概念和作用
C++标准模板库(Standard Template Library,STL)提供了一组通用的模板类和函数,用于处理常见的数据结构和算法。STL中的标准容器是其中的重要组成部分,它们提供了不同的数据结构和操作方式,适用于各种不同的使用场景。
说白了,就是每一种容器代表一种特定的数据结构。我们在学C语言数据结构时,绝大部分数据结构如栈、队列、链表等,都需要我们自己去构造,而STL帮我们构造封装好了,我们可以直接使用。
在C++中我们需要熟悉的常用容器包括:
特点和使用场景
vector
vector 叫向量,我们可以按C语言的数组理解它,vector容器对应的数据结构,是线性表的顺序存储。
1. 内部实现结构
vector是一个连续的动态数组,它在内存中以连续的方式存储元素,这使得在向量中进行随机访问非常高效,因为当我们需要访问一个位置的元素是,只需要根据首地址、位置和数据字节大小就可以计算出待访问位置的数据地址。
vector需要的内存块是连续的,它通常需要比实际元素数量更多的内存空间。当元素数量超过当前容量时,向量会自动重新分配更大的内存块,并将元素复制到新的内存中。
示意图如下
| vector | 地址 |
|---|---|
| 元素1 | 0x0000 |
| 元素2 | 0x0004 |
| 元素3 | 0x0008 |
| 元素4 | 0x0012 |
| 元素5 | 0x0016 |
| 元素6 | 0x0020 |
| 元素7 | 0x0024 |
2. 性能和效率
Search
线性访问操作,由于元素地址可以直接计算出来,所以时间复杂度为O(1)
Insert/Remove
在向量的末尾进行插入和删除操作非常高效(push back()),时间复杂度为O(1)。但在中间位置进行插入和删除操作的性能较差,需要移动元素,时间复杂度为O(n)。
以插入为例:
| 插入前vector | 地址 | 插入后vector | 地址 | |||
|---|---|---|---|---|---|---|
| 元素1 | 0x0000 | 元素1 | 0x0000 | |||
| 元素2 | 0x0004 | 元素2 | 0x0004 | |||
| 元素3 | 0x0008 | 插入元素 | 0x0008 | |||
| 元素4 | 0x0012 | 元素3 | 0x00012 | |||
| 元素5 | 0x0016 | 元素4 | 0x00016 | |||
| 元素6 | 0x0020 | 元素5 | 0x00020 | |||
| 元素7 | 0x0024 | 元素6 | 0x00024 | |||
| 元素7 | 0x00028 |
可以看出,元素3及之后的元素都要进行向后移动,删除也一样,删除位置及之后的元素都要向前移动
3. 使用场景
需要高效的随机访问和动态大小调整的容器时,可选择选vector。它适用于需要频繁访问元素、在末尾插入和删除元素的场景。
4. 常用操作
- 在末尾插入元素:使用
push_back(value)函数将元素添加到向量的末尾。 - 在指定位置插入元素:使用
insert(pos,value)函数在向量的指定位置插入元素,pos为迭代器。 - 访问元素:使用索引运算符(
[])或迭代器(*it)来访问向量中的元素。 - 获取向量大小:使用
size()函数获取向量中的元素数量。 - 动态调整向量大小:向量会根据需要自动调整大小,也可以使用
resize()函数手动调整大小
array
