Python_day3
1、列表
index = 0
while index < len(列表):
元素 = 列表[index]
对元素进行处理
index += 1
方法2:
for 临时变量 in 数据容器:
对临时变量进行处理
while 循环可以控制循环条件,但是for循环不行
2、元组
元组一旦被定义就不能被修改
元组:使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型
#定义元组字面量
变量名称 = (元素,元素,元素,。。。,元素)
#定义空元组
变量名称 = ()
变量名称 = tuple()
注意:
定义元组时,若元组中只有一个数据时,这个数据后面要添加逗号
t2 = ('Hello',)
元组的嵌套
t2 = ((1,2,3),)
取出元组的元素:可以通过下标进行,
t2[2] #一元元组取元素的用法
t2[2][2]#嵌套元组取元素的方法
元组的方法也有:
index():查找某个数据,如果数据存在返回对应的下标,否则报错
count() 统计某个数据在当前元组出现的次数
len(元组) 统计元组内的元素个数
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是有序存储的(下标索引)
允许重复的数据存在
不许修改
支持for循环
3、字符串
字符串是字符容器,一个字符串可以存放任意数量的字符
字符串也是有下标索引(具体操作和列表、元组一样)
正向:下标从0开始
反向:下标从-1开始
同元组一样,字符串是一个无法修改的数据容器
元组:不能修改指定下标的字符
移除特定下标的字符
追加字符等
均无法完成
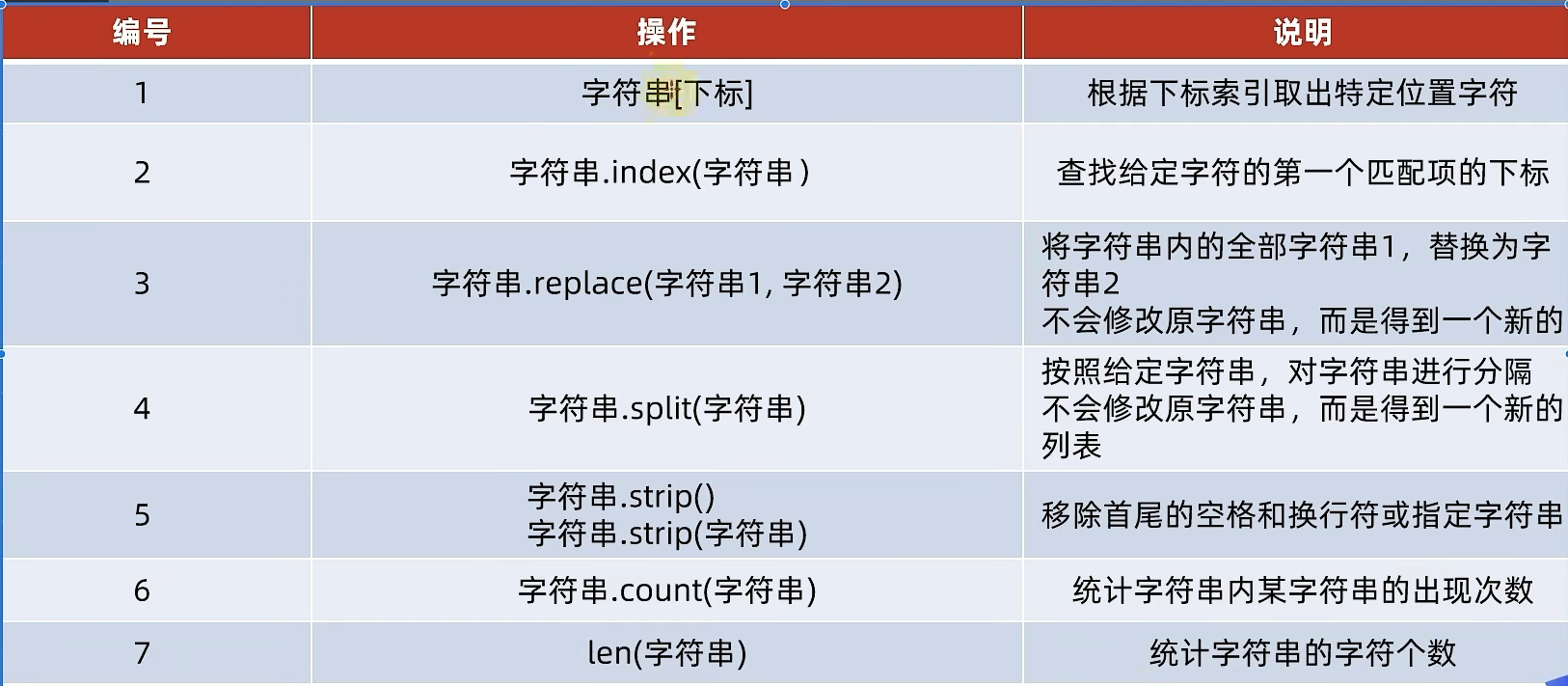
字符串的替换:
字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换成字符串2
不是修改字符串本身,而是得到了一个新字符串
my_str = "itheima and itcast"
value = my_str.replace("it","程序")
print(value)
字符串的分割
语法:
字符串的分割
字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
字符串的规整操作(去前后空格)
字符串.strip()
my_str = "12ithem and iste "
print(my_str.strip())
字符串.strip(字符串)
print(my_str.strip("12"))
删掉字符串里面的1和2
字符串的规则操作:
序列:内容连续、有序、可使用下标索引的一类数据容器
列表、元组、字符串,均可视为序列
语法:序列[起始下标:结束下标:步长]。表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列.
