咦咦咦,各位小可爱,我是你们的好伙伴——bug菌,今天又来给大家普及Java之IO流啦,别躲起来啊,听我讲干货还不快点赞,赞多了我就有动力讲得更嗨啦!所以呀,养成先点赞后阅读的好习惯,别被干货淹没了哦~
前言
Java I/O 是 Java 编程语言的核心功能之一,提供了丰富的输入输出操作。在 Java I/O 中,FilterInputStream 是一个非常有用的类,它允许对输入流进行装饰,以增强其功能。本文将深入讲解 FilterInputStream 的实现原理以及在实际开发中的应用。
摘要
FilterInputStream 是 InputStream 的子类,它提供了对输入流的装饰功能,可以通过组合多个 FilterInputStream 对输入流进行多层装饰,以实现更加复杂的功能。
本文将详细介绍 FilterInputStream 的原理以及如何使用它进行输入流装饰。
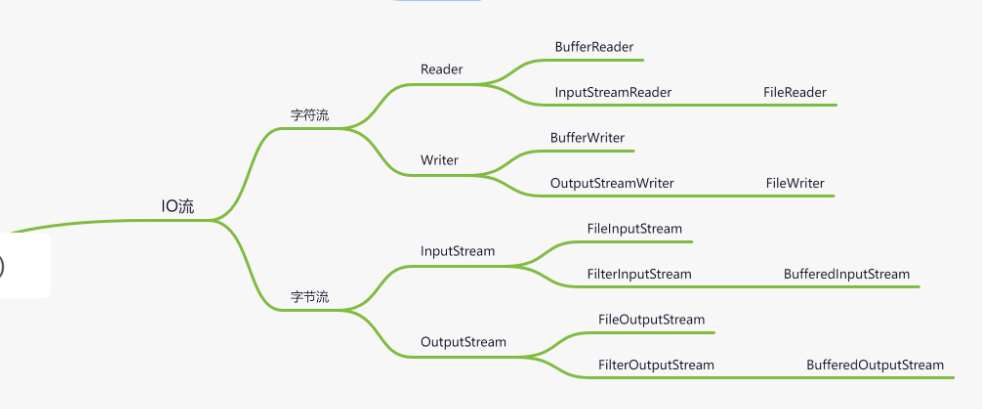
FilterInputStream
概念
FilterInputStream是Java中的一个抽象类,属于输入流的一种包装类。它继承自InputStream类,并实现了mark()和reset()等方法。FilterInputStream的作用是对底层的输入流进行包装和过滤,提供额外的功能和操作。
FilterInputStream的工作原理是通过将底层的输入流作为参数传递给构造函数,并在读取数据时对数据进行过滤或处理。它模拟了装饰器模式的思想,可以在不改变底层输入流的基础上,对数据进行包装、过滤或加工。
FilterInputStream并不是直接实现数据的读取和处理,而是将这些操作委托给底层的输入流。它的主要目的是为了提供更高级别的功能和灵活性,通过添加额外的功能层来改变原始输入流的行为。
FilterInputStream的一些具体实现类例如:
BufferedInputStream:提供了缓冲功能,减少对底层输入流的频繁读取操作,提升性能。DataInputStream:提供了读取各种基本数据类型的方法,对底层输入流进行了数据解析和类型转换。InflaterInputStream:提供了解压缩功能,可将底层输入流中的压缩数据解压缩为原始数据。PushbackInputStream:提供了回推(Pushback)功能,可将读取到的数据重新放回输入流中,以便重复读取。
通过使用FilterInputStream,我们可以对底层输入流进行多种操作和处理,从而满足不同的需求,例如解密数据、压缩数据、解析特定格式的数据等。它在Java的输入流处理中起到了重要的作用,提供了灵活性和可扩展性。
FilterInputStream 的原理
FilterInputStream 接收一个 InputStream 对象并提供了对输入流的装饰功能。它包装了一个现有的 InputStream 并向其添加一些额外的功能。FilterInputStream 的所有方法都委托给其被包装的 InputStream 对象。在装饰过程中,我们可以在方法调用前或调用后进行一些额外的操作。
每个 FilterInputStream 子类都需要实现至少四种方法:read()、read(byte[] b, int off, int len)、skip(long n) 和 available()。这些方法应该根据被装饰的 InputStream 的规范进行实现。
源码分析
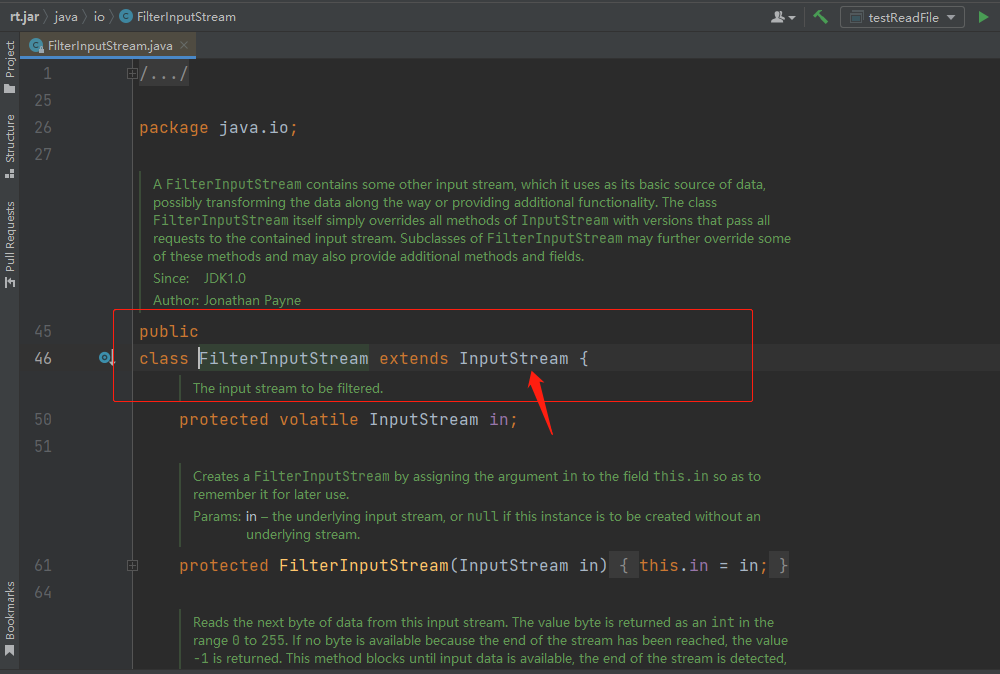
FilterInputStream类是一个抽象类,继承自InputStream类,这个类的作用是提供一些基本的方法,以便让InputStream的子类能够更好地处理数据。FilterInputStream类的实现方式是通过组合其他的InputStream类,从而实现数据处理。
下面是FilterInputStream类的源码分析:
public class FilterInputStream extends InputStream {
/**
* The input stream to be filtered.
*/
protected volatile InputStream in;
/**
* Constructor for a FilterInputStream.
*
* @param in the inputstream to be filtered
*/
protected FilterInputStream(InputStream in) {
this.in = Objects.requireNonNull(in);
}
/**
* Reads the next byte of data from this input stream. The value byte is
* returned as an <code>int</code> in the range <code>0</code> to