array和vector类似,是一个数组,但它是一个固定长度的数组,不可改变大小,相比而言,vector则是一个动态数组,可以动态改变大小。
1. 内部实现结构
和vector类似,区别就是array长度固定,而且比数组安全,不用担心越界。但是内容在栈上,属于定长容器。
2. 性能和效率
访问时和vector一样,时间复杂度是O(1),对于插入和删除,由于array的大小固定,无法在中间位置插入或删除元素。只能通过直接赋值或使用fill()函数来修改元素的值。
list
list是链表,准确的说,应该是双向链表。也就是线性表的链式存储这一数据结构。
1. 内部实现结构
链表是使用节点来存储元素,每个节点都包含一个值以及指向前一个节点和后一个节点的指针。由于list使用链表结构,它不需要连续的内存块,因此在内存占用方面相对灵活,每个节点都需要额外的内存来存储指针,指向下一个节点。节点间的地址大不是连续的。
list双向链表示意图如下
graph LR 头节点<-->节点1<-->节点2 节点2<-->节点3<-->节点42. 性能和效率
Search
由于链表的特性,list不支持高效的随机访问,由于节点间地址不连续,无法计算特定位置的节点地址,而每个节点又只存储着下一节点的地址,所以要访问特定位置的元素,需要从头节点或尾节点开始遍历链表,时间复杂度为O(n)。
Insert/Remove
在list中进行插入和删除操作效率比vector高,时间复杂度为O(1)。因为只需要调整相邻节点的指针。
删除操作也一样。
graph LR 节点n-.->节点n+1-.->节点n+2 节点n-->节点n+23. 使用场景
当需要频繁进行插入和删除操作,而不需要频繁随机访问元素时,可以选择list。它适用于需要在任意位置插入和删除元素的场景。
4. 常用操作
- 在指定位置插入元素:使用
insert(pos,value)函数在链表的指定位置插入元素(pos为迭代器)。 - 在末尾插入元素:使用
push_back(value)函数将元素添加到链表的末尾。 - 在开头插入元素:使用
push_front(value)函数将元素添加到链表的开头。 - 删除指定位置的元素:使用
erase(pos)函数删除链表中指定位置的元素。 - 访问元素:使用迭代器来遍历链表并访问元素。
for(std::list<int>::iterator it = mylist.begin(); it != mylist.end(); it++){ std::cout<<*it<<std::endl; } - 获取链表大小:使用
size()函数获取链表中的元素数量。
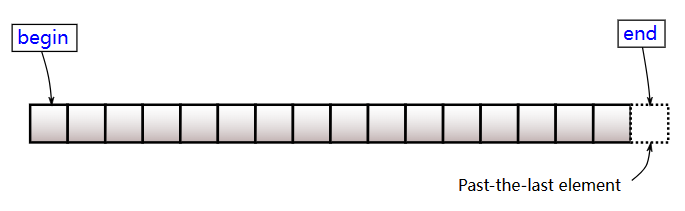
补充:为什么迭代器遍历判断条件是it != mylist.end()?看下图就会明白了:
deque
deque容器,是双端动态数组,也叫双端队列,可以对头端和尾端进行插入删除操作。
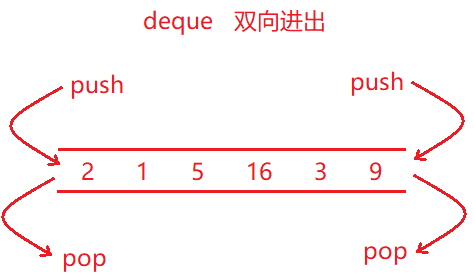
1. 内部实现结构
如上图,deque内部有个中控器,维护每段缓冲区,每个缓冲区都是一个固定大小的数组,用于存储一部分元素,中控器维护的是每个缓冲区的地址,使得使用deque时像一片连续的内存空间。实际deque类似于一个动态的二维数组
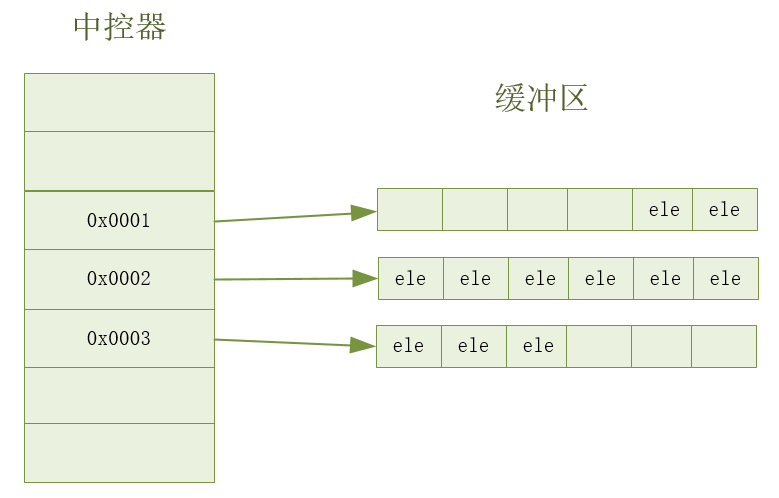
由于deque使用多个缓冲区,它可以根据需要动态增长。当需要插入更多元素时,deque会分配新的缓冲区,因此它的内存占用可以根据实际元素数量进行调整。
