线程对象是可以产生线程的对象。比如在Java平台中Thread对象,Runnable对象。线程,是指正在执行的一个指点令序列。在java平台上是指从一个线程对象的start()开始,运行run方法体中的那一段相对独立的过程。相比于多进程,多线程的优势有:
(1)进程之间不能共享数据,线程可以;
(2)系统创建进程需要为该进程重新分配系统资源,故创建线程代价比较小;
(3)Java语言内置了多线程功能支持,简化了java多线程编程。
一、创建线程和启动
(1)继承Thread类创建线程类
通过继承Thread类创建线程类的具体步骤和具体代码如下:
• 定义一个继承Thread类的子类,并重写该类的run()方法;
• 创建Thread子类的实例,即创建了线程对象;
• 调用该线程对象的start()方法启动线程。

class SomeThead extends Thraad {
public void run() {
//do something here
}
}
public static void main(String[] args){
SomeThread oneThread = new SomeThread();
步骤3:启动线程:
oneThread.start();
}
(2)实现Runnable接口创建线程类
通过实现Runnable接口创建线程类的具体步骤和具体代码如下:
• 定义Runnable接口的实现类,并重写该接口的run()方法;
• 创建Runnable实现类的实例,并以此实例作为Thread的target对象,即该Thread对象才是真正的线程对象。
class SomeRunnable implements Runnable {
public void run() {
//do something here
}
}
Runnable oneRunnable = new SomeRunnable();
Thread oneThread = new Thread(oneRunnable);
oneThread.start();
(3)通过Callable和Future创建线程
通过Callable和Future创建线程的具体步骤和具体代码如下:
• 创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
• 创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
• 使用FutureTask对象作为Thread对象的target创建并启动新线程。
• 调用FutureTask对象的get()方法来获得子线程执行结束后的返回值其中,Callable接口(也只有一个方法)定义如下:
public interface Callable {
V call() throws Exception;
}
步骤1:创建实现Callable接口的类SomeCallable(略);
步骤2:创建一个类对象:
Callable oneCallable = new SomeCallable();
步骤3:由Callable创建一个FutureTask对象:
FutureTask oneTask = new FutureTask(oneCallable);
注释: FutureTask是一个包装器,它通过接受Callable来创建,它同时实现了 Future和Runnable接口。
步骤4:由FutureTask创建一个Thread对象:
Thread oneThread = new Thread(oneTask);
步骤5:启动线程:
oneThread.start();
二、线程的生命周期

1、新建状态
用new关键字和Thread类或其子类建立一个线程对象后,该线程对象就处于新生状态。处于新生状态的线程有自己的内存空间,通过调用start方法进入就绪状态(runnable)。
注意:不能对已经启动的线程再次调用start()方法,否则会出现Java.lang.IllegalThreadStateException异常。
2、就绪状态
处于就绪状态的线程已经具备了运行条件,但还没有分配到CPU,处于线程就绪队列(尽管是采用队列形式,事实上,把它称为可运行池而不是可运行队列。因为cpu的调度不一定是按照先进先出的顺序来调度的),等待系统为其分配CPU。等待状态并不是执行状态,当系统选定一个等待执行的Thread对象后,它就会从等待执行状态进入执行状态,系统挑选的动作称之为“cpu调度”。一旦获得CPU,线程就进入运行状态并自动调用自己的run方法。
提示:如果希望子线程调用start()方法后立即执行,可以使用Thread.sleep()方式使主线程睡眠一伙儿,转去执行子线程。
3、运行状态
处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
处于就绪状态的线程,如果获得了cpu的调度,就会从就绪状态变为运行状态,执行run()方法中的任务。如果该线程失去了cpu资源,就会又从运行状态变为就绪状态。重新等待系统分配资源。也可以对在运行状态的线程调用yield()方法,它就会让出cpu资源,再次变为就绪状态。
注: 当发生如下情况是,线程会从运行状态变为阻塞状态:
①、线程调用sleep方法主动放弃所占用的系统资源
②、线程调用一个阻塞式IO方法,在该方法返回之前,该线程被阻塞
③、线程试图获得一个同步监视器,但更改同步监视器正被其他线程所持有
④、线程在等待某个通知(notify)
⑤、程序调用了线程的suspend方法将线程挂起。不过该方法容易导致死锁,所以程序应该尽量避免使用该方法。
当线程的run()方法执行完,或者被强制性地终止,例如出现异常,或者调用了stop()、desyory()方法等等,就会从运行状态转变为死亡状态。
4、阻塞状态
处于运行状态的线程在某些情况下,如执行了sleep(睡眠)方法,或等待I/O设备等资源,将让出CPU并暂时停止自己的运行,进入阻塞状态。
在阻塞状态的线程不能进入就绪队列。只有当引起阻塞的原因消除时,如睡眠时间已到,或等待的I/O设备空闲下来,线程便转入就绪状态,重新到就绪队列中排队等待,被系统选中后从原来停止的位置开始继续运行。有三种方法可以暂停Threads执行:
5、死亡状态
当线程的run()方法执行完,或者被强制性地终止,就认为它死去。这个线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦死亡,就不能复生。 如果在一个死去的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
三、线程管理
Java提供了一些便捷的方法用于会线程状态的控制。具体如下:
1、线程睡眠——sleep
如果我们需要让当前正在执行的线程暂停一段时间,并进入阻塞状态,则可以通过调用Thread的sleep方法。
注:
(1)sleep是静态方法,最好不要用Thread的实例对象调用它,因为它睡眠的始终是当前正在运行的线程,而不是调用它的线程对象,它只对正在运行状态的线程对象有效。如下面的例子:
public class Test1 {
