本文章只是自己面试遇到的问题, C#基础知识。 如达不到个人的需要请留言您的问题。大家共同交流。收藏,以备面试时,快速梳理一下,大脑。

一、基础知识
1.值类型与引用类型
值类型:int、float、char、bool、decimal、struct、enum
引用类型:string、class、object、array、interface、delegate、
2.装箱与拆箱
装箱:把值类型转换成引用类型
拆箱:把引用类型转换成值类型
装箱:对值类型在堆中分配一个对象实例,并将该值复制到新的对象中。
(1)第一步:新分配托管堆内存(大小为值类型实例大小加上一个方法表指针)。
(2)第二步:将值类型的实例字段拷贝到新分配的内存中。
(3)第三步:返回托管堆中新分配对象的地址。这个地址就是一个指向对象的引用了。
拆箱:检查对象实例,确保它是给定值类型的一个装箱值。将该值从实例复制到值类型变量中。
在装箱时是不需要显示的类型转换的,不过拆箱需要显式的类型转换。
3。堆和栈
存放在栈中时要管存储顺序,保持着先进后出的原则,他是一片连续的内存域,有系统自动分配和维护;
堆是无序的,他是一片不连续的内存域,有用户自己来控制和释放,如果用户自己不释放的话,当内存达到一定的特定值时,通过垃圾回收器(GC)来回收。
栈内存无需我们管理,也不受GC管理。
当栈顶元素使用完毕,立马释放。而堆则需要GC清理。
使用引用类型的时候,一般是对指针进行的操作而非引用类型对象本身。但是值类型则操作其本身。
4.GC(Garbage Collection)
当程序需要更多的堆空间时,GC需要进行垃圾清理工作,暂停所有线程,找出所有无被引用的对象,进行清理,并通知栈中的指针重新指向地址排序后的对象。
GC只能处理托管内存资源的释放,对于非托管资源则不能使用GC进行回收,必须由程序员手动回收,例如FileStream或SqlConnection需要调用Dispose进行资源的回收。
5.CLR(Common Language Runtime)
公共语言运行库,负责资源管理(包括内存分配、程序及加载、异常处理、线程同步、垃圾回收等),并保证应用和底层操作系统的分离。
6.静态构造函数
最先被执行的构造函数,且在一个类里只允许有一个无参的静态构造函数
执行顺序: 静态变量 > 静态构造函数 >实例变量 >实例构造函数
7.文件I/O
通过流的方式对文件进行读写操作
(1)FileStream
(2) StreamReader/StreamWriter
8.序列化与反序列化(深拷贝)
序列化:将对象状态转换为可保持或传输的格式的过程。将对象实例的字段及类的名称转换成字节流,然后把字节流写入数据流。
反序列化: 将流转换为对象。
这两个过程结合起来,可以轻松地存储和传输数据。
9.线程同步
(1)方法一:阻塞(调用Sleep() 或 join())
(2) 方法二:加互斥锁Lock
(3) 方法三:信号和句柄(AutoResetEvent/ManualResetEvent,调用Set()和Waitone())
10、抽象类abstract class 与接口 Interface 的异同
相同点:
(1)都可以被继承
(2)都不能被实例化
(3)都可以包含方法的声明
不同点:
(1)抽象类被子类继承; 接口被类实现
(2)抽象类只能被单个类继承;接口可继承接口,并可多继承接口
(3)抽象基类可以定义字段、属性、方法实现;接口只能定义属性、索引器、事件、和方法声明、不能包含字段。
(4)抽象类可以做方法声明,也可做方法实现;接口只能做方法声明
(5)具体派生类必须覆盖(override)抽象基类的抽象方法;派生类必须实现接口的所有方法
(6)抽象类是一个不完整的类,需要进一步细化;接口是一个行为规范
(7)抽象类中的虚方法或抽象方法必须用public修饰;接口中的所有成员默认为public,不能有private修饰符
11、类class与结构体struct的异同
Class属于引用类型,是分配在内存的堆上的;
Struct属于值类型,是分配在内存的栈上的;不能从另外一个结构或者类继承,本身也不能被继承;没有默认的构造函数,但是可以添加构造函数;可以不适用new初始化
12、using关键字的使用场景
