一、介绍
鸟类识别系统,使用Python作为主要开发语言,基于深度学习TensorFlow框架,搭建卷积神经网络算法。并通过对数据集进行训练,最后得到一个识别精度较高的模型。并基于Django框架,开发网页端操作平台,实现用户上传一张图片识别其名称。
数据集选自加州理工学院200种鸟类数据集
二、效果展示
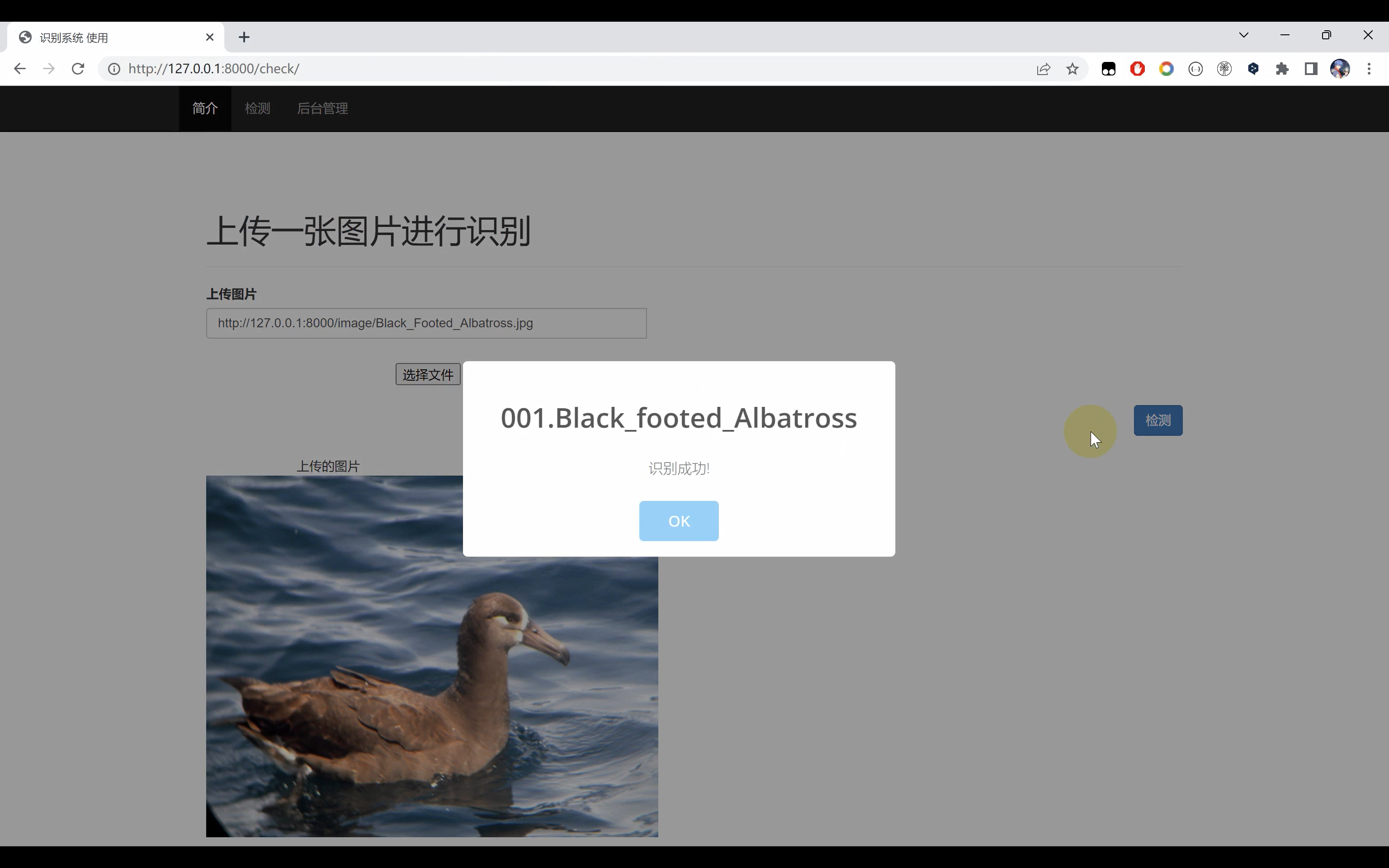

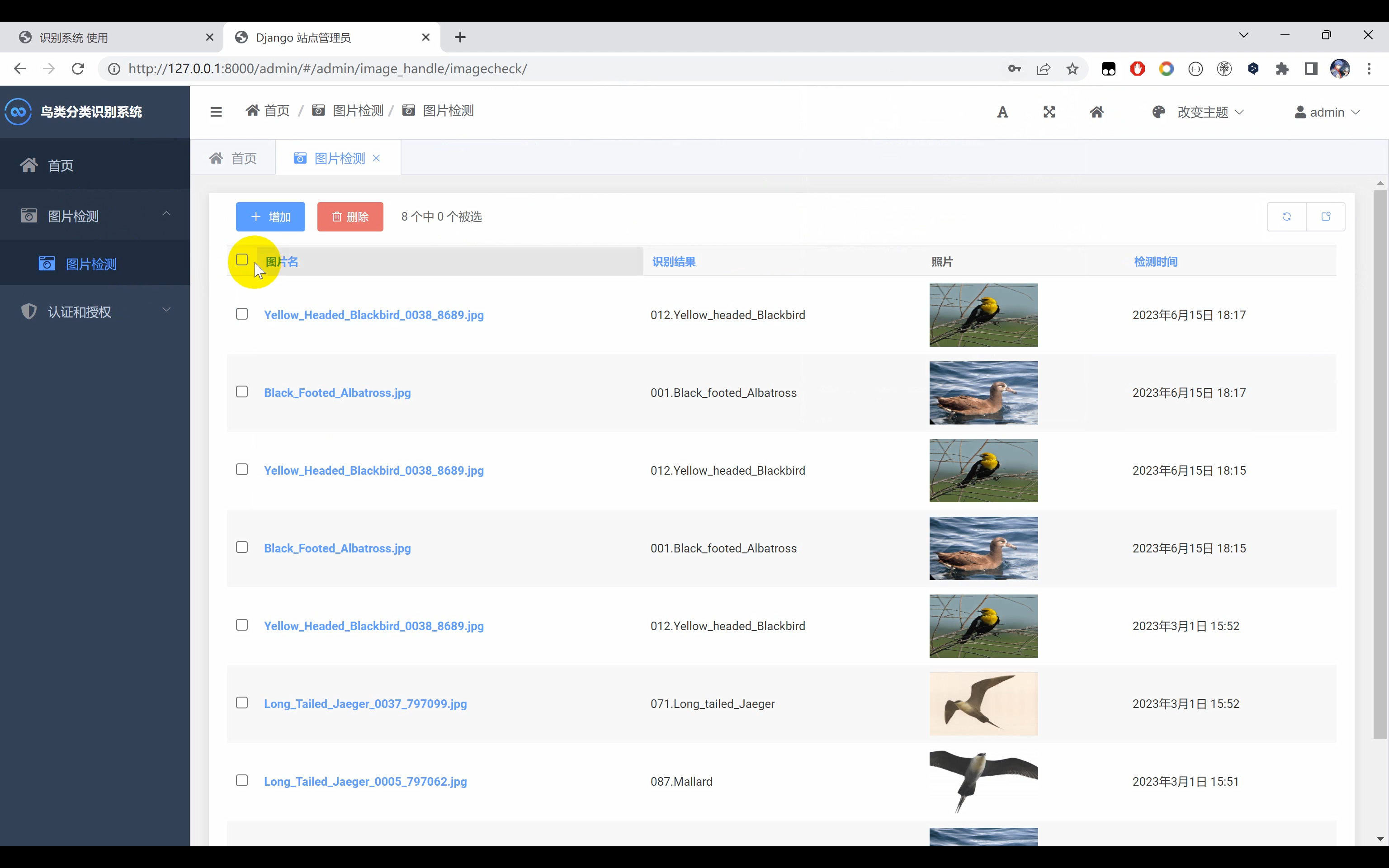
三、演示视频+代码
视频+完整代码:https://www.yuque.com/ziwu/yygu3z/txsu6elpcf0o5az1
四、TensorFlow使用
TensorFlow是由Google开发的一个开源机器学习框架。它的设计目标是让开发者能够更轻松地构建、训练和部署机器学习模型。TensorFlow的核心理念是使用计算图来表示复杂的数值计算过程,这使得它能够高效地执行分布式计算和自动微分操作。
TensorFlow的特点之一是其灵活性。它提供了丰富的工具和库,适用于各种机器学习任务和算法。无论是传统的机器学习算法还是深度学习模型,TensorFlow都可以提供强大的支持。此外,TensorFlow还支持多种硬件和平台,包括CPU、GPU和TPU等,使得开发者可以根据实际需求选择最合适的计算资源。
TensorFlow使用计算图来表示机器学习模型。计算图是一种数据流图,其中节点表示操作,边表示数据流。通过将模型表示为计算图,TensorFlow可以对模型进行高效的优化和并行化处理。此外,计算图的结构还使得TensorFlow能够轻松地将模型部署到分布式系统中,实现高性能的分布式训练和推理。
TensorFlow还提供了自动微分的功能,使得开发者可以轻松地计算模型的梯度。这对于训练深度学习模型来说尤为重要,因为梯度计算是反向传播算法的关键步骤。TensorFlow的自动微分功能大大简化了梯度计算的过程,减少了开发者的工作量。
除了这些核心特点之外,TensorFlow还具有丰富的生态系统和社区支持。它提供了许多高级API和预训练模型,使得开发者能够更快地构建模型。此外,TensorFlow还支持可视化工具,如TensorBoard,用于可视化模型的训练过程和性能分析。
总的来说,TensorFlow是一个功能强大、灵活而又易用的机器学习框架。它的设计理念和特点使得开发者能够更加高效地构建、训练和部署机器学习模型,为机器学习和深度学习的研究和应用提供了强大的工具和支持。