public static void main(String[] args) throws InterruptedException {
System.out.println(Thread.currentThread().getName());
MyThread myThread=new MyThread();
myThread.start();
myThread.sleep(1000);//这里sleep的就是main线程,而非myThread线程
Thread.sleep(10);
for(int i=0;i<100;i++){
System.out.println("main"+i);
}
}
}
(2)Java线程调度是Java多线程的核心,只有良好的调度,才能充分发挥系统的性能,提高程序的执行效率。但是不管程序员怎么编写调度,只能最大限度的影响线程执行的次序,而不能做到精准控制。因为使用sleep方法之后,线程是进入阻塞状态的,只有当睡眠的时间结束,才会重新进入到就绪状态,而就绪状态进入到运行状态,是由系统控制的,我们不可能精准的去干涉它,所以如果调用Thread.sleep(1000)使得线程睡眠1秒,可能结果会大于1秒。
2、线程让步——yield
yield()方法和sleep()方法有点相似,它也是Thread类提供的一个静态的方法,它也可以让当前正在执行的线程暂停,让出cpu资源给其他的线程。但是和sleep()方法不同的是,它不会进入到阻塞状态,而是进入到就绪状态。yield()方法只是让当前线程暂停一下,重新进入就绪的线程池中,让系统的线程调度器重新调度器重新调度一次,完全可能出现这样的情况:当某个线程调用yield()方法之后,线程调度器又将其调度出来重新进入到运行状态执行。
实际上,当某个线程调用了yield()方法暂停之后,优先级与当前线程相同,或者优先级比当前线程更高的就绪状态的线程更有可能获得执行的机会,当然,只是有可能,因为我们不可能精确的干涉cpu调度线程。用法如下:
public class Test1 {
public static void main(String[] args) throws InterruptedException {
new MyThread("低级", 1).start();
new MyThread("中级", 5).start();
new MyThread("高级", 10).start();
}
}
class MyThread extends Thread {
public MyThread(String name, int pro) {
super(name);// 设置线程的名称
this.setPriority(pro);// 设置优先级
}
@Override
public void run() {
for (int i = 0; i < 30; i++) {
System.out.println(this.getName() + "线程第" + i + "次执行!");
if (i % 5 == 0)
Thread.yield();
}
}
}
注:关于sleep()方法和yield()方的区别如下:
①、sleep方法暂停当前线程后,会进入阻塞状态,只有当睡眠时间到了,才会转入就绪状态。而yield方法调用后 ,是直接进入就绪状态,所以有可能刚进入就绪状态,又被调度到运行状态。
②、sleep方法声明抛出了InterruptedException,所以调用sleep方法的时候要捕获该异常,或者显示声明抛出该异常。而yield方法则没有声明抛出任务异常。
③、sleep方法比yield方法有更好的可移植性,通常不要依靠yield方法来控制并发线程的执行。
3、线程合并——join
线程的合并的含义就是将几个并行线程的线程合并为一个单线程执行,应用场景是当一个线程必须等待另一个线程执行完毕才能执行时,Thread类提供了join方法来完成这个功能,注意,它不是静态方法。
从上面的方法的列表可以看到,它有3个重载的方法:
void join()
当前线程等该加入该线程后面,等待该线程终止。 void join(long millis)
当前线程等待该线程终止的时间最长为 millis 毫秒。 如果在millis时间内,该线程没有执行完,那么当前线程进入就绪状态,重新等待cpu调度 void join(long millis,int nanos)
等待该线程终止的时间最长为 millis 毫秒 + nanos 纳秒。如果在millis时间内,该线程没有执行完,那么当前线程进入就绪状态,重新等待cpu调度
4、设置线程的优先级
每个线程执行时都有一个优先级的属性,优先级高的线程可以获得较多的执行机会,而优先级低的线程则获得较少的执行机会。与线程休眠类似,线程的优先级仍然无法保障线程的执行次序。只不过,优先级高的线程获取CPU资源的概率较大,优先级低的也并非没机会执行。
每个线程默认的优先级都与创建它的父线程具有相同的优先级,在默认情况下,main线程具有普通优先级。
注:Thread类提供了setPriority(int newPriority)和getPriority()方法来设置和返回一个指定线程的优先级,其中setPriority方法的参数是一个整数,范围是1~·0之间,也可以使用Thread类提供的三个静态常量:
MAX_PRIORITY =10 MIN_PRIORITY =1 NORM_PRIORITY =5
public class Test1 {
public static void main(String[] args) throws InterruptedException {
new MyThread("高级", 10).start();
new MyThread("低级", 1).start();
}
}
class MyThread extends Thread {
public MyThread(String name,int pro) {
super(name);//设置线程的名称
setPriority(pro);//设置线程的优先级
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(this.getName() + "线程第" + i + "次执行!");
}
}
}
注:虽然Java提供了10个优先级别,但这些优先级别需要操作系统的支持。不同的操作系统的优先级并不相同,而且也不能很好的和Java的10个优先级别对应。所以我们应该使用MAX_PRIORITY、MIN_PRIORITY和NORM_PRIORITY三个静态常量来设定优先级,这样才能保证程序最好的可移植性。
5、后台(守护)线程
• 守护线程通常用于执行一些后台作业,例如在你的应用程序运行时播放背景音乐,在文字编辑器里做自动语法检查、自动保存等功能。
• Java的垃圾回收也是一个守护线程。守护线的好处就是你不需要关心它的结束问题。例如你在你的应用程序运行的时候希望播放背景音乐,如果将这个播放背景音乐的线程设定为非守护线程,那么在用户请求退出的时候,不仅要退出主线程,还要通知播放背景音乐的线程退出;如果设定为守护线程则不需要了。
setDaemon方法的详细说明:
