CPU执行程序的过程
目录前言/基础知识
CPU 并不能直接执行这段 C 代码,而是需要对其进行编译,将其转换为二进制的机器码(hex文件是十六进制的机器码,这里的hex文件和嵌入式软件中的hex不太一样,这里的hex文件不带格式,一行是16bit数据),然后 CPU 才能按照顺序执行编译后的机器码。
编译好hex后,仿真是怎么跑起来的?
hex是要放到对应地址的内部ram里面去,然后CPU rst释放后,CPU就会执行ram里面的程序,然后按照之前C代码写的去执行对应的行为(配置寄存器,读写memory等等)
hex为什么要放到对应地址的ram里去?
因为代码是从某个固定的地址开始执行的,代码是要规定它的执行位置的。
C代码编译出来要是在2000起始地址去开始执行的,如果放到3000地址,它就不能正常执行。(涉及到CPU寻址原理,CPU寻址包括绝对寻址,相对寻址,是跟起始位置有关的。完全一样的代码什么都不改,就换一个内存位置,它就不能正常执行)
机器码谁都看不懂,所以要将编译出来的 可执行程序进行反汇编,这样就可以看到二进制代码和对应的汇编代码。
通常将汇编语言编写的程序转换为机器语言的过程称为“汇编”;反之,机器语言转化为汇编语言的过程称为“反汇编”
反汇编后编译出来的机器码如下:
0000000100003f84 <_main>:
100003f84: ff 43 00 d1 sub sp, sp, #16 // 开辟栈空间。即开辟了四个 4 字节空间
100003f88: ff 0f 00 b9 str wzr, [sp, #12] // 将 wzr 寄存器的数据存储到 sp 寄存器的 #12 地址上,设为0
100003f8c: 28 00 80 52 mov w8, #1 // 创建一个 x = 1,并将 1 存入 w8 寄存器中
100003f90: e8 0b 00 b9 str w8, [sp, #8] // 将 w8 寄存器的数据存入 sp 寄存器中 #8 的地址中,也就是将 x = 1 存入
100003f94: 48 00 80 52 mov w8, #2 // 创建一个 y = 2,并将 2 存入 w8 寄存器中
100003f98: e8 07 00 b9 str w8, [sp, #4] // 将 w8 寄存器的数据存入 sp 寄存器中 #4 的地址中,也就是将 y = 2 存入
100003f9c: e8 0b 40 b9 ldr w8, [sp, #8] // 读取 sp 寄存器中 #8 的数据存入 w8 寄存器中,也就是获取 x = 1
