异常
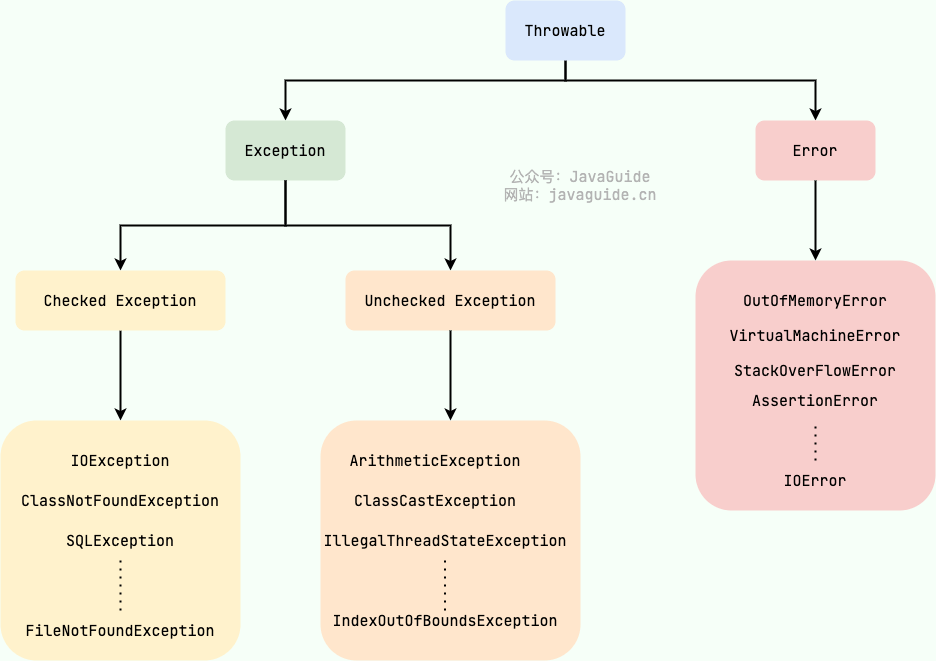
Exception 和 Error
Exception :程序本身可以处理的异常,可以通过 catch 来进行捕获。Exception 又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。
Error:Error 属于程序无法处理的错误 ,不建议通过catch捕获 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止
Checked Exception 和 Unchecked Exception
受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。
Throwable 类常用方法
String getMessage(): 返回异常发生时的简要描述
String toString(): 返回异常发生时的详细信息
String getLocalizedMessage(): 返回异常对象的本地化信息。使用 Throwable 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 getMessage()返回的结果相同
void printStackTrace(): 在控制台上打印 Throwable 对象封装的异常信息
try-catch-finally
try块:用于捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。
catch块:用于处理 try 捕获到的异常。
finally 块:无论是否捕获或处理异常,finally 块里的语句都会被执行。当在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。
不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
finally的代码不一定会执行,比如程序所在线程死亡、CPU关闭、catch里面退出等
try-with-resources
从Java 7开始,引入了一个新的特性叫做 try-with-resources,它是一种更简洁、安全的方式来处理这些资源。
Java 中类似于InputStream、OutputStream、Scanner、PrintWriter等的资源都需要我们调用close()方法来手动关闭,一般情况下我们都是通过try-catch-finally语句来实现这个需求。但是通过try-with-resources会方便很多
// try-catch-finally
Scanner scanner = null;
try {
scanner = new Scanner(new File("D://read.txt"));
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}
// try-with-resources
try (Scanner scanner = new Scanner(new File("test.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace();
}
通过使用分号分隔,可以在try-with-resources块中声明多个资源,可以有效减少多个资源关闭的麻烦
注意事项
- 异常使用时建议抛出更具体的异常而不是父类
- 每次抛出异常手动new一个对象
- 使用日志打印异常之后就不要再抛出异常
泛型
概念
Java 泛型(Generics) 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。
编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。
泛型的使用方式
泛型类
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
泛型接口
public interface Generator<T> {
public T method();
}
泛型方法
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
反射
通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
反射可以让我们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利。反射让我们在运行时有了分析操作类的能力的同时,也增加了安全问题,且性能差些。
注解
基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理
注解只有被解析之后才会生效,一般在两种情况下扫描
- 编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用
@Override注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。 - 运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的
@Value、@Component)都是通过反射来进行处理的。
SPI
概念
