概要
目前,现有的房源信息不够透明化大多中介混淆市场,内含不为人知的商业链。有经验的租客们会通过周边房价走势和走访周边房源对比调研、筛选适合自己的房源。
同时,对于用户工作地点需求和各种人群类型如大学生群体,年轻小资,或者中年人,他们希望居住的环境要求各不相同各类型条件限制这也加大了用户租房的难度。当今的租房市场并不够透,传统的实体中介已经跟不上需求。文章将介绍传统的租房信息与移动互联相结合,运用大数据收集各类房源信息聚合数据,跨平台整合信息,最后通过计算机软件开发相关技术开发出一款智能房源推荐平台推荐给用户。整个推荐系统目的就是为了解决item和user的匹配问题,本项目采用最经典的就是CF的方法,本质上是构建user和item的特征表达,你可以想办法用抽取特征的网络结构来提取这个表达形式,也就是常说的embedding方法。然后就可以直接用user的emb和所有item的emb计算相似度,按照相似度高低返回推荐结果。想办法构造巧妙的或者新颖的方式抽取特征,最后选用现代化web框架SpringBoot+Vue完成平台搭建
关键词:房源推荐系统 ALS算法 大数据 数据采集
一、研究背景与意义
1.1 项目的开发背景
目前,现有的房源信息不够透明化大多中介混淆市场,内含不为人知的商业链。有经验的租客们会通过周边房价走势和走访周边房源对比调研、筛选适合自己的房源。
同时,对于用户工作地点需求和各种人群类型如大学生群体,年轻小资,或者中年人 他们希望居住的环境要求各不相同各类型条件我限制这也加大了用户租房的难度。随着城市化建设,经济发展,就业人群流动,相较市场的庞大需求,当今的租房市场并不够透,传统的实体中介已经跟不上需求。文章将介绍传统的租房信息与移动互联相结合,运用大数据收集查阅信息,跨平台整合信息,最后推荐给用户。
1.2 项目的开发目的
对于所有人来说衣食住行是我们在社会上生活的必需品,在房价频频高涨的现在,对于所有社会上打拼的人或者说所有踏入社会的年轻人来说,都会参与到租房市场。
研究数据展示现在我国的租房人口数量约为2亿,主要由流动人口和大学毕业生组成,住房租赁市场为1.3万亿。 随着城市化进程的发展,流动人口规模的不断增加为租住人口提供了基础。到2030年,国内有需要租房的需求将达到2.9亿人口,市场规模将超过4亿人口
1.3 项目的开发意义
(1)基于用户协同过滤算法进行探索,通过数据挖掘等前沿技术,研究在Web端和移动端相关系统的设计与实现。
(2)为平台用户提供一个拥有多项功能的,且具有良好数据可视化和友好交互的系统。
(3)对房源进行数据采集,标记分析处理,通过用户协同过滤 相似度处理,让房源推荐平台更加智能,更懂用户。
(4)给缺乏房源信息和需要租房的用户带来便利。
1.4 国内的研究现状和发展趋势
回顾国内外相关领域研究,学者们在丰富用户兴趣特征、构建协同过滤个性化推荐方面已经做了很多研究工作,协同过滤算法是当前推荐系统中应用最广泛的推荐算法,从社交网络数据再到情景融入数据,基于此,本文在协同过滤方法的
基础上加上从不同网站爬取的数据进行系统设计,通过爬取不同网站数据弥补协同过滤算法数据缺失问题。获取足够多的房源信息提取有效历史租赁成功信息和租房房源真实评价做出基本的房源地理位置区分(商圈,地铁主要核心公交站等),房价价格排序,房类型排序等,并且通过预测模型,适合每一位独一无二的用户的优质房源,推荐给用户选择,同时记录下用户的选择信息,不断补充数据中心的用户数据反复进行ALS运算这样就能在后期给所有用户推送出更优更符合用户群体的准确租房房源信息。