public final void setDaemon(boolean on) 将该线程标记为守护线程或用户线程。当正在运行的线程都是守护线程时,Java 虚拟机退出。
该方法必须在启动线程前调用。 该方法首先调用该线程的 checkAccess 方法,且不带任何参数。这可能抛出 SecurityException(在当前线程中)。
参数:
on - 如果为 true,则将该线程标记为守护线程。
抛出:
IllegalThreadStateException - 如果该线程处于活动状态。
SecurityException - 如果当前线程无法修改该线程。
注:JRE判断程序是否执行结束的标准是所有的前台执线程行完毕了,而不管后台线程的状态,因此,在使用后台县城时候一定要注意这个问题。
6、正确结束线程
Thread.stop()、Thread.suspend、Thread.resume、Runtime.runFinalizersOnExit这些终止线程运行的方法已经被废弃了,使用它们是极端不安全的!想要安全有效的结束一个线程,可以使用下面的方法:
• 正常执行完run方法,然后结束掉;
• 控制循环条件和判断条件的标识符来结束掉线程。
class MyThread extends Thread {
int i=0;
boolean next=true;
@Override
public void run() {
while (next) {
if(i==10)
next=false;
i++;
System.out.println(i);
}
}
}
四、线程同步
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证了该变量的唯一性和准确性。
1、同步方法
即有synchronized关键字修饰的方法。由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
?| 1 |
public synchronized void save(){}
|
注: synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类
2、同步代码块
即有synchronized关键字修饰的语句块。被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。
public class Bank { private int count =0;//账户余额
//存钱
public void addMoney(int money){
synchronized (this) {
count +=money;
}
System.out.println(System.currentTimeMillis()+"存进:"+money);
}
//取钱
public void subMoney(int money){
synchronized (this) {
if(count-money < 0){
System.out.println("余额不足");
return;
}
count -=money;
}
System.out.println(+System.currentTimeMillis()+"取出:"+money);
}
//查询
public void lookMoney(){
System.out.println("账户余额:"+count);
}
}
注:同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
3、使用特殊域变量(volatile)实现线程同步
• volatile关键字为域变量的访问提供了一种免锁机制;
• 使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新;
• 因此每次使用该域就要重新计算,而不是使用寄存器中的值;
• volatile不会提供任何原子操作,它也不能用来修饰final类型的变量。
public class SynchronizedThread {
class Bank {
private volatile int account = 100;
public int getAccount() {
return account;
}
/**
* 用同步方法实现
*
* @param money
*/
public synchronized void save(int money) {
account += money;
}
/**
* 用同步代码块实现
*
* @param money
*/
public void save1(int money) {
synchronized (this) {
account += money;
}
}
}
class NewThread implements Runnable {
private Bank bank;
public NewThread(Bank bank) {
this.bank = bank;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
// bank.save1(10);
bank.save(10);
System.out.println(i + "账户余额为:" +bank.getAccount());
}
}
}
/**
* 建立线程,调用内部类
*/
public void useThread() {
Bank bank = new Bank();
NewThread new_thread = new NewThread(bank);
System.out.println("线程1");
Thread thread1 = new Thread(new_thread);
thread1.start();
System.out.println("线程2");
Thread thread2 = new Thread(new_thread);
thread2.start();
}
public static void main(String[] args) {
SynchronizedThread st = new SynchronizedThread();
st.useThread();
}
注:多线程中的非同步问题主要出现在对域的读写上,如果让域自身避免这个问题,则就不需要修改操作该域的方法。用final域,有锁保护的域和volatile域可以避免非同步的问题。
4、使用重入锁(Lock)实现线程同步
在JavaSE5.0中新增了一个java.util.concurrent包来支持同步。ReentrantLock类是可重入、互斥、实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力。ReenreantLock类的常用方法有:
ReentrantLock() : 创建一个ReentrantLock实例 lock() : 获得锁 unlock() : 释放锁
注:ReentrantLock()还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,不推荐使用
//只给出要修改的代码,其余代码与上同
class Bank {
private int account = 100;
//需要声明这个锁
private Lock lock = new ReentrantLock();
public int getAccount() {
return account;
}
//这里不再需要synchronized
public void save(int money) {
lock.lock();
try{
account += money;
}finally{
lock.unlock();
}
}
}
五、线程通信
1、借助于Object类的wait()、notify()和notifyAll()实现通信
线程执行wait()后,就放弃了运行资格,处于冻结状态;
线程运行时,内存中会建立一个线程池,冻结状态的线程都存在于线程池中,notify()执行时唤醒的也是线程池中的线程,线程池中有多个线程时唤醒第一个被冻结的线程。
notifyall(), 唤醒线程池中所有线程。
注: (1) wait(), notify(),notifyall()都用在同步里面,因为这3个函数是对持有锁的线程进行操作,而只有同步才有锁,所以要使用在同步中;
(2) wait(),notify(),notifyall(), 在使用时必须标识它们所操作的线程持有的锁,因为等待和唤醒必须是同一锁下的线程;而锁可以是任意对象,所以这3个方法都是Object类中的方法。
单个消费者生产者例子如下:
class Resource{ //生产者和消费者都要操作的资源
private String name;
private int count=1;
private boolean flag=false;
public synchronized void set(String name){
if(flag)
try{wait();}catch(Exception e){}
this.name=name+"---"+count++;
System.out.println(Thread.currentThread().getName()+"...生产者..."+this.name);
flag=true;
this.notify();
}
public synchronized void out(){
if(!flag)
try{wait();}catch(Exception e){}
System.out.println(Thread.currentThread().getName()+"...消费者..."+this.name);
flag=false;
this.notify();
}
}
class Producer implements Runnable{
private Resource res;
Producer(Resource res){
this.res=res;
}
public void run(){
while(true){
res.set("商品");
}
}
}
class Consumer implements Runnable{
private Resource res;
Consumer(Resource res){
this.res=res;
}
public void run(){
while(true){
res.out();
}
}
}
public class ProducerConsumerDemo{
public static void main(String[] args){
Resource r=new Resource();
Producer pro=new Producer(r);
Consumer con=new Consumer(r);
Thread t1=new Thread(pro);
Thread t2=new Thread(con);
t1.start();
t2.start();
}
}//运行结果正常,生产者生产一个商品,紧接着消费者消费一个商品。
但是如果有多个生产者和多个消费者,上面的代码是有问题,比如2个生产者,2个消费者,运行结果就可能出现生产的1个商品生产了一次而被消费了2次,或者连续生产2个商品而只有1个被消费,这是因为此时共有4个线程在操作Resource对象r, 而notify()唤醒的是线程池中第1个wait()的线程,所以生产者执行notify()时,唤醒的线程有可能是另1个生产者线程,这个生产者线程从wait()中醒来后不会再判断flag,而是直接向下运行打印出一个新的商品,这样就出现了连续生产2个商品。
为了避免这种情况,修改代码如下:
class Resource{
private String name;
private int count=1;
private boolean flag=false;
public synchronized void set(String name){
while(flag) /*原先是if,现在改成while,这样生产者线程从冻结状态醒来时,还会再判断flag.*/
try{wait();}catch(Exception e){}
this.name=name+"---"+count++;
System.out.println(Thread.currentThread().getName()+"...生产者..."+this.name);
flag=true;
this.notifyAll();/*原先是notity(), 现在改成notifyAll(),这样生产者线程生产完一个商品后可以将等待中的消费者线程唤醒,否则只将上面改成while后,可能出现所有生产者和消费者都在wait()的情况。*/
}
public synchronized void out(){
while(!flag) /*原先是if,现在改成while,这样消费者线程从冻结状态醒来时,还会再判断flag.*/
try{wait();}catch(Exception e){}
System.out.println(Thread.currentThread().getName()+"...消费者..."+this.name);
flag=false;
this.notifyAll(); /*原先是notity(), 现在改成notifyAll(),这样消费者线程消费完一个商品后可以将等待中的生产者线程唤醒,否则只将上面改成while后,可能出现所有生产者和消费者都在wait()的情况。*/
}
}
public class ProducerConsumerDemo{
public static void main(String[] args){
Resource r=new Resource();
Producer pro=new Producer(r);
Consumer con=new Consumer(r);
Thread t1=new Thread(pro);
Thread t2=new Thread(con);
Thread t3=new Thread(pro);
Thread t4=new Thread(con);
t1.start();
