。
文件操作
原文:
docs.oracle.com/javase/tutorial/essential/io/fileOps.html
Files类是java.nio.file包的另一个主要入口点。该类提供了丰富的静态方法集,用于读取、写入和操作文件和目录。Files方法适用于Path对象的实例。在继续阅读其余部分之前,您应该熟悉以下常见概念:
-
释放系统资源
-
捕获异常
-
可变参数
-
原子操作
-
方法链
-
什么是 Glob?
-
链接感知
释放系统资源
此 API 中使用的许多资源,如流或通道,实现或扩展了java.io.Closeable接口。Closeable资源的要求是在不再需要时必须调用close方法来释放资源。忽略关闭资源可能会对应用程序的性能产生负面影响。下一节描述的try-with-resources 语句会为您处理此步骤。
捕获异常
在文件 I/O 中,意外情况是生活中的一个事实:文件存在(或不存在)时预期的,程序无法访问文件系统,默认文件系统实现不支持特定功能,等等。可能会遇到许多错误。
所有访问文件系统的方法都可能抛出IOException。最佳做法是通过将这些方法嵌入到 Java SE 7 版本中引入的try-with-resources 语句中来捕获这些异常。try-with-resources 语句的优点是编译器在不再需要时会自动生成关闭资源的代码。以下代码显示了这种情况可能如何:
Charset charset = Charset.forName("US-ASCII");
String s = ...;
try (BufferedWriter writer = Files.newBufferedWriter(file, charset)) {
writer.write(s, 0, s.length());
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
有关更多信息,请参阅 try-with-resources 语句。
或者,您可以将文件 I/O 方法嵌入到try块中,然后在catch块中捕获任何异常。如果您的代码已打开任何流或通道,则应在finally块中关闭它们。使用 try-catch-finally 方法的前一个示例可能如下所示:
Charset charset = Charset.forName("US-ASCII");
String s = ...;
BufferedWriter writer = null;
try {
writer = Files.newBufferedWriter(file, charset);
writer.write(s, 0, s.length());
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
} finally {
if (writer != null) writer.close();
}
有关更多信息,请参阅捕获和处理异常。
除了IOException,许多特定异常扩展了FileSystemException。这个类有一些有用的方法,返回涉及的文件(getFile),详细的消息字符串(getMessage),文件系统操作失败的原因(getReason),以及涉及的“其他”文件(如果有)(getOtherFile)。
以下代码片段展示了getFile方法可能如何使用:
try (...) {
...
} catch (NoSuchFileException x) {
System.err.format("%s does not exist\n", x.getFile());
}
为了清晰起见,本课程中的文件 I/O 示例可能不显示异常处理,但您的代码应始终包含它。
可变参数
当指定标志时,几个Files方法接受任意数量的参数。例如,在以下方法签名中,CopyOption参数后的省略号表示该方法接受可变数量的参数,通常称为可变参数:
Path Files.move(Path, Path, CopyOption...)
当一个方法接受可变参数时,您可以传递逗号分隔的值列表或值数组(CopyOption[])。
在move示例中,该方法可以如下调用:
import static java.nio.file.StandardCopyOption.*;
Path source = ...;
Path target = ...;
Files.move(source,
target,
REPLACE_EXISTING,
ATOMIC_MOVE);
有关可变参数语法的更多信息,请参见可变参数。
原子操作
几个Files方法,比如move,可以在一些文件系统中以原子方式执行某些操作。
原子文件操作是一种不能被中断或“部分”执行的操作。要么整个操作被执行,要么操作失败。当您有多个进程在文件系统的同一区域上操作,并且您需要保证每个进程访问完整的文件时,这一点就很重要。
方法链
许多文件 I/O 方法支持方法链的概念。
首先调用返回对象的方法。然后立即在该对象上调用一个方法,该方法返回另一个对象,依此类推。许多 I/O 示例使用以下技术:
String value = Charset.defaultCharset().decode(buf).toString();
UserPrincipal group =
file.getFileSystem().getUserPrincipalLookupService().
lookupPrincipalByName("me");
这种技术产生了紧凑的代码,并使您能够避免声明您不需要的临时变量。
什么是通配符?
Files类中有两个方法接受通配符参数,但是通配符是什么?
