String 是 Java 基本数据类型吗?可以被继承吗?
String 是 Java 基本数据类型吗?
不是。Java 中的基本数据类型只有 8 个:byte、short、int、long、float、double、char、boolean;除了基本类型(primitive type),剩下的都是引用类型(reference type)。
String 是一个比较特殊的引用数据类型。
String 类可以继承吗?
不行。String 类使用 final 修饰,是所谓的不可变类,无法被继承。
String 和 StringBuilder、StringBuffer 的区别?
- String:String 的值被创建后不能修改,任何对 String 的修改都会引发新的 String 对象的生成。
- StringBuffer:跟 String 类似,但是值可以被修改,使用 synchronized 来保证线程安全。
- StringBuilder:StringBuffer 的非线程安全版本,性能上更高一些。
String str1 = new String("abc")和 String str2 = "abc" 和 区别?
两个语句都会去字符串常量池中检查是否已经存在 “abc”,如果有则直接使用,如果没有则会在常量池中创建 “abc” 对象。
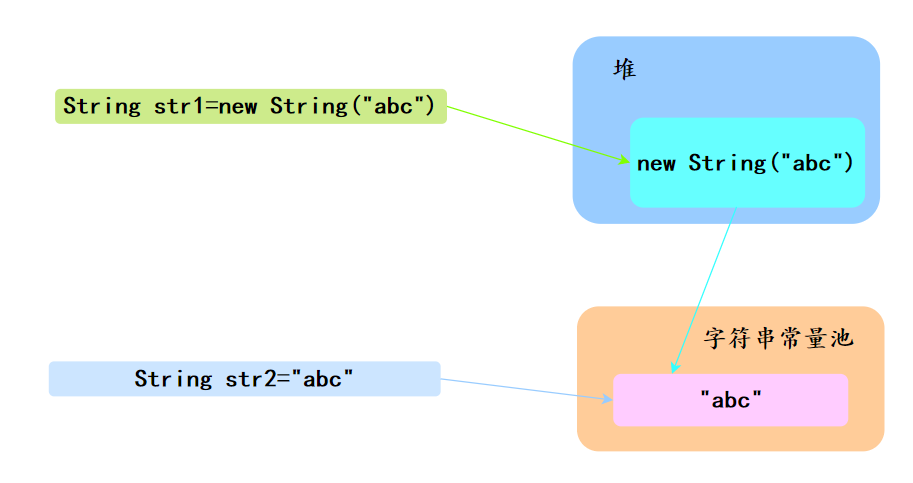
堆与常量池中的String
但是不同的是,String str1 = new String("abc") 还会通过 new String() 在堆里创建一个 "abc" 字符串对象实例。所以后者可以理解为被前者包含。
String s = new String("abc")创建了几个对象?
很明显,一个或两个。如果字符串常量池已经有“abc”,则是一个;否则,两个。
当字符创常量池没有 “abc”,此时会创建如下两个对象:
- 一个是字符串字面量 "abc" 所对应的、字符串常量池中的实例
- 另一个是通过 new String() 创建并初始化的,内容与"abc"相同的实例,在堆中。
String 不是不可变类吗?字符串拼接是如何实现的?
String 的确是不可变的,“+”的拼接操作,其实是会生成新的对象。
例如:
String a = "hello ";
String b = "world!";
String ab = a + b;
在jdk1.8 之前,a 和 b 初始化时位于字符串常量池,ab 拼接后的对象位于堆中。经过拼接新生成了 String 对象。如果拼接多次,那么会生成多个中间对象。
内存如下:
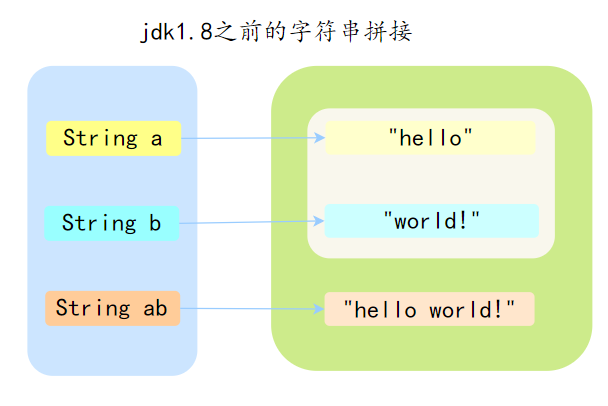
jdk1.8之前的字符串拼接
在Java8 时JDK 对“+”号拼接进行了优化,上面所写的拼接方式会被优化为基于 StringBuilder 的 append 方法进行处理。Java 会在编译期对“+”号进行处理。
下面是通过 javap -verbose 命令反编译字节码的结果,很显然可以看到 StringBuilder 的创建和 append 方法的调用。
stack=2, locals=4, args_size=1
0: ldc #2 // String hello
2: astore_1
3: ldc #3 // String world!
5: astore_2
6: new #4 // class java/lang/StringBuilder
9: dup
10: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V
13: aload_1
14: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
17: aload_2
18: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
21: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
24: astore_3
25: return
也就是说其实上面的代码其实相当于:
String a = "hello ";
String b = "world!";
StringBuilder sb = new StringBuilder();
sb.append(a);
sb.append(b);
String ab = sb.toString();
此时,如果再笼统的回答:通过加号拼接字符串会创建多个 String 对象,因此性能比 StringBuilder 差,就是错误的了。因为本质上加号拼接的效果最终经过编译器处理之后和 StringBuilder 是一致的。
当然,循环里拼接还是建议用 StringBuilder,为什么,因为循环一次就会创建一个新的 StringBuilder 对象,大家可以自行实验。
intern 方法有什么作用?
