算法通关村第一关——链表青铜挑战笔记
链表是一种经典的数据结构,在很多软件里大量使用,例如操作系统、JVM等。
在面试中链表题目数量少,类型也相对固定,考察频率却非常高,因此我们只要将常见题目都学完就万事大吉了,所以链表特别值得刷。
单链表的概念
链表的概念
单向链表就像一个铁链一样,元素之间相互连接,包含多个结点,每个结点有一个指向后继元素的指针。表中最后一个元素的next指向null。如下图:

练习:判断下图是否是单链表。
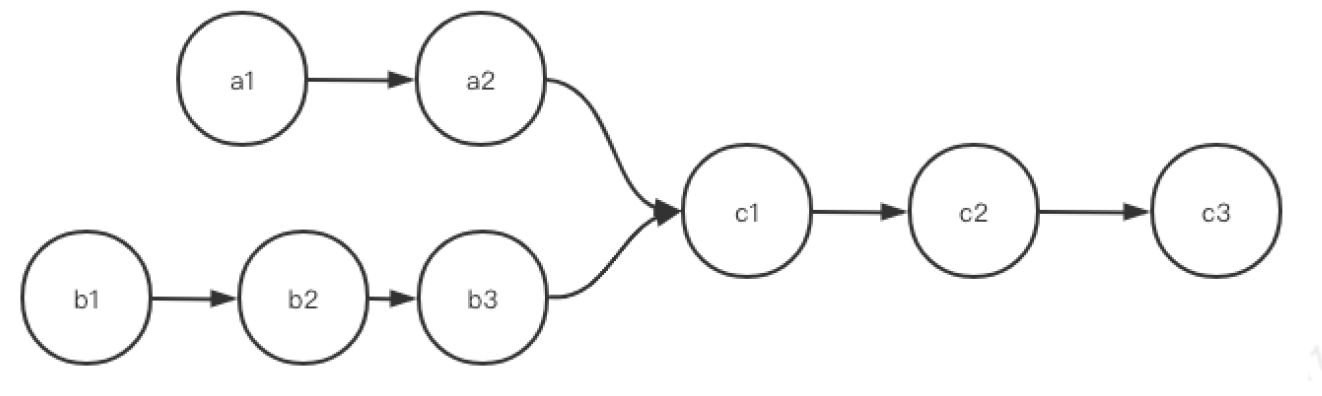
解析:满足单链表的要求:因为单链表要求环环相扣,核心是一个结点只能有一个后继,但不代表一个节点只能有一个被指向。上图中,c1被a3和b2同时指向,这是没关系的。举个例子:法律上倡导一夫一妻制度,你只能爱一个人,但是可以有多个人爱你。
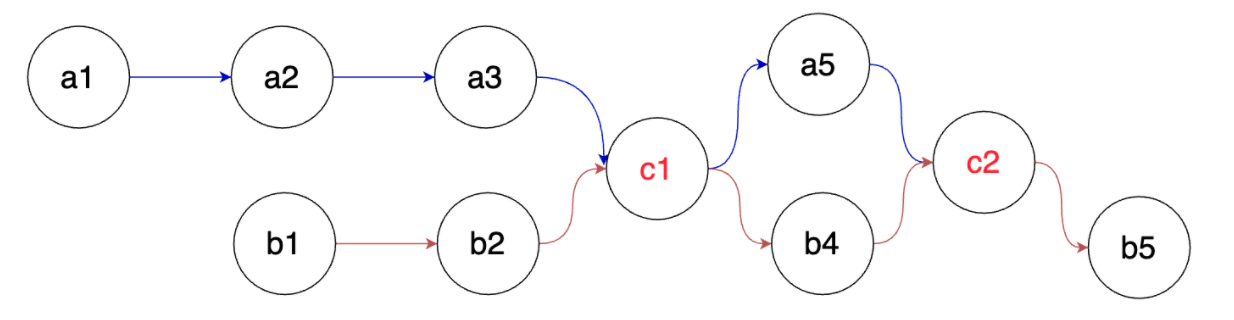
解析:上图(第二张图)就不满足单链表的要求了。因为c1有两个后继a5和b4。
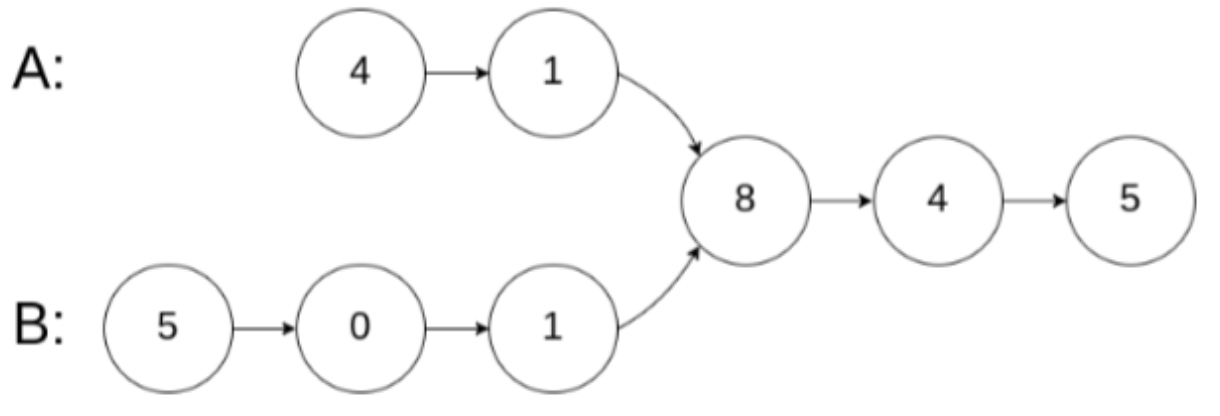
另外在做题的时候要注意比较的是值还是结点,有时可能两个节点的值相等,但并不是同一个结点,例如下图:
有两个结点的值都是1,但并不是同一个结点。
链表的相关概念
结点和头结点
在链表中,每一个点都由值和指向下一个节点的地址组成的独立的单元,称为一个结点,有时也称为节点,含义都是一样的。