机制:为某个接口寻找服务实现的机制。这有点类似 IoC 的思想,将装配的控制权移交到了程序之外
SPI 即 Service Provider Interface,将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。
SPI 和 API 的区别
当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
SPI 的优缺点
需要遍历加载所有的实现类,不能做到按需加载
当多个 ServiceLoader 同时 load 时,会有并发问题
序列化和反序列化
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
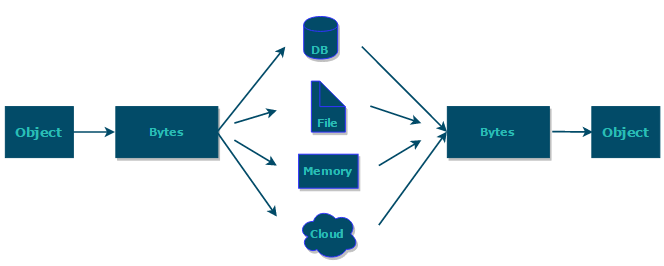
- 序列化:将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程

在OSI七层协议中表示层做的主要就是对应用层的用户数据进行处理转换为二进制流或者转换成应用层的数据,对应的就是序列化和反序列化
有些字段不想进行序列化怎么办
对于不想进行序列化的变量,使用 transient 关键字修饰
常见序列化协议
Hessian、Kryo、Protobuf、ProtoStuff,这些都是基于二进制的序列化协议。一般不用JDK自带的序列化方式,因为JDK自带的序列化方式不支持跨语言调用,性能差且存在安全问题(因为输入的反序列化数据可被用户控制)
I/O
基础知识总结
简介
IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
- 如果你正在处理原始二进制数据,那么使用字节流是合适的。
- 如果你正在处理字符数据,那么使用字符流会更加方便并且效率可能会更高,因为它可以直接读写字符,而不需要每次都转换字符和字节。
Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
字节流
InputStream(字节输入流)
read():返回输入流中下一个字节的数据。返回的值介于 0 到 255 之间。如果未读取任何字节,则代码返回 -1 ,表示文件结束。
read(byte b[ ]) : 从输入流中读取一些字节存储到数组 b 中。如果数组 b 的长度为零,则不读取。如果没有可用字节读取,返回 -1。如果有可用字节读取,则最多读取的字节数最多等于 b.length , 返回读取的字节数。这个方法等价于 read(b, 0, b.length)。
read(byte b[], int off, int len):在read(byte b[ ]) 方法的基础上增加了 off 参数(偏移量)和 len 参数(要读取的最大字节数)。
skip(long n):忽略输入流中的 n 个字节 ,返回实际忽略的字节数。
available():返回输入流中可以读取的字节数。
close():关闭输入流释放相关的系统资源。
从 Java 9 开始,InputStream 新增加了多个实用的方法:
readAllBytes():读取输入流中的所有字节,返回字节数组。readNBytes(byte[] b, int off, int len):阻塞直到读取len个字节。transferTo(OutputStream out):将所有字节从一个输入流传递到一个输出流。
FileInputStream 是一个比较常用的字节输入流对象,可直接指定文件路径,可以直接读取单字节数据,也可以读取至字节数组中
不过,一般我们是不会直接单独使用 FileInputStream ,通常会配合 BufferedInputStream(字节缓冲输入流,后文会讲到)来使用
DataInputStream 用于读取指定类型数据,不能单独使用,必须结合其它流,比如 FileInputStream 。
ObjectInputStream 用于从输入流中读取 Java 对象(反序列化),ObjectOutputStream 用于将对象写入到输出流(序列化)。
OutputStream(字节输出流)
OutputStream用于将数据(字节信息)写入到目的地(通常是文件),java.io.OutputStream抽象类是所有字节输出流的父类。
FileOutputStream 是最常用的字节输出流对象,可直接指定文件路径,可以直接输出单字节数据,也可以输出指定的字节数组。
DataOutputStream 用于写入指定类型数据,不能单独使用,必须结合其它流,比如 FileOutputStream 。
字符流
Reader(字符输入流)
Reader用于从源头(通常是文件)读取数据(字符信息)到内存中,java.io.Reader抽象类是所有字符输入流的父类。
Reader 用于读取文本, InputStream 用于读取原始字节。
InputStreamReader 是字节流转换为字符流的桥梁,其子类 FileReader 是基于该基础上的封装,可以直接操作字符文件。
Writer(字符输出流)
Writer用于将数据(字符信息)写入到目的地(通常是文件),java.io.Writer抽象类是所有字符输出流的父类。
字节缓冲流
IO 操作是很消耗性能的,缓冲流将数据加载至缓冲区,一次性读取/写入多个字节,从而避免频繁的 IO 操作,提高流的传输效率。
BufferedInputStream(字节缓冲输入流)
BufferedInputStream 从源头(通常是文件)读取数据(字节信息)到内存的过程中不会一个字节一个字节的读取,而是会先将读取到的字节存放在缓存区,并从内部缓冲区中单独读取字节。这样大幅减少了 IO 次数,提高了读取效率。
这个流会尽可能多地一次性读入数据到其内部的缓冲区
BufferedOutputStream(字节缓冲输出流)
将数据(字节信息)写入到目的地(通常是文件)的过程中不会一个字节一个字节的写入,而是会先将要写入的字节存放在缓存区,并从内部缓冲区中单独写入字节。这样大幅减少了 IO 次数,提高了读取效率
只有当缓冲区满了 / 手动调用flush() / 调用close() 时才会实际写入到磁盘
字符缓冲流
和字节缓冲流类似
一般情况下,使用缓冲流(无论是字节缓冲流还是字符缓冲流)在处理大量数据时都可以提高效率。
打印流
System.out 实际是用于获取一个 PrintStream 对象,print方法实际调用的是 PrintStream 对象的 write 方法。
随机访问流
随意跳转到文件的任意位置进行读写的 RandomAccessFile
读写模式主要有下面四种:
r: 只读模式。rw: 读写模式rws: 相对于rw,rws同步更新对“文件的内容”或“元数据”的修改到外部存储设备。rwd: 相对于rw,rwd同步更新对“文件的内容”的修改到外部存储设备
RandomAccessFile 比较常见的一个应用就是实现大文件的 断点续传
Java I/O
从计算机结构的视角来看的话, I/O 描述了计算机系统与外部设备之间通信的过程。
从应用程序的视角来看的话,我们的应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
UNIX 系统下, IO 模型一共有 5 种:同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。
这也是我们经常提到的 5 种 IO 模型。
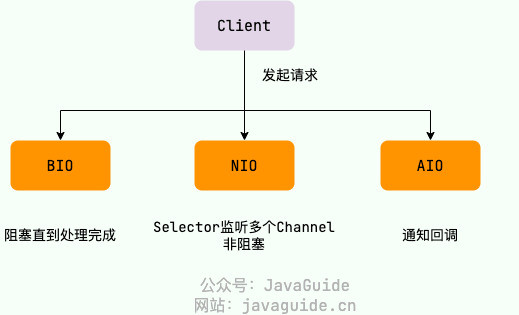
阻塞/非阻塞和同步/非同步
- 同步/异步关注的是消息通信机制: 这主要关系到程序在调用一个操作(特别是耗时的I/O操作)后,是否得到了操作完成的通知。
- 同步操作:在发起调用后,必须等待结果返回之后,才能进行下一步操作。
- 异步操作:在发起调用后,不需要等待结果,可以继续执行其他任务。当结果准备好时,会以事件、回调或者其他方式通知应用程序。
- 阻塞/非阻塞关注的是程序等待调用结果(如 I/O 操作)时的状态:
- 阻塞调用:如果结果还没有准备好,函数会停止执行并等待,直到结果准备好为止。
- 非阻塞调用:如果结果还没有准备好,函数不会等待,而是立即返回。
BIO
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。这意味着如果一个线程发起了一个 I/O 操作,例如读取数据,它必须等待操作完成才能进行其他任务。
在客户端连接数量不高的情况下,是没问题的。
NIO
提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它是支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。
Java 中的 NIO 可以看作是 I/O 多路复用模型。也有很多人认为,Java 中的 NIO 属于同步非阻塞 IO 模型。
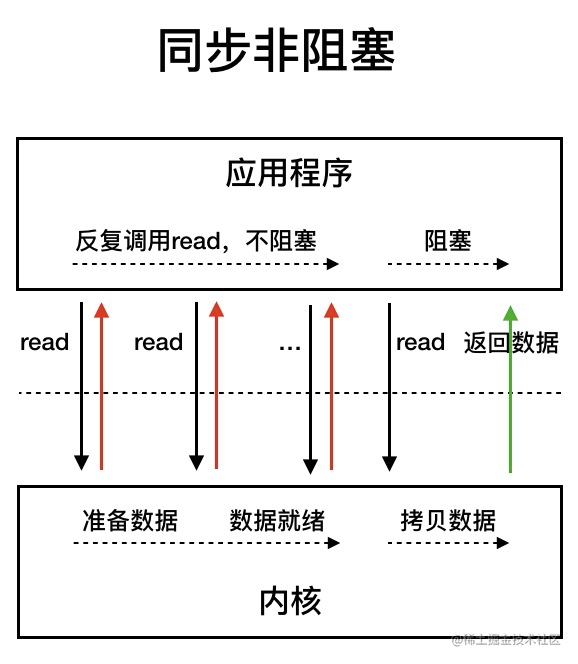
同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。
I/O 多路复用模型
线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。
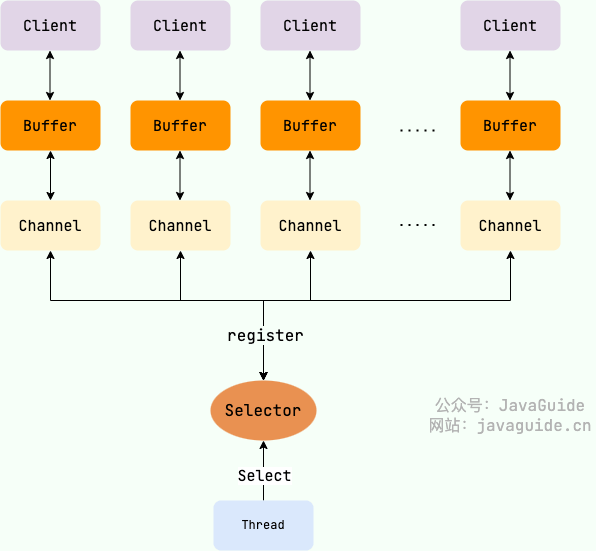
Java 中的 NIO ,有一个非常重要的选择器 ( Selector ) 的概念,也可以被称为 多路复用器。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。
AIO
AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO 模型。
设计模式
装饰器模式
装饰器模式通过组合替代继承来扩展原始类的功能,在一些继承关系比较复杂的场景(IO 这一场景各种类的继承关系就比较复杂)更加实用。
Text类
public interface Text {
String getContent();
}
public class PlainText implements Text {
private String text;
public PlainText(String text) {
this.text = text;
}
@Override
public String getContent() {
return text;
}
}
添加新的功能
// "Decorator" in decorator pattern terminology
public abstract class TextDecorator implements Text {
protected Text decoratedText;
public TextDecorator(Text decoratedText) {