JDK 源码里已经对这个方法进行了说明:
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
意思也很好懂:
- 如果当前字符串内容存在于字符串常量池(即 equals()方法为 true,也就是内容一样),直接返回字符串常量池中的字符串
- 否则,将此 String 对象添加到池中,并返回 String 对象的引用
Integer
Integer a= 127,Integer b = 127;Integer c= 128,Integer d = 128;,相等吗?
答案是 a 和 b 相等,c 和 d 不相等。
- 对于基本数据类型==比较的值
- 对于引用数据类型==比较的是地址
Integer a= 127 这种赋值,是用到了 Integer 自动装箱的机制。自动装箱的时候会去缓存池里取 Integer 对象,没有取到才会创建新的对象。
如果整型字面量的值在-128 到 127 之间,那么自动装箱时不会 new 新的 Integer 对象,而是直接引用缓存池中的 Integer 对象,超过范围 a1==b1 的结果是 false
public static void main(String[] args) {
Integer a = 127;
Integer b = 127;
Integer b1 = new Integer(127);
System.out.println(a == b); //true
System.out.println(b==b1); //false
Integer c = 128;
Integer d = 128;
System.out.println(c == d); //false
}
什么是 Integer 缓存?
因为根据实践发现大部分的数据操作都集中在值比较小的范围,因此 Integer 搞了个缓存池,默认范围是 -128 到 127,可以根据通过设置JVM-XX:AutoBoxCacheMax=来修改缓存的最大值,最小值改不了。
实现的原理是 int 在自动装箱的时候会调用 Integer.valueOf,进而用到了 IntegerCache。
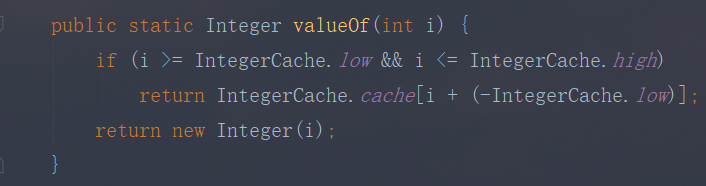
Integer.valueOf
很简单,就是判断下值是否在缓存范围之内,如果是的话去 IntegerCache 中取,不是的话就创建一个新的 Integer 对象。
IntegerCache 是一个静态内部类, 在静态块中会初始化好缓存值。
private static class IntegerCache {
……
static {
//创建Integer对象存储
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
……
}
}
String 怎么转成 Integer 的?原理?
PS:这道题印象中在一些面经中出场过几次。
String 转成 Integer,主要有两个方法:
- Integer.parseInt(String s)
- Integer.valueOf(String s)
不管哪一种,最终还是会调用 Integer 类内中的parseInt(String s, int radix)方法。
抛去一些边界之类的看看核心代码:
public static int parseInt(String s, int radix)
throws NumberFormatException
{
int result = 0;
//是否是负数
boolean negative = false;
//char字符数组下标和长度
int i = 0, len = s.length();
……
int digit;
//判断字符长度是否大于0,否则抛出异常
if (len > 0) {
……
while (i < len) {
// Accumulating negatively avoids surprises near MAX_VALUE
//返回指定基数中字符表示的数值。(此处是十进制数值)
digit = Character.digit(s.charAt(i++),radix);
//进制位乘以数值
result *= radix;
result -= digit;
}
}
//根据上面得到的是否负数,返回相应的值
return negative ? result : -result;
}
去掉枝枝蔓蔓(当然这些枝枝蔓蔓可以去看看,源码 cover 了很多情况),其实剩下的就是一个简单的字符串遍历计算,不过计算方式有点反常规,是用负的值累减。
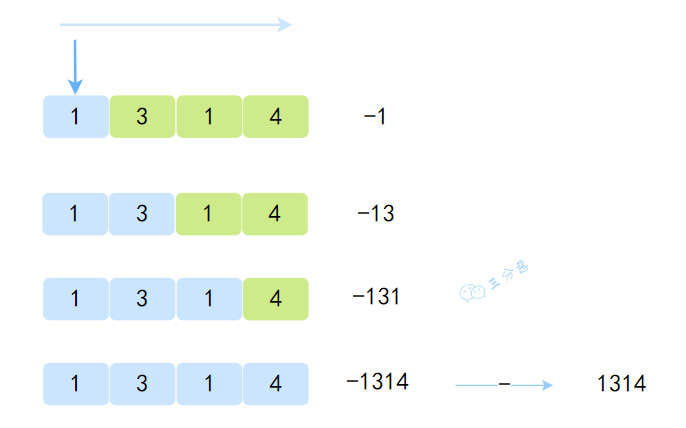
parseInt示意图
Object
Object 类的常见方法?
