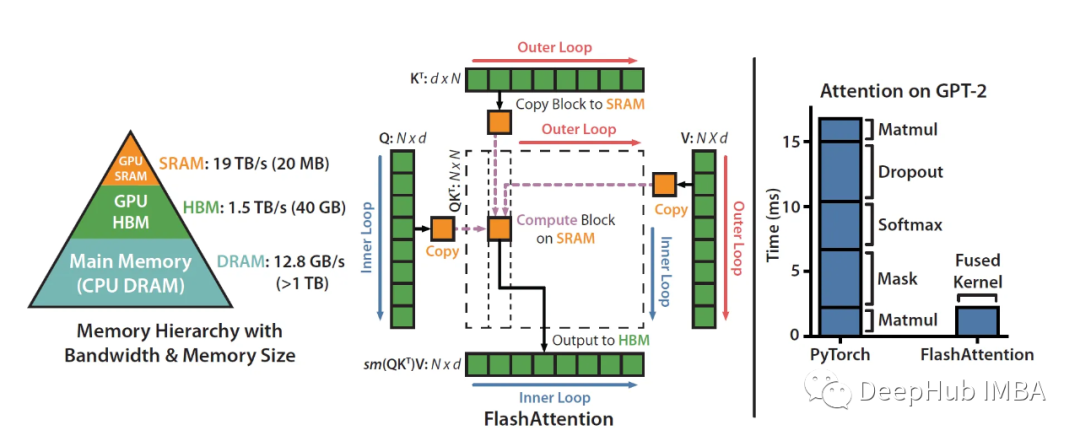
这篇文章的目的是详细的解释Flash Attention,为什么要解释FlashAttention呢?因为FlashAttention 是一种重新排序注意力计算的算法,它无需任何近似即可加速注意力计算并减少内存占用。所以作为目前LLM的模型加速它是一个非常好的解决方案,本文介绍经典的V1版本,最新的V2做了其他优化我们这里暂时不介绍。因为V1版的FlashAttention号称可以提速5-10倍,所以我们来研究一下它到底是怎么实现的。
https://avoid.overfit.cn/post/9d812b7a909e49e6ad4fb115cc25cdc1
标签:加速,V1,算法,详解,FlashAttention,注意力 From: https://www.cnblogs.com/deephub/p/17645370.html