n-gram 模型
参考:https://zhuanlan.zhihu.com/p/32829048
简介:一个句子或者一个联想词语,可以使用链式规则建模,利用马尔科夫链的假设(当前词语的产生只与前n个词语产生的概率相关)。n-gram中的n指的就是马尔科夫链假设中的长度。
定义:一元模型unigram model,二元模型bigram model,三元模型trigram model
应用:联想词
n-gram中的n对于性能的影响:n越大,之前的词对于当前词出现的约束性信息更多,词更具判别性,但同时也会造成搜索空间变大(所有词的n次方)。n越小,当前词在训练预料库中出现的次数更多,有更高的可靠性,但对于长距离的约束信息更少。
PAL (HUAWEI)
方法名由来:Position-bias aware learning framework for CTR prediction in live recommender systems
核心研究问题:Position Bias,CTR值的大小不仅仅受用户曝光、点击的影响,也受推荐条目位置信息的影响(如推荐的先后顺序)。最终造成强者越强,弱者越弱。
现有解决方法:将position也当成一个特征来建模,但只能在线下训练模型时引入,线上测试时无,只能使用一个默认值代替!这就使得默认值对模型输出结果影响很大,最终造成线上的结果只是局部最优。
本文方法:将CTR分解为probability item seen by user以及probability user click item,并假设两者相互独立,可分别用两个网络来学习。其中probability user click item是我们真正需要的目标,而probability item seen是造成position bias的干扰项。(所以线上测试的时候,我们只用probability user click item)
最终CTR表示为:
\[P(y=1|x, pos) = P(seen|x, pos) * P(y=1|x, pos, seen) \]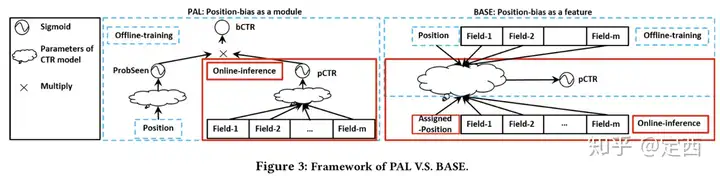
参考链接:https://zhuanlan.zhihu.com/p/83571732
MMoE (google)
方法名由来:Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
在推荐的应用场景中,我们除了需要对CTR做预测/拟合外,往往还需要拟合其他的指标。例如在抖音的短视频推荐里,视频中包含点赞、转发、评论、收藏、停留时间等,这些都可以成为网络的预测结果,我们将这些需要预测的称为一个个任务。多任务模型就是希望通过学习不同任务之间的联系和差异,从而提高每个任务的学习效率和质量。
现有方法:多塔结构使用公有结构学习公有特征提取,接着以每个任务一个塔的结构学习任务特定的特征及输出。MoE将多塔结构的公有结构替换成multi expert+gate的MoE结构(模型集成),相对于shared-bottom结构不明显增加参数的情况下,强化公有特征的学习。
本文方法:本方法在沿用MoE的同时,让每个task所对应的塔都能够得到task最需要的特征。本方法可以理解为是Shared-Bottom Multitask Model以及MoE的更泛化的形式。在本方法中,每个task的塔,相比于MoE有自己独有的gate网络,用于筛选task最需要的特征。由于公有结构的每个expert都是公用的,因此这相比于每个task一个网络的参数量少得多。此外,实验发现在任务相关度比较高的时候,MoE和MMoE的效果比较接近,但在任务相关度较低时,MMoE的效果比MoE好,说明MMoE能够在一定程度上缓解任务差异的消极影响。
个人看法:MoE中实际上做的还是用多个expert去学习公有特征,因此这个公有特征必然会受到多任务间关系的影响(可能相互增益,可能出现负迁移)。而本文的方法,则通过multi-gate给多个expert松绑了,multi-gate能够让真正有利于当前任务的expert的特征脱颖而出,而抑制不利于当前任务的expert。这种更加泛化的结构,兼具share bottom和一部分任务特有网络的优点(后者有那么点意思,但不彻底!)