this.decoratedText = decoratedText;
}
@Override
public String getContent() {
return decoratedText.getContent();
}
}
// "ConcreteDecoratorA" in decorator pattern terminology
public class HtmlText extends TextDecorator {
public HtmlText(Text decoratedText) {
super(decoratedText);
}
@Override
public String getContent() {
return "<html>" + decoratedText.getContent() + "</html>";
}
}
使用
Text myText = new PlainText("This is teh content of my web page.");
myText = new HtmlText(myText); // Format the text to HTML
在这个例子中,HtmlText就是装饰器,它继承自TextDecorator。装饰器都增加了一层额外的行为到原始的PlainText对象上,但是并没有改变PlainText对象本身。
适配器模式
适配器(Adapter Pattern)模式 主要用于接口互不兼容的类的协调工作,你可以将其联想到我们日常经常使用的电源适配器。
适配器模式中存在被适配的对象或者类称为 适配者(Adaptee) ,作用于适配者的对象或者类称为适配器(Adapter) 。适配器分为对象适配器和类适配器。类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
适配器模式 更侧重于让接口不兼容而不能交互的类可以一起工作,当我们调用适配器对应的方法时,适配器内部会调用适配者类或者和适配类相关的类的方法,这个过程透明的。
// 原始接口
interface MediaPlayer {
public void play(String audioType, String fileName);
}
// 高级媒体播放器接口
interface AdvancedMediaPlayer {
public void playVlc(String fileName);
public void playMp4(String fileName);
}
// 适配器类
class MediaAdapter implements MediaPlayer {
AdvancedMediaPlayer advancedMusicPlayer;
public MediaAdapter(String audioType){
if(audioType.equalsIgnoreCase("vlc") ){
advancedMusicPlayer = new VlcPlayer();
} else if (audioType.equalsIgnoreCase("mp4")){
advancedMusicPlayer = new Mp4Player();
}
}
@Override
public void play(String audioType, String fileName) {
if(audioType.equalsIgnoreCase("vlc")){
advancedMusicPlayer.playVlc(fileName);
}
else if(audioType.equalsIgnoreCase("mp4")){
advancedMusicPlayer.playMp4(fileName);
}
}
}
工厂模式
工厂模式用于创建对象,NIO 中大量用到了工厂模式,比如 Files 类的 newInputStream 方法用于创建 InputStream 对象(静态工厂)、 Paths 类的 get 方法创建 Path 对象(静态工厂)、ZipFileSystem 类(sun.nio包下的类,属于 java.nio 相关的一些内部实现)的 getPath 的方法创建 Path 对象(简单工厂)。
观察者模式
NIO 中的文件目录监听服务基于 WatchService 接口和 Watchable 接口。WatchService 属于观察者,Watchable 属于被观察者。
常用的监听事件有 3 种:
StandardWatchEventKinds.ENTRY_CREATE:文件创建。StandardWatchEventKinds.ENTRY_DELETE: 文件删除。StandardWatchEventKinds.ENTRY_MODIFY: 文件修改。
语法糖
常见语法糖
语法糖(Syntactic sugar) 代指的是编程语言为了方便程序员开发程序而设计的一种特殊语法,这种语法对编程语言的功能并没有影响。实现相同的功能,基于语法糖写出来的代码往往更简单简洁且更易阅读
JVM 其实并不能识别语法糖,Java 语法糖要想被正确执行,需要先通过编译器进行解糖,也就是在程序编译阶段将其转换成 JVM 认识的基本语法。这也侧面说明,Java 中真正支持语法糖的是 Java 编译器而不是 JVM。
String[] strs = {"JavaGuide", "公众号:JavaGuide", "博客:https://javaguide.cn/"};