换句话说,中控器是连续存储的空间,存储着缓冲区的地址。每个缓冲区之间地址不连续,但同一个缓冲区就是一个固定大小的数组。所以deque每一个元素的位置都可以计算出来,看起来就是连续的内存空间
2. 性能和效率
Search
deque对随机访问操作也是具有高效率的,时间复杂度为O(1)。
原因是:deque会根据索引计算出对应的缓冲区和元素位置。具体的计算过程如下:
- 首先,
deque会根据索引计算出元素所在的缓冲区。由于每个缓冲区的大小是固定的,可以通过索引除以缓冲区大小来得到所在的缓冲区的索引。 - 接下来,
deque会根据缓冲区索引找到对应的缓冲区,并通过指针跳转到该缓冲区。 - 最后,
deque会根据元素在缓冲区中的位置进行偏移,以获取正确的元素。
Insert/Remove
deque可以根据计算直接在两端进行插入和删除操作,时间复杂度为O(1)。
当需要在中间插入或删除元素时,就和vector类似,需要移动元素了,这种情况下的时间复杂度为O(n)
3. 使用场景
deque适用于需要在两端频繁进行插入和删除操作的场景。它可以作为一个高效的双端队列使用,允许在队头和队尾进行快速插入和删除操作。
4. 常用操作
- 在头部插入元素:使用
push_front(value)函数将元素添加到deque的头部。 - 在尾部插入元素:使用
push_back(value)函数将元素添加到deque的尾部。 - 在头部删除元素:使用
pop_front()函数从deque的头部删除元素。 - 在尾部删除元素:使用
pop_back()函数从deque的尾部删除元素。 - 访问两端元素:使用
front()和back()函数访问两端元素。 - 访问元素:使用索引运算符(
[])或迭代器来访问deque中的元素。 - 获取
deque大小:使用size()函数获取deque中的元素数量。
queue
queue,队列,是一种先入先出(FIFO)的数据结构,队尾进,队头出,访问也只能访问头部和尾部。示意图如下

1. 内部实现结构
queue是在deque的基础上进行封装的,基于deque实现,它的内存占用和deque相似,可以根据实际元素数量进行调整。
也就是说,queue是进一步封装的数据结构,内部实现和底层数据结构类似,只是多了一些功能或限制。
2. 性能和效率
Search
由于queue是一个队列,不支持随机访问,没有迭代器,不具备遍历功能,只能查看队头和队尾元素。
Insert/Remove
同理,不具备随机插入和删除功能,只能队尾插入,队头删除。
3. 使用场景
当需要按照先进先出的顺序处理元素时可选择。queue适用于模拟排队、任务调度等场景
4. 常用操作
- 在队尾插入元素:使用
push(value)函数将元素添加到队列的尾部。 - 在队头删除元素:使用
pop()函数从队列的头部删除元素。 - 访问队头元素:使用
front()函数获取队列的头部元素。 - 访问队尾元素:使用
back()函数获取队列的尾部元素。 - 检查队列是否为空:使用
empty()函数检查队列是否为空。 - 获取队列大小:使用
size()函数获取队列中的元素数量。
stack
stack,栈,是一种先入后出(FILO)的数据结构,只有一个出入口,那就是栈顶。栈顶插入数据叫入栈、弹出数据叫出栈。示意图如下
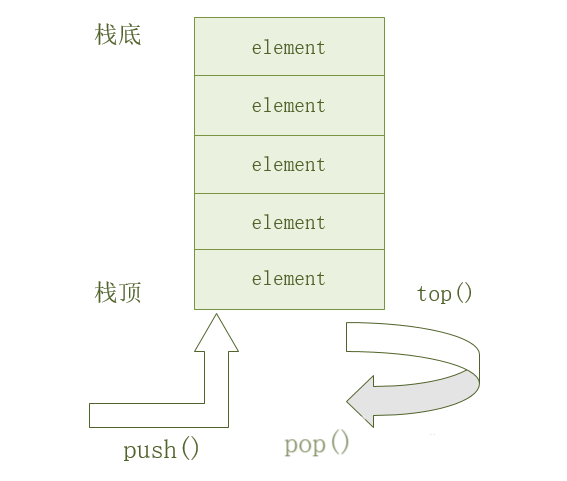
作为栈结构,stack也不支持不支持随机访问,只能在栈顶插入和删除元素,时间复杂度为O(1)。
1. 内部实现结构
和queue类似,stack也是进一步封装规定的数据结构,可以在deque、list 或 vector)的基础上进行封装的。因此内存占用与内部实现和底层数据结构一样。
在STL中,默认构造的的stack是以deque为底层容器的;
std::stack<T> myStack; // T 是元素类型,例如 int、double 等
当然也可以显示构造,指定底层容器
std::stack<T, std::vector<T>> myStack; // 使用 vector 作为底层容器
2. 使用场景
当需要按照后进先出的顺序处理元素时选择,栈也可适用于需要实现逆序操作、括号匹配、表达式求值等场景。
3. 常用操作
- 在栈顶插入元素:使用
push(value)函数将元素添加到栈的顶部。 - 在栈顶删除元素:使用
pop()函数从栈的顶部删除元素。 - 访问栈顶元素:使用
top()函数获取栈的顶部元素。 - 检查栈是否为空:使用
empty()函数检查栈是否为空。 - 获取栈的大小:使用
size()函数获取栈中的元素数量。
map
map是STL的一个关联容器,它提供一对一的hash.
- 第一个可以称为键(key),每个键只能在map中出现一次;
- 第二个可能称为该键的值(value);
1. 内部实现结构
map使用红黑树(Red-Black Tree)作为底层数据结构。红黑树是一种自平衡的二叉搜索树,具有良好的查找、插入和删除性能。
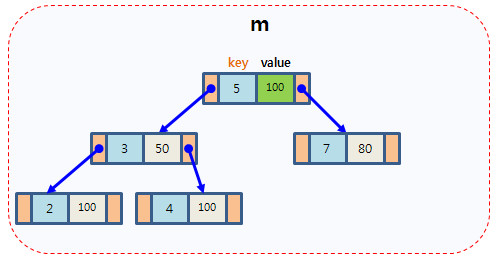
数的每个节点包括键、值、左孩子和右孩子节点指针。
2. 键的唯一性和有序性
map中的键是唯一的,每个键只能对应一个值。如果尝试插入具有相同键的元素,旧的元素将被新的元素替换。
map中的键值对按照键的有序性进行存储。这使得可以在map中进行范围查找、按键排序等操作。
3. 性能和效率
Search
map提供了对数时间复杂度的查找操作。红黑树的自平衡性质使得在树上进行查找操作的时间复杂度为 O(log n),其中 n 是元素的数量。
Insert/Remove
插入和删除操作也具有对数时间复杂度。通过红黑树的自平衡性质,插入和删除操作的时间复杂度为 O(log n)
4. 使用场景
当需要高效地存储大量键值对,并且需要按照键的有序性进行访问时,可选择map。它适用于需要快速查找、范围查找和按键排序的场景。
5. 常用操作
- 插入元素:将键值对插入容器中。但由于红黑树的性质,
map中的元素是按照键的有序性进行存储的,并不会按照插入的顺序进行存储。个人感觉1和2方法比较方便。1. mymap[key] = value; 2. mymap.insert({key,value}); 3. mymap.insert(pair<int, string>(key, value)); 4. mymap.insert(map<int, string>::value_type(key, value)); - 删除元素:使用
erase(iter)或erase(key)从容器中删除元素,iter为迭代器。 - 查找元素:
1. 使用`find(key)`函数查找特定键对应的键值对位置,返回迭代器类型。 map<string,int>::iterator it = mymap.find(key); it->first 是key it->second 是value - 检查容器是否为空:使用