(1)作为指令: 用于导入其他命名空间中定义的类型或为命名空间创建别名
(2)作为语句:用于定义一个范围,在此范围的末尾将释放对象
13.new关键字的使用场景
(1)实例化对象
(2)隐藏父类方法
14.委托与事件
委托可以把一个方法作为参数传入另一个方法,可以理解为指向一个函数的引用;
事件是一种特殊的委托。
15.重载(overload)与重写(override)的区别
重载:是方法的名称相同,参数或参数类型不同;重载是面向过程的概念。
重写:是对基类中的虚方法进行重写。重写是面向对象的概念。
16.return执行顺序
try{}里有一个return语句,那么finally{}里的code在return前执行。
17.switch(expression)
其中expression支持任何数据类型,包括null。
18.反射Reflection
动态获取程序集信息。
19.property与attribute的区别
property是属性,用于存取类的字段;
attribute是特性,用来标识类,方法等的附加性质。
20.访问修饰符
(1)public 公有访问,不受任何限制。
(2)private 私有访问,只限于本类成员访问。
(3)protected 保护访问,只限于本类和子类访问。
(4)internal 内部访问,只限于当前程序集内访问。
21、static关键字的应用
对类有意义的字段和方法使用static关键字修饰,称为静态成员,通过类名加访问操作符“.”进行访问; 对类的实例有意义的字段和方法不加static关键字,称为非静态成员或实例成员。
注: 静态字段在内存中只有一个拷贝,非静态字段则是在每个实例对象中拥有一个拷贝。而方法无论是否为静态,在内存中只会有一份拷贝,区别只是通过类名来访问还是通过实例名来访问。
22、文件编码格式
阶段一:ASCII
阶段二:ANSI(本地化) 如:GBK、GB2312
阶段三:UNICODE(国际化) 如:UTF-8
23、值传递与引用传递
值传递时,系统首先为被调用方法的形参分配内存空间,并将实参的值按位置一一对应地复制给形参,此后,被调用方法中形参值得任何改变都不会影响到相应的实参;
引用传递时,系统不是将实参本身的值复制后传递给形参,而是将其引用值(即地址值)传递给形参,因此,形参所引用的该地址上的变量与传递的实参相同,方法体内相应形参值得任何改变都将影响到作为引用传递的实参。
简而言之,按值传递不是值参数是值类型,而是指形参变量会复制实参变量,也就是会在栈上多创建一个相同的变量。而按引用传递则不会。可以通过 ref 和 out 来决定参数是否按照引用传递。
24、参数传递 ref 与 out 的区别
(1)ref指定的参数在函数调用时必须先初始化,而out不用
(2)out指定的参数在进入函数时会清空自己,因此必须在函数内部进行初始化赋值操作,而ref不用
总结:ref可以把值传到方法里,也可以把值传到方法外;out只可以把值传到方法外
注意:string作为特殊的引用类型,其操作是与值类型看齐的,若要将方法内对形参赋值后的结果传递出来,需要加上ref或out关键字。
25、浅克隆与深克隆(浅拷贝与深拷贝)
(1)浅克隆
在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。简单来说,在浅克隆中,当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制,如图:
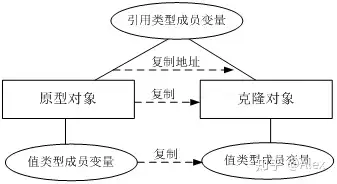
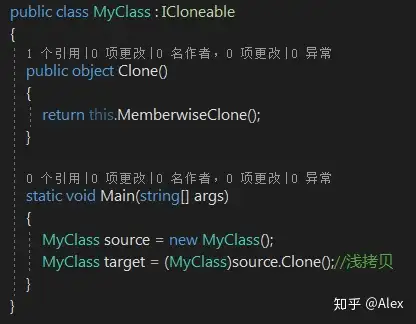
通过实现ICloneable接口的Clone()方法,并调用MemberwiseClone()方法来实现浅克隆
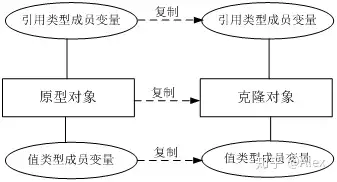
(2)深克隆
在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。简单来说,在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制,如图:
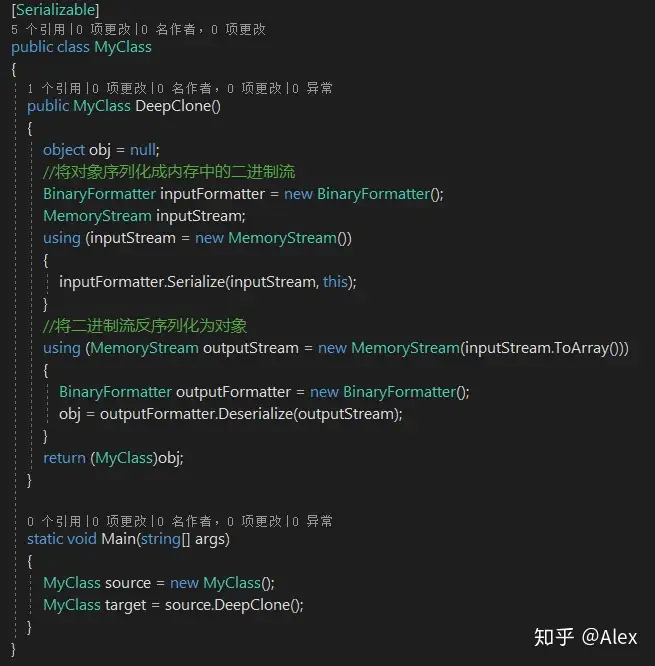
