前言
固然,轻薄短小的书籍乍见之下让所有读者心情轻松,但如果舍弃太多应该深入的地方不谈,也难免令人行止失据,进退两难。
……
作为一个好的学习者,背景不是重点,重要的是,你是否具备正确的学习态度。起步固然可从轻松小品开始,但如果碰上大部头巨著就退避三舍、逃之夭夭,面对任何技术只求快餐速成,学语言却从来不写程序,那就绝对没有成为高手乃至专家的一天。
有些人的学习,自练就一身钢筋铁骨,可以在热带丛林中披荆斩棘,在莽莽草原中追奔逐北。有些人的学习,既未习惯大部头书,也未习惯严谨格调,更未习惯自修勤学,是温室里的一朵花,没有自立自强的本钱。
——《Essential C++》前言,侯捷
参考资料
[2] cplusplus.com
[3] stl—wiki
------C++ 基础------
二 变量和基本类型
2.1 基本内置类型
2.1.1 变量类型的大小
下图列出了各类型的最小尺寸。

2.1.2 符号
-
整型
- int:正数、负数和0
- usigned int: 大于0
-
字符型
- char :在有些机器上是signed,有些机器是unsigned
- signed char
- unsigned char
如何选择?
-
明知数值不可能为负,用无符号
-
整数运算用int、long long
-
浮点用double
2.1.3类型转化
-
有个不明白的地方,不明白怎么算的:(P33)赋给无符号类型一个超出它表示范围的值时,结果是初始值对无符号类型表示数值总数取模后的余数。
-
当一个算术表达式中既有无符号又有int,int就会转换成无符号,有可能引发错误。 <-混用引发错误
2.2 字面值常量
-
整型和浮点型
- 自动选择能匹配的空间最小的一个作为其数据类型
- 十进制不会是负数。符号不在字面值之内,负号的作用是对字面值取负
- 科学计数法指数部分用E或e标识
-
字符和字符串字面值
'a' // 字符, 'a' "a" // 字符串,'a'+'\0' // 当两个字符串字面值位置紧邻且仅由空格、缩进和换行符分隔,则实际上是一个整体 std::cout<< "a really, really long string literal " <<"that spans two lines" <<std::endl; -
转义
常用转义字符 -
布尔和指针
- bool :true ,false
- 指针:nullptr
如何指定字面值类型?
- 通过添加下表的前缀和后缀,改变整型、浮点型和字符型字面值的默认类型

2.3 变量
2.3.1 了解变量
-
定义
-
初始化
- 初始化不是赋值:
- 初始化是创建变量时赋予其一个初始值;
- 赋值是把对象的当前值擦除,而以一个新值替代。
- 初始化不是赋值:
-
四种初始化方式
// 可能有信息丢失的风险 long double b = 3.1415929 int a = b; // a = 3, 信息丢失 int a(b); // a = 3 // 使用列表初始化,存在上述风险将报错 int a = {b}; int a{b}; -
默认初始化
-
内置类型默认初始化的值由定义的位置决定
- 定义与任何函数体之外 ,初始化为0
- ...内,不被默认初始化,变量值未定义
-
建议初始化每一个内置类型的变量
-
-
声明和定义的关系
-
声明使得名字为程序所知;定义负责创建与名字关联的实体,并申请存储空间。
-
只能被定义一次,可以被声明多次。
-
如果想声明一个变量而非定义,使用
extern,并且不要显示地初始化:extern int i; //仅声明 int i ; //声明并定义 -
在函数体内部,初始化一个又
extern标记的变量,将引发错误。extern int i = 3.14; //错误 -
如果要在多个文件中使用同一个变量,必须将声明和定义分离。变量的定义必须出现且只能出现在一个文件中,而其他用到该变量的文件必须对其进行声明,却绝对不能重复定义。例,
//main.cpp #include <iostream> #include "Class2.h" using namespace std; int main() { Class2::print_i(); // 重点输出:Class2: 5 return 0; } //Class2.hpp #pragma once #include <iostream> using namespace std; extern int i; // <- 注意这里,如果不写就会报:i未声明标识符 class Class2 { public: static void print_i() { cout << "Class2: "<<i << endl; } }; //Class2.cpp #include "Class2.h" int i = 5;
-
-
标识符
- 用户自定义标识符中不能连续出现两个下划线;不能下划线紧邻大写字母;定义在函数体外的标识符不能以下划线开头。
- 变量名一般小写字母;类名以大写字母开头

2.3.2 作用域
对于嵌套作用域:
- 作用域中一旦声明了某个名字,它所嵌套着的所有作用域都能访问这个名字。
- 同时,允许在内层作用域中重新定义外层作用域中已有的名字。
::访问全局变量。
#include <iostream>
using namespace std;
int a = 42;
int main()
{
int b = 0;
cout << a << "," << b << endl; //42,0
int a = 0;
cout << a << "," << b << endl; //0,0
cout << ::a << "," << b << endl; //42,0
return 0;
}
2.4 复合类型
- 声明语句:一条语句声明由一个基本数据类型和紧随其后的声明符列表组成。
- 指针和引用,前后的类型都要严格匹配
2.4.1 引用
- 引用必须被初始化,且只能绑定到对象上,不能与字面值或某个表达式的计算结果绑定;
- 无法令引用重新绑定到另一个对象;
- 引用本身不是对象,所以不能定义引用的引用
2.4.2 指针
-
指针本身是一个对象;
-
无须在定义时赋初值;
-
引用不是对象,没有实际地址,不能定义指向引用的指针;但指针是对象,存在对指针的引用,例:
int *p; int *&r = p; // r是对指针p的引用注:上面的代码如何阅读?从又向左阅读r的定义,离变量名最近的符号(此处为
&)对变量的类型有直接的影响,因此上文中r是一个引用。
void *可用于存放任意对象的地址,我们不清楚其到底指向的是什么类型的对象,也无法访问其指向的内存空间中的对象。
double a = 3.14;
void *ptr = &a;
cout<<*ptr<<endl; //报错
定义多个变量时,类型修饰符(如 *)只修饰一个变量,对该声明语句中的其他变量,不产生任何作用。例,
// 这样写容易产生误导
int* p1,p2; // p1是指向int的指针,p2是int
// 建议写成
int *p1, p2;
2.5 const
- const的宗旨:任何试图改变
const修饰的变量都将引发错误 - const对象一旦创建就不能改变,因此必须初始化,初始值可以是任意复杂表达式
- 默认状态下,const对象仅在文件内生效。如果想要在多个文件中共享,最好的办法是不管是声明还是定义都加上
extern关键字。
2.5.1 常量引用
-
即对const的引用
-
初始化常量引用允许用任意表达式作为初始值,只要该表达式的结果能转换成引用的类型即可。例:
double a = 3.14; //const int temp = a; // <-编译器内部自己做的操作,生成一个临时变量 //const int &r = temp; //<-编译器内部自己做的操作,将引用绑定到一个临时变量上 const int &r = a; //正确
2.5.2 指针和const
-
指针常量 -- 指向常量的指针
-
想要存放常量对象的地址,只能使用指向常量的指针;
const double pi = 3.14; const double *cptr = π -
允许一个指向常量的指针指向非常量对象。
-
-
常量指针 -- 指针本身是一个常量
- 把*放在const之后,用以说明指针是一个常量
int a = 0; int *const ptr = &a;
- 把*放在const之后,用以说明指针是一个常量
2.5.3 顶层const和底层const
- 顶层const表示指针本身是一个常量。推广:任意的对象是常量,如算术类型、类、指针...
- 底层const表示指针所指的对象是常量。推广:指针和引用等复合类型的基本类型部分有关。
当执行拷贝时,
- 顶层const不受影响;
- 底层const对象必须具有相同的const资格,或者两个对象的数据类型必须能够转换。
2.5.4 常量表达式和constexpr
-
常量表达式
-
常量表达式是指:值不会改变 且 在编译过程就能得到计算结果 的表达式
-
一个对象是不是常量表达式有其数据类型和初始值共同决定
/*********** 例1 **************/ const int mf = 20; const int limit = mf +1; /*********** 例2 **************/ #include <iostream> using namespace std; int get_size() { return 1; } int main() { const int sz = get_size(); // 通过 cout << sz << endl; // 输出1 return 0; }
-
-
constexpr-- 由编译器来验证变量是否是一个常量表达式。声明为constexpr的变量:-
一定是一个常量
-
必须用常量表达式初始化
/*********** 例1 **************/ constexpr int mf = 20; constexpr int limit = mf +1; /*********** 例2 **************/ #include <iostream> using namespace std; //int get_size() { return 1; } //C++表达式必须含有常量值,无法调用非constexpr函数 //const int get_size() { return 1; } //同上 constexpr int get_size() { return 1; } int main() { constexpr int sz = get_size(); cout << sz << endl; // 输出1 return 0; } -
-
字面值类型
-
算术类型、引用和指针都属于,可被定义为constexpr;
注意:
-
引用和指针初始值受限:必须是0或者nullptr,或者存储于某个固定地址中的对象。函数提内的对象一般不在固定地址,不能用constexpr;允许函数定义的一类超出函数体本身的变量,其存在于固定地址,constexpr引用(指针)也能(绑定)指向该变量。
-
constexpr定义了一个指针,constexpr仅对指针本身有效,对指针所指的对象无关 <-顶层const。
constexpr int *q = nullptr; // 类似 int *const q = nullptr; //---------------------------------- //可得 constexpr const int *p = nullptr; // 类似 const int *const p = nullptr;
-
-
io、string等不属于字面值类型
-
-
constexpr函数(笔记6.5.3)
-
constexpr类(笔记7.4.2)
2.6 处理类型
2.6.1 类型别名
-
typedeftypedef double wages; typedef wages base, *p; //base = double, p = double * -
usingusing wages = double;
需要注意的是,类型别名不能直接往代码中替换,要将类型别名看成一个整体:
typedef char *pstring; //pstring = char *
const pstring cstr = 0; // 指针本身是一个常量,char *const cstr = 0
//直接替换是错误的:
const char *cstr = 0; //指向常量的指针
2.6.2 auto
-
auto定义的变量必须有初始值
-
编译器以引用对象的类型作为auto的类型(auto会忽略引用)
int i = 0, & r = i; auto a = r; // auto = int -
auto一般会忽略掉顶层const,保留底层const。想要保留顶层const,则需要手动指出
int i = 0; const int ci = i, & cr = ci; auto b = ci; //int (顶层const) auto c = cr; //int (顶层const) auto d = &i; //int * (顶层const) auto e = &ci; //const int * (底层const) const auto f = ci; //const int (为保留顶层const而手动指出) -
auto和引用
auto &g = ci; //g 的类型为const int & //auto &h = 42; //错误,不能为非常量引用绑定字面值 const auto &h = 42; //const int & -
利用auto在一条语句中声明多个变量时,这多个变量的初始值必须是同一类型。
2.6.3 decltype
-
选择并返回操作数的数据类型 -- 编译器分析表达式并得到其类型,却不计算其值
decltype(func()) sun = x; -
如果decltype使用的表达式是一个变量,则decltype返回该变量的类型(包括顶层const和引用)<-区别于auto
const int ci = 0, &cj = ci; decltype(ci) x= 0; // const int decltype(cj) y = x; //const int & -
decltype和引用
int i = 42, *p = &i, &r = i; decltype(r+0) b; //decltype(*p) c; //出错,“引用变量c需要初始值设定项” decltype(*p) c = i; //c的类型是int & decltype(i) d; // int decltype((i)) e = i; //int &decltype(r)的结果是引用,如果想让结果类型是r所指的类型,只需把r作为表达式的一部分,如decltype(r+0)- decltype表达式的类型是解引用操作,将得到引用类型,因此必须初始化,如
decltype(*p) c = i; decltype((variable))(注意是双层括号)的结果永远是引用类型
三 字符串、向量和数组
3.1 using
-
每个名字都需要独立的
using声明using std::cout; using std::endl; -
注意:头文件中不应包含
using<-否则,每个使用该头文件的代码都会包含该声明,从而引起命名的冲突。
3.2 string
[笔记9.6 - string专题](# 9.6 string专题)
3.2.1 初始化
- 拷贝初始化。
string s = "a"; - 直接初始化。
string s("a");

[笔记9.6.2 其他初始化string的方法](#9.6.2 构造string的其他方法)
3.2.2 string对象的操作

-
读写
-
读取操作时,string对象会自动忽略开头的空白,并从真正的第一个字符开始读起,直到遇到下一个空白。
//输入" hello world"; string s; cin>>s; cout<<s<<endl; //hello string s1,s2; cin>>s1>>s2; cout << s1<<s2<<endl; //helloworld //endl 结束当前行,刷新缓冲区 -
读取未知数量的string对象
string s; while(cin>>s){ //遇到文件结束标记或非法输入,循环结束 } -
读取一整行
string line; while(getline(cin,line)){}getline从给定的输入流中读取内容,直到遇到换行符为止(换行符也被读取进来了),将内容存入string对象中(不存换行符)。- 如果一开始就是换行符,则得到空的string对象。
- 和cin一样返回流参数,因此可作为循环的判断条件
-
-
size
size()返回一个string::size_type类型的值,是一个无符号类型的值,因此要避免与有符号数混用所带来的问题。
-
相加
当把string对象和字符字面值及字符串字面值混在一条语句中使用时,必须确保每个加法运算符两侧的运算对象至少有一个是string.string s = "hello"; string s1 = s+","; //正确 string s2 = "hello"+","; // 错误 string s3 = s+","+"hello"; //正确 //等价于 string s3 = (s+",")+"hello"; //等价于 string tmp = s1+","; string s3 = tmp+"hello"; string s4 = "hello"+","+s; //错误
3.2.3 处理string对象中的字符
- 处理函数

-
范围for
- 注意declaration是引用时,是直接对experssion中原来的元素进行操作
for(declaration : experssion){ statement } -
下标运算符([ ])接收的输入是
string::size_type类型的值,返回值是该位置上字符的引用。str[str.size()-1]是最后一个字符- 在访问指定字符之前,需要检查字符串是否为空:
if(!str.isempty()){ /*访问指定字符*/},并注意下标的合法范围[0 , str.size())。
3.3 vector
3.3.1 初始化vector对象

-
使用拷贝初始化(=)只能提供一个初始值;
-
类内初始值只能使用拷贝初始化或使用花括号形式的初始值;
-
列表初始化使用{},而不是()
-
值得注意的是
vector<string> v1{10}; // 10个默认初始化的元素 vector<string> v2{10,"hi"}; // 10个值为hi的元素以上两者都不是列表初始化,花括号的值必须与元素类型相同,显然不能用int初始化string对象,因此上面两者的花括号中都不能作为元素的初始值。在无法执行列表初始化后,编译器会尝试用默认值初始化vector对象。
-
3.3.2 vector操作
-
添加元素 --
push_back()-
在定义vector对象的时候设定其大小就没什么必要了,事实上如果这么做性能可能更差
-
-
vector其他操作罗列
-
注意
size()同样返回vector<xxx>::size_type类型要使用
size_type类型,需要首先指定它是由哪些类型定义的

-
-
只有当元素的值可比时,vector对象才能被比较:元素个数相等,对应位置的元素也相等
3.3.3 迭代器
-
用法

在for循环中使用
!=,原因是c++程序员更愿意使用迭代器而非下标。并非所有的容器的迭代器都定义了<等,但都定义了==和!= -
迭代器的类型 --
iterator和const_iterator(只读)- 如果迭代器对象是一个常量,则只能用const_iterator
- 不是常量,则都能用
-
begin和end、cbegin和cend
-
它们返回的具体类型由对象是否是常量决定,如是常量返回const_iterator,否则返回iterator
-
如果只需读取,而不写入,可使用
cbegin和cend,返回const_iteratorvector<int> v; const vector<int> cv; auto it1 = v.begin(); // vector<int>::iterator auto it2 = cv.begin(); // vector<int>::const_iterator auto it3 = v.cbegin(); // vector<int>::const_iterator
-
-
使vector迭代器失效的操作:
- 在范围for循环中向vector对象添加元素
- 任何一种可能改变vector对象的操作,如push_back
-
运算

- 迭代器相减的结果的类型:
difference_type的带符号整型数
- 迭代器相减的结果的类型:
3.4 数组
3.4.1 定义和初始化数组
-
定义
- 编译的时候维度必须是已知的,维度必须是一个常量表达式(
constexpr) - 和内置类型的变量一样,如果在函数内部定义了某种内置类型的数组,那么默认初始化会令数组含有未定义的值
- 不许用auto指定数组;
- 不存在引用的数组
- 编译的时候维度必须是已知的,维度必须是一个常量表达式(
-
初始化
-
显式地初始化数组
-
列表初始化时,可不写维度,编译器会自动推测
-
指明维度后,初始值数量不应超过维度大小
-
-
字符数组的特殊性 -- 注意字符串结尾的空字符也会被拷贝到数组中
char a3[] = "c++"; // 维度为4 // 相当于 char a3[] = {'c','+','+','\0'}; -
数组不允许拷贝和赋值
int a[] = {0,1,2}; int a2[] = a; // 错误 a2 = a; // 错误 -
复杂的数组声明
int (*parray)[10] = &arr;从数组名开始,由内向外,由右向左 -->parray是一个指针,指向大小为10的数组,数组中包含int对象
-
-
在使用数组下标时,通常将其定义为
size_t类型,它是一种无符号整型,定义于cstddef中 -
两个特殊性质
- 不允许拷贝数组
- 使用数组时通常会将其转化成指针
3.4.2 指针和数组
-
数组名是指向数组首元素的指针
-
auto推断得到的类型是指针int ia[] = {0,1,2}; auto ia2(ia); // auto == int * -
使用
decltype时,返回的类型是数组 <-- 与auto区分decltype(ia) ia3 = {0,1,2,3}; ia3[1] = 5;
-
-
"迭代器"
-
获取数组的“尾后迭代器” <--不能对尾后指针进行解引用或者递增
int *e = &arr[/*元素个数*/]; -
然而这种方法极易出错,c++11在
iterator头文件中定义了两个函数begin和end,它们分别返回头指针和尾指针,用法如下#include <iterator> int ia[] = {0,1,2,3}; int *begin = begin(ia); // 正确的使用形式是将数组作为它们的参数 int *end = end(ia);
-
-
两个指向同一数组不同元素的指针相减得到它们之间的距离,类型为
ptrdiff_t,定义于cstddef,为带符号类型。[(对比3.3.3节-运算-两个迭代器相减的结果类型)](#3.3.3 迭代器) -
与vector与string等标准库下标运算仅支持无符号数不同,数组的下标运算(内置下标运算)支持负数
int a[] = {0,1,2,3}; int *p = &a[2]; int j = *(p+1); // j = a[3] int k = p[-2]; //k = a[0]
3.4.3 多维数组
严格来说,c++没有多维数组,所说多维数组其实是数组的数组。谨记这一点,对今后理解和使用多维数组大有裨益。
-
int arr[3][4]: 大小为3的数组,每个元素是含有4个整数的数组 -
初始化
int ia[3][4] = {{0,1,2,3}, {4,5,6,7}, {8,9,10,11}}; //等价 int ia[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11}; //---------------------------------------- //初始化每行首元素 int ia[3][4] = {{0},{4},{8}}; //不等于 int ia[3][4] = {0,4,8}; -
下标和多维数组 略
-
范围for处理多维数组
for(const auto & row :ia){ <--注意此处一定为 引用,原因如下所述 for(auto col :row){ cout<<col<<endl; } }auto会将数组自动转成指针 (3.4.2节-
auto推断得到...),row的类型就成了int *,怎么可能再进行内层循环呢? -
指针和多维数组
-
多维数组名 :指向第一个内层数组的指针
for(auto p = begin(ia); p!=end(ia); p++){ for(auto q = begin(*p); q != end(*p); q++){ /*...*/ } }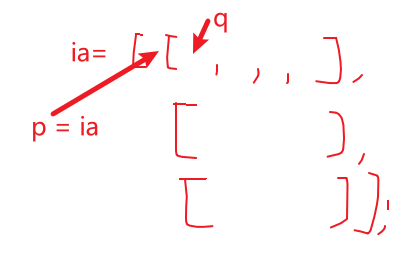
-
参考资料
-
3.4.4 与旧代码接口
-
C风格字符串
-
c++程序中最好不要使用

-
传入上述函数的指针必须指向以空字符串作为结束的数组
-
string和c风格字符串
- 任何出现字符串字面值的地方都可以用 以空字符结束的字符数组 替代
- 允许用...来初始化string对象或为string对象赋值
- 允许作为加法运算中的一员(P111)
- 但是,不能反过来用string对象直接初始化指向字符数组的指针,
string.c_str()返回一个指向以空字符结束的字符数组的指针(char *),数组存放的数据恰好与string对象一样;- 但如果后续操作改变string,之前返回的字符数组将会失效
- 任何出现字符串字面值的地方都可以用 以空字符结束的字符数组 替代
-
使用数组初始化vector
- 允许使用数组来初始化vector对象,只需指明首元素地址和尾后地址
int arr[] = {0,1,2,3,4,5}; vector<int> ivec1(begin(arr),end(arr)); //{0,1,2,3,4,5} vector<int> ivec2(arr+1,arr+3); //{1,2} <--不包含rr[3]
- 允许使用数组来初始化vector对象,只需指明首元素地址和尾后地址
四 表达式
4.1 基础
-
小整数类型(bool、char、short等)通常会被提升成较大的整数类型,主要是int
-
运算符重载时,运算对象的个数、运算符的优先级和结合律都是无法改变的
-
左值和右值 <-- 有些迷惑(P121,2024/1/13)
-
左值表示一个占据内存中可识别位置的一个对象,更进一步地,可以对左值取地址
-
判断右值的一个简单方法就是能不能对变量或者表达式取地址,如果不能,他就是右值
-
参考文献
-
-
求值顺序
-
对于那些没有指定执行顺序的运算符来说,如果表达式指向并修改了同一个对象,将会引发错误并产生未定义的行为。
-
求值顺序与优先级和结合律无关(P123底部) <--拿不准的时候用括号来强制符合要求
如,int i = f()+g()*h()+j() 这些函数的调用顺序没有明确的规定,如果它们互不相关,则无妨。如果其中某几个函数影响同一个对象,则将会产生未定义行为 -
这4种运算符明确规定了运算对象的求值顺序:
&&,||,?:,, -
例外情况:当 改变运算对象的子表达式本身 就是 另一个子表达式的运算对象 ,则没有什么影响:如
*++iter,递增运算先发生(改变运算对象的子表达式),解引用后发生。
-
4.2 运算符
本节运算符表都是按照优先级顺序将其分组,同优先级按照从左到右的顺序。
4.2.1 算术运算符
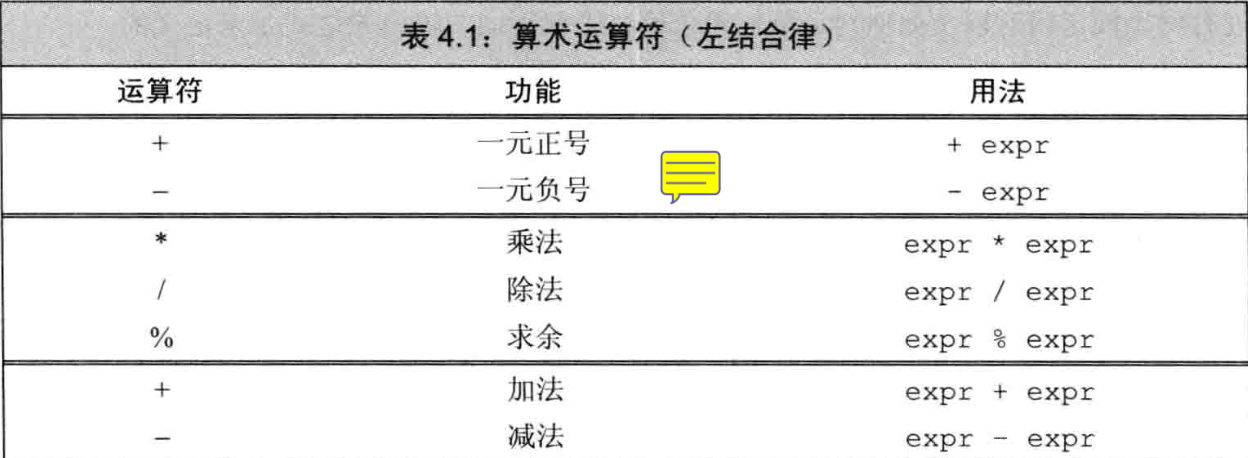
- 算术对象和求值结果都是右值
- 小整数的对象被提升成较大整数
- 一元正号、加法、减法运算符都能作用于指针
- 一元正(负)号,(负数将运算对象值取负后)返回对象值的一个(提升后的)副本
- c++11规定商一律向0取整
%返回两个整数相除所得的余数- 如果
m%n!=0,结果符号与m相同
4.2.2 逻辑和关系运算符