参考链接:https://cloud.tencent.com/developer/article/1832873
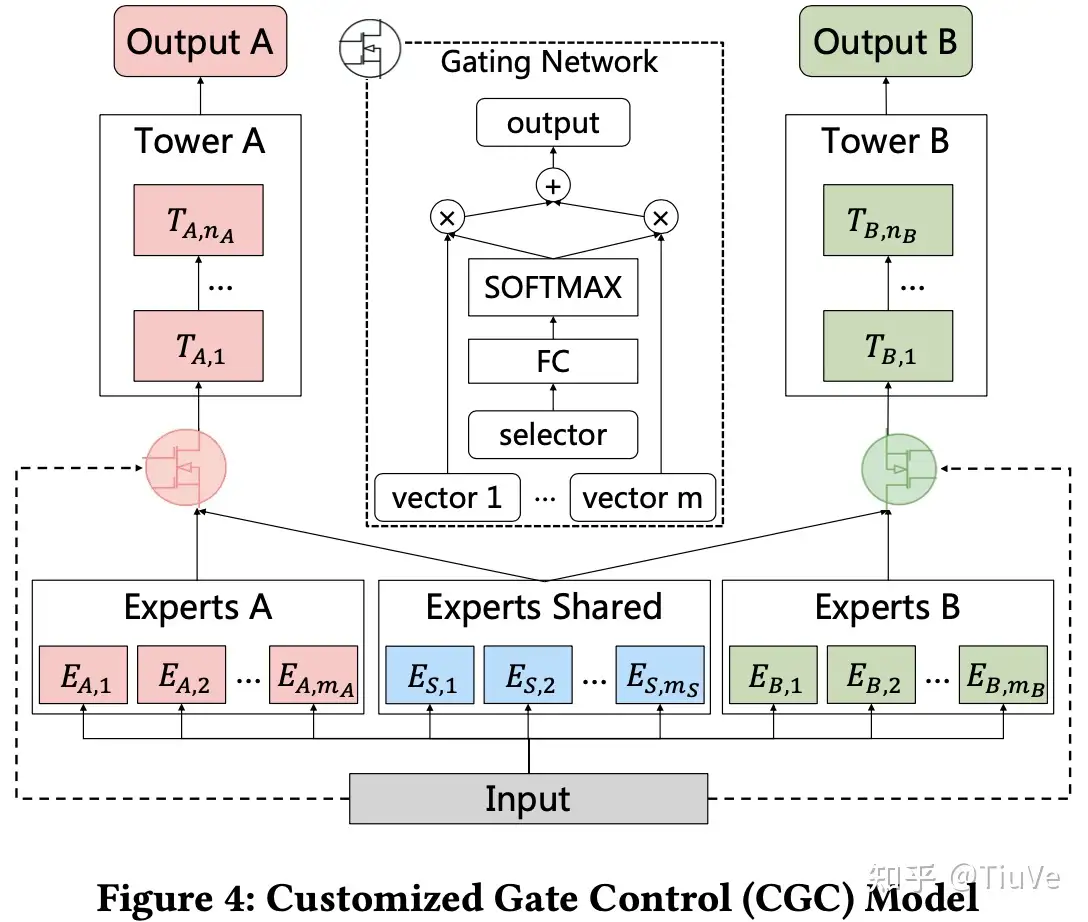
CGC (腾讯)
像MMoE的实验中体现的,多任务模型在学习多任务时,并不一定能够保证多任务对单任务的增益。这种多任务学习导致单任务性能恶化的情况成为“负迁移”。在真实情况下,当任务之间的相关性很复杂且依赖于样本时,多个任务无法同时达到最优,模型往往会牺牲其他任务的性能来改进某个任务,这种现象称之为“跷跷板”现象。本文主要想缓解的就是这个问题。
现有工作:略(见前面)
本文工作:为了实现和单任务相似的性能,本方法将任务公有网络替换成“任务公有网络+任务私有网络”,这样就能保证网络具备单任务特定参数的同时,利用公有网络中的公有特征。
个人看法:本文将MMoE的multi-gate潜藏的优势发挥到了极致,显式的将公有网络与私有网络分开开来,使得网络能够在保证单任务网络性能的同时,引入公有特征。此外,值得注意的是,这里的Gate Network与MMoE的gate不同点在于其新引入了非线性激活函数softmax(看了下别人实现的MMoE代码),相比MMoE引入非线性。
PLE将单层CGC网络扩展到了多层,使得网络能够学习更加深层的语义表示。
个人看法:相当于将网络加深了,不同之处在于中间层的Expert Shared部分的输入除了自身外,特来自任务独有expert。
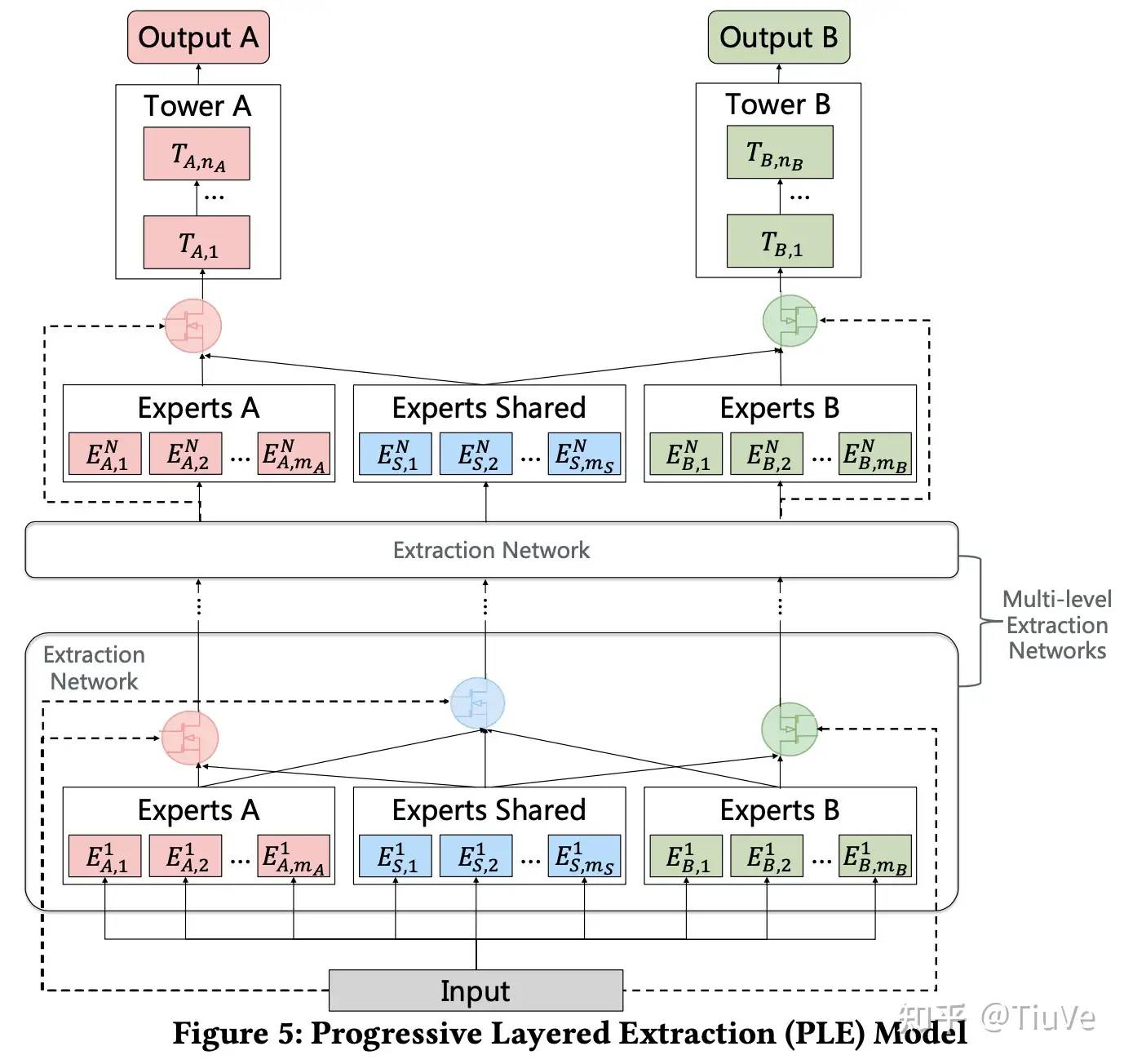
方法缺点:正如前面分析的,这里的核心贡献在于将任务参数解耦成公有和私有,但这样做就不可避免的造成网络参数量过大的问题,这对于模型推理时的效率问题提出了新要求。
参考链接:https://zhuanlan.zhihu.com/p/408631841
PEPNET (快手)