Object 类是一个特殊的类,是所有类的父类,也就是说所有类都可以调用它的方法。它主要提供了以下 11 个方法,大概可以分为六类:
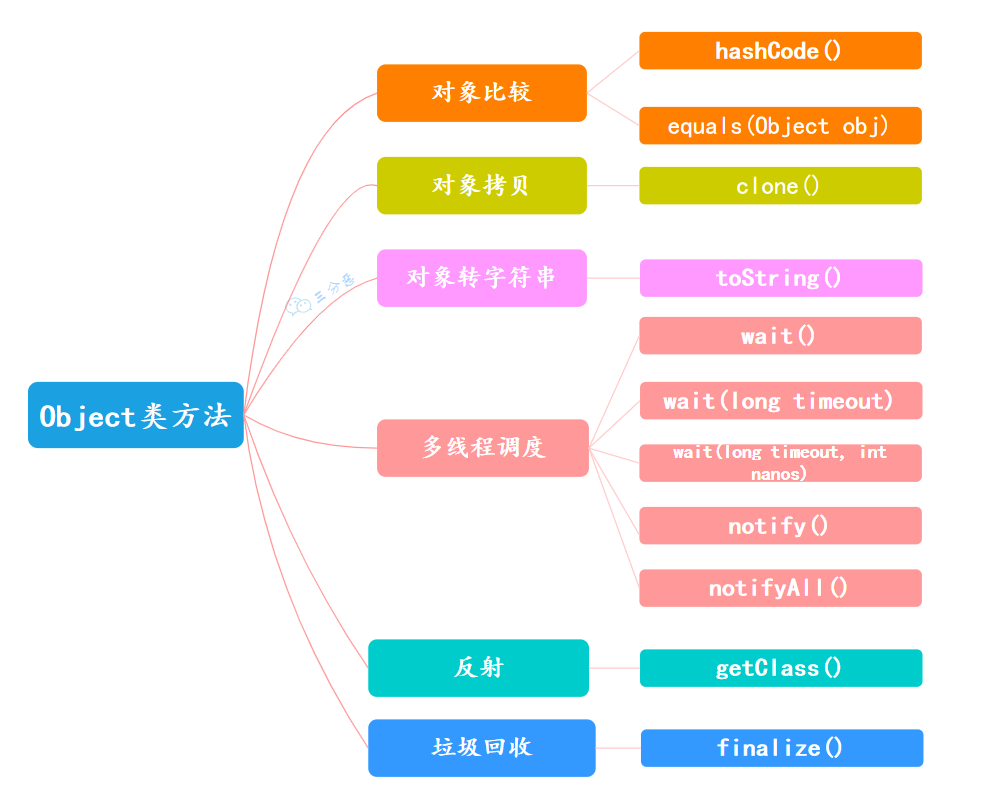
Object类的方法
对象比较:
- public native int hashCode() :native 方法,用于返回对象的哈希码,主要使用在哈希表中,比如 JDK 中的 HashMap。
- public boolean equals(Object obj):用于比较 2 个对象的内存地址是否相等,String 类对该方法进行了重写用户比较字符串的值是否相等。
对象拷贝:
- protected native Object clone() throws CloneNotSupportedException:naitive 方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为 true,x.clone().getClass() == x.getClass() 为 true。Object 本身没有实现 Cloneable 接口,所以不重写 clone 方法并且进行调用的话会发生 CloneNotSupportedException 异常。
对象转字符串:
- public String toString():返回类的名字@实例的哈希码的 16 进制的字符串。建议 Object 所有的子类都重写这个方法。
多线程调度:
- public final native void notify():native 方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
- public final native void notifyAll():native 方法,并且不能重写。跟 notify 一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
- public final native void wait(long timeout) throws InterruptedException:native 方法,并且不能重写。暂停线程的执行。注意:sleep 方法没有释放锁,而 wait 方法释放了锁 。timeout 是等待时间。
- public final void wait(long timeout, int nanos) throws InterruptedException:多了 nanos 参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 毫秒。
- public final void wait() throws InterruptedException:跟之前的 2 个 wait 方法一样,只不过该方法一直等待,没有超时时间这个概念
反射:
- public final native Class<?> getClass():native 方法,用于返回当前运行时对象的 Class 对象,使用了 final 关键字修饰,故不允许子类重写。
垃圾回收:
- protected void finalize() throws Throwable :通知垃圾收集器回收对象。
异常处理
Java 中异常处理体系?