起始下标表示从何处开始,可以留空。留空视为从头开始
结束下标(不含)表示何处结束,可以留空,留空视为截取到结尾
步长为1,一个个取元素
步长为2,每次跳过一个元素取
步长为N表示,每次跳过N-1个元素取
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
result = my_str[::-1] #等同于将序列反转了
result = my_str[3:1:-1] # 倒序输出
其中,列表元组字符串都可以视为序列
split分隔的方式:
result3 = my_str.split(", ")[1].replace("来","")[::-1]
4、集合
集合的语法:
定义集合字面量
{元素,元素,...,元素}
#定义集合变量
变量名称 = {元素,元素,...,元素}
#定义空集合
变量名称 = set()
集合不支持下标索引访问,集合是无序的
但是集合和列表一样,是允许修改的,所以我们来看看集合的修改方法。
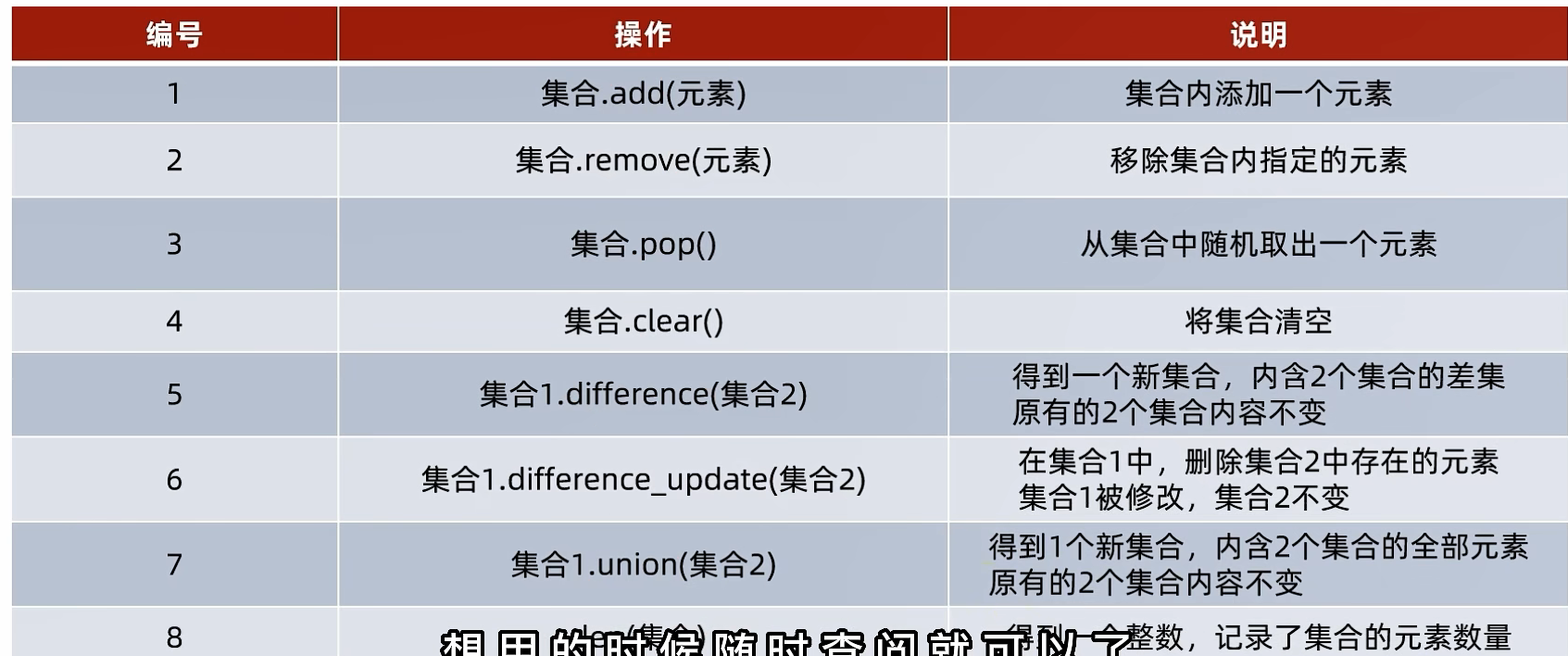
添加新元素
集合.add(元素)。将指定元素,添加到集合内
从集合中随机取出元素
集合.pop(),从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
移除元素
my_set.remove(元素)
把特定的元素移除
清空集合:clear
my_set.clear()
取出2个集合的差集
语法:集合1.difference(集合2),功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
set = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2)
print(set3)
print(set1)
print(set2)
消除差集:
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素
结果:集合1被修改,集合2不变
set = {1,2,3}
set2 = {1,5,6}
set1.difference_update(set2)
print(set3)
print(set1)
print(set2)
两个集合合并
两个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新的集合
结果:得到新集合,集合1和集合2不变
集合的元素的个数
set = {1,2,3,4,5}
num = len(set)
集合的遍历:
集合不支持下标索引,不能用while循环
可以用for循环
set1 = {1,2,3,4}
for element in set1:
print(f"集合的元素{element}")
5、字典
字典的定义:使用{},但是存储的元素是一个个的:键值对,如下语法:
my_dict = {key:valie,key:value,...,key:value}
定义空字典
my_dict = dict()
重复定义key中的字典
my_dict1 = {"王琳":80,"王琳":70,"德华":25}#前面的王琳会被后面的覆盖,字典不允许存在重复内容