t2.start();
t3.start();
t4.start();
}
}
2、使用Condition控制线程通信
jdk1.5中,提供了多线程的升级解决方案为:
(1)将同步synchronized替换为显式的Lock操作;
(2)将Object类中的wait(), notify(),notifyAll()替换成了Condition对象,该对象可以通过Lock锁对象获取;
(3)一个Lock对象上可以绑定多个Condition对象,这样实现了本方线程只唤醒对方线程,而jdk1.5之前,一个同步只能有一个锁,不同的同步只能用锁来区分,且锁嵌套时容易死锁。
class Resource{
private String name;
private int count=1;
private boolean flag=false;
private Lock lock = new ReentrantLock();/*Lock是一个接口,ReentrantLock是该接口的一个直接子类。*/
private Condition condition_pro=lock.newCondition(); /*创建代表生产者方面的Condition对象*/
private Condition condition_con=lock.newCondition(); /*使用同一个锁,创建代表消费者方面的Condition对象*/
public void set(String name){
lock.lock();//锁住此语句与lock.unlock()之间的代码
try{
while(flag)
condition_pro.await(); //生产者线程在conndition_pro对象上等待
this.name=name+"---"+count++;
System.out.println(Thread.currentThread().getName()+"...生产者..."+this.name);
flag=true;
condition_con.signalAll();
}
finally{
lock.unlock(); //unlock()要放在finally块中。
}
}
public void out(){
lock.lock(); //锁住此语句与lock.unlock()之间的代码
try{
while(!flag)
condition_con.await(); //消费者线程在conndition_con对象上等待
System.out.println(Thread.currentThread().getName()+"...消费者..."+this.name);
flag=false;
condition_pro.signqlAll(); /*唤醒所有在condition_pro对象下等待的线程,也就是唤醒所有生产者线程*/
}
finally{
lock.unlock();
}
}
}
3、使用阻塞队列(BlockingQueue)控制线程通信
BlockingQueue是一个接口,也是Queue的子接口。BlockingQueue具有一个特征:当生产者线程试图向BlockingQueue中放入元素时,如果该队列已满,则线程被阻塞;但消费者线程试图从BlockingQueue中取出元素时,如果队列已空,则该线程阻塞。程序的两个线程通过交替向BlockingQueue中放入元素、取出元素,即可很好地控制线程的通信。
BlockingQueue提供如下两个支持阻塞的方法:
(1)put(E e):尝试把Eu元素放如BlockingQueue中,如果该队列的元素已满,则阻塞该线程。
(2)take():尝试从BlockingQueue的头部取出元素,如果该队列的元素已空,则阻塞该线程。
BlockingQueue继承了Queue接口,当然也可以使用Queue接口中的方法,这些方法归纳起来可以分为如下三组:
(1)在队列尾部插入元素,包括add(E e)、offer(E e)、put(E e)方法,当该队列已满时,这三个方法分别会抛出异常、返回false、阻塞队列。
(2)在队列头部删除并返回删除的元素。包括remove()、poll()、和take()方法,当该队列已空时,这三个方法分别会抛出异常、返回false、阻塞队列。
(3)在队列头部取出但不删除元素。包括element()和peek()方法,当队列已空时,这两个方法分别抛出异常、返回false。
BlockingQueue接口包含如下5个实现类:
ArrayBlockingQueue :基于数组实现的BlockingQueue队列。 LinkedBlockingQueue:基于链表实现的BlockingQueue队列。 PriorityBlockingQueue:它并不是保准的阻塞队列,该队列调用remove()、poll()、take()等方法提取出元素时,并不是取出队列中存在时间最长的元素,而是队列中最小的元素。
它判断元素的大小即可根据元素(实现Comparable接口)的本身大小来自然排序,也可使用Comparator进行定制排序。 SynchronousQueue:同步队列。对该队列的存、取操作必须交替进行。 DelayQueue:它是一个特殊的BlockingQueue,底层基于PriorityBlockingQueue实现,不过,DelayQueue要求集合元素都实现Delay接口(该接口里只有一个long getDelay()方法),
DelayQueue根据集合元素的getDalay()方法的返回值进行排序。
copy的一个示例:
1 import java.util.concurrent.ArrayBlockingQueue;
2 import java.util.concurrent.BlockingQueue;
3 public class BlockingQueueTest{
4 public static void main(String[] args)throws Exception{
5 //创建一个容量为1的BlockingQueue
6
7 BlockingQueue<String> b=new ArrayBlockingQueue<>(1);
8 //启动3个生产者线程
9 new Producer(b).start();
10 new Producer(b).start();
11 new Producer(b).start();
12 //启动一个消费者线程
13 new Consumer(b).start();
14
15 }
16 }
17 class Producer extends Thread{
18 private BlockingQueue<String> b;
19
20 public Producer(BlockingQueue<String> b){
21 this.b=b;
22
23 }
24 public synchronized void run(){
25 String [] str=new String[]{
26 "java",
27 "struts",
28 "Spring"
29 };
30 for(int i=0;i<9999999;i++){
