SpringCloud学习笔记
未经授权不得转载,创作不易,违者必究
一、微服务架构
1.1 应用架构发展
集中式架构
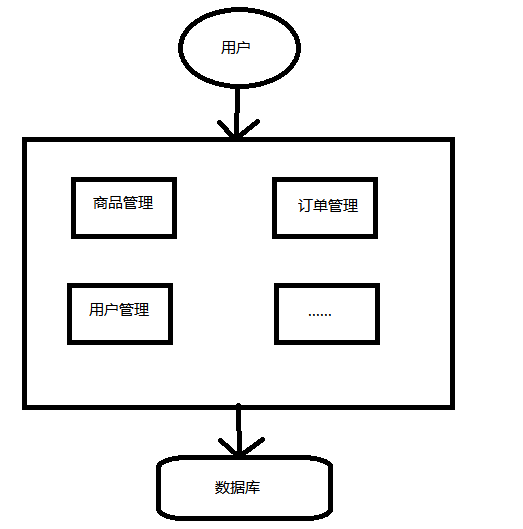
网站流量很小,一个应用将所有功能部署
优点:系统开发速度快;维护成本低;适用于并发要求较低的系统
缺点:代码耦合高,维护困难;无法进行不同模块的针对性优化;无法水平拓展;单点容错率低,并发能力差。
垂直拆分
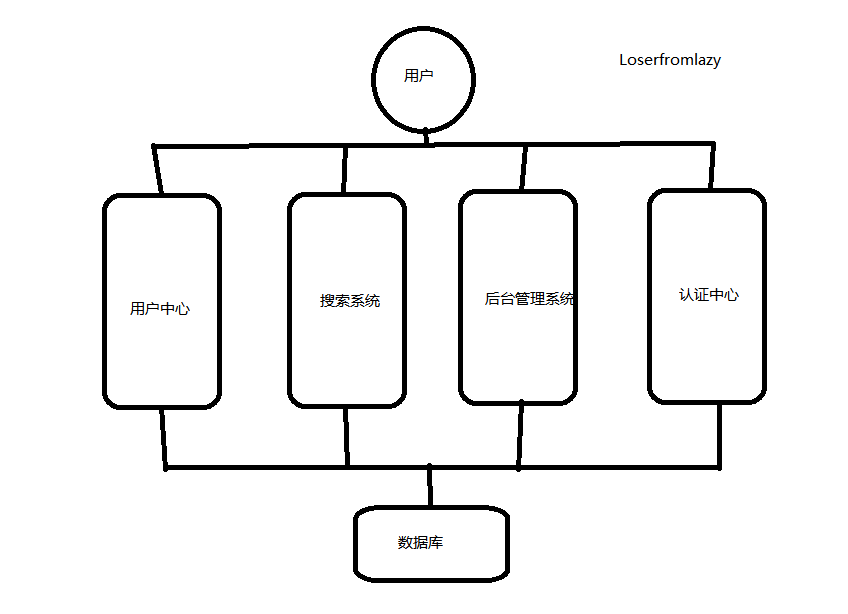
当访问量增大,为了应对更高的并发和业务需求,对业务进行拆分。
优点:系统拆分实现类流量分担,解决了并发,可以针对不同模块进行优化,方便水平拓展负载均衡,容错率提高。
缺点:系统相互独立,会有很多重复的开发工作,影响效率
分布式服务

当垂直应用越来越多,应用交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端能更快速地相应多变的市场需求
优点:将基础服务抽取,系统间互相调用提高了代码的复用和开发效率
缺点:系统间耦合变高,调用关系错综复杂,难以维护。
面向服务(SOA)
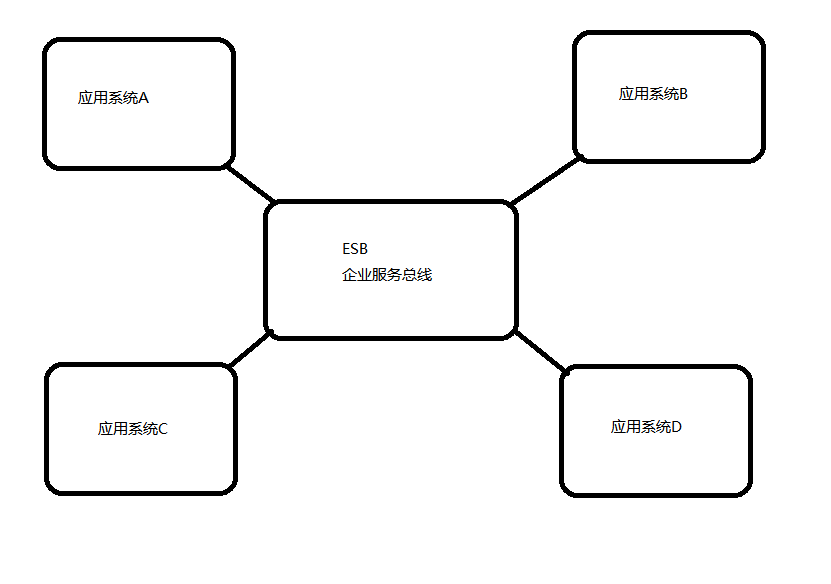
SOA面向服务架构,包含多个服务服务之间通过相互依赖最终提供一系列的功能。一个服务通常以独立的形式存在与操作系统进程中。各个服务之间通过网络调用。
缺点:每个供应商提供的ESB产品有偏差,自身实现较为复杂;应用服务粒度较大,ESB集成整合所有服务和协议、数据转换使得运维、测试部署困难。所有服务都通过一个通路通信,直接降低了通信速度。
微服务
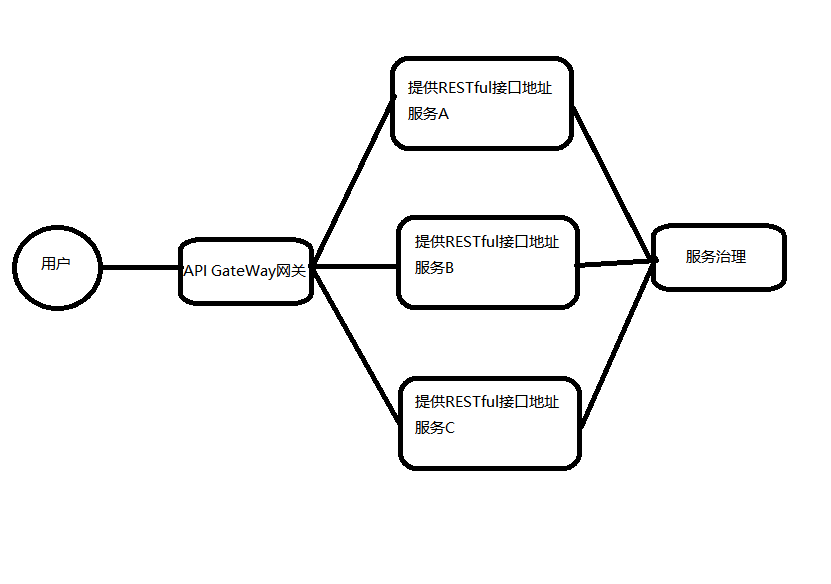
API Gateway网关是一个服务器,是系统的唯一入口。为每个客户端提供一个定制API。API网关核心是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。如它还可以具有其它职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。通常,网关提供RESTful/HTTP的方式访问服务。而服务端通过服务注册中心进行服务注册和管理。
微服务架构是使用一套小服务来开发单个应用的方式或途径,每个服务基于单一业务能力构建,运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API,并能够通过自动化部署机制来独立部署。这些服务可以使用不同的编程语言实现,以及不同数据存储技术,并保持最低限度的集中式管理。
1.2 服务调用方式
RPC和HTTP
无论是微服务还是SOA,都面临着服务间的远程调用。
常见的远程调用方式有以下2种:
RPC:Remote Produce Call远程过程调用,RPC基于Socket,工作在会话层。自定义数据格式,速度快,效率高。早期的webservice,现在热门的dubbo,都是RPC的典型代表。
Http:http其实是一种网络传输协议,基于TCP,工作在应用层,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用Http协议,也可以用来进行远程服务调用。缺点是消息封装臃肿,优势是对服务的提供和调用方没有任何技术限定,自由灵活,更符合微服务理念。
区别:RPC的机制是根据语言的API(language API)来定义的,而不是根据基于网络的应用来定义的。如果公司全部采用Java技术栈,那么使用Dubbo作为微服务架构是一个不错的选择。相反,如果公司的技术栈多样化,而且你更青睐Spring家族,那么Spring Cloud搭建微服务是不二之选。
Http客户端工具
既然微服务选择了Http,那么我们就需要考虑自己来实现对请求和响应的处理。不过开源世界已经有很多的http客户端工具,能够帮助我们做这些事情,例如:
HttpClient
OKHttp
URLConnection
不过这些不同的客户端,API各不相同。而Spring也有对http的客户端进行封装,提供了工具类叫RestTemplate。
Spring的RestTemplate
Spring提供了一个RestTemplate模板工具类,对基于Http的客户端进行了封装,并且实现了对象与json的序列化和
反序列化,非常方便。RestTemplate并没有限定Http的客户端类型,而是进行了抽象,目前常用的3种都有支持:HttpClient、OkHttp、JDK原生的URLConnection(默认的)
1.3 微服务中的一些概念
-
服务注册和服务发现
服务注册:服务提供者将所提供服务的信息(服务器IP和端⼝、服务访问协议等)注册/登记到注册中⼼。
服务发现:服务消费者能够从注册中⼼获取到较为实时的服务列表,然后根究⼀定的策略选择⼀个服务访问。
-
负载均衡
负载均衡即将请求压⼒分配到多个服务器(应⽤服务器、数据库服务器等),以此来提⾼服务的性能、可靠性。
-
熔断
熔断即断路保护。微服务架构中,如果下游服务因访问压⼒过⼤⽽响应变慢或失败,上游服务为了保护系统整体可⽤性,可以暂时切断对下游服务的调⽤。这种牺牲局部,保全整体的措施就叫做熔断。
-
链路追踪
微服务架构越发流⾏,⼀个项⽬往往拆分成很多个服务,那么⼀次请求就需要涉及到很多个服务。不同的微服务可能是由不同的团队开发、可能使⽤不同的编程语⾔实现、整个项⽬也有可能部署在了很多服务器上(甚⾄百台、千台)横跨多个不同的数据中⼼。所谓链路追踪,就是对⼀次请求涉及的很多个服务链路进⾏⽇志记录、性能监控。
-
API网关
微服务架构下,不同的微服务往往会有不同的访问地址,客户端可能需要调⽤多个服务的接⼝才能完成⼀个业务需求,如果让客户端直接与各个微服务通信可能出现以下问题:
- 客户端需要调⽤不同的url地址,增加了维护调⽤难度
- 在⼀定的场景下,也存在跨域请求的问题(前后端分离就会碰到跨域问题,原本我们在后端采⽤Cors就能解决,现在利⽤⽹关,那么就放在⽹关这层做好了)
- 每个微服务都需要进⾏单独的身份认证
那么,API⽹关就可以较好的统⼀处理上述问题,API请求调⽤统⼀接⼊API⽹关层,由⽹关转发请求。API⽹关更专注在安全、路由、流量等问题的处理上(微服务团队专注于处理业务逻辑即可),它的功能有:
- 统⼀接⼊——路由
- 安全防护——统⼀鉴权,负责⽹关访问身份认证验证,与“访问认证中⼼”通信,实际认证业务逻辑交移“访问认证中⼼”处理
- 黑白名单——实现通过IP地址控制禁⽌访问⽹关功能,控制访问
- 协议适配——实现通信协议校验、适配转换的功能
- 流量管控——限流
- 长短连接支持
- 容错能力(负载均衡)
二、Spring Cloud概述
2.1 什么是SpringCloud
[百度百科]Spring Cloud是⼀系列框架的有序集合。它利⽤Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中⼼、消息总线、负载均衡、断路器、数据监控等,都可以⽤ Spring Boot的开发⻛格做到⼀键启动和部署。Spring Cloud并没有重复制造轮⼦,它只是将⽬前各家公司开发的⽐较成熟、经得起实际考验的服务框架组合起来,通Spring Boot⻛格进⾏再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了⼀套简单易懂、易部署和易维护的分布式系统开发⼯具包。
Spring Cloud 规范及实现意图要解决的问题其实就是微服务架构实施过程中存在的⼀些问题,⽐如微服务架构中的服务注册发现问题、⽹络问题(⽐如熔断场景)、统⼀认证安全授权问题、负载均衡问题、链路追踪等问题。
2.2 Spring Cloud架构
SpringCloud的核心组件按照发展可以分为第一代SpringCloud组件和第二代核心组件。
| 第一代(Netflix,SCN) | 第二代(Alibaba,SCA) | |
|---|---|---|
| 注册中心 | Netflix Eureka | 阿里 Nacos |
| 客户端负载均衡 | Netflix Ribbon | 阿里 Dubbo LB、SpringCloud Loadbalancer |
| 熔断器 | Netflix Hystrix | 阿里 Sentinel |
| 网关 | Netflix Zuul | SpringCloud Gateway |
| 配置中心 | SpringCloud Config | 阿里 Nacos、携程Apollo |
| 服务调用 | Netflix Feign | 阿里 Dubbo RPC |
| 消息驱动 | SpringCloud Stream | |
| 链路追踪 | SpringCloud Sleuth/Zipkin | |
| 阿里巴巴Seata分布式事务 |
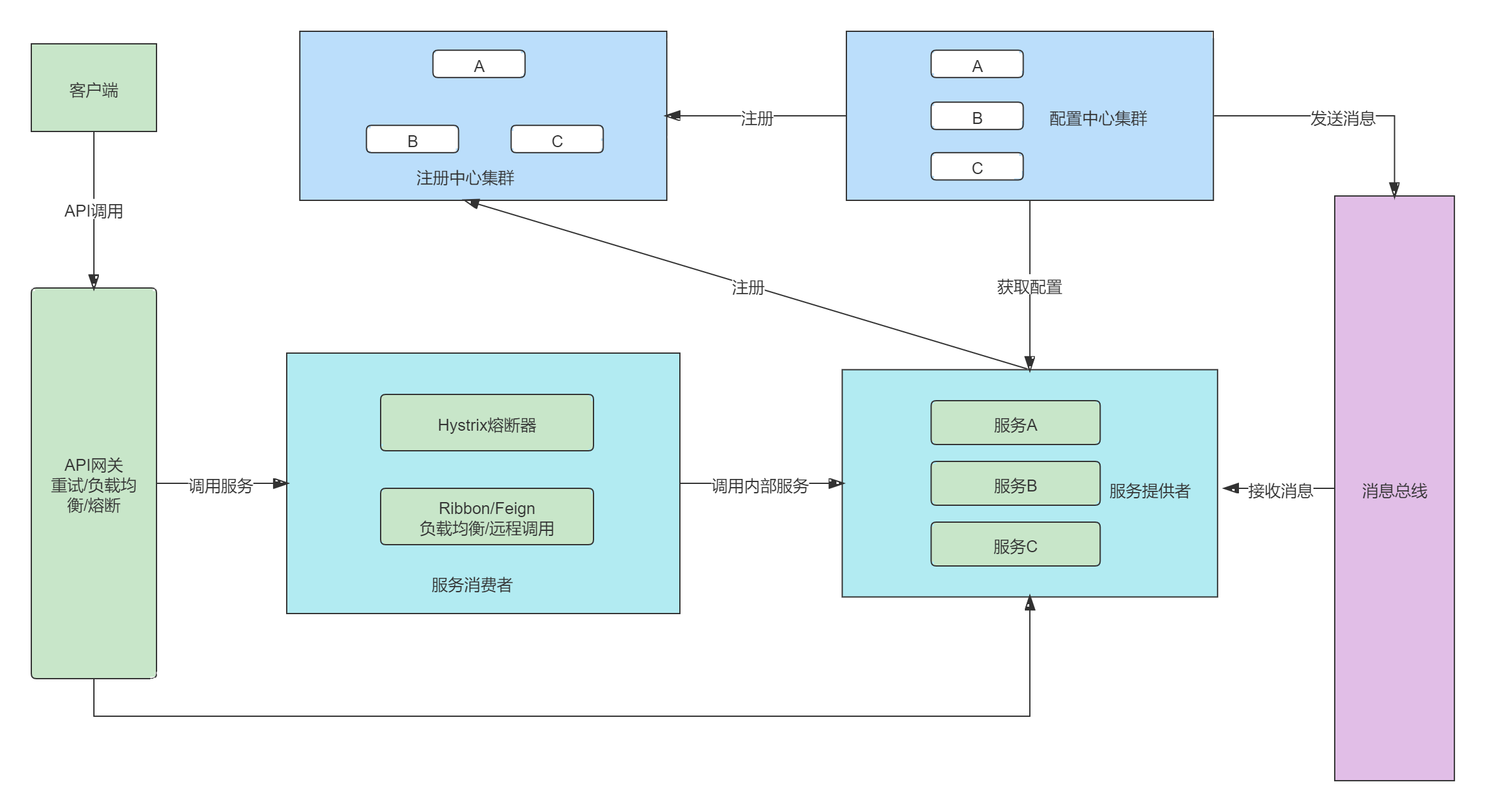
Spring Cloud中的各组件协同⼯作,才能够⽀持⼀个完整的微服务架构。⽐如:
- 注册中⼼负责服务的注册与发现,很好将各服务连接起来
- API⽹关负责转发所有外来的请求
- 断路器负责监控服务之间的调⽤情况,连续多次失败进⾏熔断保护。
- 配置中⼼提供了统⼀的配置信息管理服务,可以实时的通知各个服务获取最新的配置信息
2.3 对dubbo和SpringBoot的关系
Dubbo是阿⾥巴巴公司开源的⼀个⾼性能优秀的服务框架,基于RPC调⽤,对于⽬前使⽤率较⾼的Spring Cloud Netflflix来说,它是基于HTTP的,所以效率上没有Dubbo⾼,但问题在于Dubbo体系的组件不全,不能够提供⼀站式解决⽅案,⽐如服务注册与发现需要借助于Zookeeper等实现,⽽Spring Cloud Netflflix则是真正的提供了⼀站式服务化解决⽅案,且有Spring⼤家族背景。
Spring Cloud 只是利⽤了Spring Boot 的特点,让我们能够快速的实现微服务组件开发,否则不使⽤Spring Boot的话,我们在使⽤Spring Cloud时,每⼀个组件的相关Jar包都需要我们⾃⼰导⼊配置以及需要开发⼈员考虑兼容性等各种情况。所以Spring Boot是我们快速把Spring Cloud微服务技术应⽤起来的⼀种⽅式。
三、微服务入门案例
我们在这部分模拟一个微服务之间的调用,在之后会一步一步使用SpringCloud组件对案例进行改造。
后续变动都会在此基础上进行修改
案例需求:在交友App中会有这样类似的一个功能,就是推荐”心动女生“,根据用户的心动条件,每天匹配一定数量的”心动女生“推荐给该用户,在推荐之前查询以下女生的资料是否是保密状态,如果是保密状态则不再推荐该用户。自动推荐功能在自动推荐微服务(微服务A)中,资料查询在个人资料微服务(微服务B)中,那么就涉及到服务之间的调用,这时A就是一个服务消费者,B就是一个服务提供者。
建表语句:
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '姓名',
`sex` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '性别',
`birthday` date NULL DEFAULT NULL COMMENT '出生日期',
`phone` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '电话号码',
`email` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '邮件',
`status` varchar(80) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '状态',
`head_pic` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '头像',
`height` int(4) NULL DEFAULT NULL COMMENT '身高',
`weight` int(4) NULL DEFAULT NULL COMMENT ' 体重',
`isOpen` int(1) NULL DEFAULT NULL COMMENT ' 是否开放推荐自己简介0关闭1打开2资料不完整3从未设置',
`isDel` tinyint(1) NULL DEFAULT NULL COMMENT '是否删除',
`refuse_count` int(11) NULL DEFAULT NULL COMMENT '拒绝次数',
`one_word` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '签名',
`live_city` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '居住城市',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
创建完成后请手动建几个测试数据
3.1 父工程
根据以上需求,首先创建父工程,删除src,修改pom文件。导入springboot相关依赖,持久层框架使用mybatisplus。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.learn</groupId>
<artifactId>MyGirl</artifactId>
<version>1.0-SNAPSHOT</version>
<modules>
<module>common</module>
<module>user</module>
<module>autodeliver</module>
</modules>
<packaging>pom</packaging>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.3.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
<version>1.18.20</version>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
</project>
然后创建三个子工程,继承父工程:如图所示
3.2 Common工程
修改pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>MyGirl</artifactId>
<groupId>com.learn</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>common</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.2</version>
</dependency>
</dependencies>
</project>
编写实体类
@Data
@TableName
public class UserInfo {
@TableId(value = "id",type = IdType.AUTO)
private Integer id;
private String name;
private String sex;
private Date birthday;
private String phone;
private String email;
private String status;
private String headPic;
private Integer height;
private Integer weight;
@TableField("isOpen")
private Integer open;
@TableField("isDel")
private Boolean del;
private Integer refuseCount;
private String oneWord;
private String liveCity;
}
3.3 user工程
创建一个根据id查询user的一套mapper,service和controller方法。工程结构如下:
Controller方法如下:
@RestController
@RequestMapping("/user")
public class UserInfoController {
@Autowired
private UserInfoService userInfoService;
@GetMapping("/findUserById")
public UserInfo findUserById(@RequestParam("id") Integer id) {
return userInfoService.findUserById(id);
}
}
3.4 autodeliver工程
注入RestTemplate,创建controller调用user工程的方法
@RestController
@RequestMapping("/autoDeliver")
public class AutoDeliverController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
UserInfo forObject = restTemplate.getForObject("http://127.0.0.1:8090/user/findUserById?id=" + uid, UserInfo.class);
System.out.println(forObject.getOpen());
return forObject.getOpen();
}
}
3.5 测试
测试user工程的方法

测试autodeliver工程的方法,看是否能拿到数据
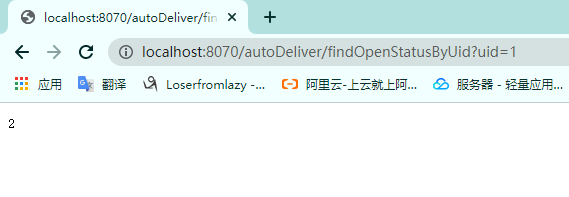
测试结果发现结果为2跟上面的测试user方法时拿到的open数据相同测试完成。
3.6 此案例问题以及微服务改造思路
此案例目前使用RestTemplate来调用服务,但如果在分布式集群的环境下就会有问题发生。
问题:
-
url地址硬编码,不方便维护
-
服务提供者现在只有一个实例,如果需要集群需要服务消费者自己实现负载均衡
-
服务消费者不清楚服务提供者的状态。
-
服务消费者调用服务提供者,如果出现故障会抛出异常很不友好
例如服务提供者挂掉了
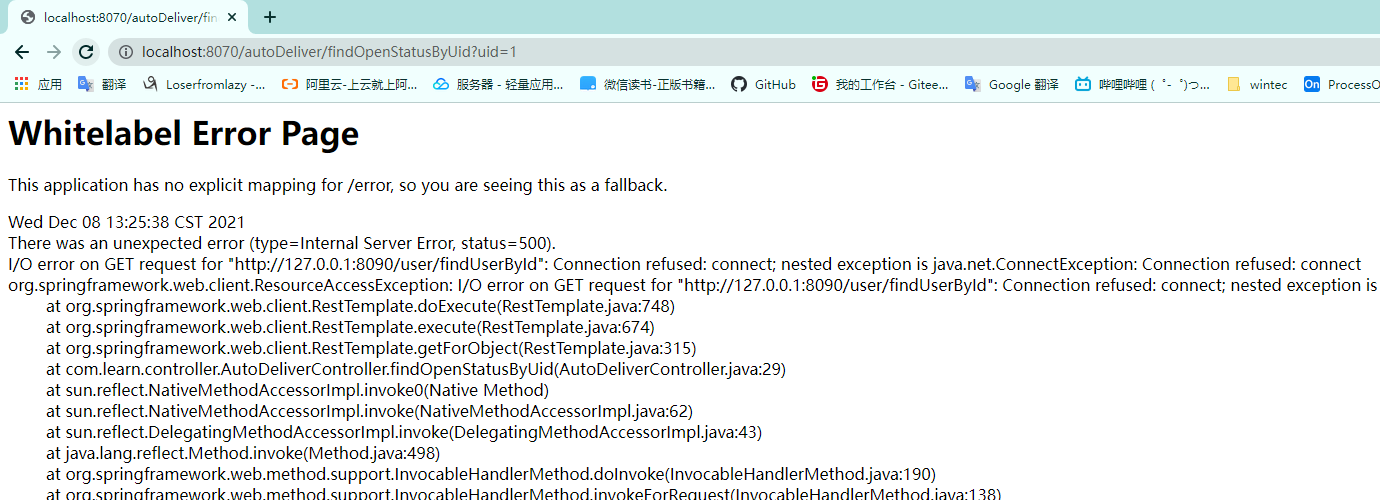
或者有异常发生
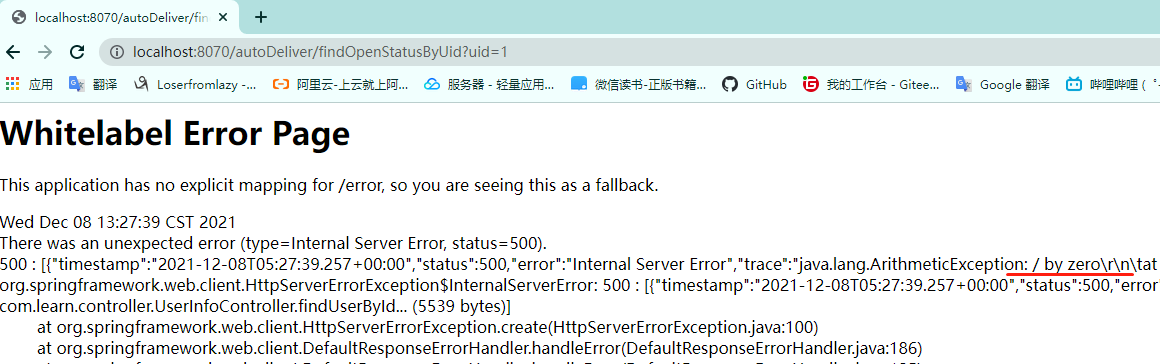
-
RestTemplate是否可以像Dubbo那样优化,即像通过调用方法那样调用远程方法
-
无法实现统一认证
-
配置文件有很多修改麻烦
-
......
以上的问题就是微服务可能出现的问题,在微服务中也需要进行解决。
在微服务中的解决思路:
- 服务管理:自动注册与发现、状态管理
- 服务负载均衡
- 熔断
- 远程调用
- 网关
- 统一认证
- 集中式配置
在SpringCloud或者SpringCloudAlibaba都有对应的解决方案。
四、SpringCloud核心组件
由于种种原因,放弃Zuul的学习,网关直接学习GateWay。
4.1 Eureka服务注册中心
4.1.1 服务注册中心简介
服务注册中心,本质上是为了解耦服务提供者和服务消费者。
对于任何⼀个微服务,原则上都应存在或者⽀持多个提供者(⽐如某个微服务部署多个实例),这是由微服务的分布式属性决定的。更进⼀步,为了⽀持弹性扩缩容特性,⼀个微服务的提供者的数量和分布往往是动态变化的,也是⽆法预先确定的。因此,原本在单体应⽤阶段常⽤的静态LB机制就不再适⽤了,需要引⼊额外的组件来管理微服务提供者的注册与发现,⽽这个组件就是服务注册中⼼。
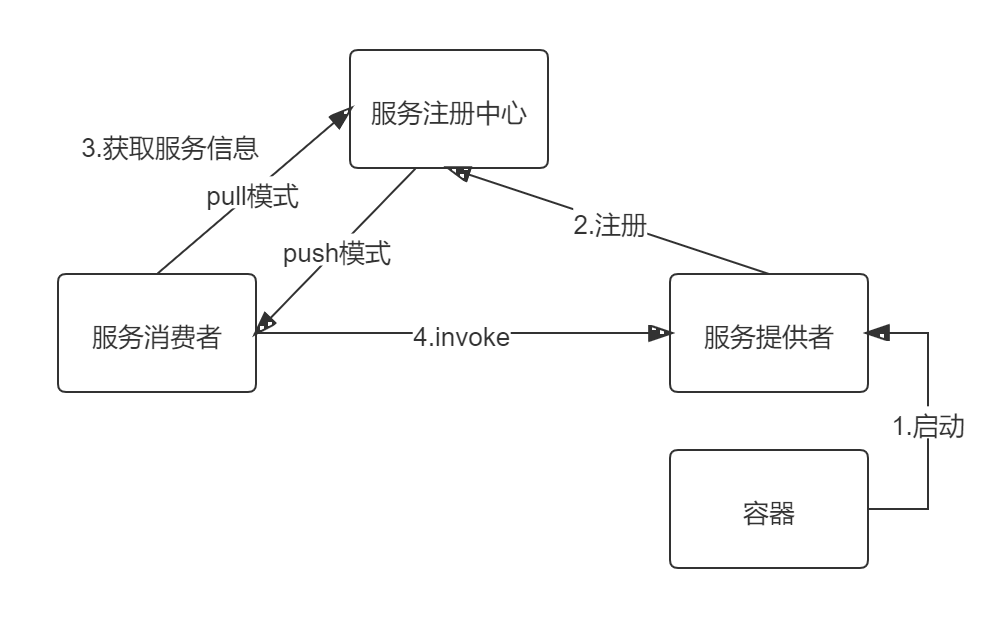
分布式微服务架构中,服务注册中⼼⽤于存储服务提供者地址信息、服务发布相关的属性信息,消费者通过主动查询和被动通知的⽅式获取服务提供者的地址信息,⽽不再需要通过硬编码⽅式得到提供者的地址信息。消费者只需要知道当前系统发布了那些服务,⽽不需要知道服务具体存在于什么位置,这就是透明化路由。
主流服务注册中心对比
| 组件 | 语言 | CAP | 对外接口 |
|---|---|---|---|
| Eureka | Java | AP(自我保护机制,保证可用) | HTTP |
| Consul | Go | CP | HTTP/DNS |
| Zookeeper | Java | CP | 客户端 |
| Nacos | Java | CP/AP切换 | HTTP |
P:分区容错性;C:数据一致性;A高可用
4.1.2 Eureka架构
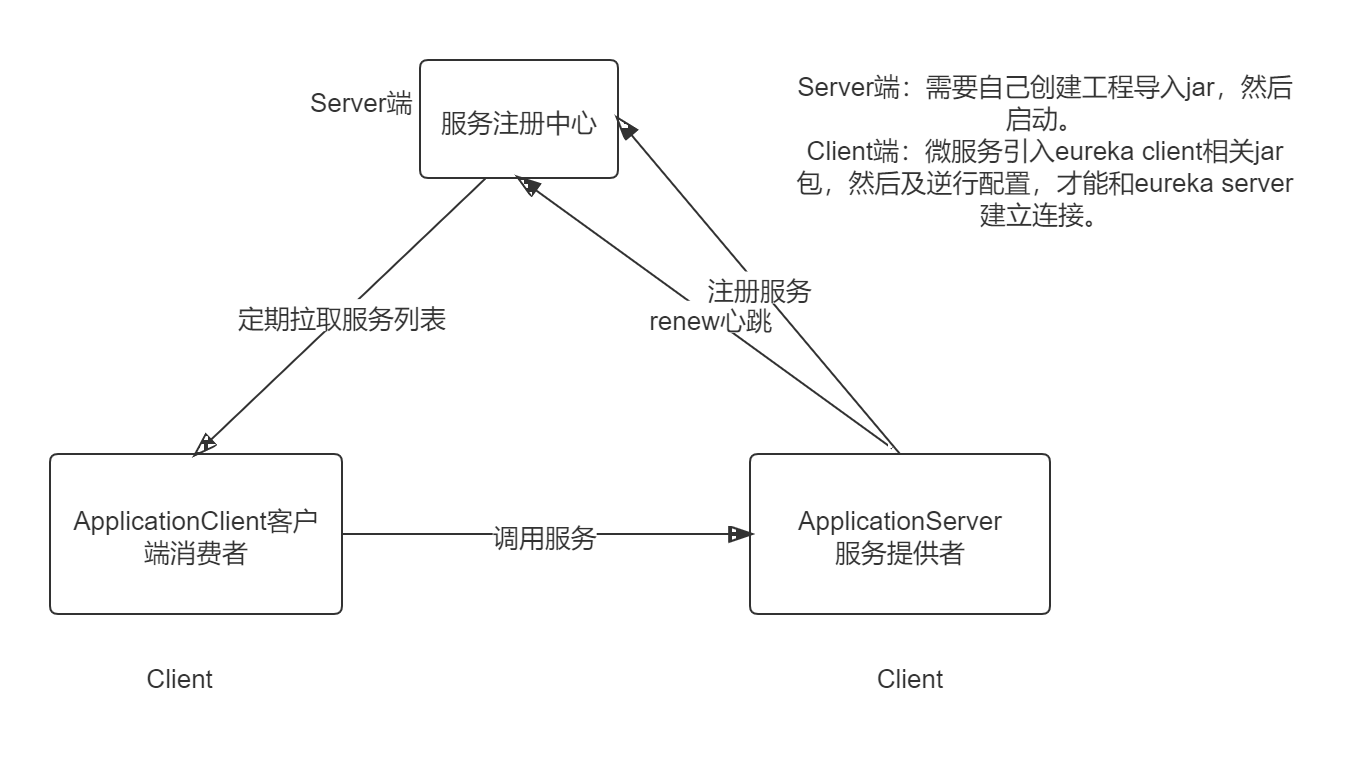
下图是官网架构:
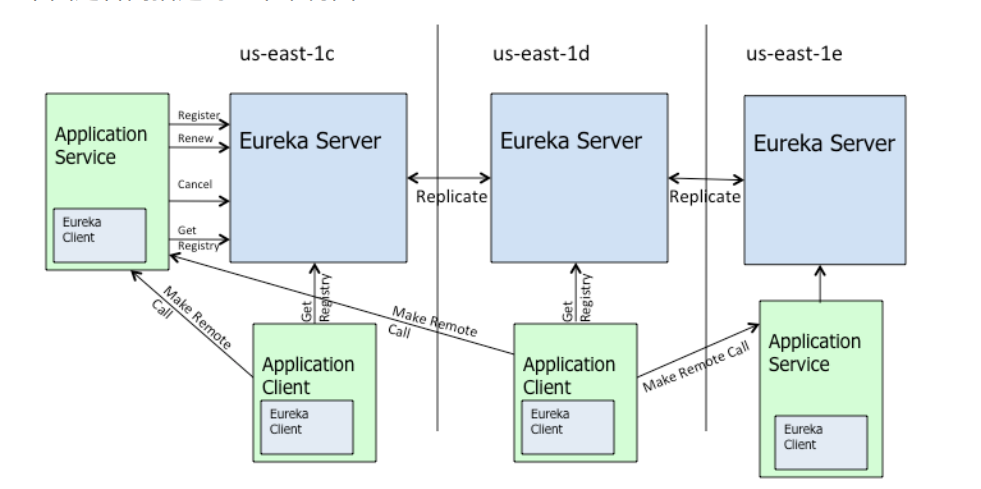
Eureka 包含两个组件:Eureka Server 和 Eureka Client,Eureka Client是⼀个Java客户端,⽤于简化与Eureka Server的交互;Eureka Server提供服务发现的能⼒,各个微服务启动时,会通过Eureka Client向Eureka Server 进⾏注册⾃⼰的信息(例如⽹络信息),Eureka Server会存储该服务的信息。
图中us-east-1c、us-east-1d,us-east-1e代表不同的区也就是不同的机房。图中每⼀个Eureka Server都是⼀个集群。图中Application Service作为服务提供者向Eureka Server中注册服务,Eureka Server接受到注册事件会在集群和分区中进⾏数据同步,Application Client作为消费端(服务消费者)可以从Eureka Server中获取到服务注册信息,进⾏服务调⽤。微服务启动后,会周期性地向Eureka Server发送⼼跳(默认周期为30秒)以续约⾃⼰的信息。Eureka Server在⼀定时间内没有接收到某个微服务节点的⼼跳,EurekaServer将会注销该微服务节点(默认90秒)。每个Eureka Server同时也是Eureka Client,多个Eureka Server之间通过复制的⽅式完成服务注册列表的同步。Eureka Client会缓存Eureka Server中的信息。即使所有的Eureka Server节点都宕掉,服务消费者依然可以使⽤缓存中的信息找到服务提供者。
4.1.3 Eureka应用和集群
下面我们通过以下顺序完成Eureka的学习:
首先创建单实例EurekaServer,然后在搭建EurekaServer集群,之后我们改造入门案例注册到集群完成调用。
创建单实例EurekaServer注册中心
在例子中创建eurekaserver8761工程,因为我们之后需要扩展集群,所以在项目名上加上端口号用来区分。
然后增加springcloud的eureka的依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
在父工程配置依赖的版本
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.RELEASE</version>
<!-- <version>Hoxton.SR4</version> -->
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
如果是jdk9以后默认时不加载jaxb的所以需要手动加上。因为eureka需要用到。
<!--引⼊Jaxb,开始--> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-core</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.2.10-b140310.1920</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> <!--引⼊Jaxb,结束-->
编写启动类和配置文件:
server:
port: 8761
spring:
application:
name: cloud-eureka-server #应用名称,会在eureka中作为server的唯一ID
eureka:
instance:
hostname: localhost #当前eureka实例的主机名
client:
service-url:
# 客户端与EurekaServer交互的地址,如果是集群,也需要写其它Server的地址
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
register-with-eureka: false # 自己就是服务不需要注册自己
fetch-registry: false #从Eureka Server获取服务信息,默认为true,置为false。自己就是服务不需要
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class,args);
}
}
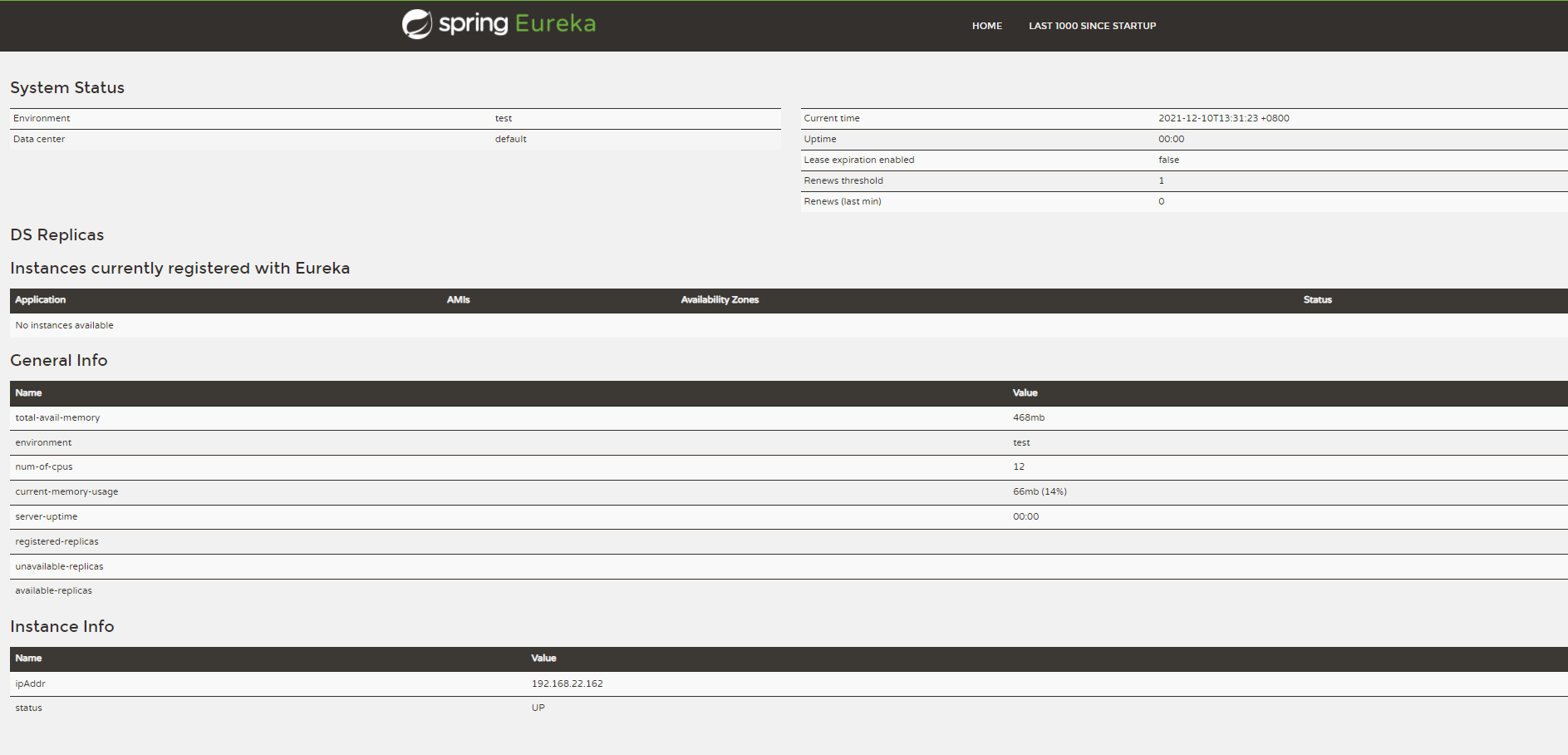
启动启动类访问127.0.0.1:8761看到以下页面说明EurekaServer发布成功。
搭建Eureka Server HA高可用集群
互联网应用中服务实例很少单个,因为如果只有一个实例,如果他挂掉而且微服务消费者的本地缓存列表也不可用,那么整个系统都会受到影响。
在生产环境中,我们可以配置Eureka Server集群,它的集群通过P2P通信的方式共享服务注册表,我们可以在这里开启两台Server来搭建集群。集群的架构与单体类似:
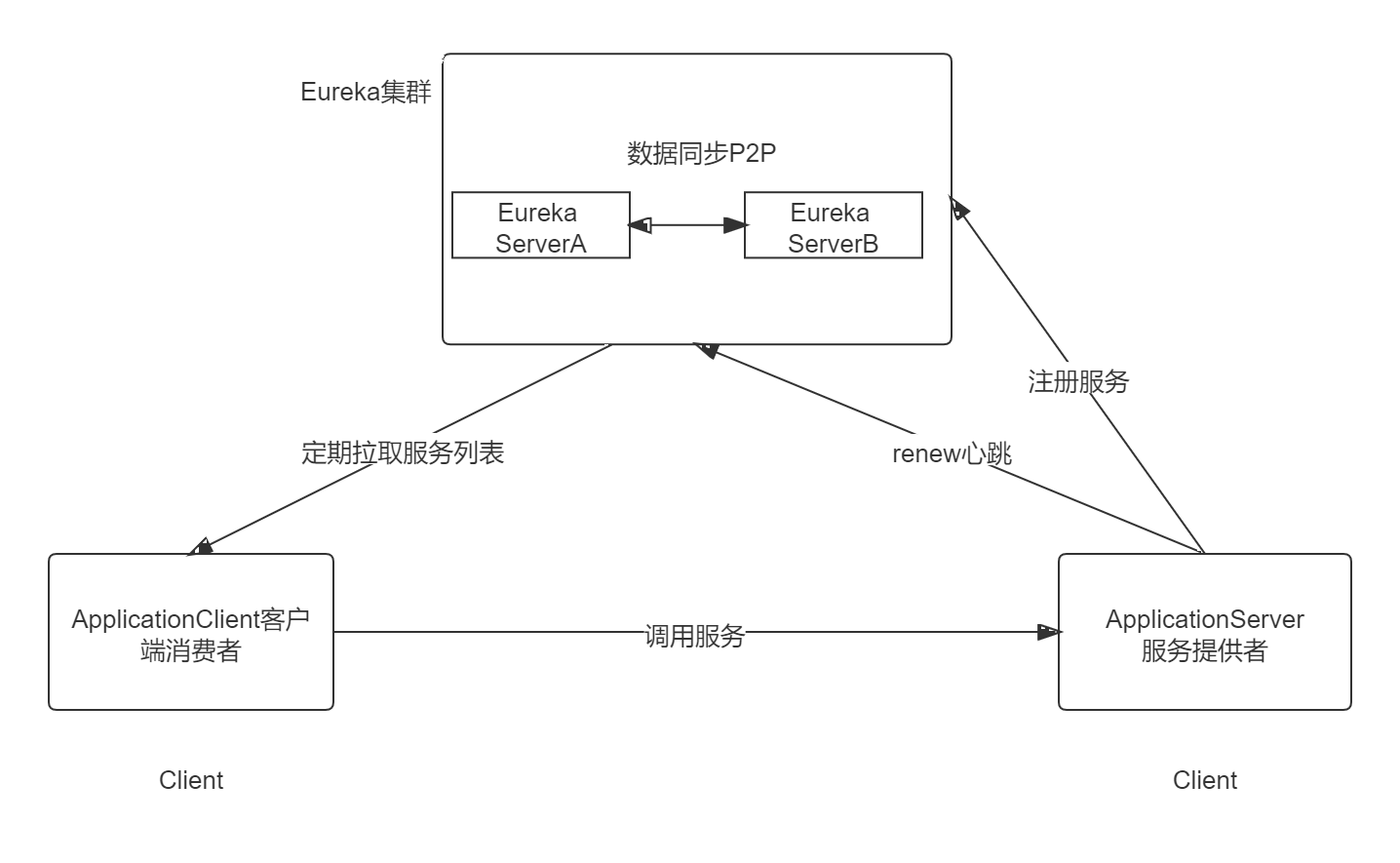
下面进行集群配置:
由于是在本地进⾏测试,很难模拟多主机的情况,Eureka配置server集群时需要执⾏host地址。 所以需要修改个⼈电脑中host地址。
127.0.0.1 CloudEurekaServerA
127.0.0.1 CloudEurekaServerB
因为eureka server本身也可以看作一个客户端,所以配置文件这样配即可,(可以看作是在其他server中注册自己)
server:
port: 8761
spring:
application:
name: cloud-eureka-server #应用名称,会在eureka中作为server的唯一ID
eureka:
instance:
hostname: CloudEurekaServerA #当前eureka实例的主机名
client:
service-url:
# 客户端与EurekaServer交互的地址,如果是集群,也需要写其它Server的地址
# 集群模式下,指向其他的Eureka Server ,如果有更多的实例逗号拼接即可
defaultZone: http://CloudEurekaServerB:8762/eureka/
register-with-eureka: true # 集群模式下可以改成true
fetch-registry: true #集群模式下可以改成true
server:
port: 8762
spring:
application:
name: cloud-eureka-server #应用名称,会在eureka中作为server的唯一ID
eureka:
instance:
hostname: CloudEurekaServerB #当前eureka实例的主机名
client:
service-url:
# 客户端与EurekaServer交互的地址,如果是集群,也需要写其它Server的地址
defaultZone: http://CloudEurekaServerA:8761/eureka/
register-with-eureka: true
fetch-registry: true
启动两个服务,http://CloudEurekaServerA:8761和http://CloudEurekaServerB:8762
可以看到两个服务的信息,且实例数为2,代表配置成功。

微服务注册到Eureka Server集群
在入门案例中有user工程作为服务提供者,autodeliver作为服务消费者,现在我们进行配置将服务提供者和服务消费者注册到Server集群。
服务提供者User工程配置:
首先在common工程中增加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-commons</artifactId>
</dependency>
然后在user工程中增加依赖
<!--eureka client客户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
然后在user工程中增加eureka配置,注释掉的配置可以不配,主要作用是修改实例名。
#注册到Eureka服务中心
eureka:
client:
service-url:
# 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。
defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
# instance:
# #使⽤ip注册,否则会使⽤主机名注册了(此处考虑到对⽼版本的兼容,新版本经过实验都是ip)
# prefer-ip-address: true
# #⾃定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress
# instance-id: ${spring.cloud.client.ip.address}:${spring.application.name}:${server.port}:@project.version@
最后增加注解
@SpringBootApplication
@MapperScan("com.learn.mapper")
//@EnableEurekaClient //开启Eureka Client
@EnableDiscoveryClient //开启注册中心客户端(通用型注解,比如注册到Eureka、Nacos等)
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class,args);
}
}
打开Eureka Server看User工程(服务提供者)是否能注册成功,如图现在已经注册成功