1.5项目的设计思路
协同过滤算法是当前推荐系统中应用最广泛的推荐算法,在互联网各个领域都有实际的应用价值,如电影推荐,短视频推荐,电商商品推荐等等。这些场景大都可以通过一种基于用户的协同过滤算法去实现,主要采集用户对这些Item的用户History与Action,去计算用户之间相似度通过邻K算法去找到最近邻居,通过设定参数比重预测对item的分值,然后将分值最高的前x个项目返回给用户就完成了推荐行为。
一般来说,用户对项目的评分能够较精准的反映用户对项目的喜爱程度,而标签标注作为一种用户行为,蕴含了用户对项目内容和属性的深入理解[4]。文献[5]通过对项目的标签进行简单的计数统计来求得用户对项目标签的偏好向量,但是这种方法在计算用户对标签兴趣偏好时会出现热门标签权重较大的问题,这样就导致了被用户选择过的稀缺标签很难给用户进行推荐造成权重偏差,降低了推荐结果的准确性并且未能充分反映用户的兴趣偏好。针对以上问题,本文引入TF-IDF的思想对用户的项目标签偏好进行计算。
TF-IDF是一种加权技术,采用一种统计方法来评估某一个特征词在一个语料库中的重要程度[6]。将其思想应用到用户偏好计算上,若用户选择某个标签越频繁,这个标签被选择的人数又越少并且这个标签在整个标签集中的占比越小,则我们认为用户对这个标签的偏好程度越高。公式如下:
由公式能够推出,若一个标签选择人数较多且在整个标签集中的自身占比较高,即热门标签,则计算结果偏低;若用户选择冷门标签,相较于其他用户而言,用户更关注此标签且该标签对于该用户的重要程度更高,这样就能在一定程度上很好的区分和明确用户的偏好,提高推荐准确率。
二、技术理论
2.1 Python简介
Python是由Guidovan Rusum于1991年创建的一种广泛使用的解释性高级通用编程语言。 Python的设计理念强调可读性和简洁的语法(尤其是通过使用空间缩进而不是花括号和关键字来分解代码块)。允许开发人员用比C,Java和Python更少的代码来表达他们的想法。
Python编程语言的特性是一种更加完全地面向对象语言,无论是代码里面的定义的函数,数字和字符串都是对象,面向对象的三大特性也就是对继承,重载,派生和多重继承的Python也是全面支持,您可以促进源代码的重构建复用。但是,Python的运行速度比静态语言(如C和Visual Basic)慢。应用范围:网络应用程序:Python通常用于创建服务器软件和Web搜寻器,因为它支持多种网络协议。丰富的第三方Web框架集使开发和管理复杂Web流程的科学计算变得容易。像NumPy,SciPy,Matplotlib一样,您可以轻松创建科学的计算程序,而无需重复API。您需要一个库:Python具有强大庞大的标准库。 提供了系统管理,文本处理,网络通信,,图形系统和其他附加功能。此外,第三方库也非常强大 它们的功能涵盖科学计算,Web开发,数据库界面和图形系统的许多领域。最受欢迎的库包括Flask,Django,PIL,Matplotlib,QT,WxPython,TensorFlow。