下面介绍的是TensorFlow的使用的一个demo例子
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 下载并解压数据集
!wget http://www.vision.caltech.edu/visipedia-data/CUB-200-2011/CUB_200_2011.tgz
!tar -xf CUB_200_2011.tgz
# 设置数据集路径和其他参数
train_data_dir = 'CUB_200_2011/train' # 训练集路径
validation_data_dir = 'CUB_200_2011/val' # 验证集路径
test_data_dir = 'CUB_200_2011/test' # 测试集路径
img_width, img_height = 224, 224 # 图像宽度和高度
batch_size = 32 # 批次大小
num_epochs = 10 # 训练轮数
# 创建图像数据生成器
train_datagen = ImageDataGenerator(
rescale=1. / 255, # 像素值缩放为0-1之间
shear_range=0.2, # 随机剪切变换
zoom_range=0.2, # 随机缩放变换
horizontal_flip=True) # 随机水平翻转
validation_datagen = ImageDataGenerator(rescale=1. / 255) # 验证集不进行数据增强
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') # 生成训练集图像和标签的批次数据
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') # 生成验证集图像和标签的批次数据
# 创建并编译ResNet50模型
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3))
model = tf.keras.Sequential([
base_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(200, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size,
epochs=num_epochs)
# 保存模型
model.save('bird_classification_model.h5')
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 下载并解压数据集
!wget http://www.vision.caltech.edu/visipedia-data/CUB-200-2011/CUB_200_2011.tgz
!tar -xf CUB_200_2011.tgz
# 设置数据集路径和其他参数
train_data_dir = 'CUB_200_2011/train' # 训练集路径
validation_data_dir = 'CUB_200_2011/val' # 验证集路径
test_data_dir = 'CUB_200_2011/test' # 测试集路径
img_width, img_height = 224, 224 # 图像宽度和高度
batch_size = 32 # 批次大小
num_epochs = 10 # 训练轮数
# 创建图像数据生成器
train_datagen = ImageDataGenerator(
rescale=1. / 255, # 像素值缩放为0-1之间
shear_range=0.2, # 随机剪切变换
zoom_range=0.2, # 随机缩放变换
horizontal_flip=True) # 随机水平翻转
validation_datagen = ImageDataGenerator(rescale=1. / 255) # 验证集不进行数据增强
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') # 生成训练集图像和标签的批次数据
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') # 生成验证集图像和标签的批次数据
# 创建并编译ResNet50模型
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3))
model = tf.keras.Sequential([
base_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(200, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size,
epochs=num_epochs)
# 保存模型
model.save('bird_classification_model.h5')