您可以使用通配符语法来指定模式匹配行为。
通配符模式被指定为一个字符串,并与其他字符串(如目录或文件名)匹配。通配符语法遵循几个简单的规则:
-
星号
*匹配任意数量的字符(包括零个)。 -
两个星号
**的工作方式类似于*,但跨越目录边界。这种语法通常用于匹配完整路径。 -
问号,
?,匹配恰好一个字符。 -
大括号指定一组子模式。例如:
-
{太阳,月亮,星星}匹配"太阳"、"月亮"或"星星"。 -
{temp*,tmp*}匹配所有以"temp"或"tmp"开头的字符串。
-
-
方括号传达一组单个字符,或者当使用连字符字符(
-)时,传达一组字符范围。例如:-
[aeiou]匹配任何小写元音字母。 -
[0-9]匹配任何数字。 -
[A-Z]匹配任何大写字母。 -
[a-z,A-Z]匹配任何大写或小写字母。在方括号内,*、?和\代表它们自身。
-
-
所有其他字符都代表它们自身。
-
要匹配
*、?或其他特殊字符,可以使用反斜杠字符\进行转义。例如:\\匹配一个反斜杠,\?匹配问号。
以下是一些通配符语法示例:
-
*.html– 匹配所有以 .html 结尾的字符串 -
???– 匹配所有恰好有三个字母或数字的字符串 -
*[0-9]*– 匹配所有包含数字值的字符串 -
*.{htm,html,pdf}– 匹配任何以 .htm、.html 或 .pdf 结尾的字符串 -
a?*.java– 匹配任何以a开头,后跟至少一个字母或数字,并以 .java 结尾的字符串 -
{foo*,*[0-9]*}– 匹配任何以 foo 开头的字符串或任何包含数字值的字符串
注意: 如果您正在键盘上输入通配符模式,并且其中包含一个特殊字符,您必须将模式放在引号中("*"),使用反斜杠(\*),或使用命令行支持的任何转义机制。
通配符语法功能强大且易于使用。但是,如果它不满足您的需求,您也可以使用正则表达式。有关更多信息,请参阅正则表达式 课程。
有关通配符语法的更多信息,请参阅FileSystem 类中 getPathMatcher 方法的 API 规范。
链接感知
Files 类是"链接感知"的。每个 Files 方法都会检测在遇到符号链接时该做什么,或者提供一个选项,使您能够配置在遇到符号链接时的行为。
检查文件或目录
您有一个代表文件或目录的Path实例,但该文件是否存在于文件系统中?它是否可读?可写?可执行?
验证文件或目录的存在
Path类中的方法是语法的,意味着它们在Path实例上操作。但最终您必须访问文件系统来验证特定的Path是否存在或不存在。您可以使用exists(Path, LinkOption...)和notExists(Path, LinkOption...)方法。请注意,!Files.exists(path)并不等同于Files.notExists(path)。当您测试文件的存在时,可能有三种结果:
-
验证文件存在。
-
验证文件不存在。
-
文件的状态未知。当程序无法访问文件时,会出现此结果。
如果exists和notExists都返回false,则无法验证文件的存在。
检查文件的可访问性
要验证程序是否可以按需访问文件,可以使用isReadable(Path)、isWritable(Path)和isExecutable(Path)方法。
以下代码片段验证特定文件是否存在,并且程序是否有执行文件的能力。
Path file = ...;
boolean isRegularExecutableFile = Files.isRegularFile(file) &
Files.isReadable(file) & Files.isExecutable(file);
注意: 一旦其中任何方法完成,就不能保证可以访问文件。许多应用程序中的常见安全漏洞是执行检查然后访问文件。要获取更多信息,请使用您喜欢的搜索引擎查找TOCTTOU(发音为TOCK-too)。
检查两个路径是否定位到相同文件
当您有一个使用符号链接的文件系统时,可能会有两个不同的路径定位到同一个文件。isSameFile(Path, Path)方法比较两个路径,以确定它们是否在文件系统上定位到同一个文件。例如:
Path p1 = ...;
Path p2 = ...;
if (Files.isSameFile(p1, p2)) {
// Logic when the paths locate the same file
}
删除文件或目录
您可以删除文件、目录或链接。对于符号链接,删除的是链接本身而不是链接的目标。对于目录,目录必须为空,否则删除操作将失败。
Files类提供了两种删除方法。
delete(Path)方法会删除文件,如果删除失败则会抛出异常。例如,如果文件不存在,则会抛出NoSuchFileException异常。您可以捕获异常以确定删除失败的原因,如下所示:
try {
Files.delete(path);
} catch (NoSuchFileException x) {
System.err.format("%s: no such" + " file or directory%n", path);
} catch (DirectoryNotEmptyException x) {
System.err.format("%s not empty%n", path);
} catch (IOException x) {
// File permission problems are caught here.
System.err.println(x);
}
deleteIfExists(Path)方法也会删除文件,但如果文件不存在,则不会抛出异常。静默失败在您有多个线程删除文件时很有用,您不希望仅因为一个线程先执行删除操作就抛出异常。
复制文件或目录
您可以使用copy(Path, Path, CopyOption...)方法复制文件或目录。如果目标文件存在,则复制将失败,除非指定了REPLACE_EXISTING选项。
目录可以被复制。但是,目录内的文件不会被复制,因此即使原始目录包含文件,新目录也是空的。
复制符号链接时,会复制链接的目标。如果要复制链接本身而不是链接的内容,请指定NOFOLLOW_LINKS或REPLACE_EXISTING选项。
这种方法接受可变参数。支持以下StandardCopyOption和LinkOption枚举:
-
REPLACE_EXISTING– 即使目标文件已经存在,也执行复制。如果目标是符号链接,则复制链接本身(而不是链接的目标)。如果目标是非空目录,则复制将失败,并显示DirectoryNotEmptyException异常。 -
COPY_ATTRIBUTES– 复制与文件关联的文件属性到目标文件。支持的确切文件属性取决于文件系统和平台,但last-modified-time在各个平台上都受支持,并且会被复制到目标文件。 -
NOFOLLOW_LINKS– 表示不应跟随符号链接。如果要复制的文件是符号链接,则复制链接本身(而不是链接的目标)。
如果您不熟悉enums,请参见枚举类型。
以下显示了如何使用copy方法:
import static java.nio.file.StandardCopyOption.*;
...