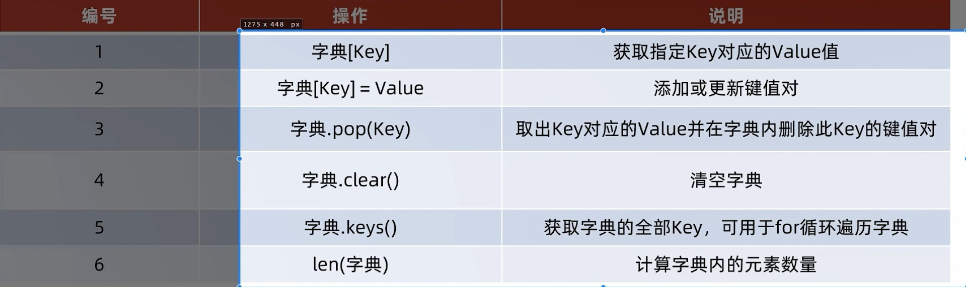
my_dict1["王琳"]#通过key来取value
字典里的key和value可以是任意数据类型(key不可为字典)
字典是可以嵌套的
stu_score_dict = {
"王力宏":{
"语文":88,
"数学":77,
"英语":33
},
"周杰伦":{
"语文":77,
"数学":22
}
}
字典新增元素:
语法:字典[key] = Value,结果:字典被修改,新增了元素
stu_score["张学由"] = 36
print(stu_score)
删除元素:
字典.pop(key),结果:指定key的value,同时字典被修改,指定key的数据被删除
my_dict.clear() #清空字典
#获取全部key的方法: 字典.keys(),结果:得到字典中的全部key
#遍历字典
for key in keys:
print(f"字典的key是:{keys}"")
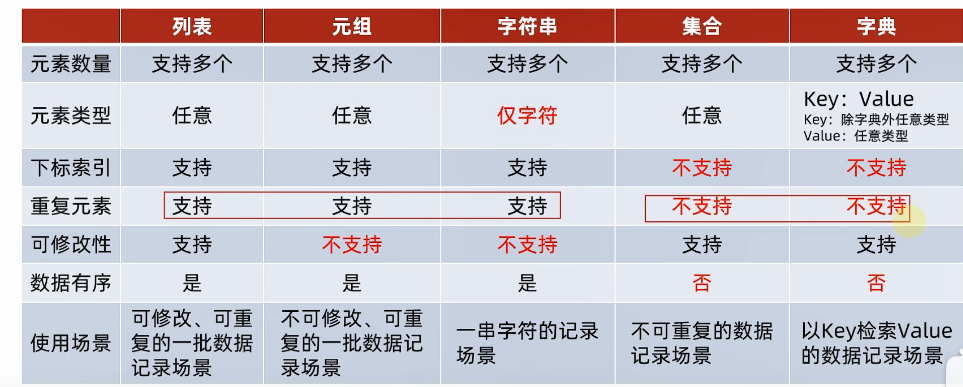
** 是否支持下标索引:
支持:列表、元组、字符串-序列类型
不支持:集合、字典 - 非序列类型
是否支持重复元素
支持:列表、元组、字符串-序列类型
不支持:集合、字典-非序列类型
是否可以修改
支持:列表、集合、字典
不支持:元组、字符串**
len(容器) #返回容器的元素个数
max(容器)#返回容器中的最大元素
min(容器)#统计容器的最小元素
如果是里面的容器是字典的话,那么返回key
容器之间还有强制类型转换
list(容器):将给定容器转换为列表、
str(容器):将给定容器转换为字符串
tuple(容器):将给定容器转换为元组
set(容器):将给定容器转换为集合
将元组和集合转成列表无非就是换了个括号
字符串转列表就是将字符串的每一个字符都取了出来,然后列成了一个列表
将字典转换成列表时,列表的值全部被取消掉了,只保留了keys
转换成字符串时,列表成了看"[1,2,3]"这种外面带了双引号,
通用排序功能:
sorted(容器,[reverse=True]),将给定容器进行排序,排序返回后的值是一个列表,且是排序好的列表
ASCI
a:97
A:65
6、演示使用多个变量
演示使用多个变量,接收多个返回值
def test_return():
return 1,"HELLO",True
x,y,z = test_return()
print(x)
print(y)
print(z)
位置参数:调用函数时根据函数定义的参数位置来传递参数
def user_info(name,age,gender):
print(f"您的名字{name},年龄是{age},性别是{gender}")
关键字传参:
函数调用时通过"键=值"形式传递参数
作用:可以让函数更加清晰、容易使用,同时也消除了参数的顺序需求。
def user_info(name,age,gender):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
#关键字传参