如果想集群可以参照以上配置完成User工程的集群。
服务消费者AutoDeliver工程配置:
增加依赖
<!--eureka client客户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
编写配置文件:
server:
port: 8070
#注册到Eureka服务中心
eureka:
client:
service-url:
# 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。
defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
# instance:
# #使⽤ip注册,否则会使⽤主机名注册了(此处考虑到对⽼版本的兼容,新版本经过实验都是ip)
# prefer-ip-address: true
# #⾃定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress
# instance-id: ${spring.cloud.client.ip.address}:${spring.application.name}:${server.port}:@project.version@
spring:
application:
name: autodeliver
启动类增加注解:
@SpringBootApplication(exclude= {DataSourceAutoConfiguration.class})
@EnableDiscoveryClient
public class AutoDeliverApplication {
public static void main(String[] args) {
SpringApplication.run(AutoDeliverApplication.class,args);
}
@Bean
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
然后我们启动工程看是否注册成功

如果想集群可以参照以上配置完成User工程的集群。
服务消费者调用服务提供者
改造Controller:
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
/*1.从Eureka Server中获取关注的那个服务的实力信息*/
List<ServiceInstance> user = discoveryClient.getInstances("user");
/*2.如果有多个实例选择一个来使用(负载均衡)*/
ServiceInstance serviceInstance = user.get(0);
/*3.从元数据信息获取host port*/
String host = serviceInstance.getHost();
int port = serviceInstance.getPort();
String url = "http://"+host+":"+port+"/user/findUserById?id="+uid;
System.out.println("############URL##########:"+url);
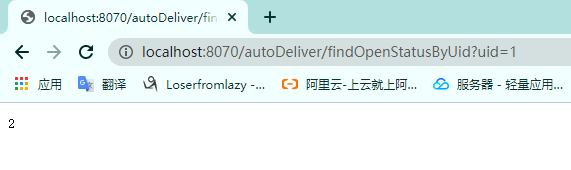
UserInfo forObject = restTemplate.getForObject(url, UserInfo.class);
return forObject.getOpen();
}
调用查看结果:
4.1.4 Eureka的元数据
Eureka的元数据有两种:标准元数据和自定义元数据
标准元数据:主机名、IP地址、端⼝号等信息,这些信息都会被发布在服务注册表中,⽤于服务之间的调⽤。
⾃定义元数据:可以使⽤eureka.instance.metadata-map配置,符合KEY/VALUE的存储格式。这 些元数据可以在远程客户端中访问。在程序中可以使⽤DiscoveryClient 获取指定微服务的所有元数据信息。自定义元数据如下:
eureka:
client:
service-url:
# 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。
defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
instance:
metadata-map:
testkey: testvalue
myname: haha
4.1.5 Eureka的客户端
服务提供者(也是Eureka客户端)要向EurekaServer注册服务,并完成服务续约等⼯作。
服务注册(服务提供者)
- 当我们导⼊了eureka-client依赖坐标,配置Eureka服务注册中心地址
- 服务在启动时会向注册中心发起注册请求,携带服务元数据信息
- Eureka注册中心会把服务的信息保存在Map中。
服务续约(服务提供者)
每隔30s会向注册中心续约(心跳)一次,如果没有心跳,租约会在90s后到期,然后服务会被失效。
eureka:
instance:
#发心跳间隔时间,默认30s
lease-renewal-interval-in-seconds: 30
#租约到期服务失效时间,默认90s
lease-expiration-duration-in-seconds: 90
获取服务列表(服务消费者)
每隔30秒服务会从注册中⼼中拉取⼀份服务列表,这个时间可以通过配置修改。往往不需要我们调整。
eureka:
instance:
#每隔多久拉取一次服务
registry-fetch-interval-seconds: 30
4.1.6 Eureka的服务端
服务下线
当服务正常关闭操作时,会发送服务下线的REST请求给EurekaServer。
服务中⼼接受到请求后,将该服务置为下线状态。
失效剔除
Eureka Server会定时(间隔值是eureka.server.eviction-interval-timer-in-ms,默认60s)进⾏检查,如果发现实例在在⼀定时间(此值由客户端设置的eureka.instance.lease-expiration-duration-in-seconds定义,默认值为90s)内没有收到⼼跳,则会注销此实例。
自我保护:
服务提供者 —> 注册中⼼定期的续约(服务提供者和注册中⼼通信),假如服务提供者和注册中⼼之间的⽹络有点问题,不代表服务提供者不可⽤,不代表服务消费者⽆法访问服务提供者。
如果在15分钟内超过85%的客户端节点都没有正常的⼼跳,那么Eureka就认为客户端与注册中⼼出现了⽹络故障,Eureka Server⾃动进⼊⾃我保护机制。
为什么会有⾃我保护机制?
默认情况下,如果Eureka Server在⼀定时间内(默认90秒)没有接收到某个微服务实例的⼼跳,Eureka Server将会移除该实例。但是当⽹络分区故障发⽣时,微服务与Eureka Server之间⽆法正常通信,⽽微服务本身是正常运⾏的,此时不应该移除这个微服务,所以引⼊了⾃我保护机制。
当处于⾃我保护模式时
- 不会剔除任何服务实例(可能是服务提供者和EurekaServer之间⽹络问题),保证了⼤多数服务依然可⽤
- Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可⽤,当⽹络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中。
- 在Eureka Server⼯程中通过eureka.server.enable-self-preservation配置可⽤关停⾃我保护,默认值是打开。
4.2 Ribbon负载均衡
负载均衡⼀般分为服务器端负载均衡和客户端负载均衡
所谓服务器端负载均衡,⽐如Nginx、F5这些,请求到达服务器之后由这些负载均衡器根据⼀定的算法将请求路由到⽬标服务器处理。
所谓客户端负载均衡,⽐如我们要说的Ribbon,服务消费者客户端会有⼀个服务器地址列表,调⽤⽅在请求前通过⼀定的负载均衡算法选择⼀个服务器进⾏访问,负载均衡算法的执⾏是在请求客户端进⾏。
Ribbon是Netflflix发布的负载均衡器。Eureka⼀般配合Ribbon进⾏使⽤,Ribbon利⽤从Eureka中读取到服务信息,在调⽤服务提供者提供的服务时,会根据⼀定的算法进⾏负载。
4.2.1 Ribbon的应用
在服务消费者中,也就是入门案例中的autodeliver工程进行改造。eureka-client中会引入Ribbon的相关jar包,所以我们不需要引入jar包,直接使用。
测试前需要复制一份user工程做集群以便查看负载均衡效果。
实际开发中,我们只需要部署在不同服务器即可,不需要复制项目来做集群。
下面进行Ribbon的使用,使用时,只需要加一个注解即可:
@SpringBootApplication(exclude= {DataSourceAutoConfiguration.class})
@EnableDiscoveryClient
public class AutoDeliverApplication {
public static void main(String[] args) {
SpringApplication.run(AutoDeliverApplication.class,args);
}
@Bean
//Ribbon负载均衡
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
修改controller:
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
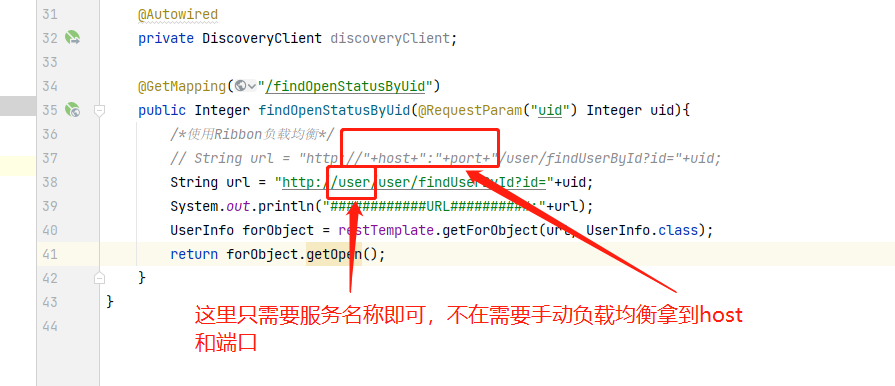
/*使用Ribbon负载均衡*/
String url = "http://user/user/findUserById?id="+uid;
System.out.println("############URL##########:"+url);
UserInfo forObject = restTemplate.getForObject(url, UserInfo.class);
return forObject.getOpen();
}
可以在服务提供者即User工程中返回当前的端口号,这样可以更好的查看负载均衡的效果。也可以加上日志如以下代码:
@GetMapping("/findUserById") public UserInfo findUserById(@RequestParam("id") Integer id) { System.out.println("当前是8090,目前请求到这里了"+new Date()); return userInfoService.findUserById(id); }
4.2.2 Ribbon负载均衡的策略
Ribbon内置了多种负载均衡策略,内部负责复杂均衡的顶级接⼝com.netflflix.loadbalancer.IRule
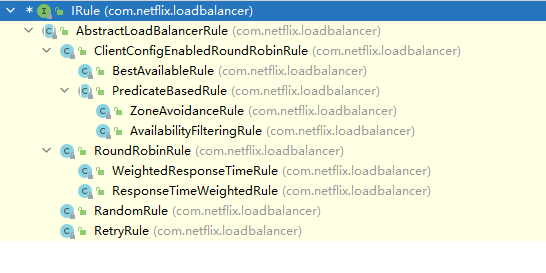
| 策略 | 描述 |
|---|---|
| RoundRobinRule:轮询策略 | 默认超过10次获取到的server都不可⽤,会返回⼀个空的server |
| RandomRule:随机策略 | 如果随机到的server为null或者不可⽤的话,会while不停的循环选取 |
| RetryRule:重试策略 | ⼀定时限内循环重试。默认继承RoundRobinRule,也⽀持⾃定义注⼊,RetryRule会在每次选取之后,对选举的server进⾏判断,是否为null,是否alive,并且在500ms内会不停的选取判断。⽽RoundRobinRule失效的策略是超过10次,RandomRule是没有失效时间的概念,只要serverList没都挂。 |
| BestAvailableRule:最小连接数策略 | 遍历serverList,选取出可⽤的且连接数最⼩的⼀个server。该算法⾥⾯有⼀个LoadBalancerStats的成员变量,会存储所有server的运⾏状况和连接数。如果选取到的server为null,那么会调⽤RoundRobinRule重新选取。 |
| AvailabilityFilteringRule:可⽤过滤策略 | 扩展了轮询策略,会先通过默认的轮询选取⼀个server,再去判断该server是否超时可⽤,当前连接数是否超限,都成功再返回 |
| ZoneAvoidanceRule:区域权衡策略(默认策略) | 扩展了轮询策略,继承了2个过滤器:ZoneAvoidancePredicate和AvailabilityPredicate,除了过滤超时和链接数过多的server,还会过滤掉不符合要求的zone区域⾥⾯的所有节点,AWS --ZONE 在⼀个区域/机房内的服务实例中轮询 |
4.3 Hystrix熔断器
4.3.1 微服务中的雪崩效应及解决方案
微服务中一个请求可能要多个微服务接口才能实现,会形成复杂的调用链路
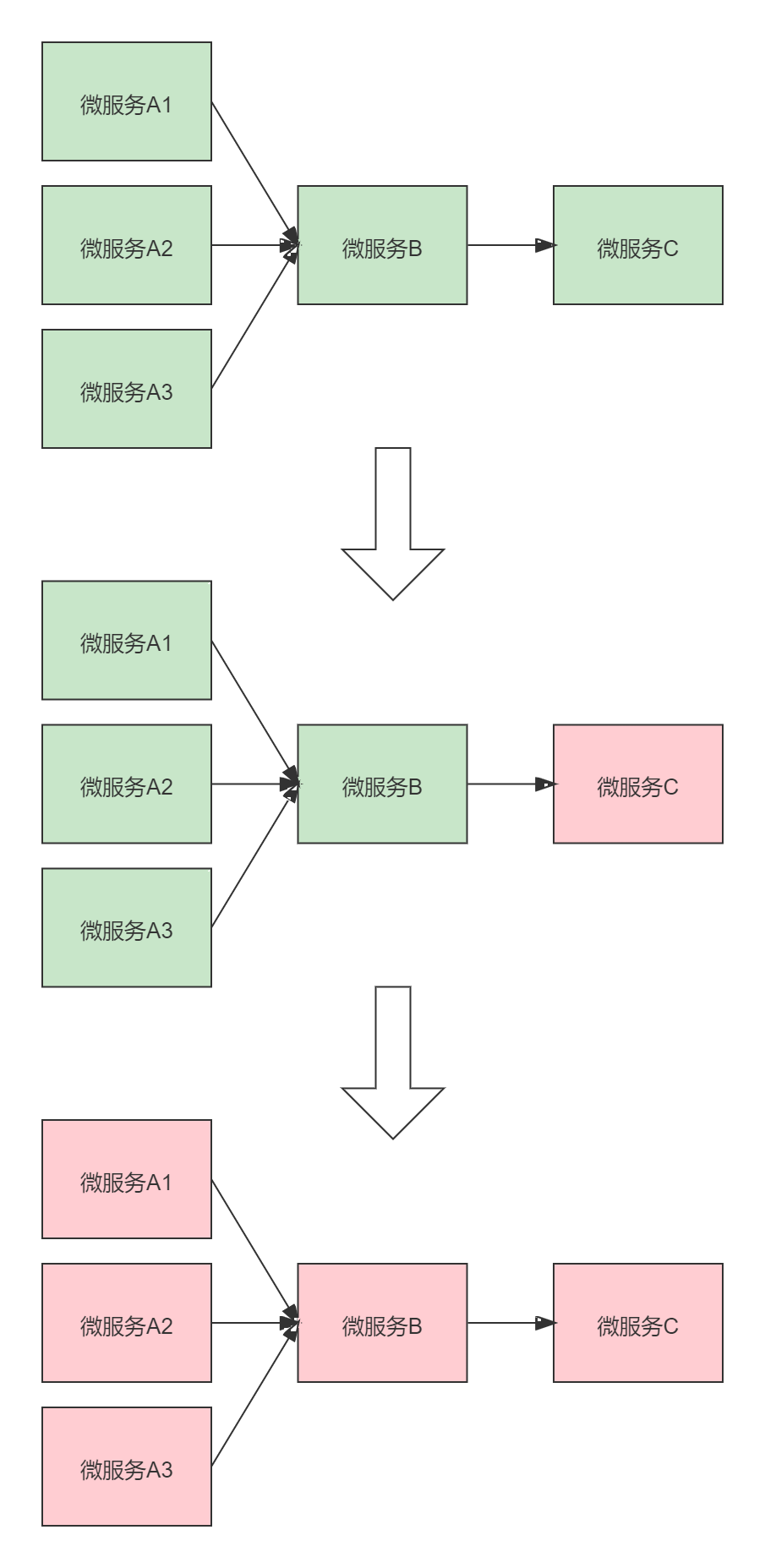
如上图,站在微服务B的角度上来说,上游微服务对它的调用是扇入,它对下游微服务的调用叫扇出。
扇⼊:代表着该微服务被调⽤的次数,扇⼊⼤,说明该模块复⽤性好
扇出:该微服务调⽤其他微服务的个数,扇出⼤,说明业务逻辑复杂
在微服务架构中,⼀个应⽤可能会有多个微服务组成,微服务之间的数据交互通过远程过程调⽤完成。这就带来⼀个问题,假设微服务A调⽤微服务B和微服务C,微服务B和微服务C⼜调⽤其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调⽤响应时间过⻓或者不可⽤,对微服务A的调⽤就会占⽤越来越多的系统资源,进⽽引起系统崩溃,所谓的“雪崩效应”。
如图中所示,最下游微服务C响应时间过⻓,⼤量请求阻塞,⼤量线程不会释放,会导致服务器资源耗尽,最终导致上游服务甚⾄整个系统瘫痪
解决雪崩效应主要有三种方法:
-
服务熔断
熔断机制是应对雪崩效应的⼀种微服务链路保护机制。当扇出链路的某个微服务不可⽤或者响应时间太⻓时,熔断该节点微服务的调⽤,进⾏服务的降级,快速返回错误的响应信息。当检测到该节点微服务调⽤响应正常后,恢复调⽤链路。
服务熔断重点在断,切断对下游服务的调⽤
服务熔断和服务降级往往是⼀起使⽤的,Hystrix就是这样。
-
服务降级
通俗讲就是整体资源不够⽤了,先将⼀些不关紧的服务停掉(调⽤我的时候,给你返回⼀个预留的值,也叫做兜底数据),待渡过难关⾼峰过去,再把那些服务打开。服务降级⼀般是从整体考虑,就是当某个服务熔断之后,服务器将不再被调⽤,此刻客户端可以⾃⼰准备⼀个本地的fallback回调,返回⼀个缺省值,这样做,虽然服务⽔平下降,但好⽍可⽤,⽐直接挂掉要强。
-
服务限流
服务降级是当服务出问题或者影响到核⼼流程的性能时,暂时将服务屏蔽掉,待⾼峰或者问题解决后再打开;但是有些场景并不能⽤服务降级来解决,⽐如秒杀业务这样的核⼼功能,这个时候可以结合服务限流来限制这些场景的并发/请求量。
限流措施也很多,⽐如
- 限制总并发数(⽐如数据库连接池、线程池)
- 限制瞬时并发数(如nginx限制瞬时并发连接数)
- 限制时间窗⼝内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,
- 限制每秒的平均速率)
- 限制远程接⼝调⽤速率、限制MQ的消费速率等
4.3.2 Hystrix简介
是由Netflflix开源的⼀个延迟和容错库,⽤于隔离访问远程系统、服务或者第三⽅库,防⽌级联失败,从⽽提升系统的可⽤性与容错性。Hystrix主要通过以下⼏点实现延迟和容错:
- 包裹请求:使⽤HystrixCommand包裹对依赖的调⽤逻辑。
- 跳闸机制:当某服务的错误率超过⼀定的阈值时,Hystrix可以跳闸,停⽌请求
该服务⼀段时间。 - 资源隔离:Hystrix为每个依赖都维护了⼀个⼩型的线程池(舱壁模式)(或者信号量)。如果该线程池已满, 发往该依赖的请求就被⽴即拒绝,⽽不是排队等待,从⽽加速失败判定。
- 监控:Hystrix可以近乎实时地监控运⾏指标和配置的变化,例如成功、失败、超时、以及被拒绝 的请求等。
- 回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执⾏回退逻辑。回退逻辑由开发⼈员 ⾃⾏提供,例如返回⼀个缺省值。
- ⾃我修复:断路器打开⼀段时间后,会⾃动进⼊“半开”状态。
4.3.3 Hystrix应用
如果我们的User工程长时间没有响应,服务消费者——自动投递微服务将快速失败给用户提示。下面我们进行修改:
首先在user工程(user8090和user8091修改一个即可,这样可以模拟两个服务实例其中一个坏掉)中进行线程休眠来模拟访问超时:
@GetMapping("/findUserById")
public UserInfo findUserById(@RequestParam("id") Integer id) {
//模拟访问超时
try {
Thread.sleep(10000);
}catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("当前是8091,目前请求到这里了"+new Date());
return userInfoService.findUserById(id);
}
然后在autodeliver工程中导入hystrix依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
启动类增加注解
@SpringBootApplication(exclude= {DataSourceAutoConfiguration.class})
@EnableDiscoveryClient
//@EnableHystrix //开启Hystrix功能
@EnableCircuitBreaker //开启熔断器功能
//@SpringCloudApplication //等价于@SpringBootApplication + @EnableDiscoveryClient + @EnableCircuitBreaker
public class AutoDeliverApplication {
public static void main(String[] args) {
SpringApplication.run(AutoDeliverApplication.class,args);
}
@Bean
@LoadBalanced//Ribbon负载均衡
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
然后修改Controller代码
//使用HystrixCommand注解进行熔断控制
@HystrixCommand(
//commandProperties:熔断的一些细节属性配置其中的每一个属性都是HystrixProperty
commandProperties = {
//设置服务超时时间
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "2000")
}
)
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
/*使用Ribbon负载均衡*/
// String url = "http://"+host+":"+port+"/user/findUserById?id="+uid;
String url = "http://user/user/findUserById?id="+uid;
System.out.println("############URL##########:"+url);
UserInfo forObject = restTemplate.getForObject(url, UserInfo.class);
return forObject.getOpen();
}
HystrixProperty的所有属性都在HystrixCommandProperties类中进行了配置。
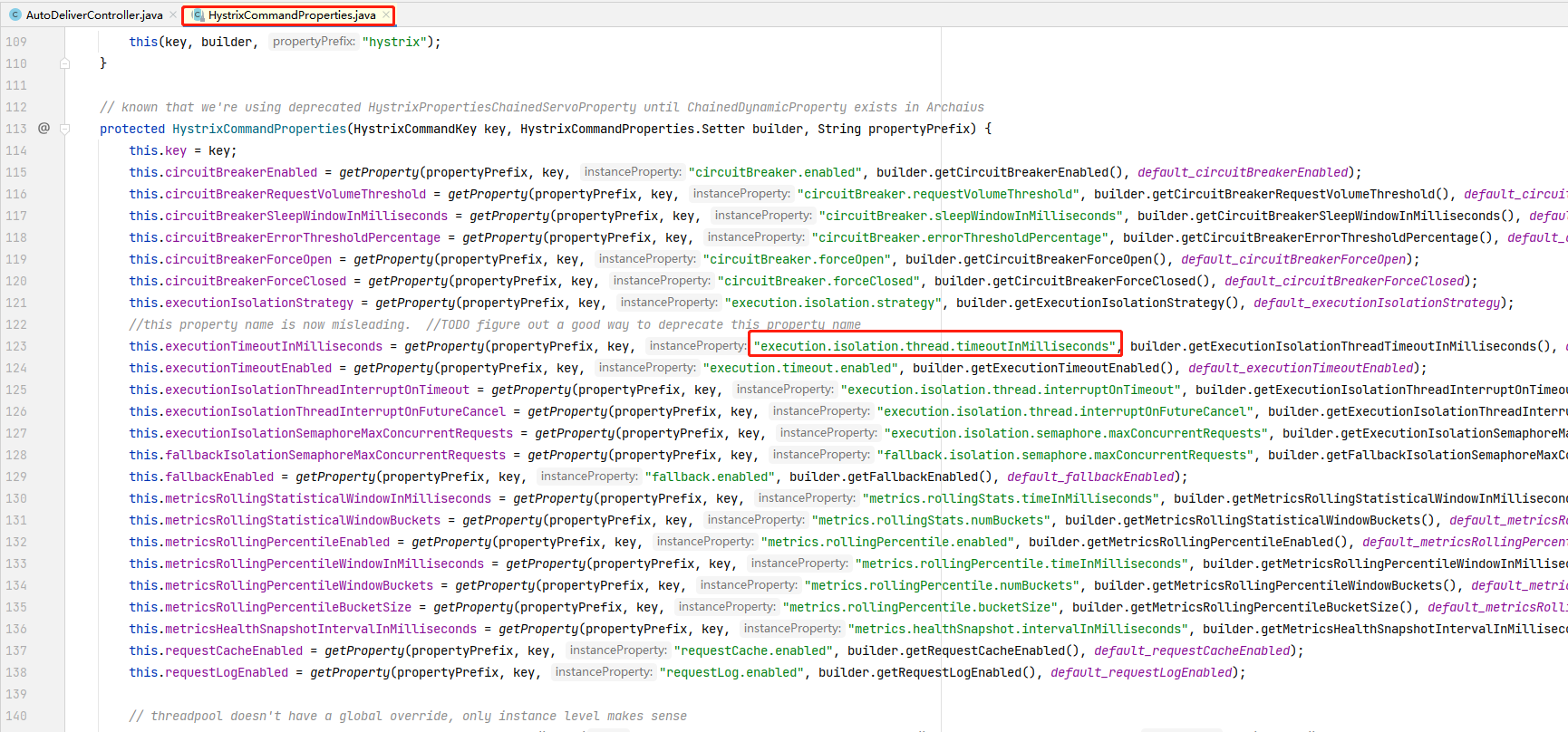
我们调用方法,因为我们只在一个服务提供者增加了休眠,所以我们会发现请求时一个会成功而另一个会超时熔断返回错误信息。
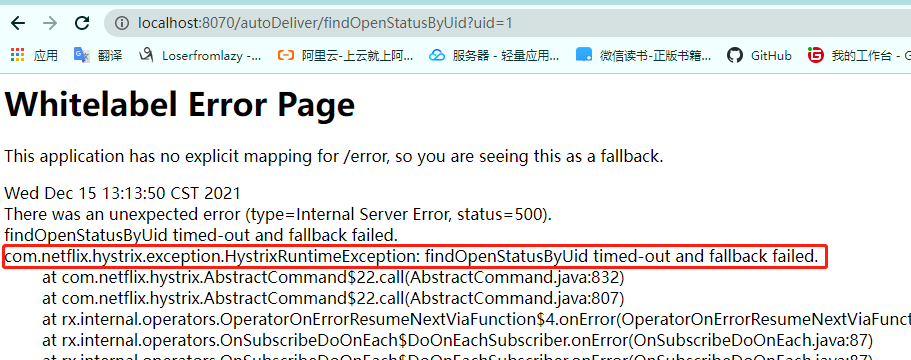
服务提供者处理超时熔断会返回错误信息,或者抛出异常信息,这些信息都会返回到服务消费者这里,但是有时候我们不想将收集到的异常或者错误信息抛到它的上游,比如以下业务场景:
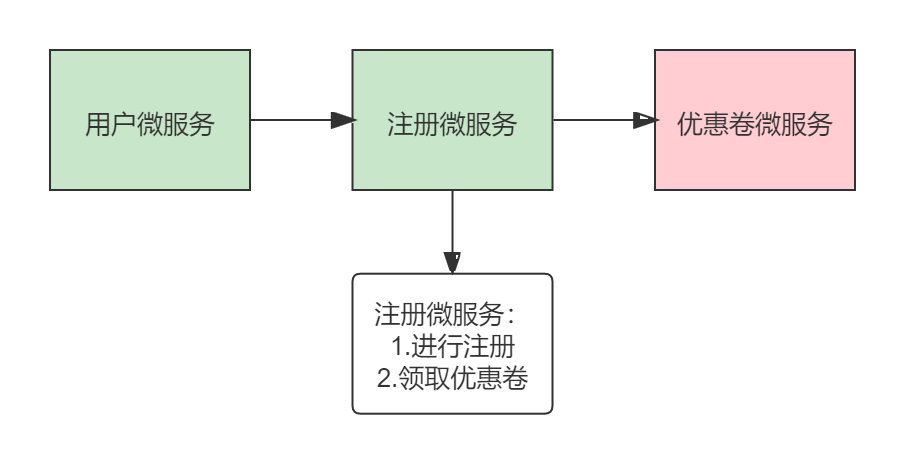
用户注册领取优惠卷,但优惠卷微服务返回了错误或异常信息,这时注册微服务直接返回给上游用户微服务很不好,所以我们可以返回一个默认数据(服务降级)。我们可以如下配置:
@RestController
@RequestMapping("/autoDeliver")
public class AutoDeliverController {
@Autowired
private RestTemplate restTemplate;
@Autowired
private DiscoveryClient discoveryClient;
//使用HystrixCommand注解进行熔断控制
@HystrixCommand(
//commandProperties:熔断的一些细节属性配置其中的每一个属性都是HystrixProperty
commandProperties = {
//设置服务超时时间
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "2000")
},
fallbackMethod = "myFallBack"
)
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
/*使用Ribbon负载均衡*/
// String url = "http://"+host+":"+port+"/user/findUserById?id="+uid;
String url = "http://user/user/findUserById?id="+uid;
System.out.println("############URL##########:"+url);
UserInfo forObject = restTemplate.getForObject(url, UserInfo.class);
return forObject.getOpen();
}
//回退方法,返回默认值
public Integer myFallBack(Integer uid){
return -1;//默认数据\兜底数据
}
}
降级方法的形参和返回值必须与原方法相同
也可以在类上使⽤@DefaultProperties注解统⼀指定整个类中共⽤的降级⽅法
这时我们可以看到超时后会返回我们设置的-1
4.3.4 Hystrix舱壁模式(线程池隔离策略)
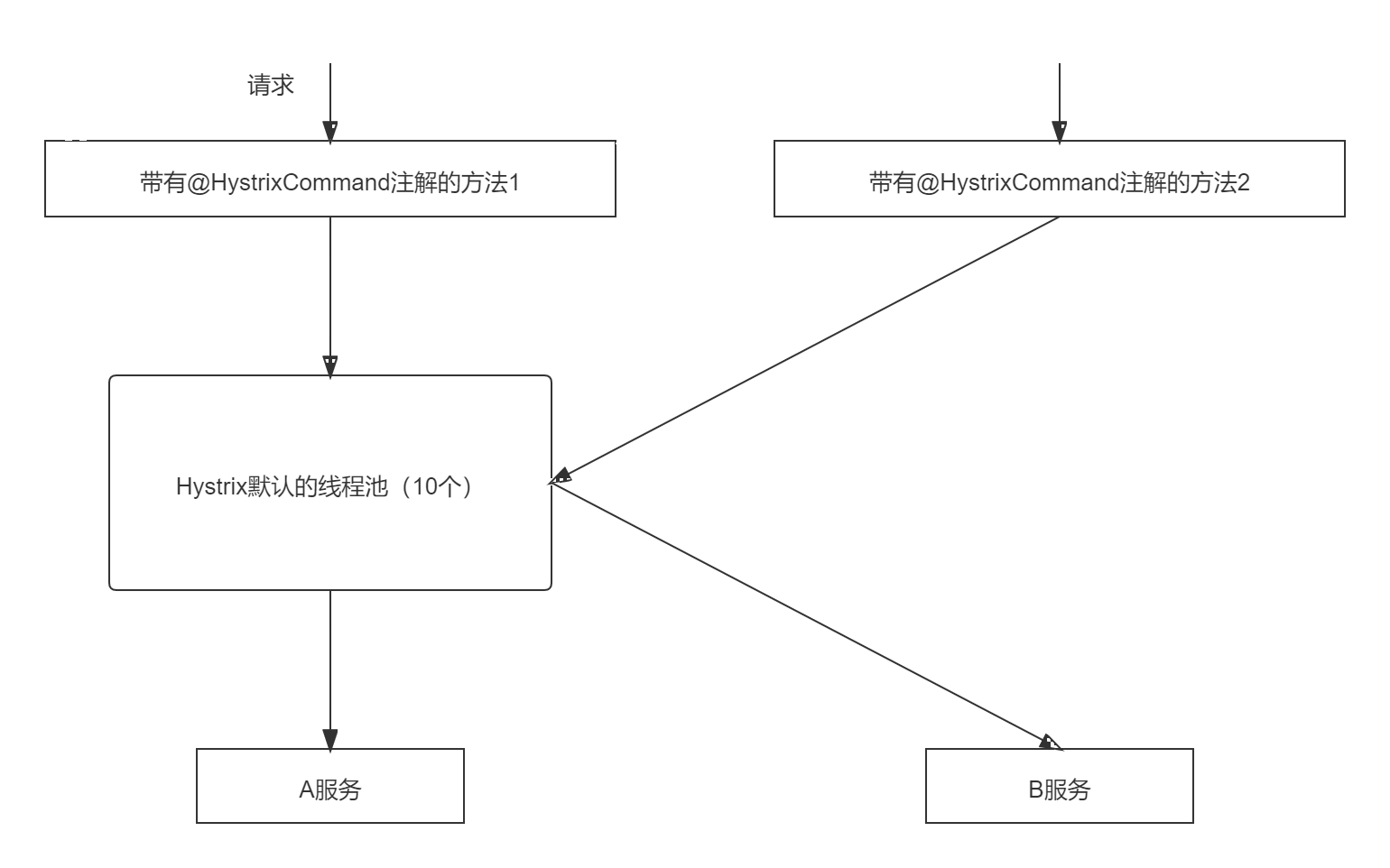
默认Hystrix有一个线程池有10个线程,如果某一个请求比如下图的请求1发了十二个请求请求A服务,那么其他请求只能等待或者拒绝连接,比如请求2,这并不是B服务不可用,而是线程不够的原因。
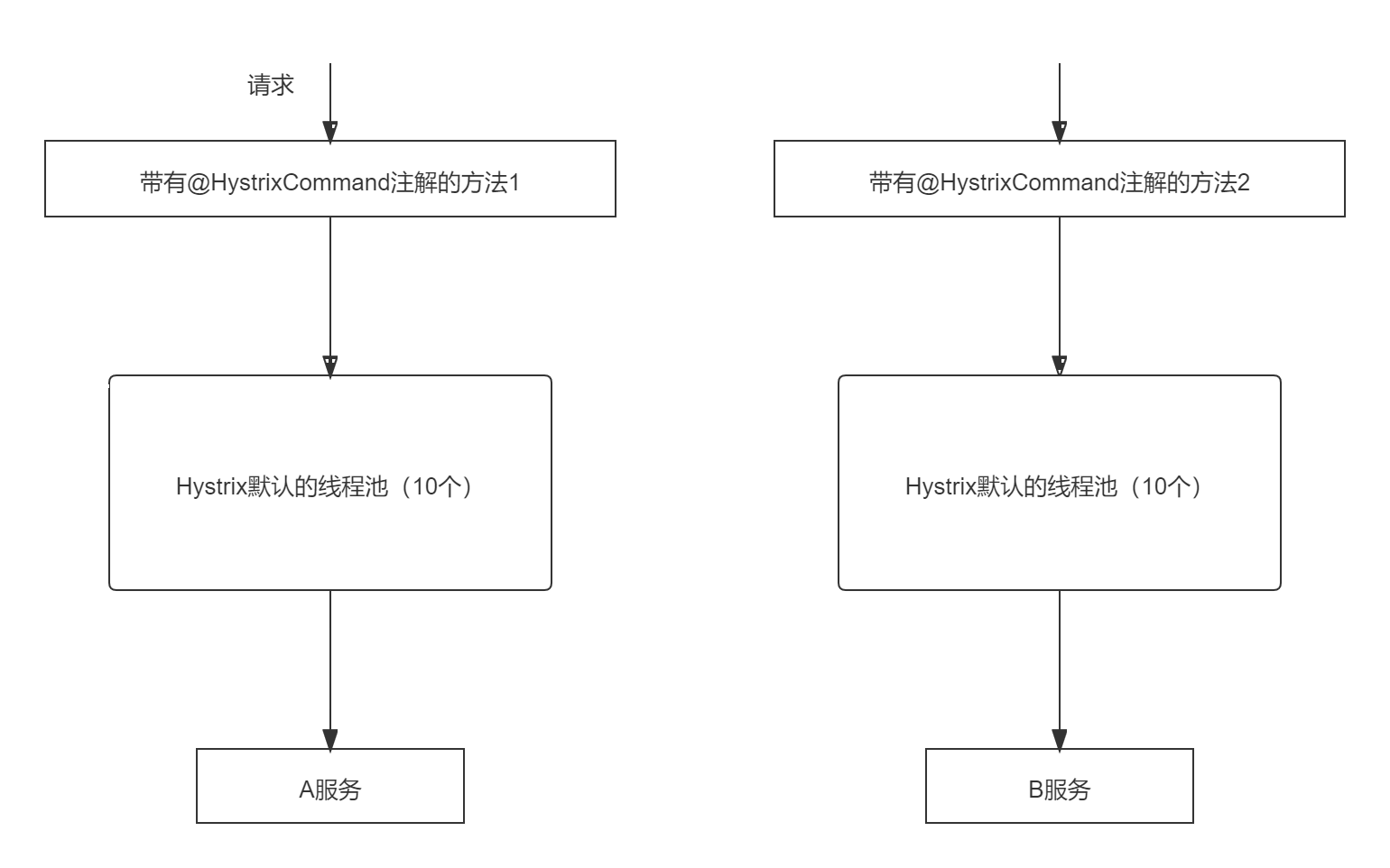
为了避免问题服务请求过多导致正常服务⽆法访问,Hystrix 不是采⽤增加线程数,⽽是单独的为每⼀个控制⽅法创建⼀个线程池的⽅式,这种模式叫做“舱壁模式",也是线程隔离的⼿段。如下图:
我们可以通过jps命令查看当前运行的Java进程,如图可以看到我们正在运行的五个进程:
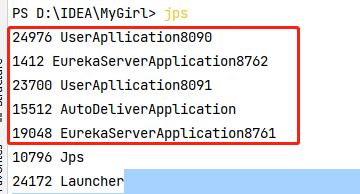
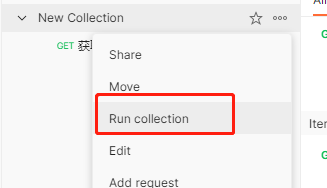
我们通过postman批量发请求发送20个请求,等待请求完成。
postman的文件夹可以使用RUN collectin创建批量请求:
然后我们可以使用jstack+pid 查看进程的线程信息可以通过grep过滤(windows下可以使用findstr代替)如下图:
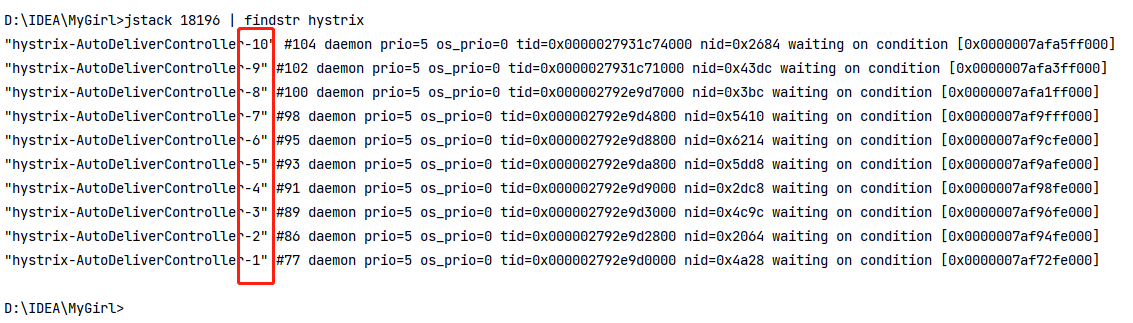
可以看到,虽然有20个请求,但是只有10个线程,所以如果不进⾏任何设置,所有熔断⽅法使⽤⼀个Hystrix线程池(10个线程),那么这样的话会因为我们的Hystrix的线程机制造成问题。
下面我们进行舱壁模式的修改,只需要设置线程池标识,并且唯一就可以每个方法使用自己的线程池,然后我们复制一个方法做对比:
@RestController
@RequestMapping("/autoDeliver")
public class AutoDeliverController {
@Autowired
private RestTemplate restTemplate;
@Autowired
private DiscoveryClient discoveryClient;
@HystrixCommand(
// 线程池标识,要保持唯一,不唯一的话就共用了
threadPoolKey = "findOpenStatusByUid",
// 线程池细节属性配置
threadPoolProperties = {
@HystrixProperty(name="coreSize",value = "2"),// 线程数
@HystrixProperty(name="maxQueueSize",value="20") // 等待队列长度
},
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "2000")
},
fallbackMethod = "myFallBack"
)
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
String url = "http://user/user/findUserById?id="+uid;
System.out.println("############URL##########:"+url);
UserInfo forObject = restTemplate.getForObject(url, UserInfo.class);
return forObject.getOpen();
}
@HystrixCommand(
// 线程池标识,要保持唯一,不唯一的话就共用了
threadPoolKey = "findOpenStatusByUid1",
// 线程池细节属性配置
threadPoolProperties = {
@HystrixProperty(name="coreSize",value = "2"),// 线程数
@HystrixProperty(name="maxQueueSize",value="20") // 等待队列长度
},
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "2000")
},
fallbackMethod = "myFallBack"
)
@GetMapping("/findOpenStatusByUid1")
public Integer findOpenStatusByUid1(@RequestParam("uid") Integer uid){
String url = "http://user/user/findUserById?id="+uid;
System.out.println("############URL##########:"+url);
UserInfo forObject = restTemplate.getForObject(url, UserInfo.class);
return forObject.getOpen();
}
//回退方法,返回默认值
public Integer myFallBack(Integer uid){
return -1;//默认数据\兜底数据
}
}
启动postman发10次请求,再查看线程情况,可以发现跟我们设置的是一致的,每个方法两个线程且不共用。

4.3.5 Hystrix工作流程及配置
如下图,当出现调用问题开一个默认10s的时间窗进行判断,如果达到阈值则跳闸,跳闸后开一个默认5s的活动窗口判断远程服务是否调用成功,调用成功则再开一个时间窗口重复流程。
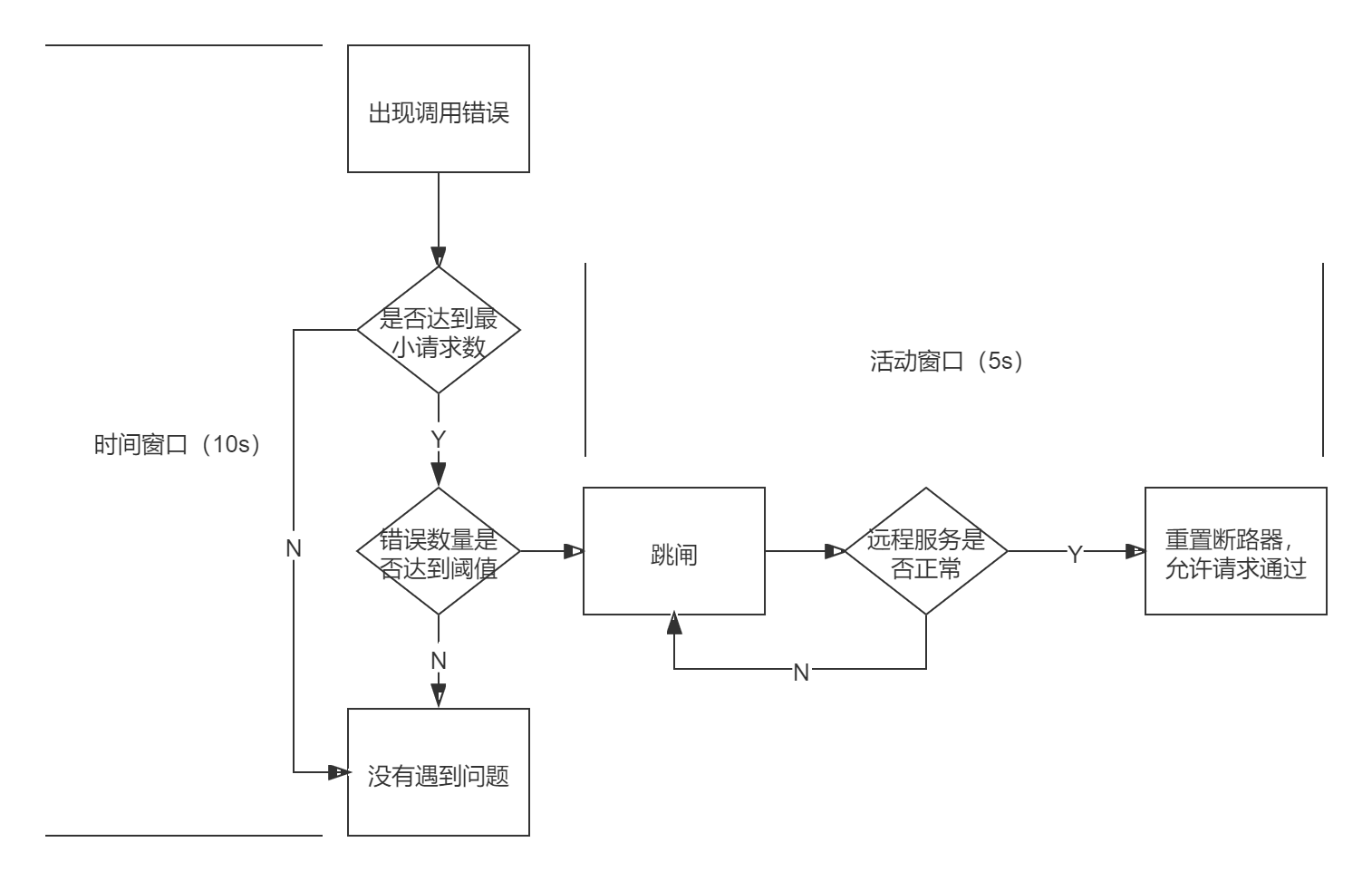
下面我们对上述条件进行配置
@HystrixCommand(
threadPoolKey = "findOpenStatusByUid",
threadPoolProperties = {
@HystrixProperty(name="coreSize",value = "2"),// 线程数
@HystrixProperty(name="maxQueueSize",value="20") // 等待队列长度
},
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "2000"),
//配置一个8s内请求次数达到2个失败率达到50%就跳闸的熔断器,跳闸后的活动窗口设置为3s
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds",value = "8000"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "2"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "50"),
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "3000")
},
fallbackMethod = "myFallBack"
)
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
String url = "http://user/user/findUserById?id="+uid;
System.out.println("############URL##########:"+url);
UserInfo forObject = restTemplate.getForObject(url, UserInfo.class);
return forObject.getOpen();
}
下面我们对验证Hystrix的章台,首先我们在autodeliver工程的配置文件中增加健康检查状态的配置,可以使用localhost:8070/actuator/health查看状态
# springboot中暴露健康检查等断点接⼝
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
我们首先启动项目访问健康检查接口,查看hystrix的状态:
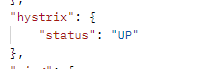
然后我们跟之前一样使用postman执行5次请求,在请求过程中一直访问健康检查接口,可以看到它的跳闸状态,然后在活动窗口时间内可以自我修复。下图为跳闸状态:

这些配置也可以配置在配置文件中:我们将代码中的配置注释掉然后在配置文件中编写,重启项目再次验证即可。
#Hystrix熔断策略
hystrix:
command:
default:
circuitBreaker:
# 强制打开熔断器,如果该属性设置为true,强制断路器进⼊打开状态,将会拒绝所有的请求。 默认false关闭的
forceOpen: false
# 触发熔断错误⽐例阈值,默认值50%
errorThresholdPercentage: 50
# 熔断后休眠时⻓,默认值5秒
sleepWindowInMilliseconds: 3000
# 熔断触发最⼩请求次数,默认值是20
requestVolumeThreshold: 2
execution:
isolation:
thread:
# 熔断超时设置,默认为1秒
timeoutInMilliseconds: 2000
4.4 Feign远程调用
4.4.1 Feign简介
之前服务消费者调用服务提供者时使用RestTemplate技术,但它存在不便,首先需要我们拼接URL,其次需要我们模板化的使用restTemplate。所以有了Feign来解决这个问题。
Feign是Netflflix开发的⼀个轻量RESTful的HTTP服务客户端(⽤它来发起请求,远程调⽤的),是以Java接口注解的⽅式调⽤Http请求,而不用像Java中通过封装HTTP请求报文的方式直接调用,Feign被⼴泛应⽤在Spring Cloud 的解决⽅案中。它类似于Dubbo,服务消费者拿到服务提供者的接⼝,然后像调⽤本地接口⽅法⼀样去调⽤,实际发出的是远程的请求。
SpringCloud对Feign进⾏了增强,使Feign⽀持了SpringMVC注解(OpenFeign)。
Feign = RestTemplate + Ribbon + Hystrix
4.4.2 Feign的应用
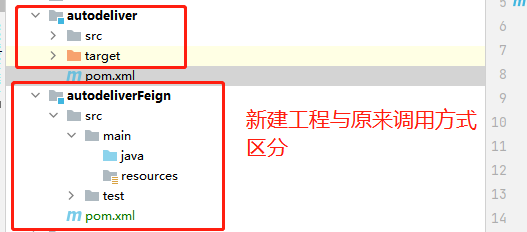
feign的应用只需要建立一个feignClient然后将服务提供者的接口放入feignClient即可,下面结合入门案例进行演示。
之前是用RestTemplate+Ribbon的方式进行远程调用的,为了与之区分我们新建一个工程:
我们导入依赖,不需要导入Ribbon和Hystrix,因为Feign = RestTemplate + Ribbon + Hystrix。
<dependencies>
<dependency>
<artifactId>common</artifactId>
<groupId>com.learn</groupId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
</dependencies>
然后将配置文件导入:
server:
port: 8071
#注册到Eureka服务中心
eureka:
client:
service-url:
# 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。
defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
instance:
metadata-map:
testkey: testvalue
myname: haha
spring:
application:
name: autodeliver
# springboot中暴露健康检查等断点接⼝
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
然后编写入口类,加入feign的注解:
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients //开启Feign客户端功能
public class AutoDeliverFeignApplication {
public static void main(String[] args) {
SpringApplication.run(AutoDeliverFeignApplication.class, args);
}
}
然后我们先把原来的controller拿过来,去掉之前的东西,如下:
@RestController
@RequestMapping("/autoDeliverFeign")
public class AutoDeliverFeignController {
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
return null;
}
}
现在我们的项目结构如下:

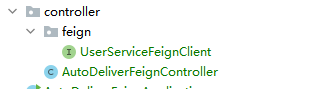
现在我们编写Feign的代码:
首先我们创建FeignClient:在controller下建立一个feign的包,然后建立feign客户端接口,如下:
//FeignClient表明当前类是一个FeignClient客户端;value指定要请求的服务名称,本项目中指的是user微服务
@FeignClient(name = "user")
@RequestMapping("/user")
public interface UserServiceFeignClient {
@GetMapping("/findUserById")
UserInfo findUserById(@RequestParam("id") Integer id);
}
然后我们在controller中调用feign方法即可,feign会自动帮我们访问远程接口
@RestController
@RequestMapping("/autoDeliverFeign")
public class AutoDeliverFeignController {
@Autowired
private UserServiceFeignClient userServiceFeignClient;
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
//表面上是调用本地方法,实际上feign帮我们拼接url访问远程方法
UserInfo userById = userServiceFeignClient.findUserById(uid);
return userById.getOpen();
}
}
当然,上述过程需要我们访问一个微服务就需要在自己的微服务中建立一个feignClient。
其实我们可以为每一个服务提供者(本例中就是user工程)创建一个api工程,在这个api工程中编写FeignClient,这样就可以把服务提供者的接口暴露出来,供服务消费者调用。
比如创建一个userApi工程,然后将需要别人调用的接口编写成FeignClient,这样别人只需要导入userApi工程的feignClient即可,不需要在自己的项目中编写feignClient。
4.4.3 Feign对Ribbon的支持
Feign本身已经集成了Ribbon依赖和自动配置,以此不需要引入额外的依赖,可以通过ribbon.xx进行全局配置或者通过服务名对执行微服务进行配置。
#针对的被调用的微服务名称,不加就是对所有调用的微服务生效
user:
ribbon:
#请求连接超时时间
ConnectTimeout: 2000
#请求处理超时时间
ReadTimeout: 5000
#对所有操作都进⾏重试
OkToRetryOnAllOperations: true
####根据如上配置,当访问到故障请求的时候,它会再尝试访问1次当前实例(次数由MaxAutoRetries配置),
####如果不⾏,就换⼀个实例进⾏访问,如果还不⾏,再换1次实例访问(更换次数由MaxAutoRetriesNextServer配置),
####如果依然不⾏,返回失败信息。
MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第⼀次调⽤
MaxAutoRetriesNextServer: 0 #切换实例的重试次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整
4.4.4 Feign日志输出
feign是http请求的客户端,它可以打印出一些详细信息,如果我们想看到Feign请求时的⽇志,我们可以进⾏配置,默认情况下Feign的⽇志没有开启。
首先开启Feign日志的功能和级别:
@Configuration
public class FeignLogConfig {
// Feign的⽇志级别(Feign请求过程信息)
// NONE:默认的,不显示任何⽇志----性能最好
// BASIC:仅记录请求⽅法、URL、响应状态码以及执⾏时间----⽣产问题追踪
// HEADERS:在BASIC级别的基础上,记录请求和响应的header
// FULL:记录请求和响应的header、body和元数据----适⽤于开发及测试环境定位问题
@Bean
Logger.Level feignLevel(){
return Logger.Level.FULL;
}
}
然后配置log日志级别是debug:
logging:
level:
#Feign日志只会对日志级别为debug做出响应
com.learn.controller.feign.UserServiceFeignClient: debug
4.4.5 Feign对熔断的支持
首先我们在配置文件中开启熔断
# 开启Feign的熔断功能
feign:
hystrix:
enabled: true
然后编写一个类继承feignClient接口,返回降级数据
@Component
public class UserServiceFeignFallback implements UserServiceFeignClient{
@Override
public UserInfo findUserById(Integer id) {
UserInfo userInfo = new UserInfo();
userInfo.setOpen(-7);
return userInfo;
}
}
最后在feignClien指定降级实现类即可:
//FeignClient表明当前类是一个FeignClient客户端;value指定要请求的服务名称,本项目中指的是user微服务
@FeignClient(name = "user", fallback = UserServiceFeignFallback.class, path = "/user")
//@RequestMapping("/user") //使用fallback时接口上的RequestMapping应该配置path属性中
public interface UserServiceFeignClient {
@GetMapping("/findUserById")
UserInfo findUserById(@RequestParam("id") Integer id);
}
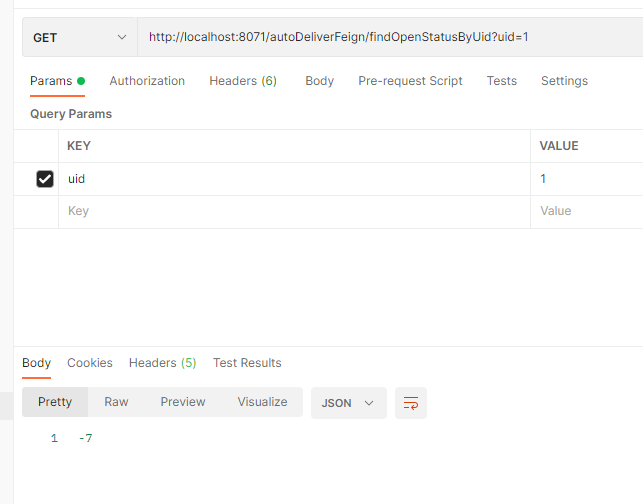
这时我们开启服务用postman测试会发现很快就会熔断,这是因为hystrix的熔断超时时长远远小于我们之前4.4.3配置的feign的超时时长,所以会熔断。两者都能配置超时时长,生效取决于最短的时间,来进行熔断。
我们可以使用以下配置来修改hystrix的超时时长
#配置hystrix的超时时长
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 15000
当前也可以使用FallBackFactory,我们创建一个类继承FallbackFactory接口,泛型是我们定义的FeignCclient。
@Component
public class UserServiceFeignFallbackFactory implements FallbackFactory<UserServiceFeignClient> {
@Override
public UserServiceFeignClient create(Throwable throwable) {
return new UserServiceFeignClient() {
@Override
public UserInfo findUserById(Integer id) {
System.out.println(throwable.getMessage());
UserInfo userInfo = new UserInfo();
userInfo.setOpen(-7);
return userInfo;
}
};
}
}
然后FeignClient指定工厂:
@FeignClient(name = "user", fallbackFactory = UserServiceFeignFallbackFactory.class, path = "/user")
//@RequestMapping("/user") //使用fallback时接口上的RequestMapping应该配置path属性中
public interface UserServiceFeignClient {
@GetMapping("/findUserById")
UserInfo findUserById(@RequestParam("id") Integer id);
}
FallBackFactory与FallBack的区别就是FallBackFactory可以获取到失败原因

4.4.6 Feign的请求压缩
Feign ⽀持对请求和响应进⾏GZIP压缩,以减少通信过程中的性能损耗。通过下⾯的参数即可开启请求与响应的压缩功能:
feign:
hystrix:
enabled: true
compression:
request:
enabled: true
min-request-size: 2048
mime-types: text/html,application/xml,application/json
response:
enabled: true
4.4.7 Feign的文件上传
Feign的文件上传与SpringMVC的写法基本类似,但是唯一不同的是Feign中要用@RequestPart注解来接收文件,下面给出示例:
正常的Controller代码:
@ApiOperation(value = "上传文件")
@RequestMapping(value ="/upload",method = RequestMethod.POST)
public Response<FilesVo> upload(@RequestParam("file") MultipartFile file) {
//fileService是注入的Service层的业务类
return fileService.upload(file);//fileService类里的代码略,里面按照自己的业务逻辑上传文件即可
}
Controller对应的Feign接口代码:
@FeignClient(name = "file",
path = "/file",
fallbackFactory = FilesFeignFallback.class
)
public interface FilesFeign {
@ApiOperation(value = "上传文件")
@RequestMapping(value = "/upload",method = RequestMethod.POST,consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
Response<FilesVo> upload(@RequestPart("file") MultipartFile file);
}
这里需要注意几点:
-
请求一定要加上consumes = MediaType.MULTIPART_FORM_DATA_VALUE,表明当前请求是上传文件的请求
-
注解要使用@RequestPart而不是@RequestParam,否则不能识别要上传的文件。
-
通过feign接口传来的文件参数名一定是file,否则会报找不到此文件
Required request part 'file' is not present举个例子,见下面代码:
//这里将调用feign接口上传文件方法抽出来了,目的是优化可读性,分离变于不变 private Response<FileVo> upload(MultipartFile file) { MultipartFile mockMultipartFile = null; try { ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(file.getBytes()); //这里转换的目的是,给MultipartFile加上参数名 mockMultipartFile = new MockMultipartFile("file", file.getOriginalFilename(), "", byteArrayInputStream); } catch (IOException e) { log.error("文件转换失败"); return ResponseUtil.responseInit(ResponseCodeEnum.BASE_ERROR_0.getCode(), "文件转换失败", "File conversion failed", null); } //如果我直接将file传入feign接口,就像下面注释的一样,那么就会报错,所以上面进行了转换,目的就是为了加一个参数名file //当然如果有更好的办法,也欢迎各位进行指正 //Response<FilesVo> filesVoResponse = filesFeign.upload(file); Response<FilesVo> filesVoResponse = filesFeign.upload(mockMultipartFile); //。。。后面代码略 }
以上就是Spring Cloud Feign上传文件需要注意的地方。
其实Feign对单文件上传支持的很好,只要没有马虎基本都不会出错。下面再着重介绍一下关于多文件上传,Feign是不支持多文件上传的,如果按照上面的写法会发现请求发不过去,会包feign codec的错误,这是因为Feign没有提供或原始的编码器有问题(更具体的原因暂时没有更深入的排查)。所以如果想通过Feign进行多文件上传,那么就需要按照以下方法进行编写:
首先需要引入Feign多文件上传的jar包,maven地址:
<dependency>
<groupId>io.github.openfeign.form</groupId>
<artifactId>feign-form</artifactId>
<version>3.8.0</version>
</dependency>
<dependency>
<groupId>io.github.openfeign.form</groupId>
<artifactId>feign-form-spring</artifactId>
</dependency>
然后需要手动编写多文件请求的编码器,代码如下:
public class MutipartEncoder extends SpringFormEncoder {
public MutipartEncoder(Encoder delegate) {
super(delegate);
MultipartFormContentProcessor processor = (MultipartFormContentProcessor) getContentProcessor(MULTIPART);
processor.addWriter(new SpringSingleMultipartFileWriter());
processor.addWriter(new SpringManyMultipartFilesWriter());
}
@Override
public void encode(Object object, Type bodyType, RequestTemplate template) throws EncodeException {
if (bodyType != null && bodyType.equals(MultipartFile[].class)) {
MultipartFile[] file = (MultipartFile[]) object;
if(file != null) {
Map data = Collections.singletonMap(file.length == 0 ? "" : file[0].getName(), object);
super.encode(data, MAP_STRING_WILDCARD, template);
return;
}
}
super.encode(object, bodyType, template);
}
}
然后将上面的编码器加入到配置文件中,也就是创建一个配置类,代码如下:
@Configuration
public class FeignMultipartSupportConfig {
@Autowired
private ObjectFactory<HttpMessageConverters> messageConverters;
@Bean
public Encoder feignEncoder() {
return new MutipartEncoder(new SpringEncoder(messageConverters));
}
}
然后给自己的FeignClient类加上这个配置:
@FeignClient(name = "file",
path = "/file",
fallbackFactory = FilesOaFeignFallback.class,
configuration = FeignMultipartSupportConfig.class
)
public interface FilesFeign {
@ApiOperation(value = "上传多个文件")
@RequestMapping(value = "/uploadFiles", method = RequestMethod.POST,consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
Response<List<FilesVo>> uploadFiles(@RequestPart("files") MultipartFile[] files);
}
完成以上即可以进行多文件上传了。
4.5 GateWay
Spring Cloud GateWay是Spring Cloud的⼀个全新项⽬,⽬标是取代Netflflix Zuul,它基于Spring5.0+SpringBoot2.0+WebFlux(基于⾼性能的Reactor模式响应式通信框架Netty,异步⾮阻塞模型)等技术开发,性能⾼于Zuul,官⽅测试,GateWay是Zuul的1.6倍,旨在为微服务架构提供⼀种简单有效的统⼀的API路由管理⽅式。
4.5.1 GateWay工作流程
Spring Cloud GateWay不仅提供统⼀的路由⽅式(反向代理)并且基于 Filter(定义过滤器对请求过滤,完成⼀些功能) 链的⽅式提供了⽹关基本的功能,例如:鉴权、流量控制、熔断、路径重写、⽇志监控等。
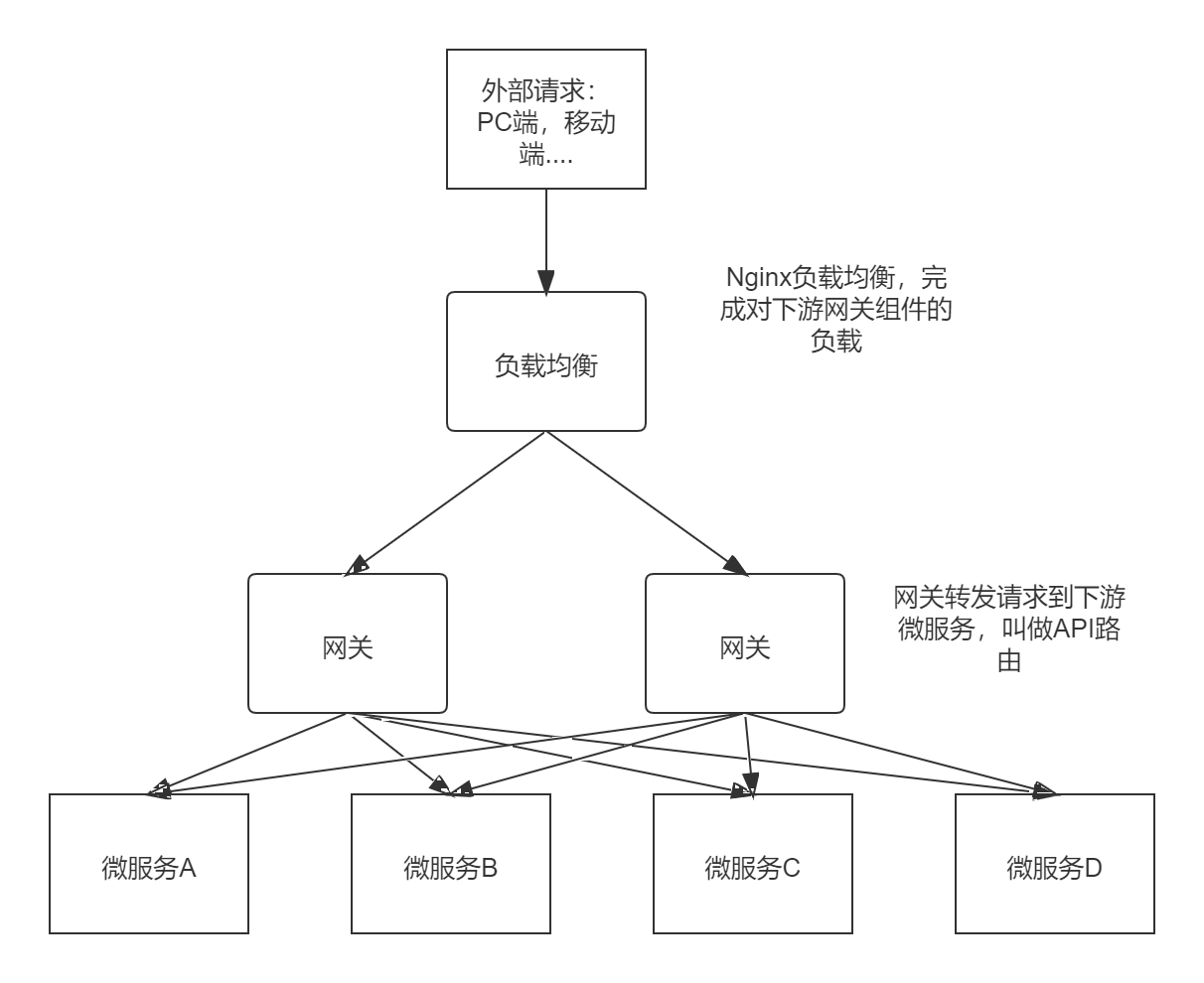
Spring Cloud GateWay是天生异步非阻塞的基于Reactor模型,一个请求打到网关,网关需要根据一定的条件匹配,然后将请求转发到指定的服务地址,在这个转发的过程中我们可以进行一些具体的控制,比如限流、日志、黑白名单等。
- 路由(route): ⽹关最基础的部分,也是⽹关⽐较基础的⼯作单元。路由由⼀个ID、⼀个⽬标URL(最终路由到的地址)、⼀系列的断⾔(匹配条件判断)和Filter过滤器(精细化控制)组成。如果断⾔为true,则匹配该路由。
- 断⾔(predicates):参考了Java8中的断⾔java.util.function.Predicate,开发⼈员可以匹配Http请求中的所有内容(包括请求头、请求参数等)(类似于nginx中的location匹配⼀样),如果断⾔与请求相匹配则路由。
- 过滤器(fifilter):⼀个标准的Spring webFilter,使⽤过滤器,可以在请求之前或者之后执⾏业务逻辑。
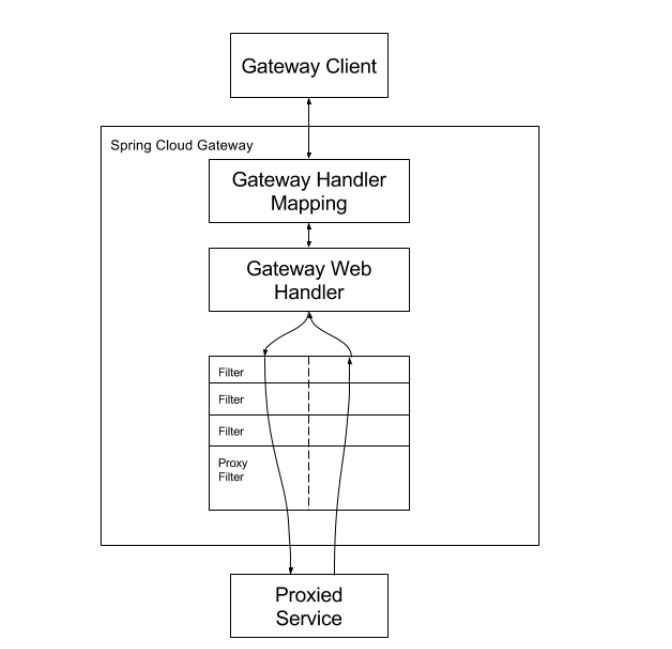
上图来自官网客户端向Spring Cloud GateWay发出请求,然后在GateWay Handler Mapping中找到与请求相匹配的路由,将其发送到GateWay Web Handler;Handler再通过指定的过滤器链来将请求发送到我们实际的服务执⾏业务逻辑,然后返回。过滤器之间⽤虚线分开是因为过滤器可能会在发送代理请求之前(pre)或者之后(post)执⾏业务逻辑。
Filter在“pre”类型过滤器中可以做参数校验、权限校验、流量监控、⽇志输出、协议转换等,在“post”类型的过滤器中可以做响应内容、响应头的修改、⽇志的输出、流量监控等。GateWay核⼼逻辑:路由转发+执⾏过滤器链。
4.5.2 GateWay应用
我们在案例中的应用主要是通过网关对自动投递微服务进行代理(相当于隐藏了具体微服务的信息,对外暴露网关)
我们创建gateway8060项目,注意不继承父工程因为gateway使用的是webflux,但父工程引入了web模块,然后编辑pom文件,增加依赖。
PS:也可以自行改变项目结构,将web从父模块移除,因为很麻烦所以这里直接不继承父工程,直接导入依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--spring boot ⽗启动器依赖-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.3.RELEASE</version>
<relativePath/><!--项目报错可以加上这个-->
</parent>
<groupId>com.learn</groupId>
<artifactId>gateway8060</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-commons</artifactId>
</dependency>
<!--eureka client客户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--gateway-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--webflux-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
<version>1.18.20</version>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
</project>
如果报错'parent.relativePath' of POM com.learn:gateway8060:1.0-SNAPSHOT可以加上
<relativePath/>有一解释说报错原因是本身在父项目中,但是<parent>不是父项目
然后我们编辑启动类:
@SpringBootApplication
@EnableDiscoveryClient //开启注册中心客户端(通用型注解,比如注册到Eureka、
public class GateWay8060 {
public static void main(String[] args) {
SpringApplication.run(GateWay8060.class,args);
}
}
最后编写配置文件:
server:
port: 8060
#注册到Eureka服务中心
eureka:
client:
service-url:
# 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。
defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: cloud-autodeliver # 路由的id,没有规定规则但要求唯一,建议配合服务名
#匹配后提供服务的路由地址
uri: http://127.0.0.1:8071
predicates:
- Path=/autoDeliverFeign/** # 断言,路径相匹配的进行路由
- id: cloud-user # 路由的id,没有规定规则但要求唯一,建议配合服务名
#匹配后提供服务的路由地址
uri: http://127.0.0.1:8091
predicates:
- Path=/user/** # 断言,路径相匹配的进行路由
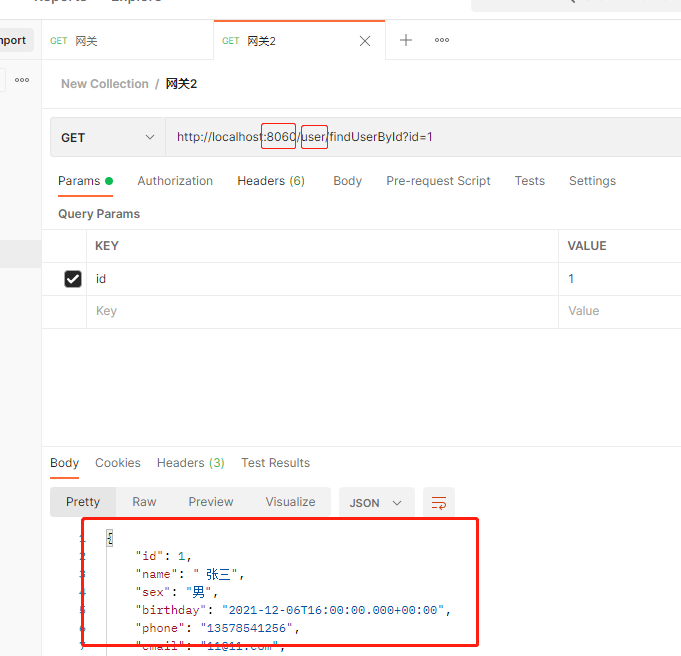
然后我们可以启动工程,访问网关,可以看到访问结果成功:
4.5.3 GatwWay路由规则
时间匹配
Spring Cloud Gateway支持设置一个时间,在请求进行转发的时候,可以通过判断在这个时间之前或者之后或者之间进行转发
server:
port: 8080
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: route
uri: lb://test
predicates:
- Path=/user/**
- After=2020-01-09T00:00:00+08:00[Asia/Shanghai]
#- Before=2020-01-09T00:00:00+08:00[Asia/Shanghai]
#- Between=2020-01-01T00:00:00+08:00[Asia/Shanghai],2020-01-09T00:00:00+08:00[Asia/Shanghai]
- id: oss-route
uri: lb://test-OSS
predicates:
- Path=/oss/**
Cookie匹配
例子如下:带上cookies访问,且userCode为123456,则正常返回。
server:
port: 8080
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: route
uri: lb://test
predicates:
- Path=/user/**
- Cookie=userCode,123456
Header匹配
Header 匹配 和 Cookie 匹配 一样,也是接收两个参数,一个 header 中属性名称和一个正则表达式,这个属性值和正则表达式匹配则执行。例子:上面的匹配规则,就是请求头要有token属性,并且值必须为数字和字母组合的正则表达式。
server:
port: 8080
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: route
uri: lb://test
predicates:
- Path=/user/**
- Header=token,^(?!\d+$)[\da-zA-Z]+$
Host匹配
Host匹配 接收一组参数,一组匹配的域名列表,它通过参数中的主机地址作为匹配规则。
server:
port: 8080
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: route
uri: lb://test
predicates:
- Host=**.baidu.com
请求方式匹配
server:
port: 8080
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: route
uri: lb://test
predicates:
- Method=GET //或者POST,PUT
请求路径匹配
server:
port: 8080
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: route
uri: lb://test
predicates:
- Path=/user/{segment}
请求参数匹配
Query匹配 支持传入两个参数,一个是属性名,一个为属性值,属性值可以是正则表达式。
predicates:
- Query=token, \d+
请求地址匹配
通过设置某个 ip 区间号段的请求才会路由。
predicates:
- RemoteAddr=192.168.1.1/24
4.5.4 动态路由
在4.5.2中我们直接写死了实例地址,但如果我们有集群的话就不是很好,所以我们可以使用动态路由,从注册中心拿。动态路由可以通过lb://服务名称写。
修改配置文件:
server:
port: 8060
#注册到Eureka服务中心
eureka:
client:
service-url:
# 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。
defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: cloud-autodeliver # 路由的id,没有规定规则但要求唯一,建议配合服务名
#匹配后提供服务的路由地址
uri: lb://autodeliver
predicates:
- Path=/autoDeliverFeign/** # 断言,路径相匹配的进行路由
- id: cloud-user # 路由的id,没有规定规则但要求唯一,建议配合服务名
#匹配后提供服务的路由地址
uri: lb://user
predicates:
- Path=/user/** # 断言,路径相匹配的进行路由
我们测试user服务来进行测试是否是动态路由(因为autodeliver看不出来)
我们postman发送请求

然后看user的两个服务
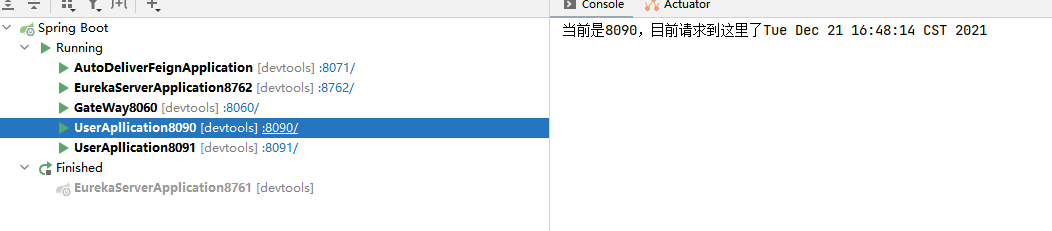

可以看到可以进行动态路由。
4.5.5 过滤器Filter
过滤器的生命周期主要有两个
| 生命周期 | 作用 |
|---|---|
| pre | 这种过滤器在请求被路由之前调⽤。我们可利⽤这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等 |
| post | 这种过滤器在路由到微服务以后执⾏。这种过滤器可⽤来为响应添加标准的HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。 |
从过滤器类型的角度。SpringCloudGateway分为GateWayFilter和GlobalFilter两种
| 类型 | 影响范围 |
|---|---|
| GateWayFilter | 应用到单个路由器上 |
| GlobalFilter | 应用到所有路由器上 |
首先是GateWayFilter,我们可以配置到单个路由之下,对当前路由使用。
predicates:
- Path=/user/name/getname # 断言,路径相匹配的进行路由
filters:
- StripPrefix=1
StripPrefix过滤器可以去掉当前的第一个路由,比如我们之前的路径是localhost:8080/user/name/getname在加上过滤器之后就变成了localhost:8080/name/getname。测试结果:
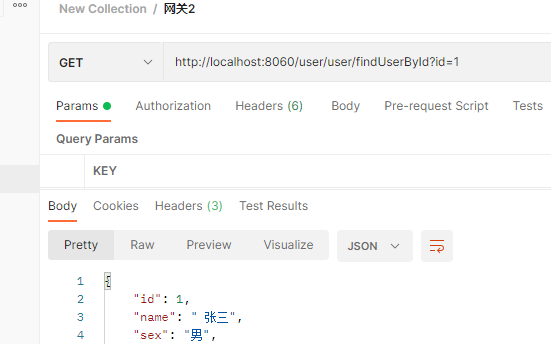
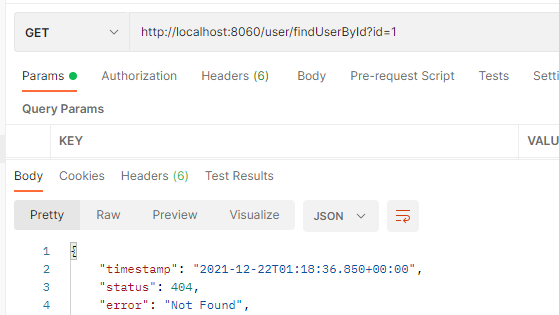
当然实际上GlobalFilter的使用频率更高,我们下面对GlobalFilter进行自定义配置。(PS:GateWayFilter也可以自定义,但是一般只用默认配置)
我们通过实现自定义全局过滤器实现IP访问限制的例子来进行GlobalFilter进行配置。
在gateway8060中新建类:
package com.learn.filter;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
@Component
public class BlackListFilter implements GlobalFilter, Ordered {
//模拟黑名单,实际可以存入redis或mysql
private static List<String> blackList = new ArrayList<>();
static {
blackList.add("0:0:0:0:0:0:0:1");//模拟本地地址
}
/**
* 过滤器的核心方法
*
* @param exchange 封装了request和response对象的上下文
* @param chain 网关过滤器链(包含全局和单路由过滤器)
* @return
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//获取客户端ip,判断是否在黑名单中,在的话拒绝,不在就放行
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
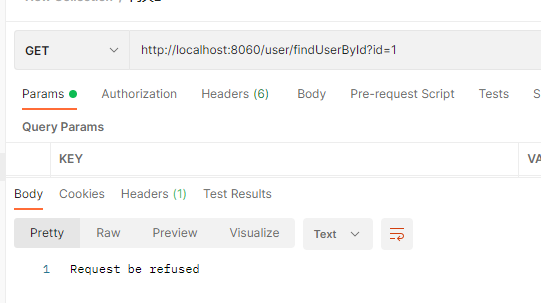
String clientIp = request.getRemoteAddress().getHostString();
if (blackList.contains(clientIp)) {
response.setStatusCode(HttpStatus.UNAUTHORIZED);
System.out.println("在黑名单中,拒绝访问,clientIP="+clientIp);
DataBuffer wrap = response.bufferFactory().wrap("Request be refused".getBytes(StandardCharsets.UTF_8));
return response.writeWith(Mono.just(wrap));
}
return chain.filter(exchange);
}
/**
* 返回值表示当前过滤器的优先级(顺序),数值越小优先级越高
*
* @return
*/
@Override
public int getOrder() {
return 0;
}
}
我们通过postman测试,测试结果:
因为网关在微服务体系十分重要,所以需要实现高可用,我们可以通过集群的方式通过上游用Nginx完成负载均衡即可。
4.6 Spring Cloud Config
4.6.1 简介
在项目中我们需要配置文件进行一些配置,在单体应用中,配置信息的管理不会很麻烦,因为就一个工程,但是在微服务体系下有很多工程,我们不可能一个个的去配置重启然后生效,有时候我们还需要在运行期间动态调整配置信息。所以我们需要对配置文件进行集中式管理,这就是分布式配置中心的作用。
Spring Cloud Config是⼀个分布式配置管理⽅案,包含了Server端和Client端两个部分。
Server 端:提供配置⽂件的存储、以接⼝的形式将配置⽂件的内容提供出去,通过使⽤@EnableConfigServer注解在Spring boot 应⽤中非常简单的嵌⼊
Client 端:通过接⼝获取配置数据并初始化自己的应用。
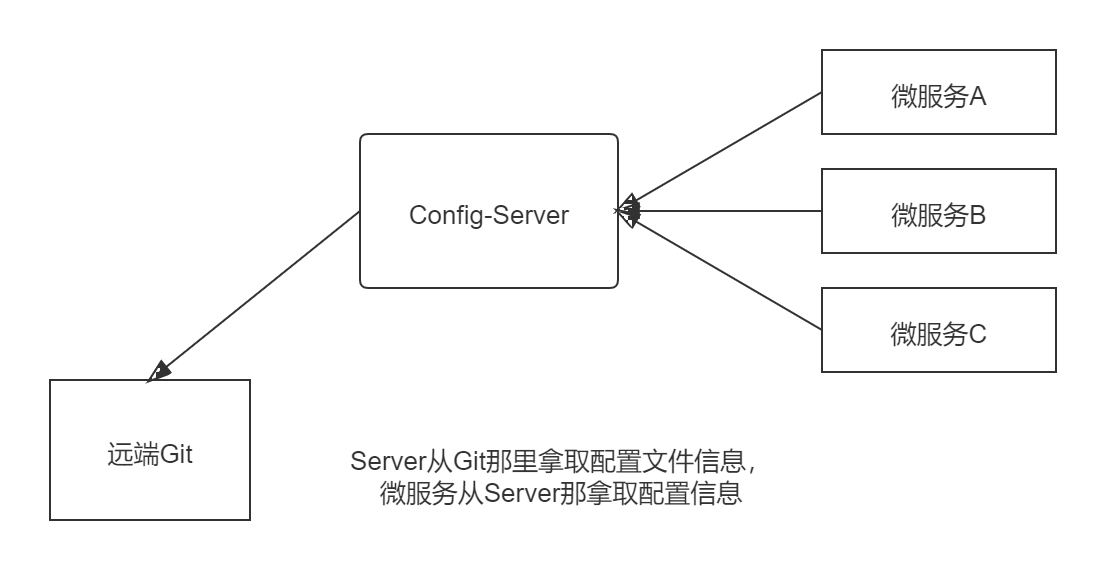
4.6.2 Config配置中心应用
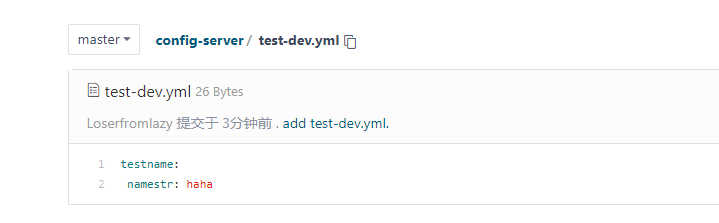
首先我们在Gitee上创建一个仓库然后增加一个测试用的配置文件:
创建configserver工程引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>MyGirl</artifactId>
<groupId>com.learn</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>serverConfig</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
</dependencies>
</project>
然后创建启动类:注意需要注解@EnableConfigServer
@SpringBootApplication
@EnableDiscoveryClient
@EnableConfigServer
public class ServerConfigApplication {
public static void main(String[] args) {
SpringApplication.run(ServerConfigApplication.class,args);
}
}
编写配置文件:
server:
port: 8050
#注册到Eureka服务中心
eureka:
client:
service-url:
# 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。
defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
spring:
application:
name: serverconfig
cloud:
config:
server:
git:
uri: https://gitee.com/yhr520/config-server.git #git地址
username: #git用户名
password: #git密码
search-paths:
- config-server
label: master #分支
# springboot中暴露健康检查等断点接⼝
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
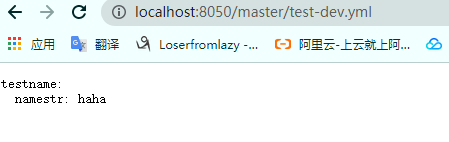
搭建完工程后我们启动工程然后访问http://localhost:8050/master/test-dev.yml
第一个master是分支名称,第二个是文件名称,测试结果如下:可以获取配置文件信息
4.6.3 Config客户端应用
我们在入门案例的autodeliver工程进行修改,其他工程几乎一样,可以自己完成修改。
首先在项目中增加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-client</artifactId>
</dependency>
然后将application.yml改为bootstrap.yml,然后增加config客户端的配置
spring:
application:
name: autodeliver
cloud:
config:
name: test #配置文件名文件名可以配多个逗号分隔
profile: dev #后缀名
label: master #分支名
uri: http://localhost:8050
然后我们创建一个Controller,测试能否拿到配置中心的配置
@RestController
@RequestMapping("config")
public class ConfigTestController {
@Value("${testname.namestr}")
private String testStr;
@RequestMapping("testGetConfig")
public String testGetConfig(){
return testStr;
}
}
打开postman进行测试,测试结果:
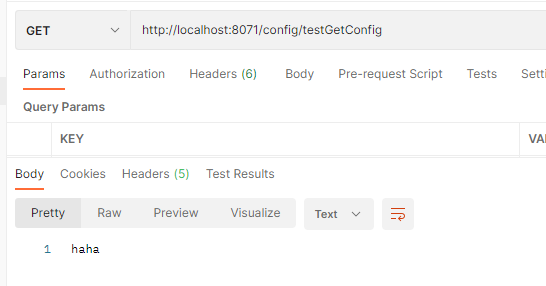
其实我们可以将全部配置信息都放入Condig远端,然后本地只留一个bootstrap拉取其他配置,这样所有配置信息都在远端管理,但是本例只是学习用所以并没有那么做。
即bootstrap只留以下信息:
spring: application: name: autodeliver cloud: config: name: test #配置文件名文件名可以配多个逗号分隔 profile: dev #后缀名 label: master #分支名 uri: http://localhost:8050 #注册到Eureka服务中心 eureka: client: service-url: # 注册到集群,把多个server地址用逗号连接即可。如果Eureka Server是单实例就写一个就行。 defaultZone: http://CloudEurekaServerA:8761/eureka/,http://CloudEurekaServerB:8762/eureka/
4.6.4 Spring Cloud Config的配置文件刷新
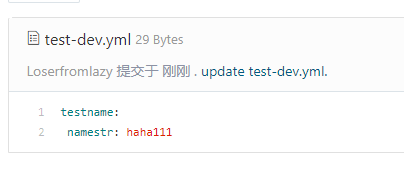
我们修改远端仓库的值:
在访问配置中心的端口:
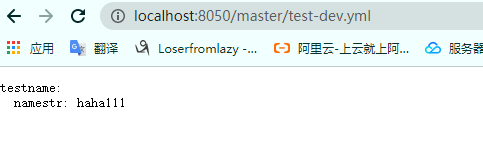
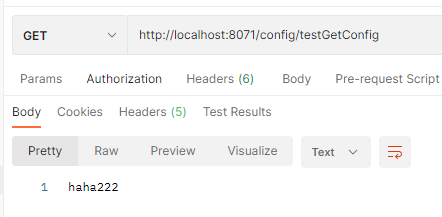
发现配置中心能够实时获取配置的修改。然后我们在访问配置的客户端(即Autodeliver)的接口
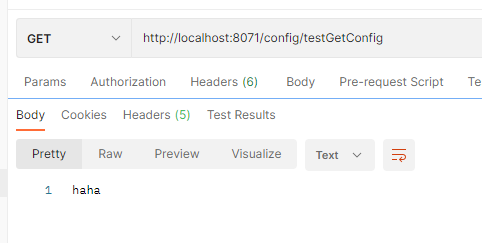
发现客户端会有缓存。这时我们可以手动刷新。
手动刷新
首先在boostrap中加上如下配置
management:
endpoints:
web:
exposure:
include: "*" #暴露的端口也可以指定refresh只暴露刷新端口
然后再客户端使用到配置信息的类上添加@RefreshScope
然后手动发起请求http://localhost:8071/actuator/refresh
测试前将远端仓库重新修改为haha222,因为添加@RefreshScope需要重启工程。
然后我们发起请求,测试结果如下:
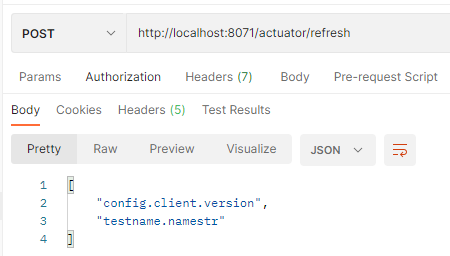
4.7 Spring Cloud Stream消息驱动组件
Spring Cloud Stream 消息驱动组件帮助我们更快速,更⽅便,更友好的去构建消息驱动微服务。
4.7.1 Stream简介
MQ消息中间件广泛用在应用解耦合,异步消息处理,流量削峰等场景中。不同的MQ消息中间件内部机制会有不同,比如RabbitMQ中有Exchange概念,kafka有Topic、Partition分区等概念,MQ的差异性不利于我们上层开发,因为可能应用程序和具体的MQ耦合了,当我们想切换MQ产品时,我们发现比较困难,很多需要重写。
Spring Cloud Stream就进行了很好的上层抽象,可以让我们与具体的消息中间件解耦合,屏蔽掉了底层具体MQ消息中间件的细节差异,就像Hibernate屏蔽掉了具体数据库,目前Spring Cloud Stream支持RabbitMQ和KafKa。
未完结
五、SpringCloudAlibaba核心组件
5.1 Nacos服务发现和配置中心
Nacos (Dynamic Naming and Confifiguration Service)是阿⾥巴巴开源的⼀个针对微服务架构中服务发现、配置管理和服务管理平台。Nacos就是注册中心+配置中心的组合Nacos=Eureka+Config+Bus
5.1.1 Nacos单例服务部署
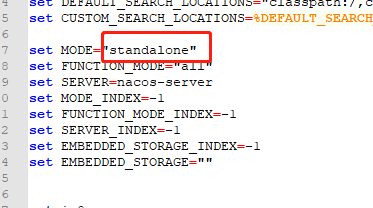
官网下载安装包,解压。然后将 startup.cmd记事本打开,修改mode为单机模式,如下图:
然后双击启动即可。linux在解压后执行命令即可
sh startup.sh -m standalone
输入localhost://127.0.0.1:8848/nacos账号密码都是nacos
5.1.2 服务提供者注册到Nacos
首先我们创建user8092nacos工程,这是为了与之前eureka做区分,所以新建一个工程然后在这里进行修改。
我们在父pom中增加阿里的微服务依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
然后再user8092nacos工程的pom中增加nacos注册中心依赖
<!--nacos client客户端-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
然后编辑application.yml
server:
port: 8092
spring:
application:
name: user
#配置注册到nacos服务端
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
# 修改服务注册中的命名空间 默认是注册到public
#namespace: xxx
# 修改服务注册到nacos上分组名称,默认是DEFAULT_GROUP
#group: xxx
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/my_girl?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
# springboot中暴露健康检查等断点接⼝
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
然后登录nacos页面查看
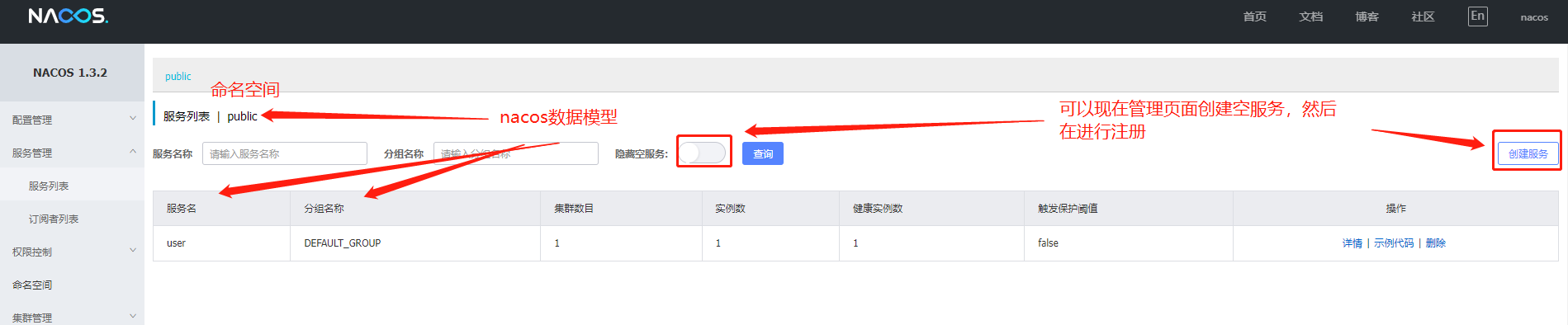
点击详情查看
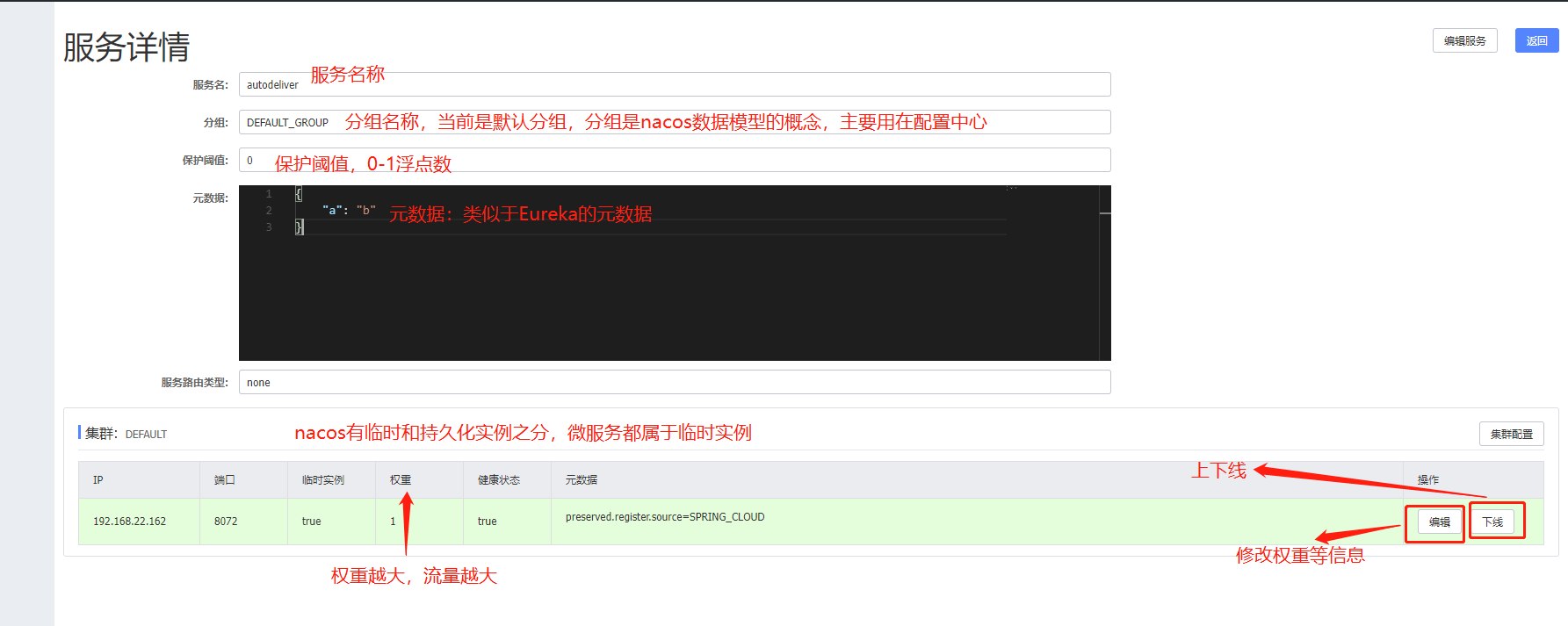
服务已经注册上来了,然后我们以同样的方式在创建一个工程,做一下集群(再强调一遍,正常情况下是同一个工程在不同服务器上实现集群,目前因为是学习项目,所以才这样做集群):
启动注册到nacos上,这时我们发现