Files.copy(source, target, REPLACE_EXISTING);
除了文件复制外,Files类还定义了可用于文件和流之间复制的方法。copy(InputStream, Path, CopyOptions...)方法可用于将输入流的所有字节复制到文件。copy(Path, OutputStream)方法可用于将文件的所有字节复制到输出流。
Copy示例使用copy和Files.walkFileTree方法支持递归复制。有关更多信息,请参见遍历文件树。
移动文件或目录
您可以使用move(Path, Path, CopyOption...)方法移动文件或目录。如果目标文件存在,则移动失败,除非指定了REPLACE_EXISTING选项。
空目录可以被移动。如果目录不为空,只有当可以移动目录而不移动该目录的内容时才允许移动。在 UNIX 系统上,将目录移动到同一分区通常是重命名目录。在这种情况下,即使目录包含文件,此方法也有效。
此方法接受可变参数 – 支持以下StandardCopyOption枚举:
-
REPLACE_EXISTING– 即使目标文件已经存在,也执行移动操作。如果目标是一个符号链接,符号链接会被替换,但它指向的内容不受影响。 -
ATOMIC_MOVE– 将移动操作作为原子文件操作执行。如果文件系统不支持原子移动,则会抛出异常。使用ATOMIC_MOVE,您可以将文件移动到目录中,并确保任何监视目录的进程访问完整文件。
以下展示了如何使用move方法:
import static java.nio.file.StandardCopyOption.*;
...
Files.move(source, target, REPLACE_EXISTING);
尽管可以像所示在单个目录上实现move方法,但该方法通常与文件树递归机制一起使用。有关更多信息,请参见遍历文件树。
管理元数据(文件和文件存储属性)
原文:
docs.oracle.com/javase/tutorial/essential/io/fileAttr.html
元数据的定义是“关于其他数据的数据”。在文件系统中,数据包含在其文件和目录中,元数据跟踪每个对象的信息:它是一个常规文件、目录还是链接?它的大小、创建日期、最后修改日期、文件所有者、组所有者和访问权限是什么?
文件系统的元数据通常被称为其文件属性。Files类包括可用于获取文件的单个属性或设置属性的方法。
| 方法 | 说明 |
|---|---|
size(Path) |
返回指定文件的大小(以字节为单位)。 |
isDirectory(Path, LinkOption) |
如果指定的Path定位到一个目录,则返回 true。 |
isRegularFile(Path, LinkOption...) |
如果指定的Path定位到一个常规文件,则返回 true。 |
isSymbolicLink(Path) |
如果指定的Path定位到一个符号链接文件,则返回 true。 |
isHidden(Path) |
如果指定的Path定位到文件系统认为是隐藏的文件,则返回 true。 |
getLastModifiedTime(Path, LinkOption...) setLastModifiedTime(Path, FileTime) |
返回或设置指定文件的最后修改时间。 |
getOwner(Path, LinkOption...) setOwner(Path, UserPrincipal) |
返回或设置文件的所有者。 |
getPosixFilePermissions(Path, LinkOption...) setPosixFilePermissions(Path, Set<PosixFilePermission>) |
返回或设置文件的 POSIX 文件权限。 |
getAttribute(Path, String, LinkOption...) setAttribute(Path, String, Object, LinkOption...) |
返回或设置文件属性的值。 |
如果程序需要同时获取多个文件属性,使用检索单个属性的方法可能效率低下。反复访问文件系统以检索单个属性可能会对性能产生不利影响。因此,Files 类提供了两个 readAttributes 方法,以便一次性获取文件的属性。
| 方法 | 注释 |
|---|---|
readAttributes(Path, String, LinkOption...) |
作为批量操作读取文件的属性。String 参数标识要读取的属性。 |
readAttributes(Path, Class<A>, LinkOption...) |
作为批量操作读取文件的属性。Class<A> 参数是请求的属性类型,该方法返回该类的对象。 |
在展示 readAttributes 方法的示例之前,应该提到不同的文件系统对应该跟踪哪些属性有不同的概念。因此,相关文件属性被分组到视图中。视图 映射到特定的文件系统实现,如 POSIX 或 DOS,或者映射到常见功能,如文件所有权。
支持的视图如下:
-
BasicFileAttributeView– 提供必须由所有文件系统实现支持的基本属性视图。 -
DosFileAttributeView– 将基本属性视图扩展为在支持 DOS 属性的文件系统上支持的标准四位。 -
PosixFileAttributeView– 将基本属性视图扩展到支持 POSIX 标准族的文件系统上支持的属性,例如 UNIX。这些属性包括文件所有者、组所有者和九个相关的访问权限。 -
FileOwnerAttributeView– 受到支持文件所有者概念的任何文件系统实现支持。 -
AclFileAttributeView– 支持读取或更新文件的访问控制列表(ACL)。支持 NFSv4 ACL 模型。任何 ACL 模型,例如 Windows ACL 模型,如果与 NFSv4 模型有明确定义的映射,也可能受支持。 -
UserDefinedFileAttributeView– 支持用户定义的元数据。此视图可以映射到系统支持的任何扩展机制。例如,在 Solaris 操作系统中,您可以使用此视图存储文件的 MIME 类型。
特定的文件系统实现可能仅支持基本文件属性视图,或者可能支持其中几个文件属性视图。文件系统实现可能支持此 API 中未包含的其他属性视图。
在大多数情况下,您不应直接处理任何 FileAttributeView 接口。(如果您确实需要直接使用 FileAttributeView,可以通过 getFileAttributeView(Path, Class<V>, LinkOption...) 方法访问它。)
readAttributes 方法使用泛型,可用于读取任何文件属性视图的属性。本页其余部分的示例使用 readAttributes 方法。
本节的其余部分涵盖以下主题:
-
基本文件属性
-
设置时间戳
-
DOS 文件属性
-
POSIX 文件权限
-
设置文件或组所有者
-
用户定义的文件属性
-
文件存储属性
基本文件属性
如前所述,要读取文件的基本属性,可以使用 Files.readAttributes 方法之一,该方法一次性读取所有基本属性。这比单独访问文件系统以读取每个单独属性要高效得多。可变参数参数当前支持 LinkOption 枚举,NOFOLLOW_LINKS。当您不希望跟随符号链接时,请使用此选项。
