re模块(regular express)(待重构)
-
re模块是 Python 中用于处理正则表达式的标准库。正则表达式是一种强大的字符串匹配和处理工具,通过一种特定的语法来描述字符串的模式。re模块提供了在字符串中进行模式匹配、搜索、替换等操作的功能。
大部分来源于官方文档
正则表达式语法
- 正则表达式(或 RE)指定了一组与之匹配的字符串;模块内的函数可以检查某个字符串是否与给定的正则表达式匹配(或者正则表达式是否匹配到字符串,这两种说法含义相同)。
- 正则表达式可以拼接;如果 A 和 B 都是正则表达式,则 AB 也是正则表达式。通常,如果字符串 p 匹配 A,并且另一个字符串 q 匹配 B,那么 pq 可以匹配 AB。除非 A 或者 B 包含低优先级操作,A 和 B 存在边界条件;或者命名组引用。所以,复杂表达式可以很容易的从这里描述的简单源语表达式构建。更多正则表达式理论和实现,详见 the Friedl book [Frie09] ,或者其他构建编译器的书籍。
- 以下是正则表达式格式的简要说明。更详细的信息和演示,参考 正则表达式指南。
- 正则表达式可以包含普通或者特殊字符。绝大部分普通字符,比如
'A','a', 或者'0',都是最简单的正则表达式。它们就匹配自身。你可以拼接普通字符,所以last匹配字符串'last'. (在这一节的其他部分,我们将用this special style这种方式表示正则表达式,通常不带引号,要匹配的字符串用'in single quotes',单引号形式。) - 有些字符,比如
'|'或者'(',属于特殊字符。 特殊字符既可以表示它的普通含义, 也可以影响它旁边的正则表达式的解释。 - 重复修饰符 (
*,+,?,{m,n}, 等) 不能直接嵌套。这样避免了非贪婪后缀?修饰符,和其他实现中的修饰符产生的多义性。要应用一个内层重复嵌套,可以使用括号。 比如,表达式(?:a{6})*匹配6个'a'字符重复任意次数。
特殊字符有:
-
.(点号) 在默认模式下,匹配除换行符以外的任意字符。 如果指定了旗标
DOTALL,它将匹配包括换行符在内的任意字符。 -
^(插入符) 匹配字符串的开头, 并且在
MULTILINE模式下也匹配换行后的首个符号。 -
$匹配字符串尾或者在字符串尾的换行符的前一个字符,在
MULTILINE模式下也会匹配换行符之前的文本。foo匹配 'foo' 和 'foobar',但正则表达式foo$只匹配 'foo'。 更有趣的是,在'foo1\nfoo2\n'中搜索foo.$,通常匹配 'foo2',但在MULTILINE模式下可以匹配到 'foo1';在'foo\n'中搜索$会找到两个(空的)匹配:一个在换行符之前,一个在字符串的末尾。 -
*对它前面的正则式匹配0到任意次重复, 尽量多的匹配字符串。
ab*会匹配'a','ab',或者'a'后面跟随任意个'b'。 -
+对它前面的正则式匹配1到任意次重复。
ab+会匹配'a'后面跟随1个以上到任意个'b',它不会匹配'a'。 -
?对它前面的正则式匹配0到1次重复。
ab?会匹配'a'或者'ab'。 -
*?,+?,??'*','+',和'?'修饰符都是 贪婪的;它们在字符串进行尽可能多的匹配。有时候并不需要这种行为。如果正则式<.*>希望找到'<a> b <c>',它将会匹配整个字符串,而不仅是'<a>'。在修饰符之后添加?将使样式以 非贪婪方式或者 :dfn:最小 方式进行匹配; 尽量 少 的字符将会被匹配。 使用正则式<.*?>将会仅仅匹配'<a>'。 -
{m}对其之前的正则式指定匹配 m 个重复;少于 m 的话就会导致匹配失败。比如,
a{6}将匹配6个'a', 但是不能是5个。 -
{m,n}对正则式进行 m 到 n 次匹配,在 m 和 n 之间取尽量多。 比如,
a{3,5}将匹配 3 到 5个'a'。忽略 m 意为指定下界为0,忽略 n 指定上界为无限次。 比如a{4,}b将匹配'aaaab'或者1000个'a'尾随一个'b',但不能匹配'aaab'。逗号不能省略,否则无法辨别修饰符应该忽略哪个边界。 -
{m,n}?前一个修饰符的非贪婪模式,只匹配尽量少的字符次数。比如,对于
'aaaaaa',a{3,5}匹配 5个'a',而a{3,5}?只匹配3个'a'。 -
\转义特殊字符(允许你匹配
'*','?', 或者此类其他),或者表示一个特殊序列;特殊序列之后进行讨论。如果你没有使用原始字符串(r'raw')来表达样式,要牢记Python也使用反斜杠作为转义序列;如果转义序列不被Python的分析器识别,反斜杠和字符才能出现在字符串中。如果Python可以识别这个序列,那么反斜杠就应该重复两次。这将导致理解障碍,所以高度推荐,就算是最简单的表达式,也要使用原始字符串。 -
[]用于表示一个字符集合。在一个集合中:字符可以单独列出,比如
[amk]匹配'a','m', 或者'k'。可以表示字符范围,通过用'-'将两个字符连起来。比如[a-z]将匹配任何小写ASCII字符,[0-5][0-9]将匹配从00到59的两位数字,[0-9A-Fa-f]将匹配任何十六进制数位。 如果-进行了转义 (比如[a\-z])或者它的位置在首位或者末尾(如[-a]或[a-]),它就只表示普通字符'-'。特殊字符在集合中会失去其特殊意义。比如[(+*)]只会匹配这几个字面字符之一'(','+','*', or')'。字符类如\w或者\S(如下定义) 在集合内可以接受,它们可以匹配的字符由ASCII或者LOCALE模式决定。不在集合范围内的字符可以通过 取反 来进行匹配。如果集合首字符是'^',所有 不 在集合内的字符将会被匹配,比如[^5]将匹配所有字符,除了'5',[^^]将匹配所有字符,除了'^'.^如果不在集合首位,就没有特殊含义。要在集合内匹配一个']'字面值,可以在它前面加上反斜杠,或是将它放到集合的开头。 例如,[()[\]{}]和[]()[{}]都可以匹配右方括号,以及左方括号,花括号和圆括号。Unicode Technical Standard #18 里的嵌套集合和集合操作支持可能在未来添加。这将会改变语法,所以为了帮助这个改变,一个FutureWarning将会在有多义的情况里被raise,包含以下几种情况,集合由'['开始,或者包含下列字符序列'--','&&','~~', 和'||'。为了避免警告,需要将它们用反斜杠转义。在 3.7 版更改: 如果一个字符串构建的语义在未来会改变的话,一个FutureWarning会raise。 -
|A|B, A 和 B 可以是任意正则表达式,创建一个正则表达式,匹配 A 或者 B. 任意个正则表达式可以用'|'连接。它也可以在组合(见下列)内使用。扫描目标字符串时,'|'分隔开的正则样式从左到右进行匹配。当一个样式完全匹配时,这个分支就被接受。意思就是,一旦 A 匹配成功, B 就不再进行匹配,即便它能产生一个更好的匹配。或者说,'|'操作符绝不贪婪。 如果要匹配'|'字符,使用\|, 或者把它包含在字符集里,比如[|]. -
(...)(组合),匹配括号内的任意正则表达式,并标识出组合的开始和结尾。匹配完成后,组合的内容可以被获取,并可以在之后用
\number转义序列进行再次匹配,之后进行详细说明。要匹配字符'('或者')', 用\(或\), 或者把它们包含在字符集合里:[(],[)]. -
(?…)这是个扩展标记法 (一个
'?'跟随'('并无含义)。'?'后面的第一个字符决定了这个构建采用什么样的语法。这种扩展通常并不创建新的组合;(?P<name>...)是唯一的例外。 以下是目前支持的扩展。 -
(?aiLmsux)(
'a','i','L','m','s','u','x'中的一个或多个) 这个组合匹配一个空字符串;这些字符对正则表达式设置以下标记re.A(只匹配ASCII字符),re.I(忽略大小写),re.L(语言依赖),re.M(多行模式),re.S(点dot匹配全部字符),re.U(Unicode匹配), andre.X(冗长模式)。 (这些标记在 模块内容 中描述) 如果你想将这些标记包含在正则表达式中,这个方法就很有用,免去了在re.compile()中传递 flag 参数。标记应该在表达式字符串首位表示。 -
(?:…)正则括号的非捕获版本。 匹配在括号内的任何正则表达式,但该分组所匹配的子字符串 不能 在执行匹配后被获取或是之后在模式中被引用。
-
(?aiLmsux-imsx:…)(
'a','i','L','m','s','u','x'中的0或者多个, 之后可选跟随'-'在后面跟随'i','m','s','x'中的一到多个 .) 这些字符为表达式的其中一部分 设置 或者 去除 相应标记re.A(只匹配ASCII),re.I(忽略大小写),re.L(语言依赖),re.M(多行),re.S(点匹配所有字符),re.U(Unicode匹配), andre.X(冗长模式)。(标记描述在 模块内容 .)'a','L'and'u'作为内联标记是相互排斥的, 所以它们不能结合在一起,或者跟随'-'。 当他们中的某个出现在内联组中,它就覆盖了括号组内的匹配模式。在Unicode样式中,(?a:...)切换为 只匹配ASCII,(?u:...)切换为Unicode匹配 (默认). 在byte样式中(?L:...)切换为语言依赖模式,(?a:...)切换为 只匹配ASCII (默认)。这种方式只覆盖组合内匹配,括号外的匹配模式不受影响。3.6 新版功能.**在 3.7 版更改: 符号'a','L'和'u'同样可以用在一个组合内。 -
(?P<name>…)(命名组合)类似正则组合,但是匹配到的子串组在外部是通过定义的 name 来获取的。组合名必须是有效的Python标识符,并且每个组合名只能用一个正则表达式定义,只能定义一次。一个符号组合同样是一个数字组合,就像这个组合没有被命名一样。命名组合可以在三种上下文中引用。如果样式是
(?P<quote>['"]).*?(?P=quote)(也就是说,匹配单引号或者双引号括起来的字符串):引用组合 "quote" 的上下文引用方法在正则式自身内(?P=quote)(如示)\1处理匹配对象 mm.group('quote')``m.end('quote')(等)传递到re.sub()里的 repl 参数中\g<quote>``\g<1>``\1 -
(?P=name)反向引用一个命名组合;它匹配前面那个叫 name 的命名组中匹配到的串同样的字串。
-
(?#…)注释;里面的内容会被忽略。
-
(?=…)当
…匹配时,匹配成功,但不消耗字符串中的任何字符。这个叫做 前视断言 (lookahead assertion)。比如,Isaac (?=Asimov)将会匹配'Isaac ',仅当其后紧跟'Asimov'。 -
(?!…)当
…不匹配时,匹配成功。这个叫 否定型前视断言 (negative lookahead assertion)。例如,Isaac (?!Asimov)将会匹配'Isaac ',仅当它后面 不是'Asimov'。 -
(?<=…)如果
...的匹配内容出现在当前位置的左侧,则匹配。这叫做 肯定型后视断言 (positive lookbehind assertion)。(?<=abc)def将会在'abcdef'中找到一个匹配,因为后视会回退3个字符并检查内部表达式是否匹配。内部表达式(匹配的内容)必须是固定长度的,意思就是abc或a|b是允许的,但是a*和a{3,4}不可以。注意,以肯定型后视断言开头的正则表达式,匹配项一般不会位于搜索字符串的开头。很可能你应该使用search()函数,而不是match()函数:>>>>>> import re >>> m = re.search('(?<=abc)def', 'abcdef') >>> m.group(0) 'def'这个例子搜索一个跟随在连字符后的单词:>>>>>> m = re.search(r'(?<=-)\w+', 'spam-egg') >>> m.group(0) 'egg'在 3.5 版更改: 添加定长组合引用的支持。 -
(?<!…)如果
...的匹配内容没有出现在当前位置的左侧,则匹配。这个叫做 否定型后视断言 (negative lookbehind assertion)。类似于肯定型后视断言,内部表达式(匹配的内容)必须是固定长度的。以否定型后视断言开头的正则表达式,匹配项可能位于搜索字符串的开头。 -
(?(id/name)yes-pattern|no-pattern)如果给定的 id 或 name 存在,将会尝试匹配
yes-pattern,否则就尝试匹配no-pattern,no-pattern可选,也可以被忽略。比如,(<)?(\w+@\w+(?:\.\w+)+)(?(1)>|$)是一个email样式匹配,将匹配'<user@host.com>'或'user@host.com',但不会匹配'<user@host.com',也不会匹配'user@host.com>'。
由 '\' 和一个字符组成的特殊序列在以下列出。 如果普通字符不是ASCII数位或者ASCII字母,那么正则样式将匹配第二个字符。比如,\$ 匹配字符 '$'.
-
\number匹配数字代表的组合。每个括号是一个组合,组合从1开始编号。比如
(.+) \1匹配'the the'或者'55 55', 但不会匹配'thethe'(注意组合后面的空格)。这个特殊序列只能用于匹配前面99个组合。如果 number 的第一个数位是0, 或者 number 是三个八进制数,它将不会被看作是一个组合,而是八进制的数字值。在'['和']'字符集合内,任何数字转义都被看作是字符。 -
\A只匹配字符串开始。
-
\b匹配空字符串,但只在单词开始或结尾的位置。一个单词被定义为一个单词字符的序列。注意,通常
\b定义为\w和\W字符之间,或者\w和字符串开始/结尾的边界, 意思就是r'\bfoo\b'匹配'foo','foo.','(foo)','bar foo baz'但不匹配'foobar'或者'foo3'。默认情况下,Unicode字母和数字是在Unicode样式中使用的,但是可以用ASCII标记来更改。如果LOCALE标记被设置的话,词的边界是由当前语言区域设置决定的,\b表示退格字符,以便与Python字符串文本兼容。 -
\B匹配空字符串,但 不 能在词的开头或者结尾。意思就是
r'py\B'匹配'python','py3','py2', 但不匹配'py','py.', 或者'py!'.\B是\b的取非,所以Unicode样式的词语是由Unicode字母,数字或下划线构成的,虽然可以用ASCII标志来改变。如果使用了LOCALE标志,则词的边界由当前语言区域设置。 -
\d对于 Unicode (str) 样式:匹配任何Unicode十进制数(就是在Unicode字符目录[Nd]里的字符)。这包括了
[0-9],和很多其他的数字字符。如果设置了ASCII标志,就只匹配[0-9]。对于8位(bytes)样式:匹配任何十进制数,就是[0-9]。 -
\D匹配任何非十进制数字的字符。就是
\d取非。 如果设置了ASCII标志,就相当于[^0-9]。 -
\s对于 Unicode (str) 样式:匹配任何Unicode空白字符(包括
[ \t\n\r\f\v],还有很多其他字符,比如不同语言排版规则约定的不换行空格)。如果ASCII被设置,就只匹配[ \t\n\r\f\v]。对于8位(bytes)样式:匹配ASCII中的空白字符,就是[ \t\n\r\f\v]。 -
\S匹配任何非空白字符。就是
\s取非。如果设置了ASCII标志,就相当于[^ \t\n\r\f\v]。 -
\w对于 Unicode (str) 样式:匹配 Unicode 单词类字符;这包括字母数字字符 (如
str.isalnum()所定义的) 以及下划线 (_)。 如果使用了ASCII旗标,则将只匹配[a-zA-Z0-9_]。对于8位(bytes)样式:匹配ASCII字符中的数字和字母和下划线,就是[a-zA-Z0-9_]。如果设置了LOCALE标记,就匹配当前语言区域的数字和字母和下划线。 -
\W匹配非单词字符的字符。这与
\w正相反。如果使用了ASCII旗标,这就等价于[^a-zA-Z0-9_]。如果使用了LOCALE旗标,则会匹配当前区域中既非字母数字也非下划线的字符。 -
\Z只匹配字符串尾。
绝大部分Python的标准转义字符也被正则表达式分析器支持。:
\a \b \f \n
\N \r \t \u
\U \v \x \\
(注意 \b 被用于表示词语的边界,它只在字符集合内表示退格,比如 [\b] 。)
'\u', '\U' 和 '\N' 转义序列只在 Unicode 模式中可被识别。 在 bytes 模式中它们会导致错误。 未知的 ASCII 字母转义序列保留在未来使用,会被当作错误来处理。
常用正则表达式
| 场景 | 正则表达式 |
|---|---|
| 用户名 | ^[a-z0-9_-]{3,16}$ |
| 密码 | ^[a-z0-9_-]{6,18}$ |
| 手机号码 | ^(?:\+86)?1[3-9]\d{9}$ |
| 颜色的十六进制值 | ^#?([a-f0-9] |
| 电子邮箱 | ^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+\.[a-z]+$ |
| URL | ^(?:https:// |
| IP 地址 | ((2[0-4]\d |
| HTML 标签 | ^<([a-z]+)([^<]+)*(?:>(.*)<\/\1> |
| utf-8编码下的汉字范围 | ^[\u2E80-\u9FFF]+$ |
以下为个人整理的,但是写的很乱,又不想删,待重构中
【一】导入
- 当你需要判断手机号是否符合格式时
- 判断手机号是否是11位数字
- 判断手机号开头是否是国内运营商
phone_number = input("请输入手机号:").strip()
# 1. 手机号需要是纯数字
if phone_number.isdigit():
# 2. 手机号必须是11位 '1111111111' 11
if len(phone_number) == 11:
# 3. 必须是13、15、16、18等开头
if phone_number.startswith('13') or phone_number.startswith('15') or phone_number.startswith('16') or phone_number.startswith('19'):
print('格式合法')
else:
print('请输入合法的手机号')
else:
print('请输入11位的手机号码,请核对之后在输入')
else:
print('手机号必须输入是纯数字的,请从新输入')
- 使用正则就可以帮我们做到字符串的判断
import re
phone_number = input('please input your phone number : ')
if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
# re.match()就是re模块中的方法,第一个参数就是正则表达式,第二个是需要判断的string
print('是合法的手机号码')
else:
print('不是合法的手机号码')
【二】正则表达式
【1】语法
(1)元字符
- 大多数字母和符号都会简单地匹配自身。例如,正则表达式
test将会精确地匹配到test。 - 但该规则有例外。有些字符是特殊的 元字符(metacharacters),并不匹配自身。事实上,它们表示匹配一些非常规的内容,或者通过重复它们或改变它们的含义来影响正则的其他部分。
- 这是元字符的完整列表。
| . ^ $ * + ? { } [ ] \ |
|---|
| 元字符 | 含义概要 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| 重复n次 | |
| 重复n次或更多次 | |
| 重复n到m次 | |
| [] | 字符组、字符类 |
| \ | 反斜杠 |
字符类[]
- 首先介绍的元字符是
[和]。这两个元字符用于指定一个字符类,也就是你希望匹配的字符的一个集合。这些字符可以单独地列出,也可以用字符范围来表示(给出两个字符并用'-'分隔)。例如,[abc]将匹配a、b、c之中的任意一个字符;这与[a-c]相同,后者使用一个范围来表达相同的字符集合。如果只想匹配小写字母,则正则表达式将是[a-z]。 - 元字符 (除了
\) 在字符类中是不起作用的。 例如,[akm$]将会匹配以下任一字符'a','k','m'或'$';'$'通常是一个元字符,但在一个字符类中它的特殊性被消除了。 [0-5][0-9]将匹配从00到59的两位数字
| 正则表达式 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| [0123456789] | 8 | True | 在一个字符组里枚举合法的所有字符,字符组里的任意一个字符和"待匹配字符"相同都视为可以匹配 |
| [0123456789] | a | False | 由于字符组中没有"a"字符,所以不能匹配 |
| [0-9] | 7 | True | 也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
| [a-z] | s | True | 同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
| [A-Z] | B | True | [A-Z]就表示所有的大写字母 |
| [0-9a-fA-F] | e | True | 可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
| [0-9a-zA-Z] | G | True | 可以匹配数字0-9,可以匹配小写字母,可以匹配大写字母,用来验证除特殊字符外的字符 |
当^在字符类中含义是取反
- 你可以通过对集合 取反 来匹配字符类中未列出的字符。方法是把
'^'放在字符类的最开头。 例如,[^5]将匹配除'5'之外的任何字符。 如果插入符出现在字符类的其他位置,则它没有特殊含义。 例如:[5^]将匹配'5'或'^'。
反斜杠\
转义符\
- 在集合内匹配一个
']'字面值,可以在它前面加上反斜杠,或是将它放到集合的开头。 例如,[()[\]{}]和[]()[{}]都可以匹配右方括号,以及左方括号,花括号和圆括号。 - 如果
-进行了转义 (比如[a\-z])或者它的位置在首位或者末尾(如[-a]或[a-]),它就只表示普通字符'-'。
特殊序列\w等
- 一些以
'\'开头的特殊序列表示预定义的字符集合,这些字符集通常很有用,例如数字集合、字母集合或非空白字符集合。 - 让我们举一个例子:
\w匹配任何字母数字字符。 如果正则表达式以 bytes 类型表示,\w相当于字符类[a-zA-Z0-9_]。如果正则表达式是 str 类型,\w将匹配由unicodedata模块提供的 Unicode 数据库中标记为字母的所有字符。 通过在编译正则表达式时提供re.ASCII标志,可以在 str 表达式中使用较为狭窄的\w定义。 - 以下为特殊序列的不完全列表。 有关 Unicode 字符串正则表达式的序列和扩展类定义的完整列表,参见标准库参考中 正则表达式语法 的最后一部分 。通常,Unicode 版本的字符类会匹配 Unicode 数据库的相应类别中的任何字符。
| 元字符 | 匹配内容 | |
|---|---|---|
| \w | 匹配任何字母与数字字符 | 等价于字符类 [a-zA-Z0-9_] |
| \W | 匹配任何非字母与数字字符 | 等价于字符类 [^a-zA-Z0-9_] |
| \s | 匹配任何空白字符 | 等价于字符类 [ \t\n\r\f\v] |
| \S | 匹配任何非空白字符 | 等价于字符类 [^ \t\n\r\f\v] |
| \d | 匹配任何十进制数字 | 等价于字符类 [0-9] |
| \D | 匹配任何非数字字符 | 等价于字符类 [^0-9] |
- 这些序列可以包含在字符类中。 例如,
[\s,.]是一个匹配任何空白字符、','或'.'的字符类。
量词* + ? {}
* : 重复0次到更多次
- 类似
*这样的重复是 贪婪的 。当重复正则时,匹配引擎将尝试重复尽可能多的次数。 如果表达式的后续部分不匹配,则匹配引擎将回退并以较少的重复次数再次尝试。 - 通过一个逐步示例更容易理解这一点。让我们分析一下表达式
a[bcd]*b。 该表达式首先匹配一个字母'a',接着匹配字符类[bcd]中的零个或更多个字母,最后以一个'b'结尾。 现在想象一下用这个正则来匹配字符串'abcbd'。
| 步骤 | 匹配 | 说明 |
|---|---|---|
| 1 | a |
正则中的 a 匹配成功。 |
| 2 | abcbd |
引擎尽可能多地匹配 [bcd]* ,直至字符串末尾。 |
| 3 | 失败 | 引擎尝试匹配 b ,但是当前位置位于字符串末尾,所以匹配失败。 |
| 4 | abcb |
回退,让 [bcd]* 少匹配一个字符。 |
| 5 | 失败 | 再次尝试匹配 b , 但是当前位置上的字符是最后一个字符 'd' 。 |
| 6 | abc |
再次回退,让 [bcd]* 只匹配 bc 。 |
| 6 | abcb |
再次尝试匹配 b 。 这一次当前位置的字符是 'b' ,所以它成功了。 |
- 此时正则表达式已经到达了尽头,并且匹配到了
'abcb'。 这个例子演示了匹配引擎一开始会尽其所能地进行匹配,如果没有找到匹配,它将逐步回退并重试正则的剩余部分,如此往复,直至[bcd]*只匹配零次。如果随后的匹配还是失败了,那么引擎会宣告整个正则表达式与字符串匹配失败。

+ : 重复1次到更多次
+,表示匹配一次或更多次。请注意*与+之间的差别。*表示匹配 零次 或更多次,也就是说它所重复的内容是可以完全不出现的。而+则要求至少出现一次。举一个类似的例子,ca+t可以匹配'cat'( 1 个'a')或'caaat'( 3 个'a'),但不能匹配'ct'。
? : 重复0次或1次
-
``?
表示匹配一次或零次。你可以认为它把内容变成了可选的。例如,home-?brew可以 匹配'homebrew'或'home-brew'`。
{ m , n } : 通过参数可以限定次数
-
{m , n }:最少重复 m 次,最多 n 次 -
其中 m 和 n 都不是必填的,缺失的情况下会设定为默认值。缺失 m 会解释为最少重复 0 次 ,缺失 n 则解释为最多重复无限次。
-
{m}: 重复 m 次 -
{n,}:最少重复 n 次,最多无限次
-
-
{0,}等同于*,{1,}等同于+,{0,1}等同于?。
贪婪匹配
- "贪婪匹配"(Greedy Matching)是指正则表达式尽可能多地匹配输入字符串。默认情况下,大多数正则表达式都是贪婪的,即它们尝试匹配尽可能长的字符串。
非贪婪匹配
*?, +?, ?? : 非贪婪匹配
'*', '+',和 '?' 修饰符都是 贪婪的;它们在字符串进行尽可能多的匹配。有时候并不需要这种行为。如果正则式 <.*> 希望找到 '<a> b <c>',它将会匹配整个字符串,而不仅是 '<a>'。在修饰符之后添加 ? 将使样式以非贪婪方式或者最小方式进行匹配; 尽量 少 的字符将会被匹配。 使用正则式 <.*?> 将会仅仅匹配 '<a>'。
{m,n}? :非贪婪匹配
前一个修饰符的非贪婪模式,只匹配尽量少的字符次数。比如,对于 'aaaaaa', a{3,5} 匹配 5个 'a' ,而 a{3,5}? 只匹配3个 'a'。
(2)其他元字符
要讨论的其余一些元字符是 零宽度断言 。 它们不会使解析引擎在字符串中前进一个字符;相反,它们根本不占用任何字符,只是成功或失败。例如,\b 是一个断言,指明当前位置位于字边界;这个位置根本不会被 \b 改变。这意味着永远不应重复零宽度断言,因为如果它们在给定位置匹配一次,它们显然可以无限次匹配。
-
|或者“or”运算符。 如果 A 和 B 是正则表达式,
A|B将匹配任何与 A 或 B 匹配的字符串。|具有非常低的优先级,以便在交替使用多字符字符串时使其合理地工作。Crow|Servo将匹配'Crow'或'Servo',而不是'Cro'、'w'或'S'和'ervo'。要匹配字面'|',请使用\|,或将其括在字符类中,如[|]。 -
^在行的开头匹配。 除非设置了
MULTILINE标志,否则只会在字符串的开头匹配。 在MULTILINE模式下,这也在字符串中的每个换行符后立即匹配。例如,如果你希望仅在行的开头匹配单词From,则要使用的正则^From。:>>>>>> print(re.search('^From', 'From Here to Eternity')) <re.Match object; span=(0, 4), match='From'> >>> print(re.search('^From', 'Reciting From Memory')) None要匹配字面'^',使用\^。 -
$匹配行的末尾,定义为字符串的结尾,或者后跟换行符的任何位置。:>>>
>>> print(re.search('}$', '{block}')) <re.Match object; span=(6, 7), match='}'> >>> print(re.search('}$', '{block} ')) None >>> print(re.search('}$', '{block}\n')) <re.Match object; span=(6, 7), match='}'>以匹配字面'$',使用\$或者将其包裹在一个字符类中,例如[$]。 -
\A仅匹配字符串的开头。 当不在
MULTILINE模式时,\A和^实际上是相同的。 在MULTILINE模式中,它们是不同的:\A仍然只在字符串的开头匹配,但^可以匹配在换行符之后的字符串内的任何位置。 -
\Z只匹配字符串尾。
-
\b字边界。 这是一个零宽度断言,仅在单词的开头或结尾处匹配。 单词被定义为一个字母数字字符序列,因此单词的结尾由空格或非字母数字字符表示。以下示例仅当它是一个完整的单词时匹配
class;当它包含在另一个单词中时将不会匹配。>>>>>> p = re.compile(r'\bclass\b') >>> print(p.search('no class at all')) <re.Match object; span=(3, 8), match='class'> >>> print(p.search('the declassified algorithm')) None >>> print(p.search('one subclass is')) None使用这个特殊序列时,你应该记住两个细微之处。 首先,这是 Python 的字符串文字和正则表达式序列之间最严重的冲突。 在 Python 的字符串文字中,\b是退格字符,ASCII 值为8。 如果你没有使用原始字符串,那么 Python 会将\b转换为退格,你的正则不会按照你的预期匹配。 以下示例与我们之前的正则看起来相同,但省略了正则字符串前面的'r'。:>>>>>> p = re.compile('\bclass\b') >>> print(p.search('no class at all')) None >>> print(p.search('\b' + 'class' + '\b')) <re.Match object; span=(0, 7), match='\x08class\x08'>其次,在一个字符类中,这个断言没有用处,\b表示退格字符,以便与 Python 的字符串文字兼容。 -
\B另一个零宽度断言,这与
\b相反,仅在当前位置不在字边界时才匹配。
(3)分组匹配
分组
通常,你需要获取更多信息,而不仅仅是正则是否匹配。 正则表达式通常用于通过将正则分成几个子组来解析字符串,这些子组匹配不同的感兴趣组件。 例如,RFC-822 标题行分为标题名称和值,用 ':' 分隔,如下所示:
From: author@example.com
User-Agent: Thunderbird 1.5.0.9 (X11/20061227)
MIME-Version: 1.0
To: editor@example.com
这可以通过编写与整个标题行匹配的正则表达式来处理,并且具有与标题名称匹配的一个组,以及与标题的值匹配的另一个组。
组由 '(',')' 元字符标记。 '(' 和 ')' 与数学表达式的含义大致相同;它们将包含在其中的表达式组合在一起,你可以使用重复限定符重复组的内容,例如 *,+,? 或 {m,n}。 例如,(ab)* 将匹配 ab 的零次或多次重复。:
>>> p = re.compile('(ab)*')
>>> print(p.match('ababababab').span())
(0, 10)
用 '(',')' 表示的组也捕获它们匹配的文本的起始和结束索引;这可以通过将参数传递给 group()、start()、end() 以及 span()。 组从 0 开始编号。组 0 始终存在;它表示整个正则,所以 匹配对象 方法都将组 0 作为默认参数。 稍后我们将看到如何表达不捕获它们匹配的文本范围的组。:
>>> p = re.compile('(a)b')
>>> m = p.match('ab')
>>> m.group()
'ab'
>>> m.group(0)
'ab'
子组从左到右编号,从 1 向上编号。 组可以嵌套;要确定编号,只需计算从左到右的左括号字符。:
>>> p = re.compile('(a(b)c)d')
>>> m = p.match('abcd')
>>> m.group(0)
'abcd'
>>> m.group(1)
'abc'
>>> m.group(2)
'b'
group() 可以一次传递多个组号,在这种情况下,它将返回一个包含这些组的相应值的元组。:
>>> m.group(2,1,2)
('b', 'abc', 'b')
groups() 方法返回一个元组,其中包含所有子组的字符串,从1到最后一个子组。:
>>> m.groups()
('abc', 'b')
模式中的后向引用允许你指定还必须在字符串中的当前位置找到先前捕获组的内容。 例如,如果可以在当前位置找到组 1 的确切内容,则 \1 将成功,否则将失败。 请记住,Python 的字符串文字也使用反斜杠后跟数字以允许在字符串中包含任意字符,因此正则中引入反向引用时务必使用原始字符串。
例如,以下正则检测字符串中重复的单词。:
>>> p = re.compile(r'\b(\w+)\s+\1\b')
>>> p.search('Paris in the the spring').group()
'the the'
像这样的后向引用通常不仅仅用于搜索字符串 —— 很少有文本格式以这种方式重复数据 —— 但是你很快就会发现它们在执行字符串替换时 非常 有用。
非捕获和命名组
精心设计的正则可以使用许多组,既可以捕获感兴趣的子串,也可以对正则本身进行分组和构建。 在复杂的正则中,很难跟踪组号。 有两个功能可以帮助解决这个问题。 它们都使用常用语法进行正则表达式扩展,因此我们首先看一下。
Perl 5 以其对标准正则表达式的强大补充而闻名。 对于这些新功能,Perl 开发人员无法选择新的单键击元字符或以 \ 开头的新特殊序列,否则 Perl 的正则表达式与标准正则容易混淆。 例如,如果他们选择 & 作为一个新的元字符,旧的表达式将假设 & 是一个普通字符,并且不会编写 \& 或 [&]。
Perl 开发人员选择的解决方案是使用 (?...) 作为扩展语法。 括号后面紧跟 ? 是一个语法错误,因为 ? 没有什么可重复的,所以这样并不会带来任何兼容性问题。 紧跟在 ? 之后的字符表示正在使用的扩展语法,所以 (?=foo) 是一种语法(一个前视断言)和 (?:foo) 是另一种语法( 包含子表达式 foo 的非捕获组)。
Python 支持一些 Perl 的扩展,并增加了新的扩展语法用于 Perl 的扩展语法。 如果在问号之后的第一个字符为 P,即表明其为 Python 专属的扩展。
现在我们已经了解了一般的扩展语法,我们可以回到简化复杂正则中组处理的功能。
有时你会想要使用组来表示正则表达式的一部分,但是对检索组的内容不感兴趣。 你可以通过使用非捕获组来显式表达这个事实: (?:...),你可以用任何其他正则表达式替换 ...。:
>>> m = re.match("([abc])+", "abc")
>>> m.groups()
('c',)
>>> m = re.match("(?:[abc])+", "abc")
>>> m.groups()
()
除了你无法检索组匹配内容的事实外,非捕获组的行为与捕获组完全相同;你可以在里面放任何东西,用重复元字符重复它,比如 *,然后把它嵌入其他组(捕获或不捕获)。 (?:...) 在修改现有模式时特别有用,因为你可以添加新组而不更改所有其他组的编号方式。 值得一提的是,捕获和非捕获组之间的搜索没有性能差异;两种形式没有一种更快。
更重要的功能是命名组:不是通过数字引用它们,而是可以通过名称引用组。
命名组的语法是Python特定的扩展之一: (?P<name>...)。 name 显然是该组的名称。 命名组的行为与捕获组完全相同,并且还将名称与组关联。 处理捕获组的 匹配对象 方法都接受按编号引用组的整数或包含所需组名的字符串。 命名组仍然是给定的数字,因此你可以通过两种方式检索有关组的信息:
>>> p = re.compile(r'(?P<word>\b\w+\b)')
>>> m = p.search( '(((( Lots of punctuation )))' )
>>> m.group('word')
'Lots'
>>> m.group(1)
'Lots'
此外,你可以通过 groupdict() 将命名分组提取为一个字典:
>>> m = re.match(r'(?P<first>\w+) (?P<last>\w+)', 'Jane Doe')
>>> m.groupdict()
{'first': 'Jane', 'last': 'Doe'}
命名分组很方便因为它们让你可以使用容易记忆的名称,而不必记忆数字。 下面是一个来自 imaplib 模块的正则表达式示例:
InternalDate = re.compile(r'INTERNALDATE "'
r'(?P<day>[ 123][0-9])-(?P<mon>[A-Z][a-z][a-z])-'
r'(?P<year>[0-9][0-9][0-9][0-9])'
r' (?P<hour>[0-9][0-9]):(?P<min>[0-9][0-9]):(?P<sec>[0-9][0-9])'
r' (?P<zonen>[-+])(?P<zoneh>[0-9][0-9])(?P<zonem>[0-9][0-9])'
r'"')
检索 m.group('zonem') 显然要容易得多,而不必记住检索第 9 组。
表达式中的后向引用语法,例如 (...)\1,指的是组的编号。 当然有一种变体使用组名而不是数字。 这是另一个 Python 扩展: (?P=name) 表示在当前点再次匹配名为 name 的组的内容。 用于查找重复单词的正则表达式,\b(\w+)\s+\1\b 也可以写为 \b(?P<word>\w+)\s+(?P=word)\b:
>>> p = re.compile(r'\b(?P<word>\w+)\s+(?P=word)\b')
>>> p.search('Paris in the the spring').group()
'the the'
(4)断言
前视断言
另一个零宽断言是前视断言。 前视断言有肯定型和否定型两种形式,如下所示:
-
(?=…)肯定型前视断言。如果内部的表达式(这里用
...来表示)在当前位置可以匹配,则匹配成功,否则匹配失败。 但是,内部表达式尝试匹配之后,正则引擎并不会向前推进;正则表达式的其余部分依然会在断言开始的地方尝试匹配。 -
(?!…)否定型前视断言。 与肯定型断言正好相反,如果内部表达式在字符串中的当前位置 不 匹配,则成功。
更具体一些,来看一个前视的实用案例。 考虑用一个简单的表达式来匹配文件名并将其拆分为基本名称和扩展名,以 . 分隔。 例如,在 news.rc 中,news 是基本名称,rc 是文件名的扩展名。
与此匹配的模式非常简单:
.*[.].*$
请注意,. 需要特别处理,因为它是元字符,所以它在字符类中只能匹配特定字符。 还要注意尾随的 $;添加此项以确保扩展名中的所有其余字符串都必须包含在扩展名中。 这个正则表达式匹配 foo.bar、autoexec.bat、sendmail.cf 和 printers.conf。
现在,考虑使更复杂一点的问题;如果你想匹配扩展名不是 bat 的文件名怎么办? 一些错误的尝试:
.*[.][^b].*$ 上面的第一次尝试试图通过要求扩展名的第一个字符不是 b 来排除 bat。 这是错误的,因为模式也与 foo.bar 不匹配。
.*[.]([^b]..|.[^a].|..[^t])$
当你尝试通过要求以下一种情况匹配来修补第一个解决方案时,表达式变得更加混乱:扩展的第一个字符不是 b。 第二个字符不 a;或者第三个字符不是 t。 这接受 foo.bar 并拒绝 autoexec.bat,但它需要三个字母的扩展名,并且不接受带有两个字母扩展名的文件名,例如 sendmail.cf。 为了解决这个问题,我们会再次使模式复杂化。
.*[.]([^b].?.?|.[^a]?.?|..?[^t]?)$
在第三次尝试中,第二个和第三个字母都是可选的,以便允许匹配的扩展名短于三个字符,例如 sendmail.cf。
模式现在变得非常复杂,这使得它难以阅读和理解。 更糟糕的是,如果问题发生变化并且你想要将 bat 和 exe 排除为扩展,那么该模式将变得更加复杂和混乱。
否定型前视可以解决所有这些困扰:
.*[.](?!bat$)[^.]*$ 否定型前视意味着:如果表达式 bat 在当前位置不能匹配,则可以接着尝试正则表达式的其余部分;如果 bat$ 能匹配,则整个正则表达式将匹配失败。尾随的 $ 是必需的,以确保可以匹配到像 sample.batch 这样以 bat 开头的文件名。当文件名中有多个点号时, [^.]* 可以确保表达式依然有效。
现在很容易排除另一个文件扩展名;只需在断言中添加它作为替代。 以下模块排除以 bat 或 exe:
.*[.](?!bat$|exe$)[^.]*$
(5)模式修正符
- 模式修正符,也叫正则修饰符,模式修正符就是给正则模式增强或增加功能的。
| 值 | 说明 |
|---|---|
| re.I | 是匹配对大小写不敏感 |
| re.L | 做本地化识别匹配 |
| re.M | 多行匹配,影响到^和$ |
| re.S | 使.匹配包括换行符在内的所有字符 |
| re.U | 根据Unicode字符集解析字符,影响\w、\W、\b、\B |
| re.X | 通过给予我们功能灵活的格式以便更好的理解正则表达式 |
import re
text = """
<12
>
<x
yz>
<!@#$%>
<1a!#
e2>
<>
"""
result_1 = re.findall("<.*?>", text)
result_2 = re.findall("<.*?>", text, re.S)
print(result_1) # ['<!@#$%>', '<>']
print(result_2) # ['<12\n>', '<x\n yz>', '<!@#$%>', '<1a!#\n e2>', '<>']
【2】Python中正则模块re的常用方法
-
re.compile(pattern, flags=0)将正则表达式的样式编译为一个 正则表达式对象 (正则对象),可以用于匹配,通过这个对象的方法
match(),search()以及其他如下描述。这个表达式的行为可以通过指定 标记 的值来改变。值可以是以下任意变量,可以通过位的OR操作来结合(|操作符)。序列
prog = re.compile(pattern) result = prog.match(string)等价于
result = re.match(pattern, string)如果需要多次使用这个正则表达式的话,使用
re.compile()和保存这个正则对象以便复用,可以让程序更加高效。注解 :通过 re.compile() 编译后的样式,和模块级的函数会被缓存, 所以少数的正则表达式使用无需考虑编译的问题。 -
re.search(pattern, string, flags=0)扫描整个 字符串 找到匹配样式的第一个位置,并返回一个相应的 匹配对象。如果没有匹配,就返回一个
None; 注意这和找到一个零长度匹配是不同的。 -
re.match(pattern, string, flags=0)如果 string 开始的0或者多个字符匹配到了正则表达式样式,就返回一个相应的 匹配对象 。 如果没有匹配,就返回
None;注意它跟零长度匹配是不同的。注意即便是MULTILINE多行模式,re.match()也只匹配字符串的开始位置,而不匹配每行开始。如果你想定位 string 的任何位置,使用search()来替代(也可参考 search() vs. match() ) -
re.fullmatch(pattern, string, flags=0)如果整个 string 匹配到正则表达式样式,就返回一个相应的 匹配对象 。 否则就返回一个
None;注意这跟零长度匹配是不同的。3.4 新版功能. -
re.split(pattern, string, maxsplit=0, flags=0)用 pattern 分开 string 。 如果在 pattern 中捕获到括号,那么所有的组里的文字也会包含在列表里。如果 maxsplit 非零, 最多进行 maxsplit 次分隔, 剩下的字符全部返回到列表的最后一个元素。
>>> re.split(r'\W+', 'Words, words, words.') ['Words', 'words', 'words', ''] >>> re.split(r'(\W+)', 'Words, words, words.') ['Words', ', ', 'words', ', ', 'words', '.', ''] >>> re.split(r'\W+', 'Words, words, words.', 1) ['Words', 'words, words.'] >>> re.split('[a-f]+', '0a3B9', flags=re.IGNORECASE) ['0', '3', '9']如果分隔符里有捕获组合,并且匹配到字符串的开始,那么结果将会以一个空字符串开始。对于结尾也是一样
>>> re.split(r'(\W+)', '...words, words...') ['', '...', 'words', ', ', 'words', '...', '']这样的话,分隔组将会出现在结果列表中同样的位置。样式的空匹配仅在与前一个空匹配不相邻时才会拆分字符串。
>>> re.split(r'\b', 'Words, words, words.') ['', 'Words', ', ', 'words', ', ', 'words', '.'] >>> re.split(r'\W*', '...words...') ['', '', 'w', 'o', 'r', 'd', 's', '', ''] >>> re.split(r'(\W*)', '...words...') ['', '...', '', '', 'w', '', 'o', '', 'r', '', 'd', '', 's', '...', '', '', '']在 3.1 版更改: 增加了可选标记参数。在 3.7 版更改: 增加了空字符串的样式分隔。
-
re.findall(pattern, string, flags=0)返回 pattern 在 string 中的所有非重叠匹配,以字符串列表或字符串元组列表的形式。对 string 的扫描从左至右,匹配结果按照找到的顺序返回。 空匹配也包括在结果中。返回结果取决于模式中捕获组的数量。如果没有组,返回与整个模式匹配的字符串列表。如果有且仅有一个组,返回与该组匹配的字符串列表。如果有多个组,返回与这些组匹配的字符串元组列表。非捕获组不影响结果。
>>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest') ['foot', 'fell', 'fastest'] >>> re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10') [('width', '20'), ('height', '10')]在 3.7 版更改: 非空匹配现在可以在前一个空匹配之后出现了。
-
re.finditer(pattern, string, flags=0)pattern 在 string 里所有的非重复匹配,返回为一个迭代器 iterator 保存了 匹配对象 。 string 从左到右扫描,匹配按顺序排列。空匹配也包含在结果里。在 3.7 版更改: 非空匹配现在可以在前一个空匹配之后出现了。
-
re.sub(pattern, repl, string, count=0, flags=0)返回通过使用 repl 替换在 string 最左边非重叠出现的 pattern 而获得的字符串。 如果样式没有找到,则不加改变地返回 string。 repl 可以是字符串或函数;如为字符串,则其中任何反斜杠转义序列都会被处理。 也就是说,
\n会被转换为一个换行符,\r会被转换为一个回车符,依此类推。 未知的 ASCII 字符转义序列保留在未来使用,会被当作错误来处理。 其他未知转义序列例如\&会保持原样。 向后引用像是\6会用样式中第 6 组所匹配到的子字符串来替换。 例如:>>> re.sub(r'def\s+([a-zA-Z_][a-zA-Z_0-9]*)\s*\(\s*\):', ... r'static PyObject*\npy_\1(void)\n{', ... 'def myfunc():') 'static PyObject*\npy_myfunc(void)\n{'如果 repl 是一个函数,那它会对每个非重复的 pattern 的情况调用。这个函数只能有一个 匹配对象 参数,并返回一个替换后的字符串。比如
>>> def dashrepl(matchobj): ... if matchobj.group(0) == '-': return ' ' ... else: return '-' >>> re.sub('-{1,2}', dashrepl, 'pro----gram-files') 'pro--gram files' >>> re.sub(r'\sAND\s', ' & ', 'Baked Beans And Spam', flags=re.IGNORECASE) 'Baked Beans & Spam'样式可以是一个字符串或者一个 样式对象 。可选参数 count 是要替换的最大次数;count 必须是非负整数。如果省略这个参数或设为 0,所有的匹配都会被替换。 样式的空匹配仅在与前一个空匹配不相邻时才会被替换,所以
sub('x*', '-', 'abxd')返回'-a-b--d-'。在字符串类型的 repl 参数里,如上所述的转义和向后引用中,\g<name>会使用命名组合name,(在(?P<name>…)语法中定义)\g<number>会使用数字组;\g<2>就是\2,但它避免了二义性,如\g<2>0。\20就会被解释为组20,而不是组2后面跟随一个字符'0'。向后引用\g<0>把 pattern 作为一整个组进行引用。在 3.1 版更改: 增加了可选标记参数。在 3.5 版更改: 不匹配的组合替换为空字符串。在 3.6 版更改: pattern 中的未知转义(由'\'和一个 ASCII 字符组成)被视为错误。在 3.7 版更改: repl 中的未知转义(由'\'和一个 ASCII 字符组成)被视为错误。在 3.7 版更改: 样式中的空匹配相邻接时会被替换。 -
re.subn(pattern, repl, string, count=0, flags=0)行为与
sub()相同,但是返回一个元组(字符串, 替换次数).在 3.1 版更改: 增加了可选标记参数。在 3.5 版更改: 不匹配的组合替换为空字符串。 -
re.escape(pattern)转义 pattern 中的特殊字符。如果你想对任意可能包含正则表达式元字符的文本字符串进行匹配,它就是有用的。比如
>>> print(re.escape('https://www.python.org')) https://www\.python\.org >>> legal_chars = string.ascii_lowercase + string.digits + "!#$%&'*+-.^_`|~:" >>> print('[%s]+' % re.escape(legal_chars)) [abcdefghijklmnopqrstuvwxyz0123456789!\#\$%\&'\*\+\-\.\^_`\|\~:]+ >>> operators = ['+', '-', '*', '/', '**'] >>> print('|'.join(map(re.escape, sorted(operators, reverse=True)))) /|\-|\+|\*\*|\*这个函数不能被用于
sub()和subn()的替换字符串,只有反斜杠应该被转义。 例如:>>> digits_re = r'\d+' >>> sample = '/usr/sbin/sendmail - 0 errors, 12 warnings' >>> print(re.sub(digits_re, digits_re.replace('\\', r'\\'), sample)) /usr/sbin/sendmail - \d+ errors, \d+ warnings在 3.3 版更改:
'_'不再被转义。在 3.7 版更改: 只有在正则表达式中具有特殊含义的字符才会被转义。 因此,'!','"','%',"'",',','/',':',';','<','=','>','@'和""` 将不再会被转义。 -
re.purge()清除正则表达式的缓存。
异常
-
exception
re.``error(msg, pattern=None, pos=None)当传递给函数的正则表达式不合法(比如括号不匹配),或者在编译或匹配过程中出现其他错误时,会引发异常。所给字符串不匹配所给模式不会引发异常。异常实例有以下附加属性:
-
msg- 未格式化的错误消息。
-
pattern- 正则表达式的模式串。
-
pos- 编译失败的 pattern 的位置索引(可以是
None)。
- 编译失败的 pattern 的位置索引(可以是
-
lineno- 对应 pos (可以是
None) 的行号。
- 对应 pos (可以是
-
colno- 对应 pos (可以是
None) 的列号。
- 对应 pos (可以是
-
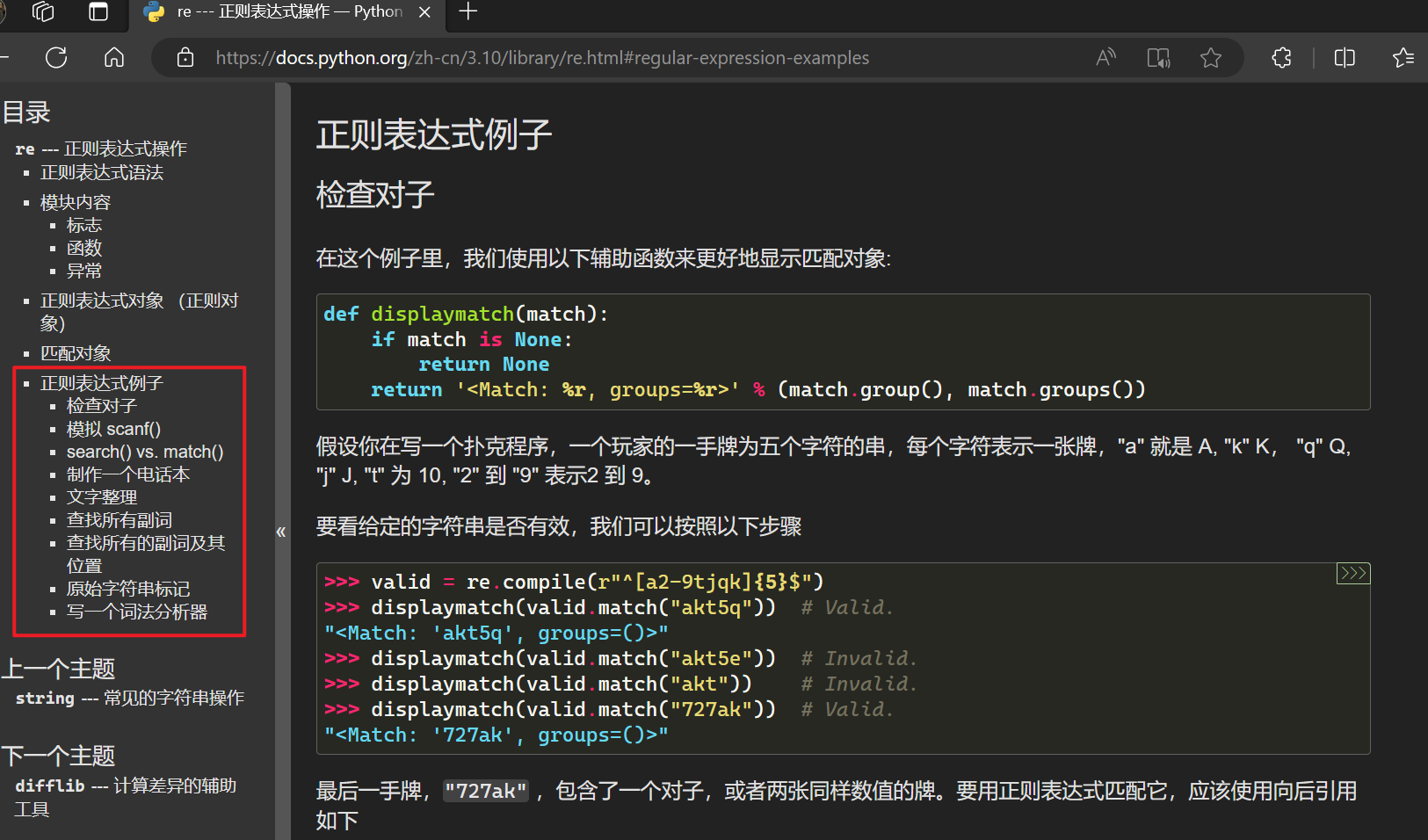
【3】re模块正则表达式例子