现有推荐系统一般都是多任务(需要模型预测多个指标)多场景(如首页、发现页等多个页面)。除了上面提到的多任务下,模型可能出现的负迁移、互相影响外,多场景下也会带来新的问题。在多场景下,不同用户具有一定的共性,但因不同场景的展现形式和时机等因素,又具有一定差异性。本文认为,如果在建模过程中不能处理好多场景、多任务给模型带来的消极影响,产生的场景跷跷板、任务跷跷板现象,会极大影响模型的性能。因此本文旨在针对上述问题(任务跷跷板、场景悄悄板),提出了一种高效、低成本、即插即用的模型。
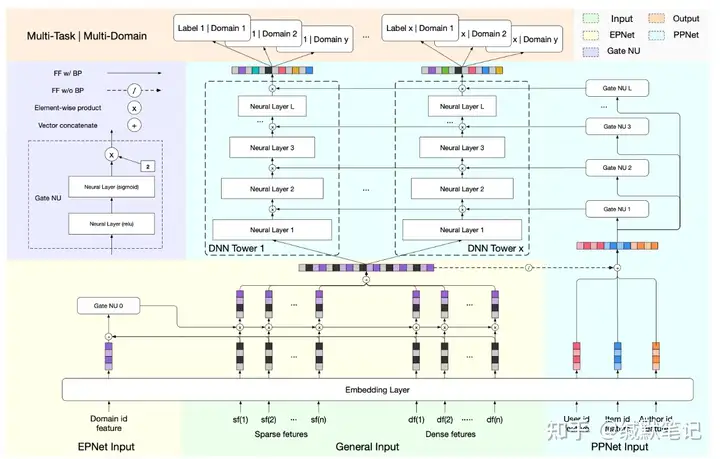
模型基本结构:模型除了由任务特定的塔组成外,还由Gate NU、EPNet、PPNet三个基本部分组成。
- Gate NU是后两个基本部分的组成模块。Gate NU由两层全连接组成(两层从前到后,分别使用ReLU、sigmoid激活函数)。
- EPNet主要用于处理场景标识信息,接受经过Embedding Layer的对应部分输出及融合后,由Gate NU处理生成General Input的门控信息。
- PPNet主要用于处理用户标识信息,其同样接收Embedding Layer对应部分输出并与general input融合后,流入任务所对应塔的各层门控结构Gate NU生成各层的门控信息。
值得注意的是。
- 网路中的Embedding Layer层是公有结构,在部署的时候快手使用了一个特殊的参数服务器来实现无冲突和内存高效共享使用。(共享embedding表)
- 网络采用在线学习的方式,embedding层和DNN塔分别采用不同的更新策略(embedding用较大学习率,DNN塔用较小学习率,从而保证更好的不抓底层embedding变化,同时稳定更新顶层DNN塔参数。)