对于单链表,如果知道了第一个元素,就可以通过遍历访问整个链表,因此第一个节点最重要,一般称为头节点。
虚拟节点
在做题以及在工程里经常会看到虚拟节点的概念,其实就是一个节点dummyNode,其next指针指向head,也就是dummyNode.next = head。
因此,如果我们在算法里使用了虚拟节点,则要注意如果要获得head节点,或者从方法(函数)里返回的时候,则应使用dummyNode.next。
另外注意,dummyNode的val不会被使用,初始化为0或-1都是可以的。既然值不会使用,那虚拟节点有啥用呢?简单来说,就是为了方便我们处理首部节点,否则我们需要在代码里单独处理首部节点的问题。在链表反转里,我们会看到该方法可以大大降低解题难度。
创建链表
我们继续看如何构建链表。
首先要理解JVM是怎么构建出链表来的,我们知道JVM中有栈区和堆区,栈区主要存引用,也就是一个指向实际对象的地址,而堆区存的才是创建的对象,例如,我们定义这样一个类:
public class Course{
Teacher teacher;
Student student;
}
这里的teacher和student就是指向堆的引用,假如我们这样定义:
public class Course{
int val;
Course next;
}
这时候next就指向了下一个同为Course类型的对象了,例如:
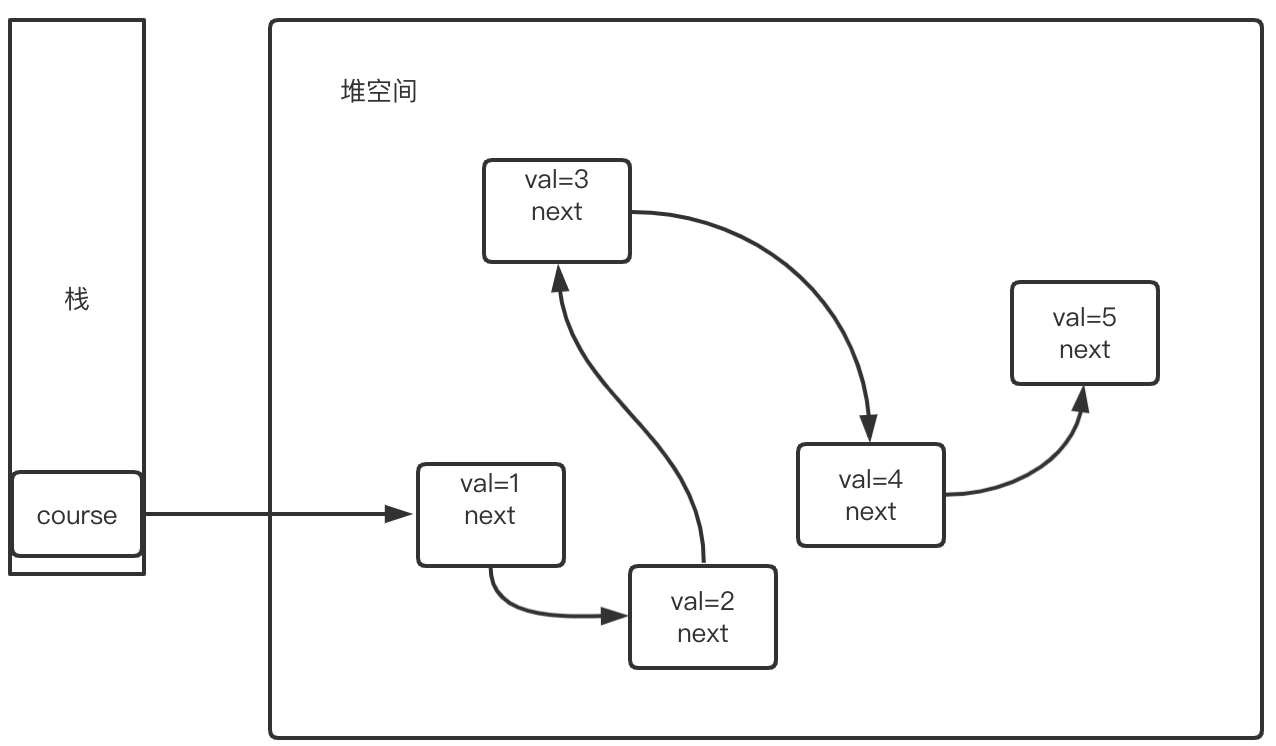