for (String s : strs) {
System.out.println(s);
}
Java 虚拟机并不支持这些语法糖。这些语法糖在编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖
泛型
自动装箱与拆箱
自动装箱就是 Java 自动将原始类型值转换成对应的对象,比如将 int 的变量转换成 Integer 对象,这个过程叫做装箱,反之将 Integer 对象转换成 int 类型值,这个过程叫做拆箱。因为这里的装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。原始类型 byte, short, char, int, long, float, double 和 boolean 对应的封装类为 Byte, Short, Character, Integer, Long, Float, Double, Boolean。
可变长参数
枚举
当我们使用enum来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类继承Enum类,所以枚举类型不能被继承
内部类
内部类又称为嵌套类,可以把内部类理解为外部类的一个普通成员。
内部类之所以也是语法糖,是因为它仅仅是一个编译时的概念,outer.java里面定义了一个内部类inner,一旦编译成功,就会生成两个完全不同的.class文件了,分别是outer.class和outer$inner.class。所以内部类的名字完全可以和它的外部类名字相同。
条件编译
在反编译后的代码中没有System.out.println("Hello, ONLINE!");,这其实就是条件编译。当if(ONLINE)为 false 的时候,编译器就没有对其内的代码进行编译。
断言
在 Java 中,断言(assertion)是一种用于在开发阶段进行程序自我验证的机制。通过使用断言,我们可以设置一些预期条件来检查代码在运行时是否符合预期的行为。
int a = 5;
assert a > 0 : "a is non-positive!";
在上述代码中,如果 a > 0 的结果为 false,则会抛出一个 AssertionError,并带有消息 "a is non-positive!"。
注意:默认情况下,断言在Java程序中是禁用的,只有在启动程序时明确指定 -ea 参数,才能启用断言功能。例如 java -ea com.example.MyClass。
字面数值量
在 java 7 中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读。
for-each
try-with-resource
编译之后会变成一个代码块并且加上close()
Lambda 表达式
lambda 表达式的实现其实是依赖了一些底层的 api,在编译阶段,编译器会把 lambda 表达式进行解糖,转换成调用内部 api 的方式
坑
当泛型遇到重载
涉及到一个泛型擦除的问题
public class GenericTypes {
public static void method(List<String> list) {
System.out.println("invoke method(List<String> list)");
}
public static void method(List<Integer> list) {
System.out.println("invoke method(List<Integer> list)");
}
}
这段代码是编译通不过的。因为我们前面讲过,参数List<Integer>和List<String>编译之后都被擦除了,变成了一样的原生类型 List,擦除动作导致这两个方法的特征签名变得一模一样。
泛型与静态变量
class GT<T>{
public static int var=0;
public void nothing(T x){}
}
所有GT的对象的var值都是一样的,因为经过类型擦除,所有的泛型类实例都关联到同一份字节码上,泛型类的所有静态变量是共享的。
泛型与catch
泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型MyException<String>和MyException<Integer>的
自动装箱与拆箱
相同对象只适用于整数值区间-128 至 +127,超过了则不认为是同一个对象
增强for循环
for (Student stu : students) {
if (stu.getId() == 2)
students.remove(stu);
}
会抛出ConcurrentModificationException异常。
Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出java.util.ConcurrentModificationException异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法remove()来删除对象,Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。不可以用集合本身的remove()方法