empty()函数检查容器是否为空。 - 获取容器中的元素数量:使用
size()函数获取容器中的元素数量。 - 迭代访问元素:使用迭代器进行范围遍历或按键顺序遍历。
for(auto it = mymap.begin();it!=mymap.end();it++){ cout<<it->first<<endl; cout<<it->second<<endl; }
### map的自定义排序
```C++
#include<bits/stdc++.h>
using namespace std;
//对于map中的key进行paixu
struct rule{
bool operator()(string a,string b){
return a>b;//对于键是string型按照从大到小排
}
};
int main()
{
//map中的第三个参数其实就是排序规则,之前不写就会默认成默认排序
map<string,int,rule>m;
m["asas"]=199;
m["zx"]=99;
m["gsgus"]=878;
m["yuy"]=1515;
map<string,int,rule>::iterator it;
for(it=m.begin();it!=m.end();it++){
cout<<it->first<<" "<<it->second<<endl;
}
return 0;
}
C++中的map排序_c++ map排序_菜到极致就是渣的博客-CSDN博客
set
set,集合。其实与map做比较的话,可以理解为set里的元素就是map里的key,它和map使用的底层数据结构都一样,都是红黑树。
1. 元素的唯一性和有序性
set中的元素是唯一的,每个元素只能出现一次。如果尝试插入已经存在的元素,插入操作将被忽略。
set中的元素按照它们的有序性进行存储。这使得可以在set中进行范围查找、按元素排序等操作
2. 性能和效率
和map一样
3.使用场景
当需要存储一组唯一元素,并且需要按照元素的有序性进行访问时,可选择set。它适用于需要快速查找、范围查找和按元素排序的场景。
4. 常用操作
- 插入元素:使用
insert(value)函数将元素插入容器中。由于红黑树的性质,set中的元素是按照它们的有序性进行存储的,并不会按照插入的顺序进行存储。 - 删除元素:使用
erase(value)或erase(iter)从容器中删除元素。 - 查找元素:使用
find(value)函数查找特定元素,返回迭代器。 - 检查容器是否为空:使用
empty()函数检查容器是否为空。 - 获取容器中的元素数量:使用
size()函数获取容器中的元素数量。 - 迭代访问元素:使用迭代器进行范围遍历或按元素顺序遍历。
for(auto it = myset.begin();it!=myset.end();it++){ cout<<*it<<endl; }
multimap
multimap和map的最大区别是,multimap可以存在相同的键key,其它用法原理应该和map一样的,头文件也是<map>
multiset
multiset和set的区别是,multiset可以存在相同的元素value,其它用法原理和set一样,头文件也是<set>。感觉用对元素排序很方便。自定义排序规则和map小节介绍的一样。
标签:容器,删除,deque,STL,元素,C++,插入,map,节点 From: https://www.cnblogs.com/gofan-SiTu/p/17739136.html