Java 的异常体系是分为多层的。
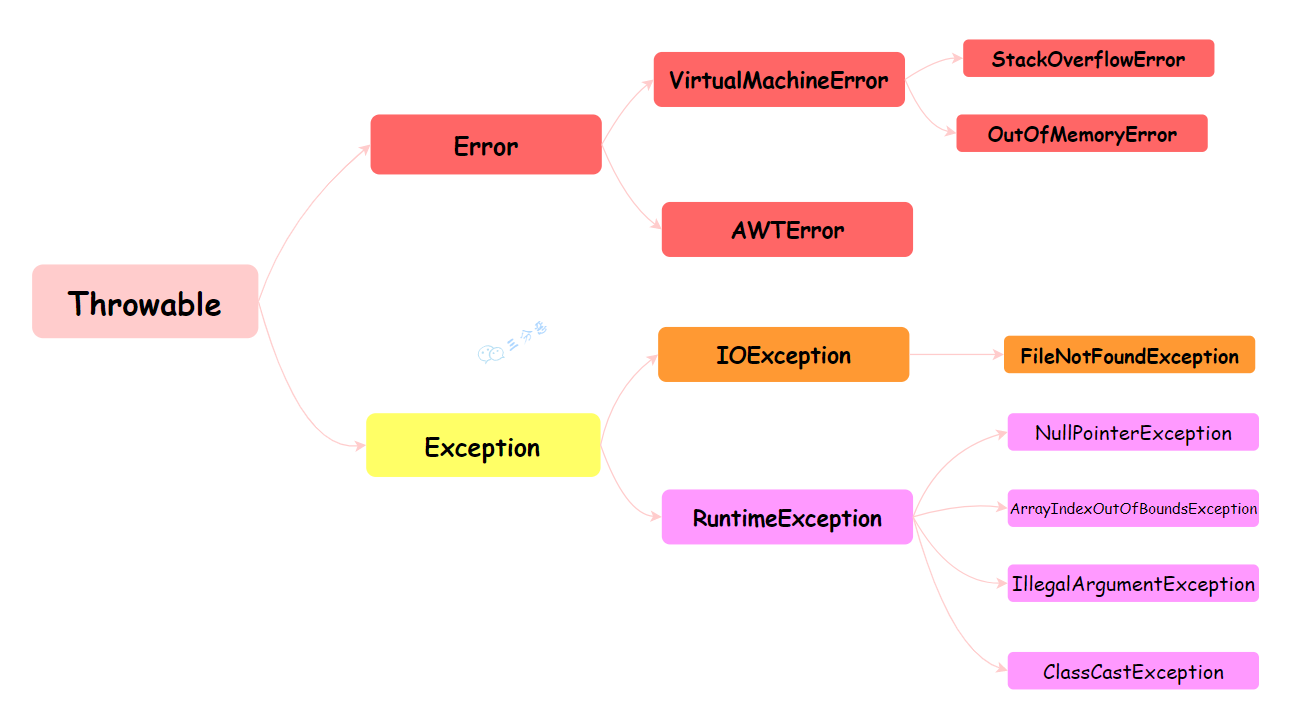
Java异常体系
Throwable是 Java 语言中所有错误或异常的基类。 Throwable 又分为Error和Exception,其中 Error 是系统内部错误,比如虚拟机异常,是程序无法处理的。Exception是程序问题导致的异常,又分为两种:
- CheckedException 受检异常:编译器会强制检查并要求处理的异常。
- RuntimeException 运行时异常:程序运行中出现异常,比如我们熟悉的空指针、数组下标越界等等
异常的处理方式?
针对异常的处理主要有两种方式:
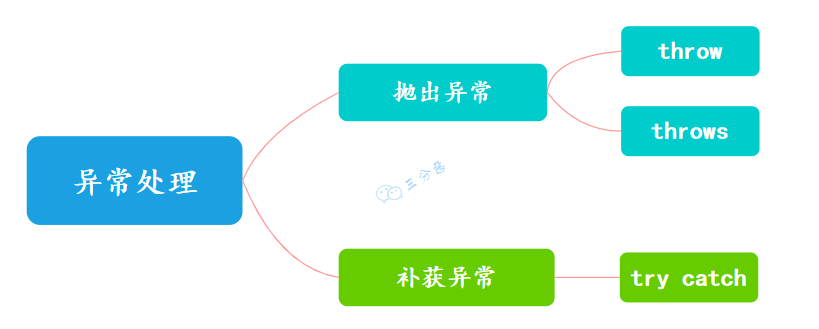
异常处理
- 遇到异常不进行具体处理,而是继续抛给调用者 (throw,throws)
抛出异常有三种形式,一是 throw,一个 throws,还有一种系统自动抛异常。
throws 用在方法上,后面跟的是异常类,可以跟多个;而 throw 用在方法内,后面跟的是异常对象。
- try catch 捕获异常
在 catch 语句块中补货发生的异常,并进行处理。
try {
//包含可能会出现异常的代码以及声明异常的方法
}catch(Exception e) {
//捕获异常并进行处理
}finally { }
//可选,必执行的代码
}
try-catch 捕获异常的时候还可以选择加上 finally 语句块,finally 语句块不管程序是否正常执行,最终它都会必然执行。
三道经典异常处理代码题
题目 1
public class TryDemo {
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
System.out.print("3");
}
}
}
执行结果:31。
try、catch。finally 的基础用法,在 return 前会先执行 finally 语句块,所以是先输出 finally 里的 3,再输出 return 的 1。
题目 2
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
try {
return 2;
} finally {
return 3;
}
}
}
执行结果:3。
try 返回前先执行 finally,结果 finally 里不按套路出牌,直接 return 了,自然也就走不到 try 里面的 return 了。
finally 里面使用 return 仅存在于面试题中,实际开发这么写要挨吊的。
题目 3
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
int i = 0;
try {
i = 2;
return i;
} finally {
i = 3;
}
}
}
执行结果:2。
大家可能会以为结果应该是 3,因为在 return 前会执行 finally,而 i 在 finally 中被修改为 3 了,那最终返回 i 不是应该为 3 吗?
但其实,在执行 finally 之前,JVM 会先将 i 的结果暂存起来,然后 finally 执行完毕后,会返回之前暂存的结果,而不是返回 i,所以即使 i 已经被修改为 3,最终返回的还是之前暂存起来的结果 2。
I/O
Java 中 IO 流分为几种?