关于时间戳的说明:基本属性集包括三个时间戳:creationTime、lastModifiedTime和lastAccessTime。 在特定实现中,这些时间戳中的任何一个可能不受支持,如果不支持,则相应的访问器方法返回一个特定于实现的值。 当支持时,时间戳作为FileTime对象返回。
以下代码片段读取并打印给定文件的基本文件属性,并使用BasicFileAttributes类中的方法。
Path file = ...;
BasicFileAttributes attr = Files.readAttributes(file, BasicFileAttributes.class);
System.out.println("creationTime: " + attr.creationTime());
System.out.println("lastAccessTime: " + attr.lastAccessTime());
System.out.println("lastModifiedTime: " + attr.lastModifiedTime());
System.out.println("isDirectory: " + attr.isDirectory());
System.out.println("isOther: " + attr.isOther());
System.out.println("isRegularFile: " + attr.isRegularFile());
System.out.println("isSymbolicLink: " + attr.isSymbolicLink());
System.out.println("size: " + attr.size());
除了本示例中显示的访问器方法之外,还有一个fileKey方法,返回一个唯一标识文件的对象,如果没有文件键可用,则返回null。
设置时间戳
以下代码片段设置最后修改时间(以毫秒为单位):
Path file = ...;
BasicFileAttributes attr =
Files.readAttributes(file, BasicFileAttributes.class);
long currentTime = System.currentTimeMillis();
FileTime ft = FileTime.fromMillis(currentTime);
Files.setLastModifiedTime(file, ft);
}
DOS 文件属性
DOS 文件属性也受支持于除 DOS 外的其他文件系统,如 Samba。 以下代码片段使用DosFileAttributes类的方法。
Path file = ...;
try {
DosFileAttributes attr =
Files.readAttributes(file, DosFileAttributes.class);
System.out.println("isReadOnly is " + attr.isReadOnly());
System.out.println("isHidden is " + attr.isHidden());
System.out.println("isArchive is " + attr.isArchive());
System.out.println("isSystem is " + attr.isSystem());
} catch (UnsupportedOperationException x) {
System.err.println("DOS file" +
" attributes not supported:" + x);
}
但是,您可以使用setAttribute(Path, String, Object, LinkOption...)方法设置 DOS 属性,如下所示:
Path file = ...;
Files.setAttribute(file, "dos:hidden", true);
POSIX 文件权限
POSIX是 UNIX 可移植操作系统接口的缩写,是一组 IEEE 和 ISO 标准,旨在确保不同 UNIX 变种之间的互操作性。 如果程序符合这些 POSIX 标准,它应该很容易移植到其他符合 POSIX 标准的操作系统。
除了文件所有者和组所有者,POSIX 还支持九种文件权限:文件所有者、同一组成员和“其他所有人”的读取、写入和执行权限。
以下代码片段读取给定文件的 POSIX 文件属性,并将其打印到标准输出。 该代码使用PosixFileAttributes类中的方法。
Path file = ...;
PosixFileAttributes attr =
Files.readAttributes(file, PosixFileAttributes.class);
System.out.format("%s %s %s%n",
attr.owner().getName(),
attr.group().getName(),
PosixFilePermissions.toString(attr.permissions()));
PosixFilePermissions辅助类提供了几个有用的方法,如下所示:
-
toString方法,在前面的代码片段中使用,将文件权限转换为字符串(例如,rw-r--r--)。 -
fromString方法接受表示文件权限的字符串并构造一个文件权限的Set。 -
asFileAttribute方法接受一个文件权限的Set并构造一个可传递给Path.createFile或Path.createDirectory方法的文件属性。
以下代码片段从一个文件中读取属性并创建一个新文件,将原始文件的属性分配给新文件:
Path sourceFile = ...;
Path newFile = ...;
PosixFileAttributes attrs =
Files.readAttributes(sourceFile, PosixFileAttributes.class);
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(attrs.permissions());
Files.createFile(file, attr);
asFileAttribute方法将权限包装为FileAttribute。然后代码尝试使用这些权限创建一个新文件。请注意,umask也适用,因此新文件可能比请求的权限更安全。
要将文件的权限设置为表示为硬编码字符串的值,可以使用以下代码:
Path file = ...;
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rw-------");
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(perms);
Files.setPosixFilePermissions(file, perms);
Chmod示例递归更改文件权限,类似于chmod实用程序。
设置文件或组所有者
要将名称翻译为可存储为文件所有者或组所有者的对象,您可以使用UserPrincipalLookupService服务。此服务查找一个字符串作为名称或组名称,并返回表示该字符串的UserPrincipal对象。您可以通过使用FileSystem.getUserPrincipalLookupService方法获取默认文件系统的用户主体查找服务。
