代码参照 React 16.13.1
什么是 Diff
在render阶段的beginWork函数中,会将上次更新产生的 Fiber 节点与本次更新的 JSX 对象(对应ClassComponent的this.render方法返回值,或者FunctionComponent执行的返回值)进行比较。根据比较的结果生成workInProgress Fiber,即本次更新的 Fiber 节点。
用通俗的语言讲
React 将上次更新的结果与本次更新的值比较,只将变化的部分体现在 DOM 上
这个比较的过程,就是 Diff。
Diff 的瓶颈以及 React 如何应对
由于 Diff 操作本身也会带来性能损耗,React 文档中提到,即使在最前沿的算法中,将前后两棵树完全比对的算法的复杂程度为 O(n 3 ),其中 n 是树中元素的数量。
如果在 React 中使用了该算法,那么展示 1000 个元素所需要执行的计算量将在十亿的量级范围。这个开销实在是太过高昂。
为了降低算法复杂度,React 的 diff 会预设三个限制:
- 只对同级元素进行 Diff。如果一个 DOM 节点在前后两次更新中跨越了层级,那么 React 不会尝试复用他。
- 两个不同类型的元素会产生出不同的树。如果元素由
div变为p,React 会销毁div及其子孙节点,并新建p及其子孙节点。 - 开发者可以通过
key属性 来暗示哪些子元素在不同的渲染下能保持稳定。考虑如下例子:
// 更新前
<div>
<p key="ka">ka</p>
<h3 key="song">song</h3>
</div>
// 更新后
<div>
<h3 key="song">song</h3>
<p key="ka">ka</p>
</div>
如果没有key,React 会认为div的第一个子节点由p变为h3,第二个子节点由h3变为p。这符合限制 2 的设定,会销毁并新建。
但是当用key指明了节点前后对应关系后,React 知道key === "ka"的p在更新后还存在,所以 DOM 节点可以复用,只是需要交换下顺序。
这就是 React 为了应对算法性能瓶颈做出的三条限制。
Diff 是如何实现的
接下来看看 Diff 的具体实现。从 Diff 的入口函数reconcileChildFibers出发,接着再看看不同类型的 Diff 是如何实现的。
Diff 函数入口函数简介
让稍稍看下 Diff 的入口函数,不要被代码长度吓到喽 ,其实逻辑很简单——在函数内部,会根据newChild类型调用不同的处理函数。
// 根据newChild类型选择不同diff函数处理
function reconcileChildFibers(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChild: any
): Fiber | null {
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
// object类型,可能是 REACT_ELEMENT_TYPE 或 REACT_PORTAL_TYPE
switch (newChild.$typeof) {
case REACT_ELEMENT_TYPE:
// 调用 reconcileSingleElement 处理
// ...其他case
}
}
if (typeof newChild === 'string' || typeof newChild === 'number') {
// 调用 reconcileSingleTextNode 处理
}
if (isArray(newChild)) {
// 调用 reconcileChildrenArray 处理
}
// 一些其他情况调用处理函数
// 以上都没有命中,删除节点
return deleteRemainingChildren(returnFiber, currentFirstChild);