这里通过栈中的引用(也就是地址)就可以找到val(1),然后val(1)节点又存了指向val(2)的地址,而val3又存了指向val4的地址,所以就构造出了一个链条访问结构。
在Java配套代码中的BasicLink类,我们debug一下看一下从head开始next会发现是这样的:
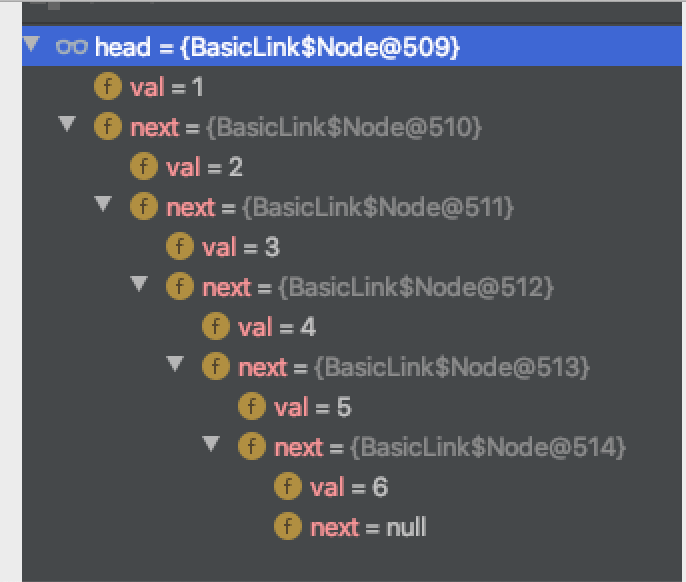
这就是一个简单的线性访问了,所以链表就是从head开始,逐个开始向后访问,而每次访问的对象类型都是一样的。
根据面向对象的理论,在Java里规范的链表应该这么定义:
public class ListNode{
private int data;
private ListNode next;
public ListNode(int data){
this.data = data;
}
public int getData(){
return data;
}
public void setData(int data){
this.data = data;
}
public ListNode getNext(){
return next;
}
public void setNext(ListNode next){
this.next = next;
}
}
但是在LeetCode中算法题中经常使用这样的方式来创建链表:
public class ListNode{
public int val;
public ListNode next;
ListNode(int x){