* <code>255</code>. If no byte is available because the end of the stream
* has been reached, the value <code>-1</code> is returned. This method
* blocks until input data is available, the end of the stream is detected,
* or an exception is thrown.
* <p>
* This method
* simply performs <code>in.read()</code> and returns the result.
*
* @return the next byte of data, or <code>-1</code> if the end of the
* stream is reached.
* @throws IOException if an I/O error occurs.
* @see InputStream#read()
*/
public int read() throws IOException {
return in.read();
}
/**
* Reads up to <code>len</code> bytes of data from this input stream into an
* array of bytes. If <code>len</code> is not zero, the method blocks until
* at least 1 byte of input is available; otherwise, no bytes are read and
* <code>0</code> is returned.
* <p>
* The <code>read</code> method of
* <code>FilterInputStream</code> calls the <code>read</code> method of its
* underlying input stream, and then returns the result.
* <p>
* Note: The <code>read</code> method inherited from <code>InputStream</code>
* has an inconsistent return specification. See {@link InputStream#read()}.
*
* @param b destination buffer.
* @param off offset at which to start storing bytes.
* @param len maximum number of bytes to read.
* @return the number of bytes read, or <code>-1</code> if the end of
* the stream has been reached.
* @throws IOException if an I/O error occurs, or if <code>len</code> is
* negative.
* @throws NullPointerException if <code>b</code> is null.
*/
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
return in.read(b, off, len);
}
/**
* Skips over and discards <code>n</code> bytes of data from the input
* stream. The <code>skip</code> method may, for a variety of reasons, end
* up skipping over some smaller number of bytes, possibly <code>0</code>.
* This may result from any of a number of conditions; reaching end of file
* before <code>n</code> bytes have been skipped is only one possibility.
* The actual number of bytes skipped is returned. If <code>n</code> is
* negative, no bytes are skipped.