31 System.out.println(getName()+"生产者准备生产集合元素!");
32 try{
33
34 b.put(str[i%3]);
35 sleep(1000);
36 //尝试放入元素,如果队列已满,则线程被阻塞
37
38 }catch(Exception e){System.out.println(e);}
39 System.out.println(getName()+"生产完成:"+b);
40 }
41
42 }
43 }
44 class Consumer extends Thread{
45 private BlockingQueue<String> b;
46 public Consumer(BlockingQueue<String> b){
47 this.b=b;
48 }
49 public synchronized void run(){
50
51 while(true){
52 System.out.println(getName()+"消费者准备消费集合元素!");
53 try{
54 sleep(1000);
55 //尝试取出元素,如果队列已空,则线程被阻塞
56 b.take();
57 }catch(Exception e){System.out.println(e);}
58 System.out.println(getName()+"消费完:"+b);
59 }
60
61 }
62 }
六、线程池
合理利用线程池能够带来三个好处。
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
1、使用Executors工厂类产生线程池
Executor线程池框架的最大优点是把任务的提交和执行解耦。客户端将要执行的任务封装成Task,然后提交即可。而Task如何执行客户端则是透明的。具体点讲,提交一个Callable对象给ExecutorService(如最常用的线程池ThreadPoolExecutor),将得到一个Future对象,调用Future对象的get方法等待执行结果。线程池实现原理类结构图如下:
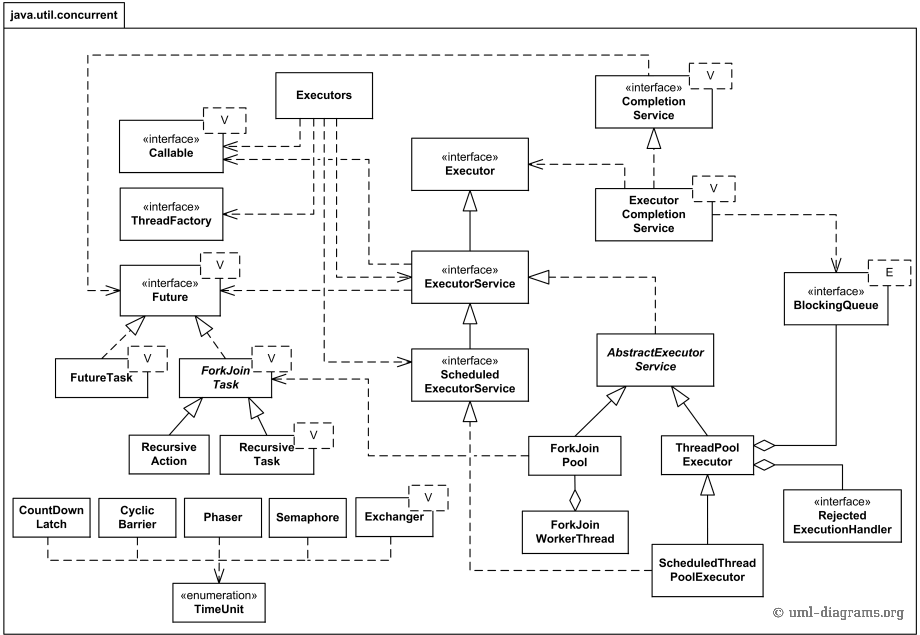
上图中涉及到的线程池内部实现原理的所有类,不利于我们理解线程池如何使用。我们先从客户端的角度出发,看看客户端使用线程池所涉及到的类结构图:

由上图可知,ExecutorService是Java中对线程池定义的一个接口,它java.util.concurrent包中。 Java API对ExecutorService接口的实现有两个,所以这两个即是Java线程池具体实现类如下:
ThreadPoolExecutor ScheduledThreadPoolExecutor
除此之外,ExecutorService还继承了Executor接口(注意区分Executor接口和Executors工厂类),这个接口只有一个execute()方法,最后我们看一下整个继承树:
使用Executors执行多线程任务的步骤如下:
• 调用Executors类的静态工厂方法创建一个ExecutorService对象,该对象代表一个线程池;
• 创建Runnable实现类或Callable实现类的实例,作为线程执行任务;
• 调用ExecutorService对象的submit()方法来提交Runnable实例或Callable实例;
• 当不想提交任务时,调用ExecutorService对象的shutdown()方法来关闭线程池。
(1)使用Executors的静态工厂类创建线程池的方法如下:
1、newFixedThreadPool() :
作用:该方法返回一个固定线程数量的线程池,该线程池中的线程数量始终不变,即不会再创建新的线程,也不会销毁已经创建好的线程,自始自终都是那几个固定的线程在工作,所以该线程池可以控制线程的最大并发数。
栗子:假如有一个新任务提交时,线程池中如果有空闲的线程则立即使用空闲线程来处理任务,如果没有,则会把这个新任务存在一个任务队列中,一旦有线程空闲了,则按FIFO方式处理任务队列中的任务。
2、newCachedThreadPool() :
作用:该方法返回一个可以根据实际情况调整线程池中线程的数量的线程池。即该线程池中的线程数量不确定,是根据实际情况动态调整的。
栗子:假如该线程池中的所有线程都正在工作,而此时有新任务提交,那么将会创建新的线程去处理该任务,而此时假如之前有一些线程完成了任务,现在又有新任务提交,那么将不会创建新线程去处理,而是复用空闲的线程去处理新任务。那么此时有人有疑问了,那这样来说该线程池的线程岂不是会越集越多?其实并不会,因为线程池中的线程都有一个“保持活动时间”的参数,通过配置它,如果线程池中的空闲线程的空闲时间超过该“保存活动时间”则立刻停止该线程,而该线程池默认的“保持活动时间”为60s。
3、newSingleThreadExecutor() :
作用:该方法返回一个只有一个线程的线程池,即每次只能执行一个线程任务,多余的任务会保存到一个任务队列中,等待这一个线程空闲,当这个线程空闲了再按FIFO方式顺序执行任务队列中的任务。
4、newScheduledThreadPool() :
作用:该方法返回一个可以控制线程池内线程定时或周期性执行某任务的线程池。
5、newSingleThreadScheduledExecutor() :
作用:该方法返回一个可以控制线程池内线程定时或周期性执行某任务的线程池。只不过和上面的区别是该线程池大小为1,而上面的可以指定线程池的大小。
注:Executors只是一个工厂类,它所有的方法返回的都是ThreadPoolExecutor、ScheduledThreadPoolExecutor这两个类的实例。
(2) ExecutorService有如下几个执行方法:
- execute(Runnable) - submit(Runnable) - submit(Callable) - invokeAny(...) - invokeAll(...)
execute(Runnable)
这个方法接收一个Runnable实例,并且异步的执行,请看下面的实例:
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.execute(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
executorService.shutdown();
submit(Runnable)
submit(Runnable)和execute(Runnable)区别是前者可以返回一个Future对象,通过返回的Future对象,我们可以检查提交的任务是否执行完毕,请看下面执行的例子:
Future future = executorService.submit(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
future.get(); //returns null if the task has finished correctly.