保护阈值:这实际上是一个0-1的浮点数,其实是一个比例值:当前服务健康实例数/当前服务总实例数。
一般情况下,nacos在服务为消费者获取一个服务的实例信息时,会把健康的实例信息返回,但在高并发的情况下会出现问题,比如A服务有100个实例,但是95个事不健康的,如果nacos只返回那五个健康的实例的话,流量洪峰会让这5个实例也扛不住,如果这5个也挂了,就会造成雪崩。
所以当一个服务的健康实例数/总实例数<保护阈值时,说明健康实例不多了,这时候保护阈值就会触发(状态改为true),nacos会把健康的不健康的都返回给消费者,这样虽然会造成请求失败,但是比雪崩会好,因为这样时牺牲了一些请求来保证整个系统的可用。
5.1.3 服务消费者注册到Nacos
同样的,为了与eureka做对比,我们也给autodeliver也新建一个工程切换到nacos上,配置方式与上面相同。
配置文件:
server:
port: 8072
spring:
application:
name: autodeliver
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
# springboot中暴露健康检查等断点接⼝
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
#针对的被调用的微服务名称,不加就是对所有调用的微服务生效
user:
ribbon:
#请求连接超时时间
ConnectTimeout: 2000
#请求处理超时时间
ReadTimeout: 8000
#对所有操作都进行重试
OkToRetryOnAllOperations: true
####根据如上配置,当访问到故障请求的时候,它会再尝试访问1次当前实例(次数由MaxAutoRetries配置),
####如果不行,就换一个实例进行访问,如果还不行,再换1次实例访问(更换次数由MaxAutoRetriesNextServer配置),
####如果依然不行,返回失败信息。
MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第一次调用
MaxAutoRetriesNextServer: 0 #切换实例的重试次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整
logging:
level:
#Feign日志只会对日志级别为debug做出响应
com.learn.controller.feign.UserServiceFeignClient: debug
# 开启Feign的熔断功能
feign:
hystrix:
enabled: true
compression:
request:
enabled: true #开启请求压缩
min-request-size: 2048 #出发压缩的大小下限
mime-types: text/html,application/xml,application/json #设置压缩的数据类型
response:
enabled: true #开启响应压缩
#配置hystrix的超时时长
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 8000
Nacos客户端引⼊的时候,会关联引⼊Ribbon的依赖包,我们使⽤OpenFiegn的时候也会引⼊Ribbon的依赖,Ribbon包括Hystrix都按原来⽅式进⾏配置即可。
创建完启动工程,查看nacos:

我们可以通过postman进行测试:可以看到访问成功且进行了负载均衡

5.1.4 Nacos领域模型
数据模型
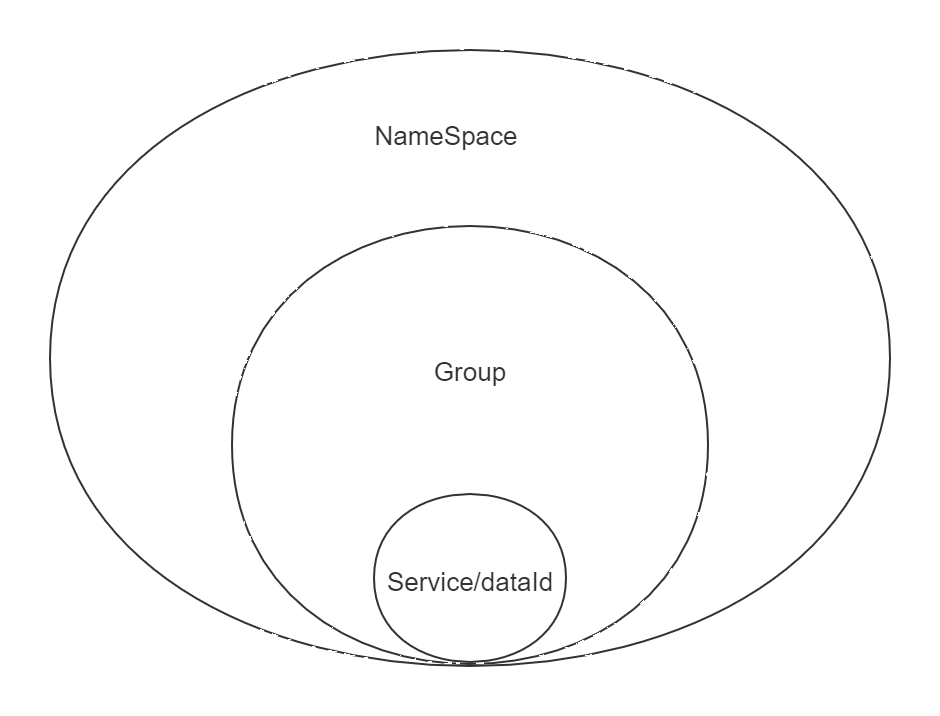
Namespace:命名空间,对不同的环境进⾏隔离,比如隔离开发环境、测试环境和⽣产环境
Group:分组,将若⼲个服务或者若⼲个配置集归为⼀组,通常习惯⼀个系统归为⼀个组
Service:某⼀个服务,⽐如简历微服务
DataId:配置集或者可以认为是⼀个配置⽂件
Namespace + Group + Service如同Maven中的GAV坐标,GAV坐标是为了锁定Jar,而这里是为了锁定服务
Namespace + Group + DataId是为了锁定配置⽂件
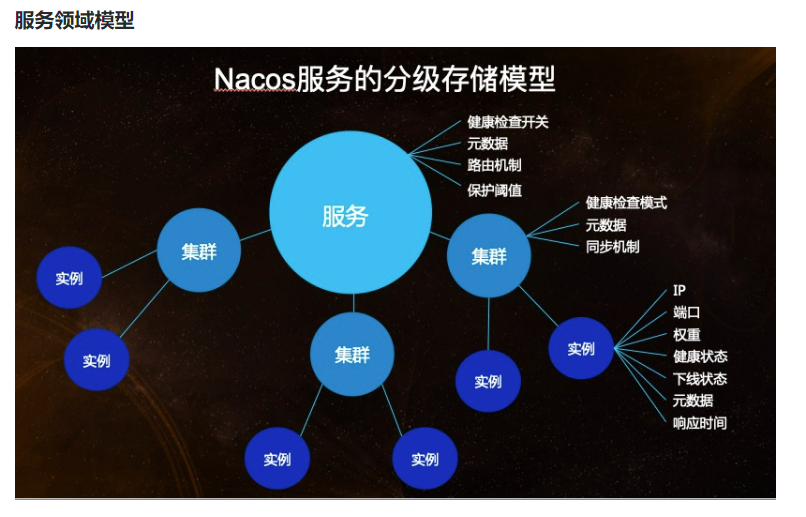
服务领域模型
5.1.5 nacos集群
安装3个或以上nacos,修改nacos的application.properties配置文件中的server.port属性8848、8849、8850,然后修改ip地址为127.0.0.1,三个nacos都要改,如下图
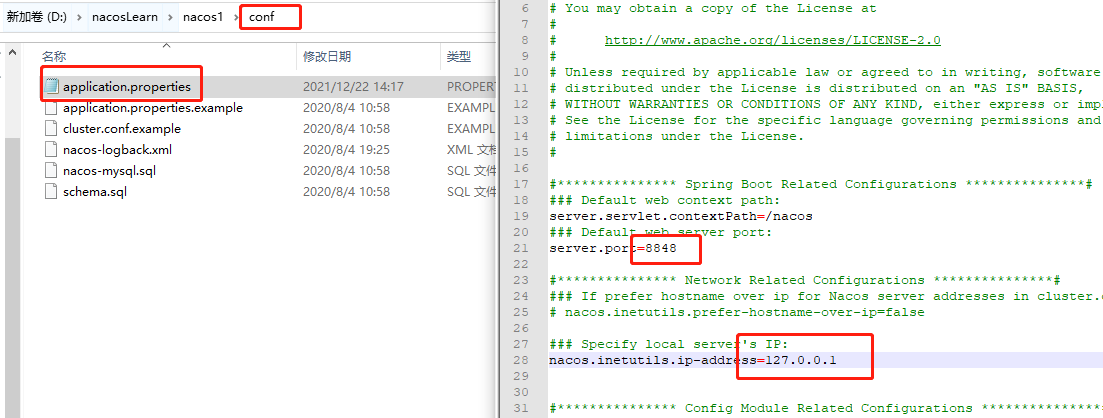
然后我们创建cluster.conf在文件中输入集群中的全部ip和端口,然后拷贝到每一个nacos的conf文件夹中。
#it is ip
#example
127.0.0.1:8848
127.0.0.1:8849
127.0.0.1:8850
将三个nacos都启动即可。
我的nacos版本是1.3.2,集群启动会报错,需要配置数据库才能启动。
配置数据库在applicatin.properties中配置数据库连接和密码
配置完后需要创建对应的数据库,同时在数据库的表中需要执行conf文件夹下的nacos-mysql.sql文件。
启动后我们可以看到
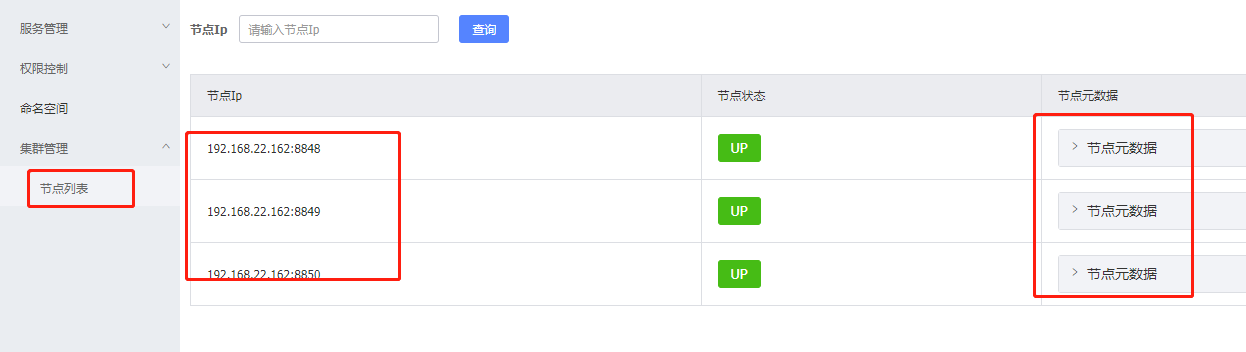
刚启动节点的状态会变成CANDIDATE,也就是大家都在竞争leader
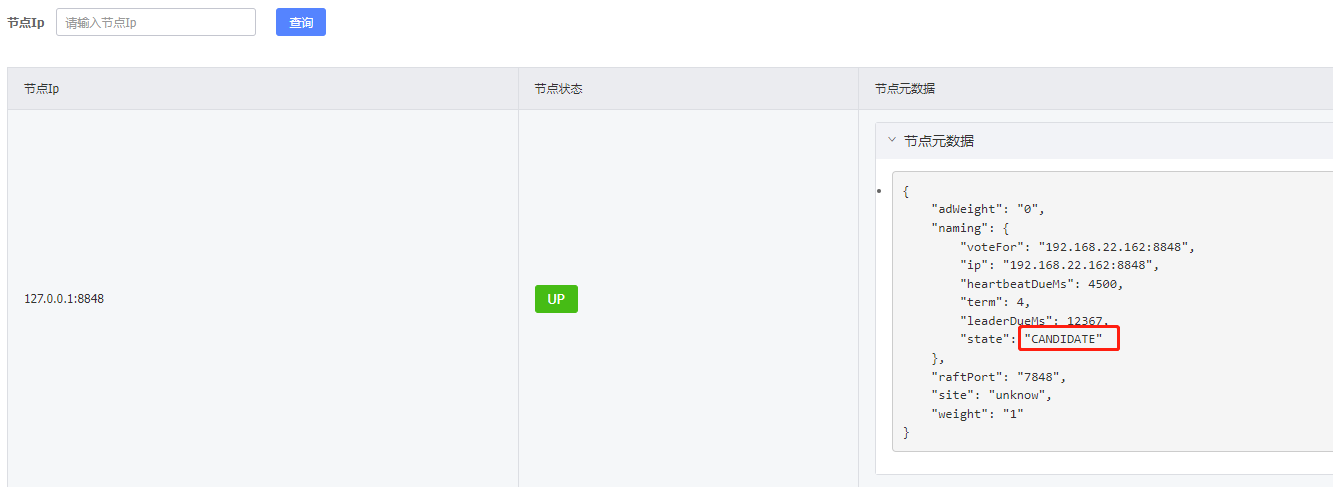
等一会后再刷新我么可以看到nacos已经竞争出了leader和follower
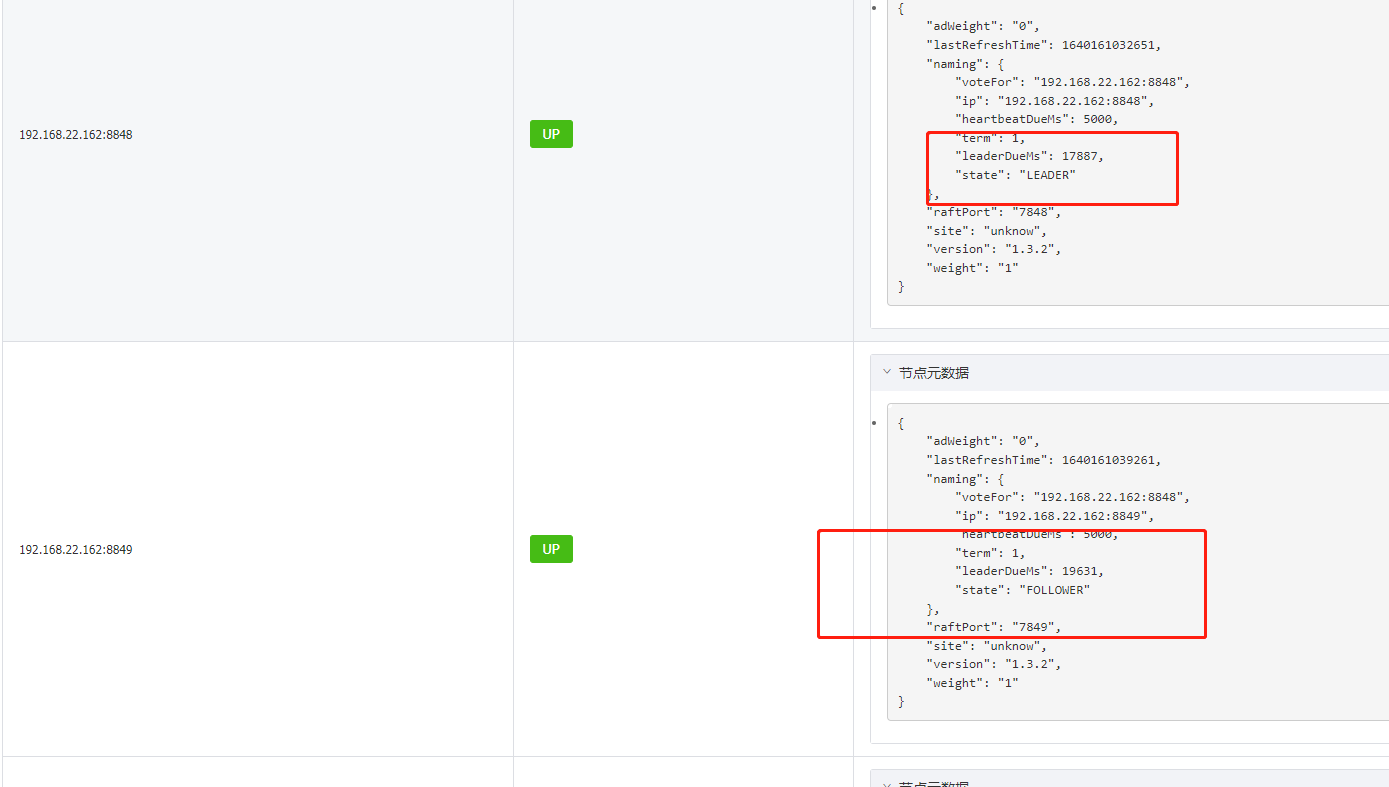
这种leader和follower的模式我们是需要3台以上的机器来搭建集群。
客户端访问到集群跟Eureka类似,逗号分隔即可:
spring:
application:
name: autodeliver
cloud:
nacos:
discovery:
server-addr: 192.168.22.162:8848,192.168.22.162:8849,192.168.22.162:8850
config:
server-addr: 192.168.22.162:8848,192.168.22.162:8849,192.168.22.162:8850
file-extension: yml
namespace: autodeliver
extension-configs[0]:
data-id: test.yml
group: DEFAULT_GROUP
refresh: true
extension-configs[1]:
data-id: test.properties
group: DEFAULT_GROUP
refresh: true
5.1.6 nacos作为配置中心
这里仅作简单介绍,具体用法见官方WIKINacos-config
nacos作为配置中心非常简单,不再需要git仓库和bus。
跟SpringConfig一样,是可以只留boostrap,其他配置全部从nacos中拉取,因为是学习项目所以只在nacos中建一个简单的配置文件,然后让客户端去拉去配置文件,下面进行配置。
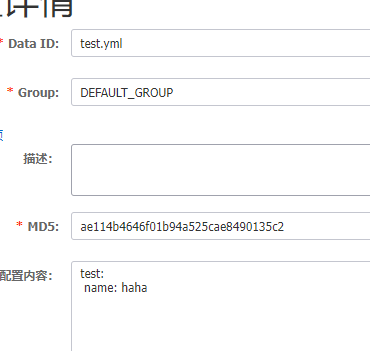
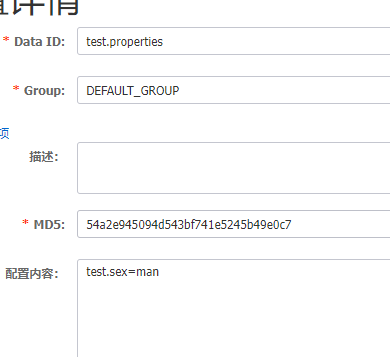
我们在nacos中建立配置文件:
然后我们在微服务中开启nacos作为配置中心。(在autodeliver中演示配置,user同理)
首先添加依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
微服务通过 Namespace + Group + dataId 来锁定配置⽂件,Namespace不指定就默认public,Group不指定就默认 DEFAULT_GROUP
DataId的格式:${prefix}-${spring.profile.active}.${file-extension}
- prefix默认为spring.applicatin.name的值,也可以通过spring.cloud.nacos.config.prefix来配置
- spring.profile.active即当前环境的profile,当此项为空时,dataId直接变成
${prefix}.${file-extension} - file-extension为配置内容的数据格式,可以通过file-extension来配置,目前只支持properties和yaml
添加配置:
spring:
application:
name: autodeliver
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
config:
server-addr: 127.0.0.1:8848
file-extension: yml
namespace: autodeliver
extension-configs[0]:
data-id: test.yml
group: DEFAULT_GROUP
refresh: true
extension-configs[1]:
data-id: test.properties
group: DEFAULT_GROUP
refresh: true
优先级:根据规则⽣成的dataId > 扩展的dataId(对于扩展的dataId,[n] n越⼤优先级越⾼)
然后我们在需要使用的类上使用@RefreshScope实现配置的自动更新。
@RestController
@RequestMapping("config")
@RefreshScope
public class ConfigTestController {
@Value("${test.name}")
private String name;
@Value("${test.sex}")
private String sex;
@RequestMapping("testGetConfig")
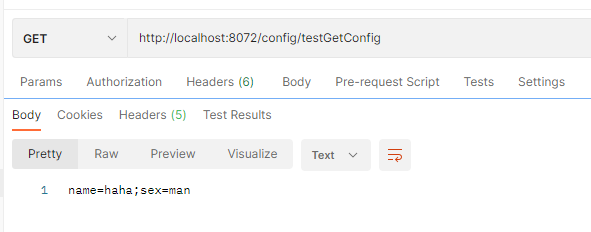
public String testGetConfig(){
return "name="+name+";sex="+sex;
}
}
使用postman进行测试
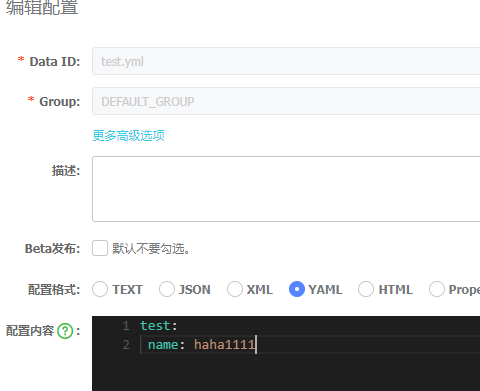
然后我们测试动态刷新:先修改配置
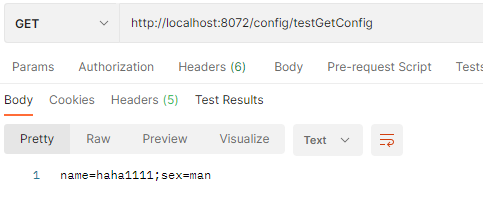
然后访问postman,发现可以进行动态刷新配置:
5.2 Sentinel服务熔断限流
Sentinel是一个面向云原生微服务的流量控制、熔断降级组件。主要是用来替代Hystrix,主要针对服务雪崩、服务降级、服务熔断、服务限流等问题。
与Hystrix对比:
- Hystrix需要自己搭建监控平台,而且没有提供UI界面进行服务熔断、降级等配置(Hystrix是通过代码来配置,这入侵了我们的源程序)
- Sentinel有独立可部署DashBoard的控制台组件,而且减少代码开发,通过UI界面配置既可以完成细粒度控制
Sentinel分为两个部分:
- 核心库:java客户端,不依赖任何框架,能运行于Java运行时环境,对SpringCloud等框架也有较好的支持
- 控制台:基于SpringBoot开发,打包后可以直接运行,不需额外的tomcat等容器。
5.2.1 控制台部署
启动方式java -Dserver.port=8080 -jar sentinel-dashboard.jar
其中 -Dserver.port=8080 用于指定 Sentinel 控制台端口为 8080。也可以加&来后台启动。
启动后就可以登录,账号密码:sentinel/sentinel
Sentinel控制台最好和客户端版本一致,我的sentinelcore版本是1.8,我是用1.7.1的控制台会造成RT降级失效,因为sentinel1.8将RT降级策略升级为慢调用比例策略。我将控制台升级为1.8后满调用比例就可以熔断了。
刚登录什么都没有,需要我们将微服务注册上去。下面我们通过autodeliver工程来实现sentinel配置。
5.2.2 Sentinel应用
为了保留之前的配置方式,所以我们按照autodelivernacos复制一份工程,然后删除hystrix的配置,并删除原有OpenFeign的降级配置。
然后我们在这个工程进行sentinel的改造,首先导入依赖
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
然后配置Sentinal注册到DashBoard:
server:
port: 8073
spring:
application:
name: autodeliver
cloud:
nacos:
discovery:
server-addr: 192.168.22.162:8848,192.168.22.162:8849,192.168.22.162:8850
config:
server-addr: 192.168.22.162:8848,192.168.22.162:8849,192.168.22.162:8850
file-extension: yml
namespace: autodeliver
extension-configs[0]:
data-id: test.yml
group: DEFAULT_GROUP
refresh: true
extension-configs[1]:
data-id: test.properties
group: DEFAULT_GROUP
refresh: true
sentinel:
transport:
dashboard: 127.0.0.1:8080 #dashboard地址
port: 8719 #此端口用于与Sentinel控制台交互,如果8719被占用会依次加一
# springboot中暴露健康检查等断点接⼝
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
user:
ribbon:
ConnectTimeout: 2000
ReadTimeout: 8000
OkToRetryOnAllOperations: true
MaxAutoRetries: 0
MaxAutoRetriesNextServer: 0
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule
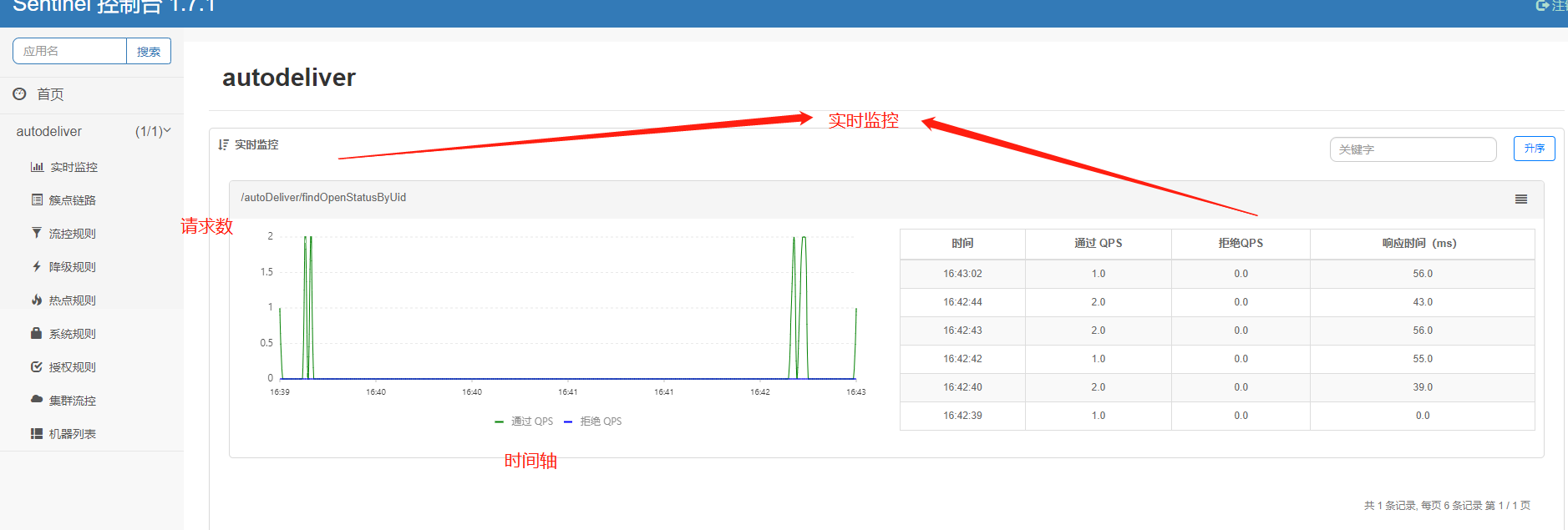
我们启动并通过postman发送请求,在控制台中查看:
如果启动后发现Sentinel控制台什么都没有,那么发送一次请求即可,因为Sentinel是懒加载
5.2.3 Sentinel中的概念
| 名称 | 描述 |
|---|---|
| 资源 | 它是Java应用程序中的任何内容,例如由应用程序提供的服务,或者是由应用程序调用的其它应用提供的服务,甚至可以是一段代码。(也可以简单的理解为API接口就是资源) |
| 规则 | 围绕资源的实时状态设定的规则,可以包括流量控制规则,熔断降级规则以及系统保护规则。所有规则可以动态实时调整。 |
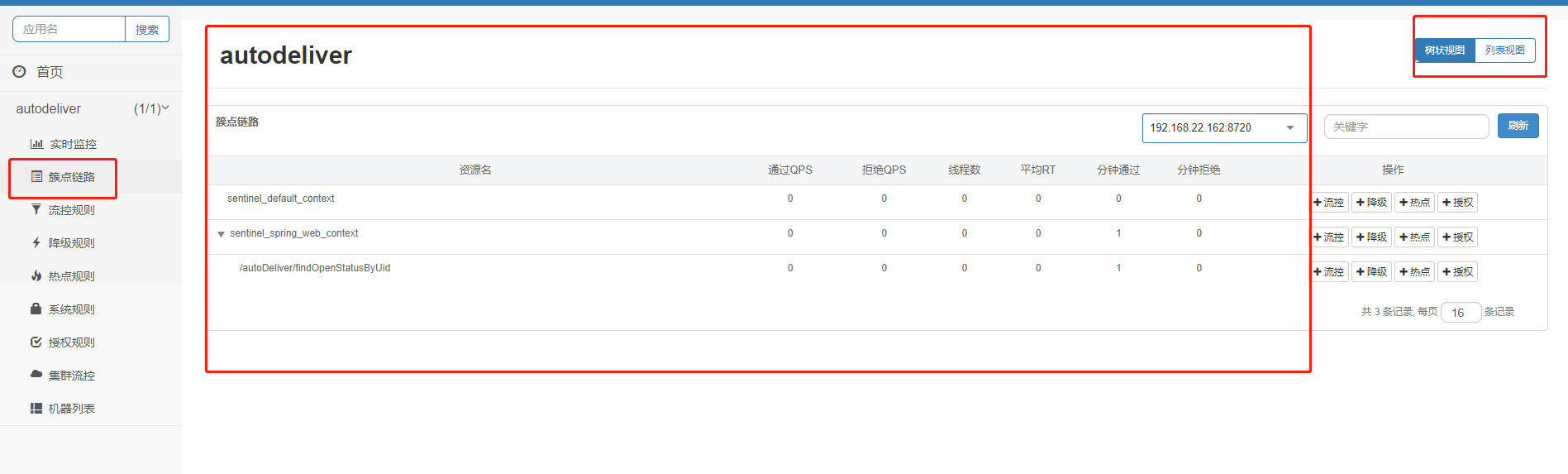
如上图,在簇点链路中我们可以看到现有的资源,当然在右上角切换为列表视图我们可以只看到接口,这样更直观和清晰。
5.2.4 Sentinel中的流量规则
在接口的操作中或者在流控规则中都可以新增定义流控规则,如下图:
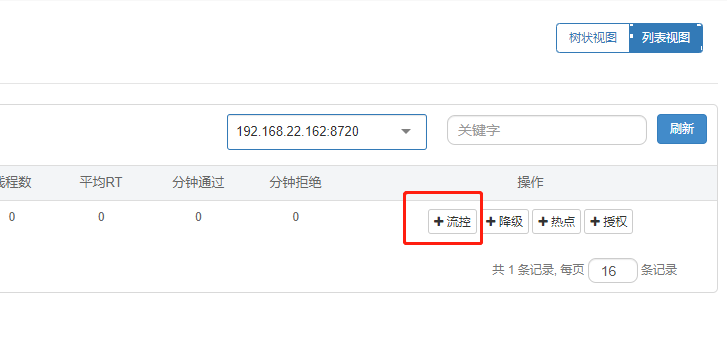
或者流控规则中也可以:
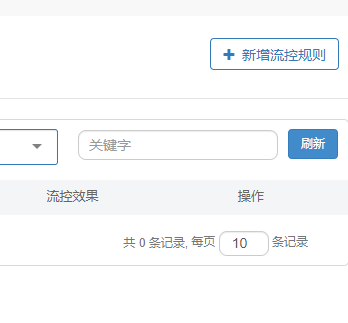
在Sentinel的流控中有阈值类型、流控模式和流控效果我们点击新增流控规则,即可看到:
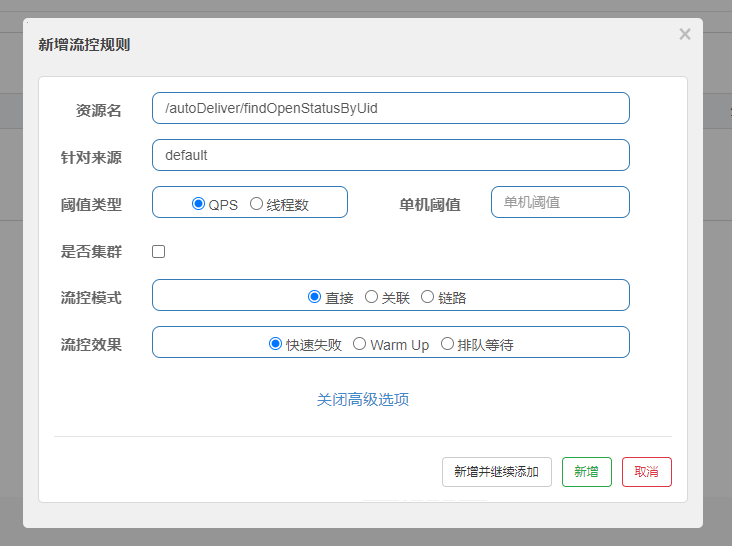
下面对这些进行一一详解。
- 资源名:请求路径
- 针对来源:Sentinel可以针对调用者进行限流,可以填写微服务名称,如果是default就不区分来源
- 阈值类型/单机阈值
- QPS(每秒钟请求数量):当调用该资源的QPS达到阈值进行限流
- 线程数:当调用该资源的线程数达到阈值进行限流(线程处理请求时,如果业务逻辑很长,当流量洪峰来临时,会消耗很多线程资源,这些线程资源会堆积,最终造成服务的不可用,甚至雪崩)
- 流控模式
- 直接:资源调用达到限流条件时,直接限流。
- 关联:关联的资源调用达到阈值时限流自己。
- 链路:只记录指定链路上的流量。
- 流控效果
- 快速失败:直接失败,抛出异常
- Warm Up:根据冷加载因子(默认3)的值,从阈值或者冷加载因子开始,经过预热时长,才能达到设置的QPS阈值。
- 排队等待:匀速排队,让请求匀速通过,阈值类型必须是QPS,否则无效
我们下面进行验证:首先验证QPS和线程数
阈值类型应用:QPS和线程数
我们对接口进行限流设置:将其他都默认,将类型设置为QPS,阈值设置为1,然后打开postman进行快速发送请求,我们会发现Sentinel会抛出失败,因为我们点击的速度超过了1QPS,所以会限流:
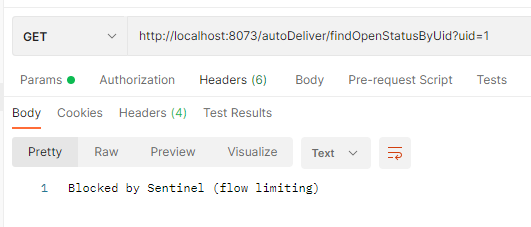
然后将流控设置改为:将其他都默认,将类型设置为线程数,阈值设置为1,然后将接口增加以下代码让线程休眠5s:
@GetMapping("/findOpenStatusByUid")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
UserInfo userById = userServiceFeignClient.findUserById(uid);
return userById.getOpen();
}
然后postman开两个窗口访问同一个接口,第一个窗口5s后会返回结果,第二个窗口会返回失败,因为同时访问线程达到了2超过阈值进行限流。
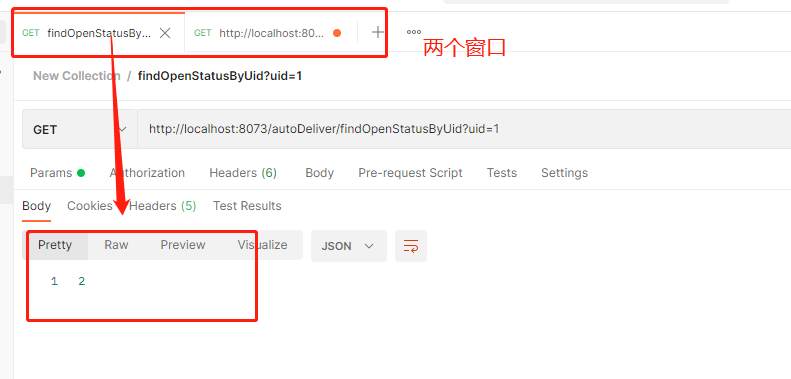
第二个窗口:
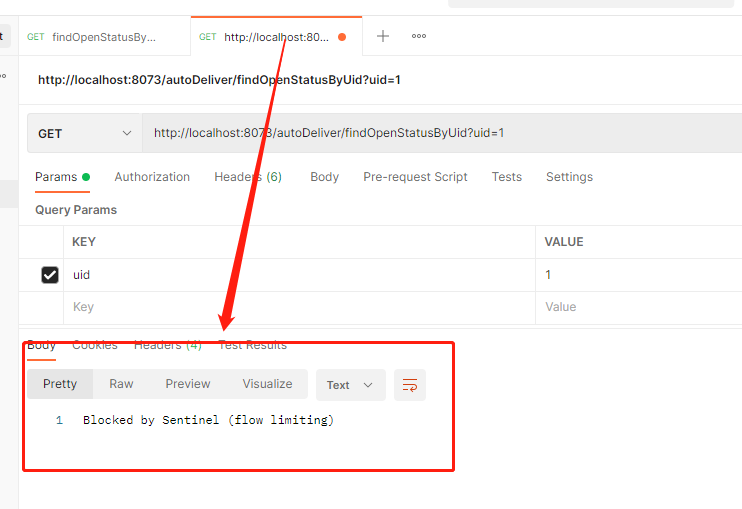
流控模式应用:直接、关联和链路
直接模式略,上面已经试过。
关联模式:关联的资源调用达到阈值限流自己
我们以案例来验证此功能,比如我们用户注册接口需要调用身份验证接口,如果身份验证接口请求达到阈值使用关联模式可以直接对用户注册接口进行限流。我们首先在autodeliverSentinel(在这个工程中编写是为了方便,因为这个工程已经注册到Sentinel中了)中编写这两个接口:
@RestController
@RequestMapping("/user")
public class UserController {
@GetMapping("/register")
public String register(){
System.out.println("注册成功");
return "注册成功";
}
@GetMapping("/validateID")
public String validateID(){
System.out.println("验证身份成功");
return "验证身份成功";
}
}
然后我们进行Sentinel设置,如下图,设置完之后/validateID达到阈值后/register会被限流:
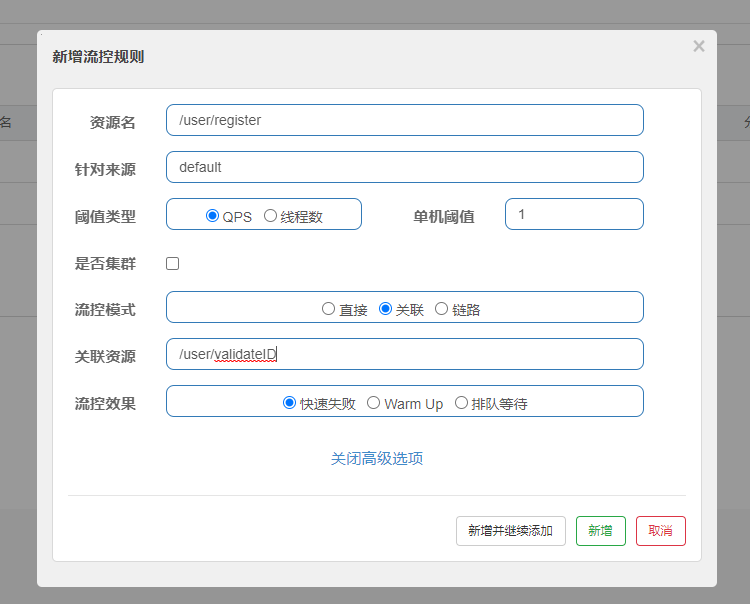
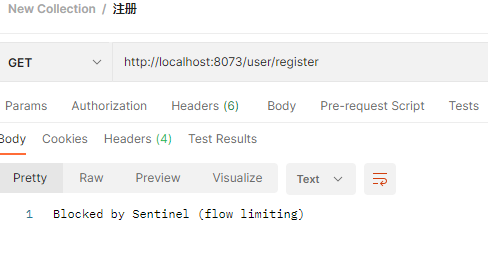
我们在postman中每0.5s发一次/validateID请求发送20次(使用RunCollection即可,使用方法见4.3.4关于postman的RunCollection介绍),在这期间我们访问/register接口,我们发现此接口会被限流,当postman的RunCollection执行完之后,我们再访问就不会被限流了。:
链路模式
/ \
/ \
register1 register2
/ \
/ \
validateID validateID
如上图:有两条调用链路都调用了validateID这一个资源,在Sentinel中允许只根据调用入口的统计信息对资源限流。比如链路模式下设置资源为register1,这样的话表示只有从register1的调用才会记录到validateID的限流统计中,而不关心register2到来的调用。
注意:测试链路模式时需要将web-context-unify设为false,这样会关闭context,就可以让controller里的方法单独成为一个链路;不关闭context的话,controller里的方法都会默认进去sentinel默认的根链路里,这样就只有一条链路,无法流控链路模式。配置文件如下
sentinel: transport: dashboard: localhost:9090 # sentinel注册地址 port: 8721 #关闭context,就可以让controller里的方法单独成为一个链路; #不关闭context的话,controller里的方法都会默认进去sentinel默认的根链路里,这样就只有一条链路,无法流控链路模式 web-context-unify: false此配置效果如下:
开启后效果如下:
关闭后效果如下:
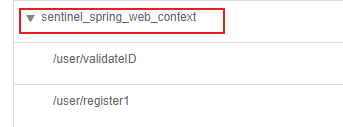