100003fa0: e9 07 40 b9 ldr w9, [sp, #4] // 读取 sp 寄存器中 #4 的数据存入 w9 寄存器中,也就是获取 y = 2
100003fa4: 08 01 09 0b add w8, w8, w9 // 将 w8、w9 寄存器的 x,y 数据进行相加,并存入 w8 寄存器中,也就是 z = 3
100003fa8: e8 03 00 b9 str w8, [sp] // 将 w8 寄存器的数据存入 sp 寄存器中
100003fac: e0 03 40 b9 ldr w0, [sp] // 读取 sp 寄存器中的数据存到 w0 寄存器中。z = 3
100003fb0: ff 43 00 91 add sp, sp, #16 // 清空开辟的栈空间
100003fb4: c0 03 5f d6 ret // 返回结果
可以观察到上图是由很多行组成的,每一行都是一个指令,该指令可以让 CPU 执行指定的任务。
中间的部分是汇编代码,例如原本是二进制表示的指令,在汇编代码中可以使用单词来表示,比如 mov、add 就分别表示数据的存储和相加。
这一大堆指令按照顺序集合在一起就组成了程序,所以程序的执行,本质上就是 CPU 按照顺序执行这一大堆指令的过程。
汇编语言程序从设计到形成可执行程序文件,在计算机上的操作过程分为三步:编辑、汇编、连接。用文本编辑程序写程序,形成
.ASM文件,用汇编程序对.ASM文件进行汇编,形成.OBJ文件,再用连接程序对.OBJ文件进行连接,形成.EXE文件。编辑
新建一个名为
HELLO.ASM的文件,用文本编辑器将源程序写入该文件中。汇编
汇编程序的作用是把汇编语言源程序翻译成为机器代码,产生二进制格式的目标文件(Object File)
连接
连接就是使用连接程序LINK把目标文件(OBJ)转换为可执行的EXE文件。
来自RISC-V-Reader-Chinese-v2p12017.pdf

为了更好的分析程序的执行过程,我们还需要了解一下基础的计算机硬件信息
具体如下图:
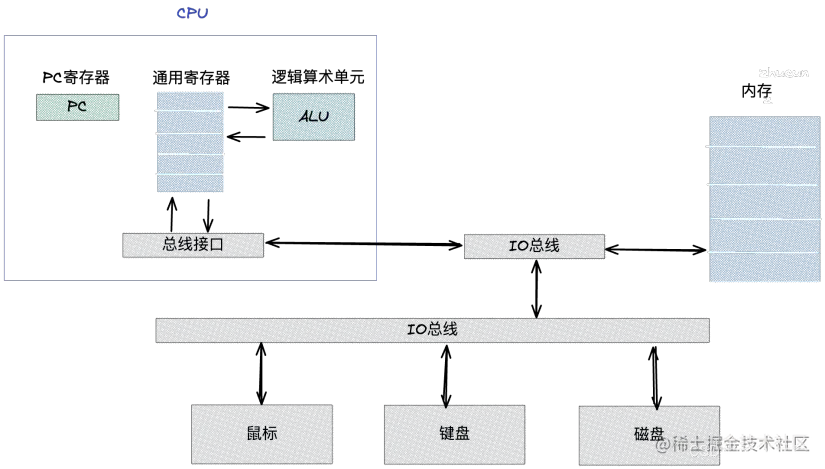
这张图是比较通用的系统硬件组织模型图,它主要是由 CPU、主存储器、各种 IO 总线,还有一些外部设备组成的。
首先,在一个程序执行之前,程序需要被装进内存。
CPU 可以通过指定内存地址,从内存中读取数据,或者往内存中写入数据,有了内存地址,CPU 和内存就可以有序地交互。
内存中的每个存储空间都有其对应的独一无二的地址:

在内存中,每个存放字节的空间都有其唯一的地址,而且地址是按照顺序排放的。