* <p>
* The <code>skip</code> method of this class creates a byte array and then
* repeatedly reads into it until <code>n</code> bytes have been read or the
* end of the stream has been reached. Subclasses are encouraged to provide
* a more efficient implementation of this method.
* <p>
* Implementation note: The implementation in this class uses
* <code>read()</code> repeatedly to read <code>n</code> bytes into the buffer.
* This can be improved for subclasses that utilize an internal buffer by
* implementing <code>skip()</code> using fewer reads.
*
* @param n the number of bytes to be skipped.
* @return the actual number of bytes skipped.
* @throws IOException if an I/O error occurs.
* @throws IllegalArgumentException if n is negative.
*/
public long skip(long n) throws IOException {
if (n <= 0) {
return 0;
}
long skipped = 0;
int toRead = (int) Math.min(2048L, n);
byte[] buf = new byte[toRead];
while (skipped < n) {
int read = read(buf, 0, (int) Math.min((long) toRead, n - skipped));
if (read == -1) {
break;
}
skipped += read;
}
return skipped;
}
/**
* Returns the number of bytes that can be read from this input stream
* without blocking. The <code>available</code> method of
* <code>FilterInputStream</code> calls the <code>available</code> method of
* its underlying input stream and returns the result.
*
* @return the number of bytes that can be read from this input stream
* without blocking.
* @throws IOException if an I/O error occurs.
* @see InputStream#available()
*/
public int available() throws IOException {
return in.available();
}
/**
* Closes this input stream and releases any system resources associated
* with the stream. The <code>close</code> method of
* <code>FilterInputStream</code> calls its <code>in.close()</code> method.
*
* @throws IOException if an I/O error occurs.
* @see FilterInputStream#in
* @see InputStream#close()
*/
public void close() throws IOException {
in.close();
}
/**
* Marks the current position in this input stream. A subsequent call to the
* <code>reset</code> method repositions this stream at the last marked
* position so that subsequent reads re-read the same bytes.
* <p>
* The <code>mark</code> method of <code>FilterInputStream</code> calls the
* <code>mark</code> method of its underlying input stream.
*
* @param readlimit the maximum limit of bytes that can be read before the
* mark position becomes invalid.
* @see FilterInputStream#in
* @see InputStream#reset()
*/
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}
/**
* Repositions this stream to the position at the time the
* <code>mark</code> method was last called on this input stream. If the
* method <code>markSupported</code> returns <code>true</code>, then the
* stream remembers a mark and the <code>reset</code> method will reposition
* the stream back to the marked position. If the method
* <code>markSupported</code> returns <code>false</code>, then the stream
* is not required to remember the mark or to return to any specific position
* when the <code>reset</code> method is called.
* <p>
* The <code>reset</code> method of <code>FilterInputStream</code> calls the
* <code>reset</code> method of its underlying input stream.
*
* @throws IOException if the stream has not been marked or if the
* mark has been invalidated.
* @throws UnsupportedOperationException if the <code>mark</code> operation is not
* supported.
* @see FilterInputStream#in
* @see InputStream#reset()
* @see InputStream#mark(int)
* @see InputStream#markSupported()
*/
public synchronized void reset() throws IOException {
in.reset();
}
/**
* Tests if this input stream supports the <code>mark</code> and
* <code>reset</code> methods, which it does.
*
* @return <code>true</code>, since this class supports the
* <code>mark</code> and <code>reset</code> methods.