注:如果任务执行完成,future.get()方法会返回一个null。注意,future.get()方法会产生阻塞。
submit(Callable)
submit(Callable)和submit(Runnable)类似,也会返回一个Future对象,但是除此之外,submit(Callable)接收的是一个Callable的实现,Callable接口中的call()方法有一个返回值,可以返回任务的执行结果,而Runnable接口中的run()方法是void的,没有返回值。请看下面实例:
Future future = executorService.submit(new Callable(){
public Object call() throws Exception {
System.out.println("Asynchronous Callable");
return "Callable Result";
}
});
System.out.println("future.get() = " + future.get());
如果任务执行完成,future.get()方法会返回Callable任务的执行结果。另外,future.get()方法会产生阻塞。
invokeAny(…)
invokeAny(...)方法接收的是一个Callable的集合,执行这个方法不会返回Future,但是会返回所有Callable任务中其中一个任务的执行结果。这个方法也无法保证返回的是哪个任务的执行结果,反正是其中的某一个。请看下面实例:
ExecutorService executorService = Executors.newSingleThreadExecutor();
Set<Callable<String>> callables = new HashSet<Callable<String>>();
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 1";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 2";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 3";
}
});
String result = executorService.invokeAny(callables);
System.out.println("result = " + result);
executorService.shutdown();
大家可以尝试执行上面代码,每次执行都会返回一个结果,并且返回的结果是变化的,可能会返回“Task2”也可是“Task1”或者其它。
invokeAll(…)
invokeAll(...)与 invokeAny(...)类似也是接收一个Callable集合,但是前者执行之后会返回一个Future的List,其中对应着每个Callable任务执行后的Future对象。情况下面这个实例:
ExecutorService executorService = Executors.newSingleThreadExecutor();
Set<Callable<String>> callables = new HashSet<Callable<String>>();
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 1";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 2";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 3";
}
});
List<Future<String>> futures = executorService.invokeAll(callables);
for(Future<String> future : futures){
System.out.println("future.get = " + future.get());
}
executorService.shutdown();
(3) ExecutorService关闭方法
当我们使用完成ExecutorService之后应该关闭它,否则它里面的线程会一直处于运行状态。举个例子,如果的应用程序是通过main()方法启动的,在这个main()退出之后,如果应用程序中的ExecutorService没有关闭,这个应用将一直运行。之所以会出现这种情况,是因为ExecutorService中运行的线程会阻止JVM关闭。
要关闭ExecutorService中执行的线程,我们可以调用ExecutorService.shutdown()方法。在调用shutdown()方法之后,ExecutorService不会立即关闭,但是它不再接收新的任务,直到当前所有线程执行完成才会关闭,所有在shutdown()执行之前提交的任务都会被执行。
如果想立即关闭ExecutorService,我们可以调用ExecutorService.shutdownNow()方法。这个动作将跳过所有正在执行的任务和被提交还没有执行的任务。但是它并不对正在执行的任务做任何保证,有可能它们都会停止,也有可能执行完成。
2、使用Java8增强的ForkJoinPool产生线程池
在Java 8中,引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,前提是使用了ForkJoinPool。
ForkJoinPool同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。比如,我们需要统计一个double数组中小于0.5的元素的个数,那么可以使用ForkJoinPool进行实现如下:
public class ForkJoinTest {
private double[] d;
private class ForkJoinTask extends RecursiveTask {
private int first;
private int last;
public ForkJoinTask(int first, int last) {
this.first = first;
this.last = last;
}
protected Integer compute() {
int subCount;
if (last - first < 10) {
subCount = 0;
for (int i = first; i <= last; i++) {
if (d[i] < 0.5){
subCount++;
}
}
}else {
int mid = (first + last) /2;
ForkJoinTask left = new ForkJoinTask(first, mid);
left.fork();
ForkJoinTask right = new ForkJoinTask(mid + 1, last);
right.fork();
subCount = left.join();
subCount += right.join();
}
return subCount;
}
}
public static void main(String[] args) {
ForkJoinPool pool=new ForkJoinPool();
pool.submit(new ForkJoinTask(0, 9999999));
pool.awaitTermination(2,TimeUnit.SECONDS);
System.out.println("Found " + n + " values");
}
}
以上的关键是fork()和join()方法。在ForkJoinPool使用的线程中,会使用一个内部队列来对需要执行的任务以及子任务进行操作来保证它们的执行顺序。
注:使用ThreadPoolExecutor和ForkJoinPool的性能差异:
(1)首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
(2)ForkJoinPool能够实现工作窃取(Work Stealing),在该线程池的每个线程中会维护一个队列来存放需要被执行的任务。当线程自身队列中的任务都执行完毕后,它会从别的线程中拿到未被执行的任务并帮助它执行。因此,提高了线程的利用率,从而提高了整体性能。
(3)对于ForkJoinPool,还有一个因素会影响它的性能,就是停止进行任务分割的那个阈值。比如在之前的快速排序中,当剩下的元素数量小于10的时候,就会停止子任务的创建。
结论:
- 当需要处理递归分治算法时,考虑使用ForkJoinPool;
- 仔细设置不再进行任务划分的阈值,这个阈值对性能有影响;
- Java 8中的一些特性会使用到ForkJoinPool中的通用线程池。在某些场合下,需要调整该线程池的默认的线程数量。
七、死锁
产生死锁的四个必要条件如下。当下边的四个条件都满足时即产生死锁,即任意一个条件不满足既不会产生死锁。
(1)死锁的四个必要条件
- 互斥条件:资源不能被共享,只能被同一个进程使用
- 请求与保持条件:已经得到资源的进程可以申请新的资源
- 非剥夺条件:已经分配的资源不能从相应的进程中被强制剥夺
- 循环等待条件:系统中若干进程组成环路,该环路中每个进程都在等待相邻进程占用的资源
举个常见的死锁例子:进程A中包含资源A,进程B中包含资源B,A的下一步需要资源B,B的下一步需要资源A,所以它们就互相等待对方占有的资源释放,所以也就产生了一个循环等待死锁。
(2)处理死锁的方法
- 忽略该问题,也即鸵鸟算法。当发生了什么问题时,不管他,直接跳过,无视它;
- 检测死锁并恢复;
- 资源进行动态分配;
- 破除上面的四种死锁条件之一。
八、线程相关类
(1)ThreadLocal
ThreadLocal它并不是一个线程,而是一个可以在每个线程中存储数据的数据存储类,通过它可以在指定的线程中存储数据,数据存储之后,只有在指定线程中可以获取到存储的数据,对于其他线程来说则无法获取到该线程的数据。 即多个线程通过同一个ThreadLocal获取到的东西是不一样的,就算有的时候出现的结果是一样的(偶然性,两个线程里分别存了两份相同的东西),但他们获取的本质是不同的。使用这个工具类可以简化多线程编程时的并发访问,很简洁的隔离多线程程序的竞争资源。
对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。ThreadLocal类提供了如下的三个public方法:
ThreadLocal()
创建一个线程本地变量。
T get()
返回此线程局部变量的当前线程副本中的值,如果这是线程第一次调用该方法,则创建并初始化此副本。
protected T initialValue()
返回此线程局部变量的当前线程的初始值。
下面通过系统源码来分析出现这个结果的原因。 在ThreadLocal中存在着两个很重要的方法,get()和set()方法,一个读取一个设置。
/**
* Returns the value of this variable for the current thread. If an entry
* doesn't yet exist for this variable on this thread, this method will
* create an entry, populating the value with the result of
* {@link #initialValue()}.