以下代码片段显示了如何使用setOwner方法设置文件所有者:
Path file = ...;
UserPrincipal owner = file.GetFileSystem().getUserPrincipalLookupService()
.lookupPrincipalByName("sally");
Files.setOwner(file, owner);
Files类中没有专门用于设置组所有者的方法。但是,直接通过 POSIX 文件属性视图安全地执行此操作的方法如下:
Path file = ...;
GroupPrincipal group =
file.getFileSystem().getUserPrincipalLookupService()
.lookupPrincipalByGroupName("green");
Files.getFileAttributeView(file, PosixFileAttributeView.class)
.setGroup(group);
用户定义的文件属性
如果您的文件系统实现支持的文件属性不足以满足您的需求,您可以使用UserDefinedAttributeView来创建和跟踪自己的文件属性。
一些实现将这个概念映射到诸如 NTFS 替代数据流和文件系统(如 ext3 和 ZFS)上的扩展属性等功能。大多数实现对值的大小施加限制,例如,ext3 将大小限制为 4 千字节。
文件的 MIME 类型可以使用此代码片段存储为用户定义的属性:
Path file = ...;
UserDefinedFileAttributeView view = Files
.getFileAttributeView(file, UserDefinedFileAttributeView.class);
view.write("user.mimetype",
Charset.defaultCharset().encode("text/html");
要读取 MIME 类型属性,您可以使用以下代码片段:
Path file = ...;
UserDefinedFileAttributeView view = Files
.getFileAttributeView(file,UserDefinedFileAttributeView.class);
String name = "user.mimetype";
ByteBuffer buf = ByteBuffer.allocate(view.size(name));
view.read(name, buf);
buf.flip();
String value = Charset.defaultCharset().decode(buf).toString();
Xdd示例显示了如何获取、设置和删除用户定义的属性。
注意:在 Linux 中,您可能需要启用扩展属性才能使用户定义的属性起作用。如果尝试访问用户定义的属性视图时收到UnsupportedOperationException,则需要重新挂载文件系统。以下命令重新挂载具有 ext3 文件系统扩展属性的根分区。如果此命令对您的 Linux 版本不起作用,请参考文档。
$ sudo mount -o remount,user_xattr /
如果要使更改永久生效,请向/etc/fstab添加条目。
文件存储属性
您可以使用FileStore类来了解文件存储的信息,例如可用空间有多少。getFileStore(Path)方法获取指定文件的文件存储。
以下代码片段打印了特定文件所在文件存储的空间使用情况:
Path file = ...;
FileStore store = Files.getFileStore(file);
long total = store.getTotalSpace() / 1024;
long used = (store.getTotalSpace() -
store.getUnallocatedSpace()) / 1024;
long avail = store.getUsableSpace() / 1024;
DiskUsage示例使用此 API 打印默认文件系统中所有存储的磁盘空间信息。此示例使用FileSystem类中的getFileStores方法来获取文件系统的所有文件存储。
读取、写入和创建文件
本页讨论了读取、写入、创建和打开文件的详细信息。有各种文件 I/O 方法可供选择。为了帮助理解 API,以下图表按复杂性排列了文件 I/O 方法。
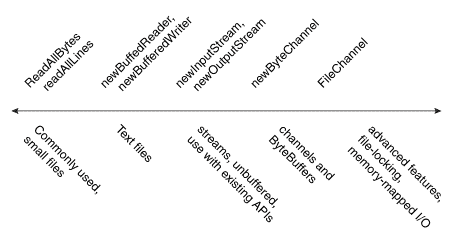 从简单到复杂排列的文件 I/O 方法
从简单到复杂排列的文件 I/O 方法
在图表的最左侧是实用方法readAllBytes、readAllLines和write方法,设计用于简单、常见情况。在这些方法的右侧是用于迭代流或文本行的方法,如newBufferedReader、newBufferedWriter,然后是newInputStream和newOutputStream。这些方法与java.io包兼容。在这些方法的右侧是处理ByteChannels、SeekableByteChannels和ByteBuffers的方法,如newByteChannel方法。最后,在最右侧是使用FileChannel进行文件锁定或内存映射 I/O 的高级应用的方法。
注意: 创建新文件的方法使您能够为文件指定一组可选的初始属性。例如,在支持 POSIX 标准集(如 UNIX)的文件系统上,您可以在创建文件时指定文件所有者、组所有者或文件权限。管理元数据页面解释了文件属性,以及如何访问和设置它们。
本页包含以下主题:
-
打开选项
-
小文件常用方法
-
文本文件的缓冲 I/O 方法
-
无缓冲流和与
java.ioAPI 兼容的方法 -
通道和
ByteBuffers的方法 -
创建常规和临时文件的方法
打开选项
本节中的几种方法采用可选的OpenOptions参数。此参数是可选的,API 会告诉您当未指定时方法的默认行为是什么。
支持以下StandardOpenOptions枚举:
-
WRITE– 打开文件以进行写访问。 -
APPEND– 将新数据追加到文件末尾。此选项与WRITE或CREATE选项一起使用。 -
TRUNCATE_EXISTING– 将文件截断为零字节。此选项与WRITE选项一起使用。 -
CREATE_NEW– 创建新文件,并在文件已存在时抛出异常。 -
CREATE– 如果文件存在则打开文件,如果不存在则创建新文件。 -
DELETE_ON_CLOSE– 在流关闭时删除文件。此选项对临时文件很有用。 -
SPARSE– 暗示新创建的文件将是稀疏的。这个高级选项在一些文件系统上得到支持,比如 NTFS,在这些文件系统中,具有数据“间隙”的大文件可以以更有效的方式存储,其中这些空白间隙不会占用磁盘空间。 -
SYNC– 保持文件(内容和元数据)与底层存储设备同步。 -
DSYNC– 保持文件内容与底层存储设备同步。
小文件常用方法
从文件中读取所有字节或行