以开头代码为例,这段代码会被编译成可执行文件,可执行文件中包含了二进制的机器码,当二进制代码被加载进了内存后,那么内存中的每条二进制代码便都有了自己对应的地址,如下图所示:
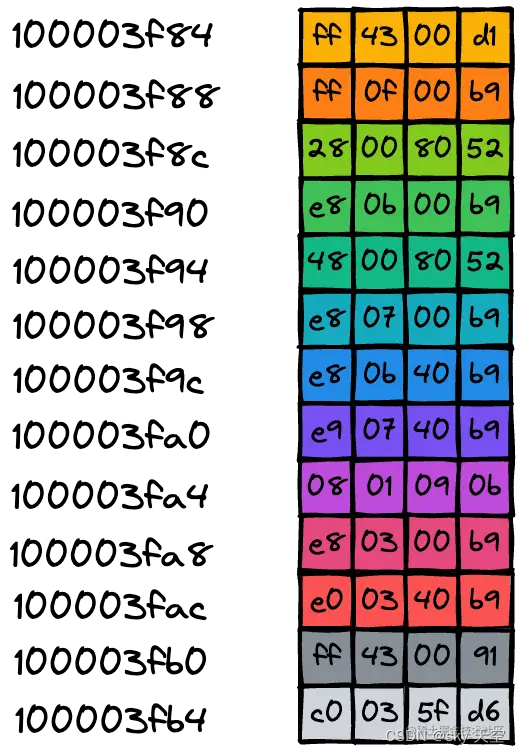
一旦二进制代码被装载进内存,CPU 便可以从内存中取出一条指令,然后分析该指令,最后执行该指令。
把取出指令、分析指令、执行指令这三个过程称为一个 CPU 时钟周期。CPU 是永不停歇的,当它执行完成一条指令之后,会立即从内存中取出下一条指令,接着分析该指令,执行该指令,CPU 一直重复执行该过程,直至所有的指令执行完成。
CPU 是怎么知道要取出内存中的哪条指令呢?:
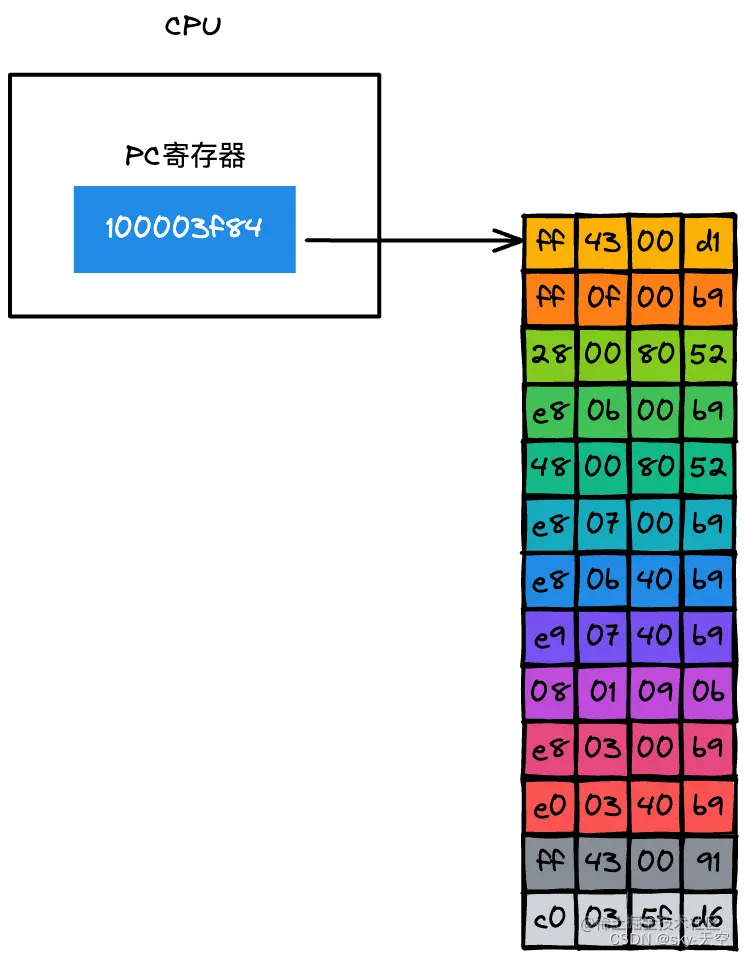
从上图可以看到 CPU 中有一个 PC 寄存器,它保存了将要执行的指令地址,当二进制代码被装载进了内存之后,系统会将二进制代码中的第一条指令的地址写入到 PC 寄存器中,到了下一个时钟周期时,CPU 便会根据 PC 寄存器中的地址,从内存中取出指令。
PC 寄存器中的指令取出来之后,系统要做两件事:
- 第一件是将下一条指令的地址更新到 PC 寄存器中,如下图所示:
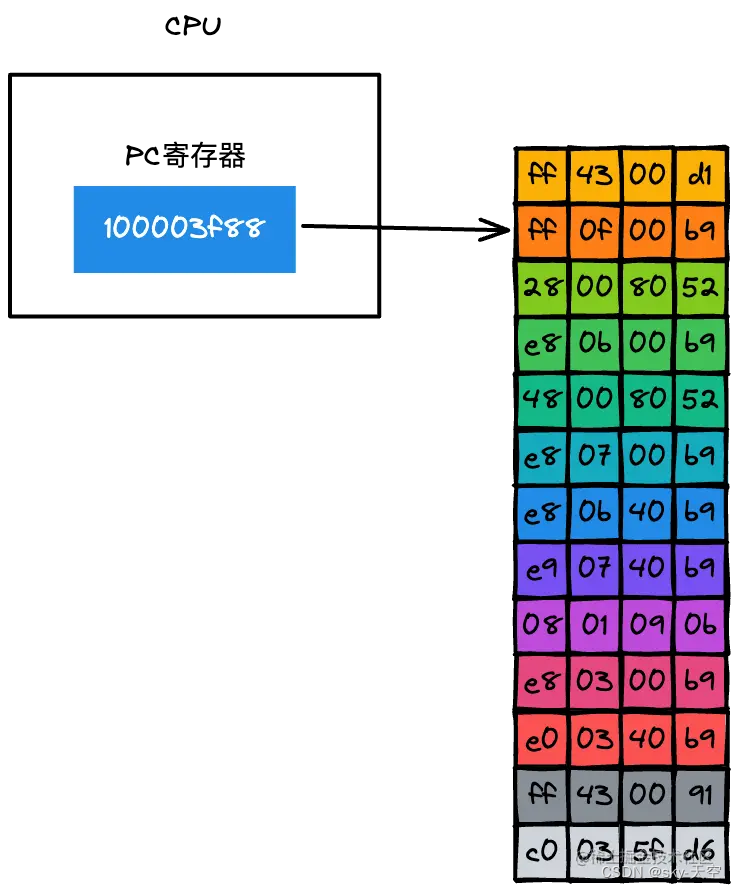
- 更新了 PC 寄存器之后,CPU 就会立即做第二件事,那就是
分析该指令,并识别出不同的类型的指令,以及各种获取操作数的方法。
在指令分析完成之后,就要执行指令了。
在执行指令前,我们还需要认识一下 CPU 中的重要部件:寄存器。
寄存器是 CPU 中用来存放数据的设备,不同处理器中寄存器的个数也是不一样的,之所以要寄存器,是因为 CPU 访问内存的速度很慢,所以 CPU 就在内部添加了一些存储设备,这些设备就是寄存器。
他们的读取速度如下:
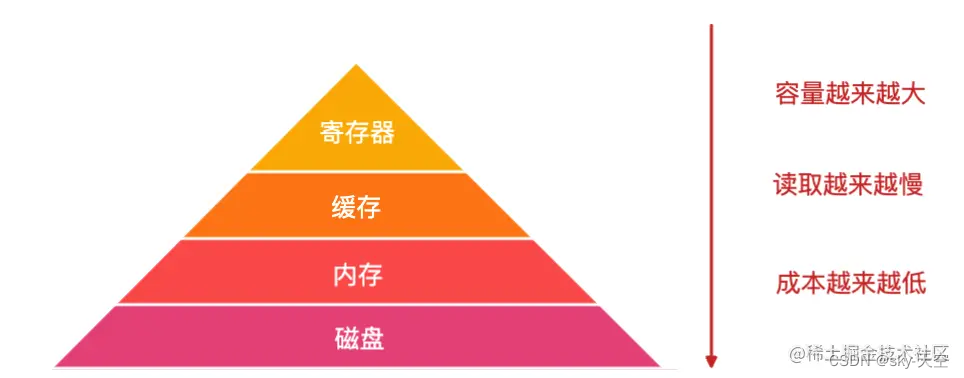
总结来说,寄存器容量小,读写速度快,内存容量大,读写速度慢。
- 寄存器通常用来存放数据或者内存中某块数据的地址,我们把这个地址又称为指针,通常情况下寄存器对存放的数据是没有特别的限制的,比如某个通用寄存器既可以存储数据,也可以存储指针。
- 不过由于历史原因,我们还会将某些专用的数据或者指针存储在专用的通用寄存器中 ,比如 rbp 寄存器通常用来存放栈帧指针的,rsp 寄存器用来存放栈顶指针的,PC 寄存器用来存放下一条要执行的指令等。
同样都是晶体管存储设备,为什么寄存器比内存快呢?
MikeAsh写了一篇很好的解释,非常通俗地回答了这个问题,有助于加深对硬件的理解。
- 原因一:距离不同
距离不是主要因素,但是最好懂。内存离CPU比较远,所以消费更长的时间储存。
以3Ghz的CPU为例子,电流每秒可以震荡30亿次,每次耗时大概为0.33纳秒,光在1纳秒里可以前进30cm,也就是说一个CPU周期内,光可以前进10cm。因此如果内存距离CPU超过5cm,就不可能在一个时钟周期内完成数据的读写。这还没考虑硬件的限制和电流实际上达不到光速。相比之下,寄存器在CPU内部,当然读起来会快一点。
- 原因二:硬件设计不同
苹果公司新推出的iphone5s,CPU是A7,寄存器有6000多位(31个64位寄存器,加上32个128位寄存器)。而iphone5s的内存是1GB,约为80亿位(bit)。这意味着高性能、高成本、高耗电的设计可以用在寄存器上,反正只有6000多位,而不能用在内存上,因为每个位的成本和耗能只要增加一点点,就会被放大80亿倍。
事实上确实如此,内存的设计相对简单,每个位就是一个电容和一个晶体管,而寄存器的设计则完全不同,多出好几个电子元件。并且通电后,寄存器的晶体管一直有电,而内存的晶体管只有在用到的才有电,没用到的就没电,这样利于省电。这些设计上的因素,决定了寄存器比内存读取速度更快。
- 原因三:工作方式不同
寄存器的工作方式只有2步:①找到相关的位 --> ②读取这些位
内存的工作方式就复杂多:
- 找到数据的指针(指针可能存放在寄存器内,所以这一步就已经包括寄存器的全部工作了。)
- 将指针送往内存管理单元(MMU),由MMU讲虚拟的内存地址翻译成实际的物理地址。
- 将物理地址送往内存控制器(memorycontroller),由于内存控制器找出该地址在哪一根内存插槽(bank)上。
- 确定数据在哪一个内存块(chunk)上,从该块读取数据。
- 内存先送回内存控制器,再送回CPU,然后开始使用。
内存的工作流程比寄存器多出许多步,每一步都会产生延迟,累积起来就使得内存比寄存器慢得多。
为了缓解寄存器和内存之间速度的巨大差异,硬件设计师做出了许多努力,包括CPU内部设置缓存,优化CPU工作方式,尽量一次从内存读取指令所要用到的全部数据等等。
特殊寄存器
Stack Pointer register(SP)
The use of SP as an operand in an instruction, indicates the use of the current stack pointer.
指向当前栈指针。
堆栈指针总是指向栈顶位置。一般堆栈的栈底不能动,所以数据入栈前要先修改堆栈指针,使它指向新的空余空间然后再把数据存进去,出栈的时候相反。
堆栈指针,随时跟踪栈顶地址,按"先进后出"的原则存取数据。
Link Register (LR)
连接寄存器,一是用来保存子程序返回地址;二是当异常发生时,LR中保存的值等于异常发生时PC的值减4(或者减2),因此在各种异常模式下可以根据LR的值返回到异常发生前的相应位置继续执行。
Program Counter(PC)
A 64-bit Program Counter holding the address of the current instruction.
保存了将要执行的指令地址
Word Zero Register(WZR)
零寄存器,用于给int清零
tips
不同指令中寄存器后 #d 有什么区别?
[#d]在ARM代表的是一个常数表达式。 如:#0x3FC、#0、#0xF0000000、#200、#0xF0000001 都是代表着一个常数。
在 sp 寄存器中,代表的是当前栈顶指针移动的位置。 如:
sub sp, sp, #16;// 获取 sp 中的栈顶指针移动 16位的位置,并把位置更新到 sp 寄存器中。实现开辟空间
在通用寄存器 W0 - W11 中,代表的操作的常数值。
mov w8, #2,// 把常数 2 添加到 w8 寄存器中
通用寄存器
以下介绍下比较常见的通用寄存器:
- 其中W0~W3 用于函数调用入参,其中,W0 还用于程序的返回值.