2.2 Scrapy爬虫框架简介
Scrapy是Python下一款数据挖掘的框架主要是从网页的内容和提取各种图像,并且打开源网络爬虫框架的结构化数据,正在进行数据挖掘、信息处理或数据存储等一系列的工作。Srapy框架主要通过采用了高效的Twisted库异步处理网络通信,可以多线程异步保证高效下载。给下载速率提供一系列高效、强大的组件,并提供各种插件或接口允许开发者快速构建网络程序。框架主要是由主引擎、调度器和下载器(Downloader)、爬虫类、项目管线5个基本部件,由可以自由配置下载机的中间件和爬虫类中间件的扩展中间件构成。下图2-1所示:
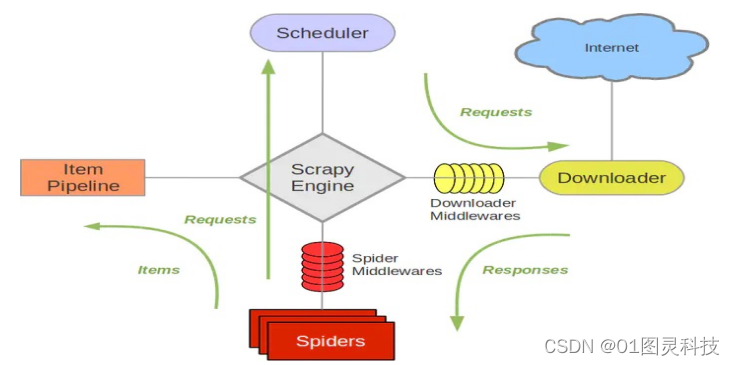
图2-1 Scrapy爬虫框架
其中,主引擎是Scrpy爬虫类的核心,主要负责各组件之间的责任。的数据流在系统中触发事件时会调用相应的组件。解决事件调度器主要接受主发动机的要求,将请求按到队列中,下载机和爬虫类从队列中获取任务的前进方向。合理的下载器的主要作用是本地下载网页的内容,并在主页内下载。可以放回爬虫类。爬虫类按照自己的分析页面规则进行页面解析。分析完成后,作为Item数据被密封,被供给数据管道。合理的项目管道主要处理爬虫类网页中提取的Item数据。主要任务是清洗、验证、检查和数据的保存。[7]一般来说,项目管线需要多个,进行一个数据的处理工作。正在下载的项目是主要的。在引擎和下载机之间,主要用于处理主引擎和下载机之间的要求。以及响应。爬虫类的中间体介于主引擎和爬虫类之间。主要处理爬虫类。响应输入和请求输出。
Scripy的详细操作流程是爬虫类首先需要发送请求的Url。经过主引擎交给了调度器,把调度器并排放进了队伍。请交给下载机。然后,下载器向因特网发送请求,接收下载的铃声。响应用主引擎向爬虫类传递响应。最后,爬虫类处理响应、提取数数据通过主引擎保存在数据管道中。
2.3 JAVA语言简介
Java是91年Sun Microsoft tems的trick Naughtn、Chris Warth、Ed Frank和Mike Sheridan共同构想的成果。最初被称为“橡子”,1995年改名为“Java”。令人惊讶的是,设计Java的最初动机不是互联网,而是开发出独立于平台的语言。可以用来制作包含微波炉、冰箱、空调,电视遥控器等等不同设备的应用程序。推测不同类型的CPU可以作为遥控器使用。
无论是什么类型的CPU都可以去通过编译运行C++的应用程序,CPU需要指出C+的编译器。编译程序的开发成本高,需要花费很多时间针对不同类型平台进行移植或者适配,所以当时的程序员寻找更优的解决方案,Gosling团队正在开发一款可移植的跨平台编程语言,这就是Java语言的诞生。
只有通过设计Java的细节,其他影响Java形成的重要组件才能出现。第二个动机是万维网。如果在Java形成之前无法使用Web,则Java可以成为对消费类电子产品进行编程的有用语言。但是,Web的出现和对Web可移植程序的需求已将Java推到了计算机语言设计的最前沿。
大多数程序员都知道手机App很有前途并且很难学习。您需要在编程领域中创建高效的移植程序,但是这留下了更紧迫的问题。随着Internet的出现和星期三的出现,原来的潜在可移植性问题再次出现在台式机上。结果,互联网是由不同类型的PC,OS和CPU组成的不同的分布式网络空间。从1993年开始,Java的研究设计团队发现频繁出现在网络编程方面需要不断解决不同平台的代码移植问题。后面因为这些方面,Java开始从消费电子而转向到在线网络Web编程。因此,与体系结构无关的编程语言的开发始于提供Starfire,最终,互联网为Java的未来做出了贡献。
2.4 Hbase简介
HBase是运作在 HDFS 之上的非关连式分散式资料库。想在 Big Data 的世界使用 DataBase,又想拥有 Hadoop 的容错机制优点,选 HBase 就对了! HBase 具备高吞吐量与低延迟性的特点,非常适合在 Big Data进行更快速的读写操作。目前HBase深受各大企业或是网站使用,包含:Adobe、Facebook、Meetup、Trend Micro、Twitter、Yahoo!等等。
Hadoop可以存储大文件,并且使用分布式运算MapReduce,但是Hadoop操作,只有put, get, cat, mv, rmr等语法,没有edit,所以我们采用HBase。
HBase的特点就是提供即时随机读写的功能。当A电脑(client)新增了一笔资料时,B电脑(client)就可以马上读取到最新资料并且可以修改。虽然RDB同样在这方面的确做得到甚至更好,但是RDB无法存放PB数据量级的数据,又或者Oracle DB可能可以放这么大的资料量,但不敢想像Oracle会收多少取授权费用了。
虽然HBase经过社群的努力下效能越来越好,但在某些情境还是无法完全取代RDB,他与RDB间没 有谁最好,甚至某些状况是相辅相成。比较常见的情境是利用RDB当作HBase的metadata储放处,或者是当作secondary index,较为复杂的relation先使用RDB查询存在放HBase的资料主键,再使用PK从HBase取出raw data。
HBase 与 Rowkey,MapReduce的WordCount范例,可以了解在文件中要搜寻某个关键字或是某行纪录时,需要对单一或是多个档案进行fully scan(完全扫描)后才能得到符合关键字的资讯,需要不少的时间来完成这件事。
HBase是一个column-oriented的键值配对(key-value pair)的database,资料储存以key-value方式储存,key即是资料的主键(PK)也是index,称之为Rowkey,如果善用Rowkey当作查询条件来搜寻,效能就会比fully scan方式快上很多,这也是HBase的优势之一,所以在存放资料时Rowkey设计就成了一们重要课题。好的Rowkey设计带你上天堂,不好的就让你住进refactor的套房。
如果以RDB的table来想像,HBase的table就是一张稀疏矩阵(Sparse matrix)的表格,每个row的column数量不一定会相等,但是每个column的row数量一定会相同。
HBase以key-value方式储存,也以key-value输入,当需要新增大批资料时这种方法效率就很低。因此HBase提供了bulk load的功能,让使用者不经过put机制,直接将资料转换成HBase的储存格式:HFile,避免使用put时触发split与compact让put效能越来越慢。HBase 与 SQL基本上HBase是没有内建任何的SQL查询功能,只能在hbase shell使用scan搭配filter 查询。
三、推荐算法介绍与平台推荐引擎实现
3.1 主流推荐算法介绍
一种是排序算法常用于人气排名等,一种是基于内容(基于内容)筛选
例如基于项目相似性的推荐常通过按数据的特征向量对相似性(如 Cos 相似性)进行排序和推荐[8],示例:向购买棒球棒的人推荐棒球。
协同过滤算法通过处理用户的使用历史记录,各项相关事务数据区建立用户项矩阵,一般来说,会采用以上混合算法去实现推荐功能,本章仅对协同过滤算法进行介绍。
协同过滤算法中常见的事件如下。只推荐类似的项目只推荐热门项目和长期发布的项目每隔几年只购买一次的推荐结果都会显示如果用户行为历史记录收集不够,那么可能精度不佳。
3.2 协同过滤算法
3.2.1 基于模型的协同过滤
协调过滤算法主要有以下类型一种是基于模型的过滤算法。基于模型使用预先检查的数据的规律性进行预测使用用户项矩阵构建模型,模型类型包括:矩阵因子分解模型,将用户项矩阵分解为用户矩阵 (user = k) 和项矩阵 (item = k) 时,使已具有值的单元格的值的误差最小,分解后,当矩阵的乘积被撤消时,值位于没有值的单元格中,该值是评估值奇异值分解(SVD:星光值分解),非负矩阵因子分解(NMF:非内加特夫矩阵因子),与 SVD 不同,分解矩阵的所有元素都是正数使用(SGD:Stochastic Gradient Descent)随机梯度下降方法与(ALS:Alternative Least Squares)交替最小二乘法去进行群集模型为具有相似偏好的用户组推荐函数模型,从用户首选项模式预测项的评级的函数概率模型。行为分布类型:对哪些用户、哪些项目和如何评估的分布进行建模m评估分布类型:对所有项的评估值同时分布建模,贝叶斯网络等。时间序列模型 马尔科夫过程:考虑评估项目的时间顺序,马尔科夫决策过程(MDP:Markov决策):此外,用户行为建模配合滤波。
3.2.2 基于内存的协调过滤算法
基于内存的协调过滤的概念是"相似性"。从过去的使用历史中,我们揭示了类似的,并使用此相似性来估计推荐的产品。
在相似性的情况下,用户之间的相似性和产品之间的相似性被认为是两个,使用前者时基于用户,后者称为基于项目。
用户群:从用户行为历史记录中计算用户之间的相似性并决定建议的项目的方法。
示例:我想向A推荐一些东西,A先生正在购买产品a、产品b和c。
B 有类似的行为历史,购买产品 a、产品 b、产品 c 和产品 d,因此,您可以向 A 推荐产品 d。
基于项从用户行为历史记录中计算项目之间的相似性并推荐类似项的技术
示例:由于产品 A 通常与产品 B 一起购买,因此,让我们向产品 A 的购买者推荐产品 B。
基于用户的协作筛选逻辑使用机器学习技术称为 kNN 回归。
简要描述 kNN(k-Nearest-Neighbor,k邻域方法),使用与要估计的最相似的 k 个观测值来估计值。
算法概述如下。
计算一个用户和另一个用户的相似性与要推荐的目标用户(如用户x)高度相似的 k 名称用户,去采集用户x 尚未使用的其他用户使用的项目的集合,返回这些项目列表的推荐项目,在此选择期间,使相似性较高的用户使用的项目具有更高的权重,基于项/用户库考虑用户之间的相似性,而项目库考虑项目之间的相似性。其他想法与基于用户相同。
使用的相似性包括:欧几里德距离 ( 欧克里迪恩 ),平方欧几里得距离 ( Squared Euclidean distance )两点之间的正常距离,皮尔逊的乘积相关系数( 皮尔森 correlation coefficient )和余弦相似性,用户评估的总体平均值规范化用户评级。
在数据未规范化的情况下,通常比欧几里得距离产生更好的结果。在用户库中,Pearson来做数学相关系数。通过这样做,在两个用户之间获得高相关性,其评估趋势相似,如下所示。用户A:"拉面是三点,但咖喱和炒饭是1.5分,因为它是无用的。 用户B:"拉面很好,有5分,但咖喱和炒饭通常有3.5分。 此外,在项目的基础上,余弦相似性经常使用。
3.3 系统中的推荐算法
本系统中的推荐算法说基于内容的推荐算法基于内容的推荐,以用户过去喜欢的东西为基础我推荐和这些项目相似的其他东西。这个方法文档类推荐领域(新闻、文档、主页、书籍等)广泛应用本论文通过对用户历史订货的评价关于文本数据的提取,表示对将来的订单的预测。
共同滤波器推荐是构建推荐系统的最一般的技术。这可以直接通过用户过去的行为(例如用户订购时)。为了预测用户的喜好而进行单一的评价。兴趣和以前的兴趣一致。为了作为参考,需要其他所有领域的知识。现有基于模型的协同滤波的目的是从应该看的评价数据中发现了潜在的影响因子。利用数据挖掘和机器学习技术从训练数据中找到模型。使用这些模式计算用户对。商品评分基于内存的联合过滤还可以通过用户和基础的
是基于用户的协作过滤。推荐系统中最早的算法]。主要思想是发现。进行亲密使用,例如类似于目标用户的亲密用户
大体过程如下。
(1)查找附近的用户N:计算目标用户与其他用户的相似度,选择超过设定阈值的用户。在用户旁边显示用户。
(2)得分预测:用户User预测项目Item。目标用户User的值是一组相邻User用户,而值是靠近它
在此,N具有项Item的等级,该等级高于相似性阈值。
(3)推荐阶段:对预测对象用户所有未评价商品打分后,采用Top-K的方法,评价值最高的K项目向目标用户推荐。
然后是物品的共同过滤是在推荐系统中非常常见流行的思路。计算一个用户和另一个用户的相似性选择与要推荐的目标用户(用户 A)高度相似的 k 名称用户,提取用户 A 尚未使用的其他用户使用的项目的集合,返回这些项目列表的推荐项目,在此选择期间,使相似性较高的用户使用的项目具有更高的权重,基于项/用户库考虑用户之间的相似性,而项目库考虑项目之间的相似性。其他想法与基于用户相同。利用目的物和目标用户评价过高的情况。利用类似度,利用其评分对目标用户的目标物品评分的具体步骤如下:
(1)计算目标物与其他物品的类似性。
(2)评价预测。用户u对物品s的预测式
(3)推荐阶段:对预测对象用户所有未评价房源评分后,采用Top-K邻K算法。
3.4 系统中的推荐引擎架构介绍
具体的系统架构图 如图3-1所示:
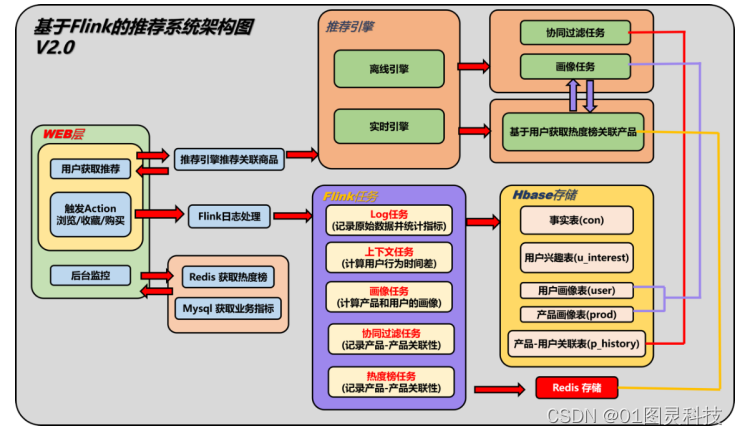
图3-1 推荐系统架构图
3.4.1 架构模块介绍
在日志数据模块(flink-2-hbase)中,又主要分为6个Flink任务:用户-产品浏览历史 -> 实现基于协同过滤的推荐逻辑,通过Flink去记录用户浏览过这个类目下的哪些产品,为后面的基于Item的协同过滤做准备 实时的记录用户的评分到Hbase中,为后续离线处理做准备[9]。
数据存储在Hbase的user_action表中,用户-兴趣->实现基于上下文的推荐逻辑。从用户对同一产品的操作中计算兴趣度,计算规则通过在操作间隔时间(购物-浏览<100s)中被判定为一次关心事件的Flink的ValueState来实现,如果用户的操作Action=3(收藏),则去除该产品的state,超过100s时,如果不发生Action=3的事件,则也清除其state,数据存储在Hbase的u_interest表中。
事实热排名–>实现基于热的推荐逻辑。
通过Flink时间窗口的机制,统计当前时间的实时热,并使数据缓慢地存在于Redis中。通过Flink的窗口机制计算实时热,并使用ListState保存一次热排序。
数据存储在redis中,按照时间戳存储list。
日志直接将从Kafka收到的数据导入Hbase事实表,保存完整的日志log,日志包含用户Id、用户操作的产品id、操作时间、行为(例如购买、点击、推荐等)。数据按时间窗统计数据画面所需的数据,返回前段展示数据并存储在Hbase的con表中。
3.4.2 基于房源用户画像的用户相似度计算方法
基于产品画像的推荐逻辑依赖于产品画像和热度榜两个维度,产品画像有三个特征,包含 价格/房源商区/工作区域 三个角度,通过计算用户对该类目产品的评分来过滤
在已经有产品画像的基础上,计算item与item之间的关联系,通过余弦相似度来计算两两之间的评分,最后在已有物品选中的情况下推荐关联性更高的产品,具体如图3-2所示:
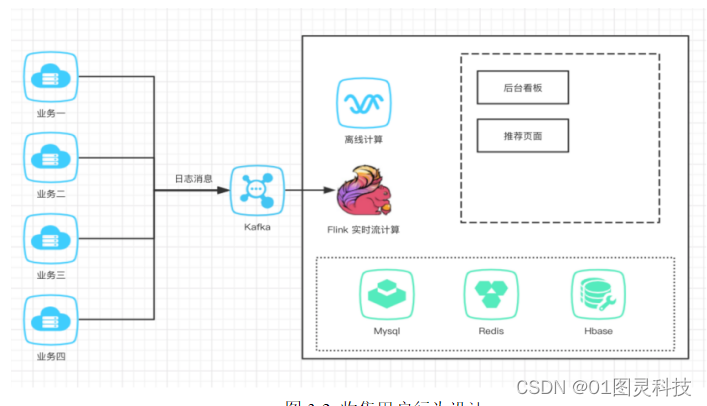
图3-2 收集用户行为设计
四、系统实现
4.1 系统功能模块的设计与实现
4.1.1 前台首页设计与实现
前台项目通过现代前端框架Vue-cli脚手架工具结合主流UI框架,自适应全屏轮播推广本平台人性化Slogen,引入Annimation.css动画框架使得无论是交互还是展示动画都非常流畅优美,好的产品体验和好的设计能让增强用户体验培养用户粘性。
(1)鼠标移入右上角用户登录注册区域,粉色背景色结合动画,点击启动前台页面用户登陆注册模块,具体如图4-1所示:
图4-1 前台页面
(2)在这登录模块中,界面是采用了常用的对话框的形式。背景用绚丽多彩的强调色,突出登陆框主题加深用户印象,让对话框的形式可以给用户一个很好互动。当用户输入用户名和密码之后,点击登录按钮,将输入的用户名和密码参数放入一个list对象中,如图4-2所示:
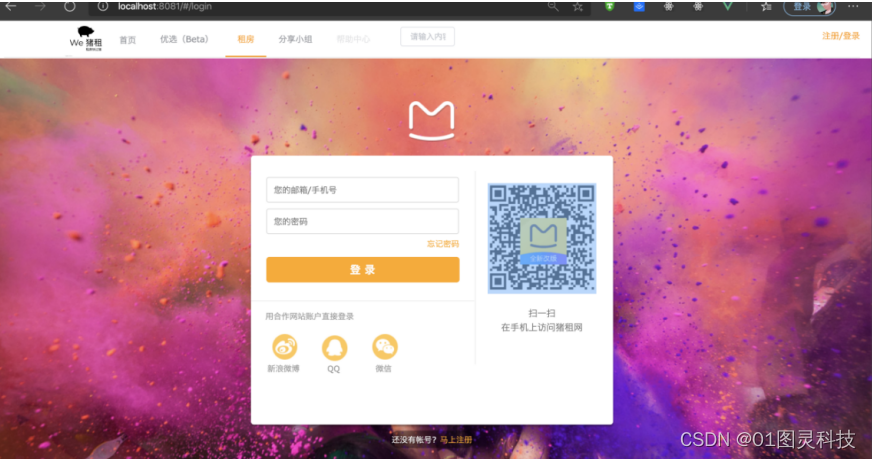
图4-2 用户登陆页面
(3)在首页,除了登录模块,还有导航栏页面,采用了折叠导航栏设计,使得整个页面布局更为舒适细腻,如图4-3所示:

图4-3 首页折叠导航栏设计
4.1.2 分享小组设计与实现