- 关系运算符作用于算术类型或指针类型,逻辑运算符作用于任意能转换成布尔值的类型。
- 返回值都是布尔类型,运算结果和求值对象都是右值
- 因为关系运算法的求值结果是布尔类型,所以将几个关系运算符连写在一起会产生意想不到的效果
4.2.3 赋值运算符
- 赋值运算符的左侧运算对象必须是一个可修改的左值
- 右侧运算对象将转换成左侧运算对象的类型
4.2.4 递增、递减运算符
-
++、--运算符必须作用于左值运算对象,前置版本将对象本身作为左值返回,后置版本将对象原始值的副本作为右值返回 -
除非必须,否则不用递增递减运算符的后置版本 <-- 额外增加开销(P132)
-
如果一个子表达式改变了某个运算对象的值,另一条子表达式又要使用该值的话,运算对象的求值顺序就很关键了
//P133 *beg = toupper(*beg++); // 未定义行为
4.2.5 成员访问运算符
ptr->mem;
(*ptr).men;
-
解引用运算符的优先级低于点运算符,所以执行解引用运算的子表达式两端必须加上
():(*ptr).men -
箭头运算符作用于一个指针类型的对象,结果是一个左值。点运算符分成两种情况:如果成员所属的对象是左值,那么结果是左值;反之,如果成员所属的对象是右值,那么结果是右值。
4.2.6 条件运算符
condition ? expr1 : expr2;
-
当条件运算符的两个表达式都是左值或者能转换成同一类左值类型时,运算结果是左值,否者,运算结果是右值。
-
可嵌套,最好别超过2到3层,如
cond1?expr1:cond2?expr2:expr3; -
满足右结合律,右边的条件运算构成了靠左边条件运算的分支。上述代码实际为例。
cond1 ? expr1 : (cond2?expr2:expr3) // <--从右边开始结合,括号中的是分支 -
条件运算符的优先级非常低,当一条长表达式中嵌套了条件运算子表达式时,通常需要在其两端加上括号
4.2.7 位运算符
-
位运算符整数类型的运算对象,并且把运算对象看成二进制位的集和
-
如果运算对象是“小整型”,则它的值将会被自动提升为较大的整数类型。 —— 先提升,再对提升后的整体进行位运算
-
不同机器对于符号位的处理各不相同,因此建议位运算符仅用于处理无符号类型

-
移位运算符
-
<<、>>的右侧的运算符一定不能为负,并且值严格小于结果的位数 -
满足左结合律
cout << "hi"<<"three"<<endl; //等价于 ( (cout<<"hi") << "three" ) <<endl; -
示例
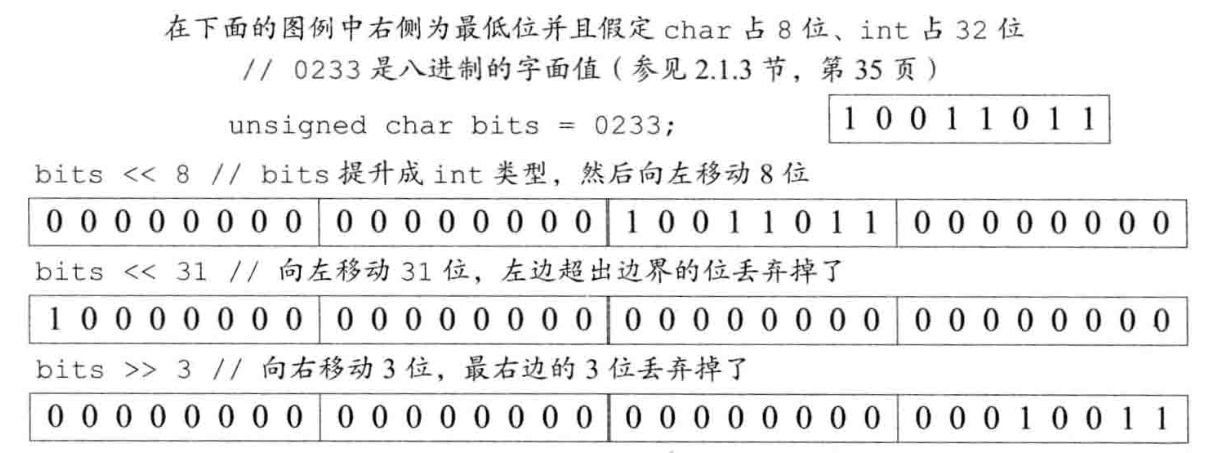
-
-
位求反运算符 略
-
位与、位或、位异或
- 异或 :不同出1,相同处0
4.2.8 sizeof运算符
-
sizeof返回一条表达式或一个类型名字所占的字节数,满足右结合律,得到size_t类型的常量表达式sizeof (type); // sizeof (类型名) sizeof expr; // sizeof 表达式 <-- 不实际计算表达式的值,意味着即使是无效指针依然安全 -
c++11新标准允许使用作用域运算符来获取类成员大小
sizeof Sale_data::revenue; -
常见的sizeof运算结果
-
char或类型为char的表达式,结果为1
-
引用类型,结果为被引用对象所占空间的大小
-
指针,指针本身所占空间的大小
-
解引用指针,指针指向的对象所占空间的大小,指针不需要有效
-
数组,整个数组所占的大小;等价于对数组中所有元素各执行一次sizeof并求和
int ia[] = {...} // 一个很多元素的数组 constexpr size_t sz = sizeof(ia) / sizeof(*ia); // 返回ia数组的元素的数量 int arr2[sz]; // sizeof返回一个常量表达式,所有可以用于声明数组的维度 -
string和vector,只返回该类型固定部分的大小,不会计算对象中的元素占用了多少空间。<-- 什么意思?没看懂
#include <iostream> #include <vector> using namespace std; int main() { cout<<sizeof(int)<<endl; // 4 vector<int> a(10, 5); // 10个5,10个int大小按理来说应该是40个字节 for (auto& ia : a) { cout << ia ; } cout << endl; cout << sizeof(a) << endl; // 却是32? <-- 不懂 return 0; }
-
4.2.9 逗号运算符
-
首先对左侧的表达式求值,然后将结果丢弃。真正的运算结果是右侧表达式的值,如果右侧运算对象是左值,那么最终的求值结果也是左值
-
一般用于for循环,例
vector<int>::size_type cnt = ivec.size(); for(vector<int>::size_type ix = 0; ix != ivec.size(); ++ix, --cnt){ ivec[ix] = cnt; }
4.3 类型转换
如果两种类型可相互转换,则它们是关联的。
4.3.1 隐式转换
-
算术转换
运算符的运算对象将转换至最宽的类型-
整型提升
- 小整数类型提升成较大的整数类型:bool、char、signed char、unsigned char、short、unsigned short 所有可能的值都能存在int里,则提升为int,否则为unsigned int
- 较大的char(wchar_t, char16_t, char32_t)提升成int、unsigned int、long、unsigned long、long long和 unsigned long long 中最小的一种类型
-
无符号类型的运算对象
-
注意有符号和无符号的混用带来的意外后果

-
-
-
数组转换成指针
- 在大多数情况下,数组名自动转化成数组首元素的指针
- 当数组名被用作
decltype关键字、取地址符、sizeof、typeid、用一个引用来初始化数组时,上述转化不会发生
-
指针的转换
- 0、nullptr能转化成任意指针类型
- 任意非常量指针能转换成void *
- 任意对象指针能转化成const void *
- 有继承关系的类型间
-
转换成bool
- 0:false 否则true
-
转换成常量
-
允许将指向非常量类型的指针(引用)转化成指向相应的常量类型的指针(引用)
-
不能反过来,因为这样试图删掉底层const
int i; const int *p = &i; const int &r = i;
-
-
类类型定义的转换 (P144)
- 类类型能定义由编译器自动执行的转换
- 每次只能执行一种类类型的转换
4.3.2 显式转换
cast-name<type>(expression)
type:要转换的类型,expression:要转换的值;如果type是引用类型,则结果是左值
cast-name包括:static_cast、dynamic_cast、const_cast和reinterpret_cast
-
static_cast <-- 最常用
-
任何具有明确定义的类型转换,只要不包含底层const,都可以使用static_cast
-
当需要把一个较大的算术类型赋给较小的类型时,利用static_cast可关闭“精度损失”的警告信息
-
利用static_cast找回void *指针。
void *p = &d; double * dp = static_cast<double *>(p); //确保等号两边类型一样,否则产生未定义行为
-
-
const_cast
-
只能改变对象的底层const,仅用于进行去除 const 属性,它也是四个强制类型转换运算符中唯一能够去除 const 属性的运算符。
-
要注意可能发生的未定义后果
-
[常用于有重载函数的上下文](#6.4 重载) <-- 比如?
-
用法举例
/*例1*/ //(P145,改) const int a = 0; const int* pc = &a; // 底层const cout << *pc << endl; //0 int* p = const_cast<int*>(pc); *p = 5; cout << *p << endl; //5 /*例2*/ // 参考文献[1] //const_cast只针对指针、引用、this指针 (只能改变对象的底层const) int main() { const int n = 5; int* k = const_cast<int*>(&n);//指针 *k = 123; cout << *k << endl; //123 int& kRef = const_cast<int&>(n);//引用 kRef = 456; cout << kRef << endl; //456 } /*例3*/ // 参考文献[1] class CTest { public: CTest() : m_nTest(2) {} //常成员函数,不能修改成员变量的值 void foo(int nTest) const { //void* p = this; //m_nTest = nTest; //m_nTest = nTest; 错误 //<CTest* const>指针地址不可改变,(this)代表常成员函数的this指针 //const_cast去除CTest*前面的const const_cast<CTest* const>(this)->m_nTest = nTest; } public: int m_nTest; }; int main() { CTest t; t.foo(1); } -
参考
-
-
reinterpret_cast
-
通常为运算对象的位模式提供较低层次上的重新解释
-
非常有风险
本质上依赖于机器,想要安全地使用必须对涉及的类型和编译器实现转换的过程都非常了解
-
-
dynamic_cast (19章介绍)
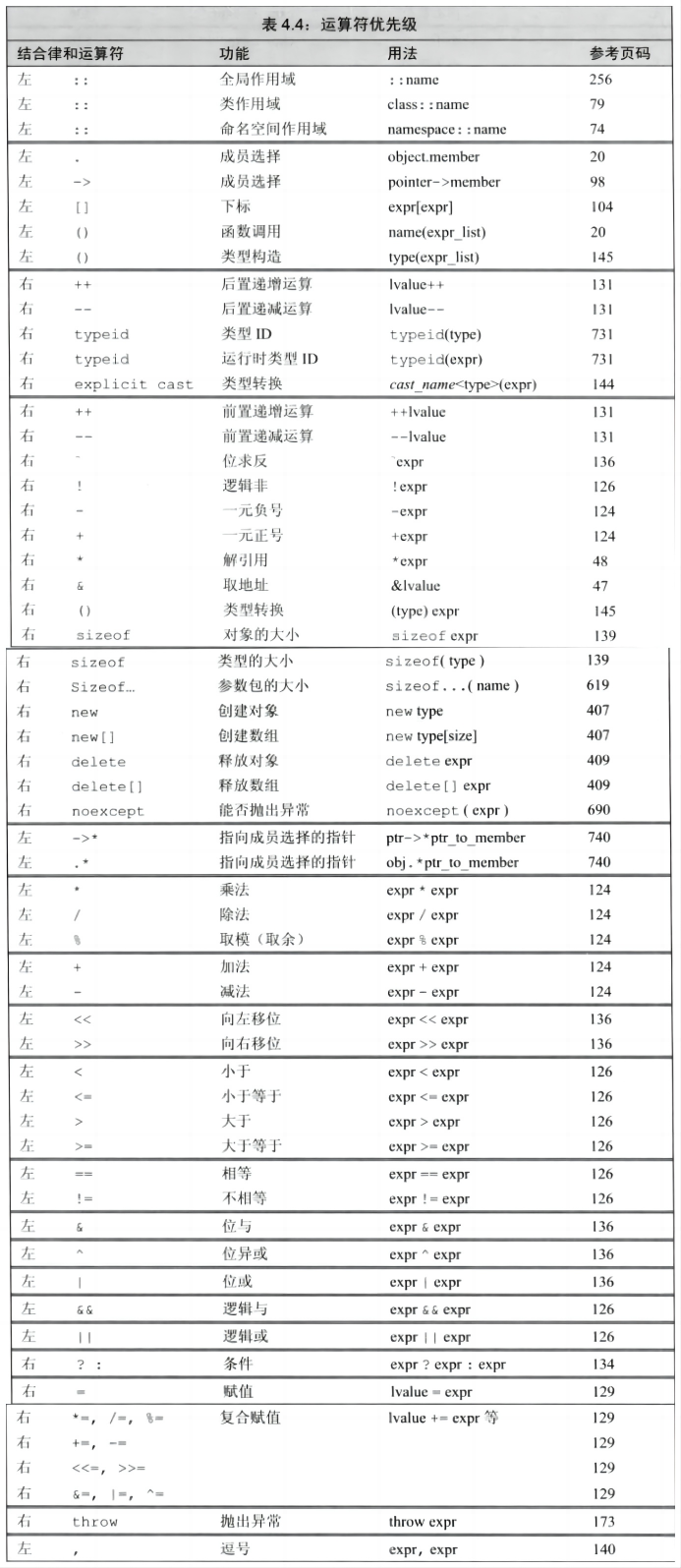
4.4 运算符优先级表
五 语句
5.1 简单语句
- 空语句 -- 没有什么用,但是需要注意对循环的影响
; //<--空语句,真么用也没有 int i = 0;; // <-- 不会报错,就是多了一条空语句 :)
5.2 作用域
略
5.3 条件语句
5.3.1 if...else
- 注意花括号
- 悬垂else
- 我们怎么知道给定的else和那个if相匹配? 这个问题被称为悬垂else
- c++规定,与离它最近的尚未匹配的if匹配,从而消除程序的二义性
5.3.2 switch...case
-
case标签必须是整型常量表达式
-
switch的默认动作是从某个匹配成功的case开始,顺序执行其下的所有case,直到遇到break。最好在每个case中都添加break,以避免不必要的问题。虽然在某些情况下,我们确实希望多个case共享同一组操作而不写break,此种情况最好加一段注释以说明。
-
最好添加default,声明我们已经考虑了默认情况,即使现在什么都没有做。
- 标签不应该孤零零地出现,它后面必须跟上一条语句或者另外一个 case标签。如果switch 结构以一个空的 default 标签作为结束则该default 标签后面必须跟上一条空语句或一个空块。 <-- (P163,没怎么懂在说什么)
-
switch内部的变量定义
-
在C++11的标准下,【变量定义】操作在编译阶段就会执行分配内存,而涉及【变量初始化】操作的语句则必须等到程序运行时才会调用执行。
-
因此对于
switch语句的使用,如果确实有需要在内部定义变量的场景,最好的方法就是在编程的时候,将整个switch语句中都用到的变量在switch外定义好,到了switch内部,则可以针对某个case需要单独使用某些变量的情况,用{}作用域符号来明确此case语句的作用域 -
参考文献
-
5.4 迭代语句
5.4.1 while
略
5.4.2 for
for(init-statemen; condition; expression){ statement; }
- 只要condition为真,就执行一次statement,如果为false,一次也不执行
- init-statemen可以定义多个变量,但只能有一条声明语句,因此意味着所有变量的基础类型必须相同
- init-statemen 、condition、 expression都可以省略(P167)
5.4.3 do...while
do{
statement;
}while(condition); //<--最后还有个分号
- condition不能为空
- condition使用的变量不能定义在循环体之外
- 不允许在condition部分定义变量
5.5 跳转语句
-
break
- 终止最近的
while,do...while,for,switch,并从这些语句之后的第一条语句开始执行;
- 终止最近的
-
continue
-
while,do...while,for可用 -
终止最近的循环中的当前迭代 并立即开始下一次迭代
-
-
goto
5.6 异常处理

5.6.1 异常类
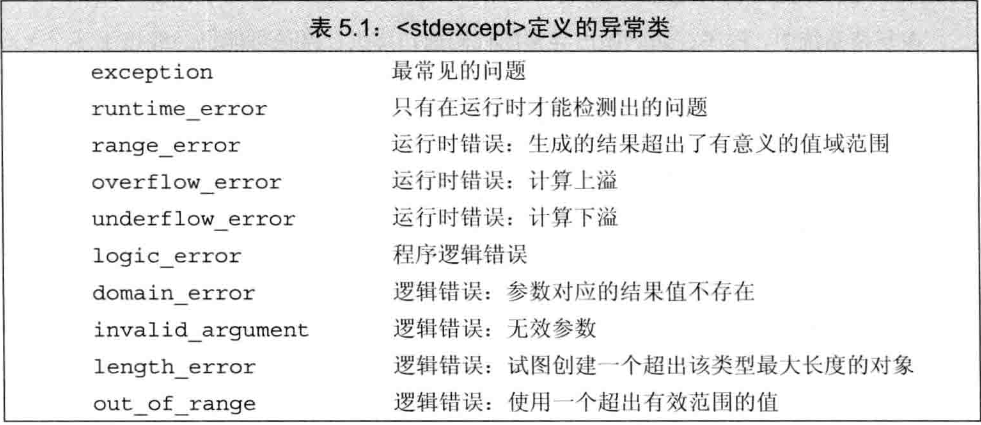
c++标准库定义了一组类,分别在4个头文件中:
- exception
- 定义exception,只报告异常的发生,不提供任何额外信息
- stdexcept
- 定义了几种常用的异常,下图列出
- new
bad_alloc(12章)
- type_info
bad_cast(19章)
其中,exception、bad_alloc、bad_cast只能默认初始化,不允许提供初值。反之,其余的异常类必须提供string或c风格字符串以初始化。
异常类只有一个名为what()的成员函数,没有任何参数,返回初始化异常类时用到string(c风格)字符串。对于默认初始化的异常类,返回内容由编译器决定。
5.6.2 抛出异常
用throw关键字抛出一个异常后,会直接跳转到对应的catch块,节选5.6.4中示例如下:
if (this->m_isbn != item.m_isbn){
throw runtime_error("data must refer to same isbn.");
}
return this->m_sales_volume + item.m_sales_volume;
5.6.3 处理异常
try...catch接住throw抛出的异常并处理,语法如下
try {
//正常逻辑
//抛出异常
}
catch (/*(可能未命名的)异常声明1*/) {
//异常处理1
}
catch (/*(可能未命名的)异常声明2*/) {
//异常处理2
}
catch一旦完成,程序跳转到try语句块最后一个catch子句之后的那条语句继续执行。
-
函数在寻找 异常处理代码 的过程中 退出(P175)
在复杂系统中,程序在遇到抛出异常的代码前,其执行路径可能已经经过了多个 try语句块。例如,一个try语句块可能调用了包含另一个try语句块的函数,新的try语句块可能调用了包含又一个 try 语句块的新函数,以此类推。
寻找处理代码的过程与函数调用链刚好相反。当异常被抛出时,首先搜索抛出该异常的函数。如果没找到匹配的 catch 子句,终止该函数,并在调用该函数的函数中继续寻找。如果还是没有找到匹配的 catch 子句,这个新的函数也被终止,继续搜索调用它的函数。以此类推,沿着程序的执行路逐层回退,直到找到适当类型的 catch 子句为止。
如果最终还是没能找到任何匹配的 catch 子句,程序转到名为
terminate的标准库函数。该函数的行为与系统有关,一般情况下,执行该函数将导致程序非正常退出。对于那些没有任何 try语句块定义的异常,也按照类似的方式处理:毕竟,没有 try语句块也就意味着没有匹配的catch 子句。如果一段程序没有 try 语句块且发生了异常系统会调用terminate函数并终止当前程序的执行。
5.6.4 示例
#include <iostream>
#include <string>
#include <stdexcept>
using namespace std;
class Sales_item {
public:
Sales_item(string isbn, int sales_volume)
:m_isbn{ isbn }, m_sales_volume{ sales_volume } {}
string isbn() const { return m_isbn; }
int saleVolume() const { return m_sales_volume; }
int operator+(Sales_item item) {
// 使用异常处理将相加的代码和与用户交互的代码分离
try {
if (this->m_isbn != item.m_isbn)
throw runtime_error("data must refer to same isbn."); //跳转到catch (runtime_error err) {行
return this->m_sales_volume + item.m_sales_volume;
}
catch (runtime_error err) {
cout << err.what() << endl;
}
return -1;
}
private:
string m_isbn;
int m_sales_volume; //销售额
};
int main() {
Sales_item item1("1-2-3", 10);
Sales_item item2("1-2-3", 11);
Sales_item item3("4-5-6", 12);
int res1 = item1 + item2;
cout << res1 << endl;//21
int res2 = item1 + item3;
cout << res2 << endl;//失败并输出-1
}
六 函数
6.1 基础
- 函数最外层的作用于中的局部变量也不能使用和函数形参一样的名字。(P184顶部,不理解)
- 函数的返回类型不能是数组类型或函数类型,但可以是指向数组或函数的指针
- 函数的三要素(返回类型、函数名、形参类型)描述了函数的接口,函数声明也被称为函数原型
- 局部静态对象:在局部变量前加
static,第一次经过该对象定义语句的时候初始化,并且直到程序终止才销毁,在此期间即使对象所在的函数结束也不会对它有影响。
6.2 参数传递
6.2.1 参数传递的方式
- 值传递
- 指针传递
- 其实是一种形式的值传递
- 在c++中,建议用引用类型的形参代替指针
- 引用传递
- 当函数无须修改引用形参的值时最好使用常量引用
- 使用引用形参返回额外的信息
6.2.2 const形参和实参
-
顶层const被忽略
-
当形参有顶层const时,形参的顶层const被忽略,传给他常量对象或非常量对象都是可以的
-
因为顶层const被忽略掉了,所以下述的两个func是一样的,不能[重载](#6.4 重载)
int func(const int i) { return i; } int func(int i) { return i; } // 函数“int func(const int)”已有主体
-
-
指针或引用参与const
-
遵循“任何可能引发修改const值的操作都是非法的”
-
P191,略
-
-
尽量使用常量引用
-
把函数不会改变的形参定义成普通的引用是一种比较常见的错误,
-
会给函数调用者“函数可以修改它们实参值的误导”
-
极大限制函数所能接收的实参类型(我们不能把const对象、字面值或者需要类型转换的对象传递给普通的引用形参)
/*例1*/ string func(const string&i){ return i; } int main() { cout << func("a") << endl; // a return 0; } /*例2*/ string func( string&i){ return i; } int main() { //无法用 "const char [2]" 类型的值初始化 "std::string &" 类型的引用(非常量限定) cout << func("a") << endl; return 0; }
-
-
参考文献
6.2.3 数组形参
-
因为不能拷贝数组,我们无法以值传递的方式使用数组参数;又因数组会被转换成指针,所以当我们为函数传递一个数组时,实际上传递的是指向数组首元素的指针。
-
三种等价的数组传参方式,数组大小对函数调用无影响
//等价 void func(const int *); void func(const int[]); void func(const int[10]); // 10表示我们期望,实际上不一定 -
数组以指针传参,函数不知道大小,有三种常用管理方式管理指针形参:
-
使用 结束标记 指定数组长度
- 使用 类似c风格字符串数组的结束标记 标记数组结束的位置
-
使用标准库规范
- 使用begin和end函数,传递首元素和尾后元素的指针
void func(const int*beg, const int*end){ while(beg != end) cout<<*beg++<<endl; } /////调用 int j[] = {0,1,2}; func(begin(j),end(j));
- 使用begin和end函数,传递首元素和尾后元素的指针
-
显式传递一个表示数组大小的形参 -- 旧式风格
void func(const int *ia, size_t size){ } /////调用 int j[] = {0,1,2}; func(j, end(j) - begin(j) );
-
-
数组引用形参
-
形参是数组的引用,维度是类型的一部分
-
下例中,
(&arr)括号必不可少,否则int &arr[10]是将arr声明成了引用的数组 -
下例中,[10]不可少,因为数组的大小是构成数组的一部分,只能将函数作用于大小为10的数组
void func(int (&arr)[10]){}
-
-
传递多维数组
- 多维数组是数组的数组,又因为将数组传递进函数的时候,传入的是指向第一个元素的指针。所以将多维数组传入函数,传入的是指向第一个数组(即多维数组的第一个元素)的指针。函数声明可以写为
//形参matrix看起来是一个二维数组,实际上是指向含有10个整数的数组的指针 void func(int matrix[][10],int rowSize){} //matrix是一个指针,指向10个整数的数组 void func(int (*matrix)[10], int rowSize){} //int (*matrix)[10] 小括号不可少,否则是10个指针构成的数组
- 多维数组是数组的数组,又因为将数组传递进函数的时候,传入的是指向第一个元素的指针。所以将多维数组传入函数,传入的是指向第一个数组(即多维数组的第一个元素)的指针。函数声明可以写为
-
main处理命令行
int main(int argc, char **argv){} int main(int argc, char *argv[]){}
6.2.4 可变形参
可变形参用于编写可处理不同数量实参的函数,主要有三种方法:
-
initializer_list-
要求所有实参类型相同
-
其中的对象永远是常量,无法改变其中的元素值
-
如果向其中传递的是一个序列,则必须放在花括号中
-
示例
/*声明*/ void error(ErrorCode e, initializer_list<string> il){ cout<<e.msg()<<endl; for(auto &msg : il) cout<<msg<<endl; } /*调用*/ error_msg(ErrorCode(0), {"functionX","okay"} );
-
-
可变参数模板 (16章)
- 实参类型不同
-
省略符
-
varargsc标准库功能 -
省略符只能出现在形参列表的最后一个位置
-
仅用于c和c++通用的类型,大多数类类型的对象在传递给省略符形参时都无法正确拷贝
-
示例
void foo(parm_list, ...); void foo(...);
-
6.3 返回类型和return
6.3.1 有返回值的函数
-
在含有return语句的循环后面也有一条return语句
-
不要返回 对局部对象的引用 或 指向局部变量的指针,局部变量在函数完成后已经被释放
/* * 在vs2022上测试,该程序能正常编译和运行, * 但是运行结果不对, * 显然意味着这种错误不容易被发现 */ const string& test() { string a; a = "a"; if (!a.empty()) return a; else return "empty"; } int main() { cout << test() << endl; // 期望输出a,实际上输出空 return 0; } -
引用返回左值
-
调用一个返回引用的函数得到左值,其他返回类型得到右值
-
我们能为返回类型是非常量引用的函数的结果赋值
char& get_val(string &str, string::size_type ix) { return str[ix]; // 返回对 str[ix]的引用 } int main() { string s = "a test"; get_val(s, 0) = 'A'; cout << s << endl; return 0; }
-
-
可返回列表初始化,
return {"funcX","okay"} -
main函数的返回值
-
cstdlib中定义了两个预处理变量,表示成功或者失败return EXIT_FALLURE; return EXIT_SUCCESS;
-
-
递归
- 在递归函数中,一定有某条路径是不包含递归调用的,否则将一直递归循环,直至内存耗尽
6.3.2 数组指针
数组不能被拷贝,所以函数不能返回数组,不过函数可以返回数组的指针或引用。定义一个返回数组的指针或引用的函数有如下几种方法:
-
使用类型别名
/*两个等价的定义类型别名的方法*/ //arrT是一个类型别名,它表示的类型是含有10个整数的数组 typedef int arrT[10]; using arrT = int[10]; /*使用*/ arrT *func(int i); -
普通方法
int (*func(int i))[10];
-
尾置返回类型
- c++11新标准可使用 ,将返回类型放在
->后,并在原来写返回值类型的地方放个autoauto func(int i) -> int(*)[10]; // 返回一个指针,指向放10个int数据的数组
- c++11新标准可使用 ,将返回类型放在
-
decltype
int odd[] = {1,3,5,7,9}; int even[] = {2,4,6,8}; decltype(odd) *arrPtr(int i){ return (i%2) ? &odd : &even; }decltype 并不负责把数组类型转换成对应的指针,所以decltype 的结果(即
int[])是个数组,要想表示 arrPtr 返回指针还必须在函数声明时加一个*符号。
6.4 重载
- 如果同一作用域内的几个函数名字相同但形参列表不同,称之为函数重载(overloaded)
- 重载和const形参
- [顶层const不影响传入的对象,有无顶层const不能构成重载](#6.2.2 const形参和实参)
- 底层const会实现重载:
- 指向const的指针(引用)传递给const形参
- 对于非常量,编译器会优先选择非常量版本的函数 (6.6-最佳匹配-实参类型的转换)
- 重载和const_cast
- const_cast在重载函数的情境中最有用 -- 保障了安全性