在C#语言中,如果需要实现深克隆,可以通过序列化(Serialization)等方式来实现。序列化就是将对象写到流的过程,写到流中的对象是原有对象的一个拷贝,而原对象仍然存在于内存中。通过序列化实现的拷贝不仅可以复制对象本身,而且可以复制其引用的成员对象,因此通过序列化将对象写到一个流中,再从流里将其读出来,可以实现深克隆。需要注意的是能够实现序列化的对象其类必须实现Serializable接口,否则无法实现序列化操作。
二、数据库
1、数据库操作的相关类
特定类:Connection,Command,CommandBuilder,DataAdapter,DataReader,Parameter,Transaction
共享类:DataSet,DataTable,DataRow,DataColumn,DataRealtion,Constraint,DataColumnMapping,DataTableMapping
(1)Connection:开启程序与数据库之间的连接。
(2)Command:对数据库发送一些指令。例如增删改查等指令,以及调用存在数据库中的存储过程等。
(3)DataAdapter:主要在数据源及DataSet 之间执行传输工作,通过Command 下达命令后,将取得的数据放进DataSet对象中。
(4)DataSet:这个对象可视为一个暂存区(Cache),可以把数据库中所查询到的数据保存起来,甚至可以将整个数据库显示出来,DataSet是放在内存中的。
备注:将DataAdapter对象当做DataSet 对象与数据源间传输数据的桥梁。DataSet包含若干DataTable、DataTableTable包含若干DataRow。
(5)DataReader:一笔向下循序的读取数据源中的数据。
总结:http://ADO.NET 使用Connection对象来连接数据库,使用Command或DataAdapter对象来执行SQL语句,并将执行的结果返回给DataReader或DataAdapter,然后再使用取得的DataReader或DataAdapter对象操作数据结果。
2、事务
3、索引
4、视图
5、存储过程
三、数据结构(常用的排序算法)
1、冒泡排序
(1)原理
(2)实现代码
2、快速排序
(1)原理
(2)实现代码
四、设计模式
1、单例模式
在软件系统中,经常有这样一些特殊的类,必须保证它们在系统中只存在一个实例,才能确保它们的逻辑正确性、以及良好的效率。保证一个类仅有一个实例,并提供一个该实例的全局访问点。
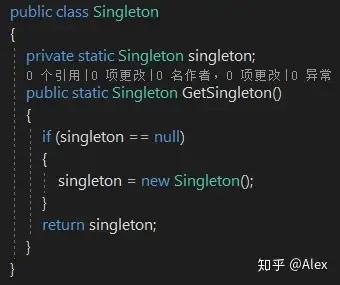
(1)经典模式--单线程
对于线程来说不安全;但在单线程中已满足要求。
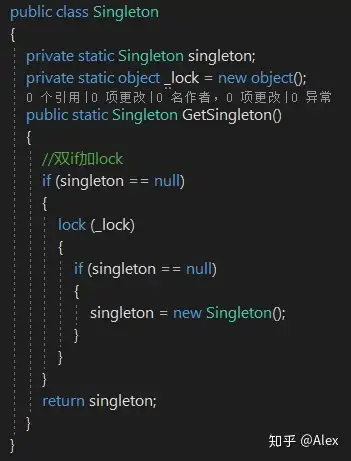
(2)懒汉模式--多线程
多线程安全;线程不是每次都加锁,节省了性能开销。
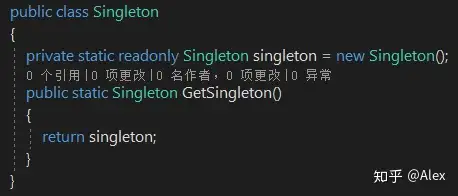
(3)饿汉模式--多线程
利用静态变量去实现单例,由CLR保证,在程序第一次使用该类之前被调用,而且只调用一次;饿汉模式中的静态变量是随着类加载时被完成初始化的,静态代码块也会随着类的加载一块执行,哪怕你一直没有调用。
五、软件开发流程
需求分析 --> 概要设计 --> 详细设计 --> 编码 --> 测试 --> 交付 --> 验收 --> 维护
六、其他(了解)
1、.NET Core 与 .NET Framework 的区别
.NET Core 就是 .NET Framework 的开源且跨平台版本。但微软毕竟不能维护两个不同的分支,一个跑在Windows上,一个跑在Linux(Unix Like)系统上,所以微软抽象出来一个标准库.NET Standard Library,.NET Core 与 .NET Framework 都必须实现标准库的API ,就这样.NET Core、.NET Framework、Xamarin成了三兄弟,分别为不同的平台服务。

标签:面试题,克隆,归纳,C#,对象,实例,引用,类型,方法 From: https://www.cnblogs.com/ZJ-CN/p/17691819.html