如果您有一个相对较小的文件,并且希望一次读取其全部内容,您可以使用readAllBytes(Path)或readAllLines(Path, Charset)方法。这些方法会为您处理大部分工作,比如打开和关闭流,但不适用于处理大文件。以下代码展示了如何使用readAllBytes方法:
Path file = ...;
byte[] fileArray;
fileArray = Files.readAllBytes(file);
将所有字节或行写入文件
您可以使用其中一种写入方法将字节或行写入文件。
以下代码片段展示了如何使用write方法。
Path file = ...;
byte[] buf = ...;
Files.write(file, buf);
用于文本文件的缓冲 I/O 方法
java.nio.file包支持通道 I/O,它通过缓冲区传输数据,绕过了一些可能成为流 I/O 瓶颈的层。
使用缓冲流 I/O 读取文件
newBufferedReader(Path, Charset)方法打开一个文件进行读取,返回一个BufferedReader,可用于以高效的方式从文件中读取文本。
以下代码片段展示了如何使用newBufferedReader方法从文件中读取内容。该文件以"US-ASCII"编码。
Charset charset = Charset.forName("US-ASCII");
try (BufferedReader reader = Files.newBufferedReader(file, charset)) {
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
使用缓冲流 I/O 写入文件
您可以使用newBufferedWriter(Path, Charset, OpenOption...)方法使用BufferedWriter写入文件。
以下代码片段展示了如何使用这种方法创建一个以"US-ASCII"编码的文件:
Charset charset = Charset.forName("US-ASCII");
String s = ...;
try (BufferedWriter writer = Files.newBufferedWriter(file, charset)) {
writer.write(s, 0, s.length());
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
用于非缓冲流和与java.ioAPI 互操作的方法
使用流 I/O 读取文件
要打开文件进行读取,您可以使用newInputStream(Path, OpenOption...)方法。该方法返回一个用于从文件中读取字节的无缓冲输入流。
Path file = ...;
try (InputStream in = Files.newInputStream(file);
BufferedReader reader =
new BufferedReader(new InputStreamReader(in))) {
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException x) {
System.err.println(x);
}
通过流 I/O 创建和写入文件
您可以通过使用newOutputStream(Path, OpenOption...)方法创建文件,追加到文件或向文件写入内容。该方法打开或创建一个文件以写入字节,并返回一个无缓冲的输出流。
该方法接受一个可选的OpenOption参数。如果未指定任何打开选项,并且文件不存在,则会创建一个新文件。如果文件存在,则会被截断。此选项等同于使用CREATE和TRUNCATE_EXISTING选项调用该方法。
以下示例打开一个日志文件。如果文件不存在,则会创建该文件。如果文件存在,则会以追加方式打开。
import static java.nio.file.StandardOpenOption.*;
import java.nio.file.*;
import java.io.*;
public class LogFileTest {
public static void main(String[] args) {
// Convert the string to a
// byte array.
String s = "Hello World! ";
byte data[] = s.getBytes();
Path p = Paths.get("./logfile.txt");
try (OutputStream out = new BufferedOutputStream(
Files.newOutputStream(p, CREATE, APPEND))) {
out.write(data, 0, data.length);
} catch (IOException x) {
System.err.println(x);
}
}
}
通道和ByteBuffers的方法
通过使用通道 I/O 读取和写入文件
流 I/O 每次读取一个字符,而通道 I/O 每次读取一个缓冲区。ByteChannel接口提供基本的read和write功能。SeekableByteChannel是一个具有在通道中保持位置并更改该位置能力的ByteChannel。SeekableByteChannel还支持截断与通道关联的文件并查询文件的大小。
在文件中移动到不同位置然后从该位置读取或写入使得文件的随机访问成为可能。查看随机访问文件获取更多信息。
有两种读取和写入通道 I/O 的方法。
注意: newByteChannel方法返回一个SeekableByteChannel的实例。对于默认文件系统,您可以将此可寻址字节通道转换为FileChannel,从而提供对更高级功能的访问,例如将文件的某个区域直接映射到内存以实现更快的访问,锁定文件的某个区域以防其他进程访问,或者从绝对位置读取和写入字节而不影响通道的当前位置。
两个newByteChannel方法都允许你指定一系列OpenOption选项。除了支持newOutputStream方法使用的相同打开选项外,还支持一个额外的选项:READ是必需的,因为SeekableByteChannel支持读取和写入。
指定READ打开通道以进行读取。指定WRITE或APPEND打开通道以进行写入。如果没有指定这些选项中的任何一个,则通道将被打开以进行读取。
下面的代码片段读取一个文件并将其打印到标准输出:
public static void readFile(Path path) throws IOException {
// Files.newByteChannel() defaults to StandardOpenOption.READ
try (SeekableByteChannel sbc = Files.newByteChannel(path)) {
final int BUFFER_CAPACITY = 10;
ByteBuffer buf = ByteBuffer.allocate(BUFFER_CAPACITY);
// Read the bytes with the proper encoding for this platform. If
// you skip this step, you might see foreign or illegible
// characters.
