Go包介绍与初始化:搞清Go程序的执行次序
目录- Go包介绍与初始化:搞清Go程序的执行次序
一、main.main 函数:Go 应用的入口函数
1.1 main.main 函数
在Go语言中,main函数是任何Go应用的入口函数--用户层入口。当你运行一个Go程序时,操作系统会首先调用main函数,然后程序开始执行。main 函数的函数原型是这样的:
package main
func main() {
// 用户层执行逻辑
... ...
}
你的程序的执行会从main函数开始,会在这个函数内按照它的调用顺序展开。
1.2 main.main 函数特点
main.main函数是Go应用程序的入口函数,它具有一些特点和规定,使得Go程序的执行流程有一定的规范性。以下是关于main.main函数的特点:
- 唯一入口点: 在一个Go应用程序中,只能有一个
main.main函数。这是整个程序的唯一入口点,程序的执行将从这里开始。如果存在多个main函数,编译时会报错。 - 不接受参数:
main.main函数不接受任何参数,它没有输入参数,也没有返回值。这是Go语言的规定,而程序的命令行参数通常通过os.Args等方式获取。
二、包介绍
2.1 包介绍与声明
在Go中,包(Package)是组织和管理代码的基本单元。包包括一组相关的函数、类型和变量,它们可以被导入到其他Go文件中以便重复使用。Go标准库以及第三方库都是以包的形式提供的。
每个Go文件都属于一个包,你可以使用package关键字来指定声明一个文件属于哪个包。例如:
package main
2.2 非 main包的 main 函数
除了 main 包外,其他包也可以拥有自己的名为 main 的函数或方法。但按照 Go 的可见性规则(小写字母开头的标识符为非导出标识符),非 main 包中自定义的 main 函数仅限于包内使用,就像下面代码这样,这是一段在非 main 包中定义 main 函数的代码片段:
package pkg1
import "fmt"
func Main() {
main()
}
func main() {
fmt.Println("main func for pkg1")
}
你可以看到,这里 main 函数就主要是用来在包 pkg1 内部使用的,它是没法在包外使用的。
2.3 包的命名规则
- 在Go语言中,包的名称通常使用小写字母,具有简洁的、描述性的名称。这有助于提高代码的可读性和可维护性。标准库中的包通常具有非常清晰的包名,例如
fmt、math、strings等。 - 在Go语言中,包级别的标识符(变量、函数、类型等)的可见性是由其首字母的大小写来决定的。如果一个标识符以大写字母开头,它就是可导出的(公有的),可以被其他包访问。如果以小写字母开头,它就是包内私有的,只能在包内部使用。
三、包的导入
3.1 包的导入介绍
要在Go程序中使用其他包的功能,你需要导入这些包。使用import关键字来导入包,导入语句通常放在文件的顶部。一个典型的包导入语句的格式如下:
import "包的导入路径"
其中,包的导入路径是指被导入包的唯一标识符,通常是包的名称或路径,它用于告诉Go编译器去哪里找到这个包的代码。
例如,导入标准库中的fmt包可以这样做:
import "fmt"
然后,你就可以在你的程序中使用fmt包提供的函数和类型。
3.2 导入多个包
在Go程序中,你可以一次导入多个包,只需在import语句中列出这些包的导入路径,用括号()括起来并以括号内的方式分隔包的导入路径。
示例:
import (
"fmt"
"math"
"net/http"
)
这个示例中导入了fmt、math和net/http三个包。这种方式使你可以更清晰地组织你的导入语句,以便程序更易读。
注意:Go语言的编译器会自动检测哪些导入的包是真正被使用的,未使用的导入包不会引起编译错误,但通常被视为不良实践。在Go中,未使用的导入包可能会引起代码不清晰,因此应该避免导入不需要的包。
3.2 包的别名
在Go语言中,你可以使用包的别名(package alias)来为一个导入的包赋予一个不同的名称,以便在代码中引用它。包的别名通常用于以下情况:
- 避免包名冲突:当你导入多个包时,有可能出现包名冲突,此时你可以为一个或多个包使用别名来解决冲突。
- 简化包名:有时,包的导入路径可能很长,为了减少代码中的冗长,你可以为包使用一个短的别名。
使用包的别名是非常简单的,只需在导入语句中使用as关键字为包指定一个别名。以下是示例:
import fm "fmt"
在上面的示例中,fm是fmt包的别名。现在,你可以在代码中使用fm来代替fmt,例如:
fm.Println("Hello, World!")