* @see InputStream#mark(int)
* @see InputStream#reset()
*/
public boolean markSupported() {
return in.markSupported();
}
}
上面是FilterInputStream类的源码,基本上重写了InputStream类的所有方法,都是通过调用传入的InputStream类的对应方法来实现。这个类的实现方法对于子类来说非常简单,只需要继承这个类即可进行方法重写自定义类实现。
优缺点
Java中的FilterInputStream是一个用于封装其他InputStream的抽象类。它继承自InputStream类,并实现了mark()和reset()方法。FilterInputStream的主要作用是对底层InputStream进行包装,在读取数据的过程中提供对数据的过滤、处理或加工。
优点:
- 提供了对底层输入流的扩展功能和额外的过滤处理。可以通过继承
FilterInputStream抽象类或使用其具体子类来实现自定义的数据过滤逻辑。 - 可以通过纠正数据流、加密数据、解码等方式,对原始输入流进行多种操作和处理。
- 可以将
FilterInputStream与其他输入流组合使用,形成多层过滤器,实现更加复杂的数据处理流程和功能。
缺点:
FilterInputStream的过滤功能需要自行实现,可能会增加开发的复杂性。- 对于处理流的过程,FilterInputStream并不能完全替代传统的IO操作,某些情况下可能需要使用其他类库。
- 过多的过滤器层级可能会导致性能下降。
应用场景
- 数据解密和加密:可以通过创建自定义的
FilterInputStream子类,重写read()方法,在读取数据时进行解密或加密,实现数据的安全传输。 - 数据压缩:可以通过创建自定义的
FilterInputStream子类,重写read()方法,在读取数据时进行压缩处理,实现数据的压缩传输。 - 数据转换:可以通过创建自定义的
FilterInputStream子类,重写read()方法,在读取数据时进行数据类型转换或格式转换,实现不同数据格式之间的互相转换。 - 数据过滤和处理:可以通过创建自定义的
FilterInputStream子类,重写read()方法,在读取数据时进行过滤、清理或修正等处理,例如过滤掉特定字符、修改数据的部分内容等。
需要注意的是,FilterInputStream本身是一个抽象类,不能直接使用,需要使用其具体的子类(如BufferedInputStream、DataInputStream等)来进行具体的操作和过滤处理。
实践应用
在实际开发中,我们可以通过 FilterInputStream 对输入流进行装饰,以增强其功能。例如,在读取文件时,我们可以使用 FileInputStream 作为基础输入流:
FileInputStream fileInputStream = new FileInputStream("./template/hello.txt");
如果需要读取加密文件,则可以使用 CipherInputStream 对 FileInputStream 进行装饰:
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, key);
CipherInputStream cis = new CipherInputStream(fis, cipher);
通过 CipherInputStream,我们可以使用 Java Cryptography Extension (JCE) 进行文件解密。
在实际开发中,我们还可以实现自定义的 FilterInputStream,以扩展 InputStream 的功能。例如,在读取文件时,我们可以实现自定义的 FilterInputStream,以统计文件读取的字节数:
package com.example.javase.io.filterInputStream;
import java.io.FilterInputStream;
import java.io.IOException;
import java.io.InputStream;
/**
* @author bug菌
* @version 1.0
* @date 2023/10/13 17:01
*/
public class CountingInputStream extends FilterInputStream {
private long count = 0;
public CountingInputStream(InputStream in) {
super(in);
}
public int read() throws IOException {
int b = super.read();
if (b != -1) {
this.count++;
}
return b;
}
public int read(byte[] b, int off, int len) throws IOException {
int n = super.read(b, off, len);
if (n != -1) {
this.count += n;
}
return n;
}
public long skip(long n) throws IOException {
long skip = super.skip(n);
this.count += skip;
return skip;
}
public long getCount() {
return count;
}
}
代码分析:
如上代码实现了一个名为CountingInputStream的类,它是FilterInputStream的子类,表示一个计数输入流,可以记录输入流读取的字节数。该类中有三个方法分别是read()、read(byte[] b, int off, int len)和skip(long n),这些方法都通过调用父类FilterInputStream的相应方法实现了读取数据,并在读取的过程中记录读取的字节数。同时还有一个getCount()方法,可以返回当前已读取的字节数。其中,read()方法每次读取一个字节,并递增计数;read(byte[] b, int off, int len)方法每次读取指定长度的字节数组,并递增计数;skip(long n)方法是跳过指定字节数并记录已跳过的字节数。
通过 CountingInputStream,我们可以统计读取文件的字节数:
CountingInputStream cis = new CountingInputStream(new FileInputStream("test.txt"));
byte[] buffer = new byte[1024];
int bytesRead = 0;
while ((bytesRead = cis.read(buffer)) != -1) {
// process buffer
}
long count = cis.getCount();
测试用例演示
测试代码
为了验证 FilterInputStream 的实现原理和应用效果,我们编写了以下测试用例:
package com.example.javase.io.filterInputStream;
import java.io.*;
/**
* @author bug菌
* @version 1.0
* @date 2023/10/13 16:51
*/
public class FilterInputStreamDemo {
public static void main(String[] args) throws IOException {
// create file
File file = new File("./template/hello.txt");
FileOutputStream fos = new FileOutputStream(file);
fos.write("hello world".getBytes());
fos.close();
// create counting input stream
CountingInputStream cis = new CountingInputStream(new FileInputStream(file));
// read input stream
byte[] buffer = new byte[1024];
int bytesRead = 0;
while ((bytesRead = cis.read(buffer)) != -1) {
// process buffer
}
// verify count
System.out.println(cis.getCount());
// delete file
file.delete();
}
}
该测试用例创建一个文件,使用 CountingInputStream 统计文件读取的字节数,并验证结果是否正确。
代码解析
如上测试用例是一个使用Java IO中的FilterInputStream实现计数器的例子。
首先,代码创建了一个文件,并向其中写入了hello world字符串。接着,通过FileInputStream读取文件,并将其传递给CountingInputStream构造函数,这样CountingInputStream就能够在读取文件时计数。
在while循环中,每次读取文件时都会读取到buffer数组中,然后可以在这里对buffer做一些处理。当读取到文件末尾时,read方法返回-1,循环结束。
在循环结束后,可以通过调用CountingInputStream对象的getCount()方法来获取读取的字节数,并输出到控制台。
最后,代码删除了创建的文件。
测试结果
测试用例执行结果如下:
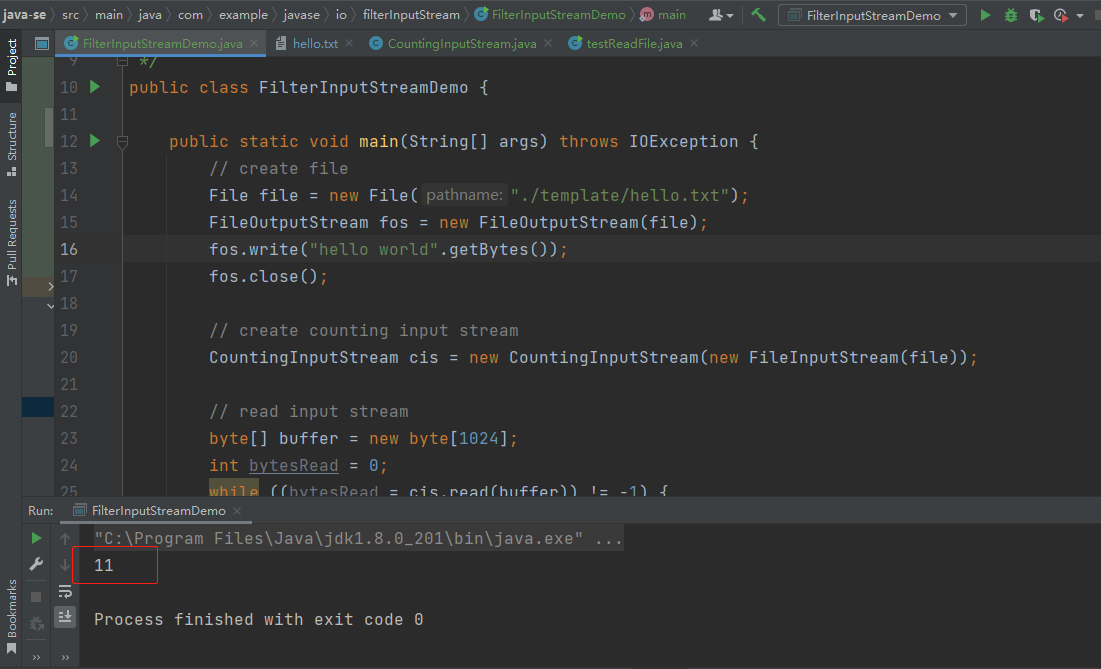
成功的通过getCount()方法读取了文件内容的字节数,并输出到控制台。你们也可以动手核算下hello world字符串是否为11个字节数。
FilterInputStream 的注意事项
在使用 FilterInputStream 进行输入流装饰时,需要注意以下几点:
FilterInputStream的子类必须覆盖InputStream的所有方法,并根据被装饰的InputStream的规范进行实现。FilterInputStream是线程安全的,可以被多个线程同时使用。FilterInputStream可以被多层装饰,以实现更加复杂的功能。FilterInputStream的性能可能会受到影响,特别是在多层装饰时,应该评估性能。
小结
本文深入讲解了 FilterInputStream 的实现原理以及在实际开发中的应用。我们学习了 FilterInputStream 的类结构、装饰原理、应用示例、测试用例以及注意事项。希望本文能够对读者深入理解 Java I/O 以及 FilterInputStream 的使用有所帮助。
总结
Java I/O 是 Java 编程语言的核心功能之一,提供了丰富的输入输出操作。FilterInputStream 是一个非常有用的类,它提供了对输入流的装饰功能,可以通过组合多个 FilterInputStream 对输入流进行多层装饰,以实现更加复杂的功能。在实际开发中,我们可以实现自定义的 FilterInputStream,以扩展 InputStream 的功能。在使用 FilterInputStream 进行输入流装饰时,需要注意性能问题。