String encoding = System.getProperty("file.encoding");
while (sbc.read(buf) > 0) {
buf.flip();
System.out.print(Charset.forName(encoding).decode(buf));
buf.clear();
}
}
}
下面的示例是为 UNIX 和其他 POSIX 文件系统编写的,它创建了一个具有特定文件权限集的日志文件。这段代码将创建一个日志文件,如果该文件已经存在,则追加到日志文件中。该日志文件为所有者提供读写权限,为组提供只读权限。
import static java.nio.file.StandardOpenOption.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.file.*;
import java.nio.file.attribute.*;
import java.io.*;
import java.util.*;
public class LogFilePermissionsTest {
public static void main(String[] args) {
// Create the set of options for appending to the file.
Set<OpenOption> options = new HashSet<OpenOption>();
options.add(APPEND);
options.add(CREATE);
// Create the custom permissions attribute.
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rw-r-----");
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(perms);
// Convert the string to a ByteBuffer.
String s = "Hello World! ";
byte data[] = s.getBytes();
ByteBuffer bb = ByteBuffer.wrap(data);
Path file = Paths.get("./permissions.log");
try (SeekableByteChannel sbc =
Files.newByteChannel(file, options, attr)) {
sbc.write(bb);
} catch (IOException x) {
System.out.println("Exception thrown: " + x);
}
}
}
创建常规和临时文件的方法
创建文件
你可以使用createFile(Path, FileAttribute<?>)方法创建一个具有初始属性集的空文件。例如,如果在创建时你想要文件具有特定的文件权限集,可以使用createFile方法来实现。如果你没有指定任何属性,文件将使用默认属性创建。如果文件已经存在,createFile会抛出异常。
在单个原子操作中,createFile方法检查文件是否存在,并使用指定的属性创建该文件,这使得该过程更加安全,防止恶意代码。
下面的代码片段创建一个具有默认属性的文件:
Path file = ...;
try {
// Create the empty file with default permissions, etc.
Files.createFile(file);
} catch (FileAlreadyExistsException x) {
System.err.format("file named %s" +
" already exists%n", file);
} catch (IOException x) {
// Some other sort of failure, such as permissions.
System.err.format("createFile error: %s%n", x);
}
POSIX 文件权限有一个示例,使用createFile(Path, FileAttribute<?>)创建一个具有预设权限的文件。
你也可以使用newOutputStream方法创建一个新文件,如使用流 I/O 创建和写入文件中所述。如果你打开一个新的输出流并立即关闭它,将会创建一个空文件。
创建临时文件
你可以使用以下createTempFile方法之一创建一个临时文件:
第一种方法允许代码指定一个临时文件的目录,而第二种方法则在默认临时文件目录中创建一个新文件。这两种方法都允许你为文件名指定后缀,而第一种方法还允许你指定前缀。以下代码片段给出了第二种方法的示例:
try {
Path tempFile = Files.createTempFile(null, ".myapp");
System.out.format("The temporary file" +
" has been created: %s%n", tempFile)
;
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
运行此文件的结果将类似于以下内容:
The temporary file has been created: /tmp/509668702974537184.myapp
临时文件名的具体格式取决于平台。
随机访问文件
随机访问文件允许对文件内容进行非顺序或随机访问。要随机访问文件,您需要打开文件,寻找特定位置,并从该位置读取或写入文件。
这种功能是通过SeekableByteChannel接口实现的。SeekableByteChannel接口扩展了通道 I/O 的概念,具有当前位置的概念。方法使您能够设置或查询位置,然后可以从该位置读取数据或将数据写入该位置。API 由一些易于使用的方法组成:
-
position– 返回通道的当前位置 -
position(long)– 设置通道的位置 -
read(ByteBuffer)– 从通道读取字节到缓冲区 -
write(ByteBuffer)– 将缓冲区中的字节写入通道 -
truncate(long)– 截断与通道连接的文件(或其他实体)
使用通道 I/O 读写文件 显示Path.newByteChannel方法返回SeekableByteChannel的实例。在默认文件系统上,您可以直接使用该通道,或者将其转换为FileChannel,从而可以访问更高级的功能,例如将文件的某个区域直接映射到内存以实现更快的访问,锁定文件的某个区域,或者从绝对位置读取和写入字节而不影响通道的当前位置。
以下代码片段通过使用newByteChannel方法打开文件进行读写。返回的SeekableByteChannel被转换为FileChannel。然后,从文件开头读取 12 个字节,并在该位置写入字符串"I was here!"。文件中的当前位置移动到末尾,并将开头的 12 个字节追加。最后,追加字符串"I was here!",并关闭文件上的通道。
String s = "I was here!\n";
byte data[] = s.getBytes();
ByteBuffer out = ByteBuffer.wrap(data);
ByteBuffer copy = ByteBuffer.allocate(12);
try (FileChannel fc = (FileChannel.open(file, READ, WRITE))) {
// Read the first 12
// bytes of the file.
int nread;
do {
nread = fc.read(copy);
} while (nread != -1 && copy.hasRemaining());
// Write "I was here!" at the beginning of the file.
fc.position(0);
while (out.hasRemaining())
fc.write(out);
out.rewind();
// Move to the end of the file. Copy the first 12 bytes to
// the end of the file. Then write "I was here!" again.
long length = fc.size();
fc.position(length-1);
copy.flip();
while (copy.hasRemaining())
fc.write(copy);
while (out.hasRemaining())
fc.write(out);
} catch (IOException x) {
System.out.println("I/O Exception: " + x);
}
创建和读取目录
其中一些先前讨论过的方法,如delete,适用于文件、链接和目录。但是如何列出文件系统顶部的所有目录?如何列出目录的内容或创建目录?