这样,你就可以使用更短的fm来调用fmt包的函数,以减少代码中的冗长。
包的别名可以根据需要自定义,但通常建议选择一个有意义的别名,以使代码更易读。使用别名时要注意避免产生混淆,要确保别名不与其他标识符(如变量名或函数名)发生冲突。
四、神器的下划线
4.1 下划线的作用
下划线 _ 在Go语言中用于以下几个不同的场景:
- 匿名变量:
_可以用作匿名变量,用于忽略某个值。当你希望某个值返回但又不需要使用它时,可以将其赋值给_。 - 空标识符:
_也被称为空标识符,它用于声明但不使用变量或导入包但不使用包的标识符。这是为了确保代码通过编译,但不会产生未使用变量或包的警告。
4.2 下划线在代码中
在代码中,下划线 _ 可以用作匿名变量,用于忽略某个值。这通常在函数多返回值中使用,如果你只关心其中的某些值而不需要其他返回值,可以将其赋值给 _。
示例:
x, _ := someFunction() // 忽略第二个返回值
在上面的示例中,_ 用于忽略 someFunction 函数的第二个返回值。
4.3 下划线在import中
- 当导入一个包时,该包下的文件里所有
init()函数都会被执行,然而,有些时候我们并不需要把整个包都导入进来,仅仅是是希望它执行init()函数而已。 - 这个时候就可以使用
import _引用该包。即使用 import _ 包路径 只是引用该包,仅仅是为了调用init()函数,所以无法通过包名来调用包中的其他函数。
以下是一个示例,演示如何使用 import _ 引用一个包以执行其 init() 函数:
项目结构:
src
|
+--- main.go
|
+--- hello
|
+--- hello.go
main.go 文件
package main
import _ "./hello"
func main() {
// hello.Print()
//编译报错:./main.go:6:5: undefined: hello
}
hello.go 文件
package hello
import "fmt"
func init() {
fmt.Println("imp-init() come here.")
}
func Print() {
fmt.Println("Hello!")
}
输出结果:
imp-init() come here.
五、init 函数:Go 包的初始化函数
5.1 init 函数 介绍
init 函数是在Go包的初始化阶段自动调用的函数。它的目的是执行一些包级别的初始化工作,例如设置变量、初始化数据、连接数据库等。init 函数没有参数,也没有返回值,它的定义形式如下:
func init() {
// 包初始化逻辑
... ...
}
5.2 init 函数 特点
init 函数有以下特点:
- 自动执行:
init函数不需要手动调用,它会在程序启动时自动执行。这确保了包的初始化工作在程序开始执行之前完成。 - 包级别:
init函数是包级别的,因此它只能在包的内部定义。不同包中的init函数互不影响,它们独立执行。 - 多个
init函数: 一个包可以包含多个init函数,它们按照定义的顺序依次执行。被导入的包的init函数会在导入它的包的init函数之前执行。 - 没有参数和返回值: 和前面
main.main函数一样,init函数也是一个无参数无返回值的函数,它只用于执行初始化工作,而不与其他函数交互。 - 顺序执行: 由于
init函数的执行顺序是根据包的导入顺序确定的,因此在编写代码时应该谨慎考虑包的依赖关系,以确保正确的初始化顺序。 - 可用于注册和初始化:
init函数通常用于执行包的初始化工作,也可用于在导入包时注册一些功能,例如数据库驱动程序的注册。
这里要特别注意的是,在 Go 程序中我们不能手工显式地调用 init,否则就会收到编译错误,就像下面这个示例,它表示的手工显式调用 init 函数的错误做法:
package main
import "fmt"
func init() {
fmt.Println("init invoked")
}
func main() {
init()
}
构建并运行上面这些示例代码之后,Go 编译器会报下面这个错误:
$go run call_init.go
./call_init.go:10:2: undefined: init
接着,我们将代码修改如下:
package main
import "fmt"
func init() {
fmt.Println("init invoked")
}