- W4~W11用于保存局部变量。
- W13为SP,时刻指向栈顶,当有数据入栈或出栈时,需要更新SP
- W14为链接寄存器,主要是用作保存子程序返回的地址。
- W15为PC寄存器,指向将要执行的下一条指令地址。
寄存器与内存
"CPU操作寄存器还是操作内存"这句话是什么意思?首先来看下寄存器和内存的关系:
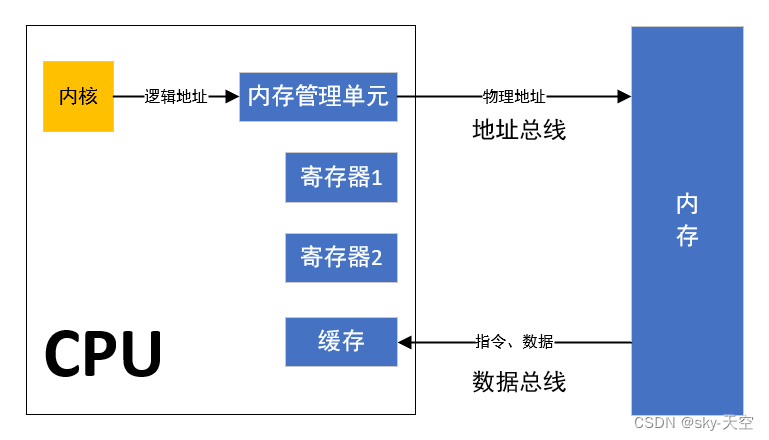
寄存器是CPU内部的一种非常快速的存储器件,用于暂存CPU执行指令和数据的地方,它位于CPU芯片内部,是CPU的一部分。由于寄存器与CPU内部的总线相连,访问速度非常快,通常仅需要一个时钟周期即可完成数据的读取和写入。寄存器被广泛用于存储CPU执行指令和计算过程中的临时数据,以及保存程序状态等。由于寄存器数量非常有限,通常只有几十个到几百个,寄存器通常只用于存储最常用的数据,而且是由硬件设计师预设的。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。在中央处理器的算术及逻辑部件中,包含的寄存器有累加器(ACC)。
内存是计算机中的主要存储设备,用于存储计算机程序和数据。与寄存器相比,内存容量大,通常以GB或TB计算。内存中存储的数据可以随时被CPU访问,但其访问速度较慢,需要多个时钟周期才能完成。内存通常用于存储程序和数据,以及作为CPU和外部设备之间数据传输的中间层。由于内存容量较大,因此内存通常可以动态分配和管理,使得计算机可以更加灵活地使用内存。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
内存是由内存芯片、电路板、金手指等部分组成的。它包涵的范围也很大,一般分为只读存储器和随即存储器,以及最强悍的高速缓冲存储器(CACHE)。
计算机的存储层次(memoryhierarchy)之中,寄存器(register)最快,内存其次,最慢的是硬盘。
寄存器和内存在存储数据的格式、容量和速度等方面都存在差异,它们在计算机系统中扮演不同的角色,它们都是重要的组件,用于存储计算机程序和数据,以及进行数据的读取和写入操作。(寄存器与内存是两种不同的部件,从概念、读写速度以及数据格式来进行区分。)
- 寄存器:通常是一个非常快速的、特殊的存储器,用于在CPU内部存储数据和指令。寄存器的容量很小,通常只有几十个字节,因此它只能存储少量的数据。寄存器中存储的数据是二进制格式的,即由0和1组成的数字序列。这种格式非常适合CPU内部的处理,因为它可以直接传递给CPU中的算术逻辑单元(ALU)进行计算。
- 内存:通常是一个较慢的、可扩展的存储器,用于在计算机系统中存储大量的数据和程序。内存的容量很大,通常可以存储几GB的数据。内存中存储的数据可以是多种格式,包括文本、数字、图像、音频和视频等,这些数据格式不一定是二进制的。
常见指令
cpu指令有操作码和操作数构成,操作码指定指令的操作类型,操作数指定指令要处理的数据及其所在的单元地址。两者用逗号隔开,比如,MOV R1,45H。整条指令以二进制编码的形式存放在存储器中。
- 什么是立刻数?
立刻数是一个常量,可以写成十进制(D),十六进制(H),八进制(O),二进制(B)。例如:ADD AX,0FFH;其中的0FFH就是立刻数。
通俗一点的理解:一个你可以凭空捏出来给CPU,不需要CPU去各种寄存器取的常量数据。
注意一点:立即数只能作为源操作数,不能放在目的操作数位置。也就是指令中结果所存放的数据位。
- 什么是操作数?