我们编写两个接口,和一个公共链路,首先在UserController中编写两个接口,代码如下:
@Autowired
UserService userService;
@GetMapping("/register1")
public String register1(){
System.out.println(new Date()+"注册成功1");
userService.validateID();
return "注册成功1";
}
@GetMapping("/register2")
public String register2(){
System.out.println(new Date()+"注册成功2");
userService.validateID();
return "注册成功2";
}
然后在UserService中编写一个公共链路(注意:Sentinel默认只标记Controller中的方法为资源,如果要标记其它方法,需要利用@SentinelResource注解):
@Service
public class UserService {
@SentinelResource("valid")
public String validateID(){
System.out.println("验证身份成功");
return "验证身份成功";
}
}
然后我们编写链路限流:
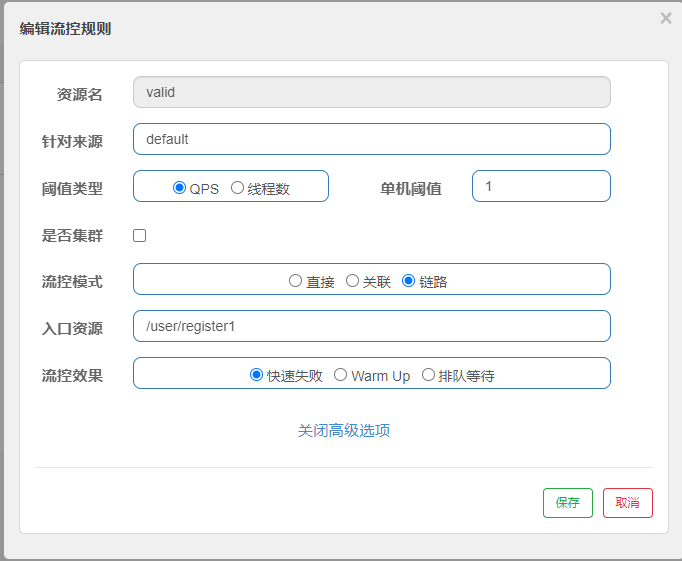
然后我们反复请求/user/register1和/user/register2两个接口,之后我们可以看到register2接口不会限流,而register1接口会被限流,如下图:
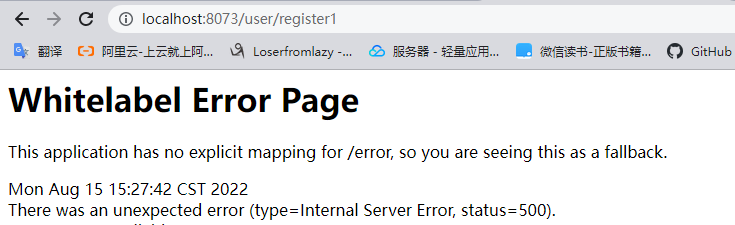
流控效果应用:快速失败、Warm UP和排队等待
快速失败:直接失败,抛出异常,略
Warm Up预热模式
当系统长期处于空闲的情况下,当流量突然增加时,直接把系统拉升到高水位可能会瞬间把系统压垮,比如电商的秒杀模块,所以我们可以通过WarmUp模式,让流速缓慢增加,通过设置的预热时间之后,达到系统处理请求速率的设定值。
Warm Up预热模式会默认从设置的QPS阈值的1/3开始慢慢上升到QPS设置值,比如我们给register接口设置为如下规则:
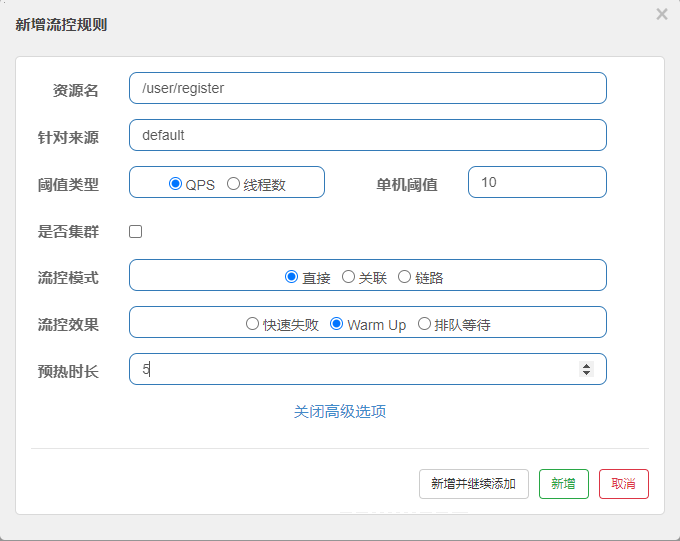
当请求来临到5s内阈值都是10的1/3,5s后才会恢复到阈值10。
我们在浏览器快速发送请求,可以看到在5s内请求会出现限流,5s后就不会出现限流(除非手速快到1s10次以上请求):
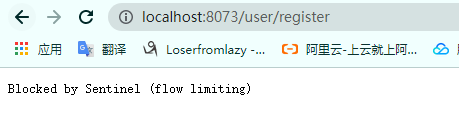
排队等待
排队等待模式下,会严格控制请求通过的间隔时间,即匀速通过请求,允许部分请求排队等待,通常用于削峰等场景,需要设置具体的超时时间,如果等待时间超过超时时间请求就会被拒绝。等待时间使用1s除以阈值,比如QPS设置为5,那么就代表没200ms才能通过一个请求。下面我们进行实验:我们先给register接口打印时间:
@GetMapping("/register")
public String register(){
System.out.println(new Date()+"注册成功");
return "注册成功";
}
然后在Sentinel中设置规则,我们设置为1s通过一个请求:
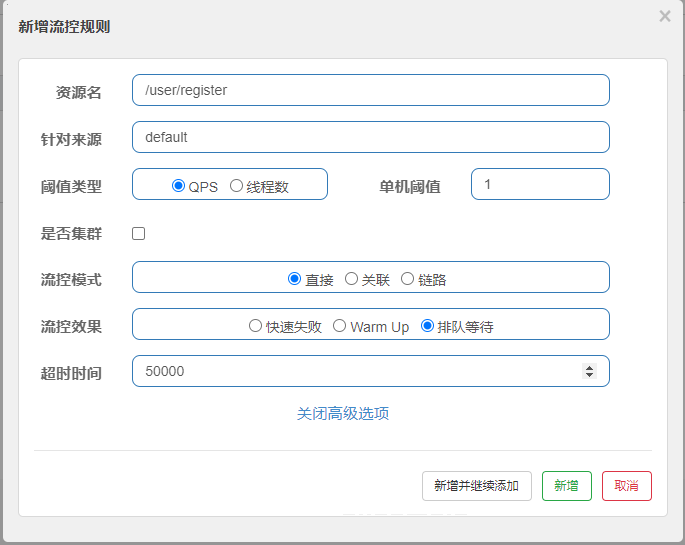
然后用postman的run每20ms发一个请求:
观察控制台发现虽然是每20ms发送一个请求,但是实际上是1s通过一个请求:
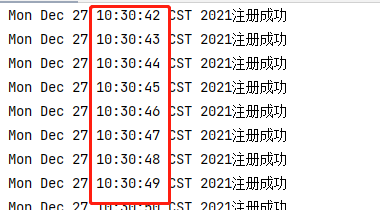
5.2.5 Sentinel中的降级规则
流控是对外部的大流量进行控制,而熔断降级是对内部问题进行处理,Sentinel降级会在调用链路中某个资源出现不稳定状态时(调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其他的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口内,对该资源的调用都自动熔断。
Sentinel中对降级有三种策略:
-
RT(平均响应时间)
选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(
statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。Sentineld额默认的RT上限是4900ms超出时间都会算作4900ms,可以配置启动项
- Dcsp.sentinel.statistic.max.rt=xxx下面我们进行实验:首先在findOpenStatusByUid方法中,加入休眠一秒:
@GetMapping("/findOpenStatusByUid") public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){ // 测试慢比例调用 try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } // 测试异常熔断 // int i = 1/0; System.out.println("请求到这了"); UserInfo userById = userServiceFeignClient.findUserById(uid); return userById.getOpen(); }然后配置RT为200ms,以下配置表示统计时长1000ms内超过RT(200ms)的调用且请求数大于5个则该请求成为慢调用,慢调用的比例大于配置的阈值即0.5那么就熔断5s。
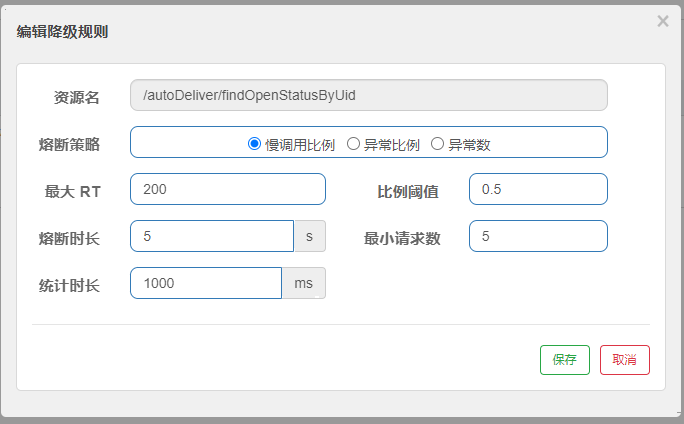
然后开启jmeter设置线程数为10,启动时间1s永远循环,这时我们在用postman调用就会失败,如果我们关闭jmeter的循环请求,那么5s后将不在熔断,请求恢复正常。
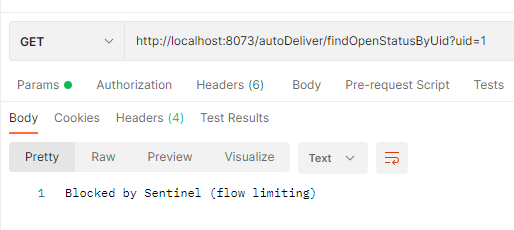
-
异常比例
当单位统计时长(
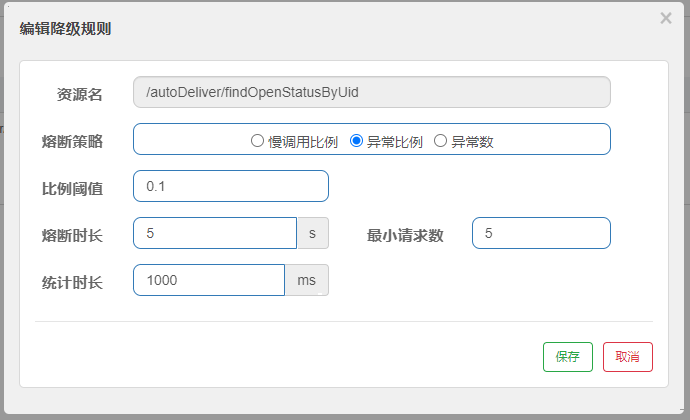
statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是[0.0, 1.0],代表 0% - 100%。我们注释掉线程休眠然后制造异常:
@GetMapping("/findOpenStatusByUid") public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){ // 测试慢比例调用 // try { // TimeUnit.SECONDS.sleep(1); // } catch (InterruptedException e) { // e.printStackTrace(); // } // 测试异常熔断 int i = 1/0; System.out.println("请求到这了"); UserInfo userById = userServiceFeignClient.findUserById(uid); return userById.getOpen(); }然后配置sentinel降级:
打开之前的jemter,使用postman测试发现可以熔断:
-
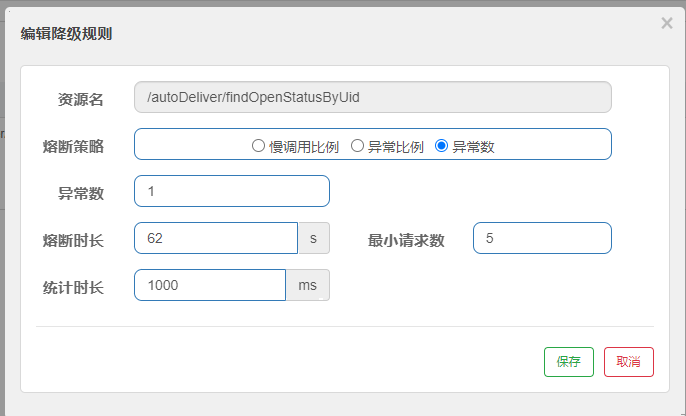
异常数
当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
设置降级规则:
打开jmeter测试postman:发现可以降级:
在Sentinel中降级约等于Hystrix的熔断
5.2.6 自定义兜底数据
使用@SentinelResource注解自定义兜底数据,它类似于Hystrix中的@HystrixCommand注解。
@SentinelResource有两个属性需要区分一个是blockHandler用于指定不满足Sentinel规则的降级方法,fallback属性用于指定Java运行时异常方法。
案例应用:
Controller中API配置注解:
@GetMapping("/findOpenStatusByUid")
@SentinelResource(value = "findOpenStatusByUid" ,blockHandler = "doException")
public Integer findOpenStatusByUid(@RequestParam("uid") Integer uid){
UserInfo userById = userServiceFeignClient.findUserById(uid);
return userById.getOpen();
}
兜底数据类:
public class SentinelFallback {
public static Integer handleException(Integer uid, BlockException blockException) {
return -100;
}
public static Integer handleError(Integer uid) {
return -500;
}
}
我们可以开一个阈值为1的流控,然后postman测试handleException
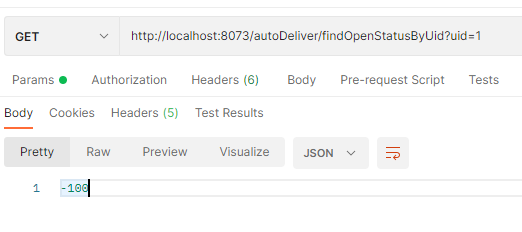
然后写一个1/0的异常,再次测试:
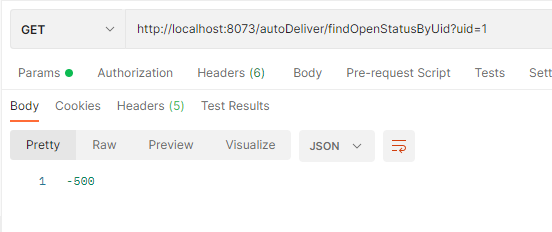
如果想在FeignClient指定fallback,需要将hystrix改成Sentinel
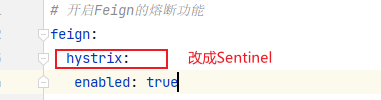
5.2.7 基于nacos的Sentinel规则持久化
Sentinel的规则数据都是存储在内存中的,所以一旦我们停掉微服务,数据就会消失,因此我们可以将规则数据持久化到nacos上,让微服务获取nacos数据。Sentinel的持久化一共有三种模式:
- 规则存在内存中
- 拉模式,规则存在文件中
- 推模式,规则存在数据源中
官方文档介绍如下:
我们用push模式:下面我们在autodeliverSentinel中进行规则数据持久化配置。
首先我们导入依赖:
<!--sentinel配置nacos作为数据源-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
然后在配置文件中进行配置:
sentinel:
transport:
dashboard: 127.0.0.1:8080 #dashboard地址
port: 8719 #此端口用于与Sentinel控制台交互,如果8719被占用会依次加一
datasource:
#flow为自定义的数据源名称
flow:
nacos:
server-addr: ${spring.cloud.nacos.discovery.server-addr}
data-id: ${spring.application.name}-flow-rules
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow #类型来自RuleType
degrade:
nacos:
server-addr: ${spring.cloud.nacos.discovery.server-addr}
data-id: ${spring.application.name}-degrade-rules
groupId: DEFAULT_GROUP
data-type: json
rule-type: degrade #类型来自RuleType
在nacos上的public的DEFAULT_GROUP添加两个配置文件
内容分别是:以下规则可以在源码FlowRule类和DegradeRule类中找到
autodeliver-flow-rules
[
{
"resource":"/findOpenStatusByUid",
"limitApp":"default",
"grade":1,
"count":1,
"strategy":0,
"controlBehavior":0,
"clusterMode":false
}
]
autodeliver-degrade-rules
[
{
"resource":"/findOpenStatusByUid",
"grade":2,
"count":1,
"timeWindow":5
}
]
启动工程就可以在Sentinel中看到我们配置的规则了。这种配置的特点如下:
- ⼀个资源可以同时有多个限流规则和降级规则,所以配置集中是⼀个json数组。
- 这种配置方式在Sentinel控制台中修改规则,仅是内存中⽣效,不会修改Nacos中的配置值,重启后恢复原来的值; Nacos控制台中修改规则,不仅内存中⽣效,Nacos中持久化规则也⽣效,重启后规则依然保持。也就是说只能在Nacos中对配置进行更改
这部分官方文档写的很不清楚,我查了很多资料按照上面的流程走了一遍,发现并不能完成配置同步,报错空指针:
我查了很多资料可能是jdk版本的问题,可以见下面的issue
https://github.com/alibaba/Sentinel/issues/1817
也有可能是Sentinel版本与springcloudalibaba版本冲突的的问题:
解决办法:我将SpringCloudAlibaba降为2.2.1;sentinel降为1.7.2即可正常使用
最终解决办法:我不想降低springCloudAlibaba的版本,因为很多东西再用,不可能说降就降,所以我在NacosDataSourceFactoryBean的第70行源码加上了断点,发现username找不到,会报空指针,所以我们配置文件上配置了username和password然后就可以使用了,真的是很坑!!!配置文件如下:
spring: application: name: autodeliver cloud: sentinel: transport: dashboard: localhost:8080 # sentinel注册地址 datasource: # 名称随意 flow: nacos: server-addr: localhost:8848 username: nacos password: nacos dataId: ${spring.application.name}-flow-rules namespace: sentinel groupId: SENTINEL_GROUP rule-type: flow # 规则类型,取值见:org.springframework.cloud.alibaba.sentinel.datasource.RuleType degrade: nacos: server-addr: localhost:8848 username: nacos password: nacos dataId: ${spring.application.name}-degrade-rules namespace: sentinel groupId: SENTINEL_GROUP rule-type: degrade问题分析:应该是这个版本sentinel配置nacos持久化,需要账户密码去验证但之前的版本不需要,所以会报这个错。PS:官方文档真的很不友好。

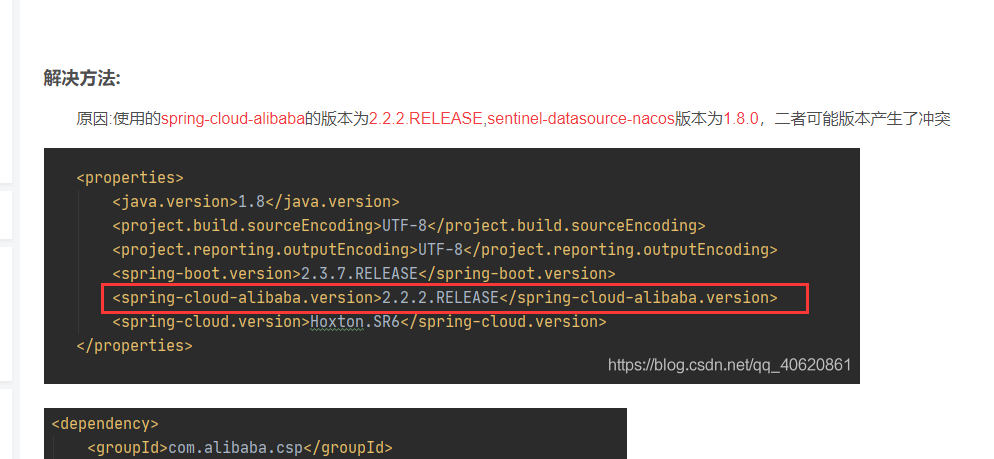
所以如果想实现sentinel修改能保存规则,那么可以通过修改源代码的方式实现。见下面的5.3.5。
5.3 Sentinel源码1.8版本
5.3.1 工程搭建
下载Sentinel源码并解压,源码在Github可以下载。解压后用IDEA打开,如下图,可以通过dashboard启动类来启动工程,这时我们就可以使用我们自己的入门案例连接到这个控制台上。
项目结构:
- sentinel-core 核心模块,限流降级、系统保护等实现
- sentinel-dashboard控制台模块,可以实现可视化管理
- sentinel-transport传输模块,提供了基本的监控服务端和客户端的API接口,以及一些基于不同库的实现。
- sentinel-extension扩展模块,主要对datasource进行了部分扩展
- sentinel-adapter适配器模块,主要对以下常见框架进行了适配
- sentinel-demo样例模块,可以参考
- sentinel-benchmark基准测试模块,对核心代码的精确性提供基准测试。
如果控制台打开页面时会一直转圈,可以清除浏览器缓存,缓存会造成打开sentinel页面时一直转圈。
5.3.2 入门案例
在Github的wiki上有Sentinel简单的使用案例:
public static void main(String[] args) {
initFlowRules();
while (true) {
Entry entry = null;
try {
entry = SphU.entry("HelloWorld");
/*您的业务逻辑 - 开始*/
System.out.println("hello world");
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {
/*流控逻辑处理 - 开始*/
System.out.println("block!");
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
}
当然上面的代码是对业务有侵入性的所以也提供了注解模式即@SentinelResource,我们之前已经介绍过了。
我们下面使用SphU的方式写一个案例,方便我们理解源码:
我们在autodeliverSentinel工程中新建一个OrderController,然后编写如下代码:
@RestController
@RequestMapping("/order")
public class OrderController {
@RequestMapping("/testFunc")
public String testFunc(String application,long id){
initFlowRules();
ContextUtil.enter("user",application);
Entry entry = null;
try {
//1 SphU.entry
entry = SphU.entry("testFunc", EntryType.IN);
/*您的业务逻辑 - 开始*/
System.out.println("hello world");
return getOrderName(id);
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {//2 BlockException异常分支
/*流控逻辑处理 - 开始*/
System.out.println("block!");
throw new RuntimeException("系统繁忙");
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
//用此方法模拟调用其他服务的接口
public String getOrderName(long id){
Entry entry = null;
try {
entry = SphU.entry("getOrderName");
/*您的业务逻辑 - 开始*/
return "BuySomething";
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {
/*流控逻辑处理 - 开始*/
return null;
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("testFunc");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
}
我们对上面的代码进行解释,部分解释来自源码,注意实际开发不会这么写,目前是为了分析源码:
-
Entry,这是Sentinel的重点,对于
SphU#entry方法,作用是记录统计信息并对给定资源进行规则检查,它有很多重载,我们这里介绍上面代码中的两个参数-
第一个参数是标识资源,通常就是我们的接口标识,对于数据统计、规则控制等,我们一般都是在这个粒度上进行的,根据这个字符串来唯一标识,我们跟源码进入会发现,它最后会被包装成ResourceWrapper 实例,ResourceWrapper 的hashCode和equals源码如下,可以证实资源是根据这个字符串来唯一标识
@Override public int hashCode() { return getName().hashCode(); } @Override public boolean equals(Object obj) { if (obj instanceof ResourceWrapper) { ResourceWrapper rw = (ResourceWrapper)obj; return rw.getName().equals(getName()); } return false; } -
第二个参数标识资源的类型,我们的代码使用了
EntryType.IN代表这个是入口流量,比如我们的接口对外提供服务,那么我们通常就是控制入口流量;EntryType.OUT代表出口流量,比如上面的 getOrderName方法(没写默认就是 OUT源码,自行查看源码确认),这个流量类型主要在SystemSlot类中实现自适应限流。
-
-
BlockException:进入 BlockException 异常分支,代表该次请求被流量控制规则限制了,我们一般会让代码走入到熔断降级的逻辑里面。当然,BlockException 其实有好多个子类,如 DegradeException、FlowException 等,我们也可以 catch 具体的子类来进行处理。
5.3.3 Sentinel客户端与dashboard通信
在 Sentinel 的源码中,打开 sentinel-transport 工程,可以看到三个子工程,common 是基础包和接口定义。

如果客户端要接入 dashboard,可以使用 netty-http 或 simple-http 中的一个。我们这里使用http的方式。
我们在使用Sentinel时需要执行SphU#entry方法,源码如下:
public static Entry entry(String name) throws BlockException {
return Env.sph.entry(name, EntryType.OUT, 1, OBJECTS0);
}
这里有一个Env类,这个类是用来与dashboard通信的。
public class Env {
public static final Sph sph = new CtSph();
static {
// If init fails, the process will exit.
InitExecutor.doInit();
}
}
这个类有一个doInit方法,点进去源码如下:
public static void doInit() {
if (!initialized.compareAndSet(false, true)) {
return;
}
try {
ServiceLoader<InitFunc> loader = ServiceLoaderUtil.getServiceLoader(InitFunc.class);
List<OrderWrapper> initList = new ArrayList<OrderWrapper>();
for (InitFunc initFunc : loader) {
RecordLog.info("[InitExecutor] Found init func: " + initFunc.getClass().getCanonicalName());
insertSorted(initList, initFunc);
}
for (OrderWrapper w : initList) {
//断点
w.func.init();
RecordLog.info(String.format("[InitExecutor] Executing %s with order %d",
w.func.getClass().getCanonicalName(), w.order));
}
} catch (Exception ex) {
RecordLog.warn("[InitExecutor] WARN: Initialization failed", ex);
ex.printStackTrace();
} catch (Error error) {
RecordLog.warn("[InitExecutor] ERROR: Initialization failed with fatal error", error);
error.printStackTrace();
}
}
我们在w.func.init();这行加入断点,这里使用 SPI 加载 InitFunc 的实现。可以发现这里加载了 CommandCenterInitFunc 类和 HeartbeatSenderInitFunc 类。


前者是客户端启动的接口服务,提供给 dashboard 查询数据和规则设置使用的。后者用于客户端主动发送心跳信息给 dashboard。
客户端服务注册
我们先看HeartbeatSenderInitFunc#init方法
@Override
public void init() {
//SPI机制,如果我们添加了http的依赖,那么 SimpleHttpHeartbeatSender 就会被加载,可以自行断点查看
HeartbeatSender sender = HeartbeatSenderProvider.getHeartbeatSender();
if (sender == null) {
RecordLog.warn("[HeartbeatSenderInitFunc] WARN: No HeartbeatSender loaded");
return;
}
initSchedulerIfNeeded();
//设置心跳任务发送的时间间隔,默认10s
long interval = retrieveInterval(sender);
setIntervalIfNotExists(interval);
//启动心跳任务
scheduleHeartbeatTask(sender, interval);
}
我们跟进去查看sendHeartbeat()方法
@Override
public boolean sendHeartbeat() throws Exception {
if (TransportConfig.getRuntimePort() <= 0) {
RecordLog.info("[SimpleHttpHeartbeatSender] Command server port not initialized, won't send heartbeat");
return false;
}
//获取Socket连接地址
Tuple2<String, Integer> addrInfo = getAvailableAddress();
if (addrInfo == null) {
return false;
}
InetSocketAddress addr = new InetSocketAddress(addrInfo.r1, addrInfo.r2);
//封装SimpleHttpRequest对象,发送路径/registry/machine
SimpleHttpRequest request = new SimpleHttpRequest(addr, TransportConfig.getHeartbeatApiPath());
request.setParams(heartBeat.generateCurrentMessage());
try {
//发送请求,ps:在这行打断点就可以看到发送路径
SimpleHttpResponse response = httpClient.post(request);
if (response.getStatusCode() == OK_STATUS) {
return true;
} else if (clientErrorCode(response.getStatusCode()) || serverErrorCode(response.getStatusCode())) {
RecordLog.warn("[SimpleHttpHeartbeatSender] Failed to send heartbeat to " + addr
+ ", http status code: " + response.getStatusCode());
}
} catch (Exception e) {
RecordLog.warn("[SimpleHttpHeartbeatSender] Failed to send heartbeat to " + addr, e);
}
return false;
}
请求参数截图:
有了路径后我们可以搜索这个请求,在dashboard的MachineRegistryController中可以看见请求最终到达receiverHeartBeat方法。
@ResponseBody
@RequestMapping("/machine")
public Result<?> receiveHeartBeat(String app, @RequestParam(value = "app_type", required = false, defaultValue = "0") Integer appType, Long version, String v, String hostname, String ip, Integer port) {
if (app == null) {
app = MachineDiscovery.UNKNOWN_APP_NAME;
}
if (ip == null) {
return Result.ofFail(-1, "ip can't be null");
}
if (port == null) {
return Result.ofFail(-1, "port can't be null");
}
if (port == -1) {
logger.info("Receive heartbeat from " + ip + " but port not set yet");
return Result.ofFail(-1, "your port not set yet");
}
String sentinelVersion = StringUtil.isEmpty(v) ? "unknown" : v;
version = version == null ? System.currentTimeMillis() : version;
try {
MachineInfo machineInfo = new MachineInfo();
machineInfo.setApp(app);
machineInfo.setAppType(appType);
machineInfo.setHostname(hostname);
machineInfo.setIp(ip);
machineInfo.setPort(port);
machineInfo.setHeartbeatVersion(version);
machineInfo.setLastHeartbeat(System.currentTimeMillis());
machineInfo.setVersion(sentinelVersion);
//将接收到的信息添加到应用程序管理中
appManagement.addMachine(machineInfo);
return Result.ofSuccessMsg("success");
} catch (Exception e) {
logger.error("Receive heartbeat error", e);
return Result.ofFail(-1, e.getMessage());
}
}
客户端处理请求
在sentinel中数据存储限流规则都是在客户端存储的。实现类CommandCenterInitFunc完成sentinel服务端发送过来的请求相关操作。我们再看CommandCenterInitFunc#init方法。
//命令中心初始化类
@InitOrder(-1)
public class CommandCenterInitFunc implements InitFunc {
@Override
public void init() throws Exception {
CommandCenter commandCenter = CommandCenterProvider.getCommandCenter();
if (commandCenter == null) {
RecordLog.warn("[CommandCenterInitFunc] Cannot resolve CommandCenter");
return;
}
//注册处理器
commandCenter.beforeStart();
//启动命令中心
commandCenter.start();
RecordLog.info("[CommandCenterInit] Starting command center: "
+ commandCenter.getClass().getCanonicalName());
}
}
我们进入到beforeStart()方法,打断点会发现handlers会注册所有的处理器,然后最后会将所有的处理器注册到handlerMap中。
@Override
@SuppressWarnings("rawtypes")
public void beforeStart() throws Exception {
// Register handlers
Map<String, CommandHandler> handlers = CommandHandlerProvider.getInstance().namedHandlers();
registerCommands(handlers);
}
@SuppressWarnings("rawtypes")
public static void registerCommands(Map<String, CommandHandler> handlerMap) {
if (handlerMap != null) {
for (Entry<String, CommandHandler> e : handlerMap.entrySet()) {
registerCommand(e.getKey(), e.getValue());
}
}
}
@SuppressWarnings("rawtypes")
public static void registerCommand(String commandName, CommandHandler handler) {
if (StringUtil.isEmpty(commandName)) {
return;
}
if (handlerMap.containsKey(commandName)) {
CommandCenterLog.warn("Register failed (duplicate command): " + commandName);
return;
}
handlerMap.put(commandName, handler);
}
以上就是注册处理器的工作,然后我们进入commandCenter#start方法,此方法会创建并执行一个serverInitTask线程,在这个线程中启用一个ServerThread线程监听socket请求,在ServerThread中将接收到的socket封装成HttpEventTask由业务线程去处理。
@Override
public void start() throws Exception {
int nThreads = Runtime.getRuntime().availableProcessors();
//创建业务线程池
this.bizExecutor = new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(10),
new NamedThreadFactory("sentinel-command-center-service-executor"),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
CommandCenterLog.info("EventTask rejected");
throw new RejectedExecutionException();
}
});
Runnable serverInitTask = new Runnable() {
int port;
{
try {
//获取端口号,没有就设置默认端口8719
port = Integer.parseInt(TransportConfig.getPort());
} catch (Exception e) {
port = DEFAULT_PORT;
}
}
@Override
public void run() {
boolean success = false;
//根据端口创建一个可用的Socket连接
ServerSocket serverSocket = getServerSocketFromBasePort(port);
if (serverSocket != null) {
CommandCenterLog.info("[CommandCenter] Begin listening at port " + serverSocket.getLocalPort());
socketReference = serverSocket;
//在主线程中在启用一个ServerThread线程监听请求
executor.submit(new ServerThread(serverSocket));
success = true;
port = serverSocket.getLocalPort();
} else {
CommandCenterLog.info("[CommandCenter] chooses port fail, http command center will not work");
}
if (!success) {
port = PORT_UNINITIALIZED;
}
TransportConfig.setRuntimePort(port);
executor.shutdown();
}
};
new Thread(serverInitTask).start();
}
private static ServerSocket getServerSocketFromBasePort(int basePort) {
int tryCount = 0;
while (true) {
try {
//如果发现端口占用情况则默认加一,重试三次
ServerSocket server = new ServerSocket(basePort + tryCount / 3, 100);
server.setReuseAddress(true);
return server;
} catch (IOException e) {
tryCount++;
try {
TimeUnit.MILLISECONDS.sleep(30);
} catch (InterruptedException e1) {
break;
}
}
}
return null;
}
class ServerThread extends Thread {
private ServerSocket serverSocket;
ServerThread(ServerSocket s) {
this.serverSocket = s;
setName("sentinel-courier-server-accept-thread");
}
@Override
public void run() {
while (true) {
Socket socket = null;
try {
//socket监听
socket = this.serverSocket.accept();
setSocketSoTimeout(socket);
//将接收到的socket封装成HttpEventTask由业务线程去处理
HttpEventTask eventTask = new HttpEventTask(socket);
bizExecutor.submit(eventTask);
} catch (Exception e) {
CommandCenterLog.info("Server error", e);
if (socket != null) {
try {
socket.close();
} catch (Exception e1) {
CommandCenterLog.info("Error when closing an opened socket", e1);
}
}
try {
// In case of infinite log.
Thread.sleep(10);
} catch (InterruptedException e1) {
// Indicates the task should stop.
break;
}
}
}
}
}
我们进入到HttpEventTask#run中,这里主要是处理接收到socket监听的请求后的业务逻辑。首先是读取消息内容,然后将消息封装成CommandRequest对象,然后在handlerMap中找到请求的commandName对应的处理器,然后执行该处理器的handle方法。
@Override
public void run() {
if (socket == null) {
return;
}
PrintWriter printWriter = null;
InputStream inputStream = null;
try {
long start = System.currentTimeMillis();
inputStream = new BufferedInputStream(socket.getInputStream());
OutputStream outputStream = socket.getOutputStream();
printWriter = new PrintWriter(
new OutputStreamWriter(outputStream, Charset.forName(SentinelConfig.charset())));
//读取消息内容
String firstLine = readLine(inputStream);
CommandCenterLog.info("[SimpleHttpCommandCenter] Socket income: " + firstLine
+ ", addr: " + socket.getInetAddress());
//封装CommandRequest对象
CommandRequest request = processQueryString(firstLine);
if (firstLine.length() > 4 && StringUtil.equalsIgnoreCase("POST", firstLine.substring(0, 4))) {
// Deal with post method
processPostRequest(inputStream, request);
}
// Validate the target command.验证目标命令是否合法
String commandName = HttpCommandUtils.getTarget(request);
if (StringUtil.isBlank(commandName)) {
writeResponse(printWriter, StatusCode.BAD_REQUEST, INVALID_COMMAND_MESSAGE);
return;
}
// Find the matching command handler.找到匹配的命令处理程序
//在getHandler中就是通过handlerMap进行key的匹配
CommandHandler<?> commandHandler = SimpleHttpCommandCenter.getHandler(commandName);
if (commandHandler != null) {
//执行处理方法
CommandResponse<?> response = commandHandler.handle(request);
handleResponse(response, printWriter);
} else {
// No matching command handler.
writeResponse(printWriter, StatusCode.BAD_REQUEST, "Unknown command `" + commandName + '`');
}
long cost = System.currentTimeMillis() - start;
CommandCenterLog.info("[SimpleHttpCommandCenter] Deal a socket task: " + firstLine
+ ", address: " + socket.getInetAddress() + ", time cost: " + cost + " ms");
} catch (RequestException e) {
writeResponse(printWriter, e.getStatusCode(), e.getMessage());
} catch (Throwable e) {
CommandCenterLog.warn("[SimpleHttpCommandCenter] CommandCenter error", e);
try {
if (printWriter != null) {
String errorMessage = SERVER_ERROR_MESSAGE;
e.printStackTrace();
if (!writtenHead) {
writeResponse(printWriter, StatusCode.INTERNAL_SERVER_ERROR, errorMessage);
} else {
printWriter.println(errorMessage);
}
printWriter.flush();
}
} catch (Exception e1) {
CommandCenterLog.warn("Failed to write error response", e1);
}
} finally {
closeResource(inputStream);
closeResource(printWriter);
closeResource(socket);
}
}
不同的处理器的handle方法肯定是不同的,所以我们以其中一个ModifyRulesCommandHandler处理器举例,这是个流控规则的处理器。我们先来验证这个处理器:
我们先在dashboard页面新增一个限流规则,在新增前在对应的dashboard的controller打上断点。
新增流控规则如下,先不点新增按钮:
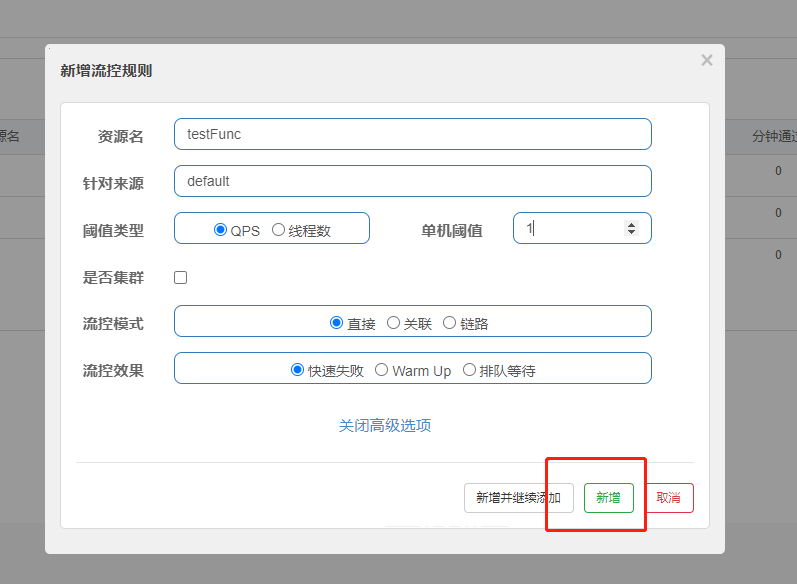
我们先去找这个对应的代码,加上断点,然后回到页面点新增按钮,断点就会停下,如下图:
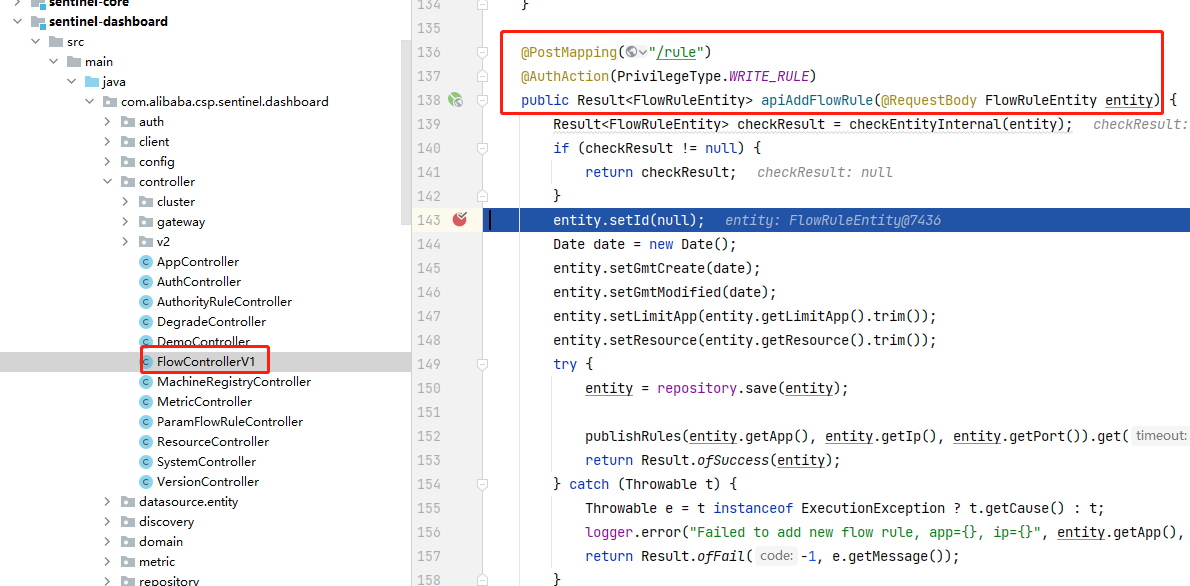
apiAddFlowRule方法代码如下,dashboard前台将规则信息传给后台,后台封装到entity保存,然后在发布规则:
@PostMapping("/rule")
@AuthAction(PrivilegeType.WRITE_RULE)
public Result<FlowRuleEntity> apiAddFlowRule(@RequestBody FlowRuleEntity entity) {
Result<FlowRuleEntity> checkResult = checkEntityInternal(entity);
if (checkResult != null) {
return checkResult;
}
entity.setId(null);
Date date = new Date();
entity.setGmtCreate(date);
entity.setGmtModified(date);
entity.setLimitApp(entity.getLimitApp().trim());
entity.setResource(entity.getResource().trim());
try {
//dashboard保存流控规则信息
entity = repository.save(entity);
//发布规则
publishRules(entity.getApp(), entity.getIp(), entity.getPort()).get(5000, TimeUnit.MILLISECONDS);
return Result.ofSuccess(entity);
} catch (Throwable t) {
Throwable e = t instanceof ExecutionException ? t.getCause() : t;
logger.error("Failed to add new flow rule, app={}, ip={}", entity.getApp(), entity.getIp(), e);
return Result.ofFail(-1, e.getMessage());
}
}
//publishRules代码如下:
private CompletableFuture<Void> publishRules(String app, String ip, Integer port) {
//查询之前保存的规则
List<FlowRuleEntity> rules = repository.findAllByMachine(MachineInfo.of(app, ip, port));
//发布规则:实际上是将信息通过http请求,发布到客户端,具体代码可以自己跟进去看
return sentinelApiClient.setFlowRuleOfMachineAsync(app, ip, port, rules);
}
apiAddFlowRule这里的这个publishRules方法,是用于发布规则到客户端的,我们可以对此进行修改,让规则发布到nacos中。
上述代码断点后查看的entity信息:

跟代码到发送http请求的地方,发现会拼接信息,然后发送POST请求,注意这里的SET_RULES_PATH是setRules
到这为止是dashboard将规则发送到sentinel客户端,我们在sentinel客户端打上断点,打断点的位置就是之前说过的HttpEventTask#run中,我们可以看到dashboard发送过来的请求,也可以看到SET_RULES_PATH就是setRules
我们继续一步一步执行,发现setRules的处理器是ModifyRulesCommandHandler
我们查看ModifyRulesCommandHandler#handle的代码:
@Override
public CommandResponse<String> handle(CommandRequest request) {
//强制失败fastjson过老的版本
// XXX from 1.7.2, force to fail when fastjson is older than 1.2.12
// We may need a better solution on this.
if (VersionUtil.fromVersionString(JSON.VERSION) < FASTJSON_MINIMAL_VER) {
// fastjson too old
return CommandResponse.ofFailure(new RuntimeException("The \"fastjson-" + JSON.VERSION
+ "\" introduced in application is too old, you need fastjson-1.2.12 at least."));
}
//获取规则类型
String type = request.getParam("type");
// rule data in get parameter
//获取参数
String data = request.getParam("data");
if (StringUtil.isNotEmpty(data)) {
try {
data = URLDecoder.decode(data, "utf-8");
} catch (Exception e) {
RecordLog.info("Decode rule data error", e);
return CommandResponse.ofFailure(e, "decode rule data error");
}
}
RecordLog.info("Receiving rule change (type: {}): {}", type, data);
String result = "success";
if (FLOW_RULE_TYPE.equalsIgnoreCase(type)) {//限流
List<FlowRule> flowRules = JSONArray.parseArray(data, FlowRule.class);
FlowRuleManager.loadRules(flowRules);
if (!writeToDataSource(getFlowDataSource(), flowRules)) {
result = WRITE_DS_FAILURE_MSG;
}
return CommandResponse.ofSuccess(result);
} else if (AUTHORITY_RULE_TYPE.equalsIgnoreCase(type)) {//授权
List<AuthorityRule> rules = JSONArray.parseArray(data, AuthorityRule.class);
AuthorityRuleManager.loadRules(rules);
if (!writeToDataSource(getAuthorityDataSource(), rules)) {
result = WRITE_DS_FAILURE_MSG;
}
return CommandResponse.ofSuccess(result);
} else if (DEGRADE_RULE_TYPE.equalsIgnoreCase(type)) {//熔断
List<DegradeRule> rules = JSONArray.parseArray(data, DegradeRule.class);
DegradeRuleManager.loadRules(rules);
if (!writeToDataSource(getDegradeDataSource(), rules)) {
result = WRITE_DS_FAILURE_MSG;
}
return CommandResponse.ofSuccess(result);
} else if (SYSTEM_RULE_TYPE.equalsIgnoreCase(type)) {//系统规则
List<SystemRule> rules = JSONArray.parseArray(data, SystemRule.class);
SystemRuleManager.loadRules(rules);
if (!writeToDataSource(getSystemSource(), rules)) {
result = WRITE_DS_FAILURE_MSG;
}
return CommandResponse.ofSuccess(result);
}
return CommandResponse.ofFailure(new IllegalArgumentException("invalid type"));
}
我们当前传递的参数是限流,所以进入到FlowRuleManager.loadRules(flowRules);加载规则方法:
我们一直让代码一直往下走:
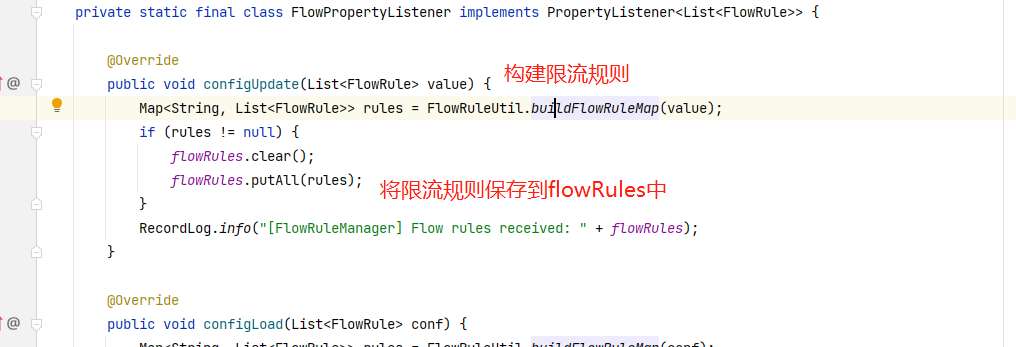
我们继续进入buildFlowRuleMap:
public static <K> Map<K, List<FlowRule>> buildFlowRuleMap(List<FlowRule> list, Function<FlowRule, K> groupFunction,
Predicate<FlowRule> filter, boolean shouldSort) {
Map<K, List<FlowRule>> newRuleMap = new ConcurrentHashMap<>();
if (list == null || list.isEmpty()) {
return newRuleMap;
}
Map<K, Set<FlowRule>> tmpMap = new ConcurrentHashMap<>();
//遍历规则
for (FlowRule rule : list) {
if (!isValidRule(rule)) {
RecordLog.warn("[FlowRuleManager] Ignoring invalid flow rule when loading new flow rules: " + rule);
continue;
}
if (filter != null && !filter.test(rule)) {
continue;
}
if (StringUtil.isBlank(rule.getLimitApp())) {
rule.setLimitApp(RuleConstant.LIMIT_APP_DEFAULT);
}
//根据流量规则生成不同的控制器
TrafficShapingController rater = generateRater(rule);
rule.setRater(rater);
K key = groupFunction.apply(rule);
if (key == null) {
continue;
}
Set<FlowRule> flowRules = tmpMap.get(key);
if (flowRules == null) {
// Use hash set here to remove duplicate rules.
flowRules = new HashSet<>();
tmpMap.put(key, flowRules);
}
flowRules.add(rule);
}
Comparator<FlowRule> comparator = new FlowRuleComparator();
for (Entry<K, Set<FlowRule>> entries : tmpMap.entrySet()) {
List<FlowRule> rules = new ArrayList<>(entries.getValue());
if (shouldSort) {
// Sort the rules.
Collections.sort(rules, comparator);
}
newRuleMap.put(entries.getKey(), rules);
}
return newRuleMap;
}
进入到generateRater方法:
private static TrafficShapingController generateRater(/*@Valid*/ FlowRule rule) {
//如果限流规则为QPS,则根据不同的流控规则生成不同的处理器,这个地方使用的是策略模式
if (rule.getGrade() == RuleConstant.FLOW_GRADE_QPS) {
switch (rule.getControlBehavior()) {
case RuleConstant.CONTROL_BEHAVIOR_WARM_UP://预热策略
return new WarmUpController(rule.getCount(), rule.getWarmUpPeriodSec(),
ColdFactorProperty.coldFactor);
case RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER://匀速排队
return new RateLimiterController(rule.getMaxQueueingTimeMs(), rule.getCount());
case RuleConstant.CONTROL_BEHAVIOR_WARM_UP_RATE_LIMITER:
return new WarmUpRateLimiterController(rule.getCount(), rule.getWarmUpPeriodSec(),
rule.getMaxQueueingTimeMs(), ColdFactorProperty.coldFactor);
case RuleConstant.CONTROL_BEHAVIOR_DEFAULT:
default:
// Default mode or unknown mode: default traffic shaping controller (fast-reject).
}
}
//默认是直接拒绝策略
return new DefaultController(rule.getCount(), rule.getGrade());
}
我们让代码返回到保存的地方,然后可以看到我们创建的直接拒绝策略的处理器
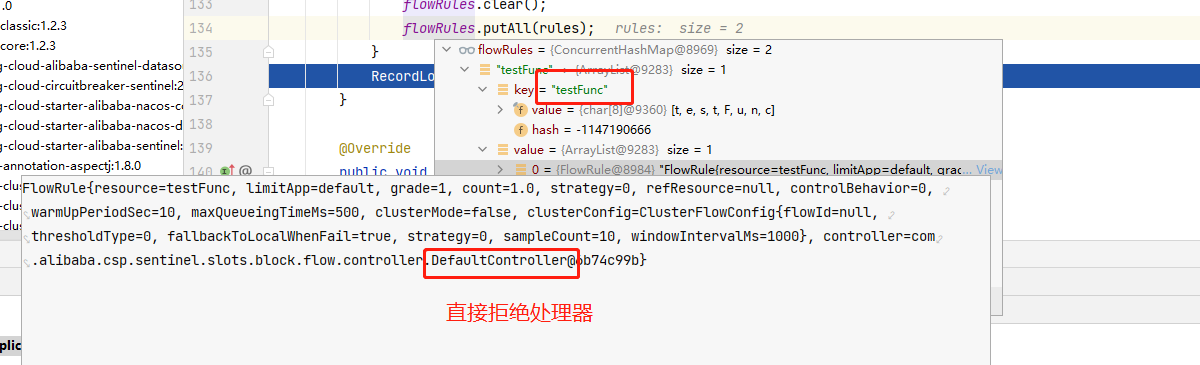
然后执行完handle方法并创建完处理器后,会走到handleResponse,在这里会返回response给dashboard断开连接。
5.3.4 Sentinel进行限流
Sentinel是通过 SphU.entry(target, EntryType.IN)代码完成限流/熔断等操作,所以我们在SphU#entry方法上打上断点。