func main() {
fmt.Println("this is main")
}
Go 编译器运行结果如下:
init invoked
this is main
我们看到,在初始化 Go 包时,Go 会按照一定的次序,逐一、顺序地调用这个包的 init 函数。一般来说,先传递给 Go 编译器的源文件中的 init 函数,会先被执行;而同一个源文件中的多个 init 函数,会按声明顺序依次执行。所以说,在Go中,main.main 函数可能并不是第一个被执行的函数。
六、Go 包的初始化次序
6.1 包的初始化次序探究
我们从程序逻辑结构角度来看,Go 包是程序逻辑封装的基本单元,每个包都可以理解为是一个“自治”的、封装良好的、对外部暴露有限接口的基本单元。一个 Go 程序就是由一组包组成的,程序的初始化就是这些包的初始化。每个 Go 包还会有自己的依赖包、常量、变量、init 函数(其中 main 包有 main 函数)等。
在平时开发中,我们在阅读和理解代码的时候,需要知道这些元素在在程序初始化过程中的初始化顺序,这样便于我们确定在某一行代码处这些元素的当前状态。
下面,我们就通过一张流程图,来了解 Go 包的初始化次序:
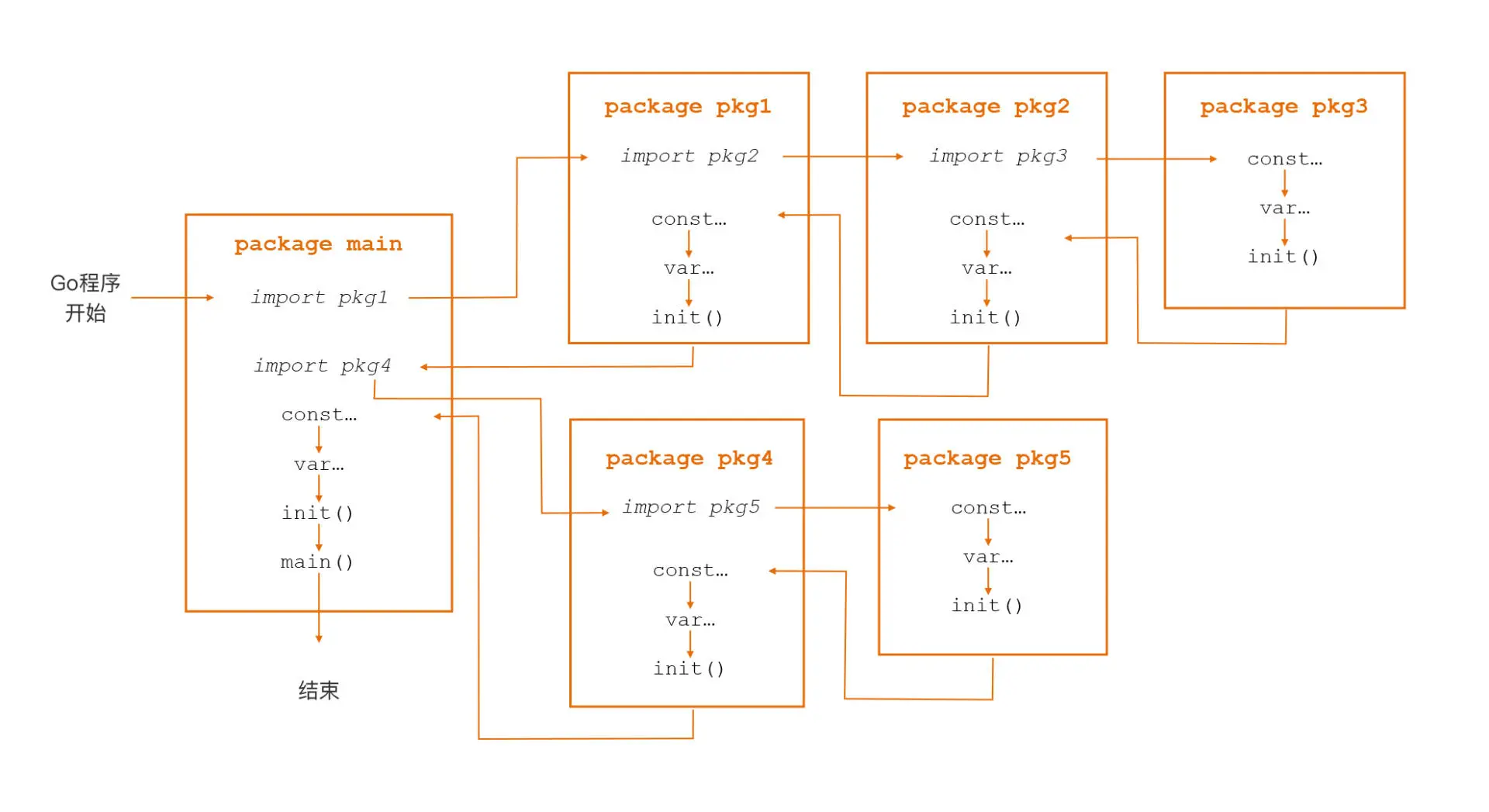
这里,我们来看看具体的初始化步骤。
首先,main 包依赖 pkg1 和 pkg4 两个包,所以第一步,Go 会根据包导入的顺序,先去初始化 main 包的第一个依赖包 pkg1。
第二步,Go 在进行包初始化的过程中,会采用“深度优先”的原则,递归初始化各个包的依赖包。在上图里,pkg1 包依赖 pkg2 包,pkg2 包依赖 pkg3 包,pkg3 没有依赖包,于是 Go 在 pkg3 包中按照“常量 -> 变量 -> init 函数”的顺序先对 pkg3 包进行初始化;
紧接着,在 pkg3 包初始化完毕后,Go 会回到 pkg2 包并对 pkg2 包进行初始化,接下来再回到 pkg1 包并对 pkg1 包进行初始化。在调用完 pkg1 包的 init 函数后,Go 就完成了 main 包的第一个依赖包 pkg1 的初始化。
接下来,Go 会初始化 main 包的第二个依赖包 pkg4,pkg4 包的初始化过程与 pkg1 包类似,也是先初始化它的依赖包 pkg5,然后再初始化自身;
然后,当 Go 初始化完 pkg4 包后也就完成了对 main 包所有依赖包的初始化,接下来初始化 main 包自身。
最后,在 main 包中,Go 同样会按照“常量 -> 变量 -> init 函数”的顺序进行初始化,执行完这些初始化工作后才正式进入程序的入口函数 main 函数。
现在,我们可以通过一段代码示例来验证一下 Go 程序启动后,Go 包的初始化次序是否是正确的,示例程序的结构如下:
prog-init-order
├── main.go
├── pkg1
│ └── pkg1.go
├── pkg2
│ └── pkg2.go
└── pkg3
└── pkg3.go
这里我只列出了 main 包的代码,pkg1、pkg2 和 pkg3 可可以到代码仓库中查看。
package main
import (
"fmt"
_ "gitee.com/tao-xiaoxin/study-basic-go/syntax/prog-init-order/pkg1"
_ "gitee.com/tao-xiaoxin/study-basic-go/syntax/prog-init-order/pkg2"
)
var (
_ = constInitCheck()
v1 = variableInit("v1")
v2 = variableInit("v2")
)
const (
c1 = "c1"
c2 = "c2"
)
func constInitCheck() string {
if c1 != "" {
fmt.Println("main: const c1 has been initialized!")
}
if c2 != "" {
fmt.Println("main: const c2 has been initialized!")
}
return ""
}
func variableInit(name string) string {
fmt.Printf("main: var %s has been initialized\n", name)
return name
}
func init() {