}
这里的newChild参数就是本次更新的 JSX 对象(对应ClassComponent的this.render方法返回值,或者FunctionComponent执行的返回值)
不同类型的 Diff 是如何实现的
可以从同级的节点数量将 Diff 分为两类:
- 当
newChild类型为object、number、string,代表同级只有一个节点 - 当
newChild类型为Array,同级有多个节点
接下来,分别讨论。
情况一:同级只有一个节点的 Diff
对于单个节点,以类型object为例,会进入reconcileSingleElement
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
// 对象类型,可能是 REACT_ELEMENT_TYPE 或 REACT_PORTAL_TYPE
switch (newChild.$typeof) {
case REACT_ELEMENT_TYPE:
// 调用 reconcileSingleElement 处理
// ...其他case
}
}
这个函数会做如下事情:
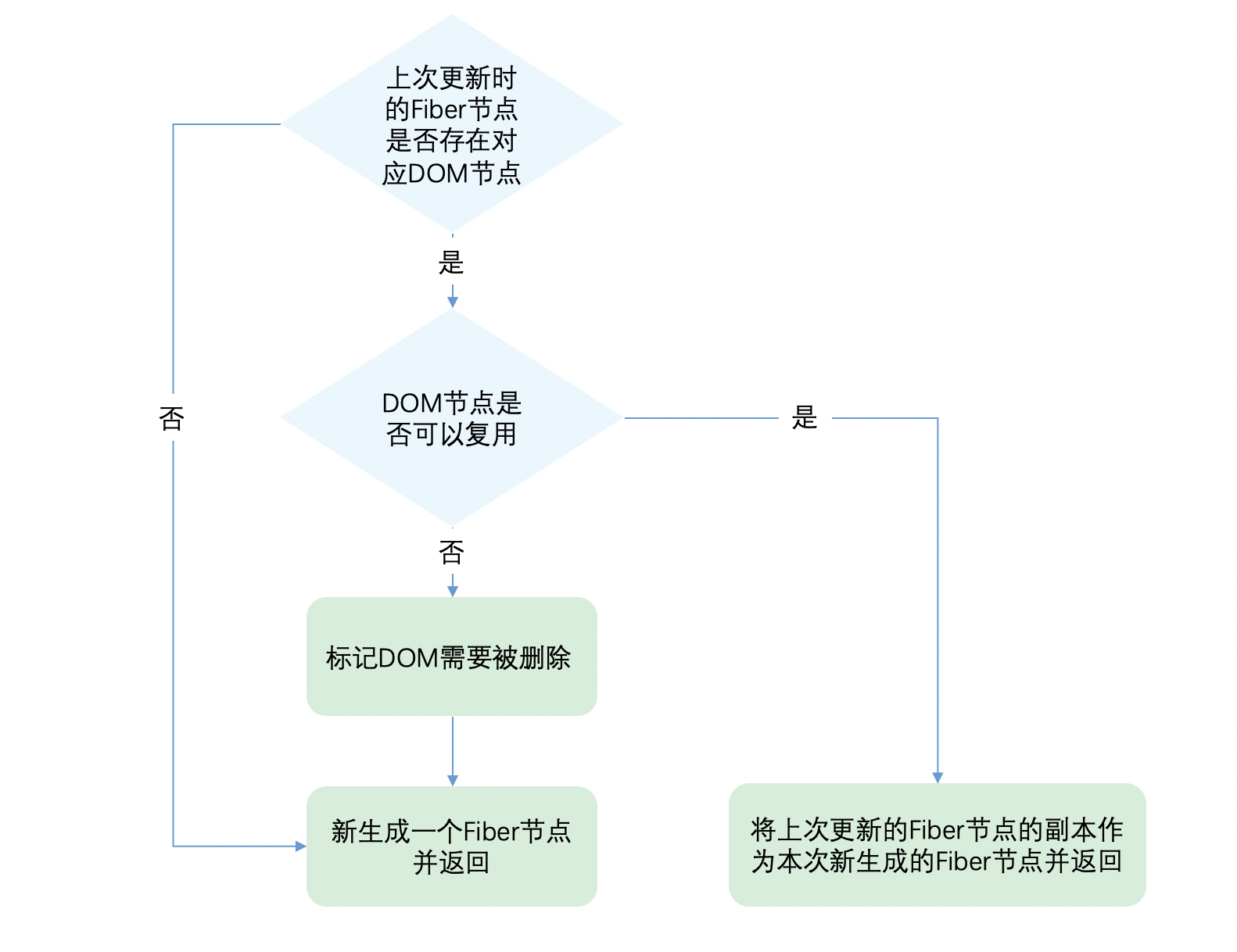
其中第二步判断 DOM 节点是否可以复用,让通过代码看看是如何判断的:
不要怕,逻辑也很简单
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement
): Fiber {
const key = element.key;
let child = currentFirstChild;
// 首先判断是否存在对应DOM节点
while (child !== null) {
// 上一次更新存在DOM节点,接下来判断是否可复用
if (child.key === key) {
// ️同学看这里,首先比较key是否相同
switch (child.tag) {
// ...省略case
default: {
if (child.elementType === element.type) {
// ️同学看这里,key相同后再看type是否相同
// 如果相同则表示可以复用
return existing;
}
// type不同则跳出循环
break;
}
}
// key不同或type不同都代表不能复用,会到这里
// 不能复用的节点,被标记为删除
deleteRemainingChildren(returnFiber, child);
break;
} else {
deleteChild(returnFiber, child);
}
child = child.sibling;
}
// 创建新Fiber,并返回
}
还记得刚才提到的,React 预设的限制么,
从代码可以看出,React 通过先判断key是否相同,如果key相同则判断type是否相同,只有都相同时一个 DOM 节点才能复用。
课间练习题
让来做几道习题巩固下吧:
请判断如下 JSX 对象对应的 DOM 元素是否可以复用:
// 习题1 更新前
<div>ka song</div>
// 更新后
<p>ka song</p>
// 习题2 更新前
<div key="xxx">ka song</div>
// 更新后
<div key="ooo">ka song</div>
// 习题3 更新前
<div key="xxx">ka song</div>
// 更新后
<p key="ooo">ka song</p>
// 习题4 更新前
<div key="xxx">ka song</div>
// 更新后
<div key="xxx">xiao bei</div>
习题 1: 未设置key prop默认 key = null;,所以更新前后 key 相同,都为null,但是更新前type为div,更新后为p,type改变则不能复用。