通常一条指令包含操作符和操作数,操作数是指令执行的参与者,也就是说操作数是参与某种功能操作的数据
操作数有三种方式提供:立即数、寄存器存放的数据、内存中的数据
通俗一点的理解:操作符是加工的方式,操作数是被加工的东西。
- 立即操作数到底是什么
前面提到操作数有一种提供方式是立即数,那么通常把在立即寻址方法指令中给出的数称为立即操作数。(7种寻址方法)
或者这样理解:指令要操作的数据以常量的形式出现在指令中,称为立即操作数。
同样的可以这样延伸理解寄存器操作数、内存操作数。
mov
数据传送指令。将立即数或寄存器(operant2)传送到目标寄存器Rd,可用于移位运算等操作。指令格式如下:
MOV{cond}{S} Rd,operand2
如:
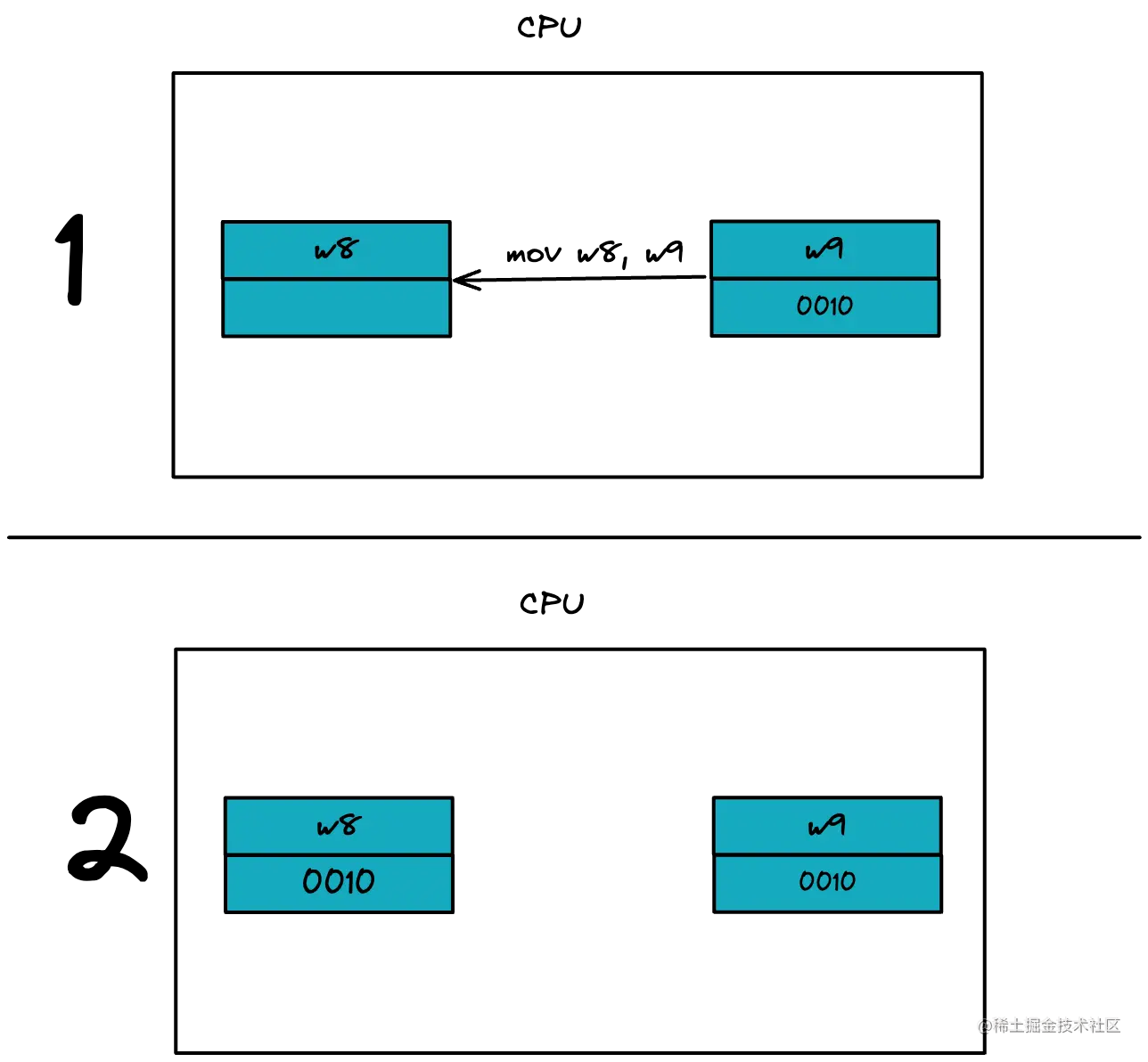
mov w8, #1,就是往 w8 寄存器中写入 #1.