fmt.Println("main: first init function invoked")
}
func init() {
fmt.Println("main: second init function invoked")
}
func main() {
//
}
我们可以看到,在 main 包中其实并没有使用 pkg1 和 pkg2 中的函数或方法,而是直接通过空导入的方式“触发”pkg1 包和 pkg2 包的初始化(pkg1 包和和 pkg2 包都通过空导入的方式依赖 pkg3 包的,),下面是这个程序的运行结果:
$go run main.go
pkg3: const c has been initialized
pkg3: var v has been initialized
pkg3: init func invoked
pkg1: const c has been initialized
pkg1: var v has been initialized
pkg1: init func invoked
pkg2: const c has been initialized
pkg2: var v has been initialized
pkg2: init func invoked
main: const c1 has been initialized
main: const c2 has been initialized
main: var v1 has been initialized
main: var v2 has been initialized
main: first init func invoked
main: second init func invoked
正如我们预期的那样,Go 运行时是按照“pkg3 -> pkg1 -> pkg2 -> main”的顺序,来对 Go 程序的各个包进行初始化的,而在包内,则是以“常量 -> 变量 -> init 函数”的顺序进行初始化。此外,main 包的两个 init 函数,会按照在源文件 main.go 中的出现次序进行调用。根据 Go 语言规范,一个被多个包依赖的包仅会初始化一次,因此这里的 pkg3 包仅会被初始化了一次。
6.2 包的初始化原则
根据以上,包的初始化按照依赖关系的顺序执行,遵循以下规则:
- 依赖包按照 "深度优先" 的方式进行初始化,即先初始化最底层的依赖包。
- 在每个包内部以“常量 -> 变量 -> init 函数”的顺序进行初始化。
- 包内的多个
init函数按照它们在代码中的出现顺序依次自动调用。
七、init 函数的常用用途
Go 包初始化时,init 函数的初始化次序在变量之后,这给了开发人员在 init 函数中对包级变量进行进一步检查与操作的机会。
7.1 用途一:重置包级变量值
init 函数就好比 Go 包真正投入使用之前唯一的“质检员”,负责对包内部以及暴露到外部的包级数据(主要是包级变量)的初始状态进行检查。在 Go 标准库中,我们能发现很多 init 函数被用于检查包级变量的初始状态的例子,标准库 flag 包对 init 函数的使用就是其中的一个,这里我们简单来分析一下。
flag 包定义了一个导出的包级变量 CommandLine,如果用户没有通过 flag.NewFlagSet 创建新的代表命令行标志集合的实例,那么 CommandLine 就会作为 flag 包各种导出函数背后,默认的代表命令行标志集合的实例。
而在 flag 包初始化的时候,由于 init 函数初始化次序在包级变量之后,因此包级变量 CommandLine 会在 init 函数之前被初始化了,可以看如下代码:
var CommandLine = NewFlagSet(os.Args[0], ExitOnError)
func NewFlagSet(name string, errorHandling ErrorHandling) *FlagSet {
f := &FlagSet{
name: name,
errorHandling: errorHandling,
}
f.Usage = f.defaultUsage
return f
}
func (f *FlagSet) defaultUsage() {
if f.name == "" {
fmt.Fprintf(f.Output(), "Usage:\n")
} else {
fmt.Fprintf(f.Output(), "Usage of %s:\n", f.name)