习题 2: 更新前后key改变,不需要再判断type,不能复用。
习题 3: 更新前后key改变,不需要再判断type,不能复用。
习题 4: 更新前后key与type都未改变,可以复用。children变化,DOM 的子元素需要更新。
情况二:同级有多个元素的 Diff
刚才介绍了单一元素的 Diff,现在考虑有一个FunctionComponent:
function List() {
return (
<ul>
<li key="0">0</li>
<li key="1">1</li>
<li key="2">2</li>
<li key="3">3</li>
</ul>
);
}
他的返回值 JSX 对象的children属性不是单一元素,而是包含四个对象的数组
这种情况下,reconcileChildFibers的newChild参数为Array,在函数内部对应如下情况:
if (isArray(newChild)) {
// 调用 reconcileChildrenArray 处理
}
接下来来看看,React 如何处理同级多个元素的 Diff。
同级多个节点 Diff 详解
整体概括
首先看下,需要处理的情况:
- 情况 1 节点更新
<!-- 情况1 节点更新 -->
<!-- 之前 -->
<ul>
<li key="0" className="before">0<li>
<li key="1">1<li>
</ul>
<!-- 之后情况1 节点属性变化 -->
<ul>
<li key="0" className="after">0<li>
<li key="1">1<li>
</ul>
<!-- 之后情况2 节点类型更新 -->
<ul>
<div key="0">0<li>
<li key="1">1<li>
</ul>
- 情况 2 节点新增或减少
<!-- 情况2 节点新增或减少 -->
<!-- 之前 -->
<ul>
<li key="0">0</li
><li> </li
><li key="1">1</li
><li> </li
></ul>
<!-- 之后情况1 新增节点 -->
<ul>
<li key="0">0</li
><li> </li
><li key="1">1</li
><li> </li
><li key="2">2</li
><li> </li
></ul>
<!-- 之后情况2 删除节点 -->
<ul>
<li key="1">1</li
><li> </li
></ul>
- 情况 3 节点位置变化
<!-- 情况3 节点位置变化 -->
<!-- 之前 -->
<ul>
<li key="0">0</li
><li> </li
><li key="1">1</li
><li> </li
></ul>
<!-- 之后 -->
<ul>
<li key="1">1</li
><li> </li
><li key="0">0</li
><li> </li
></ul>
同一次同级多个元素的 Diff,一定属于以上三种情况中的一种或多种。
该如何设计算法呢
如果让我设计一个 Diff 算法,我首先想到的方案是:
- 判断当前节点的更新属于哪种情况
- 如果是新增,执行新增逻辑
- 如果是删除,执行删除逻辑
- 如果是更新,执行更新逻辑
按这个方案,其实有个隐含的前提——不同操作的优先级是相同的
但 React 团队发现,在日常开发中,相对于增加和删除,更新组件发生的频率更高。所以 React Diff 会优先判断当前节点是否属于更新。
值得注意的是,在做数组相关的算法题时,经常使用双指针从数组头和尾同时遍历以提高效率,但是这里却不行。
虽然本次更新的 JSX 对象newChildren为数组形式,但是和newChildren中每个值进行比较的是上次更新的 Fiber 节点,Fiber 节点的同级节点是由sibling指针链接形成的链表。
即 newChildren[0]与oldFiber比较,newChildren[1]与oldFiber.sibling比较。
单链表无法使用双指针,所以无法对算法使用双指针优化。
基于以上原因,Diff 算法的整体逻辑会经历两轮遍历。
第一轮遍历:处理更新的节点。
第二轮遍历:处理剩下的不属于更新的节点。
第一轮遍历
第一轮遍历步骤如下:
- 遍历
newChildren,i = 0,将newChildren[i]与oldFiber比较,判断 DOM 节点是否可复用。 - 如果可复用,
i++,比较newChildren[i]与oldFiber.sibling是否可复用。可以复用则重复步骤 2。 - 如果不可复用,立即跳出整个遍历。
- 如果
newChildren遍历完或者oldFiber遍历完(即oldFiber.sibling === null),跳出遍历。
当最终完成遍历后,会有两种结果:
结果一: 如果是步骤 3 跳出的遍历,newChildren没有遍历完,oldFiber也没有遍历完。
举个栗子
如下代码中,前 2 个节点可复用,key === 2的节点type改变,不可复用,跳出遍历。
此时oldFiber剩下key === 2未遍历,newChildren剩下key === 2、key === 3未遍历。
<!-- 之前 -->
<li key="0">0</li>
<li key="1">1</li>
<li key="2">2</li>
<!-- 之后 -->
<li key="0">0</li>
<li key="1">1</li>
<div key="2">2</div>
<li key="3">3</li>
结果二: 如果是步骤 4 跳出的遍历,可能newChildren遍历完,或oldFiber遍历完,或他们同时遍历完。
再来个
<!-- 之前 -->
<li key="0" className="a">0</li>
<li key="1" className="b">1</li>
<!-- 之后情况1 newChildren与oldFiber都遍历完 -->
<li key="0" className="aa">0</li>
<li key="1" className="bb">1</li>
<!-- 之后情况2 newChildren没遍历完,oldFiber遍历完 -->
<li key="0" className="aa">0</li>
<li key="1" className="bb">1</li>
<li key="2" className="cc">2</li>
<!-- 之后情况3 newChildren遍历完,oldFiber没遍历完 -->
<li key="0" className="aa">0</li>
带着这两种结果,开始第二轮遍历。
第二轮遍历
对于结果二,聪明的你想一想,newChildren没遍历完,oldFiber遍历完意味着什么?
老的 DOM 节点都复用了,这时还有新加入的节点,意味着本次更新有新节点插入,只需要遍历剩下的newChildren依次执行插入操作(Fiber.effectTag = Placement;)。
同样的,举一反三。newChildren遍历完,oldFiber没遍历完意味着什么?
意味着多余的oldFiber在这次更新中已经不存在了,所以需要遍历剩下的oldFiber,依次执行删除操作(Fiber.effectTag = Deletion;)。
那么结果一怎么处理呢?newChildren与oldFiber都没遍历完,这意味着有节点在这次更新中改变了位置。
接下来,就是 Diff 算法最精髓的部分!!!! 打起精神来,胜利在望
处理位置交换的节点
由于有节点交换了位置,所以不能再用位置索引对比前后的节点,那么怎样才能将同一个节点在两次更新中对应上呢?