- const_cast在重载函数的情境中最有用 -- 保障了安全性
- 重载与作用域
- 不要把函数声明置于局部作用域内
6.5 特殊用途语言特性
6.5.1 默认实参
-
一旦某个形参被赋予了默认值,其后所有形参都必须有默认值
-
默认实参负责填补函数调用缺少的尾部实参
-
合理设置形参顺序,将经常使用默认值的形参放在后面
-
函数后续声明只能为之前那些没有默认值的形参添加默认实参,而且该形参右侧的所有形参必须都有默认值
string screen(sz,sz,char=' '); string screen(sz,sz,char= '*'); //错误,重复声明 string screen(sz = 24, sz = 80, char);// 正确,添加默认形参 -
默认实参初始值
-
局部变量不能作为默认实参,用作默认实参初始值的 表达式的值 必须声明在函数之外
-
只要表达式的类型能转换成形参所需的类型,该表达式就能作为默认实参
sz wd = 80; char def = ' '; sz ht(); string screen(sz = ht(), sz = wd, char = def) void f2() { string window = screen(); //screen(ht(), 80, ' ' ); def = '*'; // 将传递这个更新过的 全局变量的 值 sz wd = 100; //局部变量与默认实参没有任何关系 window = screen(); //screen(ht(), 80, '*'); }
-
6.5.2 内联函数
-
inline -
对编译器的建议,
-
加速程序
6.5.3 constexpr函数
-
能用于常量表达式的函数
-
函数的返回类型及所有形参的类型都得是字面值类型,函数体中必须有且只有一条return语句
constexpr int new_sz() {return 42;} -
初始化任务时,编译器会把constexpr函数的调用替换成其结果值,函数被隐式地指定为内联函数
int arr[new_sz()]; -
constexpr函数中也可以包含其他语句,只要这些语句在运行时不执行任何操作(空语句、typedef、using) <-- 唯一可执行的语句就是return
-
允许返回非常量:当实参是是一个常量表达式时,返回常量表达式,反之则不然: <-- constexpr函数不一定返回常量表达式
constexpr int scale(size_t cnt) {return new_sz() * cnt ;} int arr[scale(2)]; // 正确 int i = 2; int arr[scale(i)]; //错误,返回的不是常量表达式,无法初始化数组
6.5.4 调试帮助
-
assert(expr)--#include <cassert>- expr为假,输出信息并终止,为真,什么也不做。即expr为不可能情况
-
NDEBUG预处理变量
-
针对
assert():定义NDEBUG能避免检查各种条件所需的运行时开销,当然此时根本就不会执行运行时检查。因此,assert 应该仅用于验证那些确实不可能发生的事情。我们可以把assert当成调试程序的一种辅助手段,但是不能用它替代真正的运行时逻辑检查,也不能替代程序本身应该包含的错误检查。/*例1*/ #include <cassert> int main() { int i = 5; assert(i > 6); // Assertion failed: i > 6, file ... line 4 return 0; } /*例2 NDEBUG要写在整个程序的开头,否则没有用*/ #define NDEBUG #include <cassert> int main() { int i = 5; assert(i > 6); // 失效 return 0; } /*例3 NDEBUG要写在整个程序的开头,否则没有用*/ #include <cassert> #define NDEBUG int main() { int i = 5; assert(i > 6); // Assertion failed: i > 6,file ... return 0; } -
针对
#ifndef ...#endif- 如果定义了NDEBUG,
#ifndef ...#endif之间的代码将被忽略
//#define NDEBUG #ifndef NDEBUG ... #endif-
补充,预处理器定义的几个 用于调试程序的 变量
变量名 功能 __func__const char 的一个静态数组,存放函数的名字 __FILE__存放文件名的字符串字面值 __LINE__存放当前行号的整型字面值 __TIME__存放文件编译时间的字符串字面值 __DATE__存放文件编译日期的字符串字面值 //示例 std::cout<<__func__ <<"in file: "<<__FILE__ <<"line "<<__LINE__;
- 如果定义了NDEBUG,
-
6.6 函数匹配
-
候选函数
- 与被调用的函数同名
- 其声明在调用的可见
-
可行函数 -- 从候选函数中选出能被这组实参调用的函数
- 实参数量相等,类型相同
-
最佳匹配
-
单个参数:实参类型与形参类型越接近,它们匹配得越好
-
多个参数:如果有且只有一个函数满足下列条件,则匹配成功。如果在检查了所有实参之后没有任何一个函数脱颖而出,则该调用是错误的。编译器将报告二义性调用的信息。
- 该函数每个实参的匹配都不劣于其他可行函数需要的匹配。
- 至少有一个实参的匹配优于其他可行函数提供的匹配。
-
实参类型的转换 (P219)
-
编译器将实参类型到形参类型的转换划分成几个等级:

-
在设计良好的系统中函数很少会含有与下列例子相似的形参:(P219底部-220)
- 假设有两个函数,一个接受 int、另一个接受short,则只有当调用提供的是 short 类型的值时才会选择 short 版本的函数。有时候,即使实参是一个很小的整数值,也会直接将它提升成int 类型。
- 所有算术类型转换的级别都一样。例如,从int 向unsigned int 的转换并不比从int向 double的转换级别高。当存在两种可能的算数类型转换时,调用具有二义性。
-
重载忽略顶层const,因此顶层const不能用于重载;而底层const可重载:如果重载函数的区别在于它们的引用类型的形参是否引用了 const(或者指针类型的形参是否指向const),则当调用发生时编译器通过实参是否是常量来决定选择哪个函数:
int lookup(string&); int lookup(const string &); int a; const int b; lookup(a); // 调用 lookup( string &); lookup(b); // 调用 lookup(const string &);
-
-
6.7 函数指针
6.7.1 函数指针是什么?
-
函数指针指向的是函数而非对象
-
函数指针指向某种特定类型。函数的类型由它的返回类型和形参列表共同决定,与函数名无关
// 函数 bool lengthCompare(const string &, const string &); // 类型 bool(const string &, const string &); //指向函数的指针 bool (*ptr)(const string &, const string &) /*ptr是一个指针,指向参数是(const string &, const string &)的函数,返回bool类型*/ /*(*ptr)的括号不可少,否则ptr变成了一个返回 bool* 类型的函数*/
6.7.2 如何使用
- 当我们把函数名作为一个值使用时,该函数自动转换成指针
- 还能指向函数的指针调用该函数,而无须提前解引用指针
- 不同类型的函数指针间不存在转换
- 可用nullptr或0初始化指针
/* 函数 */
bool lengthCompare(const string &, const string &);
/* 指向函数的指针 */
bool (*ptr)(const string &, const string &);
/*声明的同时定义*/
bool (*ptr)(const string &, const string &) = lengthCompare;
/* 初始化 */
ptr = nullptr;
/* 赋值 */
ptr = lengthCompare;
// 等价于
ptr = &lengthCompare;
/* 调用 */
bool b = ptr("hello", "goodbye");
//等价
bool b = (*ptr)("hello", "goodbye");
//等价
bool b = lengthCompare("hello", "goodbye")
6.7.3 重载函数的指针
- 编译器通过指针类型决定选用哪个函数
- 指针类型必须与重载函数中的某一个精确匹配
//重载的func函数
void func(int *);
void func(unsigned int);
//指向func函数的指针
void (*ptr)(unsigned int) = func; // 正确
void (*ptr)(int) = func; // 错误,没有一个重载的func与该形参列表匹配
double (*ptr)(unsigned int) = func; // 错误,没有一个重载的func与该返回类型匹配
6.7.4 函数指针作形参
-
和数组类型(6.2.3节),形参可以是指向函数的指针。
//形参看起来是函数类型,实际上确实当成指针使用 void useBigger(const string &s1, const string &s2, bool pf(const string &, const string &)); //等价 void useBigger(const string &s1, const string &s2, bool (*pf)(const string &, const string &)); -
可以直接把函数作为实参使用,他会被自动转换为指针
useBigger(s1,s2,lengthCompare); // 函数名即指向函数的指针 -
如上,直接使用函数指针类型显得冗长,使用类型别名和decltype简化
/*函数类型*/ typedef bool Func(const string &, const string &); //等价 using Func = bool(const string &, const string &); //等价 typedef decltype(lengthCompare) Func; /*指向函数的指针*/ typedef bool (*FuncPtr)(const string &, const string &); //等价 using FuncPtr = bool(*)(const string &, const string &); //等价 typedef decltype(lengthCompare) *FuncPtr; /*用简化的函数类型声明useBigger*/ void useBigger(const string &s1, const string &s2, Func); // 编译器自动地将Func表示的函数类型转换成指针 //等价 void useBigger(const string &s1, const string &s2, FuncPtr);
6.7.5 返回指向函数的指针
-
与形参不同,编译器不会自动地将函数返回类型当成对应的指针类型处理,因此我们必须显式地将返回类型指定为指针
//四个等价 FuncPtr useBigger(const string &s1, const string &s2, FuncPtr); Func *useBigger(const string &s1, const string &s2, FuncPtr); auto useBigger(const string &s1, const string &s2, FuncPtr) -> bool(*)(const string &, const string &);//尾置返回类型 bool (* useBigger(const string &s1, const string &s2, FuncPtr) ) (const string &, const string &); /*解释:先看括号里的,useBigger有形参列表,是一个函数;其前面有*,是一个指针;指向一个bool(const string &, const string &)的函数类型*/ -
将auto和decltype用于函数指针类型
- 牢记将decltype作用于某个函数,它返回函数类型而非指针类型
string::size_type sumlength(const string&, const string &); string::size_type largerlength(const string &, const string &); decltype(sumlength) *getFunc(const string &);
- 牢记将decltype作用于某个函数,它返回函数类型而非指针类型
七 类
7.1 定义抽象数据类型
7.1.1 关于类的基础知识
(P228~P235)主要讲述了“类”的基础知识。
一、
首先说明了类是什么:
- 类的基本思想是数据抽象 (data abstraction)和封装(encapsulation)。数据抽象是一种依赖于接口(interface)和**实现 **(implementation)分离的编程(以及设计)技术。
- 类的接口包括用户所能执行的操作;类的实现则包括类的数据成员、负责接口实现的函数体以及定义类所需的各种私有函数。
- 封装实现了类的接口和实现的分离。封装后的类隐藏了它的实现细节,也就是说,类的用户只能使用接口而无法访问实现部分。
二、
通过设计Sales_data类,讲述了数据成员及成员函数。并提出了如下建议:
在一些简单的应用程序中,类的用户和类的设计者常常是同一个人。尽管如此,还是最好把角色区分开来。当我们设计类的接口时,应该考虑如何才能使得类易于使用;而当我们使用类时,不应该顾及类的实现机理。
三、
接着通过成员函数引入this指针,该指针是类的成员函数额外的隐式参数,指向调用它的那个对象。有如下代码,
//Sale_data定义于P230中间
Sales_data total;
total.isbn(); // total调用了成员函数isbn()
实际上,编译器将该调用重写成如下形式
Sales_data::isbn(&total);
- 任何对类成员的直接访问都被看做this的隐式引用;
- 任何自定义名为this的参数或变量的行为都是非法的;
this是一个常量指针,不允许修改this中保存的地址。
成员函数在紧随参数列表之后,可以有const,用以修改隐式this指针的类型。示例如下:
string isbn() const {return bookNo; }
-
默认的情况下,this是指向非常量版本的常量指针,所以不能把this绑定到常量对象上,这使得我们不能在一个常量对象上调用普通的成员函数。C++允许在成员函数紧随参数列表后,添加const关键字,使得this变成一个指向常量的常量指针。如此,该成员函数被称为常量成员函数,常量成员函数不能改变调用它的对象的内容。
-
常量对象,及常量对象的引用或指针都只能调用常量成员函数。
四、
关于成员变量声明于成员函数之后,成员函数却能读取到成员变量,书中作出如下解释:
编译器分两步处理类:
- 首先编译成员的声明
- 然后才轮到成员函数体(如果有的话)。
因此,成员函数可以随意使用类中的其他成员而无须在意这些成员出现的次序。
五、
之后,
-
P232提及如何在类外部定义成员函数;
-
P233介绍了如何定义一个返回this对象的函数,通过
*this以获得执行该函数的对象。 -
P234在“定义类相关的非成员函数”一节中,提到了如下几个关键点:
-
一些辅助函数,尽管定义的操作从概念上来说属于类的接口的组成部分,但它们实际上并不属于类本身。这些函数也应与类声明(而非定义)在同一个头文件内。这样,用户使用接口的任何部分都只需要引入一个文件。
-
istream、ostream等io类属于不能被拷贝的类型,因此,我们只能通过引用来传递它们。又因为读写操作会改变流的内容,所以两个函数接受的都是普通引用,而非对常量的引用。istream &read(istream &is, Sales_data &item){ ...; is>>a>>b>>c; return is; } ostream &write(ostream &os, Sales_data &item){ ...; os<<item.isbn(); //注意没有endl()等控制格式 return os; } -
执行输出任务的函数应该尽量减少对格式的控制,将格式控制交给用户
-
默认情况下,拷贝类的对象其实拷贝的是对象的数据成员(没有拷贝成员函数,不同的类对象共用成员函数,并用this控制(侯捷高级面向对象课程))
-
7.1.2 构造函数
一、构造函数不能被声明成const。
当我们创建类的一个const对象时,直到构造函数完成初始化过程,对象才真正取得“常量”属性-->因此,构造函数在const对象的构造过程中可以向其写值
二、(编译器)合成的默认构造函数将按如下规则初始化类的数据成员:
- 如果存在类内初始值。则用它来初始化成员
- 否则,默认初始化
(P262 默认构造函数的作用)
-
类必须包含一个默认构造函数以便在下述情况下使用。
-
在实际中,如果定义了其他构造函数,那么最好也提供一个默认构造函数。
-
当对象被默认初始化或值初始化时自动执行默认构造函数。默认初始化在以下情况下发生:
- 当我们在块作用域内不使用任何初始值定义一个非静态变量(参见2.2.1节,第39页)或者数组时(参见3.5.1节,第101页)。
- 当一个类本身含有类类型的成员且使用合成的默认构造函数时(参见7.1.4 节,第235页)。
- 当类类型的成员没有在构造函数初始值列表中显式地初始化时(参见7.1.4 节,第237页)。
-
值初始化在以下情况下发生:
- 在数组初始化的过程中如果我们提供的初始值数量少于数组的大小时 (参见3.5.1节,第 101页)。
- 当我们不使用初始值定义一个局部静态变量时(参见6.1.1节,第185页)。
- 当我们通过书写形如 T()的表达式显式地请求值初始化时,其中T是类型名(vector 的一个构造函数只接受一个实参用于说明 vector 大小(参见3.3.1节第88页),它就是使用一个这种形式的实参来对它的元素初始化器进行值初始化).
三、某些类不能依赖于默认构造函数:
- 类内已经显式声明了构造函数
- 类中包含内置类型(int等)或复合类型(如数组、指针),如执行默认构造,则他们的值将是未定义的。只有当这些值被赋予了初始值(7.3.4),才可使用默认构造
- 类中包含一个其他类型的成员,其这个成员的类型没有默认构造,则编译器也无法对当前类执行默认构造
四、构造函数的几种方式
-
=default在c++11新标准中,可以在参数列表后面写
=default来要求编译器生成默认构造函数。注意要为内置类型或复合类型数据成员提供初始值。Sales_data() = default; -
构造函数列表初始化
当某个数据成员被构造函数初始值化列表忽略时,它将以与合成的默认构造函数相同的方式隐式初始化(此时要求有类内初始值),Sales_data(const string &s,double p) : bookNo(s),revenue(p) {} -
在类外部定义构造函数
五、拷贝、赋值和析构
尽管编译器能替我们合成拷贝、赋值和销毁的操作,但是必须要清楚的一点是,对于某些类来说合成的版本无法正常工作。特别是,当类需要分配类对象之外的资源时,合成的版本常常会失效。管理动态内存的类通常不能依赖于上述操作的合成版本。
7.1.3 构造函数再探
本节应是 书本P257页开始7.5 的内容,为了笔记结构的简洁,放到 笔记7.1.2构造函数 之后。
一、关于列表初始
-
使用列表初始化和在构造函数体内通过拷贝赋值的方式初始化,看似一样,但有时必须使用列表初始化且必不可少:如果成员是const、引用,或者属于某种未提供默认构造函数的类类型,我们必须通过列表初始化为这些成员变量提供初始值。
class ConstRef{ public: /*正确*/ ConstRef(int ii):i(ii),ci(ii),ri(i){} /*引发错误*/ ConstRef(int ii){ i = ii; ci = ii; //错误,不能给const赋值 ri = i; //错误,引用未被初始化 } private: int i; const int ci; int &ri; }; -
列表初始化的初始化顺序问题 -- 成员列表初始化的顺序与它们在类定义中的出现顺序一致:
构造函数初始值列表只说明用于初始化成员的值,而不限定初始化的具体执行顺序。成员列表初始化的顺序与它们在类定义中的出现顺序一致:第一个成员先被初始化,然后第二个,以此类推。构造函数初始值列表中初始值的前后位置关系不会影响实际的初始化顺序。一般来说,初始化的顺序没什么特别要求。不过一个成员用另一个成员来初始化,那么这两个成员的初始化顺序就很关键了。最好令构造函数初始值的顺序与成员声明的顺序保存一致,如果可能的话,尽量避免使用某些成员初始化其他成员。
/*例1*/ class ConstRef { public: /*正确*/ ConstRef(int ii) :j(ii),i(j) { cout <<"i = "<< i << ", j = " << j << endl; // 终端输出:i = -858993460, j = 1 // 出错,因为根据声明的顺序,先初始化i,而此时j还是未定义状态 } private: int i; int j; }; /*例2*/ class ConstRef { public: /*正确*/ ConstRef(int ii) :j(ii),i(j) { cout <<"i = "<< i << ", j = " << j << endl; // 终端输出:i = 1, j = 1 } private: // 声明顺序与列表初始化顺序匹配 int j; int i; }; -
如果为一个构造函数的所有参数都提供了默认实参,则其实际上也成为了默认构造函数。
二、委托构造
- 概念:一个委托构造函数 使用它所属类的其他构造函数 执行自身初始化过程。(将自身的(一些或全部)职责委托给了其他构造函数)
- 当一个构造函数委托给另一个构造函数时,受委托的构造函数的列表初始化和函数体被依次执行,然后才轮到委托者的函数体。
- 示例
class Sales_data {
public:
using unint = unsigned int;
//非委托构造使用对应的实参初始化成员
Sales_data(string s, unint cnt, double price)
:bookNo(s), sold(cnt), rev(cnt* price) {}
// 委托构造
Sales_data() :Sales_data("", 0, 0) {}
Sales_data(string s) :Sales_data(s, 0, 0) {}
Sales_data(istream& is) :Sales_data() { read(is, *this); }
void read(istream& is, Sales_data) {/*...*/ }
private:
string bookNo;
unint sold;
double rev;
};
三、隐式类型转换
-
如果一个类的构造函数只接受一个参数,则有从 该参数类型 到 该类类型 的隐式转换
#include <cassert> #include <string> #include <iostream> using namespace std; class Sales_data { public: using uint = unsigned int; Sales_data() = default; Sales_data(string s, uint cnt, double p) :m_isbn(s), m_cnt(cnt), m_price(p) {} Sales_data(string s) :m_isbn(s) { } // 1.string 可隐式转换为 Sales_data Sales_data& combine(Sales_data sd) { // 3. <-- string转换为Sales_data后带入 if (sd.m_isbn != this->m_isbn) cerr << "isbn is not same." << endl; this->m_cnt += sd.m_cnt; return *this; } private: string m_isbn = ""; uint m_cnt = 0; double m_price = 0; }; int main() { Sales_data item("978-7-121-15535-2"); // 直接初始化 //也可拷贝初始化 //Sales_data item = string("978-7-121-15535-2"); string isbn = "978-7-121-15535-2"; item.combine(isbn); // 2.正确,string 隐式转换为 Sales_data类型 return 0; } -
但是,这种类型转换只允许一步完成,下面这种分开是不允许的:
int main() { Sales_data item("978-7-121-15535-2", 2, 3); /*错误*/ item.combine("978-7-121-15535-2"); //编译器先向字符串常量转化为string;再将该string临时变量转换成Sales_data //两步转换导致隐式转换失败 //编译器报错: 不存在从 "const char [18]" 转换到 "Sales_data" 的适当构造函数 /*正确*/ item.combine(string("978-7-121-15535-2")); //或 item.combine(Sales_data("978-7-121-15535-2")); return 0; } -
利用
explicit关键字抑制单参数构造函数的隐式类型转换-
关键字
explicit只对一个实参的构造函数有效。需要多个实参的构造函数不能用于执行隐式转换,所以无须将这些构造函数指定为explicit的。 -
只能在类内声明构造函数时使用explicit 关键字,在类外部定义时不应重复
-
使用了
explicit关键字的构造函数只能以直接初始化的形式使用,不再支持拷贝形式的初始化class Sales_data{ public: explicit Sales_data(string s) :m_isbn(s) { } // 禁止隐式转换 }; string isbn = "978-7-121-15535-2"; Sales_data item1(isbn); // 正确 Sales_data item2 = isbn; // 错误 item1.combine(isbn); // 错误,隐式转化为explicit禁止了 -
可是我们非要类型转换怎么办?可以显式类型转换
item1.combine(Sales_data(isbn)); // 错误,隐式转化为explicit禁止了 //或 item1.combine(static_cast<Sales_data>(isbn));
-
-
标准库中含有显式构造(explicit)的类
- 接受一个单参数的const char*的string构造函数(参见3.21节,第76页)不是explicit的。
- 接受一个容量参数的 vector 构造函数(参见3.3.1节,第87页)是explicit 的。
7.2 控制访问和封装
7.2.1 访问说明符
- public
- private
- protected
7.2.2 class与struct
- class默认private
- struct默认public
7.3.3 友元
一、友元函数
- 当类的数据成员被设为private,非成员函数(所谓辅助函数)就无法访问到它们了。为解决这个问题,可将这些非成员函数设为友元
friend; - 友元生命只能定义在类的内部,但是在类内出现的具体位置不限。友元不是类的成员,也不受它所在区域访问控制级别的约束。不过,一般来说,最好在类开始或结束的位置集中声明友元。
- 友元的声明仅仅指定了访问权限,而非通常意义上的函数声明,所以必须在友元声明之外再专门对函数进行一次声明。
class Sales data{
//为Salesdata的非成员函数所做的友元声明
friend Sales_data add(const Sales_data&,const Sales_data&);
//其他成员及访问说明符与之前一致
public:
Sales_data() = default;
......
private:
std::string bookNo;
......
}
//Salesdata接口的非成员组成部分的声明
Sales_data add(const Sales data&,const Sales datas); //类的非成员函数声明
二、友元类
书本P250~P252对友元进行了补充,介绍了类与类之间的友元关系。
1.类作友元
-
友元类的成员函数可以访问此类的所有成员
class Screen{ friend class Window_mgr; // Window_mgr的成员函数可以访问Screen的所有成员 }; -
友元关系不具有传递性。Window_mgr的友元与Screen没有关系。
2.类的成员函数作友元
-
当把一个成员函数声明成友元时,我们必须明确指出该成员函数属于哪个类
class Screen{ friend void Window_mgr::clear(ScreenIdx); // Window_mgr的成员函数可以访问Screen的所有成员 }; -
想要某个成员函数作为友元,必须仔细组织程序结构,以满足声明和定义的彼此依赖关系:

-
尽管重载函数名字相同,但它们是不同的函数,友元声明要分别声明。
3.友元声明和作用域
- 要理解:友元声明的作用是设定访问权限,其本身并不是普通意义上的声明。(必须在别处书写真正的声明。)
void f(); // 声明 struct X{ friend void f() { cout << "hello" << endl; } // 即使在此处定义,也要在类的外部提供声明 X() { f(); } }; // void f(); //在此处定义,本例类的构造函数会报“f找不到标识符”
7.3 类的其他特性
7.3.1 在类中定义类型成员
- 类还可以自定义某种类型在类中的别名,该别名同样存在访问权限。
- 与不同成员不用关注定义的顺序不同,定义类型的成员必须先定义后使用。因此类型成员通常出现在类开始的地方;
class Screen{
public:
/* 在类中定义类型成员 */
typedef string::size_type pos;
//等价
//using pos = string::size_type;
private:
pos cursor = 0;
pos height = 0, width = 0; // 默认初始值
}
/* 如何在类外使用?*/
Screen::pos myPos;
7.3.2 令成员做inline函数
-
最好在类外部定义的地方说明inline,以使类更容易理解
class Screen{ public: Screen &move(pos r, pos c); } inline Screen &Screen::move(pos r, pos c){ } -
inline成员函数也应与相应的类定义在同一个头文件中
7.3.3 可变数据成员 -- mutable
- 可以通过向类的某个变量声明中加入
mutable关键字,达到即使是在一个const成员函数内也能修改该成员变量的目的。 - 可变数据成员永远不会是const,任何时候都能被修改
class Screen{
public:
void some_member() const { ++access_ctr; } //access_ctr用于记录成员函数被调用了多少次
private:
mutable size_t access_ctr;
}
7.3.4 类数据成员的初始值
- 希望自己设计的类一开始就被一个默认初始化,最好的方式就是将默认值声明成类内初始值
- 当我们提供一个类内初始值时,必须以等号或者花括号表示
class Window_mgr{
private:
vector<Screen> screens{Screen(24,80,' ')};
}
7.3.5 ⭐成员函数利用引用返回*this
一、可将一系列操作连接成一条表达式
typedef string::size_type pos;
inline Screen &Screen::move(pos r, pos c){ // <-- 返回*this的引用
...;
return *this;
}
inline Screen &Screen::set(char ch){
...;
return *this;
}
上述代码中,返回引用的函数是左值的,意味着上述函数返回的是对象本身而非副本。将this对象作为左值返回,可以把一系列操作连接成一条表达式:
Screen myScreen;
myScreen.move(4,0).set('#'); // 一系列操作连接成一条表达式
//等价
myScreen.move(4,0);
myScreen.set('#');
反之,如果返回的非引用(Screen &)而是值传递(Screen),则调用set()只是改变副本,而不能改变myScreen的值,连续调用将会失败。
Scream tmp = myScreen.move(4,0);
tmp.set('#');
对比实验如下
#include <cassert>
#include <string>
#include <iostream>
using namespace std;
class Screen {
public:
typedef string::size_type pos;
Screen() = default;
// 返回值为引用的版本 <-- 正确的版本
Screen& move(pos r, pos c);
Screen& set(char ch);
// 重载返回值非引用的版本,noRefer是用于重载的参数,无实际意义
Screen move(pos r, pos c, string noRefer);
Screen set(char ch, string noRefer);
void print() { cout << m_r << ", " << m_c << ", " << m_ch << endl; }
private:
pos m_r = 0, m_c = 0;
char m_ch = ' ';
};
// 返回值为引用的版本
inline Screen& Screen::move(pos r, pos c) {
m_r = r;
m_c = c;
return *this;
}
inline Screen& Screen::set(char ch) {
m_ch = ch;
return *this;
}
// 重载返回值非引用的版本,noRefer是用于重载的参数,无实际意义
inline Screen Screen::move(pos r, pos c, string noRef) {
m_r = r;
m_c = c;
return *this;
}
inline Screen Screen::set(char ch, string noRef) {
m_ch = ch;
return *this;
}
//main
int main() {
Screen myScreen1,myScreen2;
myScreen1.print(); //0,0,
myScreen1.move(4, 0).set('#');
myScreen1.print(); //4,0,#
myScreen2.move(4, 0, "noRef").set('#', "noRef"); // set失败,作用于了myScreen的副本
myScreen2.print(); //4,0,
return 0;
}
二、const成员函数的重载和*this指针的返回
- 重载多个const成员函数如何选择?下图1
- 从const成员函数返回*this:一个const成员函数如果以引用形式返回this,返回类型将是常量引用,下图2。
- this指针的隐式传递,下图3

7.3.6 类类型
-
只声明而未定义的类被称作前向声明;
-
在类定义之后,声明之前被称为不完全类型;
-
不完全类型用于有限的场景:
-
可以定义指向这种类型的指针或引用
-
可以声明(但不可定义)以不完全类型作为参数或者返回类型的函数
-
-
我们创建类的对象之前,该类必须被定义过
-
一种例外情况:(此处没有读懂,但是知道该用法)

7.4 类的其他形式
7.4.1 聚合类
-
用户可以直接访问其成员,且具有特殊初始化语法
-
满足如下条件:
- 所有成员都是 public的。
- 没有定义任何构造函数。
- 没有类内初始值
- 没有基类,也没有 virtual函数
-
示例
struct data{ int ival; string s; }; -
初始化 -- 顺序必须与生命顺序一致
data val{0,"anna"};
7.4.2 constexpr类
- 对于聚合类,如果数据成员都是字面值类型,则为字面值常量类
- 对于普通的类,满足:
- 数据成员都必须是字面值类型
- 类必须至少含有一个 constexpr 构造函数。
- 如果一个数据成员含有类内初始值,则内置类型成员的初始值必须是一条常量表达式(笔记2.5.4);或者如果成员属于某种类类型,则初始值必须使用成员自己的constexpr构造函数。
- 类必须使用析构函数的默认定义,该成员负责销毁类的对象(书7.1.5节,第239页)。
关于constexpr构造函数
- 尽管构造函数不能是 const 的,但是字面值常量类的构造函数可以是 constexpr函数。
- 事实上,一个字面值常量类必须至少提供一个constexpr 构造函数。
- constexpr构造函数的形式:
- 法一:
=default - 法二:既符合构造函数的要求(无返回语句),又符合constexpr函数的要求。 <-- constexpr构造函数体一般是空的。
- 法一:
- constexpr构造函数必须初始化所有数据成员。初始值 或者使用constexpr 构造函数 ,或者是一条常量表达式。
- constexpr 构造函数用于生成constexpr 对象以及 constexpr 函数的参数或返回类型。
#include <cassert>
#include <string>
#include <iostream>
using namespace std;
class Debug {
public:
constexpr Debug(bool b = true) : hw(b),io(b),other(b) {}
constexpr Debug(bool h,bool i, bool o) : hw(h),io(i),other(o) {}
/*constexpr */bool any() const { return hw || io || other; }
//在vs2022上须指定为const成员函数,否则:
//“bool Debug::any(void)”: 不能将“this”指针从“const Debug”转换为“Debug &”
void set_io(bool b) { io = b; }
void set_hw(bool b) { hw = b; }
void set_other(bool b) { hw = b; }
private:
bool hw;
bool io;
bool other;
};
int main() {
/*调用*/
constexpr Debug io_sub(false, true, false);
if (io_sub.any()) // if(true)
cerr << "print appropriate error messages" << endl;
constexpr Debug prod(false);
if (prod.any()) // if(false)
cerr << "print anerror message" << endl;
return 0;
}
7.5 类的作用域
7.5.1 类名::的作用范围
本节从书本P253开始,首先简述了如何通过类访问其中的成员变量、成员函数和typedef的类型别名。
接着,讲述了类名::的作用范围,即其后的所有东西,包括函数名、参数列表和函数体。而其之前的返回值类型不包含在其中,如果返回值类名在此类中定义,也要用类名::额外声明
class Screen{
public:
/* 在类中定义类型成员 */
typedef string::size_type pos;
//等价
//using pos = string::size_type;
pos clear(int i);
private:
pos cursor = 0;
pos height = 0, width = 0; // 默认初始值
}
/*调用*/
// Screen::clear中的 `Screen::`不作用于pos,pos需要额外声明其所属类
Screen::pos Screen::clear(int i){}
7.5.2 名字查找
-
类成员声明的名字查找,考虑下述代码
typedef double Money; string bal; class Account{ public: Money balance() {return bal;} //1. private: //typedef double Money; //2.错误,Money不可重复定义 Money bal; };-
编译器处理完类中的全部声明后,才会处理成员函数的定义。
-
在注释1处,编译器没有找到 在Account中 使用Money前 出现的声明,接着到Account外层作用域寻找,找到了Money。
-
另一方面,成员函数
balance()的函数体在整个类全部可见(声明)后才被处理(函数定义),因此返回成员变量bal,而非外层的string的bal。 -
在注释2处,
一般来说,内层作用域可以重新定义外层作用域中的名字,即使该名字已经在内层作用域中使用过。然而在类中,如果成员使用了外层作用域中的某个名字,而该名字代表一种类型,则类不能在之后重新定义该名字。
建议将类型名的定义放在类开始处,这样保证所有使用该类的成员都出现在类名定义之后。
-
-
成员函数中使用的名字的查找方式:

-
成员变量名和成员函数参数名重名,降低了代码的阅读性。
建议不要将成员名字作为参数或其他局部变量使用,如下述代码例3所示。
int height; class Screen{ public: typedef string::size_type pos; /*********** 例1 *************/ void func(pos height){ cursor = width * height; // height是参数声明 } /*****************************/ private: pos cursor = 0; pos height = 0,width = 0; }; /*将例1替换成例2*/ /*********** 例2 *************/ void func(pos height){ cursor = width * this->height; //类成员height //等价 cursor = width * Screen::height; //类成员height } /*****************************/ /*将例1替换成例3*/ /*********** 例3 建议的写法*************/ void func(pos ht){ cursor = width * height; // 类成员height } /*****************************/ /*将例1替换成例4*/ /*********** 例4 *************/ void func(pos height){ cursor = width * ::height; // 全局的那个int height; } /*****************************/
-
-
在文件中名字的出现处进行解析
int height; class Screen{ public: typedef string::size_type pos; void func(pos); private: pos cursor = 0; pos height = 0,width = 0; }; Screen::pos verify(Screen::pos); void func(pos var){ height = verify(var); }虽然函数
verify()在类Screen定义之后,但出现在了成员函数func()定义之前的全局作用域,所以可被正常使用。(参见:成员函数中使用的名字的查找方式第3点:如果类内也没找到该名字的声明,在成员函数定义之前的作用域内继续查找。)
7.6 类的静态成员
7.6.1 基础
- 在成员声明前加上
static关键字声明静态成员。静态成员直接与类关联,而不是与类的对象关联。 - 静态成员存在于任何对象之外,对象中不包含任何与静态数据成员有关的数据。只会存在一个静态数据,被所有对象共享。
- 静态成员函数不与任何对象绑定,不包含this指针,不能声明为const成员函数。
7.6.2 定义静态成员
- 因为静态成员不属于类的任何一个对象,因此不能用类的构造函数初始化。
- 一般来说,不能再类内初始化静态成员,必须在类外部定义和初始化每个静态成员。除了笔记7.6.3的情况。
- 一旦定义,将存在于整个程序的生命周期。
class Account
{
public:
Account();
~Account() = default;
private:
static int i; /*= 0;//错误,带有类内初始值设定项的成员必须为常量*/
};
int Account::i = 0; // 类外定义和初始化
7.6.3 静态成员的类内初始化
笔记7.6.2说:“不能再类内初始化静态成员,必须在类外部定义和初始化每个静态成员。”但是,有一种例外。
我们可以为静态成员提供const 整数类型的类内初始值,不过要求静态成员必须是字面值常量类型的constexpr(参见 7.5.6 节,第267 页)。初始值必须是常量表达式,因为这些成员本身就是常量表达式,所以它们能用在所有适合于常量表达式的地方。例如,我们可以用一个初始化了的静态数据成员指定数组成员的维度:
class Account{
private:
static constexpr int period = 30;
double daily_tbl[period];
};
// 不带初始值的定义
constexpr int Account::period;
书中提到了两种情况,说明static constexpr是否需要重复定义:
- 仅用静态常量表达式替换它的值,如定义数组维度,则不用重复定义(也可以多此一举地定义)
- 当需要将其传递为一个接收该类型的函数时,则需要重复定义。
为省去麻烦,干脆不论上述何种情况,都在类外重新不带初始值地定义一下该成员。如上述代码最后一行所示。
7.6.4 能使用静态成员,而不能使用普通成员变量的场景
一、静态数据成员可以是不完全类型
有关不完全类型见书P250--类的声明和笔记7.3.6 类类型
- 特别的,静态数据成员的类型可以就是它所属的类型,而非静态成员变量只能声明它所属的类的指针或引用
class Bar{
private:
static Bar mem1; //正确,静态成员可以是不完全类型
Bar *men2; //正确,指针成员可以是不完全类型
Bar mem3; // 错误,数据成员必须是完整类型
};
二、可以使用静态成员作默认实参,而普通成员不行
class Screen {
public:
//静态成员作默认实参
Screen& clear(char = bg) ;
private:
static char bg;
};
char Screen::bg = 'a'; // 类外定义static数据成员
Screen& Screen::clear(char s) {
cout << s << endl;
return *this;
}
int main() {
Screen a;
a.clear(); // 使用默认实参bg,终端输出 a
return 0;
}
------标准库------
八 标准库的IO操作
8.1 IO类
8.1.1 IO库类型和头文件
- 标准库给出的IO类型如下图所示;其中,以“w”开头的版本是为了支持宽字符语言,标准库定义了一组类型和对象来操纵
wchar_t类型的数据。

8.1.2 IO对象无拷贝或赋值
- IO对象不能拷贝或者赋值
- 不能拷贝io对象,因此我们不能将形参或返回值类型设置为流类型,而常以引用方式传递
- 读写一个io对象会改变其状态,因此传递和返回的引用不能是
const
ofstream out1,out2;
out1 = out2; //错误,不能对流对象赋值
ofstream print(ofstream); //错误,不能初始化ofstream参数
out1 = print(out2); //错误,不能拷贝流对象(不能将形参设置为流对象)
8.1.3 IO状态
- 条件状态表

-
判断一个流是否处于良好状态的最简单的方法
while(cin>>word){ //读取成功的操作 } -
IO 库定义了一个与机器无关的
iostate类型,该类型应作为一个位集合来使用。有4个iostate类型的constexpr值(badbit,failbit,eofbit,goodbit),表示特定的位模式,这些值可以与位运算符一起使用来一次性检测或设置多个标志位:badbit表示系统级错误,如不可恢复的读写错误。通常情况下,一旦badbit被置位,流就无法再使用了。failbit被置位于发生可恢复错误后,如期望读取数值却读取一个字符等错误。这种问题通常是可以修正的,流还可以继续使用。- 如果到达文件结束位置,
eofbit和failbit都会被置位。 goodbit的值为0,表示流未发生错误。如果badbit、failbit和eofbit任一个被置位,则检测流状态的条件会失败。
-
为检测流的状态,IO库提供了一组函数。其中,
good()和fail()是确定流的总体状态的方法。下面列出两种使用方法:-
状态管理:保存流的状态并恢复
auto old_state = cin.rdstate(); cin.clear(); proess_func(cin); cin.setstate(old_state); -
将failbit和badbit复位,但保持eofbit不变:
cin.clear(cin.rdstate() & ~cin.failbit & ~cin.badbit);过程如下图所示
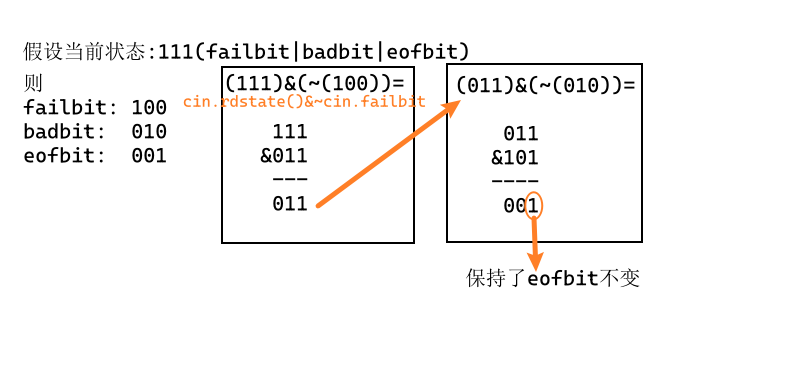
-
8.1.4 缓冲区
-
导致缓冲区刷新的原因
-
程序正常结束,作为main函数
return操作的一部分,缓冲刷新被执行。 -
缓冲区满时,需要刷新缓冲,而后新的数据才能继续写入缓冲区。
-
我们可以使用操纵符如
endl(参见1.2节,第6页)来显式刷新缓冲区。 -
在每个输出操作之后,我们可以用操纵符
unitbuf设置流的内部状态,来清空缓冲区。默认情况下,对cerr是设置unitbuf的,因此写到cerr的内容都是立即刷新的。 -
一个输出流可能被关联到另一个流。在这种情况下,当读写被关联的流时,关联到的流的缓冲区会被刷新。例如,默认情况下,
cin和cerr都关联到cout。因此,读cin或写cerr都会导致cout的缓冲区被刷新。
-
-
刷新缓冲区的几种方式
cout<<"hi"<<endl; //附加一个换行符,然后刷新缓冲区 cout<<"hi"<<flush; //不附加任何字符,刷新缓冲区 cout<<"hi"<<end; //附加一个空字符,然后刷新缓冲区 cout<<unitbuf; //任何输出都立即刷新,无缓冲 ......;// 一些操作 cout<<nounitbuf; // 回到正常的缓冲模式 -
书中提到的一个注意事项:
警告:如果程序崩溃,输出缓冲区不会被刷新
如果程序异常终止,输出缓冲区是不会被刷新的。当一个程序崩溃后,它所输出的数据很可能停留在输出缓冲区中等待打印。
当调试一个已经崩溃的程序时,需要确认那些你认为已经输出的数据确实已经刷新了。否则,可能将大量时间浪费在追踪代码为什么没有执行上,而实际上代码已经执行了,只是程序崩溃后缓冲区没有被刷新,输出数据被挂起没有打印而已。
程序员常常在调试添加打印语句。这类语句应该保证一直刷新流。否则,如果程序崩溃,输出可能还留在缓冲区中,从而导致关于程序崩溃位置的错误推断。
8.1.5 关联输入流和输出流
-
当一个输入流被关联到一个输出流时,任何试图从输入流读取数据的操作都会先刷新关联的输出流。标准库将cin和cout关联,因此
cin >>ival将会导致cout的缓冲区被刷新。 -
利用
iostream::tie()函数,既可以将一个istream对象关联到另一个ostream上,也可以将一个ostream关联到另一个ostream上cin.tie(&cout); // 标准库中,cin与cout关联 //old_tie指向旧的关联 ostream *old_tie = cin.tie(nullptr);//cin不再与任何流关联(即解除关联) cin.tie(&cerr); // 将cin与cerr关联,读取cin会导致cerr的刷新 cin.tie(old_tie); // 恢复之前的关联
8.2 iostream
书本第5页(略)
8.3 fstream(文件流)
8.3.1 fstream的特有操作
- fstream继承与iostream,除了可以使用iostream的操作外,还有其特有的操作,如下所示:

- 在要求使用基类类型对象的地方,我们可以用继承类型的对象来替代。因为fstream(和sstream)继承于iostream,所以接受iostream的引用(或指针)参数的函数,可以用对用的fstream(或sstream)类型来调用。
- 通过构造函数打开文件的,会自动调用
open()和close()(自动构造和析构)。通过open()打开文件,则必须在结束是手动书写close()。 - 对一个已经打开的文件流调用
open()会失败,并导致failbit被置位。必须先关闭(close())已经关联的文件,再打开新文件。
8.3.2 文件模式

-
默认模式
- ifstream:in模式
- ofstream:out模式
- fstream:in+out模式
-
一些注意事项
- 以
out模式打开文件会将文件清空,除非同时显式指定app或in。 - 只有当
out也被设定时才可设定trunc - 每次调用
open()都要(显式或隐式地)重新设置文件模式。 - 只可以对
ofstream或fstream设置out - 只可以对
ifstream或fstream设置in - 只要
trunc没被设定,就可以设定app模式。在app模式下,即使没有显式指定out模式,文件也总是以输出方式被打开。 ate和binary模式可用于任何类型的文件流对象,且可以与其他任何文件模式组合使用。
- 以
8.4 sstream(string流)
-
和fstream同样继承与ostream,既可以使用iostream的操作,也有其特有操作:

-
strm.str(s)会清空strm中原有的数据,示例:#include <string> #include <iostream> #include <sstream> #include <vector> using namespace std; int main() { ostringstream nums; vector<string> nums_vec{"123","456","789","101112"}; for ( auto num : nums_vec) { nums << num << " "; } cout << nums.str() << endl; //123 456 789 101112 nums.str(string("888")); // 清空了string流中原有的数据 cout << nums.str() << endl; //888 return 0; }
8.4.1 istringstream
- 何时使用?
- 当我们对整行文本进行处理,并同时需要处理行内的单个单词时。
- 示例
#include <string>
#include <iostream>
#include <sstream>
#include <vector>
using namespace std;
struct PersonInfo {
string name;
vector<string> phones;
};
int main() {
string line, phone;
vector<PersonInfo> people;
// 将文件中的所有数据存入people:vector<PersonInfo>中
while (getline(cin, line)) {
PersonInfo info;
istringstream record(line);
record >> info.name;
while (record >> phone)
{
info.phones.push_back(phone);
}
people.push_back(info);
}
// 逐人验证号码是否有效
for(const auto &entry : people)
{
ostringstream formated, badNums;
for (const auto &phone :entry.phones)
{
if (!valid(phone)) { // 省略判断电话是否有效的代码
badNums << phone << " ";
}
else{
formated << format(phone) << " "; //省略格式化电话号码的代码
}
}
if (badNums.str().empty())
cout << entry.name << " " << formated.str() << endl;
else
cerr << "input error: " << entry.name
<< " invalid numbers(s) "<< badNums.str() << endl;
}
return 0;
}
8.4.2 ostringstream
-
何时使用?我们想逐步构造输出的内容,希望放在最后一起打印。(此构造非构造函数的构造,不要过分解读))
-
接着8.4.1节的代码,示例如下:
// 逐人验证号码是否有效 for(const auto &entry : people) { ostringstream formated, badNums; for (const auto &phone :entry.phones) { if (!valid(phone)) { // 省略判断电话是否有效的代码 badNums << phone << " "; } else{ formated << format(phone) << " "; //省略格式化电话号码的代码 /*注意此处 ↑。 使用标准的输出运算符`<<`向这些对象写入数据, 但这些“写入”操作实际上转换为 `string`操作, 分别向` formatted`和`badNums`中的`string `对象添加字符。*/ } } if (badNums.str().empty()) cout << entry.name << " " << formated.str() << endl; else cerr << "input error: " << entry.name << " invalid numbers(s) "<< badNums.str() << endl;程序最有趣的部分是对字符串流
formatted和badNums的使用。我们使用标准的输出运算符<<向这些对象写入数据,但这些“写入”操作实际上转换为string操作,分别向formatted和badNums中的string对象添加字符。
8.4.3 本节完整的示例代码
/* 文件中的数据 */
//morgan 2015552368 8625550123
//drew 9735550130l
//ee 6095550132 2015550175 8005550000
#include <string>
#include <iostream>
#include <sstream>
#include <vector>
using namespace std;
struct PersonInfo {
string name;
vector<string> phones;
};
int main() {
string line, phone;
vector<PersonInfo> people;
// 将文件中的所有数据存入people:vector<PersonInfo>中
while (getline(cin, line)) {
PersonInfo info;
istringstream record(line);
record >> info.name;
while (record >> phone)
{
info.phones.push_back(phone);
}
people.push_back(info);
}
// 逐人验证号码是否有效
for(const auto &entry : people)
{
ostringstream formated, badNums;
for (const auto &phone :entry.phones)
{
if (!valid(phone)) { // 省略判断电话是否有效的代码
badNums << phone << " ";
}
else{
formated << format(phone) << " "; //省略格式化电话号码的代码
}
}
if (badNums.str().empty())
cout << entry.name << " " << formated.str() << endl;
else
cerr << "input error: " << entry.name
<< " invalid numbers(s) "<< badNums.str() << endl;
}
return 0;
}
九 顺序容器
9.1 概述

forward_list没有size操作,因为保存或计算其大小就会比手写链表多出额外的开销。对其他容器而言,size保证的是一个快速的常量时间的操作。
9.1.1 选用顺序容器的原则
- 首选
vector - 很多小元素,且空间开销重要 --> 不要使用
list或forward_list - 要求随机访问 -->
vector或deque - 中间插入和删除 -->
list或forward_list - 头尾插入和删除,但不在中间插入和删除 -->
deque - 如果程序只有在读取输入时才需要在容器中间位置插入元素,随后需要随机访问元素,则
- 首先,确定是否真的需要在容器中间位置添加元素。当处理输入数据时,通常可以很容易地向
vector追加数据,然后再调用标准库的sort函数,来重排容器中的元素,从而避免在中间位置添加元素。 - 如果必须在中间位置插入元素,考虑在输入阶段使用
list,一旦输入完成,将list中的内容拷贝到一个vector中。
- 首先,确定是否真的需要在容器中间位置添加元素。当处理输入数据时,通常可以很容易地向
- 如果程序既需要随机访问元素,又需要在容器中间位置插入元素,则取决于在
list或forward_list中访问元素与vector或deque中插入/删除元素的相对性能,一般来说,应用中占主导地位的操作(执行的访问操作更多还是插入/删除更多)决定了容器类型的选择。在此情况下,对两种容器分别测试应用的性能可能就是必要的了)。
如果你不确定应该使用哪种容器,那么可以在程序中只使用
vector和list公共的操作:迭代器,而不是使用下标,以避免随机访问。这样,在必要时选择使用vector或list都很方便。
9.2 容器库概览
对于容器类型的操作,有些适用于所有容器;有些仅针对顺序或关联或无序;有些适用于个别容器。
本节介绍适用于所用容器的操作。
本章剩余部分则聚焦顺序容器的操作。

虽然我们可以在容器中保存几乎任何类型,但某些容器操作对元素类型有其自己的特殊要求。我们可以为不支持特定操作需求的类型定义容器,但这种情况下就只能使用那些没有特殊要求的容器操作了。有如下示例。
顺序容器的 接受容器大小的 构造函数版本,要求其中元素的类型必须能够被默认初始化。
//NoDefault:a Type With No Default Constructor
vector<NoDefault> v1(10,init); // 正确,提供了元素初始化器
vector<NoDefault> v1(10); // 错误,需要元素初始化
9.2.1 迭代器
在书P296~P299,介绍了容器的迭代器。书中首先说,与容器一样,迭代器有着公共的接口,不同容器的迭代器都执行着类似的操作。 并特别指出,forward_list的迭代器不支持-- 。
接着介绍了迭代器的左闭右开区间:[ begin , end ),以及利用该特性对容器中元素进行访问的操作。特别提到需要保证在合法的范围内解引用begin。
然后提到了类型成员,特别提到了反向迭代器,与正向迭代器相比,各种操作的含义都发生了颠倒。比如,++会得到上一个元素;rbegin和rend会获得尾元素和首元素之前位置的迭代器。笔记10.4.3介绍
提到容器相关的类型别名在书16章介绍。
P298,书9.2.3节begin和end成员 中提到:
-
迭代器中(begin,cbegin,rbegin,crbegin,end,cend,rend,crend),不以
c开头的版本都是重载过的。 -
可以将一个普通版本的
iterator转化为对应的const_iterator,反之则不然。 -
当
auto与begin或end结合使用时,获得的选代器类型依赖于容器类型,与我们想要如何使用迭代器毫不相干。但以c开头的版本还是可以获得const_iterator的而不管容器的类型是什么。示例如下auto it7 = a.begin(); // 仅当a是const时,it7是const_iterator auto it8 = a.cbegin(); // it8是const_iterator当不需要写访问时,应使用
cbegin和cend。
笔记10.4 再探迭代器将对迭代器的内容进行拓展。
9.2.2 容器定义和初始化

一、拷贝初始化
将一个新容器创建为另一个容器的拷贝的方法有两种:
-
直接拷贝整个容器
-
要求两个容器的类型及其元素类型必须匹配
-
示例
list<string> authors = {"Milton","Shakespeare","Austen"}; // 列表初始化 list<string> list2(authors); //等价 list<string> list2 = authors; vector<string> list3(authors); //错误,容器的类型不匹配 list<char *> list4(authors); //错误,元素的类型不匹配
-
-
拷贝由 迭代器对 指定的元素范围
-
不要求容器的类型相同,也不要求元素的类型相同。只要能将要拷贝的元素转换为要初始化的容器的元素类型即可。
list<const char *> authors = {"Milton","Shakespeare","Austen"}; forward_list<string> words(authors.begin(), authors.end()); -
array不适用
-
二、列表初始化
略
三、顺序容器独有:指定容器大小来初始化
-
只有顺序容器的构造函数才接受大小参数,关联容器并不支持。
-
如果元素类型是内置类型或者是具有默认构造函数的类类型,可以只为构造函数提供一个容器大小参数。如果元素类型没有默认构造函数,除了大小参数外,还必须指定一个显式的元素初始值。举个例子,创建一个Test类,并将其默认构造函数删除,编译器报错如下。
class Test { public: Test() = delete; /*删除了默认构造函数,成员变量a无法执行默认初始化。 * 当创建10个Test类型的vector的时候,找不到默认构造函数,编译器报错如下: * 错误 C2280 “Test::Test(void)”: 尝试引用已删除的函数 */ private: int a; }; int main() { vector<Test> t(10); return 0; } -
不指定大小的容器中,元素可以没有构造函数。如上面提到的拷贝初始化、列表初始化等。
四、array的固定大小
-
大小也是类型的一部分,必须同时指定元素类型和大小。
-
和其他容器不同,默认构造的array是非空的。其包含了指定数量的被默认初始化后的元素(因此元素类型一定要有默认初始化)。
-
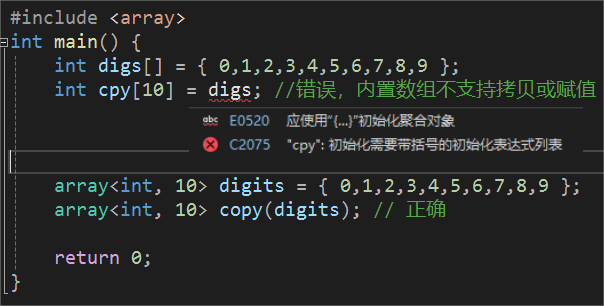
值得注意的是,虽然不能对内置数组类型进行拷贝或者对象赋值,但array没有该限制。
array<>在拷贝赋值的时候,注意元素类型和数量要一样。内置数组拷贝赋值和array容器拷贝赋值对比如下:
9.2.3 赋值和swap

-
上表中列出的,与赋值有关的运算符可用于所有容器:
c1=c2; c1={a,b}; -
由于右边运算对象的大小可能与左边运算对象的大小不同,因此array类型不支持assign,也不允许用花括号值列表进行赋值。
array<int,10> a1 = {0,1,2,3,4,5,6,7,8,9}; array<int,10> a2 = {0}; // 10个0 a2 = a1; //正确 a2 = {0}; //错误,不能用花括号值列表给array赋值 -
assign()-
仅顺序容器
-
允许我们从一个不同但相容的类型赋值,或者从容器的一个子序列赋值。
#include <iostream> #include <list> #include <vector> using namespace std; int main() { list<string> names; vector<const char*> old_style; names = old_style; // 错误,容器类型不匹配 names.assign(old_style.begin(), old_style.end()); // 自动进行了类型转换 return 0; } -
由于其旧元素被替代,因此传递给assign的迭代器不能指向调用assign的容器。以下是ChatGPT给出的例子,人为制造一个错误。
#include <iostream> #include <list> using namespace std; int main() { std::list<int> originalList = {1, 2, 3, 4, 5}; // 试图在循环中使用迭代器来调用 assign for (auto it = originalList.begin(); it != originalList.end(); ++it) { // 尝试在循环中调用 assign,传递迭代器指向原始列表 originalList.assign(it, it); // 这里迭代器已经失效,因为 assign 改变了容器的大小 // 这可能导致未定义的行为或程序崩溃 std::cout << *it << std::endl; // 试图访问失效的迭代器 } return 0; }
-
-
swap()- 交换两个相同类型的容器内容。
- 除
array外,swap不对任何元素进行拷贝、删除或插入操作,只交换两个容器的内部数据结构,因此速度非常快。而对array则会真正交换它们的元素。 - 除
string外,指向容器的迭代器、引用和指针,在swap操作后都不会失效,仍指向swap操作前所指向的那些元素。但是这些元素已经属于不同的容器了。 - 统一使用非成员版本的
swap()是个好习惯。
9.2.4 容器大小
size():返回元素数目。forward_list不支持size()empty():容器是否为空max_size():返回一个大于或等于该类型容器所能容纳的最大元素数的值。
9.2.5 关系运算
- 每个容器类型都支持相等运算符(==和!=)
- 除无序关联容器外都支持关系运算符(> 、>=、 < 、<=)
- 比较的对象必须有相同的容器类型和相同的元素类型。
- 用于比较的元素类型必须重载了(定义了)关系运算符
- 比较规则类似string,如下:

9.3 顺序容器的特有操作
9.3.1 插入元素

一、push_back
-
除
array和forward_list外,每个顺序容器(包括string)都支持push_back。 -
push_back是将对象拷贝,
关键概念:容器元素是拷贝
当我们用一个对象来初始化容器时,或将一个对象插入到容器中时,实际上放入到容器中的是对象值的一个拷贝,而不是对象本身。就像我们将一个对象传递给非引用参数一样,容器中的元素与提供值的对象之间没有任何关联。随后对容器中元素的任何改变都不会影响到原始对象,反之亦然。
二、push_front
list、forward_list、deque还支持push_front
三、insert
-
vector、deque、list、string都支持insert。(注:forward_list为特殊版本,于forward_list专题介绍) -
每个insert都接受一个迭代器作为其第一参数,表示将某个(些)额外的元素添加到这个迭代器所指向的元素之前。 <--注意,是之前插入
-
虽然某些容器(如vector)不支持push_front 操作,但它们对于 insert 操作并无类似的限制(插入开始位置)。因此我们可以将元素插入到容器的开始位置,而不必担心容器是否支持push_front :
#include <iostream> using namespace std; #include <vector> #include <string> int main() { vector<string> vec_str = {"a","b","c"}; // vector不支持push_front,但是可以通过insert插入新的首元素,但是可能很耗时 vec_str.insert(vec_str.begin(), "hello"); for(const auto &word : vec_str) cout<<word<<" "; // hello a b c return 0; }
一、插入特定元素
c.insert(p,t); //对容器c,向p位置之前插入元素t
二、插入范围内元素
-
c.insert(p,n,t):对容器c,向p位置之前插入n个元素t -
c.insert(p,b,e):对容器c,向p位置之前插入一对迭代器,特别说明,这对迭代器不能指向 调用insert的容器对象(此处为c) 的元素 -
c.insert(p,il):对容器c,向p位置之前插入初始化列表il
本节的三种插入方式,返回指向第一个新加入元素的迭代器。如果插入为空,则将insert的第一个参数返回。
通过使用该返回值,可以在容器中一个特定的位置反复插入元素。示例如下:
#include <iostream>
using namespace std;
#include <string>
#include <list>
int main() {
list<string> lst;
string word;
auto iter = lst.begin();
while(cin>>word)
//等价于调用push_front
iter = lst.insert(iter,word);
return 0;
}
三、
emplace_front、emplace、emplace_back与push_front、insert、push_back对应。
push_xxx和insert,将元素类型的对象拷贝到容器中;
emplace_xxx则是将参数传递给元素类型的构造函数,以在容器管理的内存空间中直接构造元素。传递给emplace函数的参数必须元素类型的构造函数相匹配。
#include <iostream>
using namespace std;
#include <utility>
#include <vector>
class Sales_data{
friend ostream & operator<<(ostream& os, Sales_data sd);
public:
using uint = unsigned ;
Sales_data() = default;
Sales_data(string isbn, uint cnt, double price)
:m_isbn(isbn),m_cnt(cnt),m_price(price){}
private:
string m_isbn;
uint m_cnt = 0;
double m_price = 0;
};
ostream & operator<<(ostream& os, Sales_data sd){
os<<sd.m_isbn<<" "<<sd.m_cnt<<" "<<sd.m_price;
return os;
}
int main() {
vector<Sales_data> vec;
vec.emplace_back("123",25,15.99);//直接在容器的内存空间中创建对象
vec.push_back(Sales_data("456",15,36.2)); // 创建元素的临时对象,并将其拷贝到容器
for(const auto & sales_data : vec)
cout<<sales_data<<endl;
/* 终端输出:
123 25 15.99
456 15 36.2
*/
}
9.3.2 访问元素

at和下标运算符只使用于string、vector、deque、arrayback不适用forward_listback()、front()、at和下标运算符返回的都是引用。at相较于下标运算符较安全,越界抛出out_of_range的异常。
因为返回的是引用,可通过访问元素的函数修改容器内容:
#include <vector>
#include <iostream>
using namespace std;
int main(){
vector<int> vec{0,1,2,3,4,5,6,7,8,9};
vec.front() = 42;
auto &v1 = vec.back();
v1 = 1024;
//理解auto的规则(笔记2.6.2):
// auto以引用对象的类型作为auto的类型
auto v2 = vec.back(); //不是引用,是一个拷贝
v2 = 0; //未能改变vec中的元素
for(const auto & num : vec)
cout<<num<<" ";
cout<<endl;
return 0;
}
9.3.3 删除元素

-
pop_front()和pop_back()返回void,如果还需要弹出的元素值,要在弹出前保存。 -
erase(p)返回p的下一个元素的迭代器 -
erase(b,e)e指向要删除的最后一个元素的下一个位置,结束后b==evector<int> vec{0,1,2,3}; vec.clear(); //等价 vec.erase(vec.begin(),vec.end());
补充:forward_list没有pop_back(),如何删除尾元素?
在C++中,std::forward_list是单向链表,由于单向链表的特性,删除最后一个元素需要一些额外的考虑,因为它没有直接提供像pop_back这样的成员函数,而是需要从头开始遍历链表找到倒数第二个元素,然后将其next指针置为空。
/**
* forward_list删除尾元素
*/
#include <iostream>
#include <forward_list>
int main() {
std::forward_list<int> myList = {1, 2, 3, 4, 5};
// 如果列表为空,无需进行任何操作
if (!myList.empty()) {
auto current = myList.before_begin(); // 迭代器指向头之前的位置
auto last = myList.begin(); // 迭代器指向头
// 遍历找到倒数第二个元素
while (std::next(last) != myList.end()) {
++current;
++last;
}
// 删除最后一个元素
myList.erase_after(current);
}
// 输出删除后的列表
for (const auto& value : myList) {
std::cout << value << " ";
}
std::cout << std::endl;
return 0;
}
std::next是C++标准库中的一个函数模板,用于返回给定迭代器的下一个迭代器。该函数的定义位于头文件 <iterator> 中。下面是它的基本语法:
template< class InputIt >
InputIt next( InputIt it, typename std::iterator_traits<InputIt>::difference_type n = 1 );
it:要获取下一个迭代器的起始迭代器。n:要移动的步数,默认为1。
std::next在迭代器上执行递增操作,允许你在容器中向前移动指定数量的位置。这对于在算法中进行迭代器操作时非常有用。
以下是一个简单的示例,演示如何使用std::next:
#include <iostream>
#include <iterator>
#include <vector>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
auto it = numbers.begin();
// 使用 std::next 将迭代器向前移动两个位置
auto advancedIt = std::next(it, 2);
// 输出结果
std::cout << "Original iterator value: " << *it << std::endl;
std::cout << "Advanced iterator value: " << *advancedIt << std::endl;
return 0;
}
在这个示例中,std::next被用来将迭代器 it 向前移动两个位置,产生一个新的迭代器 advancedIt。这样,你可以在容器中灵活地移动迭代器,而不必手动进行逐步增加。
如果有其他问题或需要更详细的解释,请随时提出。
9.3.4 改变容器大小

-
如果当前大小大于所要求的大小,容器后部的元素会被删除:如果当前大小小于新大小,会将新元素添加到容器后部:
list<int> ilist(10,42); //10个int:每个的值都是42 ilist.resize(15); //将5个值为0的元素添加到 ilist 的末尾 ilist.resize(25,-1); //将10个值为-1的元素添加到 ilist的末尾 ilist.resize(5); //从ilist末尾删除20个元素 -
resize 操作接受一个可选的元素值参数,用来初始化添加到容器中的元素。如果调用者未提供此参数,新元素进行值初始化。
-
如果容器保存的是类类型元素,且 resize 向容器添加新元素,则我们必须提供初始值,或者元素类型必须提供一个默认构造函数。
9.3.5 容器操作可能使迭代器失效
一、添加元素

二、删除元素

三、因此,我们需要管理迭代器
当你使用迭代器(或指向容器元素的引用或指针)时,最小化要求迭代器必须保持有效的程序片段是一个好的方法。
由于向迭代器添加元素和从迭代器删除元素的代码可能会使迭代器失效,因此必须保证每次改变容器的操作之后都正确地重新定位迭代器。这个建议对 vector、string和 deque尤为重要。
有两个要求:
-
添加/删除vector、string 或deque 元素的循环程序必须考虑迭代器、引用和指针可能失效的问题:
每次循环都更新迭代器、引用或指针。
/** * 添加/删除vector、string 或deque 元素的循环程序必须考虑迭代器、引用和指针可能失效的问题。 * 程序必须保证每个循环步中都更新迭代器、引用或指针。 * 如果循环中调用的是insert()或erase(),那么更新迭代器很容易,因为这些操作都返回迭代器,我们可以用来更新: */ #include <vector> #include <iostream> using namespace std; int main(){ vector<int> vec{0,1,2,3,4,5,6,7,8,9}; auto it = vec.begin(); while(it!=vec.end()){ //注意等号左侧,每步循环都更新了迭代器 if(*it % 2){ //奇数 it = vec.insert(it, *it); it += 2; // 向前移动迭代器,跳过当前元素及插入到它之前的元素 // insert()在it的前面插入新元素,并返回指向新插入元素的迭代器,所以+2 } else{ //偶数 it = vec.erase(it); // 不必向前移动迭代器,erase()使it指向删除元素的下一个位置 } } for(const auto &num:vec) cout<<num<<" "; // 1 1 3 3 5 5 7 7 9 9 cout<<endl; return 0; } -
不要保存end返回的迭代器
当添加/删除vector、string的元素,或在deque中首元素之外的任何位置添加/删除元素,原来的end返回的迭代器总是失效。
因此,如果在一个循环中插入/删除deque、string、vector中的元素,不要缓存end返回的迭代器。
/** * 想要往每两个数中间插入42 */ #include <vector> #include <iostream> using namespace std; int main(){ vector<int> vec{0,1,2,3,4,5,6,7,8,9}; auto be = vec.begin(); // auto en = vec.end(); /*insert后,end迭代器失效会引发死循环*/ // while(be != en){ /*循环中,不要缓存尾后迭代器*/ while(be != vec.end()){ /*应该在每次插入操作后重新调用end()*/ ++be; be = vec.insert(be,42); ++be; } for(const auto &num:vec) cout<<num<<" "; // 0 42 1 42 2 42 3 42 4 42 5 42 6 42 7 42 8 42 9 42 cout<<endl; return 0; }
9.4 vector对象是如何增长的?

- resize和reserve
- resize改变容器中元素的数目,而不是容器的容量,如不能减少预留的内存空间。
- reserve仅影响vector/string预先分配多大的内存,并不改变容器中元素的数目
- capacity和size
- size已经保存的元素数目
- capacity表示在不分配新的内存的前提下,容器最多保存多少元素。
示例
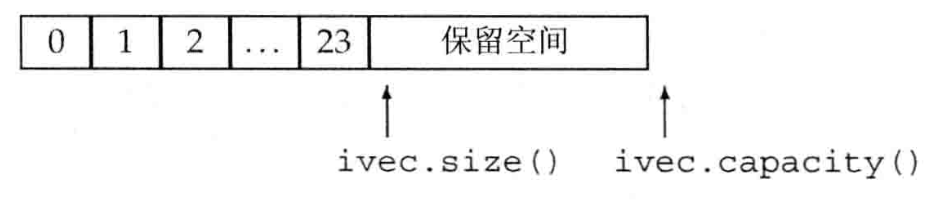
#include <vector>
#include <iostream>
using namespace std;
int main(){
vector<int> ivec;
cout<<"size = "<<ivec.size()<<" | "<<"capacity = "<<ivec.capacity()<<endl;
// size = 0 | capacity = 0
for(int i = 0; i < 24; ++i)
ivec.push_back(i);
cout<<"size = "<<ivec.size()<<" | "<<"capacity = "<<ivec.capacity()<<endl;
// size = 24 | capacity = 32
// 存了24个元素,分配了可保存32个元素内存
ivec.reserve(50);
cout<<"size = "<<ivec.size()<<" | "<<"capacity = "<<ivec.capacity()<<endl;
// size = 24 | capacity = 50、
// reserve()将内存括展到了50,ivec内元素个数没变
while(ivec.size()!=ivec.capacity())
ivec.push_back(0); //写满预分配的内存
ivec.push_back(1); // 在添加1位
cout<<"size = "<<ivec.size()<<" | "<<"capacity = "<<ivec.capacity()<<endl;
// size = 51 | capacity = 100
// 超出预分配的内存,ivec的内存两倍括展
ivec.shrink_to_fit();
cout<<"size = "<<ivec.size()<<" | "<<"capacity = "<<ivec.capacity()<<endl;
// size = 51 | capacity = 51
// 请求退还没有用过的内存(不一定采纳)
return 0;
}
9.5 forward_list专题
原文《特殊的forward_list》操作
当添加或删除一个元素时,删除或添加的元素之前的那个元素的后继会发生改变。为了添加或删除一个元素,我们需要访问其前驱,以便改变前驱的链接。但是,forward_list 是单向链表。在一个单向链表中,没有简单的方法来获取一个元素的前驱。
出于这个原因,在一个 forward list 中添加或删除元素的操作是通过改变给定元素之后的元素来完成的。这样,我们总是可以访问到被添加或删除操作所影响的元素。由于这些操作与其他容器上的操作的实现方式不同,forward_list 并未定义insert、emplace和erase,而是定义了名为insert_after、emplace_after和erase_after 的操作(参见表 9.8)。
例如,在我们的例子中,为了删除 elem3,应该用指向elem2的迭代器调用
erase_after。为了支持这些操作,forward_list还定义了before_begin,它返回一个首前迭代器。这个选代器允许我们在链表首元素之前并不存在的元素“之后”添加或删除元素(亦即在链表首元素之前添加删除元素)。

示例:
当向forward_list中添加或删除元素时,我们必须关注两个选代器:一个指向我们要处理的元素,另一个指向其前驱。
/**
* 知识点:
* 当向forward_list中添加或删除元素时,我们必须关注两个选代器:
* 一个指向我们要处理的元素,另一个指向其前驱。
*
* 示例:删除forward_list中的奇数
*/
#include <forward_list>
#include <iostream>
using namespace std;
int main(){
forward_list<int> flist = {0,1,2,3,4,5,6,7,8,9};
auto prev = flist.before_begin();//首前迭代器
auto curr = flist.begin();
while(curr != flist.end()){
if(*curr%2){
//奇数
curr = flist.erase_after(prev);//返回删除的元素的下一个位置的迭代器,并用其更新curr
}
else{
prev = curr;
++curr;
}
}
for(const auto &num:flist)
cout<<num<<" "; //0 2 4 6 8
cout<<endl;
return 0;
}
9.6 string专题
书P320《9.5 额外的string操作》
除了顺序容器的共同操作外,string还提供了一些额外的操作,如所述。
9.6.1 string操作函数汇总
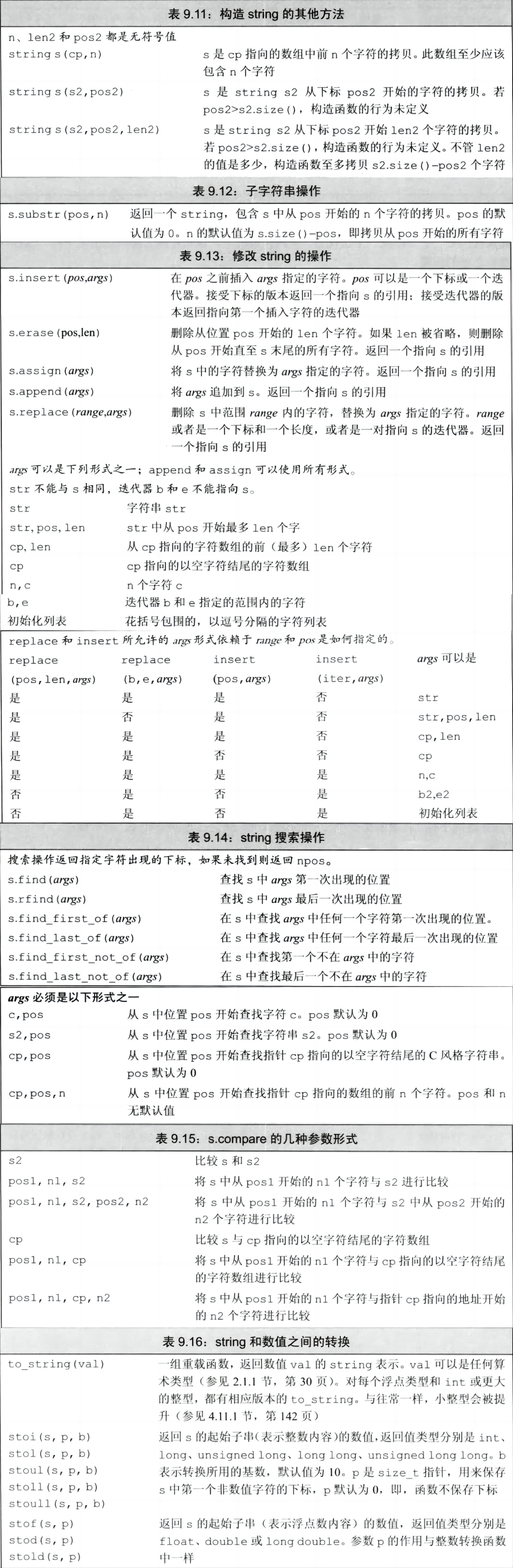
9.6.2 构造string的子序列
除了在[笔记3.2.1](#3.2.1 初始化)已经介绍过的构造函数方法,以及与其他顺序容器相同的构造函数外,string还支持另外3个构造函数。

当我们从一个const char*创建string时
- 通常,指针指向的数组必须以空字符结尾,拷贝操作遇到空字符时停止。
- 如果我们还传递给构造函数一个计数值,数组就不必以空字符结尾。
- 如果我们未传递计数值且数组也未以空字符结尾,或者给定计数值大于数组大小,则构造函数的行为是未定义的。
因此,const char *数组最好以空字符结尾。
当从string拷贝:
- 开始位置要小于或等于size
- 计数值再大,最多拷贝到string结束的位置
子字符串操作:
str.substr(pos = 0, n = str.size() -pos);
9.6.2 改变string的其他方法
联想:[3.4.4 与旧代码接口—c风格字符串](#3.4.4 与旧代码接口)
string类型支持顺序容器的赋值运算符以及assign、insert 和erase操作(表9.4;表9.7)外,还定义了额外的insert和erase版本。
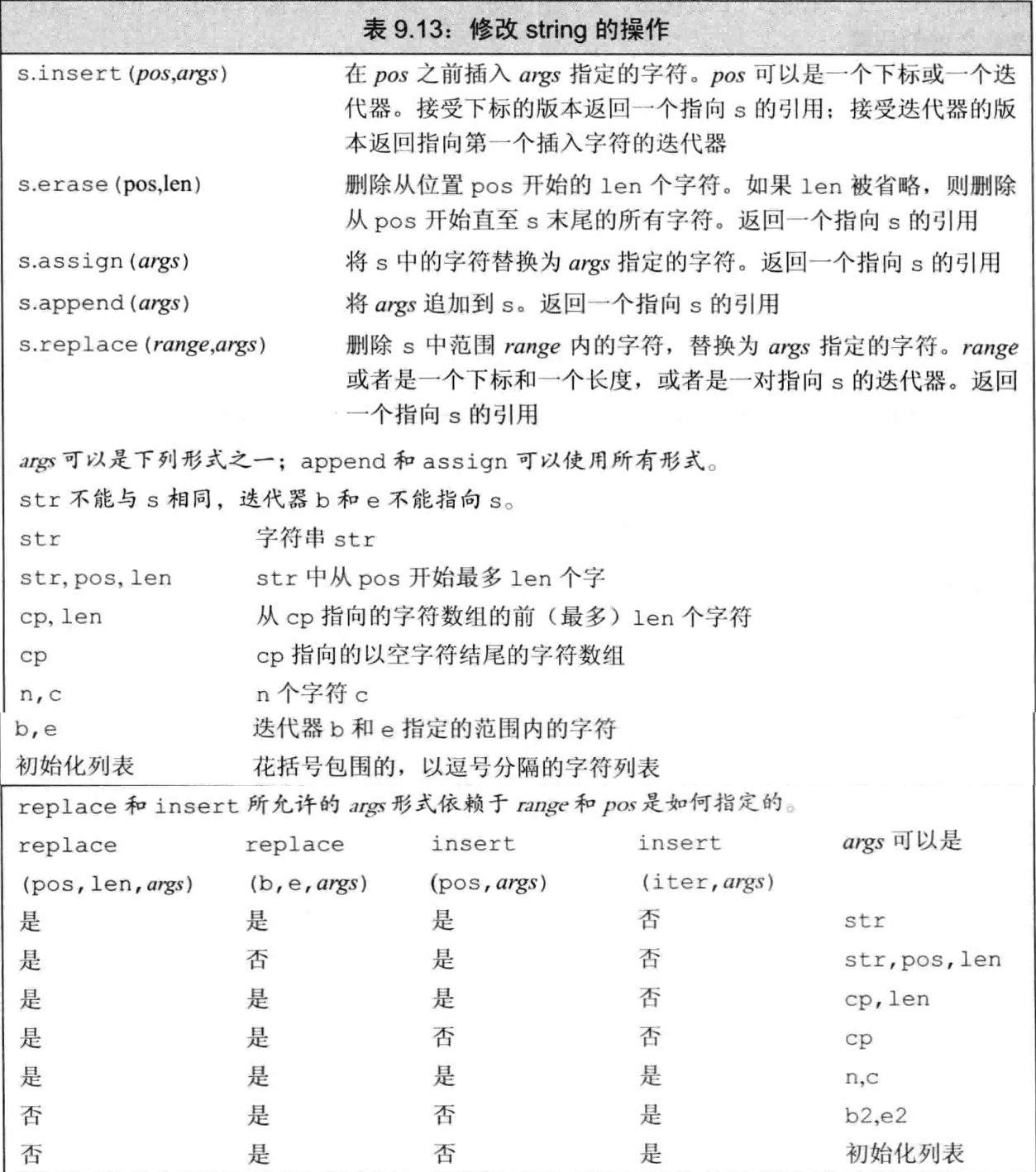
-
insert、erase、assign示例
#include <string> #include <iostream> using namespace std; void printStr(string &str){ cout<<str<<" | size = "<<str.size()<<endl; } int main(){ string s = "abcdefghij"; printStr(s); // abcdefghij | size = 10 string s1 = s; s1.insert(s1.size(), 5, '!'); //末尾插入5个感叹号 printStr(s1); // abcdefghij!!!!! | size = 15 string s2 = s; s2.erase(s.size()-5/*, 5*/); // 从s的倒数5个位置开始,删除最后5个字符 printStr(s2); // abcde | size = 5 string s3 = s; const char *cp = "stately, plump buck"; s3.assign(cp,2); // 用cp的前2个字符覆盖整个s printStr(s3); // st | size = 2 string s4 = s; s4.insert(s.size(), cp+7); // 从cp向后移动7位所指向的元素开始,到cp结束之间的所有字符,插入到s的末尾(s.size()) printStr(s4); // abcdefghij, plump buck | size = 22 string s5 = s; string s5_ = ",xyz"; s5.insert(0,s5_); //在s5的位置0处插入s5_ printStr(s5); // ,xyzabcdefghij | size = 14 string s6 = s; s6.insert(0,s5_,0,s5_.size()); // 在s6[0]之前插入s5_中s5_[0]开始的s5_.size()个字符 printStr(s6); //,xyzabcdefghij | size = 14 } -
append、replace示例
append(str):末尾追加strreplace(开始位置pos,删除几个元素n,在当前位置添加字符串str)= erase+insert;删除的字符数n可以不等于添加的字符数量str
#include <string> #include <iostream> using namespace std; void printStr(string &str){ cout<<str<<" | size = "<<str.size()<<endl; } int main(){ string s{"c++ primer"}; s.append(" 4th Ed."); printStr(s); // c++ primer 4th Ed. | size = 18 s.replace(11,3,"5th"); printStr(s); //c++ primer 5th Ed. | size = 18 //replace时,删除的字符数和添加的字符数可以不相等 s.replace(11,3,"Fifth");// 删除3个字符,但增加5个字符 printStr(s); // c++ primer Fifth Ed. | size = 20 }
9.6.3 string搜索操作

-
string类提供了6个搜索函数,每个函数都有4个重载版本。
-
搜索操作返回
string::size_type值,表示匹配发生位置的下标。若搜索失败,返回string::npos的static成员。标准库将npos定义为const string::size_type类型,并初始化为-1。又由于npos是unsigned类型,此初始值意味着npos等于任何string最大的可能大小。 -
搜索操作大小写敏感
-
str.find_first_of(args):返回str中第一个出现在args中的元素的下标
string str{"pi=3.14"}; string nums{"+-.0123456789"}; auto pos = str.find_first_of(nums); //str中第一个出现在nums的元素的下标(即“pi=3.14”的‘3’的下标) cout<<pos<<endl; // 3find_last_of、find_first_not_of、find_last_not_of
-
逆向搜索:有从左向右搜索,也有从右向左搜索的函数
-
一个常见的设计模式:
通过指定 从哪里搜索的可选参数 在字符串中循环地搜索 子字符串出现的所有位置string::size_type pos=0; string name{"bananabananabanana"}; string nums{"hb"}; while((pos=name.find_first_of(nums,pos))!=string::npos){ cout<<"found number at idx: "<<pos <<"element is "<< name[pos]<<endl; ++pos; //<-- 必须,否则死循环 } /* found number at idx: 0element is b found number at idx: 6element is b found number at idx: 12element is b */
9.6.4 compare
见笔记9.6.1汇总 表9.15
9.6.5 数值转换
书P327~P328

-
要转换为数值的string中,第一个空白字符必须是数值可能出现的字符:
string str{"pi = 3.14"}; double val = stod(str.substr(str.find_first_of("+-.0123456789"))); cout<<val<<endl; // 3.14- 如果string不能转换为数值,表9.6中函数抛出
invalid_argument异常 - 如果转换得到的数值无法用任何类型表示,抛出
out_of_range
- 如果string不能转换为数值,表9.6中函数抛出
-
查找原则
string 参数中第一个非空白符必须是符号(+ 或 -)或数字。它可以以0x 或0X开头来表示十六进制数。
对那些将字符串转换为浮点值的函数,string 参数也可以以小数点 (.)开头,并可以包含 e 或 E 来表示指数部分。
对于那些将字符串转换为整型值的函数,根据基数不同,string 参数可以包含字母字符,对应大于数字9的数。
9.7 适配器
(adaptor)

9.7.1 什么是适配器
9.7.2 定义一个适配器
一、每个适配器都定义两个构造函数
-
A a;默认构造函数创建一个空对象 -
A a(c)接受一个容器c的构造函数 ,拷贝容器c的元素来初始化适配器int main(){ deque<int> deq; stack<int> stk(deq); // 拷贝deq的元素到stk,以初始化stk // 其实隐藏了默认容器类型,等价于 stack<int,deque<int>> stk(deq); return 0; }
二、重载默认容器类型
默认容器类型:
- stack和queue基于deque实现
- priority_queue基于vector实现
我们可以在创建一个适配器时,将一个命名的顺序容器作为第二个 类型 参数,来重载默认容器类型。
using namespace std;
int main(){
vector<int> vec;
// 在vector的基础上实现空栈
stack<int,vector<int>> stk1;
// 在vector的基础上实现,初始化时保存vec的拷贝
stack<int,vector<int>> stk2(vec);
return 0;
}
三、重载默认容器类型的限制
stack:可用于除了array和forward_list之外的任何容器类型(deque、list、vector)
queue:只能用于list和deque之上,不能用于vector
priority_queue只能用于vector和deque,不能用于list
9.7.3 栈适配器
参考资料
stack定义在stack头文件中

用法示例(书P330):
#include <stack>
using namespace std;
int main(){
stack<int> stk;
for(size_t i = 0; i < 10; ++i)
stk.push(static_cast<int>(i));
while (!stk.empty())
{
int val = stk.top();
stk.pop();
}
return 0;
}
虽然每个适配器都是基于底层容器的操作定义自己的操作,但我们只可以使用适配器的操作,而不可使用底层容器的操作。如,虽然stack基于deque实现,stack.push()基于deque.push_back(),但我们不能在一个stack上调用push_back()
9.7.4 队列适配器
参考资料
queue和priority_queue定义在queue头文件中

queue(FIFO)
priority_queue:
priority_queue 允许我们为队列中的元素建立优先级。新加入的元素会排在所有优先级比它低的已有元素之前。
饭店按照客人预定时间而不是到来时间的早晚来为他们安排座位,就是一个优先队列的例子。
默认情况下,标准库在元素类型上使用
<运算符来确定相对优先级。
对于表9.19有个疑问:表中第二行说,queue也可以用list或vector实现,是不是有有误?
在《笔记9.6.2三、重载默认容器类型的限制(书P329最下面的一大段话)》中提到:queue:只能用于list和deque之上,不能用于vector。
两者是不是冲突了?
不知道两句换描述的事物是不是不一样,但照我理解,两句话在说一个东西。
实际测试:
1.正确执行
#include <queue>
#include <deque>
#include <iostream>
using namespace std;
int main(){
deque<int> deq{1,2,3,4};
queue<int,deque<int>> que1(deq);
while(!que1.empty())
{
cout<<que1.front()<<endl;
que1.pop();
}
}
2.正常编译:
#include <queue>
#include <vector>
using namespace std;
int main(){
vector<int> vec{1,2,3,4};
queue<int,vector<int>> que1(vec);
}
3.编译器报错:
In template: no member named 'pop_front' in 'std::vector
'
#include <vector>
#include <queue>
#include <iostream>
using namespace std;
int main(){
vector<int> vec{1,2,3,4};
queue<int,vector<int>> que1(vec);
while(!que1.empty())
{
cout<<que1.front()<<endl;
que1.pop(); // <--在此处报错
}
}
我认为,确实queue能用vector构造,但是当碰到处理(增删)首元素的情况,就会出错。所以不要用vector构造queue。
9.8 特例汇总
9.8.1 forward_list<>
- 没有
size操作 - 不支持反向迭代器
- 不支持
-- - 不支持适配器(因为所有适配器都要求容器有添加、删除和访问尾元素的能力)
单向链表对尾元素的处理很耗时,所以一般不支持xxx_back()操作,而是xxx_after():
- 不支持
push_back和emplace_back,有自己专有的insert和emplace - 不支持
back()获取尾元素的引用。 - 不支持
pop_back() - forward_list 并未定义insert、emplace和erase,而是定义了名为
insert_after、emplace_after和erase_after的操作(见forward_list专题)
9.8.2 string
- 不支持
C c(n)构造 swap会导致string的迭代器、指针和引用失效。而其他容器不会。
9.8.3 array<>
一、构造
C c默认构造的时候,c中的元素也会通过默认构造初始化。如果c是其他容器时,则为空。- 不支持通过
C c(n,t)、C c(n)构造容器。(n个值为t的元素)
二、拷贝和赋值
- 不支持
c = {a,b,c,...} - 不支持
C c(b,e):b和e为迭代器的范围拷贝构造(见笔记9.2.2 一、拷贝初始化) C c1=c2两者必须是相同大小
三、其他
-
不支持添加/插入/删除元素的函数
- 不支持笔记9.3.1中表9.5(如
push_back) - 不支持笔记9.3.3的所有操作
- 不支持笔记9.3.1中表9.5(如
-
swap会真正交换array的元素值,而其他容器不会。 -
不支持
resize() -
不支持适配器(因为所有适配器都要求容器有添加和删除元素的能力)
十 泛型算法
10.1 概述
关键概念:算法永远不会执行容器的操作(算法只所用于迭代器)
泛型算法本身不会执行容器的操作,它们只会运行于迭代器之上,执行迭代器的操作。泛型算法运行于迭代器之上而不会执行容器操作的特性带来了一个令人惊讶但非常必要的编程假定:算法永远不会改变底层容器的大小。算法可能改变容器中保存的元素的值,也可能在容器内移动元素,但永远不会直接添加或删除元素。
如我们将在书本10.4.1节(第358页)所看到的,标准库定义了一类特殊的迭代器,称为插入器(inserter)。与普通迭代器只能遍历所绑定的容器相比,插入器能做更多的事情。当给这类迭代器赋值时,它们会在底层的容器上执行插入操作。因此,当一个算法操作一个这样的迭代器时,迭代器可以完成向容器添加元素的效果,但算法自身永远不会做这样的操作。
-
大多数算法定义在
algorithm中,numeric也定义了一组数值泛型算法。 -
一般情况下,这些算法并不直接操作容器,而是遍历由两个迭代器指定的一个元素范围来进行操作。
-
迭代器令算法不依赖于容器,但是算法依赖于容器的元素类型。(因为算法要对元素进行比较等操作)
10.2 初识泛型算法
10.2.1 只读算法
-
find_<algorithm>
fund(开始迭代器(指针),结束迭代器(指针),val)- 作用:在指定范围内
[开始迭代器,结束迭代器)查找val值,找到了就返回 第一个 等于val的 元素的 迭代器,否则返回结束迭代器。
- 作用:在指定范围内
-
count_<algorithm>- 作用:返回给定值在次序中出现的次数
-
accumulate_<numeric>
sum = accumulate(vec.cbegin(),vec.cend(),0)-
作用:将范围内所有元素加到第三个参数上,返回最终的加法之和。
-
要求第三个参数重载过
+。 -
第三个参数决定了函数中使用哪个类型重载的加法运算符,以及返回值类型。
string sum = accumulate(str.cbegin(),str.cend(),string("")); //正确 string sum = accumulate(str.cbegin(),str.cend(),""); //错误,const char*没有重载过‘+’运算符
-
-
equal_<algorithm>
equal(roster1.cbegin(),roster1.cend(),roster2.cbegin());- 作用:用于确定两个序列是否保存相同的值。第三个参数是第二个序列的首元素的迭代器
- 基于假设:它假定第二序列至少与第一序列一样长


- 由于equal利用迭代器完成操作,因此,我们可以通过调用equal来比较两个不同类型的容器中的元素,而且,元素类型也不必一样,只要我们能用
==来比较两个元素类型即可。

10.2.2 写容器元素算法
-
fill
fill(vec.begin(),vec.end(),val);- 作用:将范围内的每个元素重置为第三个参数
-
fill_n
fill_n(起始位置迭代器,n,val)-
作用:从其实位置的迭代器开始,将n和元素替换为val
-
注意:不应在一个空容器上调用
fill_n,或类似写元素的算法。示例如下://灾难错误示例 vector<int> vec; //空vector //修改了10个不存在的向量,引发未定义的结果 fill_n(vec.begin(), 10, 0);
-
-
back_inserter_<iterator>:“插入” 迭代器-
作用:接受一个指向容器的引用,返回一个与该容器绑定插入迭代器。
-
我们用此迭代器赋值时,赋值运算符会调用push_back。
-
常常使用back_inserter创建一个插入迭代器,作为算法的目的位置使用
-
示例:
#include <string> #include <iostream> #include <vector> #include <iterator> using namespace std; /** 有bug * 重载<<,流式输出容器中的元素 * @tparam T * @param os * @param ctor * @return */ template<typename T> ostream& operator<<(ostream &os,T &ctor){ for(const auto &ele:ctor){ os<<ele; } return os; } int main(){ /*例1*/ vector<int> vec; //空容器 auto iter = back_inserter(vec); // 插入迭代器 *iter = 24; //赋值运算符调用push_back cout<<vec<<endl; /*例2*/ vec.clear(); //清空容器 //常常使用back_inserter创建一个插入迭代器,作为算法的目的位置使用 fill_n(back_inserter(vec),10,1); cout<<vec<<endl; return 0; }
-
-
copy
copy(源起始迭代器,源终止迭代器,目的序列的起始位置)-
传递给copy的目的序列至少要包含与输入序列一样多的元素
-
返回目的位置迭代器增值后的值。下例中为a2尾后位置:
#include <string> #include <iostream> #include <vector> #include <iterator> using namespace std; /** 有bug * 流式输出容器 * @tparam T * @param os * @param ctor * @return */ template<typename T> ostream& operator<<(ostream &os,T &ctor){ for(const auto &ele:ctor){ os<<ele; } return os; } int main(){ int a1[] = {1,2,3,4,5,6,7,8,9}; int a2[sizeof(a1)/sizeof(*a1)]; auto re = copy(begin(a1), end(a1),a2); // re指向尾后 cout<<a2<<endl; // 123456789 cout<<*(re-1)<<endl; // 9 return 0; }
-
-
replace_copy
replace_copy(ilst.cbegin(), ilst.end(), back_inserter(ivec), 0, 42);
将ilst(值不会改变)中的所有元素拷贝到ivec(可以是空列表)之后,并将ivec中的0替换为24- 对比replace是将原来的序列范围内的值替换
10.2.3 重排容器元素算法
sort:sort(序列开始位置迭代器,结束位置迭代器)unique:返回不重复区域之后一个位置的迭代器 = unique(序列开始位置迭代器,结束位置迭代器)
书中的例子:排序一个由单词组成的vector,并删除重复的单词

#include <string>
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
template<typename T>
void printCtor(T &ctor){
for(const auto &ele:ctor){
cout<<ele<<" ";
}
}
int main(){
vector<string> vec{"the","quick","red","fox","jumps","over","the","slow","red","turtle"};
printCtor(vec);cout<<endl;
// 输出:the quick red fox jumps over the slow red turtle
/*sort*/
sort(vec.begin(), vec.end());
printCtor(vec);cout<<endl;
// 输出:fox jumps over quick red red slow the the turtle
/*unique 将重复项移动到末尾*/
// iter指向不重复区域的下一个位置
auto iter = unique(vec.begin(), vec.end());
vec.erase(iter,vec.end());
printCtor(vec);cout<<endl;
// 输出:fox jumps over quick red slow the turtle
return 0;
}
10.3 定制操作
10.3.1 谓词
一、通过“谓词”改变算法的默认行为
“谓词”是一种可调用的表达式,其返回结果是一个能用作条件的值。
- 一元谓词,只接受一个单一参数的谓词
- 二元谓词,接受两个参数的谓词
接受谓词参数的算法对输入序列中的元素调用谓词,元素类型必须能转化为谓词的参数类型。
根据算法接受一元谓词还是二元谓词,我们传递给算法的谓词必须严格接受一个或两个参数。
二、举例
接受一个二元谓词参数的sort(),用谓词替换<来比较元素
bool isShorter(const string s1, const string s2){
return s1.size()<s2.size();
}
sort(words.begin(), words.end(), isShorter);
stable_sort(words.begin(), words.end(), isShorter);//可保持等长元素间的字典顺序
三、补充
find_if()算法接受一对迭代器,表示一个范围。与find()不同的是,find_if()的第三个参数是一个谓词,find_if算法对输入序列中的每个元素调用给定的这个谓词,返回第一个使谓词返回非0值的元素,如果不存在这样的元素,则返回尾迭代器。
size_t sz = 5;
auto wc = find_if(word.begin(), word.end(), [sz](const string &s){return s.size() >= sz ;});
for_each()接受一个可调用的对象,并对输入序列中的每个元素调用此对象。
for_each(word.begin(), word.end(), [](const string &s){cout<<s<<" ";});
10.3.2 lambda
(很重要,放在二级标题)
一、书写格式
[capture list](parameter list) -> return type { function body }
我们可以忽略参数列表和返回类型,但必须永远包含捕获列表和函数体
auto f = []{ return 42; }; // 相当于空参数列表;自动推导返回类型。
cout<<f()<<endl;
二、参数
lambda不能有默认参数 ---> 一个lambda调用的实参数目永远与形参数目相等。
三、捕获列表
一、谁需要被捕获?
捕获列表只适用于局部非static变量,可以直接使用局部static变量和在它所在函数之外声明的名字。
int a = 1;
int main() {
int b = 2; // 只有局部非static变量需要捕获
static int c = 3;
auto f = [b]() {cout << a << " " << b << " " << c; };
// f的类型 main::__l2::<lambda_1>
f(); // 1 2 3
return 0;
}
二、几种捕获方式
1.值捕获
-
采用值捕获的前提是变量可以拷贝
-
被捕获的变量的值是在lambda创建时拷贝,而不是调用时拷贝。(与函数参数不同)
-
又由于 “ 被捕获的变量的值是在lambda创建时拷贝”,因此,随后对其修改不会影响到lambda内对应的值
void func1(){ size_t v1 = 42; auto f = [v1]{return v1;};// <--值捕获 v1=0; auto j = f();// j = 42; }
2.引用捕获
下例为引用捕获示例与上述值捕获示例的对比
void func1(){
size_t v1 = 42;
auto f = [&v1]{return v1;}; // <--引用捕获
v1=0;
auto j = f();// j = 0;
}
lambda捕获的都是函数的局部变量,函数结束后,捕获的引用指向的局部变量已经消失。
-
必须确保被引用的对象在lambda执行的时候是存在的。
-
函数不能返回一个包含引用捕获的lambda(因为局部变量已消失,和函数不能返回局部变量的引用/指针是一个道理)

3.隐式捕获
- 当我们混合使用隐式捕获和显式捕获时,
- 必须以隐式捕获开头(原文:捕获列表的第一个元素必须是一个
&或=,以指定默认捕获方式)。 - 显式捕获的变量必须使用与隐式捕获不同的方式。
- 必须以隐式捕获开头(原文:捕获列表的第一个元素必须是一个
三、捕获列表的书写方式汇总

四、可变lambda(mutable)
-
默认情况下,对于一个值被拷贝的变量,lambda 不会改变其值。但是,如果我们希望能改变个被捕获的变量的值,就必须在参数列表首加上关键字 mutable。
-
一个引用捕获的变量是否可以修改,依赖于此引用指向的是一个const还是一个非const
-
对于局部static变量和在它所在函数之外声明,不用mutable也可以在lambda中修改
/*如果我们希望能改变个被捕获的变量的值,就必须在参数列表首加上关键字 mutable。*/
int v1 = 42;
auto f = [v1]() mutable {return ++v1; };
// auto f = [v1]() { return ++v1; }; //v1报错:表达式必须是可修改的左值(v1只读)
cout << v1 << " " << f() << endl; // 42 43
/*一个引用捕获的变量是否可以修改,依赖于此引用指向的是一个const还是一个非const*/
auto f1 = [&v1]() {return ++v1; };
cout << v1 << " " << f1() << endl; //43 43
const int v2 = 1;
//auto f2 = [&v2] {return ++v2; }; //v2报错:表达式必须是可修改的左值
/*对于局部static变量和在它所在函数之外声明,不用mutable也可以在lambda中修改*/
static int v3 = 1;
auto f3 = [] {return ++v3; };
cout << v3 << " " << f3(); // 2 2
四、指定lambda的返回类型
-
默认情况下,如果一个lambda体 除了单一return外 还包含了其他语句,则编译器假定lambda返回void。如果与本意不符,需要显式指明返回类型。
-
示例
//lambda体内只有一条return语句,编译器自动推导返回类型 transform(vi.begin(), vi.end(), vi,begin(), [](int i){ return i < 0 ? -i : i; }); //编译错误: //除了单一return外 还包含了其他语句,编译器推断为void,实际却返回int transform(vi.begin(), vi.end(), vi,begin(),[](int i){ if(i < 0) return -i; else return i; }); //正确写法:显式指定返回类型 transform(vi.begin(), vi.end(), vi,begin(),[](int i)->int{ // 尾置返回类型 if(i < 0) return -i; else return i; }); -
补充:
transform()
使用标准库 transform 算法和一个 lambda来将一个序列中的每个负数替换为其绝对值:transform(vi.begin(), vi.end(), vi.begin(), [](int i) { return i < 0 ?-i :i; });函数transform接受三个迭代器和一个可调用对象。前两个迭代器表示输入序列,第三个迭代器表示目的位置。算法对输入序列中每个元素调用可调用对象,并将结果写到目的位置。
五、参数绑定
一、引入
之前我们写过的代码
size_t sz = 5;
auto wc = find_if(word.begin(), word.end(), [sz](const string &s){return s.size() >= sz ;});
如果好多地方使用同样的操作,或者操作需要很多语句才能完成,使用lambda不方便,需要使用函数。但是如何用接受两个参数的函数替换一元谓词?如
bool check_sz(const string &s, string::size_type sz){
return s.size() > sz ;
}
auto wc = find_if(word.begin(), word.end(), /*check_sz*/); // 如何用接受两个参数的函数替换一元谓词?
二、bind
使用在库functional中的bind()。可以将其看做函数适配器(类比容器适配器),接受一个可调用对象,生成一个新的可调用对象来“适应”原本对象的参数列表。一般形式为:
auto newCallable = bind(callable, arg_list);
当调用newCallable时,newCallable会调用函数callable,并向callable传递arg_list中的参数。
其中,arg_list中可能会有std::placeholders::_n,为占位符。表示调用newCallable时,传入的参数应该填入callable形参列表的第n位。
举例,对于一中的例子,利用bind改写:
bool check_sz(const string &s, string::size_type sz){
return s.size() > sz ;
}
auto check6 = bind(check_sz, std::placeholders::_1, 6);
auto wc = find_if(word.begin(), word.end(), check6);
举例2:
using namesapce std::placeholders;
bool check_sz(const string &s, string::size_type sz){
return s.size() > sz ;
}
auto check6 = bind(check_sz, _1, 6);
string s = "hello";
bool b1 = check6(s); // 相当于 check_sz(s,6);
三、bind的参数
bind对参数的作用:
-
绑定给定可调用对象中的参数(上文所述)
-
重新安排参数的顺序。示例如下:
auto g = bind(func, a, b, _2, c, _1); g(X,Y);//func(a,b,Y,c,X);
四、绑定引用参数
我们希望传递一个引用给bind,而不是拷贝,用ref()或cref()
#include <functional>
for_each(words.begin(), words.end(), bind(print, ref(os), _1, ' '));
10.4 再探迭代器
补充额外的迭代器:
- 插入迭代器(insert iterator):迭代器被绑定到一个容器上,可以用来向容器插入元素
- 流迭代器(stream iterator):迭代器被绑定到输入/输出流上,用来遍历所关联的io
- 反向迭代器(reverse iterator):迭代器向反方向移动(++/--方向相反)。除了forward_list外标准库容器都有反向迭代器
- 移动迭代器(move iterator):这些迭代器不是拷贝其中的元素,而是移动它们。
10.4.1 插入迭代器

vector<int> nums{ 0,1,2,3,4,5,6,7,8,9 };
auto it = inserter(nums,++nums.begin()); // inserter(容器,迭代器);插入迭代器之前的位置
it = 12; //等价*it或++it或it++ = 12,因为这三个存在但什么都不做,只返回it
for (const auto& num : nums) {
cout << num << " ";//0 12 1 2 3 4 5 6 7 8 9
}
//等价
vector<int> nums{ 0,1,2,3,4,5,6,7,8,9 };
int ins_num = 12;
auto iter = nums.insert(++nums.begin(), ins_num);
++iter; // <--特别注意这里,iter又指回了原来的地方
for (const auto& num : nums) {
cout << num << " ";//0 12 1 2 3 4 5 6 7 8 9
}
一个值得注意的地方:
list<int> lst{1,2,3,4};
list<int> lst2, lst3;
copy(lst.begin(), lst.end(), front_inserter(lst2));//lst2=4 3 2 1
copy(lst.begin(), lst.end(), inserter(lst3,lst3.begin()));//lst2=1 2 3 4
原理如图所示:
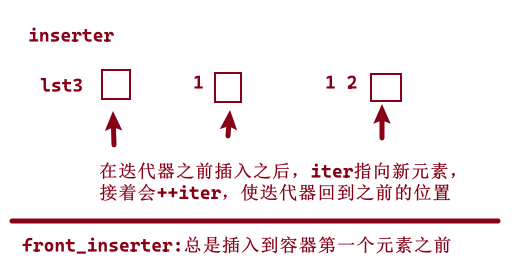
10.4.2 流迭代器
原文:iostream迭代器
虽然iostream类型不是容器,但标准库定义了可以用于这些IO类型对象的选代器(参见8.1 节,第278页)。
istream_iterator (参见表10.3)读取输入流,ostream_iterator(参见表10.4节,第361页)向一个输出流写数据。
这些选代器将它们对应的流当作一个特定类型的元素序列来处理。通过使用流迭代器,我们可以用泛型算法从流对象读取数据以及向其写入数据。
一、istream_iterator

用法示例:用一个istream_iterator从标准输入读取数据,存入一个vector的例子
/* 写法1 */
vector<int> vec;
istream_iterator<int> in_iter(cin) /* 从cin读取int类型的数据 */, eof/*istream尾后迭代器*/;
while (in_iter != eof)
{
vec.push_back(*in_iter++);
}
/*写法2,等价于写法1*/
istream_iterator<int> in_iter(cin), eof;
vector<int> vec(in_iter, eof); // 从迭代器范围构造vec(用一对表示元素范围的迭代器构造vec)
要求:
- 必须指定迭代器将要读写的对象类型
- 该对象类型定义了
>>来读取流 - 默认初始化迭代器,即创建了istream流的尾后迭代器
特点:允许使用懒惰求值。 <-- 没怎么看懂
当我们将一个istream_iterator 绑定到一个流时,标准库并不保证迭代器立即从流读取数据。具体实现可以推迟从流中读取数据,直到我们使用迭代器时才真正读取。
标准库中的实现所保证的是,在我们第一次解引用迭代器之前,从流中读取数据的操作已经完成了。对于大多数程序来说,立即读取还是推迟读取没什么差别。但是,如果我们创建了一个istream_iterator,没有使用就销毁了,或者我们正在从两个不同的对象同步读取同一个流,那么何时读取可能就很重要了。
应用:用一对istream_iterator来调用accumulate
istream_iterator<int> in(cin), eof;
cout<<accumulate(in, eof, 0)<<endl;
二、ostream_iterator

用法示例:用ostream_iterator来输出 值的序列
/* 写法1 */
vector<int> vec{0,1,2,3,4,5,6};
ostream_iterator<int> out_iter(cout, " ");
for (const auto& n : vec)
*out_iter++ = n; // 0 1 2 3 4 5 6
// 等价
// out_iter = n; // 不推荐,因为上面的写法更易阅读
/* 写法2 */
copy(vec.begin(), vec.end(), out_iter);
要求:
- 要输出的类型 定义了
<< - 第二个可选参数表示:在输出的每个元素后都会打印该字符(必须是c风格字符串——字符串字面常量或以空字符结尾的字符数组的指针)
- ostream_iterator必须绑定到一个指定的流,不允许空的或表示尾后位置的ostream_iterator
应用:(书P362)
10.4.3 反向迭代器
rbegin(),rend(), crbegin(),crend()- forward_list和流迭代器不能创建反向迭代器
- reverse_iterator的
base()将反向迭代器转换为普通迭代器(在容器中正向移动)

应用:
/*例1*/
sort(vec.begin(), vec.end()); // 顺序
sort(vec.rbegin(), vec.rend()); // 逆序
/*例2*/
//first,middle,last
auto comma = find(line.cbegin(), line.cend(), ',');
cout<<string(line.cbegin(), comma);//first
auto rcomma = find(line.crbegin(), line.crend(), ',');
cout<<string(line.crbegin(), rcomma);//tsal
cout<<string(rcomma.base(),line.cend());//last
10.5 泛型算法结构
10.5.1 五类迭代器
任何算法最基本的特性是 它要求其迭代器提供哪些操作。
类似容器,迭代器也定义了一组公共操作。迭代器按其提供的操作分类,这些分类形成了一种层次,除了输出迭代器外,一个高层类别的迭代器支持低层类别迭代器的所有操作。
C++标准指明了泛型和数值算法的每个迭代器参数的最小类别(至少应该达到的类别)。例如,find 算法在个序列上进行一遍扫描,对元素进行只读操作,因此至少需要输入迭代器。对每个迭代器参数来说,其能力必须与规定的最小类别至少相当。向算法传递一个能力更差的迭代器会产生错误。
迭代器提供的操作可以划分为5类。每个算法都会对 它的每个迭代器参数 指明 需要提供哪类迭代器。

迭代器类别简述:

10.5.2 算法形参模式

- dest
- 表示算法可以写入的目的位置迭代器
- 使用dest时,算法假定:按其需要写入的数据,不管写入多少元素都是安全的
- 如果dest是一个直接指向容器的迭代器,算法将输出数据写到容器中已存在的元素内
- beg2
- 接受单独beg2的算法 假定从beg2开始的序列 至少 与beg和end所表示的范围 一样大
10.5.3 算法命名规范
-
一些算法使用重载形式传递一个谓词
-
_if版本的算法
-
接受一个元素值的算法通常有一个不同名的版本,接受一个谓词以替代元素值,这类接受谓词参数的算法都附加_if。
-
示例
find(beg,end,val);//查找范围内val第一次出现的位置 find_if(beg,end,pred);//查找第一个令pred为真的元素的位置
-
-
_copy版本的算法
-
默认情况下,重排元素的算法将重排后的元素写回给定的输入序列中。这些算法还提供另一个版本,将元素写到一个指定的输出目的位置。如我们所见,写到额外目的空间的算法都在名字后面附加一个
_copy -
示例
reverse(begin,end); // 反向输入范围中的序列 reverse_copy(begin,end,dest); // 将元素按逆序拷贝到dest
-
-
一些算法同时提供_if和_copy,如
remove_if和remove_copy_if
10.6 特定容器算法
-
对于
list和forward_list,应该 优先使用成员函数版本的算法 而不是通用算法

-
链表类型还定义了
splice成员(链表特有,splice和splice_after)

-
链表特有的操作会改变容器
多数链表特有的算法都与其通用版本很相似,但不完全相同。链表特有版本与通用版本间的一个至关重要的区别是链表版本 会 改变底层的容器。例如,remove 的链表版本会删除指定的元素。unique 的链表版本会删除第二个和后继的重复元素。
类似的,merge和splice 会销毁其参数。例如,通用版本的merge 将合并的序列写到一个给定的目的迭代器:两个输入序列是不变的。而链表版本的 merge 函数会销毁给定的链表——元素从参数指定的链表中删除,被合并到调用 merge 的链表对象中。在merge 之后,来自两个链表中的元素仍然存在,但它们都已在同一个链表中。
十一 关联容器
-
map & set
- map中的元素是键值对
- set每个元素只包含一个关键字
-
8个容器见的不同体现在3个维度上
-
map or set
-
要求不重复关键字 or 允许重复关键字
multi -
顺序存储 or 无序存储
unordered-
有序存储会自动排序
multimap<string,string> authors{{"Alain","a"}, {"Stanley","c++Primer"}, {"Alain","b"}, {"Blain","c"}};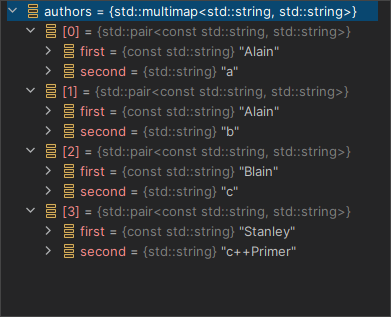
-
-
-
也可以对一个关联容器进行列表初始化
11.1 简单使用关联容器
-
map
-
map是键值对的集和
-
map通常被称为关联数组,可使用key而不是位置作为下标来查找val
-
map<key的类型,val的类型>--> 每个元素是一个pair类型,.first表示key,.second表示val
-
-
set
- set就是关键字的简单集和。
- 值就是关键字
简单应用:单词计数
map<string,size_t> word_cnt;
set<string> exclude{"the","a","an","but"}; //忽略计数的单词
string word;
while(cin>>word)
if(exclude.find(word) == exclude.end()) // 没找到,返回尾后指针
++word_cnt[word]; // ++是将val加1
for(const auto &w:word_cnt){
cout<<w.first<<" occurs "<<w.second
<<((w.second>1)?" times ":" time ")<<endl;
}
11.2 关联容器概述
11.2.1 如何定义关联式容器
- 除了不支持顺序容器的
push_back等位置操作,以及构造函数和插入操作这些接受一个元素值和一个数量值的操作外,都支持[笔记9.2中表9.2](#9.2 容器库概览)的普通容器操作。 - 关联容器的迭代器都是双向的
- 初始化

- 初始化时,没有muti的关联容器会自动删除key重复的元素

11.2.2 关键字类型的要求
-
对于有序容器,关键字类型必须定义元素比较的方法。默认情况下标准库使用key类型的
<运算符来比较两个关键字。 -
key类型可以提供自己的操作来替代默认的
<,遵循严格弱序(小于等于)

-
key如果没有自定义的
<运算符,也可使用关键字类型的比较函数,下例所示// 比较函数 bool compareIsbn(const Sales_data &sd1, const Sales_data &sd2){ return sd1.isbn() < sd2.isbn(); } // 定义mutiset mutiset<Sales_data, decltype(compareIsbn) *> bookstore(); // decltype作用于函数时,返回函数类型而非指针类型,所以要另加*号- 元素的操作类型(比较函数)也是容器类型的一部分
- 操作类型也仅仅只是类型,当创建容器时,才会以构造函数参数的形式提供真正的比较操作。
11.2.3 pair
-
#include <utility> -
pair上的操作

-
如何创建一个
pair对象/*写法1*/ {key,val}; /*写法2*/ pair<key_type,val_type>(key,val); /*写法3*/ make_pair(key,val); /*隐式构造一个空的pair*/ pair<key_type,val_type>();
11.3 关联容器操作
11.3.1 获得关联容器中元素的类型 & 容器迭代器

-
关键字是const的,不能随便改变一个元素的关键字
-
1.类型别名

-
2.不能改变map的key的值,因为是const的

-
3.set的val就是key,同样是const的
虽然set 类型同时定义了iterator和const_iterator类型,但两种类型都只允许只读访问 set 中的元素。
与不能改变一个map 元素的关键字一样,一个 set 中的关键字也是 const 的。

-
-
同样可由
++迭代器遍历关联容器 -
关联容器和算法
- 通常不对关联容器使用泛型算法——关键字是const的
- 关联容器可用于只读容器的算法——不过建议使用成员函数
- 在实际编程中,如果我们真要对一个关联容器使用算法,要么是将它当作一个源序列,要么当作一个目的序列。
11.3.2 添加元素

-
非muti在构造时会自动忽略重复的项
-
对map进行insert,切记所需元素类型的pair
-
insert/emplace的返回值
-
对于非muti,返回一个pair。first是一个指向插入的元素的迭代器。second是一个bool,指出 插入成功(true) 还是 已在容器中(false)
-
对于first,通常用auto代替,详细的结构如下:
map<string,size_t> word_cnt; pair<map<string,size_t>::iterator, bool> ret = word_cnt.insert({word,1});
-
-
对muti,返回值为指向新元素的迭代器,没有bool
- 应用:添加具有相同关键字的多个元素
11.3.3 删除元素

11.3.4 map的下标操作

- 仅map和unordered_map支持下标操作
- 如果关键字不在map/unordered_map中,会创建该关键字。初始化顺序如下:

- 由于下标运算符可能插入一个新元素,所以只能对非const使用
- 解引用迭代器和下标操作所得到的值不同,前者为(value_type),后者为(mapped_type)
11.3.5 访问元素

-
只是为了判断特定元素在不在容器中,find是最佳选择,下标运算会有副作用
-
muti容器中,具有相同关键字的多个元素相邻存储
multimap<string,string> authors{{"Alain","a"}, {"Stanley","c++Primer"}, {"Alain","b"}, {"Blain","c"}}; string author{"Alain"}; auto entries = authors.count(author); // 元素个数 auto iter = authors.find(author); // 作者的第一本书 while (entries--){ cout<<iter->second<<" "; // a b ++iter; } -
针对muti,lower_bound和upper_bound
- lower_bound返回的迭代器指向第一个具有给定关键字的元素
- upper_bound返回的迭代器指向最后一个具有给定关键字的元素之后的位置
- 如果给定关键字不存在,则两个函数指向相同的位置——第一个安全的插入点(即能够保持容器顺序的插入位置)
//等价上例 multimap<string,string> authors{{"Alain","a"}, {"Stanley","c++Primer"}, {"Alain","b"}, {"Blain","c"}}; string author{"Alain"}; for(auto beg = authors.lower_bound(author), end = authors.upper_bound(author); beg != end; ++beg) { cout<<beg->second<<" "; // a b }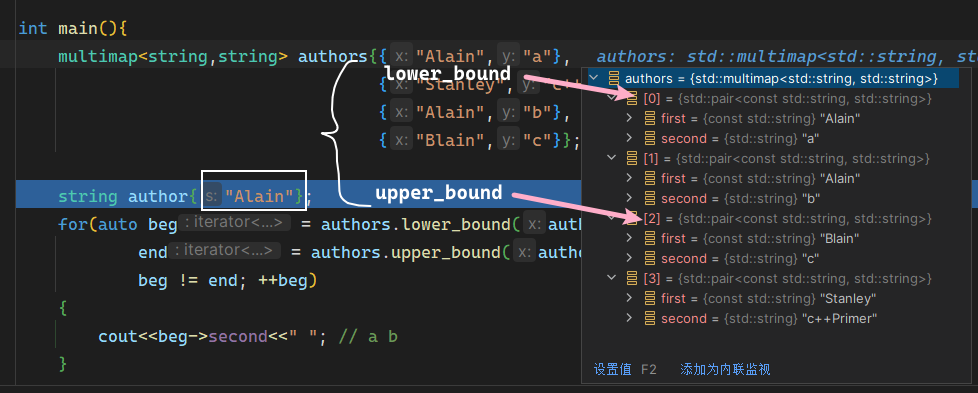
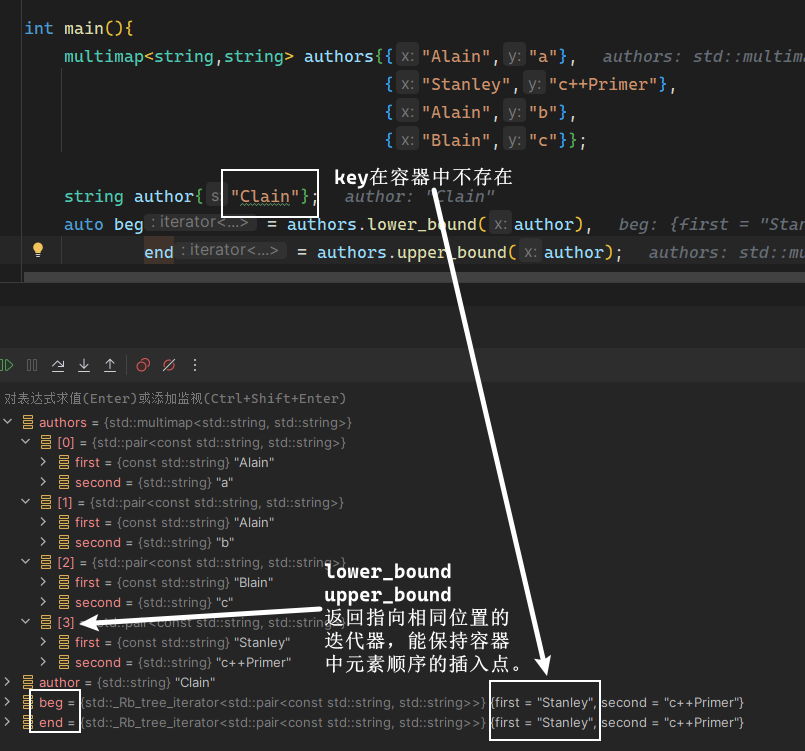
-
equal_bound
-
此函数接受一个关键字,返回一个选代器对pair。若关键字存在,则第一个迭代器指向第一个与关键字匹配的元素(相当于lower_bound),第二个迭代器指向最后一个匹配元素之后的位置(相当于upper_bound)。若未找到匹配元素,则两个迭代器都指向关键字可以插入的位置(同样类似lower_bound和upper_bound)。
-
示例
//等价上例 multimap<string,string> authors{{"Alain","a"}, {"Stanley","c++Primer"}, {"Alain","b"}, {"Blain","c"}}; string author{"Alain"}; for(auto pos = authors.equal_range(author); pos.first != pos.second; ++pos.first) { cout<<pos.first->second<<" "; // a b }
-
11.4 无序容器
-
通常可以用无序容器替换对应的有序容器,反之亦然。但是,由于元素未按顺序存储,一个使用无序容器的输出(通常)会与使用有序容器的版本不同。
-
管理桶
-
无序容器的形式如下图所示
-
无序容器在存储上组织为一组桶,每个桶保存零个或多个元素。无序容器使用一个哈希函数将元素映射到桶。为了访问一个元素,容器首先计算元素的哈希值,它指出应该搜索哪个桶。容器将具有一个特定哈希值的所有元素都保存在相同的桶中。如果容器允许重复关键字,所有具有相同关键字的元素也都会在同一个桶中。因此,无序容器的性能依赖于哈希函数的质量和桶的数量和大小。
对于相同的参数,哈希函数必须总是产生相同的结果。理想情况下,哈希函数还能将每个特定的值映射到唯一的桶。但是,将不同关键字的元素映射到相同的桶也是允许的。当一个桶保存多个元素时,需要顺序搜索这些元素来查找我们想要的那个。计算一个元素的哈希值和在桶中搜索通常都是很快的操作。但是,如果一个桶中保存了很多元素,那么查找一个特定元素就需要大量比较操作。
-
无序容器的管理操作

-
-
无序容器对key类型的要求
-
无序容器需要
==来比较元素和hash<key_type>来生成每个元素的hash值 -
可以通过重载关键字类型的默认操作,类定义无序容器:
class Sales_data{ public: explicit Sales_data(string isbn):m_isbn(std::move(isbn)){} string isbn() const { return m_isbn;} private: string m_isbn; }; size_t hasher(const Sales_data &sd){ return hash<string>()(sd.isbn()); } bool eqop(const Sales_data &lhs, const Sales_data &rhs){ return lhs.isbn() == rhs.isbn(); } int main(){ using sd_mutiset = unordered_set<Sales_data, decltype(hasher)*, decltype(eqop)*>; sd_mutiset bookstore(42, hasher, eqop);//桶数目、哈希函数指针、相等性判断运算符指针 //如果Sales_data中重载了==,可省略等号 unordered_set<Foo,decltype(FooHash)*> fooSet(10,FooFash); return 0; }
-
十二 动态内存
12.1 动态内存与智能指针
使用动态内存的原因:
- 程序不知道自己使用多少个对象
- 程序不知道所需对象的准确类型
- 程序需要在对个对象间共享数据

12.1.1 shared_ptr
-
make_shared()-
最安全的分配和使用动态内存的方法.
-
返回一个
shared_ptr,指向函数在动态内存中分配的对象 -
#include <memery> -
类似
emplace,make_shared()用其参数构造给定类型的对象shared_ptr<string> ptr = make_shared<string>(10,'9');// 9999999999
-
-
shared_ptr- 自动销毁所管理的对象,自动释放关联的内存(析构函数)
- 如果是容器中的元素,不用时记得用erase删除
- 如果多个对象共享底层数据(使用动态内存的原因),当某个对象被销毁时,我们不能单方面地销毁底层数据
12.1.2 new & delete
(原文:12.1.2 直接管理内存)
-
直接管理内存的类不能依赖类对象的拷贝、赋值和销毁操作的任何默认定义。(相对于智能指针容易出错)
-
初始化方式
int *p = new int; //默认构造 int *p = new int(); // 值初始化 int *p = new int(5); // 传统构造方式 int *p = new int{5};//列表初始化 string *p = new string(10,'9');//*p为"9999999999",注意'9'是单引号的字符 -
值初始化
-
对于自定义构造函数会执行默认构造函数,默认/值初始化没有差别;
-
而对于内置类型, 建议使用值初始化,而不是默认初始化 。
int *p0 = new int;//默认初始化,*p0的值未定义 int *p1 = new int();//值初始化,*p1=0 string *p2 = new string;//string有默认构造函数,*p="" -
同样,对于自定义类中的那些依赖于编译器合成的默认构造函数的内置类型成员,如果未在类内被初始化,那么它们的值也是未定义的。
-
如果提供了括号包围的初始化器,则可以用auto
auto p = new auto(obj);
-
-
动态分配const对象
//const int *pci = new const int; //错误 const int *pci = new const int(1024); const string *pcs = new const string; // string有默认构造函数,隐式初始化- 类似其他任何 const 对象,一个动态分配的 const 对象必须进行初始化。
- 对于一个定义了默认构造函数的类类型,其const 动态对象可以隐式初始化,而其他类型的对象就必须显式初始化。
- 由于分配的对象是 const 的,new 返回的指针是一个指向const的指针。
-
内存耗尽,会抛出
bab_alloc异常,可以通过定位new的方式阻止其抛出异常#include <new> int *p = new (nothrow) int(); //如果分配失败,返回一个空指针,而不是抛出异常 -
delete
(书本P409~P411)都是在讲delete的用法,并没有特别的知识。需要注意的地方有:-
delete销毁给定的指针指向的对象,并释放其内存
-
delete之后,指针变为空悬指针,最好将指针置为nullptr
-
delete指向数组的指针
auto *p = new string(10, '9'); delete p; auto *p1 = new int[5]; //delete p1;//只会删除数组中的一个元素 delete[] p1; //告诉编译器,将要删除的是数组
-
12.1.3 shared_ptr & new

-
可以使用new通过值初始化的方式构造智能指针
shared_ptr<int> p(new int(42)); -
接受指针参数的智能指针构造函数时explicit的,不能使用隐式转换构造指针指针,有如下几种错误情况:
/*例1*/ shared_ptr<int> p = new int(42);// 错误 /*例2*/ shared_ptr<int> clone(int p){ //return new int(p); // 错误 return shared_ptr<int>(new int(p)); // 正确,显式转换 } /*例3*/ // <-- 不要混用普通指针和智能指针,推荐使用make_shared void process(shared_ptr<int> ptr){} //-------------------- // 错误 int *x = new int(42); //process(x); //错误,不可隐式转换 process(shared_ptr<int>(x)); // 错误。虽然合法,但x在process结束时会被释放 int j = *x; //未定义行为,x已经被释放 //-------------------- //正确的写法 shared_ptr<int> p(new int(42)); process(p); // 引用计数+1 int i = *p; //仍然存在 -
不要混用普通指针和智能指针,推荐使用make_shared。
- 当将一个 shared_ptr 绑定到一个普通指针时,我们就将内存的管理责任交给了这个shared_ptr。一旦这样做了,我们就不应该再使用内置指针来访问 shared_ptr所指向的内存了。如上例3错误写法所示。
- 也不要使用get初始化另一个智能指针或为智能指针赋值——
get()返回内置指针,如果delete了,指针指针就失效了。

-
reset()用一个新的指针赋予一个shared_ptr,常与unique()(注意:是shared_ptr的成员函数,不是unique_ptr<>)一起用,来控制多个shared_ptr共享的对象。shared_ptr<string> a,b; shared_ptr<string> p(new string("x")); a = p, b = p; if(!p.unique()) p.reset(new string(*p)); *p+=string("y"); cout<<*p<<endl; // xy cout<<*a<<endl; //x cout<<*b<<endl; //x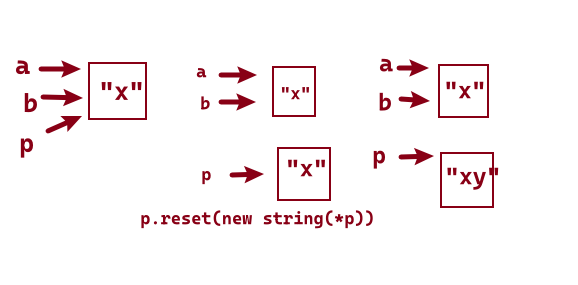
12.1.4 智能指针 & 异常
-
如果在new和delete之间发生了异常,且异常没有在函数内部被捕获,new的内存就永远无法释放了——使用智能指针就不会有这样的问题。
-
智能指针陷阱

-
shared_ptr额外的用法 ——释放哑类(没有析构函数的类)
(书P416)
利用shared_ptr并指定删除器(deleter),当func()退出时(即使由于异常而退出),哑类对象也会被正常关闭struct destination{};//目的ip struct connection{}; connection connect(destination *); void disconnect(connection); // 断开connect连接(析构) //删除器(deleter) void end_disconnect(connection *p /*指向 shared_ptr尖括号中类型 的指针*/){ disconnect(*p); } void func(destination &d){ connection c = connect(&d); // 如果我们在f()退出前没有调用disconnect,就无法关闭c了 // 利用shared_ptr并指定删除器,当f()退出时(即使由于异常而退出),connection也会被正常关闭,如下: shared_ptr<connection> p(&c, end_disconnect); // 第二个参数指定自定义的删除器(指向函数的指针) }
12.1.5 unique_ptr

-
独占、“拥有”
-
初始化unique_ptr必须采用直接初始化形式。
-
不支持普通拷贝和赋值。但是有个例外:可以拷贝或赋值一个将要被销毁的unique_ptr,如
unique_ptr<int> clone(int p){ return unique_ptr<int> (new int(p)); } unique_ptr<int> clone(int p){ unique_ptr<int> ret(new int(p)); return ret; } -
虽然不能拷贝和赋值unique_ptr,但是可以通过调用release或reset将指针的所有权转移(非const)
-
reset(重置)就是将std::unique_ptr指向新的资源。由于std::unique_ptr就是最后一个指向当前资源的智能指针,因此,在重置前需要销毁回收当前的资源。unique_ptr<string> p2(); unique_ptr<string> p3(new string("p3")); p2.reset(p3.release()); // reset释放p2原来的指向的内存,并令p2指向内存 // release返回p3当前指向的内存地址后,令p3 == nullptr -
release函数可以释放所有权,并返回指向std::unique_ptr所管理的资源的指针。- 注意:
release仅仅释放了所有权,并没有销毁回收所管理的资源。而回收内存资源的责任交还给了使用者。
/*例1*/ p2.release(); //错误,p2不会释放内存,并且我们丢失了指针 auto p = p2.release(); // 正确,但要记得手动 delete p /*例2*/ unique_ptr<string> p3(new string("p3")); string *pstr = p3.release(); cout<<*pstr; //终端输出: p3 delete pstr; - 注意:
-
书中示例
unique_ptr<string> p1(new string("p1")); unique_ptr<string> p2(p1.release()); //**release只是将p1置空(p1==nullptr),并没有销毁原来指向的内存** unique_ptr<string> p3(new string("p3")); p2.reset(p3.release()); // reset释放p2原来的指向的内存,并令p2指向内存 -
参考文献
-
-
向unique_ptr传递删除器
-
与shared_ptr不同,需要在
<>指定删除器函数类型unique_ptr<objType,decltype(deleteFunc)*> n(new ObjType, deleteFunc) -
用unique_ptr重写shared_ptr网络连接的例子
struct destination{};//目的ip struct connection{}; connection connect(destination *); void disconnect(connection); // 断开connect连接(析构) //删除器(deleter) void end_disconnect(connection *p /*指向 shared_ptr尖括号中类型 的指针*/){ disconnect(*p); } void func(destination &d){ connection c = connect(&d); // 如果我们在f()退出前没有调用disconnect,就无法关闭c了 // 利用unique_ptr并指定删除器,当f()退出时(即使由于异常而退出),connection也会被正常关闭,如下: unique_ptr<connection,decltype(end_disconnect)*> p(&c, end_disconnect); // 第二个参数指定自定义的删除器(指向函数的指针) }
-
12.1.6 weak_ptr

-
weak_ptr的主要特点
weak_ptr(见表 12.5)是一种不控制所指向对象生存期的智能指针,它指向由一个shared_ptr管理的对象。将一个 weak_ptr 绑定到一个 shared_ptr 不会改变shared_ptr的引用计数。一旦最后一个指向对象的 shared_ptr 被销毁,对象就会被释放。即使有 weak_ptr 指向对象,对象也还是会被释放,因此,weak_ptr 的名字抓住了这种智能指针“弱”共享对象的特点。
-
weak_ptr需要用shared_ptr初始化
auto p = make_shared<int> (42); weak_ptr<int> wp(p); -
调用
lock()以使用weak_ptr- 由于对象可能不存在,我们不能使用weak_ptr直接访问对象,而必须调用
lock()if(shared_ptr<int> np = wp.lock()){ // lock检查weak_ptr指向的对象是否存在; // 如果存在,返回指向共享对象的shared_ptr // 否则返回空 }
- 由于对象可能不存在,我们不能使用weak_ptr直接访问对象,而必须调用
12.2 动态数组
建议使用容器,而不是动态分配的数组
12.2.1 new & 数组
一、两种声明方法
// 声明
// 法1
int *pia = new int[42]; // 必须指定大小,必须是整形,但不一定是常量表达式
// 法2
typedef int arrT[42];
int *p = new arrT ;
-
分配一个数组会得到一个元素类型的指针,分配的内存不是数组类型。
-
不能调用begin和end
-
不能使用范围for
-
原文
分配一个数组会得到一个元素类型的指针
虽然我们通常称 new T[]分配的内存为“动态数组”,但这种叫法某种程度上有些误导。当用 new 分配一个数组时,我们并未得到一个数组类型的对象,而是得到一个数组元素类型的指针。即使我们使用类型别名定义了一个数组类型,new 也不会分配一个数组类型的对象。在上例中,我们正在分配一个数组的事实甚至都是不可见的一一连[num]都没有。new 返回的是一个元素类型的指针。
由于分配的内存并不是一个数组类型,因此不能对动态数组调用 begin 或end(参见3.5.3 节,第106 页)。这些函数使用数组维度(回忆一下,维度是数组类型的一部分)来返回指向首元素和尾后元素的指针。出于相同的原因,也不能用范围 for 语句来处理所谓的)动态数组中的元素。
-
二、初始化
int *pia = new int[42]; // 10个未初始化的int。内置类型未初始化,其中的值是未定义的
int *pia2 = new int[42]();
int *pia3 = new int[10]{0,1,2,3,4,5,6,7,8,9};
string *psa = new string[10]; // 10个值初始化的空stirng,string中有默认构造函数
string *psa2 = new string[10]();
string *psa3 = new string[10]{"a","an","the",string(3,'x')};
-
如果,初始化器中数目大于指定的元素数,new失败,不会分配任何内存,抛出
bad_array_new_length异常(#include <new>) -
虽然我们可用空括号对数组中的元素进行值初始化,但不能在括号中给出初始化器。意味着不能用auto分配数组——笔记12.1.2 new & delete节-->值初始化-->第4小点
-
动态分配一个空数组是合法的
char arr[0]; // 错误,不能定义长度为0的数组 char *cp = new char[0]; //正确,但cp不能解引用。可用于循环的比较操作,如下 /*动态分配一个空数组,用于循环的比较操作*/ size_t n = get_size(); int *p = new int[n]; // n为0,算法依然成立 for(int *q = p; q != p+n; ++q){ /*处理数组*/ }
三、释放动态数组
必须带有方括号,不论是那种初始化形式。例:
int *pia2 = new int[42]();
delete[] pia2;
四、智能指针和动态数组
-
unique_ptr
-
标准库提供了一个 管理new分配的数组的 unique_ptr版本,销毁时将自动调用
delete[]// unique_ptr<int[]> up = new int[10]; //No viable conversion from 'int *' to 'unique_ptr<int[]>' unique_ptr<int[]> up(new int[10]{1,2}); auto p = up.release(); // 书P425说的是销毁其*指针*,而不是说销毁指针指向的元素 cout<<*p; //终端输出: 1 -
也可以使用下标运算符,但不支持 点和箭头 运算符
for(size_t i = 0; i != 10; ++i){ up[i] = i; } -
unique_ptr管理数组的方式汇总

-
-
shared_ptr
shared_ptr不直接支持动态管理数组,需要我们:1)提供删除器;2)使用
get()获取数组首元素指针,以访问数组中的元素。-
提供删除器(否则,shared_ptr将用delete销毁其所指向的对象)
shared_ptr<int> sp(new int[10], [](int *p){ delete[] p; }); sp.reset();// 将调用我们提供的删除器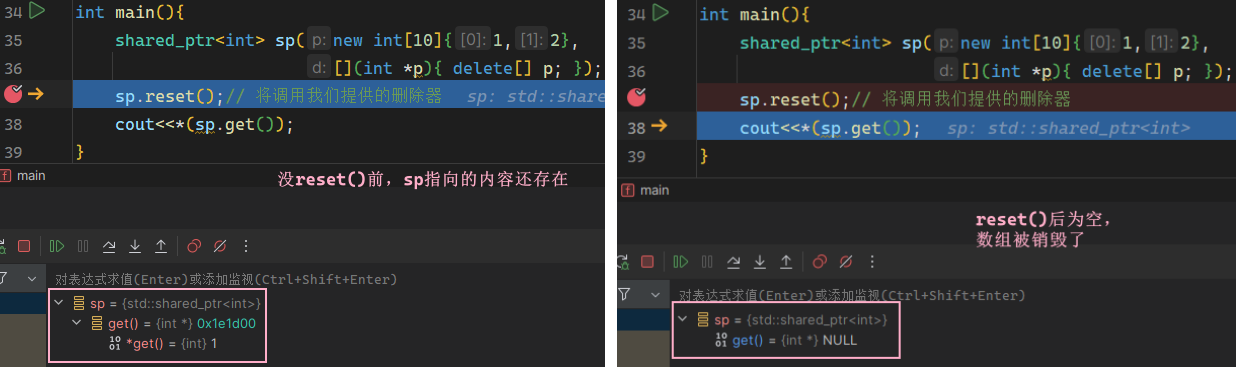
-
使用
get()获取数组首元素指针,以访问数组中的元素for(size_t i = 0; i != 10; ++i){ *(sp.get() + i) = i; // 使用get()获得内置指针 }
-
12.2.2 allocator类
#include <memory>- 目的:先分配内存,在需要的时候再在该内存创建对象。(区别于new等同时分配内存和创建对象)

-
基础用法示例
#include <iostream> #include <memory> using namespace std; int main(){ int n = 5; allocator<string> alloc; // 可以分配string内存的allocator对象 auto const p = alloc.allocate(n); // 分配5个未初始化的string的内存 auto q = p; // q指向构造元素之后的位置 // construct(指向当前要填充位置的指针,...构造函数所需的参数...) alloc.construct(q++); // *q为空字符串 alloc.construct(q++,10,'c'); //*q为"cccccccccc" alloc.construct(q++,"hi"); // *q为"hi" // cout<<*q<<endl;//灾难:q指向未构造的内存,不能在未构造的情况下使用原始内存 cout<<*(q-1)<<endl; //hi // 当我们用完对象后,必须对每个构造的元素调用destroy()销毁 while (q != p) alloc.destroy(--q); // 只能对真正构造了的元素调用destory // 一旦元素销毁,就可以用该内存保存其他的string元素 // 程序结束,释放alloc申请的内存(要先对所有元素destory) alloc.deallocate(p,n); // p必须指向由allocate分配的内存,n必须等于allocate分配的大小 } -
拷贝和填充未初始化的内存

- 书中例子:作为一个例子,假定有一个 int 的 vector,希望将其内容拷贝到动态内存中。我们将分配一块比 vector 中元素所占用空间大一倍的动态内存,然后将原 vector 中的元素拷贝到前一半空间,对后一半空间用一个给定值进行填充:
#include <iostream> #include <memory> using namespace std; #include <vector> int main(){ vector<int> v{0,1,2,3,4}; allocator<int> alloc; auto const p = alloc.allocate(v.size() * 2); auto q = uninitialized_copy(v.begin(),v.end(), p); // p:第三个参数**必须指向未构造的内存** // q:指向最后一个构造的元素之后的位置 q = uninitialized_fill_n(q,v.size(), 42); // 在目的指针(q)指向的内存中创建给定数目(v.size())个对象,用给定的值(42)对他们进行初始化 while(p!=q){ cout<<*(--q)<<" "; //输出: 42 42 42 42 42 4 3 2 1 0 alloc.destroy(q); } alloc.deallocate(q,v.size()*2); return 0; }
- 书中例子:作为一个例子,假定有一个 int 的 vector,希望将其内容拷贝到动态内存中。我们将分配一块比 vector 中元素所占用空间大一倍的动态内存,然后将原 vector 中的元素拷贝到前一半空间,对后一半空间用一个给定值进行填充:
跳过的书中例子的记录
P391 一个单词转换的map
P404 ~ P406 StrBlob类
P420底部 ~ P422 核查指针类 —— 为StrBlob定义一个伴随指针类
P432 ~ P435 文本查询类的定义
------类设计者工具------
十三 拷贝控制
十四 重载运算与类型转换
------高级主题------
标签:const,string,迭代,int,C++,类型,Primer,函数 From: https://www.cnblogs.com/hezexian/p/18012166/cpp_primer_5th