流按照不同的特点,有很多种划分方式。
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分为节点流和处理流
Java Io 流共涉及 40 多个类,看上去杂乱,其实都存在一定的关联, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
![IO-操作方式分类-图片来源参考[2]](https://cdn.tobebetterjavaer.com/tobebetterjavaer/images/sidebar/sanfene/javase-24.jpeg)
IO-操作方式分类-图片来源参考[2]
IO 流用到了什么设计模式?
其实,Java 的 IO 流体系还用到了一个设计模式——装饰器模式。
InputStream 相关的部分类图如下,篇幅有限,装饰器模式就不展开说了。
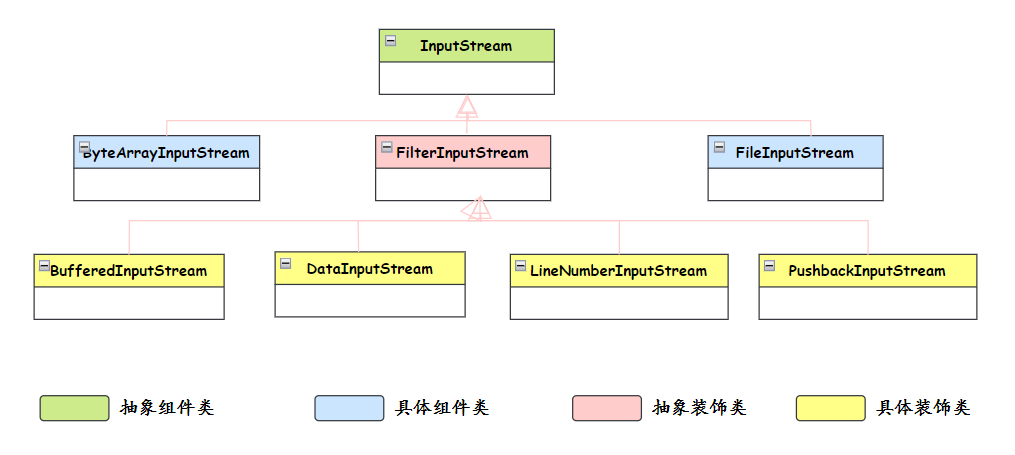
Java IO流用到装饰器模式
既然有了字节流,为什么还要有字符流?
其实字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还比较耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。
所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
BIO、NIO、AIO?
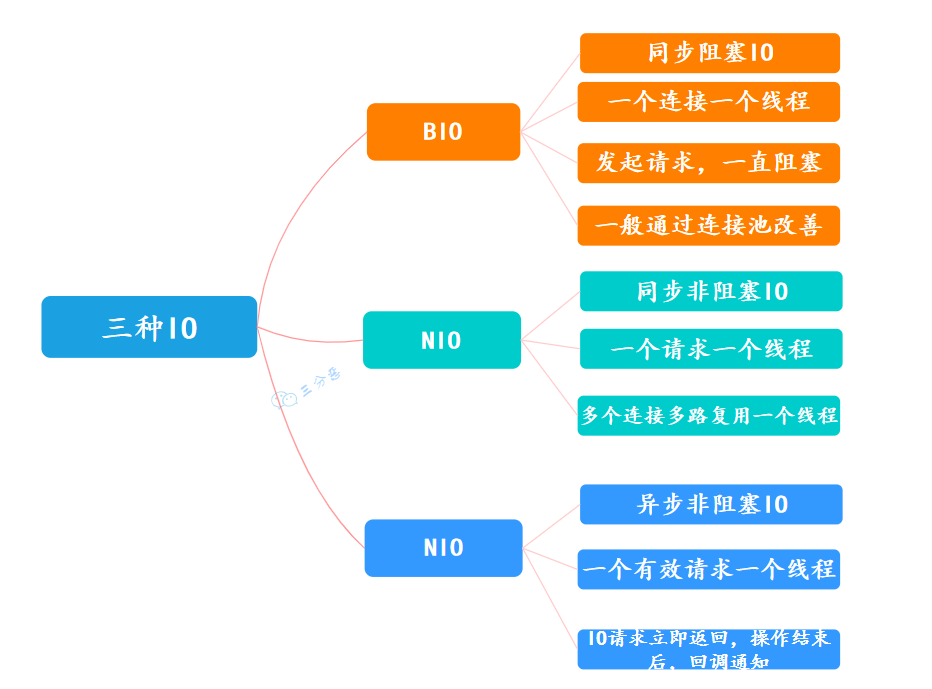
BIO、NIO、AIO
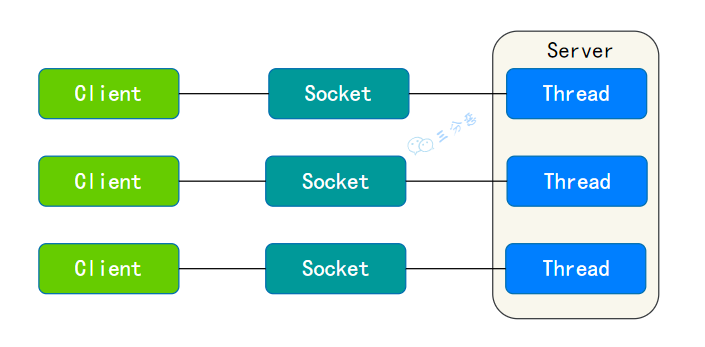
BIO(blocking I/O) : 就是传统的 IO,同步阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,可以通过连接池机制改善(实现多个客户连接服务器)。
BIO、NIO、AIO
BIO 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4 以前的唯一选择,程序简单易理解。
NIO :全称 java non-blocking IO,是指 JDK 提供的新 API。从 JDK1.4 开始,Java 提供了一系列改进的输入/输出的新特性,被统称为 NIO(即 New IO)。
NIO 是同步非阻塞的,服务器端用一个线程处理多个连接,客户端发送的连接请求会注册到多路复用器上,多路复用器轮询到连接有 IO 请求就进行处理:
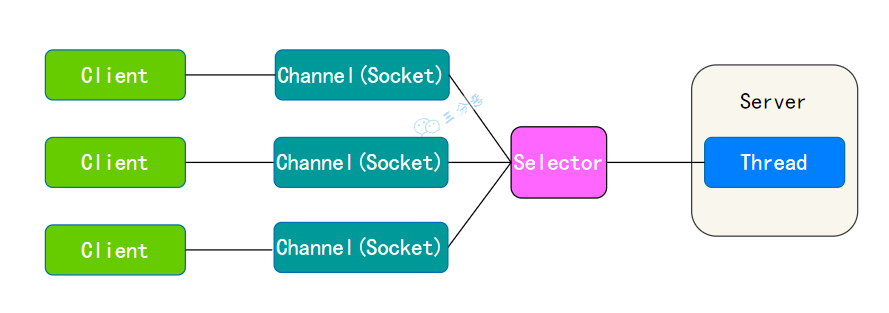
NIO线程
NIO 的数据是面向缓冲区 Buffer的,必须从 Buffer 中读取或写入。
所以完整的 NIO 示意图:
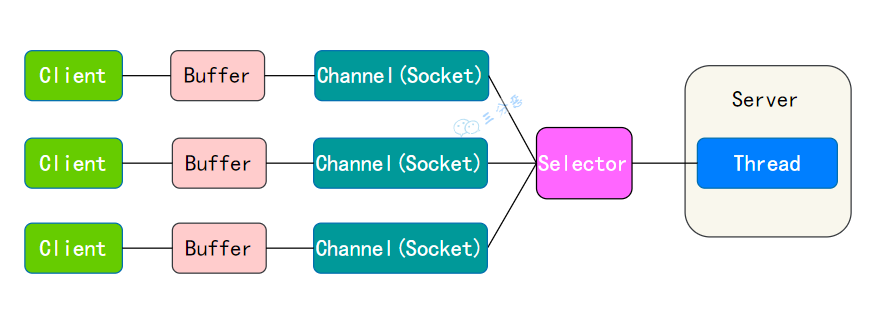
NIO完整示意图
可以看出,NIO 的运行机制:
- 每个 Channel 对应一个 Buffer。
- Selector 对应一个线程,一个线程对应多个 Channel。
- Selector 会根据不同的事件,在各个通道上切换。
- Buffer 是内存块,底层是数据。
AIO:JDK 7 引入了 Asynchronous I/O,是异步不阻塞的 IO。在进行 I/O 编程中,常用到两种模式:Reactor 和 Proactor。Java 的 NIO 就是 Reactor,当有事件触发时,服务器端得到通知,进行相应的处理,完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
序列化
什么是序列化?什么是反序列化?
什么是序列化,序列化就是把 Java 对象转为二进制流,方便存储和传输。
所以反序列化就是把二进制流恢复成对象。
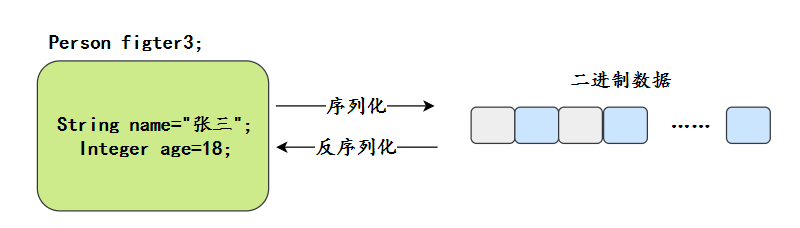
序列化和反序列化
类比我们生活中一些大件物品的运输,运输的时候把它拆了打包,用的时候再拆包组装。
Serializable 接口有什么用?
这个接口只是一个标记,没有具体的作用,但是如果不实现这个接口,在有些序列化场景会报错,所以一般建议,创建的 JavaBean 类都实现 Serializable。
serialVersionUID 又有什么用?
serialVersionUID 就是起验证作用。
private static final long serialVersionUID = 1L;
我们经常会看到这样的代码,这个 ID 其实就是用来验证序列化的对象和反序列化对应的对象 ID 是否一致。
这个 ID 的数字其实不重要,无论是 1L 还是 IDE 自动生成的,只要序列化时候对象的 serialVersionUID 和反序列化时候对象的 serialVersionUID 一致的话就行。
如果没有显示指定 serialVersionUID ,则编译器会根据类的相关信息自动生成一个,可以认为是一个指纹。
所以如果你没有定义一个 serialVersionUID, 结果序列化一个对象之后,在反序列化之前把对象的类的结构改了,比如增加了一个成员变量,则此时的反序列化会失败。
因为类的结构变了,所以 serialVersionUID 就不一致。
Java 序列化不包含静态变量?