本节涵盖了以下特定于目录的功能:
-
列出文件系统的根目录
-
创建目录
-
创建临时目录
-
列出目录的内容
-
通过使用 Globbing 筛选目录列表
-
编写自己的目录过滤器
列出文件系统的根目录
您可以使用FileSystem.getRootDirectories方法列出文件系统的所有根目录。此方法返回一个Iterable,使您可以使用增强型 for 语句遍历所有根目录。
以下代码片段打印默认文件系统的根目录:
Iterable<Path> dirs = FileSystems.getDefault().getRootDirectories();
for (Path name: dirs) {
System.err.println(name);
}
创建目录
您可以使用createDirectory(Path, FileAttribute<?>)方法创建一个新目录。如果不指定任何FileAttributes,新目录将具有默认属性。例如:
Path dir = ...;
Files.createDirectory(path);
以下代码片段在具有特定权限的 POSIX 文件系统上创建一个新目录:
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rwxr-x---");
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(perms);
Files.createDirectory(file, attr);
要在可能尚不存在一个或多个父目录的情况下创建几层深的目录,您可以使用方便的方法createDirectories(Path, FileAttribute<?>)。与createDirectory(Path, FileAttribute<?>)方法一样,您可以指定一组可选的初始文件属性。以下代码片段使用默认属性:
Files.createDirectories(Paths.get("foo/bar/test"));
目录是按需自上而下创建的。在foo/bar/test示例中,如果foo目录不存在,则会创建它。接下来,如果需要,将创建bar目录,最后创建test目录。
在创建一些但不是所有父目录后,此方法可能会失败。
创建临时目录
你可以使用createTempDirectory方法之一创建临时目录:
第一个方法允许代码指定临时目录的位置,第二个方法在默认临时文件目录中创建一个新目录。
列出目录的内容
您可以使用newDirectoryStream(Path)方法列出目录的所有内容。此方法返回一个实现了DirectoryStream接口的对象。实现DirectoryStream接口的类还实现了Iterable,因此您可以遍历目录流,读取所有对象。这种方法适用于非常大的目录。
记住: 返回的DirectoryStream是一个流。如果你没有使用try-with-resources 语句,请不要忘记在finally块中关闭流。try-with-resources 语句会为您处理这个问题。
以下代码片段展示了如何打印目录的内容:
Path dir = ...;
try (DirectoryStream<Path> stream = Files.newDirectoryStream(dir)) {
for (Path file: stream) {
System.out.println(file.getFileName());
}
} catch (IOException | DirectoryIteratorException x) {
// IOException can never be thrown by the iteration.
// In this snippet, it can only be thrown by newDirectoryStream.
System.err.println(x);
}
迭代器返回的Path对象是相对于目录解析的条目名称。因此,如果您正在列出/tmp目录的内容,则条目将以/tmp/a、/tmp/b等形式返回。
此方法返回目录的全部内容:文件、链接、子目录和隐藏文件。如果您想更有选择地检索内容,可以使用本页后面描述的其他newDirectoryStream方法之一。
请注意,如果在目录迭代过程中出现异常,则会抛出DirectoryIteratorException,其原因是IOException。迭代器方法不能抛出异常。
通过使用 Globbing 筛选目录列表
如果您只想获取文件和子目录,其中每个名称都匹配特定模式,可以使用newDirectoryStream(Path, String)方法,该方法提供了内置的 glob 过滤器。如果您不熟悉 glob 语法,请参阅什么是 Glob?
例如,以下代码片段列出了与 Java 相关的文件:.class,.java和.jar文件。
Path dir = ...;
try (DirectoryStream<Path> stream =
Files.newDirectoryStream(dir, "*.{java,class,jar}")) {
for (Path entry: stream) {
System.out.println(entry.getFileName());
}
} catch (IOException x) {
// IOException can never be thrown by the iteration.
// In this snippet, it can // only be thrown by newDirectoryStream.
System.err.println(x);
}
编写自己的目录过滤器
也许您想要根据除了模式匹配之外的某些条件来过滤目录的内容。您可以通过实现DirectoryStream.Filter<T>接口来创建自己的过滤器。该接口由一个方法accept组成,用于确定文件是否满足搜索要求。
例如,以下代码片段实现了一个仅检索目录的过滤器:
DirectoryStream.Filter<Path> filter =
newDirectoryStream.Filter<Path>() {
public boolean accept(Path file) throws IOException {
try {
return (Files.isDirectory(path));
} catch (IOException x) {
// Failed to determine if it's a directory.
System.err.println(x);
return false;
}
}
};
一旦过滤器被创建,就可以通过使用newDirectoryStream(Path, DirectoryStream.Filter<? super Path>)方法来调用它。以下代码片段使用isDirectory过滤器仅将目录的子目录打印到标准输出:
Path dir = ...;
try (DirectoryStream<Path>
stream = Files.newDirectoryStream(dir, filter)) {
for (Path entry: stream) {
System.out.println(entry.getFileName());
}
} catch (IOException x) {
System.err.println(x);
}
此方法仅用于过滤单个目录。然而,如果您想要在文件树中找到所有子目录,您将使用遍历文件树的机制。
标签:文件,教程,Java,file,System,2022,Path,方法,out From: https://www.cnblogs.com/apachecn/p/18131099