val = x;
//这个一般作用不大,写了会更加规范。
next = null;
}
}
ListNode listnode = new ListNode(1);
这里的val就是当前节点的值,next指向下一个节点。因为两个变量都是public的,创建对象后能直接使用listnode.val和listnode.next来操作,虽然违背了面向对象的设计要求,但是上面的代码更为精简,因此在算法题目中应用广泛。
链表的增删改查
遍历链表
对于单链表,不管进行什么操作,一定是从头开始逐个向后访问,所以操作之后是否还能找到表头非常重要。一定要注意“熊瞎子掰棒子”问题,也就是只顾当前位置而将标记标头的指针丢掉了。

代码如下:
public static int getListLength(Node head){
int length = 0;
Node node = 0;
while (node != null){
length++;
node = node.next;
}
return length;
}
链表插入
单链表的插入和数组的插入一样,过程不复杂,但是在编码时会发现处处是坑。
单链表的插入操作需要考虑三种情况:首部、中部和尾部。
在链表的表头插入
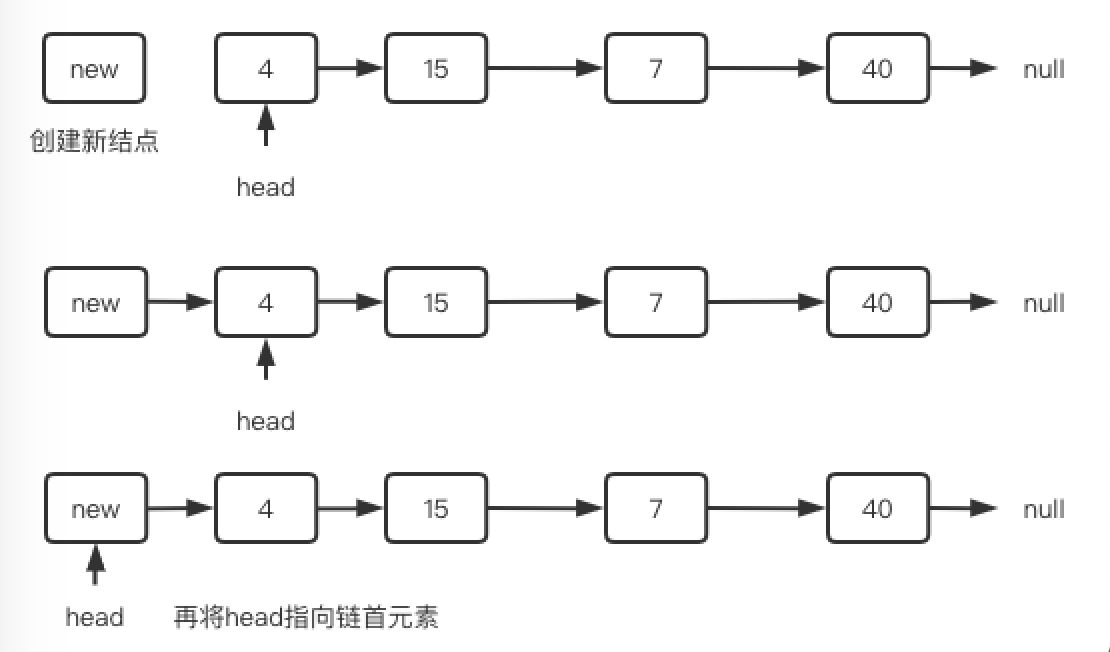
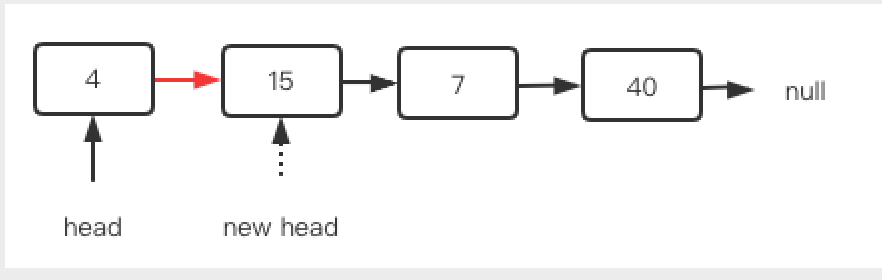