序列化的时候是不包含静态变量的。
如果有些变量不想序列化,怎么办?
对于不想进行序列化的变量,使用transient关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
说说有几种序列化方式?
Java 序列化方式有很多,常见的有三种:
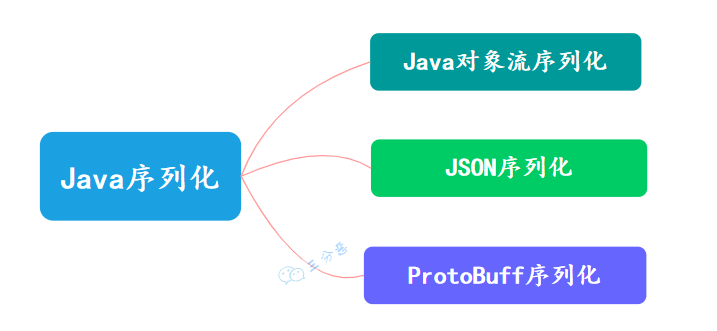
Java常见序列化方式
- Java 对象序列化 :Java 原生序列化方法即通过 Java 原生流(InputStream 和 OutputStream 之间的转化)的方式进行转化,一般是对象输出流
ObjectOutputStream和对象输入流ObjectInputStream。 - Json 序列化:这个可能是我们最常用的序列化方式,Json 序列化的选择很多,一般会使用 jackson 包,通过 ObjectMapper 类来进行一些操作,比如将对象转化为 byte 数组或者将 json 串转化为对象。
- ProtoBuff 序列化:ProtocolBuffer 是一种轻便高效的结构化数据存储格式,ProtoBuff 序列化对象可以很大程度上将其压缩,可以大大减少数据传输大小,提高系统性能。
泛型
Java 泛型了解么?什么是类型擦除?介绍一下常用的通配符?
什么是泛型?
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
List<Integer> list = new ArrayList<>();
list.add(12);
//这里直接添加会报错
list.add("a");
Class<? extends List> clazz = list.getClass();
Method add = clazz.getDeclaredMethod("add", Object.class);
//但是通过反射添加,是可以的
add.invoke(list, "kl");
System.out.println(list);
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。

泛型类、泛型接口、泛型方法
1.泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
如何实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456);
2.泛型接口 :
public interface Generator<T> {
public T method();
}
实现泛型接口,指定类型:
class GeneratorImpl<T> implements Generator<String>{
@Override
public String method() {
return "hello";
}
}
3.泛型方法 :
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
使用:
// 创建不同类型数组: Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray( intArray );
printArray( stringArray );
泛型常用的通配符有哪些?
常用的通配符为: T,E,K,V,?
- ? 表示不确定的 java 类型
- T (type) 表示具体的一个 java 类型
- K V (key value) 分别代表 java 键值中的 Key Value
- E (element) 代表 Element
什么是泛型擦除?
所谓的泛型擦除,官方名叫“类型擦除”。
Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的类型信息都会被擦掉。
也就是说,在运行的时候是没有泛型的。
例如这段代码,往一群猫里放条狗:
LinkedList<Cat> cats = new LinkedList<Cat>();
LinkedList list = cats; // 注意我在这里把范型去掉了,但是list和cats是同一个链表!
list.add(new Dog()); // 完全没问题!
因为 Java 的范型只存在于源码里,编译的时候给你静态地检查一下范型类型是否正确,而到了运行时就不检查了。上面这段代码在 JRE(Java运行环境)看来和下面这段没区别:
LinkedList cats = new LinkedList(); // 注意:没有范型!
LinkedList list = cats;
list.add(new Dog());
为什么要类型擦除呢?
主要是为了向下兼容,因为 JDK5 之前是没有泛型的,为了让 JVM 保持向下兼容,就出了类型擦除这个策略。
注解
说一下你对注解的理解?
Java 注解本质上是一个标记,可以理解成生活中的一个人的一些小装扮,比如戴什么什么帽子,戴什么眼镜。
Java注解和帽子
注解可以标记在类上、方法上、属性上等,标记自身也可以设置一些值,比如帽子颜色是绿色。
有了标记之后,我们就可以在编译或者运行阶段去识别这些标记,然后搞一些事情,这就是注解的用处。
例如我们常见的 AOP,使用注解作为切点就是运行期注解的应用;比如 lombok,就是注解在编译期的运行。
注解生命周期有三大类,分别是:
- RetentionPolicy.SOURCE:给编译器用的,不会写入 class 文件
- RetentionPolicy.CLASS:会写入 class 文件,在类加载阶段丢弃,也就是运行的时候就没这个信息了
- RetentionPolicy.RUNTIME:会写入 class 文件,永久保存,可以通过反射获取注解信息
所以我上文写的是解析的时候,没写具体是解析啥,因为不同的生命周期的解析动作是不同的。
像常见的:
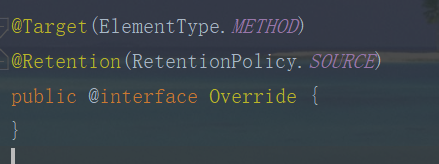
Override注解
就是给编译器用的,编译器编译的时候检查没问题就 over 了,class 文件里面不会有 Override 这个标记。
再比如 Spring 常见的 Autowired ,就是 RUNTIME 的,所以在运行的时候可以通过反射得到注解的信息,还能拿到标记的值 required 。

Autowired注解
反射
什么是反射?应用?原理?