- 由于模型采用在线学习,且用户、item是不断新增的,这会导致id特征快速膨胀,从而导致大量过期或低频id特征,因此本文采用了“限制总存储数量”+“设置过期时间,定期删除过期特征”。
个人看法:本方法中的domain只能影响浅层的embedding过程(EPNet部分),基本逻辑是认为任务domain之间差异不大,不同的domain只需要有稍微的变化,就能适用(按照前面的逻辑,此处的发展有点像MoE阶段,是否可以做成domain特有?以缓解domain相差过大导致的性能下降)。User id部分则只能影响高层的任务特定塔部分,基本出发点同样不考虑或者少考虑用户间的相互影响,认为可以使用同一个网络来处理多用户。(但其实有可能用户之间也存在负迁移!但一个用户一个模块的形式开销太大!是否可以从给用户分组的角度设计模块?)
参考链接:https://zhuanlan.zhihu.com/p/611400673
GemNN
方法名由来:GemNN: Gating-Enhanced Multi-Task Neural Networks with Feature Interaction Learning for CTR Prediction
本文的一大重点是下图中的Gating layer,这部分其实就是迁移自CV领域的context-gating。说白了就是将原来的残差结构中的加换成乘(逐元素相乘),数学表达如下:
\[Y = \sigma(WX+b) \cdot X \]反映到本文中的Gating Layer就是逐元素乘以特征。
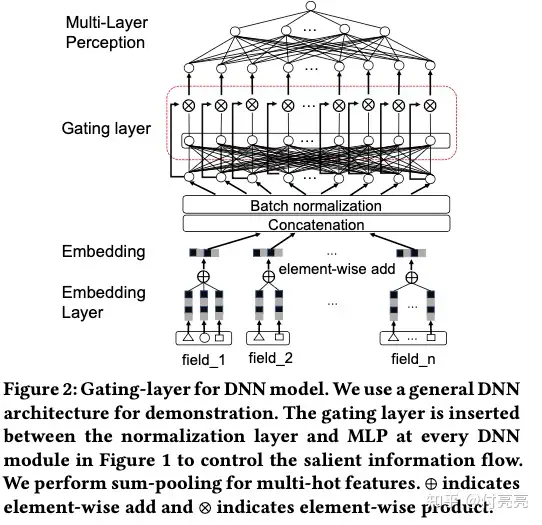
参考链接:https://zhuanlan.zhihu.com/p/602465907
标签:速读,模型,论文,网络,搜索算法,公有,任务,MMoE,MoE From: https://www.cnblogs.com/yujun273/p/17581525.html