}
f.PrintDefaults()
}
我们可以看到,在通过 NewFlagSet 创建 CommandLine 变量绑定的 FlagSet 类型实例时,CommandLine 的 Usage 字段被赋值为 defaultUsage。
也就是说,如果保持现状,那么使用 flag 包默认 CommandLine 的用户就无法自定义 usage 的输出了。于是,flag 包在 init 函数中重置了 CommandLine 的 Usage 字段:
func init() {
CommandLine.Usage = commandLineUsage // 重置CommandLine的Usage字段
}
func commandLineUsage() {
Usage()
}
var Usage = func() {
fmt.Fprintf(CommandLine.Output(), "Usage of %s:\n", os.Args[0])
PrintDefaults()
}
这个时候我们会发现,CommandLine 的 Usage 字段,设置为了一个 flag 包内的未导出函数 commandLineUsage,后者则直接使用了 flag 包的另外一个导出包变量 Usage。这样,就可以通过 init 函数,将 CommandLine 与包变量 Usage 关联在一起了。
然后,当用户将自定义的 usage 赋值给了 flag.Usage 后,就相当于改变了默认代表命令行标志集合的 CommandLine 变量的 Usage。这样当 flag 包完成初始化后,CommandLine 变量便处于一个合理可用的状态了。
7.2 用途二:实现对包级变量的复杂初始化
有些包级变量需要一个比较复杂的初始化过程。有些时候,使用它的类型零值(每个 Go 类型都具有一个零值定义)或通过简单初始化表达式不能满足业务逻辑要求,而 init 函数则非常适合完成此项工作。标准库 http 包中就有这样一个典型示例:
var (
http2VerboseLogs bool // 初始化时默认值为false
http2logFrameWrites bool // 初始化时默认值为false
http2logFrameReads bool // 初始化时默认值为false
http2inTests bool // 初始化时默认值为false
)
func init() {
e := os.Getenv("GODEBUG")
if strings.Contains(e, "http2debug=1") {
http2VerboseLogs = true // 在init中对http2VerboseLogs的值进行重置
}
if strings.Contains(e, "http2debug=2") {
http2VerboseLogs = true // 在init中对http2VerboseLogs的值进行重置
http2logFrameWrites = true // 在init中对http2logFrameWrites的值进行重置
http2logFrameReads = true // 在init中对http2logFrameReads的值进行重置
}
}
我们可以看到,标准库 http 包定义了一系列布尔类型的特性开关变量,它们默认处于关闭状态(即值为 false),但我们可以通过 GODEBUG 环境变量的值,开启相关特性开关。
可是这样一来,简单地将这些变量初始化为类型零值,就不能满足要求了,所以 http 包在 init 函数中,就根据环境变量 GODEBUG 的值,对这些包级开关变量进行了复杂的初始化,从而保证了这些开关变量在 http 包完成初始化后,可以处于合理状态。
7.3 用途三:在 init 函数中实现“注册模式”
首先我们来看一段使用 lib/pq 包访问 PostgreSQL 数据库的代码示例:
import (
"database/sql"
_ "github.com/lib/pq"
)
func main() {
db, err := sql.Open("postgres", "user=pqgotest dbname=pqgotest sslmode=verify-full")
if err != nil {
log.Fatal(err)
}
age := 21
rows, err := db.Query("SELECT name FROM users WHERE age = $1", age)
...