什么是反射?
我们通常都是利用new方式来创建对象实例,这可以说就是一种“正射”,这种方式在编译时候就确定了类型信息。
而如果,我们想在时候动态地获取类信息、创建类实例、调用类方法这时候就要用到反射。
通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
反射最核心的四个类:
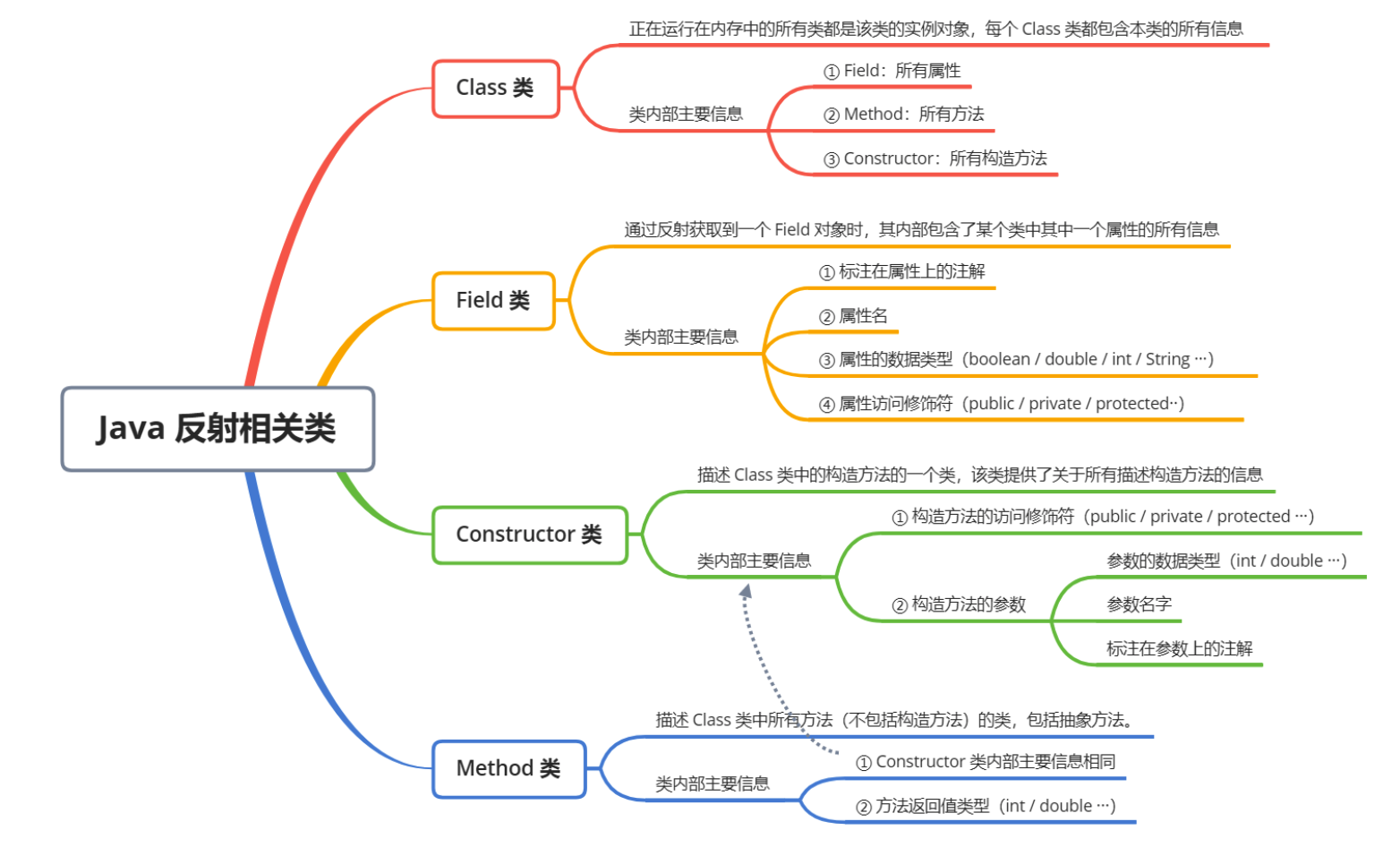 Java反射相关类
Java反射相关类
反射的应用场景?
一般我们平时都是在在写业务代码,很少会接触到直接使用反射机制的场景。
但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
像 Spring 里的很多 注解 ,它真正的功能实现就是利用反射。
就像为什么我们使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
这些都是因为我们可以基于反射操作类,然后获取到类/属性/方法/方法的参数上的注解,注解这里就有两个作用,一是标记,我们对注解标记的类/属性/方法进行对应的处理;二是注解本身有一些信息,可以参与到处理的逻辑中。
反射的原理?
我们都知道 Java 程序的执行分为编译和运行两步,编译之后会生成字节码(.class)文件,JVM 进行类加载的时候,会加载字节码文件,将类型相关的所有信息加载进方法区,反射就是去获取这些信息,然后进行各种操作。
标签:Java,String,基础,面试,泛型,Integer,序列化,public From: https://www.cnblogs.com/pxzbky/p/17538628.html