mov w8, w9, 就是把 w9 寄存器的数据发送到 w8 寄存器中,最终 w8 和 w9 寄存器的数据一致。如下图:
ldr
ldr 从内存中读取数据放入寄存器中
LDR{cond}{T} Rd,<地址>;加载指定地址上的数据(字),放入Rd中
如:
ldr w8, [sp, #8] 读取 sp 寄存器中 #8 位置的数据存入 w8 寄存器中,改变的只有 w8 ,sp 寄存器不变
str
str 指令用于将寄存器中的数据保存到内存
STR{cond}{T} Rd,<地址>;存储数据(字)到指定地址的存储单元,要存储的数据在Rd中
如: str w8, [sp] , 将 w8 寄存器的数据存入 sp 寄存器中
add
加法运算指令。将operand2 数据与Rn 的值相加,结果保存到Rd 寄存器。指令格式如下:
ADD{cond}{S} Rd,Rn,operand2
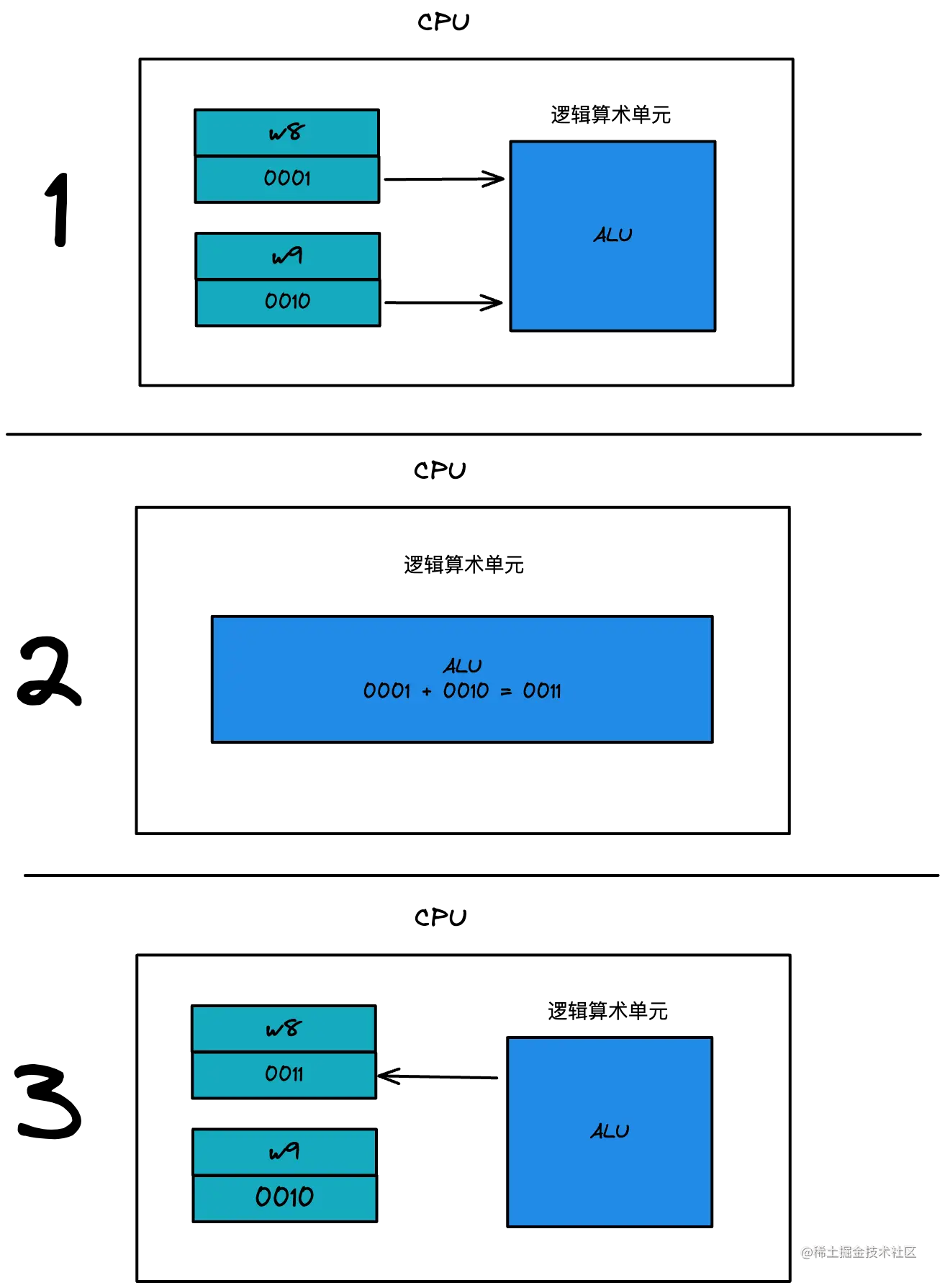
以 add w8, w8, w9 为例,就是把 w8、w9 寄存器的 x,y 数据进行相加,并存入 w8 寄存器中
如下图:
sub
减法运算指令。用寄存器 Rn 减去operand2。结果保存到 Rd 中。指令格式如下:
SUB{cond}{S} Rd,Rn,operand2
如:
sub R0,R0,#1 -- R0=R0-1
执行过程
了解了以上的知识,我们再来分析一遍代码的执行过程。
在 C 程序中,CPU 会首先执行调用 main 函数,在调用 main 函数时,生成一块内存空间,用来存放 main 函数执行过程中的数据。
sub sp, sp, #16
将 0 写入到 #12 的字节位置上。
str wzr, [sp, #12]
接下来给 x 赋值
mov w8, #1 //把 1 添加进寄存器中
str w8, [sp, #8] //把 1 存入 #8 地址的内存空间中。
接着给 y赋值
mov w8, #2 //把 2 添加进寄存器中
str w8, [sp, #4] //把 2 存入 #4 地址的内存空间中。
执行完 x, y 的生成,接下来执行 z = x + y
ldr w8, [sp, #8] //取出内存空间地址为 #8 的数据,也就是 1.