*
* @return the current value of the variable for the calling thread.
*/
@SuppressWarnings("unchecked")
public T get() {
// Optimized for the fast path.
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values != null) {
Object[] table = values.table;
int index = hash & values.mask;
if (this.reference == table[index]) {
return (T) table[index + 1];
}
} else {
values = initializeValues(currentThread);
}
return (T) values.getAfterMiss(this);
}
/**
* Sets the value of this variable for the current thread. If set to
* {@code null}, the value will be set to null and the underlying entry will
* still be present.
*
* @param value the new value of the variable for the caller thread.
*/
public void set(T value) {
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values == null) {
values = initializeValues(currentThread);
}
values.put(this, value);
}
从注释上可以看出,get方法会返回一个当前线程的变量值,如果数组不存在就会创建一个新的。另外,对于“当前线程”和“数组”,数组对于每个线程来说都是不同的 values.table。而values是通过当前线程获取到的一个Values对象,因此这个数组是每个线程唯一的,不能共用,而下面的几句话也更直接了,获取一个索引,再返回通过这个索引找到数组中对应的值。这也就解释了为什么多个线程通过同一个ThreadLocal返回的是不同的东西。
Java中为什么要这么设置呢?
- ThreadLocal在日常开发中使用到的地方较少,但是在某些特殊的场景下,通过ThreadLocal可以轻松实现一些看起来很复杂的功能。一般来说,当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑使用ThreadLocal。例如在Handler和Looper中。对于Handler来说,它需要获取当前线程的Looper,很显然Looper的作用域就是线程并且不同的线程具有不同的Looper,这个时候通过ThreadLocal就可以轻松的实现Looper在线程中的存取。如果不采用ThreadLocal,那么系统就必须提供一个全局的哈希表供Handler查找指定的Looper,这样就比较麻烦了,还需要一个管理类。
- ThreadLocal的另一个使用场景是复杂逻辑下的对象传递,比如监听器的传递,有些时候一个线程中的任务过于复杂,就可能表现为函数调用栈比较深以及代码入口的多样性,这种情况下,我们又需要监听器能够贯穿整个线程的执行过程。这个时候就可以使用到ThreadLocal,通过ThreadLocal可以让监听器作为线程内的全局对象存在,在线程内通过get方法就可以获取到监听器。如果不采用的话,可以使用参数传递,但是这种方式在设计上不是特别好,当调用栈很深的时候,通过参数来传递监听器这个设计太糟糕。而另外一种方式就是使用static静态变量的方式,但是这种方式存在一定的局限性,拓展性并不是特别的强。比如有10个线程在执行,就需要提供10个监听器对象。
注:ThreadLocal和其他所有的同步机制一样,都是为了解决多线程中对于同一变量的访问冲突。值普通的同步机制中,通过对象加锁来实现多线程对同一变量的安全访问,且该变量是多线程共享的,所有需要使用这种同步机制来明确分开是在什么时候对变量进行读写,在什么时候需要锁定该对象。此种情况下,系统并没有将这个资源复制多份,而是采取安全机制来控制访问而已。ThreadLocal只是从另一个角度解决多线程的并发访问,即将需要并发访问的资源复制多份,每个线程拥有一份资源,每个线程都有自己的资源副本。
总结:若多个线程之间需要共享资源,以达到线程间的通信时,就使用同步机制;若仅仅需要隔离多线程之间的关系资源,则可以使用ThreadLocal。
标签: Java线程 好文要顶 关注我 收藏该文
 snow_flower
snow_flower 粉丝 - 29 关注 - 0
+加关注 47 0 升级成为会员 « 上一篇: Android中点击事件的处理解析及常见问题
» 下一篇: curl命令详解 标签:Java,Thread,void,详解,线程,new,多线程,方法,public From: https://www.cnblogs.com/zhou111f/p/17744839.html