链表表头插入新结点非常简单,容易出错的是经常会忘了head需要重新指向表头。我们创建一个新结点newNode,怎么连接到原来的链表上呢?执行newNode.neXt = head即可。之后我们要遍历新链表就要从newNode开始一路next向下了是吧,但是我们还是习惯让head来表示,所以让head = newNode 就行了,如下图:
在链表中间插入
在中间位置插入,我们必须先遍历找到要插入的位置,然后将当前位置接入到前结点和后继结点之间,但是到了该位置之后我们却不能获得前驱结点了,也就无法将结点接入进来了。这就好比一边过河一边拆桥,结果自己也回不去了。
当你想往一个排列好的列表中插入一个新的东西,就好比在一座桥上行走,然后突然想在桥的中间加点东西。但是,一旦你走过了桥上的某个位置,你就无法回到那个位置了,也不知道在哪里插入新东西。
就是等你遍历到要插入的位置时候,这时就不能操作他的前一个节点了,相当于一边过河一边拆桥,结果自己也回不去了。不能够完成插入操作。
这是因为在列表中,你只能往前走,不能后退。如果你需要在列表中插入东西并且知道插入位置的前一个位置,就像在桥上留下路标,这样你就能随时回到那个位置,然后在那里插入新东西。
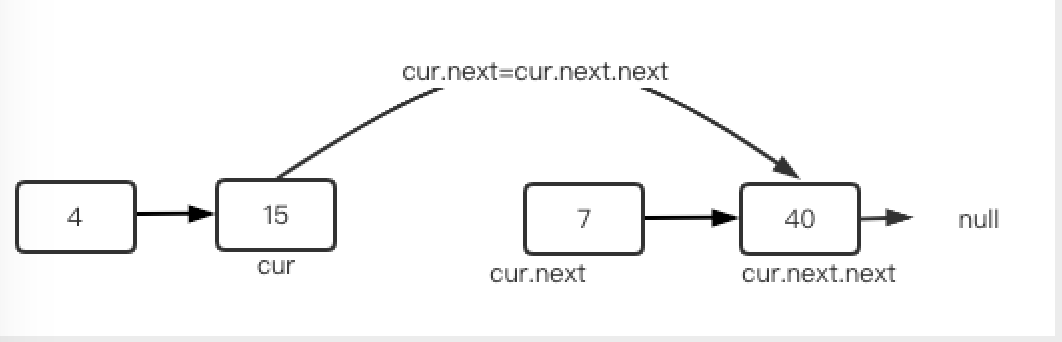
为此,我们要在目标结点的前一个位置停下来,也就是使用cur.neXt的值而不是cur的值来判断,这是链表最常用的策略。
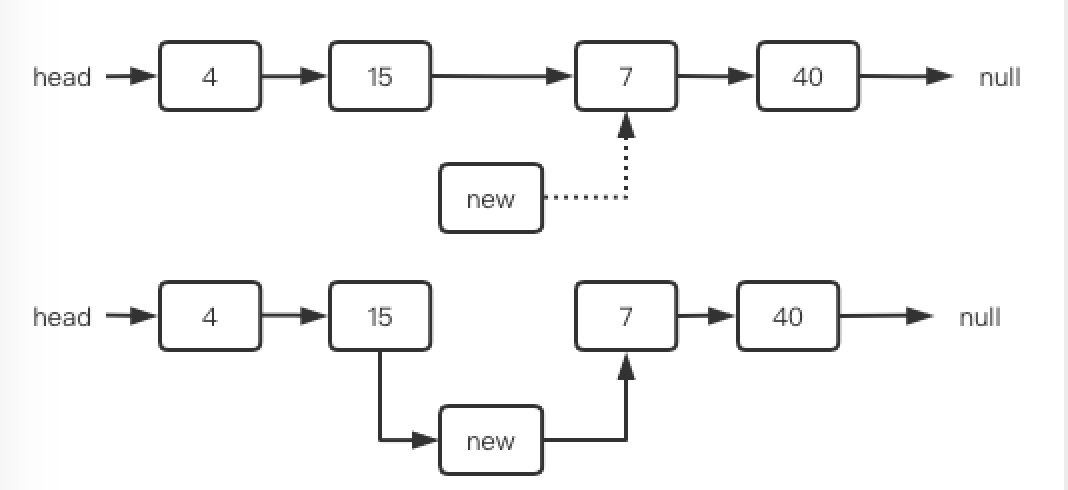