user_info(name = "小明",age = 20,gender = "男")
如果不这样传参,那每个参数设定值必须与要设定的一致,
而关键字传参是不需要遵守这个顺序的。
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用参数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用
def user_info(name,age,gender="男"):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
user_info("TOM",20)
user_info("Rose",18,"女")
设置默认值时,必须将其放到最后
不定长参数:不定长参数也可叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
作用:当调用函数时不确定参数个数时,可以使用不定长参数
1、位置传递
2、关键字传递
1、位置传递
def user_info(*args):
print(args)
#('TOM',)
user_info('TOM')
#('TOM',18)
user_info('TOM',18)
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
关键字传递:
def user_info(**kwargs):
print(kwargs)
user_info(name="TOM",age = 18,id = 110)
参数是"键=值"形式的情况下,所有”键=值“都会被kwargs接收,
同时,根据"键=值"组成字典
函数作为参数进行传递
在前面的函数学习中,我们一直使用的函数,都是接受数据作为参数传入:
- 数字
- 字符串
- 字典、列表、元组等
def test_info(compute):
result = compute(1,2)
print(result)
def compute(x,y)
return x+y
test_info(compute)
这是一种计算逻辑的传递,而非数据的传递。
lambda匿名函数
函数的定义中
def 关键字,可以定义带有名称的函数
lambda 关键字,可以定义匿名函数(无名称)
有名称的函数可以重复使用,无名称的匿名函数,只能临时使用一次
lambda 传入参数:函数体(一行代码)
lambda是关键字:表示定义匿名函数(只能支持一行代码)
传入参数表示匿名函数的形式参数,如:x,y表示接收2个形式参数
函数体:就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
def test_func(compite):
result = compute(1,2)
print(result)
test_func(lambda x,y:x+y) #结果:3
lambda用于只用一次的场景
而要重复使用函数时,最好还是用def进行定义
标签:python,元素,print,day3,元组,字符串,集合,字典 From: https://www.cnblogs.com/lycheezhang/p/17742655.html