(1)通过首页隐藏式导航栏或者顶部导航栏进入后,可以看到各种帖子点击帖子可以进入帖子详细信息页面,看到别人回复也可以回复别人和旅行家们或者城市租客沟通交流,遇到喜欢的评论也可以点赞。发帖操作设计思路:通过点击发帖按钮填入对应的信息进行发帖,对数据库表进行插入数据的操作,然后再通过获取ID再显示对页面。点赞操作设计思路:对点赞按钮设计一个事件监听器,当用户点击按钮时获取对应的数据帖子ID、用户ID等然后对数据库的点赞数据进行一个更新操作,再显示到页面上。具体如图4-4所示:
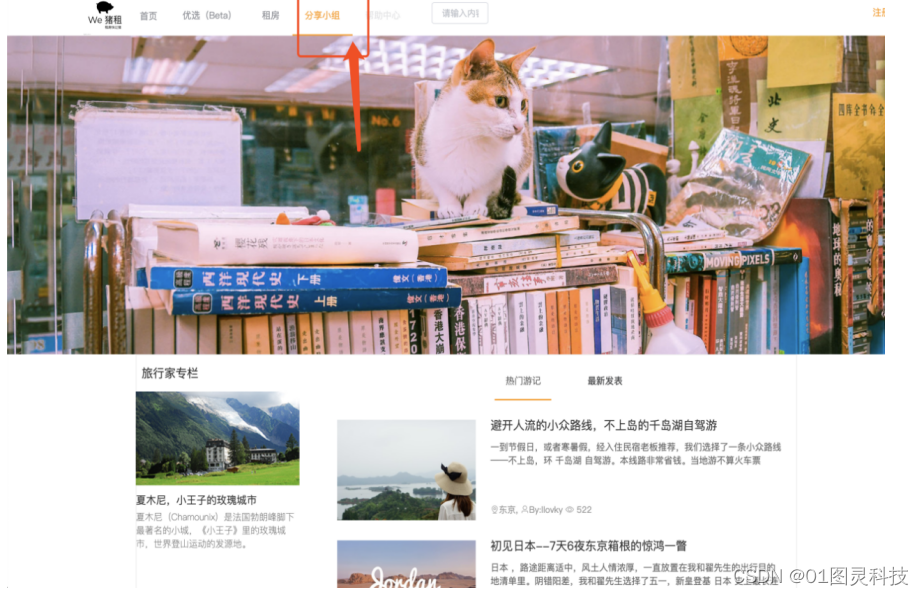
图4.4 社交模块分享小组
(2)社交模块里帖子的详情页,如图4-5所示:
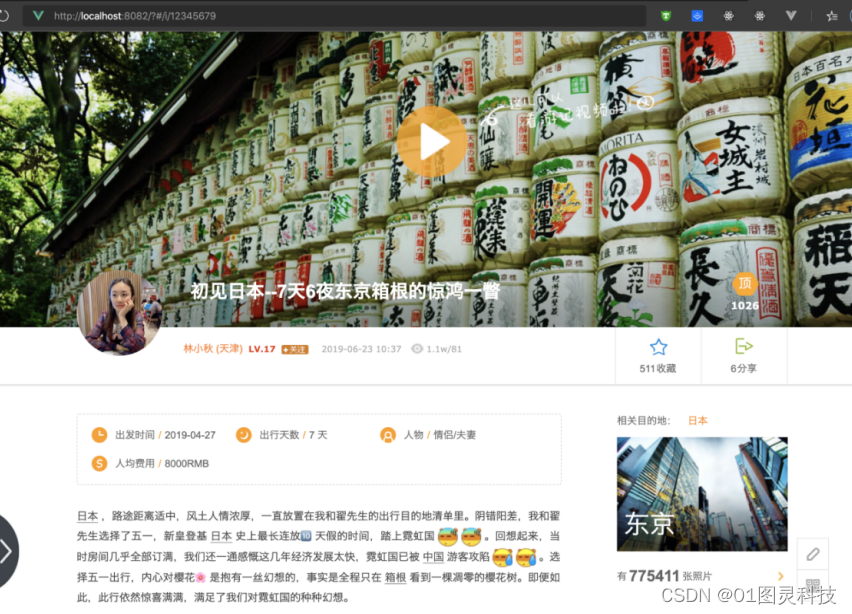
图4-5 社交模块-分享小组-帖子页面
五、 总结
基于用户协同过滤算法的智能房源推荐系统能够为所有人提供一个信息化以智能化的租房 APP,这是智慧生活的一个重要体现。本文研究了基于用户肖像数据,用户行为信息如用户收藏,和用户长时间停留的浏览记录等等数据, 为用户提供住房数据的高度相似性。通过协同过滤和其他算法的使用的挖掘相关数据。项目利用爬虫框架从市面上公开房源平台抓取房源信息,通过数据分析选出优质房源放入数据库中,通过Java SpringBoot框架结合前端MVVM框架Vue进行开发,实现本项目同时也存在不足。例如对于房源数据的多维度数据的处理,这对数据分析的可定制性有折扣。后续会通过更多数据反复耦合区训练模型,用户量用户行为信息足够多的情况下,最大化地发挥了各算法的优势,使两种协同过滤算法优势互补、相互融合,后续推荐系统能为用户提供更加精准的服务提供支持。
总体而言,本系统的设计研究为智能房源推荐平台,给用户提供更加个性化和人性化的房源数据推荐,获取了关键数据,另一方面,能给用户推荐相似用户精选优质房源,节省选房时间。
六、 目录
目录
第一章 概述 6
1.1课题背景及意义 6
1.2 国内外研究现状 6
1.3 本课题主要工作 7
第二章 系统开发环境 8
2.1 python技术 8
2.2 图像检测简介 9
1 基于直线检测的方法 9
2 基于阈值化的方法 9
3 基于灰度边缘检测方法 9
2.3 人脸识别简介 10
2.3.1 人脸识别阶段 10
2.3.2 人脸识别方法 10
2.4 深度学习算法及CNN 10
第三章 系统分析 12
3.1 可行性分析 12
3.1.1 技术可行性 12
3.1.2操作可行性 12
3.1.3 经济可行性 12
3.1.4 法律可行性 12
3.2需求分析 13
3.2.1 功能需求分析 13
3.2.2 性能需求分析 13
3.3开发环境分析 13
(1)开发硬件平台: 13
(2)开发软件平台: 13
第四章 系统设计与实现 14
4.1系统设计原则 14
(1)数据安全性 14
(2)易用性 14
(3)柔软性 14
(4)扩展性 14
4.2系统流程设计 14
4.2.1系统开发流程 14
4.2.2 人脸识别流程 15
4.3 系统功能设计 16
4.4接口设计 16
4.4.1 外部接口 16
4.4.2 内部接口 16
4.5系统实现 16
4.5.1 人脸检测 16
4.5.2 人脸识别 18
4.5.3 人脸识别效果 19
第五章 系统测试 21
5.1测试环境与条件 21
5.2功能测试 21
5.3测试结果分析 24
总结与展望 25
谢 辞 26
参考文献 27
附录 28