ldr w9, [sp, #4] //去除内存空间地址为 #4 的数据,也就是 2,
add w8, w8, w9 //去除内存空间地址为 #4 的数据,也就是 2,
str w8, [sp] //把寄存器中的最终的数据存入内存中
ldr w0, [sp] //获取内存中的结果,存入寄存器中。等待返回
add sp, sp, #16
把开辟的空间进行清理。
ret
返回结果
在C code的验证环境中,如何判断case已经执行完了?或者说如何判断C代码执行到了哪一步?
以下三种方法为C code验证环境最常用的debug方式:
- 通过uart向外部输出debug信息
- 往空闲寄存器写数据
- toogle_GPIO,检测GPIO高电平
- 调用“wfi”指令
共同特征:要么IO是可观测的,要么寄存器是可观测的,无法通过内部的状态观测的。在C的仿真环境中,从软件角度去看,它只能去操作IO的状态,可被访问的寄存器的值。
- SV的case可以调用$finish结束仿真;
- UVm的case,当sequence执行完之后会自动调用$finish,结束仿真。
debug的时候,在波形里面,CPU内部有个ex_reg_pc(当ex_reg_pc_valid为高的时候才有效)的寄存器,代表当前正在执行的指令。(zf哥c code验证环境讲asm的时候说的)
具体使用例子:
C语言执行完main函数一般是不希望它退出的。在main函数一般是不做return的,main函数可以调用其他子函数,子函数里面可以return。main函数一般执行完啥也不干的时候,加个while(1),在while=(1)上面加一个判断条件,仿真结束的标志(即上述所列方法)。
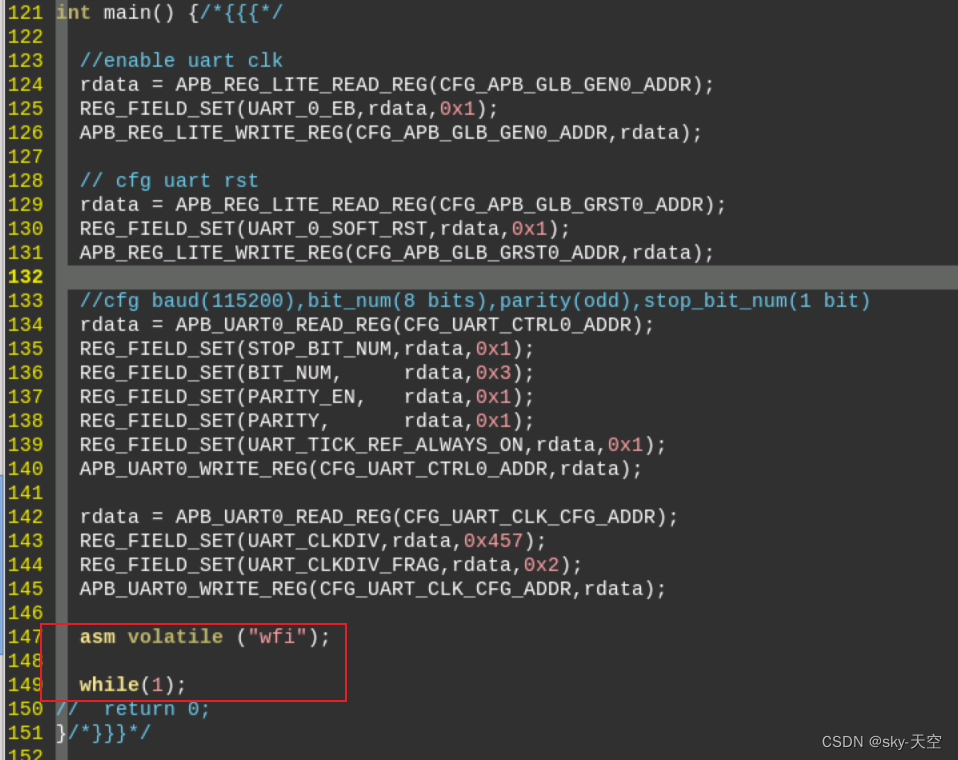
asm就是执行汇编指令 CPU里有io_wfi(wait for interrupt)这个信号,是CPU的一个状态,当这个信号拉高时就结束仿真。


总结
本文主要讲解了 CPU 的执行过程,顺便了解了一下基础的计算机硬件信息。
标签:sp,执行程序,指令,内存,寄存器,过程,CPU,w8 From: https://www.cnblogs.com/skyaha/p/17675771.html