你一定想到了,需要用key属性了。
为了快速的找到key对应的oldFiber,将所有还没处理的oldFiber放进以key属性为 key,Fiber为 value 的map。
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
再遍历剩余的newChildren,通过newChildren[i].key就能在existingChildren中找到key相同的oldFiber。
接下来是重点哦,敲黑板
在第一轮和第二轮遍历中,遇到的每一个可以复用的节点,一定存在一个代表上一次更新时该节点状态的oldFiber,并且页面上有一个 DOM 元素与其对应。
那么在 Diff 函数的入口处,定义一个变量
let lastPlacedIndex = 0;
该变量表示当前最后一个可复用节点,对应的oldFiber在上一次更新中所在的位置索引。通过这个变量判断节点是否需要移动。
是不是有点绕, 不要怕,老师的栗子又来啦
这里简化一下书写,每个字母代表一个节点,字母的值代表节点的key
// 之前
abcd
// 之后
acdb
===第一轮遍历开始===
a(之后)vs a(之前)
key不变,可复用
此时 a 对应的oldFiber(之前的a)在之前的数组(abcd)中索引为0
所以 lastPlacedIndex = 0;
继续第一轮遍历...
c(之后)vs b(之前)
key改变,不能复用,跳出第一轮遍历
此时 lastPlacedIndex === 0;
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === cdb,没用完,不需要执行删除旧节点
oldFiber === bcd,没用完,不需要执行插入新节点
将剩余oldFiber(bcd)保存为map
// 当前oldFiber:bcd
// 当前newChildren:cdb
继续遍历剩余newChildren
key === c 在 oldFiber中存在
const oldIndex = c(之前).index;
即 oldIndex 代表当前可复用节点(c)在上一次更新时的位置索引
此时 oldIndex === 2; // 之前节点为 abcd,所以c.index === 2
比较 oldIndex 与 lastPlacedIndex;
如果 oldIndex >= lastPlacedIndex 代表该可复用节点不需要移动
并将 lastPlacedIndex = oldIndex;
如果 oldIndex < lastplacedIndex 该可复用节点之前插入的位置索引小于这次更新需要插入的位置索引,代表该节点需要向右移动
在例子中,oldIndex 2 > lastPlacedIndex 0,
则 lastPlacedIndex = 2;
c节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:bd
// 当前newChildren:db
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
oldIndex 3 > lastPlacedIndex 2 // 之前节点为 abcd,所以d.index === 3
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:b
// 当前newChildren:b
key === b 在 oldFiber中存在
const oldIndex = b(之前).index;
oldIndex 1 < lastPlacedIndex 3 // 之前节点为 abcd,所以b.index === 1
则 b节点需要向右移动
===第二轮遍历结束===
最终acd 3个节点都没有移动,b节点被标记为移动
相信你已经明白了节点移动是如何判断的。如果还有点懵逼,正常的~~ 再看一个栗子~~
// 之前
abcd
// 之后
dabc
===第一轮遍历开始===
d(之后)vs a(之前)
key改变,不能复用,跳出遍历
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === dabc,没用完,不需要执行删除旧节点
oldFiber === abcd,没用完,不需要执行插入新节点
将剩余oldFiber(abcd)保存为map
继续遍历剩余newChildren
// 当前oldFiber:abcd
// 当前newChildren dabc
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
此时 oldIndex === 3; // 之前节点为 abcd,所以d.index === 3
比较 oldIndex 与 lastPlacedIndex;
oldIndex 3 > lastPlacedIndex 0
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:abc
// 当前newChildren abc
key === a 在 oldFiber中存在
const oldIndex = a(之前).index; // 之前节点为 abcd,所以a.index === 0
此时 oldIndex === 0;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 0 < lastPlacedIndex 3
则 a节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:bc
// 当前newChildren bc
key === b 在 oldFiber中存在
const oldIndex = b(之前).index; // 之前节点为 abcd,所以b.index === 1
此时 oldIndex === 1;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 1 < lastPlacedIndex 3
则 b节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:c
// 当前newChildren c
key === c 在 oldFiber中存在
const oldIndex = c(之前).index; // 之前节点为 abcd,所以c.index === 2
此时 oldIndex === 2;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 2 < lastPlacedIndex 3
则 c节点需要向右移动
===第二轮遍历结束===
可以看到,以为从 abcd 变为 dabc,只需要将d移动到前面。
但实际上 React 保持d不变,将abc分别移动到了d的后面。
从这点可以看出,考虑性能,要尽量减少将节点从后面移动到前面的操作。
标签:oldFiber,oldIndex,遍历,React,详解,key,newChildren,diff,节点 From: https://www.cnblogs.com/wp-leonard/p/17888780.html