我们跟进去,最终会走到CtSph#entryWithPriority方法,这个方法是 Sentinel 的骨架,非常重要。:
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
//从ThreadLocal中获取Context实例
Context context = ContextUtil.getContext();
//如果是 NullContext,那么说明 context name 超过了 2000 个,参见 ContextUtil#trueEnter
//这个时候,Sentinel 不再接受处理新的 context 配置,也就是不做这些新的接口的统计、限流熔断等
if (context instanceof NullContext) {
// The {@link NullContext} indicates that the amount of context has exceeded the threshold,
// so here init the entry only. No rule checking will be done.
return new CtEntry(resourceWrapper, null, context);
}
//如果我们不显式调用 ContextUtil#enter,这里会进入到默认的 context 中
if (context == null) {
// Using default context.
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
// Global switch is close, no rule checking will do.
//Sentinel的全局开关
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
//这里使用了责任链模式
//下面这行代码用于构建一个责任链,入参是 resource,资源的唯一标识是 resource name
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
/*
* Means amount of resources (slot chain) exceeds {@link Constants.MAX_SLOT_CHAIN_SIZE},
* so no rule checking will be done.
*/
//根据 lookProcessChain 方法,我们知道,当 resource 超过 Constants.MAX_SLOT_CHAIN_SIZE,也就是 6000 的时候,Sentinel 开始不处理新的请求,这么做主要是为了 Sentinel 的性能考虑
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
// 执行这个责任链。如果抛出 BlockException,说明链上的某一环拒绝了该请求,
// 把这个异常往上层业务层抛,业务层处理 BlockException 应该进入到熔断降级逻辑中
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
//开启链路调用
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}
在上面的代码中,Sentinel的处理核心就在这个责任链上,链中每一个节点是一个 Slot 实例,这个链通过 BlockException 异常来告知调用入口最终的执行情况。
我们进入lookProcessChain方法中,如果链路是空的,我们将会构建一个链路,走到newSlotChain方法:
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
ProcessorSlotChain chain = chainMap.get(resourceWrapper);
if (chain == null) {
synchronized (LOCK) {
chain = chainMap.get(resourceWrapper);
if (chain == null) {
// Entry size limit.
if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) {
return null;
}
//构建链路
chain = SlotChainProvider.newSlotChain();
Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>(
chainMap.size() + 1);
newMap.putAll(chainMap);
newMap.put(resourceWrapper, chain);
chainMap = newMap;
}
}
}
return chain;
}
然后我们进入到newSlotChain方法中,这里会将所有的Slot添加到链中这里主要是通过SPI的方式,然后构建chain并返回。
public static ProcessorSlotChain newSlotChain() {
if (slotChainBuilder != null) {
return slotChainBuilder.build();
}
// Resolve the slot chain builder SPI.
//Sentinel 提供了 SPI 端点,,我们可以定制builder
slotChainBuilder = SpiLoader.loadFirstInstanceOrDefault(SlotChainBuilder.class, DefaultSlotChainBuilder.class);
if (slotChainBuilder == null) {
// Should not go through here.
RecordLog.warn("[SlotChainProvider] Wrong state when resolving slot chain builder, using default");
slotChainBuilder = new DefaultSlotChainBuilder();
} else {
RecordLog.info("[SlotChainProvider] Global slot chain builder resolved: "
+ slotChainBuilder.getClass().getCanonicalName());
}
//构建
return slotChainBuilder.build();
}
具体添加Slot在build方法中:
@Override
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
// Note: the instances of ProcessorSlot should be different, since they are not stateless.
List<ProcessorSlot> sortedSlotList = SpiLoader.loadPrototypeInstanceListSorted(ProcessorSlot.class);
for (ProcessorSlot slot : sortedSlotList) {
if (!(slot instanceof AbstractLinkedProcessorSlot)) {
RecordLog.warn("The ProcessorSlot(" + slot.getClass().getCanonicalName() + ") is not an instance of AbstractLinkedProcessorSlot, can't be added into ProcessorSlotChain");
continue;
}
//添加Slot
chain.addLast((AbstractLinkedProcessorSlot<?>) slot);
}
return chain;
}
然后我们回到entryWithPriority方法,继续往下走会执行,会对链路中每个进行逐一调用,一直到到最后一个Slot。可以自行打断点查看。
//开启链路调用
chain.entry(context, resourceWrapper, null, count, prioritized, args);
执行完后,我们可以在断点查看当前链路中的所有slot。
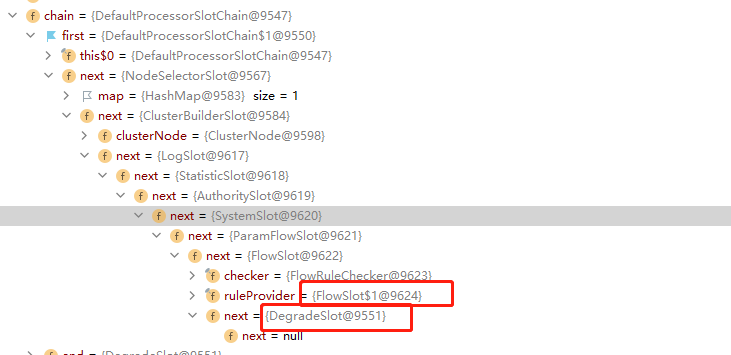
在这里,我们主要看FlowSlot,因为这个是限流的插槽。
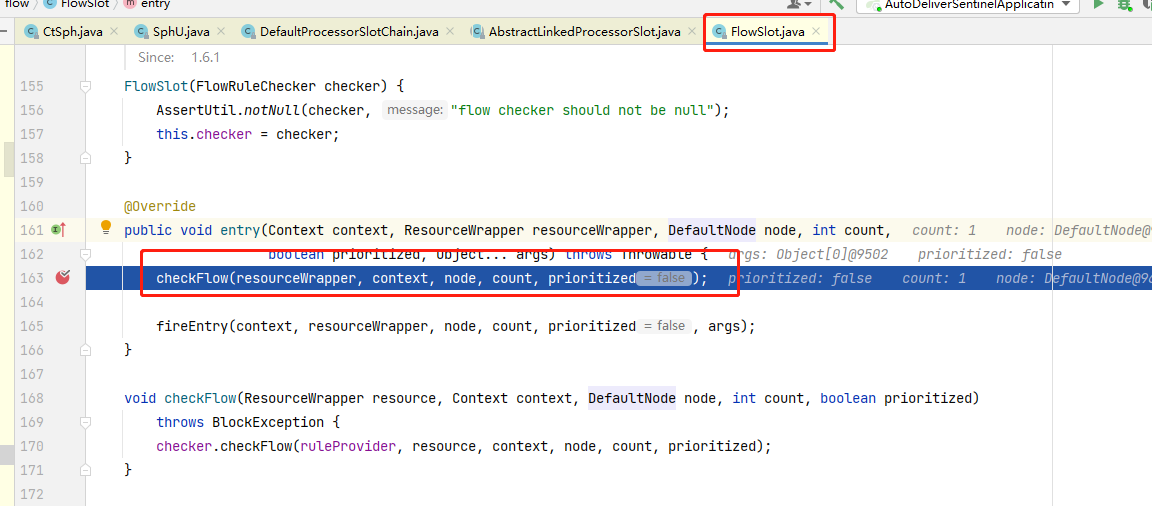
我们进入checkFlow方法,这里会根据资源的名称去找限流规则:
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource,
Context context, DefaultNode node, int count, boolean prioritized) throws BlockException {
if (ruleProvider == null || resource == null) {
return;
}
//根据资源名称找到对应的限流规则
Collection<FlowRule> rules = ruleProvider.apply(resource.getName());
if (rules != null) {
for (FlowRule rule : rules) {
//遍历规则以此判断是否通过
if (!canPassCheck(rule, context, node, count, prioritized)) {
throw new FlowException(rule.getLimitApp(), rule);
}
}
}
}
我们进入ruleProvider#apply方法,然后再FlowRuleManager#getFlowRuleMap中可以看到我们的限流规则,如下图:
private final Function<String, Collection<FlowRule>> ruleProvider = new Function<String, Collection<FlowRule>>() {
@Override
public Collection<FlowRule> apply(String resource) {
// Flow rule map should not be null.
Map<String, List<FlowRule>> flowRules = FlowRuleManager.getFlowRuleMap();
return flowRules.get(resource);
}
};
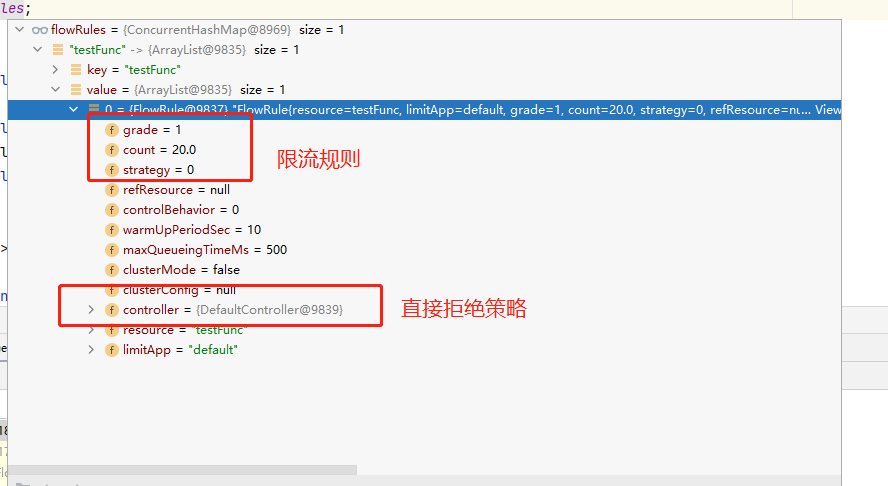
我们回到checkFlow方法,找完限流规则回去执行canPassCheck方法判断规则是否通过,canPassCheck代码如下:
public boolean canPassCheck(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
String limitApp = rule.getLimitApp();
if (limitApp == null) {
return true;
}
//判断是否是集群
if (rule.isClusterMode()) {
return passClusterCheck(rule, context, node, acquireCount, prioritized);
}
//不是集群则本地检查
return passLocalCheck(rule, context, node, acquireCount, prioritized);
}
我们跟进本地检查方法
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node);
if (selectedNode == null) {
return true;
}
//根据规则处理器进行检查
return rule.getRater().canPass(selectedNode, acquireCount, prioritized);
}
我们继续跟进canPass会进入到Defaultcontroller中,因为我们当时设置的就是直接拒绝策略
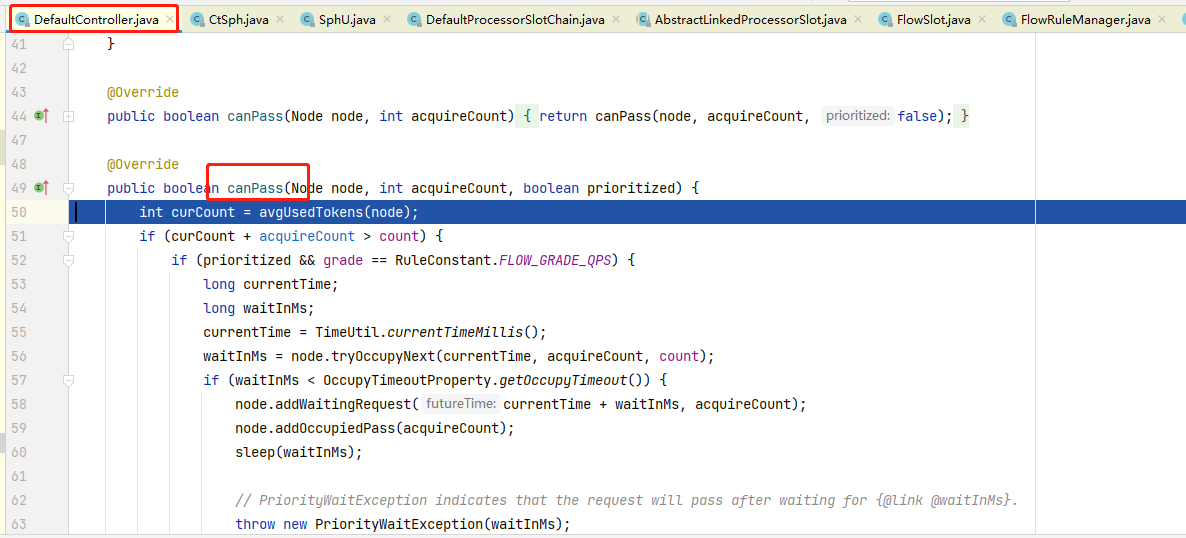
代码如下:
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
//当前已经统计的数
int curCount = avgUsedTokens(node);
//如果已统计的数+请求计数>限流数量,返回false,代表限流
if (curCount + acquireCount > count) {
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
long currentTime;
long waitInMs;
currentTime = TimeUtil.currentTimeMillis();
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
node.addOccupiedPass(acquireCount);
sleep(waitInMs);
// PriorityWaitException indicates that the request will pass after waiting for {@link @waitInMs}.
throw new PriorityWaitException(waitInMs);
}
}
return false;
}
return true;
}
private int avgUsedTokens(Node node) {
if (node == null) {
return DEFAULT_AVG_USED_TOKENS;
}
//如果当前是线程数限流,则返回当前线程数
//如果是QPS,则返回当前通过的qps数据
return grade == RuleConstant.FLOW_GRADE_THREAD ? node.curThreadNum() : (int)(node.passQps());
}
以上就是最简单的限流的源码跟踪,建议自己跟一遍源码。
5.3.5 Sentinel持久化到Nacos
根据5.2.7的介绍,之前的配置只能修改nacos中的配置,而不能在Sentinel中进行修改,我们需要sentinel和nacos修改都能完成同步,这就需要对源码进行修改了。步骤:
可以参照flow模块去修改,因为阿里提供了flow模块的例子
- 修改NacosConfig,增加对应模块转换器
- 增加对应模块的publisher和provider
- 修改对应模块的controller
- 首先注入publisher和provider
- 然后将publish用注入的publisher代替
PS:其实修改Controller时只需要修改publishRules就可以了,也就是说其实不用注入provider,因为之前5.2.7中可以发现dashboard是可以从nacos拉数据的只是不同同步数据,所以只需要将publishRules改了就行。
其实改源码的整体核心,我个人感觉就是将推送规则从之前的推到内存现在改到推送到数据源中。
我这里的版本是Sentinel DashBoard1.8,下面进行修改:
修改flow模块
首先将源码下载下来,然后IDEA打开Sentinel DashBoard1.8源码工程,在源码工程的test中有阿里为我们写好的流控改造的案例,如下图:
然后我们将这四个文件分别拷贝到如下图的位置(放哪都行,只是这样更符合包的逻辑):
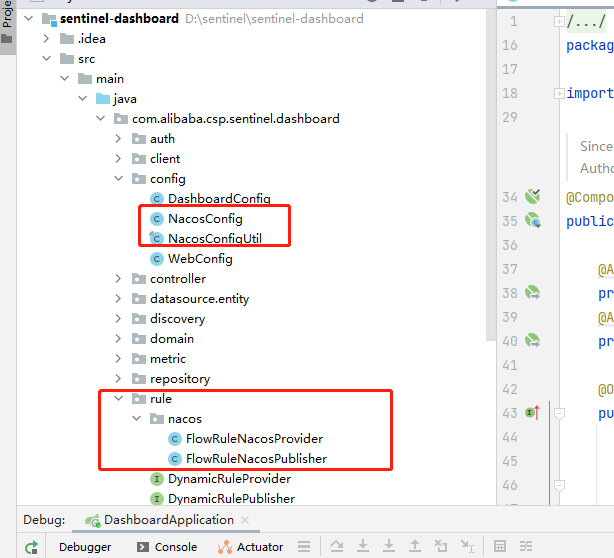
然后我们稍作修改NacosConfig和NacosConfigUtil:
NacosConfig.java:这个文件主要是把nacos上的地址命名空间等配置好即可。
@Configuration
public class NacosConfig {
//可以都写在配置文件里,这里是为了方便
@Value("${nacos.addr}")
private String nacosAddr;
@Bean
public Converter<List<FlowRuleEntity>, String> flowRuleEntityEncoder() {
return JSON::toJSONString;
}
@Bean
public Converter<String, List<FlowRuleEntity>> flowRuleEntityDecoder() {
return s -> JSON.parseArray(s, FlowRuleEntity.class);
}
//...之后不同的模块需要自己加转换器
@Bean
public ConfigService nacosConfigService() throws Exception {
Properties properties = new Properties();
properties.put(PropertyKeyConst.SERVER_ADDR,nacosAddr);
properties.put(PropertyKeyConst.NAMESPACE,"sentinel");
properties.put(PropertyKeyConst.USERNAME,"nacos");
properties.put(PropertyKeyConst.PASSWORD,"nacos");
return ConfigFactory.createConfigService(properties);
}
}
NacosConfigUtil.java:这个文件主要是nacos上配置的后缀和GroupID
public final class NacosConfigUtil {
public static final String GROUP_ID = "SENTINEL_GROUP";
//不同的模块的dataId需要自己加
public static final String FLOW_DATA_ID_POSTFIX = "-flow-rules";
public static final String DEGRADE_DATA_ID_POSTFIX = "-degrade-rules";
public static final String PARAM_FLOW_DATA_ID_POSTFIX = "-param-rules";
public static final String SYS_DATA_ID_POSTFIX = "-system-rules";
public static final String AUTH_DATA_ID_POSTFIX = "-auth-rules";
/*
public static final String GATEWAY_FLOW_DATA_ID_POSTFIX = "-gateway-flow";
public static final String GATEWAY_API_DATA_ID_POSTFIX = "-gateway-api";
public static final String CLUSTER_MAP_DATA_ID_POSTFIX = "-cluster-map";*/
/**
* cc for `cluster-client`
*/
public static final String CLIENT_CONFIG_DATA_ID_POSTFIX = "-cc-config";
/**
* cs for `cluster-server`
*/
public static final String SERVER_TRANSPORT_CONFIG_DATA_ID_POSTFIX = "-cs-transport-config";
public static final String SERVER_FLOW_CONFIG_DATA_ID_POSTFIX = "-cs-flow-config";
public static final String SERVER_NAMESPACE_SET_DATA_ID_POSTFIX = "-cs-namespace-set";
private NacosConfigUtil() {}
}
FlowRuleNacosPublisher和FlowRuleNacosProvider不需要修改,阿里已经写好了。
然后我们把FlowControllerV1的publishRules方法给改了,并且在FlowControllerV1中注入FlowRuleNacosPublisher和FlowRuleNacosProvider。
//注入依赖
@Autowired
@Qualifier("flowRuleNacosProvider")
private DynamicRuleProvider<List<FlowRuleEntity>> ruleProvider;
@Autowired
@Qualifier("flowRuleNacosPublisher")
private DynamicRulePublisher<List<FlowRuleEntity>> rulePublisher;
//修改方法
// private CompletableFuture<Void> publishRules(String app, String ip, Integer port) {
// List<FlowRuleEntity> rules = repository.findAllByMachine(MachineInfo.of(app, ip, port));
// return sentinelApiClient.setFlowRuleOfMachineAsync(app, ip, port, rules);
// }
private void publishRules(/*@NonNull*/ String app) throws Exception {
List<FlowRuleEntity> rules = repository.findAllByApp(app);
rulePublisher.publish(app, rules);
}
到此流控模块就可以实现nacos和sentinel互相同步了。
我们下面来测试,打开autoDeliverSentinel和我们改造好的控制台,发送一个请求,然后我们可以看到从nacos中拉取的配置规则:

我们在Sentinel中进行修改比如将阈值修改成1或者新增一个流控规则,然后去nacos上看,发现nacos已经完成修改,然后再nacos中在改一个数,回来看Sentinel中也完成了修改。结果如下图:
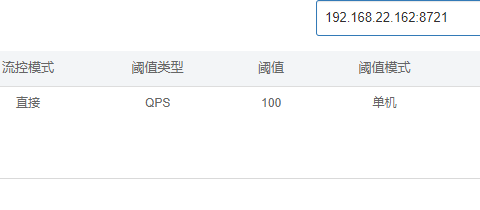
修改降级模块
首先在nacosconfig和nacosconfigUtil中增加降级的转换器和dataId:
//降级规则 Converter
@Bean
public Converter<List<DegradeRuleEntity>, String> degradeRuleEntityEncoder() {
return JSON::toJSONString;
}
@Bean
public Converter<String, List<DegradeRuleEntity>> degradeRuleEntityDecoder() {
return s -> JSON.parseArray(s, DegradeRuleEntity.class);
}
然后增加降级的provider和publisher:
@Component("degradeRuleNacosProvider")
public class DegradeRuleNacosProvider implements DynamicRuleProvider<List<DegradeRuleEntity>> {
@Autowired
private ConfigService configService;
@Autowired
private Converter<String, List<DegradeRuleEntity>> converter;
@Override
public List<DegradeRuleEntity> getRules(String appName) throws Exception {
//System.out.println(appName+NacosConfigUtil.DEGRADE_DATA_ID_POSTFIX+NacosConfigUtil.GROUP_ID);
String rules = configService.getConfig(appName + NacosConfigUtil.DEGRADE_DATA_ID_POSTFIX,
NacosConfigUtil.GROUP_ID, 3000);
if (StringUtil.isEmpty(rules)) {
return new ArrayList<>();
}
System.out.println(rules);//用日志代替,这里是为了方便
return converter.convert(rules);
}
}
@Component("degradeRuleNacosPublisher")
public class DegradeRuleNacosPublisher implements DynamicRulePublisher<List<DegradeRuleEntity>> {
@Autowired
private ConfigService configService;
@Autowired
private Converter<List<DegradeRuleEntity>, String> converter;
@Override
public void publish(String app, List<DegradeRuleEntity> rules) throws Exception {
AssertUtil.notEmpty(app, "app name cannot be empty");
if (rules == null) {
return;
}
configService.publishConfig(app + NacosConfigUtil.DEGRADE_DATA_ID_POSTFIX,
NacosConfigUtil.GROUP_ID, converter.convert(rules));
}
}
然后修改降级的controller,只需要改publishRules就可以:
@RestController
@RequestMapping("/degrade")
public class DegradeController {
private final Logger logger = LoggerFactory.getLogger(DegradeController.class);
@Autowired
@Qualifier("degradeRuleNacosProvider")
private DynamicRuleProvider<List<DegradeRuleEntity>> ruleProvider;
@Autowired
@Qualifier("degradeRuleNacosPublisher")
private DynamicRulePublisher<List<DegradeRuleEntity>> rulePublisher;
@Autowired
private RuleRepository<DegradeRuleEntity, Long> repository;
@Autowired
private SentinelApiClient sentinelApiClient;
@GetMapping("/rules.json")
@AuthAction(PrivilegeType.READ_RULE)
public Result<List<DegradeRuleEntity>> apiQueryMachineRules(String app, String ip, Integer port) {
if (StringUtil.isEmpty(app)) {
return Result.ofFail(-1, "app can't be null or empty");
}
if (StringUtil.isEmpty(ip)) {
return Result.ofFail(-1, "ip can't be null or empty");
}
if (port == null) {
return Result.ofFail(-1, "port can't be null");
}
try {
List<DegradeRuleEntity> rules = sentinelApiClient.fetchDegradeRuleOfMachine(app, ip, port);
//List<DegradeRuleEntity> rules = ruleProvider.getRules(app);
System.out.println(rules);
rules = repository.saveAll(rules);
return Result.ofSuccess(rules);
} catch (Throwable throwable) {
logger.error("queryApps error:", throwable);
return Result.ofThrowable(-1, throwable);
}
}
@PostMapping("/rule")
@AuthAction(PrivilegeType.WRITE_RULE)
public Result<DegradeRuleEntity> apiAddRule(@RequestBody DegradeRuleEntity entity) {
Result<DegradeRuleEntity> checkResult = checkEntityInternal(entity);
if (checkResult != null) {
return checkResult;
}
Date date = new Date();
entity.setGmtCreate(date);
entity.setGmtModified(date);
try {
entity = repository.save(entity);
} catch (Throwable t) {
logger.error("Failed to add new degrade rule, app={}, ip={}", entity.getApp(), entity.getIp(), t);
return Result.ofThrowable(-1, t);
}
try {
if (!publishRules(entity.getApp(), entity.getIp(), entity.getPort())) {
logger.warn("Publish degrade rules failed, app={}", entity.getApp());
}
} catch (Exception e) {
e.printStackTrace();
}
return Result.ofSuccess(entity);
}
@PutMapping("/rule/{id}")
@AuthAction(PrivilegeType.WRITE_RULE)
public Result<DegradeRuleEntity> apiUpdateRule(@PathVariable("id") Long id,
@RequestBody DegradeRuleEntity entity) {
if (id == null || id <= 0) {
return Result.ofFail(-1, "id can't be null or negative");
}
DegradeRuleEntity oldEntity = repository.findById(id);
if (oldEntity == null) {
return Result.ofFail(-1, "Degrade rule does not exist, id=" + id);
}
entity.setApp(oldEntity.getApp());
entity.setIp(oldEntity.getIp());
entity.setPort(oldEntity.getPort());
entity.setId(oldEntity.getId());
Result<DegradeRuleEntity> checkResult = checkEntityInternal(entity);
if (checkResult != null) {
return checkResult;
}
entity.setGmtCreate(oldEntity.getGmtCreate());
entity.setGmtModified(new Date());
try {
entity = repository.save(entity);
} catch (Throwable t) {
logger.error("Failed to save degrade rule, id={}, rule={}", id, entity, t);
return Result.ofThrowable(-1, t);
}
try {
if (!publishRules(entity.getApp(), entity.getIp(), entity.getPort())) {
logger.warn("Publish degrade rules failed, app={}", entity.getApp());
}
} catch (Exception e) {
e.printStackTrace();
}
return Result.ofSuccess(entity);
}
@DeleteMapping("/rule/{id}")
@AuthAction(PrivilegeType.DELETE_RULE)
public Result<Long> delete(@PathVariable("id") Long id) {
if (id == null) {
return Result.ofFail(-1, "id can't be null");
}
DegradeRuleEntity oldEntity = repository.findById(id);
if (oldEntity == null) {
return Result.ofSuccess(null);
}
try {
repository.delete(id);
} catch (Throwable throwable) {
logger.error("Failed to delete degrade rule, id={}", id, throwable);
return Result.ofThrowable(-1, throwable);
}
try {
if (!publishRules(oldEntity.getApp(), oldEntity.getIp(), oldEntity.getPort())) {
logger.warn("Publish degrade rules failed, app={}", oldEntity.getApp());
}
} catch (Exception e) {
e.printStackTrace();
}
return Result.ofSuccess(id);
}
// private boolean publishRules(String app, String ip, Integer port) {
// List<DegradeRuleEntity> rules = repository.findAllByMachine(MachineInfo.of(app, ip, port));
// return sentinelApiClient.setDegradeRuleOfMachine(app, ip, port, rules);
// }
private boolean publishRules(/*@NonNull*/ String app, String ip, Integer port) throws Exception {
List<DegradeRuleEntity> rules = repository.findAllByMachine(MachineInfo.of(app, ip, port));
try{
rulePublisher.publish(app, rules);
return true;
}catch (Exception e){
return false;
}
}
private <R> Result<R> checkEntityInternal(DegradeRuleEntity entity) {
if (StringUtil.isBlank(entity.getApp())) {
return Result.ofFail(-1, "app can't be blank");
}
if (StringUtil.isBlank(entity.getIp())) {
return Result.ofFail(-1, "ip can't be null or empty");
}
if (entity.getPort() == null || entity.getPort() <= 0) {
return Result.ofFail(-1, "invalid port: " + entity.getPort());
}
if (StringUtil.isBlank(entity.getLimitApp())) {
return Result.ofFail(-1, "limitApp can't be null or empty");
}
if (StringUtil.isBlank(entity.getResource())) {
return Result.ofFail(-1, "resource can't be null or empty");
}
Double threshold = entity.getCount();
if (threshold == null || threshold < 0) {
return Result.ofFail(-1, "invalid threshold: " + threshold);
}
Integer recoveryTimeoutSec = entity.getTimeWindow();
if (recoveryTimeoutSec == null || recoveryTimeoutSec <= 0) {
return Result.ofFail(-1, "recoveryTimeout should be positive");
}
Integer strategy = entity.getGrade();
if (strategy == null) {
return Result.ofFail(-1, "circuit breaker strategy cannot be null");
}
if (strategy < CircuitBreakerStrategy.SLOW_REQUEST_RATIO.getType()
|| strategy > RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT) {
return Result.ofFail(-1, "Invalid circuit breaker strategy: " + strategy);
}
if (entity.getMinRequestAmount() == null || entity.getMinRequestAmount() <= 0) {
return Result.ofFail(-1, "Invalid minRequestAmount");
}
if (entity.getStatIntervalMs() == null || entity.getStatIntervalMs() <= 0) {
return Result.ofFail(-1, "Invalid statInterval");
}
if (strategy == RuleConstant.DEGRADE_GRADE_RT) {
Double slowRatio = entity.getSlowRatioThreshold();
if (slowRatio == null) {
return Result.ofFail(-1, "SlowRatioThreshold is required for slow request ratio strategy");
} else if (slowRatio < 0 || slowRatio > 1) {
return Result.ofFail(-1, "SlowRatioThreshold should be in range: [0.0, 1.0]");
}
} else if (strategy == RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO) {
if (threshold > 1) {
return Result.ofFail(-1, "Ratio threshold should be in range: [0.0, 1.0]");
}
}
return null;
}
}
5.4 Nacos源码
我这里用的springcloud版本是Hoxton.RELEASE;spring-cloud-alibaba版本2.2.2
nacos服务端版本 1.3.2版本
5.4.1 工程搭建
Github上下载源码,解压后导入IDEA,IDEA会自动下载Maven的相关依赖(下载过程可能会很久,视网络情况而定),下载完成后,我们需要对源码工程进行编译,如下图:
编译完成后各模块如下:
- address模块:主要查询nacos集群中节点的个数以及IP的列表
- api模块:主要给客户端调用的api接口的抽象
- common模块:主要是通用的工具包和字符串常量的定义
- client模块:主要是对依赖api模块和common模块接口的实现,给nacos客户端使用
- cmdb模块:操作的数据存储在内存中,该模块提供一个查询数据标签的接口
- config模块:主要是服务配置的管理,即配置中心,提供api给客户端拉取配置信息,以及提供更新配置的api,客户端通过长轮询更新配置信息
- naming模块:作为服务注册中心的实现模块,具有服务注册和发现的功能。
- console模块:实现控制台的功能,具有权限校验,服务状态,健康检查等功能
- core模块:实现Spring的PropertySource的后置处理器,用于属性加载、初始化、监听器相关操作
- distribution模块:主要是打包nacos-server的操作,使用maven-assembly-plugin进行自定义打包。
工程编译完了之后我们可以在console模块启动主启动类,如下图:
当然nacos默认是集群启动的,所以需要在启动类上配置上单机启动参数-Dnacos.standalone=true,IDEA在VM参数中配置即可,不然启动会报错。然后在浏览器输入localhost:8848/nacos登录即可。
5.4.2 Nacos客户端启动及自动装配
在Dalston.SR4版本之前,nacos客户端的启动,需要在spring-cloud主函数上添加@EnableDiscoveryClient注解,在此版本之后也就是从Spring Cloud Edgware开始,@EnableDiscoveryClient 可省略。官方文档如下:
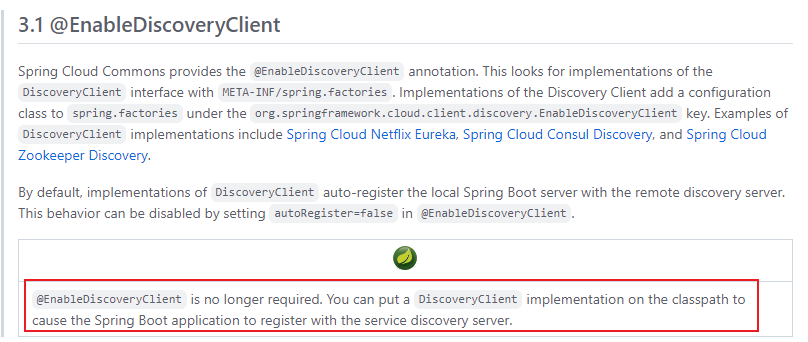
nacos客户端是基于SpringBoot是自动装配(关于自动装配可以看我的SpringBoot笔记#2.2自动装配原理)的,因此我们可以在我们引入的nacos客户端的jar包中找到自动装配文件spring.factories。
我们查看spring.factories文件,发现最后有一个BootstrapConfiguration,我们进入此类:
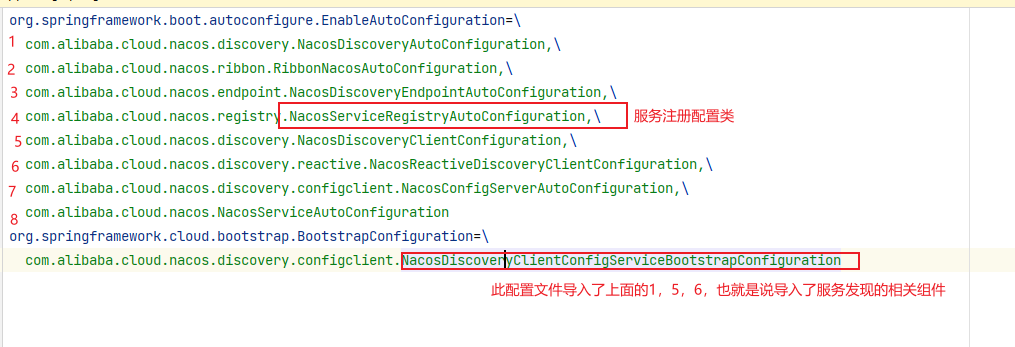
使用BootstrapConfiguration加载,等同于bootstrap.yml中的配置
@ImportAutoConfiguration({
NacosDiscoveryAutoConfiguration.class,//注入NacosServiceDiscovery这个Bean
NacosDiscoveryClientConfiguration.class,//注入NacosDiscoveryClient这个Bean
NacosReactiveDiscoveryClientConfiguration.class//注入NacosReactiveDiscoveryClient,用于响应式
})
public class NacosDiscoveryClientConfigServiceBootstrapConfiguration {
}
发现此类导入了三个配置类,我们先看一下NacosDiscoveryAutoConfiguration
@Configuration(proxyBeanMethods = false)
@ConditionalOnDiscoveryEnabled
@ConditionalOnBlockingDiscoveryEnabled
@ConditionalOnNacosDiscoveryEnabled//确保spring.cloud.nacos.discovery.enable为true
@AutoConfigureBefore({ SimpleDiscoveryClientAutoConfiguration.class,
CommonsClientAutoConfiguration.class })
@AutoConfigureAfter(NacosDiscoveryAutoConfiguration.class)
public class NacosDiscoveryClientConfiguration {
//注入了NacosDiscoverClient,此类实现了Spring Cloud的接口DiscoveryClient
@Bean
public DiscoveryClient nacosDiscoveryClient(
NacosServiceDiscovery nacosServiceDiscovery) {
return new NacosDiscoveryClient(nacosServiceDiscovery);
}
//当spring.cloud.nacos.discovery.watch.enabled配置为true时会注入NacosWatch
//此配置默认为true
//此类作用将在5.4.5中介绍
@Bean
@ConditionalOnMissingBean
@ConditionalOnProperty(value = "spring.cloud.nacos.discovery.watch.enabled",
matchIfMissing = true)
public NacosWatch nacosWatch(NacosServiceManager nacosServiceManager,
NacosDiscoveryProperties nacosDiscoveryProperties) {
return new NacosWatch(nacosServiceManager, nacosDiscoveryProperties);
}
}
这个配置类中注入了NacosDiscoverClient,此类实现了Spring Cloud的接口DiscoveryClient。
我们先来了解一下Spring Cloud的相关接口:
- DiscoveryClient,服务发现的接口,有两个核心方法:
List<ServiceInstance> getInstances(String serviceId);和List<String> getServices(),当我们进行服务调用时,会先通过调用服务的名称,调用getInstances方法,到对应的服务中心获取到服务的IP等信息的列表,最后通过负载均衡算法调用具体的ip地址。- ReactiveDiscoveryClient 接口中定义的方法和DiscoveryClient 中定义的方法完全一样,不同的是将返回值为
List改为Flux,主要用于支持响应式服务发现,在Spring WebFlux就会使用该接口的实现- ServiceRegistry 服务注册的接口,该接口有
register(Registration)、deregister(Registration)等方法,可以让你提供自定义的服务注册方法进行服务注册。
我们进入NacosDiscoverClient(源码很简单,这里略不贴出源码)发现此类的方法全部委托给了NacosServiceDiscovery,而NacosServiceDiscovery正是NacosDiscoveryAutoConfiguration注入的。
NacosDiscoveryAutoConfiguration源码如下:
@Configuration(proxyBeanMethods = false) @ConditionalOnDiscoveryEnabled @ConditionalOnNacosDiscoveryEnabled//确保spring.cloud.nacos.discovery.enable为true public class NacosDiscoveryAutoConfiguration { @Bean @ConditionalOnMissingBean public NacosServiceDiscovery nacosServiceDiscovery( NacosDiscoveryProperties discoveryProperties, NacosServiceManager nacosServiceManager) { return new NacosServiceDiscovery(discoveryProperties, nacosServiceManager); } //略。。。 }
也就是说这个BootstrapConfiguration实际上是将服务发现的相关组件进行了注入。
然后我们看spring.factories中的EnableAutoConfiguration的相关配置,其中有一个NacosServiceRegistryAutoConfiguration配置,我们进去看一下这个配置类中导入了NacosServiceRegistry继承了ServiceRegistry说明此类会将服务注册的相关组件导入,源码如下:
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties
@ConditionalOnNacosDiscoveryEnabled//确保spring.cloud.nacos.discovery.enable为true
//默认为true,当@EnableDiscoveryClient注解配置为false时,此属性为false
@ConditionalOnProperty(value = "spring.cloud.service-registry.auto-registration.enabled",
//matchIfMissing,也就是在自动配置的bean中如果miss了,就去properties或者yml文件中去找
matchIfMissing = true)
@AutoConfigureAfter({ AutoServiceRegistrationConfiguration.class,
AutoServiceRegistrationAutoConfiguration.class,
NacosDiscoveryAutoConfiguration.class })
public class NacosServiceRegistryAutoConfiguration {
//注入了NacosServiceRegistry
@Bean
public NacosServiceRegistry nacosServiceRegistry(
NacosDiscoveryProperties nacosDiscoveryProperties,
NacosServiceManager nacosServiceManager) {
return new NacosServiceRegistry(nacosDiscoveryProperties, nacosServiceManager);
}
@Bean
@ConditionalOnBean(AutoServiceRegistrationProperties.class)
public NacosRegistration nacosRegistration(
ObjectProvider<List<NacosRegistrationCustomizer>> registrationCustomizers,
NacosDiscoveryProperties nacosDiscoveryProperties,
ApplicationContext context) {
return new NacosRegistration(registrationCustomizers.getIfAvailable(),
nacosDiscoveryProperties, context);
}
@Bean
@ConditionalOnBean(AutoServiceRegistrationProperties.class)
public NacosAutoServiceRegistration nacosAutoServiceRegistration(
NacosServiceRegistry registry,
AutoServiceRegistrationProperties autoServiceRegistrationProperties,
NacosRegistration registration) {
return new NacosAutoServiceRegistration(registry,
autoServiceRegistrationProperties, registration);
}
}
这里我们注意,除了@ConditionalOnNacosDiscoveryEnabled,服务注册配置类还有一个@ConditionalOnProperty注解,用于检测@EnableDiscoveryClient的配置,也就是说当我们把@EnableDiscoveryClient注解配置为false时仅仅是不能进行服务注册了,但是服务发现等相关组件还可以使用。同时这也是不再需要在启动类加上@EnableDiscoveryClient注解的原因,因为所有组件都检测spring.cloud.nacos.discovery.enable。这也是开头不在需要@EnableDiscoveryClient注解的原因。
我们可以对此进行测试验证,用我们的demo即可验证,编写一个获取nacos服务端的接口
@GetMapping("/test") public String testEnable(){ //getInstances("服务名称") return discoveryClient.getInstances("user1").toString(); }然后在一个微服务中设置
spring.cloud.nacos.discovery.enable和@EnableDiscoveryClient这两个的值,然后通过此接口查看是否能获取nacos服务端信息,获取另一个微服务的相关信息;另一个微服务直接连nacos即可。
我们可以查看@EnableDiscoveryClient的源码进行验证:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(EnableDiscoveryClientImportSelector.class)
public @interface EnableDiscoveryClient {
boolean autoRegister() default true;
}
我们发现此注解通过注入EnableDiscoveryClientImportSelector来实现功能,我们查看此类源码,此类继承了ImportSelector,所以我们应该重点查看selectImports方法,源码如下:
@Import是spring框架的底层注解,作用是给容器导入某个组件类
而且实现ImportSelector接口的类,需要返回String[],通过@Import()注解,将数组中的对象名将作为对象生成为bean
@Order(Ordered.LOWEST_PRECEDENCE - 100)
public class EnableDiscoveryClientImportSelector
extends SpringFactoryImportSelector<EnableDiscoveryClient> {
@Override
public String[] selectImports(AnnotationMetadata metadata) {
String[] imports = super.selectImports(metadata);
//获取注解属性
AnnotationAttributes attributes = AnnotationAttributes.fromMap(
metadata.getAnnotationAttributes(getAnnotationClass().getName(), true));
//获取是否自动注册
boolean autoRegister = attributes.getBoolean("autoRegister");
if (autoRegister) {
List<String> importsList = new ArrayList<>(Arrays.asList(imports));
importsList.add(
"org.springframework.cloud.client.serviceregistry.AutoServiceRegistrationConfiguration");
imports = importsList.toArray(new String[0]);
}
else {
//如果不开启就将spring.cloud.service-registry.auto-registration.enabled设为false,表示不开启自动注册
Environment env = getEnvironment();
if (ConfigurableEnvironment.class.isInstance(env)) {
ConfigurableEnvironment configEnv = (ConfigurableEnvironment) env;
LinkedHashMap<String, Object> map = new LinkedHashMap<>();
map.put("spring.cloud.service-registry.auto-registration.enabled", false);
MapPropertySource propertySource = new MapPropertySource(
"springCloudDiscoveryClient", map);
configEnv.getPropertySources().addLast(propertySource);
}
}
return imports;
}
//略。。。
}
@Configuration(proxyBeanMethods = false)
//启用配置类,spring.cloud.service-registry.auto-registration.enabled默认为true
@EnableConfigurationProperties(AutoServiceRegistrationProperties.class)
@ConditionalOnProperty(value = "spring.cloud.service-registry.auto-registration.enabled",
matchIfMissing = true)
public class AutoServiceRegistrationConfiguration {
}
可以看到@EnableDiscoveryClient注解主要是将spring.cloud.service-registry.auto-registration.enabled设置为true,而此值默认就是true,因此不加此注释也可以进行服务注册。
5.4.3 客户端服务注册流程
在上一小节,服务注册的自动装配配置类如下,这个配置类一共导入了三个Bean,分别有不同的作用,代码如下:
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties
@ConditionalOnNacosDiscoveryEnabled
@ConditionalOnProperty(value = "spring.cloud.service-registry.auto-registration.enabled",
matchIfMissing = true)
@AutoConfigureAfter({ AutoServiceRegistrationConfiguration.class,
AutoServiceRegistrationAutoConfiguration.class,
NacosDiscoveryAutoConfiguration.class })
public class NacosServiceRegistryAutoConfiguration {
//向注册中心注册服务
@Bean
public NacosServiceRegistry nacosServiceRegistry(
NacosDiscoveryProperties nacosDiscoveryProperties,
NacosServiceManager nacosServiceManager) {
return new NacosServiceRegistry(nacosDiscoveryProperties, nacosServiceManager);
}
//存储nacos服务的信息
@Bean
@ConditionalOnBean(AutoServiceRegistrationProperties.class)
public NacosRegistration nacosRegistration(
ObjectProvider<List<NacosRegistrationCustomizer>> registrationCustomizers,
NacosDiscoveryProperties nacosDiscoveryProperties,
ApplicationContext context) {
return new NacosRegistration(registrationCustomizers.getIfAvailable(),
nacosDiscoveryProperties, context);
}
//向nacos服务完成自动注册
@Bean
@ConditionalOnBean(AutoServiceRegistrationProperties.class)
public NacosAutoServiceRegistration nacosAutoServiceRegistration(
NacosServiceRegistry registry,
AutoServiceRegistrationProperties autoServiceRegistrationProperties,
NacosRegistration registration) {
return new NacosAutoServiceRegistration(registry,
autoServiceRegistrationProperties, registration);
}
}
那我们就从自动注册NacosAutoServiceRegistration这里开始看起,我们可以在这里打一个断点,可以看到这里注入的就是我们上面注入的两个Bean,如下图:
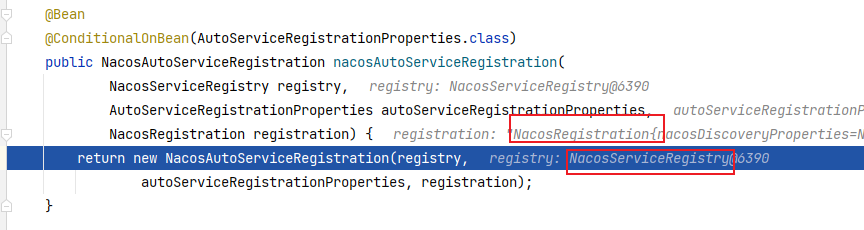
然后我们进入这个类:
public class NacosAutoServiceRegistration
extends AbstractAutoServiceRegistration<Registration> {
public NacosAutoServiceRegistration(ServiceRegistry<Registration> serviceRegistry,
AutoServiceRegistrationProperties autoServiceRegistrationProperties,
NacosRegistration registration) {
//执行了父类的构造方法
super(serviceRegistry, autoServiceRegistrationProperties);
this.registration = registration;
}
//略。。
}
我们查看父类源码,发现其继承了ApplicationListener<WebServerInitializedEvent>
继承后在容器启动时会执行onApplicationEvent方法,于是我们查看此方法,会从onApplicationEvent一路到register()方法,源码如下:
/**AbstractAutoServiceRegistration.java**/
@Override
@SuppressWarnings("deprecation")
public void onApplicationEvent(WebServerInitializedEvent event) {
//调用bind方法
bind(event);
}
@Deprecated
public void bind(WebServerInitializedEvent event) {
ApplicationContext context = event.getApplicationContext();
if (context instanceof ConfigurableWebServerApplicationContext) {
if ("management".equals(((ConfigurableWebServerApplicationContext) context)
.getServerNamespace())) {
return;
}
}
this.port.compareAndSet(0, event.getWebServer().getPort());
//调用start方法
this.start();
}
public void start() {
if (!isEnabled()) {
if (logger.isDebugEnabled()) {
logger.debug("Discovery Lifecycle disabled. Not starting");
}
return;
}
// only initialize if nonSecurePort is greater than 0 and it isn't already running
// because of containerPortInitializer below
if (!this.running.get()) {
this.context.publishEvent(
new InstancePreRegisteredEvent(this, getRegistration()));
//执行服务注册
register();
if (shouldRegisterManagement()) {
registerManagement();
}
this.context.publishEvent(
new InstanceRegisteredEvent<>(this, getConfiguration()));
this.running.compareAndSet(false, true);
}
}
我们进入register()方法,会跳转到NacosAutoServiceRegistration的register方法:
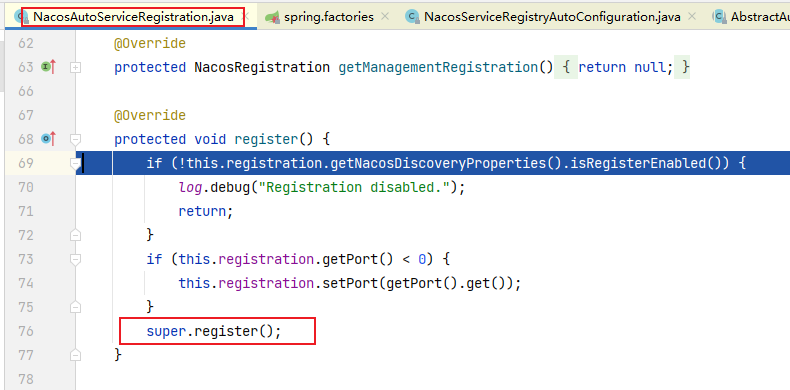
然后又会调用父类的register()方法,父类的此方法又会委托给实现子类:
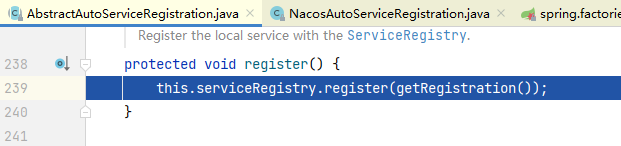
最终会走到NacosServiceRegistry#register方法:
@Override
public void register(Registration registration) {
if (StringUtils.isEmpty(registration.getServiceId())) {
log.warn("No service to register for nacos client...");
return;
}
NamingService namingService = namingService();
String serviceId = registration.getServiceId();
String group = nacosDiscoveryProperties.getGroup();
Instance instance = getNacosInstanceFromRegistration(registration);
try {
//通过NamingService完成注册
namingService.registerInstance(serviceId, group, instance);
log.info("nacos registry, {} {} {}:{} register finished", group, serviceId,
instance.getIp(), instance.getPort());
}
catch (Exception e) {
log.error("nacos registry, {} register failed...{},", serviceId,
registration.toString(), e);
// rethrow a RuntimeException if the registration is failed.
// issue : https://github.com/alibaba/spring-cloud-alibaba/issues/1132
rethrowRuntimeException(e);
}
}
这个方法会通过NamingService服务完成注册,我们进入到namingService.registerInstance方法:
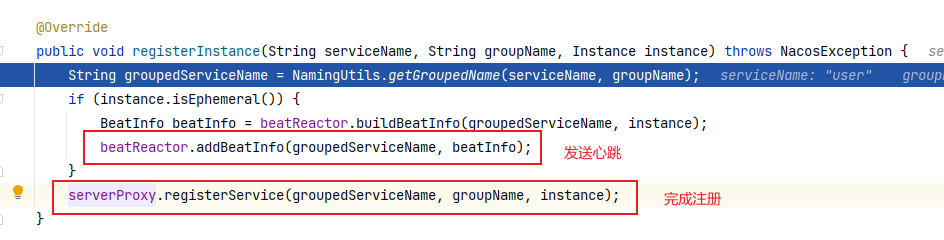
在这里就会分别发送心跳和完成注册。我们先看发送心跳的部分:
public void addBeatInfo(String serviceName, BeatInfo beatInfo) {
NAMING_LOGGER.info("[BEAT] adding beat: {} to beat map.", beatInfo);
String key = buildKey(serviceName, beatInfo.getIp(), beatInfo.getPort());
BeatInfo existBeat = null;
//fix #1733
if ((existBeat = dom2Beat.remove(key)) != null) {
existBeat.setStopped(true);
}
dom2Beat.put(key, beatInfo);
//通过线程池进行异步心跳发送
executorService.schedule(new BeatTask(beatInfo), beatInfo.getPeriod(), TimeUnit.MILLISECONDS);
MetricsMonitor.getDom2BeatSizeMonitor().set(dom2Beat.size());
}
可以看到,心跳是通过线程池异步发送的,我们进入BeatTask,找到run方法,一路向下跟代码,流程如下图:
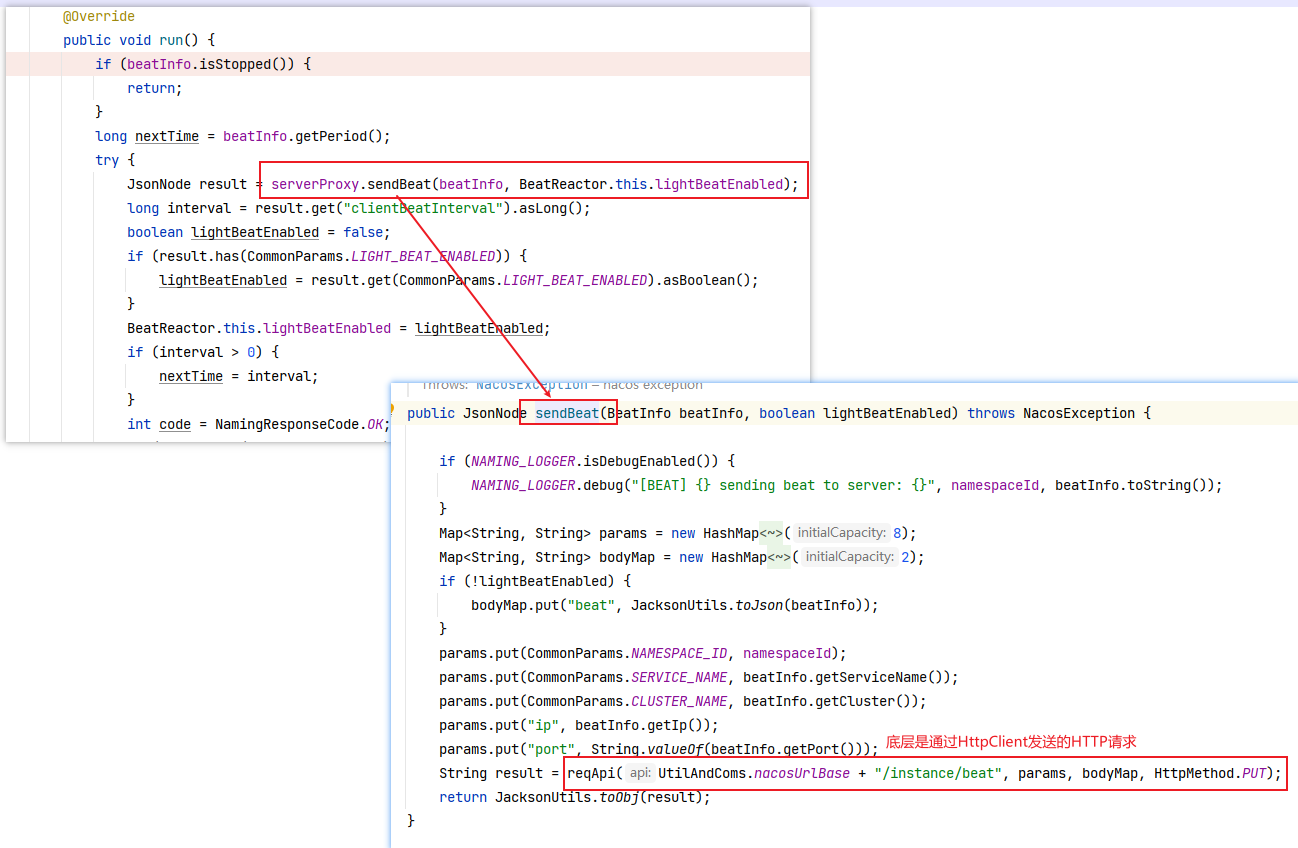
最后会发现会发送一个HTTP请求,将心跳信息发送到服务端。这个reqApi是nacos封装的方法,底层是封装了一个HttpClient发送了一个HTTP请求(这部分源码略,感兴趣可以自己debug去跟一下)。
nacos的NacosRestTemplate的最底层是使用jdk的进行的封装:

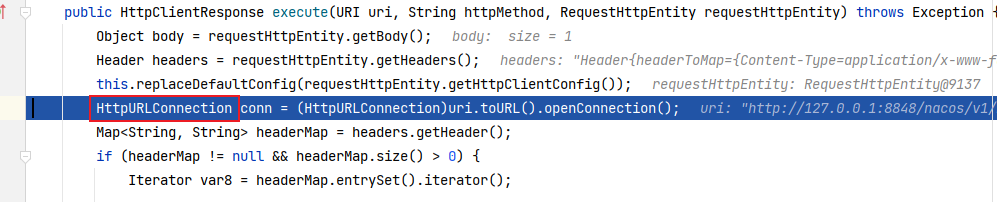
然后我们再看服务注册的部分:
我们跟进serverProxy.registerService(groupedServiceName, groupName, instance);方法,会发现注册也是通过HTTP请求将相关信息发送给服务端进行注册(接口地址/nacos/v1/ns/instance)。
public void registerService(String serviceName, String groupName, Instance instance) throws NacosException {
NAMING_LOGGER.info("[REGISTER-SERVICE] {} registering service {} with instance: {}", namespaceId, serviceName,
instance);
final Map<String, String> params = new HashMap<String, String>(16);
params.put(CommonParams.NAMESPACE_ID, namespaceId);
params.put(CommonParams.SERVICE_NAME, serviceName);
params.put(CommonParams.GROUP_NAME, groupName);
params.put(CommonParams.CLUSTER_NAME, instance.getClusterName());
params.put("ip", instance.getIp());
params.put("port", String.valueOf(instance.getPort()));
params.put("weight", String.valueOf(instance.getWeight()));
params.put("enable", String.valueOf(instance.isEnabled()));
params.put("healthy", String.valueOf(instance.isHealthy()));
params.put("ephemeral", String.valueOf(instance.isEphemeral()));
params.put("metadata", JacksonUtils.toJson(instance.getMetadata()));
//通过POST请求,进行注册
reqApi(UtilAndComs.nacosUrlInstance, params, HttpMethod.POST);
}
5.4.4 服务端服务注册流程
上面我们知道了客户端服务注册时会分别发送心跳和注册请求,我们在nacos源码中找到这两个接口,这两个接口在nacos-naming模块下的InstanceController下,我们来看一下这两个方法,源码如下:
@CanDistro
@PostMapping
@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)
//处理服务注册
public String register(HttpServletRequest request) throws Exception {
//获取服务名,命名空间
final String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
final String namespaceId = WebUtils
.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
//获取实例
final Instance instance = parseInstance(request);
//注册实例
serviceManager.registerInstance(namespaceId, serviceName, instance);
return "ok";
}
@CanDistro
@PutMapping("/beat")
@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)
//处理心跳请求
public ObjectNode beat(HttpServletRequest request) throws Exception {
ObjectNode result = JacksonUtils.createEmptyJsonNode();
result.put(SwitchEntry.CLIENT_BEAT_INTERVAL, switchDomain.getClientBeatInterval());
//获取请求信息,集群名称服务名称等等
String beat = WebUtils.optional(request, "beat", StringUtils.EMPTY);
RsInfo clientBeat = null;
if (StringUtils.isNotBlank(beat)) {
clientBeat = JacksonUtils.toObj(beat, RsInfo.class);
}
String clusterName = WebUtils
.optional(request, CommonParams.CLUSTER_NAME, UtilsAndCommons.DEFAULT_CLUSTER_NAME);
String ip = WebUtils.optional(request, "ip", StringUtils.EMPTY);
int port = Integer.parseInt(WebUtils.optional(request, "port", "0"));
if (clientBeat != null) {
if (StringUtils.isNotBlank(clientBeat.getCluster())) {
clusterName = clientBeat.getCluster();
} else {
// fix #2533
clientBeat.setCluster(clusterName);
}
ip = clientBeat.getIp();
port = clientBeat.getPort();
}
String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
String namespaceId = WebUtils.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
Loggers.SRV_LOG.debug("[CLIENT-BEAT] full arguments: beat: {}, serviceName: {}", clientBeat, serviceName);
//获取客户端注册的服务实例
Instance instance = serviceManager.getInstance(namespaceId, serviceName, clusterName, ip, port);
//如果还未注册就进行注册
if (instance == null) {
if (clientBeat == null) {
result.put(CommonParams.CODE, NamingResponseCode.RESOURCE_NOT_FOUND);
return result;
}
Loggers.SRV_LOG.warn("[CLIENT-BEAT] The instance has been removed for health mechanism, "
+ "perform data compensation operations, beat: {}, serviceName: {}", clientBeat, serviceName);
//设置实例信息
instance = new Instance();
instance.setPort(clientBeat.getPort());
instance.setIp(clientBeat.getIp());
instance.setWeight(clientBeat.getWeight());
instance.setMetadata(clientBeat.getMetadata());
instance.setClusterName(clusterName);
instance.setServiceName(serviceName);
instance.setInstanceId(instance.getInstanceId());
instance.setEphemeral(clientBeat.isEphemeral());
//完成实例注册
serviceManager.registerInstance(namespaceId, serviceName, instance);
}
//获取服务
Service service = serviceManager.getService(namespaceId, serviceName);
if (service == null) {
throw new NacosException(NacosException.SERVER_ERROR,
"service not found: " + serviceName + "@" + namespaceId);
}
if (clientBeat == null) {
clientBeat = new RsInfo();
clientBeat.setIp(ip);
clientBeat.setPort(port);
clientBeat.setCluster(clusterName);
}
//处理客户端心跳,主要是设置心跳时间和健康状态
service.processClientBeat(clientBeat);
result.put(CommonParams.CODE, NamingResponseCode.OK);
if (instance.containsMetadata(PreservedMetadataKeys.HEART_BEAT_INTERVAL)) {
result.put(SwitchEntry.CLIENT_BEAT_INTERVAL, instance.getInstanceHeartBeatInterval());
}
result.put(SwitchEntry.LIGHT_BEAT_ENABLED, switchDomain.isLightBeatEnabled());
return result;
}
从这两个方法我们可以看到,发送心跳请求时如果服务还没有注册就会进行服务注册,也就是说客户端发送的两个方法都会进行服务注册。
然后我们在跟进注册方法之前,先看一下上面代码中的处理客户端心跳的部分
service.processClientBeat(clientBeat);,这部分代码流程如下图,此方法主要是设置心跳时间和健康状态:
那么这个方法的作用就是重置心跳时间,跟后面心跳超时检测做配合
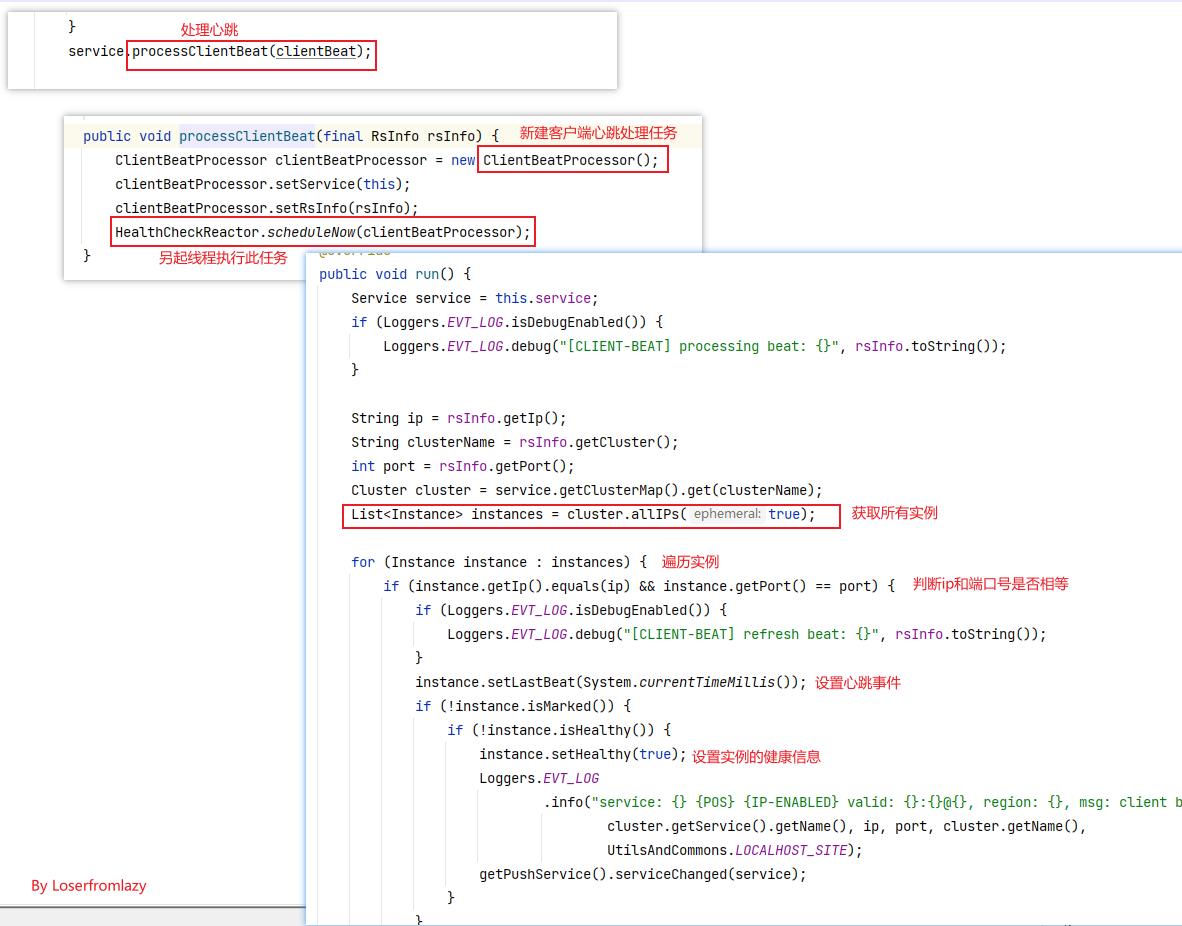
我们跟进注册方法serviceManager.registerInstance(namespaceId, serviceName, instance);在这个方法我们可以加上断点,然后debug启动nacos源码工程,然后随便起一个客户端注册到我们nacos源码工程上就可以debug调试服务端的服务注册的流程了,如下图:
createEmptyService
我们先跟进createEmptyService方法,
//这里serviceName服务名称=分组名称+微服务服务名
public void createEmptyService(String namespaceId, String serviceName, boolean local) throws NacosException {
createServiceIfAbsent(namespaceId, serviceName, local, null);
}
public void createServiceIfAbsent(String namespaceId, String serviceName, boolean local, Cluster cluster) throws NacosException {
//获取服务,如果服务为空就创建服务
Service service = getService(namespaceId, serviceName);
if (service == null) {
Loggers.SRV_LOG.info("creating empty service {}:{}", namespaceId, serviceName);
service = new Service();
service.setName(serviceName);
service.setNamespaceId(namespaceId);
service.setGroupName(NamingUtils.getGroupName(serviceName));
// now validate the service. if failed, exception will be thrown
service.setLastModifiedMillis(System.currentTimeMillis());
service.recalculateChecksum();
if (cluster != null) {
cluster.setService(service);
service.getClusterMap().put(cluster.getName(), cluster);
}
service.validate();
//存储服务及初始化
putServiceAndInit(service);
if (!local) {
addOrReplaceService(service);
}
}
}
在这个方法中,会先获取服务,如果服务为空就创建服务,然后调用putServiceAndInit(service);进行新增服务和心跳初始化,我们进入此方法:
private void putServiceAndInit(Service service) throws NacosException {
//添加服务
putService(service);
//服务初始化
service.init();
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), true), service);
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), false), service);
Loggers.SRV_LOG.info("[NEW-SERVICE] {}", service.toJson());
}
到这里service相关属性如下:
上面方法中的添加服务putService(service);方法十分简单,本质就是将服务存储到一个Map中:
public void putService(Service service) {
if (!serviceMap.containsKey(service.getNamespaceId())) {
synchronized (putServiceLock) {
if (!serviceMap.containsKey(service.getNamespaceId())) {
serviceMap.put(service.getNamespaceId(), new ConcurrentHashMap<>(16));
}
}
}
//以service.getName()作为Key进行存储
serviceMap.get(service.getNamespaceId()).put(service.getName(), service);
}
serviceMap的结构是这样的:
Map(namespace, Map(group::serviceName, Service))
然后我们看一下服务初始化service.init();这个方法,这个方法启动了一个线程执行了客户端心跳检测任务
public void init() {
//启动一个线程执行clientBeatCheckTask
HealthCheckReactor.scheduleCheck(clientBeatCheckTask);
for (Map.Entry<String, Cluster> entry : clusterMap.entrySet()) {
entry.getValue().setService(this);
entry.getValue().init();
}
}
我们可以进入到这个任务类中,然后在run方法中打上断点,run方法源码如下:
@Override
public void run() {
try {
if (!getDistroMapper().responsible(service.getName())) {
return;
}
if (!getSwitchDomain().isHealthCheckEnabled()) {
return;
}
//获取所有的实例
List<Instance> instances = service.allIPs(true);
//遍历所有实例检测心跳是否超时(默认15s)
// first set health status of instances:
for (Instance instance : instances) {
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getInstanceHeartBeatTimeOut()) {
if (!instance.isMarked()) {
if (instance.isHealthy()) {
//如果超时就设置实例不健康
instance.setHealthy(false);
Loggers.EVT_LOG
.info("{POS} {IP-DISABLED} valid: {}:{}@{}@{}, region: {}, msg: client timeout after {}, last beat: {}",
instance.getIp(), instance.getPort(), instance.getClusterName(),
service.getName(), UtilsAndCommons.LOCALHOST_SITE,
instance.getInstanceHeartBeatTimeOut(), instance.getLastBeat());
getPushService().serviceChanged(service);
ApplicationUtils.publishEvent(new InstanceHeartbeatTimeoutEvent(this, instance));
}
}
}
}
if (!getGlobalConfig().isExpireInstance()) {
return;
}
//遍历所有实例
// then remove obsolete instances:
for (Instance instance : instances) {
if (instance.isMarked()) {
continue;
}
//如果实例超时过长(这里默认30s)就删除实例
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getIpDeleteTimeout()) {
// delete instance
Loggers.SRV_LOG.info("[AUTO-DELETE-IP] service: {}, ip: {}", service.getName(),
JacksonUtils.toJson(instance));
deleteIp(instance);
}
}
} catch (Exception e) {
Loggers.SRV_LOG.warn("Exception while processing client beat time out.", e);
}
}
这里主要对所有服务的心跳进行检测,超时15s就设置为不健康,超时30s就删除该实例。
createEmptyService到此就结束了,然后我们回到ServiceManager#registerInstance这个方法:
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException {
//创建服务,并初始化心跳检测
createEmptyService(namespaceId, serviceName, instance.isEphemeral());
//获取服务
Service service = getService(namespaceId, serviceName);
if (service == null) {
throw new NacosException(NacosException.INVALID_PARAM,
"service not found, namespace: " + namespaceId + ", service: " + serviceName);
}
//新增实例
addInstance(namespaceId, serviceName, instance.isEphemeral(), instance);
}
addInstance
然后我们跟进addInstance方法:
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips)throws NacosException {
//生成key
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
//获取服务
Service service = getService(namespaceId, serviceName);
//对service上锁,锁住当前注册的服务
synchronized (service) {
//比较并获得新的实例列表
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
Instances instances = new Instances();
instances.setInstanceList(instanceList);
//存储实例
consistencyService.put(key, instances);
}
}
这里key大概可以看成命名空间+服务名称
我们debug跟进consistencyService.put(key, instances);方法,它会进入到DistroConsistencyServiceImpl#put方法中,在跟进其中的onPut方法:
public void onPut(String key, Record value) {
if (KeyBuilder.matchEphemeralInstanceListKey(key)) {
Datum<Instances> datum = new Datum<>();
datum.value = (Instances) value;
datum.key = key;
datum.timestamp.incrementAndGet();
//将实例存入dataStore中
dataStore.put(key, datum);
}
//其余代码略。。。
}
public class DataStore { private Map<String, Datum> dataMap = new ConcurrentHashMap<>(1024); public void put(String key, Datum value) { dataMap.put(key, value); } //其余代码略 }
也就是说服务注册最终会将实例信息存入DataStore中,到此服务端服务注册流程完。
5.4.5 客户端服务发现流程
这部分涉及到Spring Cloud远程调用的相关原理,可以先看我的Spring Cloud远程调用笔记。
定时拉取服务列表
我们编写一个测试用的接口,这里我们先简单使用discoveryClient进行服务发现:
@GetMapping("/testServiceFind")
public Integer testServiceFind(){
/*1.从Nacos Server中获取关注的那个服务的实例信息即服务发现*/
List<ServiceInstance> user = discoveryClient.getInstances("user");
/*2.如果有多个实例选择一个来使用(负载均衡)*/
ServiceInstance serviceInstance = user.get(0);
/*3.从元数据信息获取host port*/
String host = serviceInstance.getHost();
int port = serviceInstance.getPort();
String url = "http://"+host+":"+port+"/user/findUserById";
System.out.println("############URL##########:"+url);
return 111;
}
我们在getInstances方法上打上断点,然后请求方法并跟进代码。请求链路如下:
CompositeDiscoveryClient#getInstances
-->NacosDiscoveryClient#getInstances
-->NacosServiceDiscovery#getInstances
然后我们来看NacosServiceDiscovery#getInstances方法:
public List<ServiceInstance> getInstances(String serviceId) throws NacosException {
String group = discoveryProperties.getGroup();
//调用命名服务选取实例,这里可以看到订阅模式默认为true
List<Instance> instances = namingService.selectInstances(serviceId, group, true);
return hostToServiceInstanceList(instances, serviceId);
}
然后我们跟进selectInstances方法,最后会来到NacosNamingService#selectInstances():
@Override
public List<Instance> selectInstances(String serviceName, String groupName, List<String> clusters, boolean healthy,
boolean subscribe) throws NacosException {
ServiceInfo serviceInfo;
//这个subscribe表示是否是订阅模式,默认为true,即默认为订阅模式
if (subscribe) {
//获取服务信息
serviceInfo = hostReactor.getServiceInfo(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
} else {
//直接从服务端获取信息
serviceInfo = hostReactor
.getServiceInfoDirectlyFromServer(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
}
//将serviceInfo转换成实例数组,并去除不健康的、未启用的以及权重小于等于0的
return selectInstances(serviceInfo, healthy);
}
然后我们跟进hostReactor.getServiceInfo:
public ServiceInfo getServiceInfo(final String serviceName, final String clusters) {
NAMING_LOGGER.debug("failover-mode: " + failoverReactor.isFailoverSwitch());
String key = ServiceInfo.getKey(serviceName, clusters);
if (failoverReactor.isFailoverSwitch()) {
return failoverReactor.getService(key);
}
//获取本地缓存的服务信息
ServiceInfo serviceObj = getServiceInfo0(serviceName, clusters);
//如果为空再去服务端获取服务信息
if (null == serviceObj) {
serviceObj = new ServiceInfo(serviceName, clusters);
serviceInfoMap.put(serviceObj.getKey(), serviceObj);
updatingMap.put(serviceName, new Object());
//更新服务列表
updateServiceNow(serviceName, clusters);
updatingMap.remove(serviceName);
} else if (updatingMap.containsKey(serviceName)) {
if (UPDATE_HOLD_INTERVAL > 0) {
// hold a moment waiting for update finish
synchronized (serviceObj) {
try {
serviceObj.wait(UPDATE_HOLD_INTERVAL);
} catch (InterruptedException e) {
NAMING_LOGGER
.error("[getServiceInfo] serviceName:" + serviceName + ", clusters:" + clusters, e);
}
}
}
}
//如果没有更新定时任务就创建一个
scheduleUpdateIfAbsent(serviceName, clusters);
return serviceInfoMap.get(serviceObj.getKey());
}
在上面这段源码中,有三个关键点:
-
getServiceInfo0(serviceName, clusters);
我们跟进去可以发现,nacos首先会从本地缓存获取服务信息
private ServiceInfo getServiceInfo0(String serviceName, String clusters) { String key = ServiceInfo.getKey(serviceName, clusters); return serviceInfoMap.get(key); } -
updateServiceNow(serviceName, clusters);
此方法的含义是更新服务列表,我们跟进此方法:
public void updateServiceNow(String serviceName, String clusters) { ServiceInfo oldService = getServiceInfo0(serviceName, clusters); try { //获取服务列表 String result = serverProxy.queryList(serviceName, clusters, pushReceiver.getUdpPort(), false); if (StringUtils.isNotEmpty(result)) { //解析返回结果,更新serviceInfoMap processServiceJson(result); } } catch (Exception e) { NAMING_LOGGER.error("[NA] failed to update serviceName: " + serviceName, e); } finally { if (oldService != null) { synchronized (oldService) { oldService.notifyAll(); } } } }其中,获取服务列表方法源码如下:
public String queryList(String serviceName, String clusters, int udpPort, boolean healthyOnly) throws NacosException { final Map<String, String> params = new HashMap<String, String>(8); params.put(CommonParams.NAMESPACE_ID, namespaceId); params.put(CommonParams.SERVICE_NAME, serviceName); params.put("clusters", clusters); params.put("udpPort", String.valueOf(udpPort)); params.put("clientIP", NetUtils.localIP()); params.put("healthyOnly", String.valueOf(healthyOnly)); //向nacos服务端发送请求,获取服务列表 return reqApi(UtilAndComs.nacosUrlBase + "/instance/list", params, HttpMethod.GET); } -
scheduleUpdateIfAbsent(serviceName, clusters);
这个方法主要作用是如果没有更新定时任务就创建一个服务定时查询更新的任务,源码如下:
//private final Map<String, ScheduledFuture<?>> futureMap = new HashMap<String, ScheduledFuture<?>>(); //futureMap 是一个缓存 map,其 key 为 groupId@@微服务名称@@clusters,value 是一个定时异步操作对象ScheduledFuture public void scheduleUpdateIfAbsent(String serviceName, String clusters) { if (futureMap.get(ServiceInfo.getKey(serviceName, clusters)) != null) { return; } synchronized (futureMap) { if (futureMap.get(ServiceInfo.getKey(serviceName, clusters)) != null) { return; } //新增一个UpdateTask任务并延时启动 ScheduledFuture<?> future = addTask(new UpdateTask(serviceName, clusters)); futureMap.put(ServiceInfo.getKey(serviceName, clusters), future); } } public synchronized ScheduledFuture<?> addTask(UpdateTask task) { //延时一秒启动 return executor.schedule(task, DEFAULT_DELAY, TimeUnit.MILLISECONDS); }下面我们来看一下这个updateTask都干了什么,其源码如下
public class UpdateTask implements Runnable { //省略部分代码 @Override public void run() { long delayTime = -1; try { //本地缓存获取服务 ServiceInfo serviceObj = serviceInfoMap.get(ServiceInfo.getKey(serviceName, clusters)); //如果本地缓存没有则立即更新本地缓存 if (serviceObj == null) { updateServiceNow(serviceName, clusters); delayTime = DEFAULT_DELAY; return; } //如果服务的最新更新时间小于等于缓存刷新(最后一次拉取数据的时间)时间,从服务端重新查询 if (serviceObj.getLastRefTime() <= lastRefTime) { updateServiceNow(serviceName, clusters); serviceObj = serviceInfoMap.get(ServiceInfo.getKey(serviceName, clusters)); } else { // if serviceName already updated by push, we should not override it // since the push data may be different from pull through force push refreshOnly(serviceName, clusters); } //设置缓存刷新时间 lastRefTime = serviceObj.getLastRefTime(); if (!eventDispatcher.isSubscribed(serviceName, clusters) && !futureMap .containsKey(ServiceInfo.getKey(serviceName, clusters))) { // abort the update task NAMING_LOGGER.info("update task is stopped, service:" + serviceName + ", clusters:" + clusters); return; } //获取延时时间 delayTime = serviceObj.getCacheMillis(); } catch (Throwable e) { NAMING_LOGGER.warn("[NA] failed to update serviceName: " + serviceName, e); } finally { if (delayTime > 0) { //延时执行,一般是10s,该时间是由服务端传回来的 executor.schedule(this, delayTime, TimeUnit.MILLISECONDS); } } } }
综上,我们简单了解一下nacos客户端服务发现的总体流程,也知道了nacos会本地维护一个服务列表缓存并进行定时更新,从而达到服务发现的目的。
Nacos结合Ribbon定时拉取服务列表
但是我们在开发中其实主要使用的是Feign接口进行远程调用而不是手动获取服务列表进行负载均衡,那么nacos是如何与Feign+Ribbon结合维护本地服务列表缓存的呢?
基于对Feign+Ribbon的了解(详见我的Spring远程调用笔记),我们直到ribbon是在这里进行服务实例的更新的。因此我们打上断点,如下图:
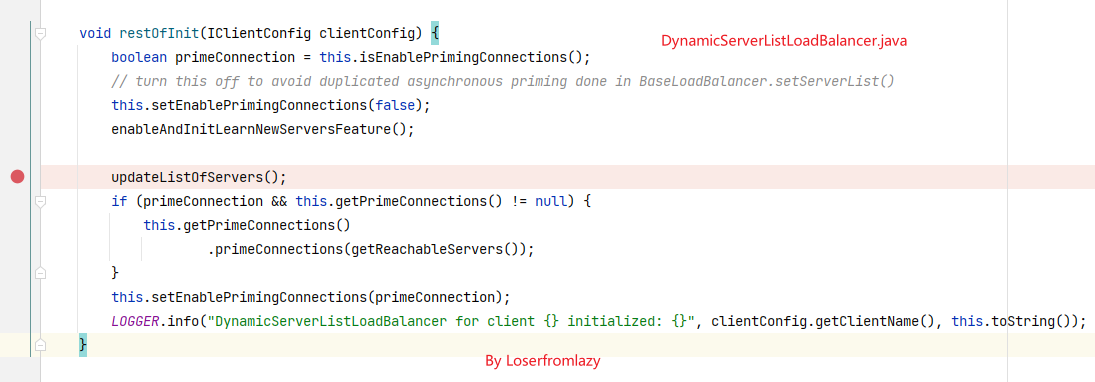
这里需要先了解Feign+Ribbon+Hystrix/Sentinel的整体工作流程,具体介绍本笔记中略,可以去看我的Spring Cloud远程调用笔记。
Spring Cloud远程调用笔记中其实也介绍了nacos或eureka实现了ribbon的ServerList接口,因此Ribbon定时更新服务列表时,本质上是走的nacos的方法进行的数据维护。
然后我们跟进去:
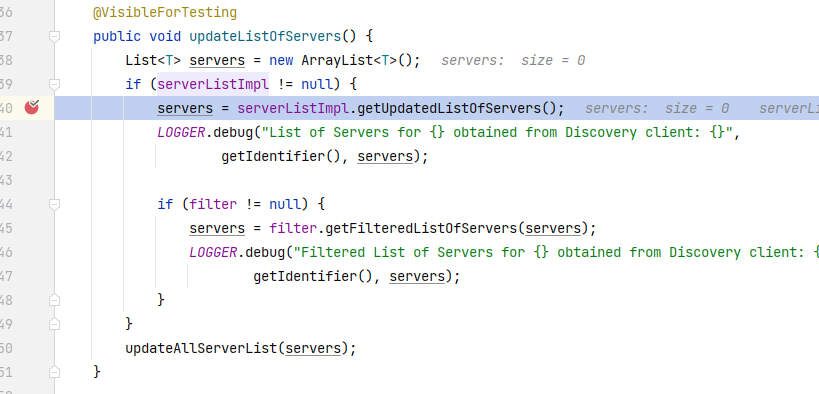
在这个方法中我们继续跟进,会走到NacosServerList#getUpdatedListOfServers方法:
@Override
public List<NacosServer> getUpdatedListOfServers() {
return getServers();
}
private List<NacosServer> getServers() {
try {
String group = discoveryProperties.getGroup();
//先获取NamingService,然后调用selectInstances方法
List<Instance> instances = nacosServiceManager
.getNamingService(discoveryProperties.getNacosProperties())
.selectInstances(serviceId, group, true);
return instancesToServerList(instances);
}
catch (Exception e) {
throw new IllegalStateException(
"Can not get service instances from nacos, serviceId=" + serviceId,
e);
}
}
上面源码中的selectInstances方法我们很熟悉,我们前面已经介绍过了,因此到这里我们已经了解了,ribbon的服务实例的更新本质上是调用的nacos的方法,而nacos在订阅模式下,会先在本地缓存中进行查询。因此,可以简单地理解为ribbon是通过同步nacos的服务实例进行的服务实例数据的维护。
我们可以简单的这么理解,但是实际上的流程我们上面已经了解过了,这里就不再赘述。
订阅自身的服务列表
接下来我们看一下NacosWatch。请不要觉得突兀,其实在上面5.4.2中,在介绍配置类NacosDiscoveryClientConfiguration时,就介绍了默认这个类是注入的。这个类的作用其实主要是拉取自己的服务列表。我们下面来看一下:

此类继承了SmartLifecycle接口和ApplicationEventPublisherAware接口,我们这里重点关注以下start和stop方法:
@Override
public void start() {
//CAS保证方法只执行一次
if (this.running.compareAndSet(false, true)) {
//新建监听器监听NamingEvent事件
EventListener eventListener = listenerMap.computeIfAbsent(buildKey(),
event -> new EventListener() {
@Override
public void onEvent(Event event) {
if (event instanceof NamingEvent) {
List<Instance> instances = ((NamingEvent) event)
.getInstances();
Optional<Instance> instanceOptional = selectCurrentInstance(
instances);
//更新当前实例的元数据
instanceOptional.ifPresent(currentInstance -> {
resetIfNeeded(currentInstance);
});
//发布心跳事件
publisher.publishEvent(new HeartbeatEvent(NacosWatch.this,
nacosWatchIndex.getAndIncrement()));
}
}
});
//获取NamingService并进行订阅
NamingService namingService = nacosServiceManager
.getNamingService(properties.getNacosProperties());
try {
//订阅当前服务
namingService.subscribe(properties.getService(), properties.getGroup(),
Arrays.asList(properties.getClusterName()), eventListener);
}
catch (Exception e) {
log.error("namingService subscribe failed, properties:{}", properties, e);
}
}
}
@Override
public void stop() {
if (this.running.compareAndSet(true, false)) {
EventListener eventListener = listenerMap.get(buildKey());
NamingService namingService = nacosServiceManager
.getNamingService(properties.getNacosProperties());
try {
//取消订阅
namingService.unsubscribe(properties.getService(), properties.getGroup(),
Arrays.asList(properties.getClusterName()), eventListener);
}
catch (NacosException e) {
log.error("namingService unsubscribe failed, properties:{}", properties,
e);
}
}
}
在start方法中会调用namingService.subscribe方法,我们下面来看一下此方法:
//NacosNamingService#subscribe(...)
@Override
public void subscribe(String serviceName, String groupName, List<String> clusters, EventListener listener)
throws NacosException {
eventDispatcher.addListener(hostReactor
.getServiceInfo(NamingUtils.getGroupedName(serviceName, groupName), StringUtils.join(clusters, ",")),
StringUtils.join(clusters, ","), listener);
}
此方法会调用hostReactor#getServiceInfo方法,然后加入到事件分发器eventDispatcher中。其中getServiceInfo方法我们已经很熟悉了。因此我们可以知道,在服务启动时,nacos会查询并维护一份自己服务名的本地服务实例缓存。
处理服务变更通知
本小节建议看完下一章节5.4.6后再回来看
那么在服务端发送变更通知后,客户端是如何接收处理呢?在HostReactor类中有一个Field即PushReceiver,这个类负责udp的接受处理。
public HostReactor(EventDispatcher eventDispatcher, NamingProxy serverProxy, BeatReactor beatReactor,
String cacheDir, boolean loadCacheAtStart, int pollingThreadCount) {
//。。。略
this.pushReceiver = new PushReceiver(this);
}
我们看一下PushReceiver类的构造函数,在构造函数中创建了线程池和udp客户端并执行了自己的线程任务:
public PushReceiver(HostReactor hostReactor) {
try {
this.hostReactor = hostReactor;
//创建UDP客户端
this.udpSocket = new DatagramSocket();
//新建线程池
this.executorService = new ScheduledThreadPoolExecutor(1, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
thread.setName("com.alibaba.nacos.naming.push.receiver");
return thread;
}
});
//开启线程任务
this.executorService.execute(this);
} catch (Exception e) {
NAMING_LOGGER.error("[NA] init udp socket failed", e);
}
}
因为PushReceiver类本身也继承的Runnable接口,所以我们看一下run方法:
@Override
public void run() {
while (!closed) {
try {
// byte[] is initialized with 0 full filled by default
byte[] buffer = new byte[UDP_MSS];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
//udp接收数据
udpSocket.receive(packet);
//将数据解析为json字符串
String json = new String(IoUtils.tryDecompress(packet.getData()), UTF_8).trim();
NAMING_LOGGER.info("received push data: " + json + " from " + packet.getAddress().toString());
PushPacket pushPacket = JacksonUtils.toObj(json, PushPacket.class);
String ack;
if ("dom".equals(pushPacket.type) || "service".equals(pushPacket.type)) {
//将json字符串交给hostReactor处理,此方法processServiceJson的作用我们上面也了解了就是解析json字符串,更新本地服务缓存
hostReactor.processServiceJson(pushPacket.data);
// send ack to server
ack = "{\"type\": \"push-ack\"" + ", \"lastRefTime\":\"" + pushPacket.lastRefTime + "\", \"data\":"
+ "\"\"}";
} else if ("dump".equals(pushPacket.type)) {
// dump data to server
ack = "{\"type\": \"dump-ack\"" + ", \"lastRefTime\": \"" + pushPacket.lastRefTime + "\", \"data\":"
+ "\"" + StringUtils.escapeJavaScript(JacksonUtils.toJson(hostReactor.getServiceInfoMap()))
+ "\"}";
} else {
// do nothing send ack only
ack = "{\"type\": \"unknown-ack\"" + ", \"lastRefTime\":\"" + pushPacket.lastRefTime
+ "\", \"data\":" + "\"\"}";
}
//发送ack回执
udpSocket.send(new DatagramPacket(ack.getBytes(UTF_8), ack.getBytes(UTF_8).length,
packet.getSocketAddress()));
} catch (Exception e) {
NAMING_LOGGER.error("[NA] error while receiving push data", e);
}
}
}
5.4.6 服务端服务发现流程
处理拉去服务请求
上面我们已经了解了,nacos的服务发现最终是向/instance/list接口发送请求获取的服务实例,因此我们来到nacos服务端源码上,找到此方法,并加上断点,源码如下:
@GetMapping("/list")
@Secured(parser = NamingResourceParser.class, action = ActionTypes.READ)
public ObjectNode list(HttpServletRequest request) throws Exception {
//获取请求传过来的服务信息
String namespaceId = WebUtils.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
String agent = WebUtils.getUserAgent(request);
String clusters = WebUtils.optional(request, "clusters", StringUtils.EMPTY);
String clientIP = WebUtils.optional(request, "clientIP", StringUtils.EMPTY);
int udpPort = Integer.parseInt(WebUtils.optional(request, "udpPort", "0"));
String env = WebUtils.optional(request, "env", StringUtils.EMPTY);
boolean isCheck = Boolean.parseBoolean(WebUtils.optional(request, "isCheck", "false"));
String app = WebUtils.optional(request, "app", StringUtils.EMPTY);
String tenant = WebUtils.optional(request, "tid", StringUtils.EMPTY);
boolean healthyOnly = Boolean.parseBoolean(WebUtils.optional(request, "healthyOnly", "false"));
//
return doSrvIpxt(namespaceId, serviceName, agent, clusters, clientIP, udpPort, env, isCheck, app, tenant,
healthyOnly);
}
上面方法中我们主要跟进doSrvIpxt方法:
public ObjectNode doSrvIpxt(String namespaceId, String serviceName, String agent, String clusters, String clientIP,
int udpPort, String env, boolean isCheck, String app, String tid, boolean healthyOnly) throws Exception {
ClientInfo clientInfo = new ClientInfo(agent);
ObjectNode result = JacksonUtils.createEmptyJsonNode();
//从nacos的服务map中获取服务信息
Service service = serviceManager.getService(namespaceId, serviceName);
//如果服务为空就返回空
if (service == null) {
if (Loggers.SRV_LOG.isDebugEnabled()) {
Loggers.SRV_LOG.debug("no instance to serve for service: {}", serviceName);
}
result.put("name", serviceName);
result.put("clusters", clusters);
result.replace("hosts", JacksonUtils.createEmptyArrayNode());
return result;
}
checkIfDisabled(service);
long cacheMillis = switchDomain.getDefaultCacheMillis();
// now try to enable the push
//添加当前客户端 IP、UDP端口等信息到 PushService 中
try {
if (udpPort > 0 && pushService.canEnablePush(agent)) {
//此方法最终存入PushService的clientMap中
pushService
.addClient(namespaceId, serviceName, clusters, agent, new InetSocketAddress(clientIP, udpPort),
pushDataSource, tid, app);
cacheMillis = switchDomain.getPushCacheMillis(serviceName);
}
} catch (Exception e) {
Loggers.SRV_LOG
.error("[NACOS-API] failed to added push client {}, {}:{}", clientInfo, clientIP, udpPort, e);
cacheMillis = switchDomain.getDefaultCacheMillis();
}
//从service实例中基于srvIps得到 所有 服务提供者 信息
List<Instance> srvedIPs;
srvedIPs = service.srvIPs(Arrays.asList(StringUtils.split(clusters, ",")));
//省略结果的检测,异常实例的剔除等代码
//封装返回结果
result.replace("hosts", hosts);
if (clientInfo.type == ClientInfo.ClientType.JAVA
&& clientInfo.version.compareTo(VersionUtil.parseVersion("1.0.0")) >= 0) {
result.put("dom", serviceName);
} else {
result.put("dom", NamingUtils.getServiceName(serviceName));
}
result.put("name", serviceName);
result.put("cacheMillis", cacheMillis);
result.put("lastRefTime", System.currentTimeMillis());
result.put("checksum", service.getChecksum());
result.put("useSpecifiedURL", false);
result.put("clusters", clusters);
result.put("env", env);
result.replace("metadata", JacksonUtils.transferToJsonNode(service.getMetadata()));
return result;
}
我们可以看到在服务端服务发现的主要流程如下:
- 根据客户端请求的参数,从服务端中获取对应的服务信息(本质是从注册时存入的ServiceMap中获取)
- 然后将当前客户端的ip、udp端口等信息添加到 PushService 中
- 然后获取服务实例,并进行实例结果检测、异常实例剔除等操作。
- 最后封装返回结果,返回给nacos客户端。
服务变更通知
这里我们重点关注一下PushService ,它基于UDP的通信方式,主要功能就是用来辅助服务实例变化时对客户端进行通知,因为nacos除了客户端定时轮询,服务端在变化时也会向客户端进行推送,该推送是基于UDP的。
这个类借助了Spring的观察者模式(或者说是发布订阅模型)进行实现的。我们看一下源码:

首先,这个类继承了ApplicationListener,这是Spring的事件机制(是基于观察者模式的),因此我们主要关注它的onApplicationEvent方法:
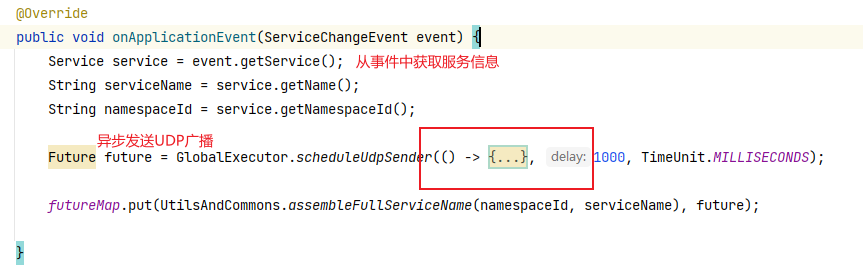
可以看到当发生服务变更事件时,PushService 会先获取服务信息然后向对应的客户端异步发送UDP广播进行通知,然后存入futureMap中。(futureMap中存放的都是已经发送了udp包的服务,如果已经发送过了,就不再发,可以减少发送的频率,节省资源。)。下面我们看一下异步操作(上图红框内)的具体代码:
Future future = GlobalExecutor.scheduleUdpSender(() -> {
try {
Loggers.PUSH.info(serviceName + " is changed, add it to push queue.");
//从clientMap取出udp客户端实例,该客户端是在doSrvIpxt方法中存入的
//也就是说客户端在获取服务实例时,会在服务端保存一个客户端信息用于udp推送
ConcurrentMap<String, PushClient> clients = clientMap
.get(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName));
if (MapUtils.isEmpty(clients)) {
return;
}
Map<String, Object> cache = new HashMap<>(16);
long lastRefTime = System.nanoTime();
for (PushClient client : clients.values()) {
if (client.zombie()) {
Loggers.PUSH.debug("client is zombie: " + client.toString());
clients.remove(client.toString());
Loggers.PUSH.debug("client is zombie: " + client.toString());
continue;
}
Receiver.AckEntry ackEntry;
Loggers.PUSH.debug("push serviceName: {} to client: {}", serviceName, client.toString());
String key = getPushCacheKey(serviceName, client.getIp(), client.getAgent());
byte[] compressData = null;
Map<String, Object> data = null;
//switchDomain.getDefaultPushCacheMillis()默认是10s,因此不会进入此分支
//因此compressData为空会进入到下一个分支
if (switchDomain.getDefaultPushCacheMillis() >= 20000 && cache.containsKey(key)) {
org.javatuples.Pair pair = (org.javatuples.Pair) cache.get(key);
compressData = (byte[]) (pair.getValue0());
data = (Map<String, Object>) pair.getValue1();
Loggers.PUSH.debug("[PUSH-CACHE] cache hit: {}:{}", serviceName, client.getAddrStr());
}
if (compressData != null) {
ackEntry = prepareAckEntry(client, compressData, data, lastRefTime);
} else {
//compressData为空,默认会进入此分支,这里方法源码略,感兴趣可自行查看,主要作用如下:
//这里的prepareHostsData方法最后还是会调用doSrvIpxt方法获取当前服务实例列表进行封装
//然后prepareAckEntry会将所有需要发送的信息进行封装,封装成ackEntry
ackEntry = prepareAckEntry(client, prepareHostsData(client), lastRefTime);
if (ackEntry != null) {
cache.put(key, new org.javatuples.Pair<>(ackEntry.origin.getData(), ackEntry.data));
}
}
Loggers.PUSH.info("serviceName: {} changed, schedule push for: {}, agent: {}, key: {}",
client.getServiceName(), client.getAddrStr(), client.getAgent(),
(ackEntry == null ? null : ackEntry.key));
//通过udp协议向nacos客户端推送数据
udpPush(ackEntry);
}
} catch (Exception e) {
Loggers.PUSH.error("[NACOS-PUSH] failed to push serviceName: {} to client, error: {}", serviceName, e);
} finally {
futureMap.remove(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName));
}
}, 1000, TimeUnit.MILLISECONDS);
以上就是服务端的服务变更通知部分的源码。nacos客户端在获取服务列表时,如果能订阅就会在服务端进行订阅,并存储在服务端的clientMap中,当服务端收到服务变更通知(基于Spring事件机制)后,会通过udp向所有订阅的客户端发送服务变更消息。当客户端收到消息后的操作就与5.4.5中的处理服务变更通知一节中的介绍相对应了。
5.4.7 Nacos服务发现总结
Nacos的服务发现分为两种模式:
- 轮询拉取模式:nacos客户端定期主动从Nacos服务端拉取服务列表并缓存起来,再服务调用时优先读取本地缓存中的服务列表。
- 订阅推送模式,nacos客户端订阅Nacos服务端中的服务列表,并基于UDP协议来接收服务变更通知。当Nacos中的服务列表更新时,会发送UDP广播给所有订阅者。
5.4.8 Nacos配置中心
客户端拉取配置中心配置
关于nacos的配置中心我们依旧从springboot自动装配入手,我们先来到spring-cloud-starter-alibaba-nacos-config下的spring.properties中。在里面有一个NacosConfigBootstrapConfiguration类,我们跟进去:
@Configuration(proxyBeanMethods = false)
@ConditionalOnProperty(name = "spring.cloud.nacos.config.enabled", matchIfMissing = true)
public class NacosConfigBootstrapConfiguration {
//nacos配置信息即Nacos配置文件的POJO
@Bean
@ConditionalOnMissingBean
public NacosConfigProperties nacosConfigProperties() {
return new NacosConfigProperties();
}
@Bean
@ConditionalOnMissingBean
public NacosConfigManager nacosConfigManager(
NacosConfigProperties nacosConfigProperties) {
return new NacosConfigManager(nacosConfigProperties);
}
//nacos属性源定位器
@Bean
public NacosPropertySourceLocator nacosPropertySourceLocator(
NacosConfigManager nacosConfigManager) {
return new NacosPropertySourceLocator(nacosConfigManager);
}
}
我们这里主要关注NacosPropertySourceLocator这个Bean。跟进方法发现此类实现了PropertySourceLocator接口,于是我们主要关注其locate方法:
PropertySourceLocator是一个Spring自定义配置接口,继承此接口spring会调用locate方法,获取自定义配置文件的配置信息,引导到上下文中。PropertySourceLocator让spring读取我们自定义的配置文件(注册到Spring Environment),然后使用@Value注解即可读取到配置文件中的属性,这解释了为什么Nacos等配置中心可以直接使用Value注解进行配置的读取。具体入口如下:
在SpringApplication.run方法中会调用prepareContext方法来准备上下文,这个方法中调用了applyInitializers方法来执行实现了ApplicationContextInitializer接口的类的initialize方法。其中包括PropertySourceBootstrapConfiguration#initialize。在initialize方法中会执行locate方法将PropertySource加载进来。这里显然NacosPropertySourceLocator的locate方法会被执行。
@Override
public PropertySource<?> locate(Environment env) {
//设置Spring上下文环境
nacosConfigProperties.setEnvironment(env);
//获取nacos的ConfigService
ConfigService configService = nacosConfigManager.getConfigService();
if (null == configService) {
log.warn("no instance of config service found, can't load config from nacos");
return null;
}
//获取超时时间(spring.cloud.nacos.config.timeout)
long timeout = nacosConfigProperties.getTimeout();
//新建一个NacosPropertySourceBuilder
nacosPropertySourceBuilder = new NacosPropertySourceBuilder(configService,
timeout);
//获取nacos配置dataId名称。(spring.cloud.nacos.config.name)
String name = nacosConfigProperties.getName();
String dataIdPrefix = nacosConfigProperties.getPrefix();
if (StringUtils.isEmpty(dataIdPrefix)) {
dataIdPrefix = name;
}
if (StringUtils.isEmpty(dataIdPrefix)) {
dataIdPrefix = env.getProperty("spring.application.name");
}
CompositePropertySource composite = new CompositePropertySource(
NACOS_PROPERTY_SOURCE_NAME);
//加载共享配置信息
loadSharedConfiguration(composite);
//加载扩展配置信息
loadExtConfiguration(composite);
//加载应用配置信息
loadApplicationConfiguration(composite, dataIdPrefix, nacosConfigProperties, env);
return composite;
}
private void loadSharedConfiguration(
CompositePropertySource compositePropertySource) {
//从配置文件中获取一组共享配置eg: spring.cloud.nacos.config.shared-configs[0]=xxx
List<NacosConfigProperties.Config> sharedConfigs = nacosConfigProperties
.getSharedConfigs();
if (!CollectionUtils.isEmpty(sharedConfigs)) {
checkConfiguration(sharedConfigs, "shared-configs");
//构建配置源并存储
loadNacosConfiguration(compositePropertySource, sharedConfigs);
}
}
private void loadExtConfiguration(CompositePropertySource compositePropertySource) {
//从配置文件中获取一组扩展配置eg: spring.cloud.nacos.config.extension-configs[0]=xxx
List<NacosConfigProperties.Config> extConfigs = nacosConfigProperties
.getExtensionConfigs();
if (!CollectionUtils.isEmpty(extConfigs)) {
checkConfiguration(extConfigs, "extension-configs");
//构建配置源并存储
loadNacosConfiguration(compositePropertySource, extConfigs);
}
}
//此方法本质上是调用loadNacosDataIfPresent
private void loadNacosConfiguration(final CompositePropertySource composite,
List<NacosConfigProperties.Config> configs) {
for (NacosConfigProperties.Config config : configs) {
String dataId = config.getDataId();
String fileExtension = dataId.substring(dataId.lastIndexOf(DOT) + 1);
loadNacosDataIfPresent(composite, dataId, config.getGroup(), fileExtension,
config.isRefresh());
}
}
private void loadApplicationConfiguration(
CompositePropertySource compositePropertySource, String dataIdPrefix,
NacosConfigProperties properties, Environment environment) {
//获取配置文件拓展名,官方注解:the suffix of nacos config dataId, also the file extension of config content.
String fileExtension = properties.getFileExtension();
//获取组
String nacosGroup = properties.getGroup();
// load directly once by default 直接根据默认值加载一次
loadNacosDataIfPresent(compositePropertySource, dataIdPrefix, nacosGroup,
fileExtension, true);
// load with suffix, which have a higher priority than the default
//带上后缀加载一次
loadNacosDataIfPresent(compositePropertySource,
dataIdPrefix + DOT + fileExtension, nacosGroup, fileExtension, true);
// Loaded with profile, which have a higher priority than the suffix
//对于所有活动的配置文件,使用文件名-配置文件后缀.文件类型 进行加载
for (String profile : environment.getActiveProfiles()) {
String dataId = dataIdPrefix + SEP1 + profile + DOT + fileExtension;
loadNacosDataIfPresent(compositePropertySource, dataId, nacosGroup,
fileExtension, true);
}
}
在locate方法中,主要是加载共享配置、扩展配置和应用配置信息(本质上是加载不同写法的配置文件信息),存入CompositePropertySource并返回此类。这里总结一下上面源码中方法的调用流程:
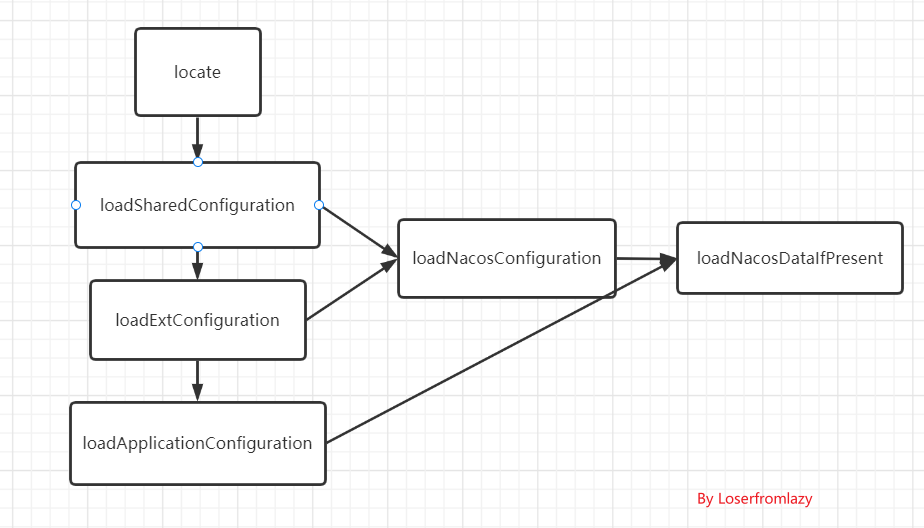
关于共享配置、扩展配置和应用配置信息:
Nacos-config的WIKI上有关于nacos配置介绍和demo案例。三种配置的写法如下:
共享配置:
扩展配置:
应用配置:
nacos这么设计的原因在其issue中也写明了,即:
- 从单个应用的角度来看: 应用可能会有多套(develop/beta/product)发布环境,多套发布环境之间有不同的基础配置,例如数据库。
- 从多个应用的角度来看:多个应用间可能会有一些共享通用的配置,比如多个应用之间共用一套zookeeper集群。
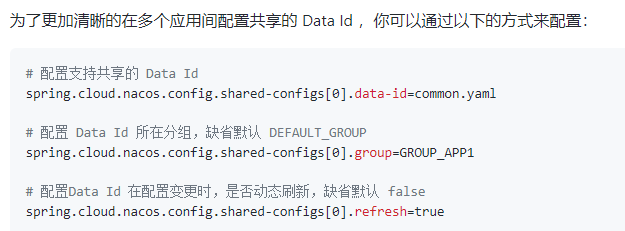


从上图中我们可以看到,不论是加载哪一类配置信息,最后都会走到loadNacosDataIfPresent方法中,因此我们跟入此方法:
//加载nacos数据
private void loadNacosDataIfPresent(final CompositePropertySource composite,
final String dataId, final String group, String fileExtension,
boolean isRefreshable) {
if (null == dataId || dataId.trim().length() < 1) {
return;
}
if (null == group || group.trim().length() < 1) {
return;
}
//创建NacosPropertySource
NacosPropertySource propertySource = this.loadNacosPropertySource(dataId, group,
fileExtension, isRefreshable);
//存入CompositePropertySource中第一个
this.addFirstPropertySource(composite, propertySource, false);
}
private NacosPropertySource loadNacosPropertySource(final String dataId,
final String group, String fileExtension, boolean isRefreshable) {
if (NacosContextRefresher.getRefreshCount() != 0) {
if (!isRefreshable) {
return NacosPropertySourceRepository.getNacosPropertySource(dataId,
group);
}
}
return nacosPropertySourceBuilder.build(dataId, group, fileExtension,
isRefreshable);
}
上面代码最后会调用NacosPropertySourceBuilder的build方法,关于如何从Config Server获取配置源的流程封装在此类中。NacosPropertySourceBuilder类是在locate方法中被创建的。
我们跟进build方法:
NacosPropertySource build(String dataId, String group, String fileExtension,
boolean isRefreshable) {
Map<String, Object> p = loadNacosData(dataId, group, fileExtension);
NacosPropertySource nacosPropertySource = new NacosPropertySource(group, dataId,
p, new Date(), isRefreshable);
NacosPropertySourceRepository.collectNacosPropertySource(nacosPropertySource);
return nacosPropertySource;
}
此方法主要是加载nacos数据并构建NacosPropertySource。这里我们继续跟进loadNacosData,此方法中会通过configService的getConfig方法获取配置,我们跟进getConfig方法:
@Override
public String getConfig(String dataId, String group, long timeoutMs) throws NacosException {
return getConfigInner(namespace, dataId, group, timeoutMs);
}
private String getConfigInner(String tenant, String dataId, String group, long timeoutMs) throws NacosException {
group = null2defaultGroup(group);
ParamUtils.checkKeyParam(dataId, group);
ConfigResponse cr = new ConfigResponse();
cr.setDataId(dataId);
cr.setTenant(tenant);
cr.setGroup(group);
// 优先使用本地配置
String content = LocalConfigInfoProcessor.getFailover(agent.getName(), dataId, group, tenant);
if (content != null) {
//日志代码略
cr.setContent(content);
configFilterChainManager.doFilter(null, cr);
content = cr.getContent();
return content;
}
try {
//从远程获取配置
String[] ct = worker.getServerConfig(dataId, group, tenant, timeoutMs);
cr.setContent(ct[0]);
configFilterChainManager.doFilter(null, cr);
content = cr.getContent();
return content;
} catch (NacosException ioe) {
if (NacosException.NO_RIGHT == ioe.getErrCode()) {
throw ioe;
}
//日志代码略
content = LocalConfigInfoProcessor.getSnapshot(agent.getName(), dataId, group, tenant);
cr.setContent(content);
configFilterChainManager.doFilter(null, cr);
content = cr.getContent();
return content;
}
此方法中会优先使用本地配置,当本地配置为空时,会通过ClientWorker#getServerConfig方法去获取。
public String[] getServerConfig(String dataId, String group, String tenant, long readTimeout)
throws NacosException {
String[] ct = new String[2];
if (StringUtils.isBlank(group)) {
group = Constants.DEFAULT_GROUP;
}
HttpRestResult<String> result = null;
try {
Map<String, String> params = new HashMap<String, String>(3);
//构造请求参数略
//请求地址Constants.CONFIG_CONTROLLER_PATH=/v1/cs/configs
result = agent.httpGet(Constants.CONFIG_CONTROLLER_PATH, null, params, agent.getEncode(), readTimeout);
} catch (Exception ex) {
//异常处理略
}
//根据请求返回值进行处理,处理过程略
switch (result.getCode()) {
case HttpURLConnection.HTTP_OK:
//。。。
case HttpURLConnection.HTTP_NOT_FOUND:
//。。。
case HttpURLConnection.HTTP_CONFLICT: {
//。。。
}
case HttpURLConnection.HTTP_FORBIDDEN: {
//。。。
}
}
}
此方法,最终会发送HTTP请求到nacos服务端,获取配置信息请求地址为/v1/cs/configs
综上,就是nacos客户端拉取配置的流程。
服务端处理拉取配置请求
根据上一节,获取配置信息请求地址为/v1/cs/configs,我们在服务端找到此处源码:
@GetMapping
@Secured(action = ActionTypes.READ, parser = ConfigResourceParser.class)
public void getConfig(HttpServletRequest request, HttpServletResponse response,
@RequestParam("dataId") String dataId, @RequestParam("group") String group,
@RequestParam(value = "tenant", required = false, defaultValue = StringUtils.EMPTY) String tenant,
@RequestParam(value = "tag", required = false) String tag)
throws IOException, ServletException, NacosException {
// check tenant
ParamUtils.checkTenant(tenant);
tenant = processTenant(tenant);
// check params
ParamUtils.checkParam(dataId, group, "datumId", "content");
ParamUtils.checkParam(tag);
final String clientIp = RequestUtil.getRemoteIp(request);
//获取服务端对应的配置信息
inner.doGetConfig(request, response, dataId, group, tenant, tag, clientIp);
}
这里我们主要关注doGetConfig方法,此方法有点长,我们重点关注以下几部分代码:
首先是tryConfigReadLock方法,此方法会从nacos的CACHE缓存中根据groupKey检查是否能获取当前配置的相关信息,然后尝试加锁,根据是否能成功获取、是否加锁成功返回不同的结果值,代码流程如下:
然后经过一系列检查(比如是否是Bate是否使用Tag等),判断是否是从数据库中读取(因为nacos有多种存储配置的方式),如果是就读数据库否则就读本地文件,代码如下:
最后nacos通过IO写回配置信息
以上就是服务端拉取配置的源码流程。
5.4.9 Nacos配置中心动态感知
Nacos Client长轮询
那么nacos的配置是如何实现动态感知的呢?我们还是从locate方法看起:
@Override
public PropertySource<?> locate(Environment env) {
nacosConfigProperties.setEnvironment(env);
ConfigService configService = nacosConfigManager.getConfigService();
//略
}
在locate方法中会获取一个ConfigService类,我们跟进getConfigService方法,以下是源码的调用过程:
public ConfigService getConfigService() {
if (Objects.isNull(service)) {
createConfigService(this.nacosConfigProperties);
}
return service;
}
//-------->NacosConfigManager#createConfigService
static ConfigService createConfigService(
NacosConfigProperties nacosConfigProperties) {
//其余代码略
service = NacosFactory.createConfigService(nacosConfigProperties.assembleConfigServiceProperties());
return service;
}
//-------->NacosFactory#createConfigService(...)
public static ConfigService createConfigService(Properties properties) throws NacosException {
return ConfigFactory.createConfigService(properties);
}
//-------->ConfigFactory#createConfigService(...)
public static ConfigService createConfigService(Properties properties) throws NacosException {
try {
//反射创建NacosConfigService
Class<?> driverImplClass = Class.forName("com.alibaba.nacos.client.config.NacosConfigService");
Constructor constructor = driverImplClass.getConstructor(Properties.class);
ConfigService vendorImpl = (ConfigService) constructor.newInstance(properties);
return vendorImpl;
} catch (Throwable e) {
throw new NacosException(NacosException.CLIENT_INVALID_PARAM, e);
}
}
从上面可知,最终会通过反射创建NacosConfigService,因此我们跟进此类,查看其构造函数:
public NacosConfigService(Properties properties) throws NacosException {
//其余代码略
//新建ClientWorker
this.worker = new ClientWorker(this.agent, this.configFilterChainManager, properties);
}
在NacosConfigService的构造函数中会新建ClientWorker类,我们跟进此类的构造方法中:
public ClientWorker(final HttpAgent agent, final ConfigFilterChainManager configFilterChainManager,
final Properties properties) {
this.agent = agent;
this.configFilterChainManager = configFilterChainManager;
// Initialize the timeout parameter
init(properties);
//构建executor和executorService线程池,代码略
//启动了定时任务
this.executor.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
checkConfigInfo();
} catch (Throwable e) {
LOGGER.error("[" + agent.getName() + "] [sub-check] rotate check error", e);
}
}
}, 1L, 10L, TimeUnit.MILLISECONDS);
}
我们发现,在ClientWorker的构造函数中启动了定时任务,于是我们应该关注此任务,此任务通过Runnable匿名内部类的方式实现,我们重点关注其中的checkConfigInfo()方法。
public void checkConfigInfo() {
// Dispatch taskes.
int listenerSize = cacheMap.get().size();
// Round up the longingTaskCount.
int longingTaskCount = (int) Math.ceil(listenerSize / ParamUtil.getPerTaskConfigSize());
if (longingTaskCount > currentLongingTaskCount) {
for (int i = (int) currentLongingTaskCount; i < longingTaskCount; i++) {
// The task list is no order.So it maybe has issues when changing.
executorService.execute(new LongPollingRunnable(i));
}
currentLongingTaskCount = longingTaskCount;
}
}
在这里我们可以看到此方法中会异步执行长轮询任务LongPollingRunnable。我们直接看它的run方法,由于run方法较长,这里就不全贴代码了,这里给出run方法中的关键部分代码:
首先是checkUpdateDataIds方法,这个方法就是和nacos服务端进行通信,看是否有数据发生改变,如果发生改变,返回的changedGroupKeys就是发生了变化的key值,此方法的源码流程如下图:
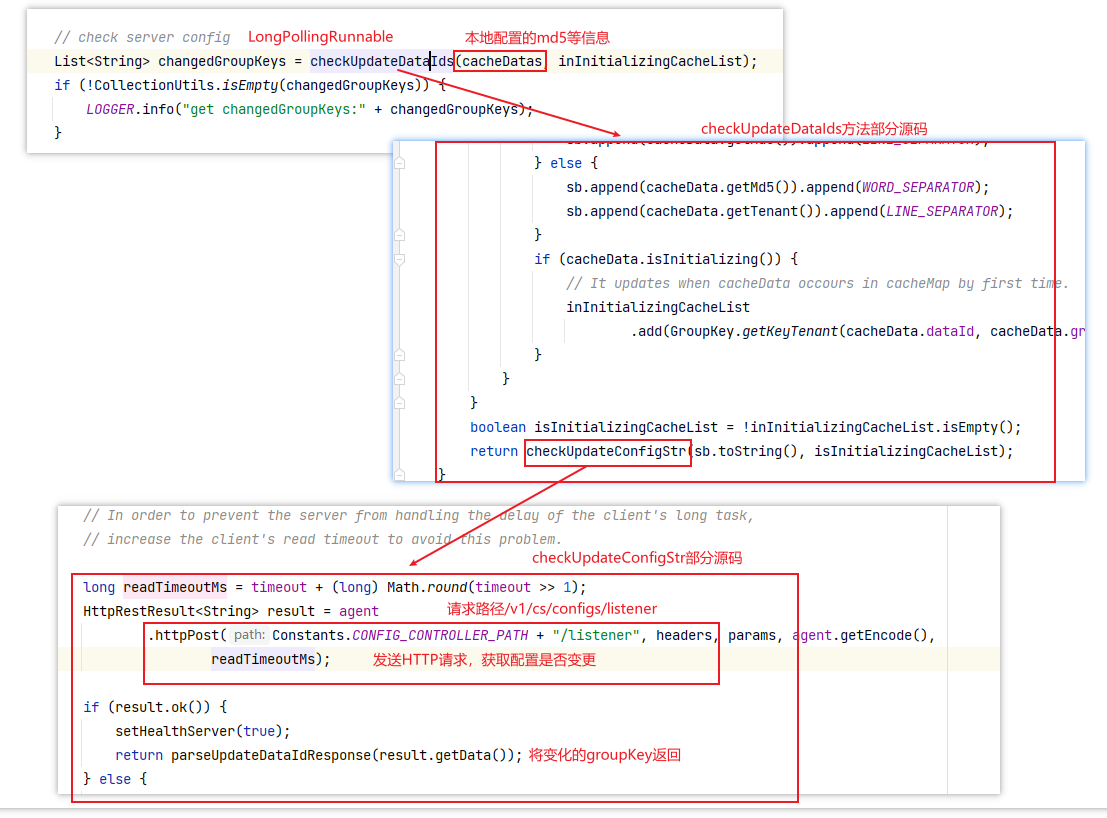
这里我们注意一下,这里是一个长轮询,这里参数中有超时时间。所谓长轮询,就是服务器接收到请求后,保持连接一段时间不返回消息,直到进行相关处理完毕后才返回响应信息并关闭连接,客户端接收到响应信息后,进行相关处理,处理完毕后再向服务器发送新的请求,长轮询流程如下(图片来自jsvascript.info/long-polling):
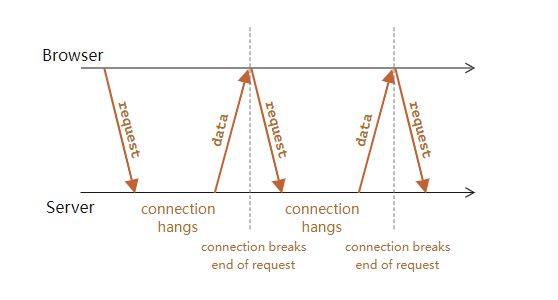
cacheData的数据(debug形式):
cacheData存的是本地配置的相关信息,比如md5、group、tenant等信息。
请求nacos服务端时的参数:
请求时会把cacheData的数据用分隔符分隔处理,具体处理逻辑在checkUpdateDataIDs方法中。
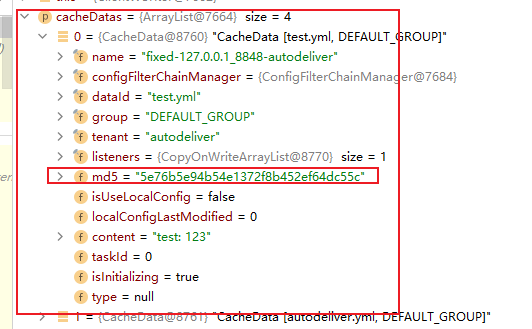

在上图中,可知此方法最终是将本地配置的groupKey和md5等信息传入nacos服务端进行比较,然后将发生变化的key返回。
在执行完checkUpdateDataIds之后,会获取到发生变化的key即changedGroupKeys数组,然后会遍历此数组,调用getServerConfig方法,从nacos服务器端获取变化的配置,代码如下:
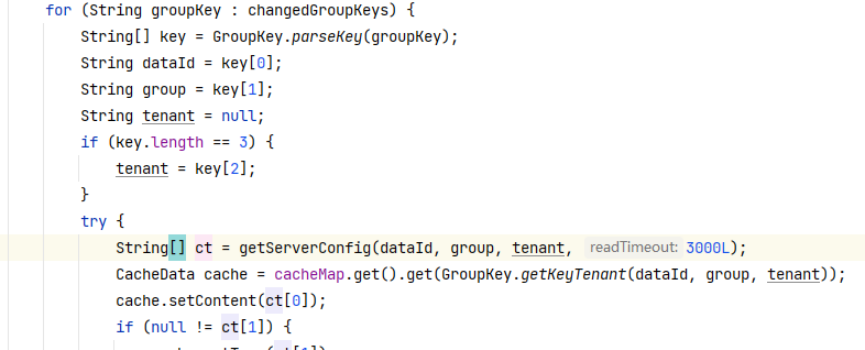
最后一步是重点,这一步会循环通知监听器刷新nacos数据,最后通过executorService.execute(this)方法继续长轮询。代码如下:
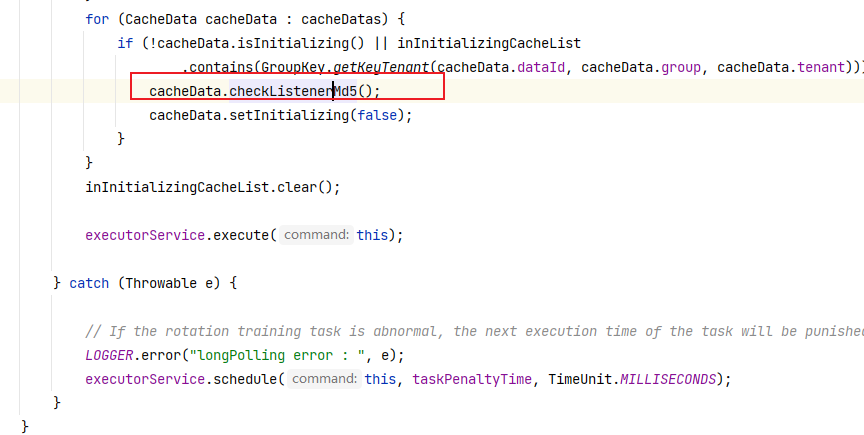
以上就是整个Nacos长轮询的流程。
Nacos动态刷新配置
承接上文,这里我们可以关注一下checkListenerMd5()方法,是如何通知监听器进行刷新Naocs数据的。我们跟进此方法,部分源码如下图:
在此方法中会遍历所有的监听器,最终执行safeNotifyListener()方法。在此方法中创建了一个Runnable的任务,然后通过监听器Listener里面的线程池执行了此任务。这个Runnable中最核心的就是这一句代码:listener.receiveConfigInfo(contentTmp);即接收修改的配置内容。
想要弄清楚这句代码,首先我们要清楚这个Listener是哪里的实现类?我们可以通过debug的方式查看,我们打上断点最终方法会进入到AbstractSharedListener#receiveConfigInfo中,此方法是抽象方法,最终我们会发现这个实现此抽象方法的是NacosContextRefresher类中的一个匿名内部类。整体debug流程如下:
于是我们关注一下这个innerReceive方法:
@Override
public void innerReceive(String dataId, String group,
String configInfo) {
refreshCountIncrement();
//记录nacos历史变更数据
nacosRefreshHistory.addRefreshRecord(dataId, group, configInfo);
// todo feature: support single refresh for listening
//发布RefreshEvent事件刷新容器
applicationContext.publishEvent(
new RefreshEvent(this, null, "Refresh Nacos config"));
if (log.isDebugEnabled()) {
log.debug(String.format(
"Refresh Nacos config group=%s,dataId=%s,configInfo=%s",
group, dataId, configInfo));
}
}
这个NacosContextRefresher可以说就是与Spring沟通的桥梁,实现了ApplicationContextAware用来获取ApplicationContext,实现了ApplicationListener用来注册监听器用来通知spring发布事件。这个类的onApplicationEvent方法就注册了nacos的监听器,而这个监听器的内部类的抽象方法实现就是上面的innerReceive方法。
扩展:Spring Cloud刷新配置文件
承接上文,也就是说Nacos会发布一个RefreshEvent事件,我们直接搜索(IDEA 双击shift可以搜索)看一下这个事件的监听器的onApplicationEvent方法,如下:
//org.springframework.cloud.endpoint.event.RefreshEventListener#onApplicationEvent
@Override
public void onApplicationEvent(ApplicationEvent event) {
if (event instanceof ApplicationReadyEvent) {
handle((ApplicationReadyEvent) event);
}
else if (event instanceof RefreshEvent) {
handle((RefreshEvent) event);
}
}
//------>handle((RefreshEvent) event)
public void handle(RefreshEvent event) {
if (this.ready.get()) { // don't handle events before app is ready
log.debug("Event received " + event.getEventDesc());
Set<String> keys = this.refresh.refresh();
log.info("Refresh keys changed: " + keys);
}
}
//------>this.refresh.refresh()
//org.springframework.cloud.context.refresh.ContextRefresher#refresh
public synchronized Set<String> refresh() {
Set<String> keys = refreshEnvironment();
this.scope.refreshAll();
return keys;
}
代码如上,最后会来到ContextRefresher#refresh中,我们跟进这两个方法:
//org.springframework.cloud.context.refresh.ContextRefresher#refreshEnvironment
public synchronized Set<String> refreshEnvironment() {
//获取未刷新前的配置
Map<String, Object> before = extract(
this.context.getEnvironment().getPropertySources());
//刷新配置环境
addConfigFilesToEnvironment();
//这里Environment中是最新的值,因此这里是获取变化的值
Set<String> keys = changes(before,
extract(this.context.getEnvironment().getPropertySources())).keySet();
//发布EnvironmentChangeEvent事件
this.context.publishEvent(new EnvironmentChangeEvent(this.context, keys));
return keys;
}
//org.springframework.cloud.context.scope.refresh.RefreshScope#refreshAll
public void refreshAll() {
//销毁容器
super.destroy();
//发布RefreshScopeRefreshedEvent事件
this.context.publishEvent(new RefreshScopeRefreshedEvent());
}
我们会发现这里主要有四件事:
-
刷新配置环境——
addConfigFilesToEnvironment()
此方法部分代码如上图,主要作用就是新建一个上下文获取最新配置,并替换当前配置中变化的值。简单来说就是刷新配置环境。
-
发布EnvironmentChangeEvent事件——
publishEvent(new EnvironmentChangeEvent(...))我们来看一下这个事件的监听器,首先他内部存储所有@ConfigurationProperties注解标注的类,然后继承了ApplicationContextAware获取了Spring的上下文对象,最后继承了ApplicationListener监听EnvironmentChangeEvent事件。
在事件监听方法中,对bean对象进行了先销毁,然后重新初始化,这样就会有处理
@ConfigurationProperties注解的Bean去进行值的设置。@Component @ManagedResource public class ConfigurationPropertiesRebinder implements ApplicationContextAware, ApplicationListener<EnvironmentChangeEvent> { //Collects references to @ConfigurationProperties beans in the context and its parent. //存储所有@ConfigurationProperties注解标注的类 private ConfigurationPropertiesBeans beans; public ConfigurationPropertiesRebinder(ConfigurationPropertiesBeans beans) { this.beans = beans; } private ApplicationContext applicationContext; //继承ApplicationContextAware,获取Spring上下文 @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext = applicationContext; } @Override public void onApplicationEvent(EnvironmentChangeEvent event) { if (this.applicationContext.equals(event.getSource()) // Backwards compatible || event.getKeys().equals(event.getSource())) { rebind(); } } @ManagedOperation public void rebind() { this.errors.clear(); for (String name : this.beans.getBeanNames()) { rebind(name); } } @ManagedOperation public boolean rebind(String name) { if (!this.beans.getBeanNames().contains(name)) { return false; } if (this.applicationContext != null) { try { Object bean = this.applicationContext.getBean(name); if (AopUtils.isAopProxy(bean)) { bean = ProxyUtils.getTargetObject(bean); } if (bean != null) { this.applicationContext.getAutowireCapableBeanFactory() .destroyBean(bean); this.applicationContext.getAutowireCapableBeanFactory() .initializeBean(bean, name); return true; } } //catch代码略。。。 } return false; } }这里还有一个问题,ConfigurationPropertiesBeans是如何收集
@ConfigurationProperties的组件的?我们可以进入ConfigurationPropertiesBeans类,发现其继承了BeanPostProcessor(Spring的扩展机制),因此我们看一下它的postProcessBeforeInitialization方法,可以看到这里是维护了非RefreshScope并且标注了@ConfigurationProperties注解的组件。
@Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { //排除掉RefreshScope的Bean if (isRefreshScoped(beanName)) { return bean; } //扫描标注了@ConfigurationProperties注解的组件,具体可跟ru ConfigurationPropertiesBean propertiesBean = ConfigurationPropertiesBean .get(this.applicationContext, bean, beanName); if (propertiesBean != null) { this.beans.put(beanName, propertiesBean); } return bean; }BeanPostProcessor可以在Bean初始化前后去进行干预,关于Bean的初始化可以看我的Spring笔记6.3.1关于Bean初始化的源码解析。
-
销毁容器——
super.destroy()此方法是在调用父类的方法,作用是清空缓存
@Override public void destroy() { List<Throwable> errors = new ArrayList<Throwable>(); //清空缓存,当再次获取对象时 Collection<BeanLifecycleWrapper> wrappers = this.cache.clear(); for (BeanLifecycleWrapper wrapper : wrappers) { try { Lock lock = this.locks.get(wrapper.getName()).writeLock(); lock.lock(); try { //回调方法 wrapper.destroy(); } finally { lock.unlock(); } } catch (RuntimeException e) { errors.add(e); } } if (!errors.isEmpty()) { throw wrapIfNecessary(errors.get(0)); } this.errors.clear(); }这个缓存是从何而来呢?我们知道当我们想让配置自动刷新的时候需要加上@RefreshScope注解,那么我们就从这个注解入手:
@Target({ ElementType.TYPE, ElementType.METHOD }) @Retention(RetentionPolicy.RUNTIME) @Scope("refresh") @Documented public @interface RefreshScope { }我们可以发现此方法其实就是一个特殊的Scope注解,且Scope注解值为refresh。那么它是如何注册的呢?我们依旧从自动装配寻找答案,我们可以在Spring-Cloud-Context中的spring.factory中找到RefreshAutoConfiguration配置类,部分源码如下:
//注册RefreshScope @Bean @ConditionalOnMissingBean(RefreshScope.class) public static RefreshScope refreshScope() { return new RefreshScope(); } //刷新配置文件,发布事件 @Bean @ConditionalOnMissingBean public ContextRefresher contextRefresher(ConfigurableApplicationContext context, RefreshScope scope) { return new ContextRefresher(context, scope); } //监听上下文刷新事件 @Bean public RefreshEventListener refreshEventListener(ContextRefresher contextRefresher) { return new RefreshEventListener(contextRefresher); }我们进入到RefreshScope类,此类继承了GenericScope,而GenericScope继承了BeanDefinitionRegistryPostProcessor(这是Spring的扩展点),因此我们重点关注postProcessBeanFactory方法:
@Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { this.beanFactory = beanFactory; //存入缓存中,底层是调用AbstractBeanFactory#registerScope beanFactory.registerScope(this.name, this); setSerializationId(beanFactory); }而当我们获取该对象时会调用AbstractBeanFactory的getBean方法(Spring的流程),部分源码如下:
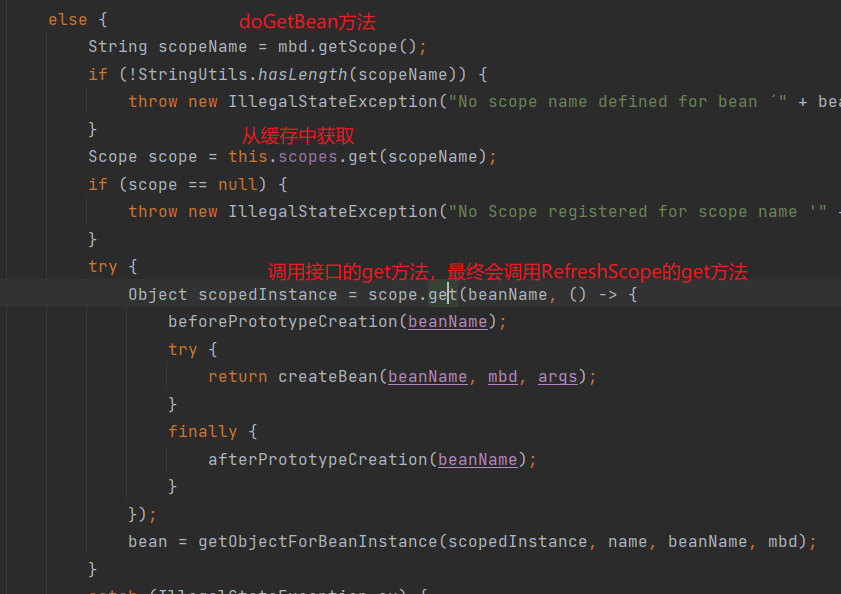
get方法源码如下:
@Override public Object get(String name, ObjectFactory<?> objectFactory) { //包装成BeanLifecycleWrapper存入缓存中 BeanLifecycleWrapper value = this.cache.put(name, new BeanLifecycleWrapper(name, objectFactory)); this.locks.putIfAbsent(name, new ReentrantReadWriteLock()); try { //调用BeanLifecycleWrapper的getBean return value.getBean(); } catch (RuntimeException e) { this.errors.put(name, e); throw e; } }先是将ObjectFactory实例对象包装成BeanLifecycleWrapper放入缓存中。这里的这个缓存我们非常熟悉也就是我们上面刷新的时候清空的缓存。
然后调用BeanLifecycleWrapper的getBean方法,源码如下:
public Object getBean() { if (this.bean == null) { synchronized (this.name) { if (this.bean == null) { this.bean = this.objectFactory.getObject(); } } } return this.bean; }如果该对象为空,则调用this.objectFactory.getObject()回到Spring的IOC流程。
-
发布RefreshScopeRefreshedEvent事件——
context.publishEvent(new RefreshScopeRefreshedEvent())在最后它会发一个
RefreshScopeRefreshedEvent事件,我并没有找到它的事件监听器,我猜测是可能跟其他的Spring Cloud组件有关,或者是Spring Cloud给出的拓展点。如果有大佬懂这里也欢迎指正,感激不尽。
Nacos服务端处理拉取配置请求
在上面我们也讲了,nacos客户端会长轮询去nacos服务端检测相关配置,所以我们看一下服务端的接口:
@PostMapping("/listener")
@Secured(action = ActionTypes.READ, parser = ConfigResourceParser.class)
public void listener(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
request.setAttribute("org.apache.catalina.ASYNC_SUPPORTED", true);
String probeModify = request.getParameter("Listening-Configs");
if (StringUtils.isBlank(probeModify)) {
throw new IllegalArgumentException("invalid probeModify");
}
probeModify = URLDecoder.decode(probeModify, Constants.ENCODE);
Map<String, String> clientMd5Map;
try {
clientMd5Map = MD5Util.getClientMd5Map(probeModify);
} catch (Throwable e) {
throw new IllegalArgumentException("invalid probeModify");
}
// do long-polling 处理长轮询
inner.doPollingConfig(request, response, clientMd5Map, probeModify.length());
}
上面方法中我们主要跟进doPollingConfig方法
public String doPollingConfig(HttpServletRequest request, HttpServletResponse response,
Map<String, String> clientMd5Map, int probeRequestSize) throws IOException {
//如果是长轮询就调用addLongPollingClient
//判断请求头中是否有Long-Pulling-Timeout
if (LongPollingService.isSupportLongPolling(request)) {
longPollingService.addLongPollingClient(request, response, clientMd5Map, probeRequestSize);
return HttpServletResponse.SC_OK + "";
}
//这里是为了兼容短轮询的逻辑,首先检测出变化的Key
List<String> changedGroups = MD5Util.compareMd5(request, response, clientMd5Map);
// 兼容短轮询的result
String oldResult = MD5Util.compareMd5OldResult(changedGroups);
String newResult = MD5Util.compareMd5ResultString(changedGroups);
String version = request.getHeader(Constants.CLIENT_VERSION_HEADER);
if (version == null) {
version = "2.0.0";
}
int versionNum = Protocol.getVersionNumber(version);
// Befor 2.0.4 version, return value is put into header.
if (versionNum < START_LONG_POLLING_VERSION_NUM) {
//短轮询直接将返回的数据放到响应头中
response.addHeader(Constants.PROBE_MODIFY_RESPONSE, oldResult);
response.addHeader(Constants.PROBE_MODIFY_RESPONSE_NEW, newResult);
} else {
request.setAttribute("content", newResult);
}
Loggers.AUTH.info("new content:" + newResult);
// Disable cache.
response.setHeader("Pragma", "no-cache");
response.setDateHeader("Expires", 0);
response.setHeader("Cache-Control", "no-cache,no-store");
response.setStatus(HttpServletResponse.SC_OK);
return HttpServletResponse.SC_OK + "";
}
上面对短轮询的兼容逻辑就是根据clientMd5Map和服务端进行对比,如果有变化就将新老数据都放到响应头中返回给nacos客户端。我们这里主要关注长轮询的逻辑,我们跟进addLongPollingClient方法:
public void addLongPollingClient(HttpServletRequest req, HttpServletResponse rsp, Map<String, String> clientMd5Map,
int probeRequestSize) {
//获取请求头
String str = req.getHeader(LongPollingService.LONG_POLLING_HEADER);
String noHangUpFlag = req.getHeader(LongPollingService.LONG_POLLING_NO_HANG_UP_HEADER);
String appName = req.getHeader(RequestUtil.CLIENT_APPNAME_HEADER);
String tag = req.getHeader("Vipserver-Tag");
//这里一般是500
int delayTime = SwitchService.getSwitchInteger(SwitchService.FIXED_DELAY_TIME, 500);
// Add delay time for LoadBalance, and one response is returned 500 ms in advance to avoid client timeout.
//这里源码注释解释的也很清楚了,这里是将超时时间减500ms,防止客户端超时,所以一般是29500ms
long timeout = Math.max(10000, Long.parseLong(str) - delayTime);
if (isFixedPolling()) {
timeout = Math.max(10000, getFixedPollingInterval());
// Do nothing but set fix polling timeout.
} else {
long start = System.currentTimeMillis();
//对比数据检测出变化的Key
List<String> changedGroups = MD5Util.compareMd5(req, rsp, clientMd5Map);
//发生变化直接返回客户端
if (changedGroups.size() > 0) {
generateResponse(req, rsp, changedGroups);
LogUtil.CLIENT_LOG.info("{}|{}|{}|{}|{}|{}|{}", System.currentTimeMillis() - start, "instant",
RequestUtil.getRemoteIp(req), "polling", clientMd5Map.size(), probeRequestSize,
changedGroups.size());
return;
} else if (noHangUpFlag != null && noHangUpFlag.equalsIgnoreCase(TRUE_STR)) {
LogUtil.CLIENT_LOG.info("{}|{}|{}|{}|{}|{}|{}", System.currentTimeMillis() - start, "nohangup",
RequestUtil.getRemoteIp(req), "polling", clientMd5Map.size(), probeRequestSize,
changedGroups.size());
return;
}
}
String ip = RequestUtil.getRemoteIp(req);
// Must be called by http thread, or send response.
//开启异步上下文,将主线程交还给Tomcat,异步上下文是保持连接不断的原因
final AsyncContext asyncContext = req.startAsync();
// AsyncContext.setTimeout() is incorrect, Control by oneself
asyncContext.setTimeout(0L);
//开启ClientLongPolling线程
ConfigExecutor.executeLongPolling(
new ClientLongPolling(asyncContext, clientMd5Map, ip, probeRequestSize, timeout, appName, tag));
}
AsyncContext是Servlet 3.0的异步处理支持的特性,使Servlet 线程不再需要一直阻塞,直到业务处理完毕才能再输出响应,最后才结束该 Servlet 线程。在接收到请求之后,Servlet 线程可以将耗时的操作委派给另一个线程来完成,自己在不生成响应的情况下返回至容器。针对业务处理较耗时的情况,这将大大减少服务器资源的占用,并且提高并发处理速度。关于AsyncContext更具体的信息,请自行百度。
上面代码当得到AsyncContext实例之后,会先释放容器分配给请求的线程与相关资源,然后把把实例放入了一个定时任务里面;等时间到了或者有配置变更之后,调用
complete()方法响应完成,这也是服务端保持住客户端请求不挂断的关键。
上面的方法有三个关键点:
-
一是将超时时间设置为29500ms也就是29.5s,防止客户端超时,关键代码为:
long timeout = Math.max(10000, Long.parseLong(str) - delayTime); -
二是检测是否有发生变化的key,如果发生变化则直接返回客户端。代码流程如下图
-
三是开启异步上下文开启ClientLongPolling线程
class ClientLongPolling implements Runnable { @Override public void run() { //不立即返回,而是延迟29500ms后返回请求结果 //这里通过单线程池延时一段时间执行任务 asyncTimeoutFuture = ConfigExecutor.scheduleLongPolling(new Runnable() { @Override public void run() { try { getRetainIps().put(ClientLongPolling.this.ip, System.currentTimeMillis()); // Delete subsciber's relations. allSubs.remove(ClientLongPolling.this); if (isFixedPolling()) { //日志代码略 //比较数据的MD5,得到变化的值 List<String> changedGroups = MD5Util .compareMd5((HttpServletRequest) asyncContext.getRequest(), (HttpServletResponse) asyncContext.getResponse(), clientMd5Map); if (changedGroups.size() > 0) { //将变化的值返回给客户端 sendResponse(changedGroups); } else { sendResponse(null); } } else { //日志代码略 sendResponse(null); } } catch (Throwable t) { //日志代码略 } } }, timeoutTime, TimeUnit.MILLISECONDS); //存入客户端订阅缓存,便于主动推送时使用 allSubs.add(this); } void sendResponse(List<String> changedGroups) { // Cancel time out task. if (null != asyncTimeoutFuture) { asyncTimeoutFuture.cancel(false); } generateResponse(changedGroups); } }上面代码中sendResponse方法也会调用generateResponse方法,但是与关键点二中的generateResponse方法有一些不同,那就是需要调用
asyncContext.complete();来完成响应。
服务端推送发生变化的配置
我们知道nacos在配置发生变化时也会主动推送给客户端,那么这是怎么做到的呢?我们来到LongPollingService的构造方法中:
public LongPollingService() {
//初始化订阅者缓存
allSubs = new ConcurrentLinkedQueue<ClientLongPolling>();
ConfigExecutor.scheduleLongPolling(new StatTask(), 0L, 10L, TimeUnit.SECONDS);
// Register LocalDataChangeEvent to NotifyCenter.注册LocalDataChangeEvent事件
NotifyCenter.registerToPublisher(LocalDataChangeEvent.class, NotifyCenter.ringBufferSize);
// Register A Subscriber to subscribe LocalDataChangeEvent.
//注册LocalDataChangeEvent订阅
NotifyCenter.registerSubscriber(new Subscriber() {
@Override
public void onEvent(Event event) {
if (isFixedPolling()) {
// Ignore.
} else {
//监听LocalDataChangeEvent事件并封装成DataChangeTask通过线程池去执行
if (event instanceof LocalDataChangeEvent) {
LocalDataChangeEvent evt = (LocalDataChangeEvent) event;
ConfigExecutor.executeLongPolling(new DataChangeTask(evt.groupKey, evt.isBeta, evt.betaIps));
}
}
}
@Override
public Class<? extends Event> subscribeType() {
return LocalDataChangeEvent.class;
}
});
}
其实此方法很简单,主要是注册一个LocalDataChangeEvent时间的监听,然后封装成DataChangeTask任务去处理此事件。我们接下来进入DataChangeTask看一下,我们重点关注其run方法:
@Override
public void run() {
try {
ConfigCacheService.getContentBetaMd5(groupKey);
//遍历之前缓存的客户端订阅
for (Iterator<ClientLongPolling> iter = allSubs.iterator(); iter.hasNext(); ) {
ClientLongPolling clientSub = iter.next();
//和groupKey匹配并且配置数据发生了变更则通知客户端
if (clientSub.clientMd5Map.containsKey(groupKey)) {
//略过bate和tag发布
// If published tag is not in the beta list, then it skipped.
if (isBeta && !CollectionUtils.contains(betaIps, clientSub.ip)) {
continue;
}
// If published tag is not in the tag list, then it skipped.
if (StringUtils.isNotBlank(tag) && !tag.equals(clientSub.tag)) {
continue;
}
getRetainIps().put(clientSub.ip, System.currentTimeMillis());
iter.remove(); // Delete subscribers' relationships.
//日志代码略
//返回客户端,代码与上面相同
clientSub.sendResponse(Arrays.asList(groupKey));
}
}
} catch (Throwable t) {
LogUtil.DEFAULT_LOG.error("data change error: {}", ExceptionUtil.getStackTrace(t));
}
}