}
其实,这是一段“神奇”的代码。你可以看到示例代码是以空导入的方式导入 lib/pq 包的,main 函数中没有使用 pq 包的任何变量、函数或方法,这样就实现了对 PostgreSQL 数据库的访问。而这一切的奥秘,全在 pq 包的 init 函数中:
func init() {
sql.Register("postgres", &Driver{})
}
这个奥秘就在,我们其实是利用了用空导入的方式导入 lib/pq 包时产生的一个“副作用”,也就是 lib/pq 包作为 main 包的依赖包,它的 init 函数会在 pq 包初始化的时候得以执行。
从上面的代码中,我们可以看到在 pq 包的 init 函数中,pq 包将自己实现的 SQL 驱动注册到了 database/sql 包中。这样只要应用层代码在 Open 数据库的时候,传入驱动的名字(这里是“postgres”),那么通过 sql.Open 函数,返回的数据库实例句柄对数据库进行的操作,实际上调用的都是 pq 包中相应的驱动实现。
实际上,这种通过在 init 函数中注册自己的实现的模式,就有效降低了 Go 包对外的直接暴露,尤其是包级变量的暴露,从而避免了外部通过包级变量对包状态的改动。
另外,从标准库 database/sql 包的角度来看,这种“注册模式”实质是一种工厂设计模式的实现,sql.Open 函数就是这个模式中的工厂方法,它根据外部传入的驱动名称“生产”出不同类别的数据库实例句柄。
这种“注册模式”在标准库的其他包中也有广泛应用,比如说,使用标准库 image 包获取各种格式图片的宽和高:
package main
import (
"fmt"
"image"
_ "image/gif" // 以空导入方式注入gif图片格式驱动
_ "image/jpeg" // 以空导入方式注入jpeg图片格式驱动
_ "image/png" // 以空导入方式注入png图片格式驱动
"os"
)
func main() {
// 支持png, jpeg, gif
width, height, err := imageSize(os.Args[1]) // 获取传入的图片文件的宽与高
if err != nil {
fmt.Println("get image size error:", err)
return
}
fmt.Printf("image size: [%d, %d]\n", width, height)
}
func imageSize(imageFile string) (int, int, error) {
f, _ := os.Open(imageFile) // 打开图文文件
defer f.Close()
img, _, err := image.Decode(f) // 对文件进行解码,得到图片实例
if err != nil {
return 0, 0, err
}
b := img.Bounds() // 返回图片区域
return b.Max.X, b.Max.Y, nil
}
你可以看到,上面这个示例程序支持 png、jpeg、gif 三种格式的图片,而达成这一目标的原因,正是 image/png、image/jpeg 和 image/gif 包都在各自的 init 函数中,将自己“注册”到 image 的支持格式列表中了,你可以看看下面这个代码:
// $GOROOT/src/image/png/reader.go
func init() {
image.RegisterFormat("png", pngHeader, Decode, DecodeConfig)
}
// $GOROOT/src/image/jpeg/reader.go
func init() {
image.RegisterFormat("jpeg", "\xff\xd8", Decode, DecodeConfig)
}
// $GOROOT/src/image/gif/reader.go
func init() {
image.RegisterFormat("gif", "GIF8?a", Decode, DecodeConfig)
}
那么,现在我们了解了 init 函数的常见用途。init 函数之所以可以胜任这些工作,恰恰是因为它在 Go 应用初始化次序中的特殊“位次”,也就是 main 函数之前,常量和变量初始化之后。