例如下图中,如果要在7的前面插入,当cur.next=node(7)了就应该停下来,此时cur.val=15。然后需要给newNodei前后接两根线,比时只能先让new.next=node(15).next(图中虚线),然后node(15).next=new,而且顺序还不能错。
想一下为什么不能颠倒顺序?
解答:
由于每个节点都只有一个next,因比执行了node(15).next=new之后,结点15和7之间的连线就自动断开了,如下图所示:
在链表的结尾插入节点
链表结尾插入就比较容易了,只需要将尾结点指向新节点就可以了。
综上所述,我们可以写出链表插入的方法的Java代码如下所示:
链表删除
删除同样分为删除头部元素,删除中间元素和删除尾部元素。
删除表头结点
删除头部元素还是非常简单的,一般只需要执行head = head.next 就行了。如下图,将head向前移动一次之后,原来的结点不可达,会被JVM回收掉。
删除最后一个节点
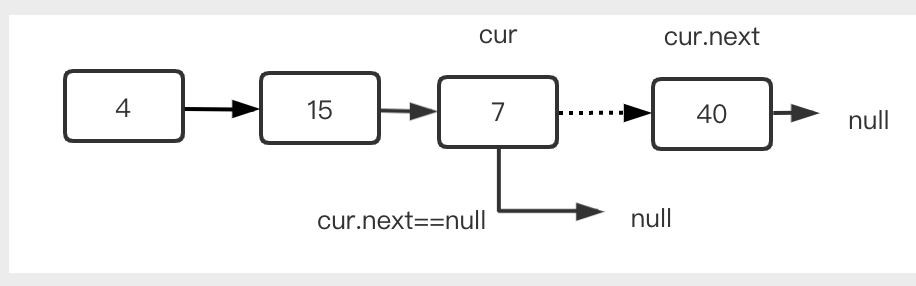
删除的过程不算复杂,也是要找到删除的节点的前驱节点,这里同样要提前一个位置判断,例如下图中删除40,他的前驱结点为7.便利的时候就要判断cur.next是否为40,如果是,则只要执行cur.next = null即可,此时结点40变得不可达,最终会被JVM回收掉。
删除中间结点
删除中间结点的时候,也要用cur.next来进行比较,找到位置后,将cur.next指针的值更新为cur.next.next就可以解决,如下图所示: