代码请自取 https://github.com/xoslh/CNN-MNIST-CPP-
1 卷积神经网络-CNN 的基本原理
卷积神经网络(Convolutional Neural Networks, CNNs)是一种深度学习算法,特别适用于图像处理和分析。其设计灵感来源于生物学中视觉皮层的机制,是一种强大的特征提取和分类工具。
1.1 Layers
整个CNN是由若干层不同类型的网络连接构成的的。例如下图,首先经过一次卷积滤波处理,得到了C1(卷积层 Feature map),然后又经过了一次下采样(池化)处理得到了S2(下采样层),之后又是一次卷积滤波得到C3卷积层,依次处理至途中的C5位全连接层,至此卷积的过程结束,被抽象的特征输入至传统的全连接神经网络。
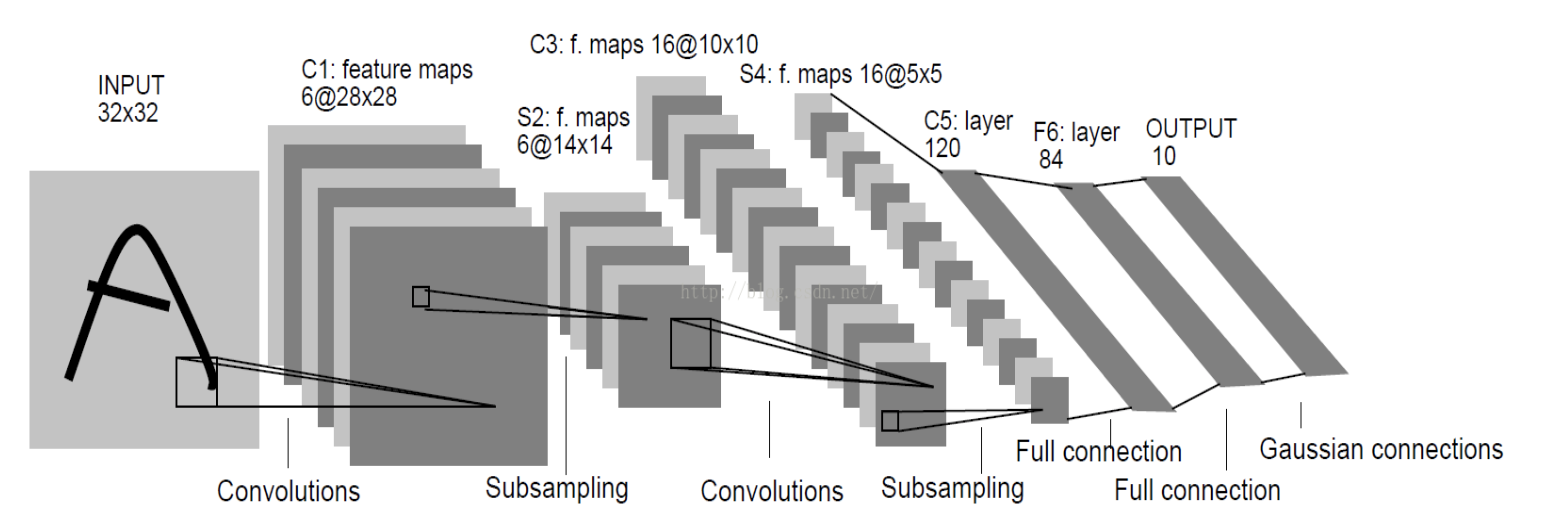
1.1.1 输入层(Input Layer)
这是网络的最初层,负责接收原始像素数据。每个像素的值都被视为原始特征。
1.1.2 卷积层(Convolutional Layer)
在卷积层中,一组可学习的滤波器或卷积核在输入数据上进行滑动操作以生成特征图(Feature Maps)。卷积操作允许网络学习到输入数据的局部特征。此外,由于滤波器的权重在图像的不同部分是共享的,卷积层可以显著减少模型的参数数量,从而减轻过拟合的风险。
怎么理解权重共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
卷积层的运算过程如下图,用一个卷积核扫完整张图片:
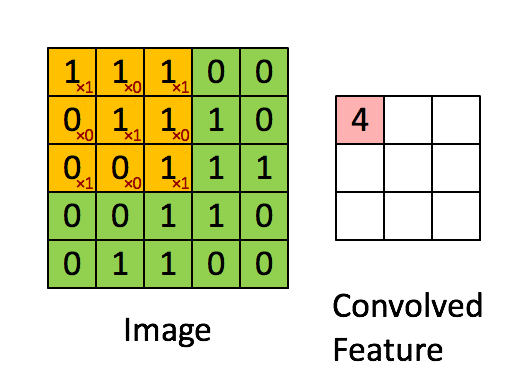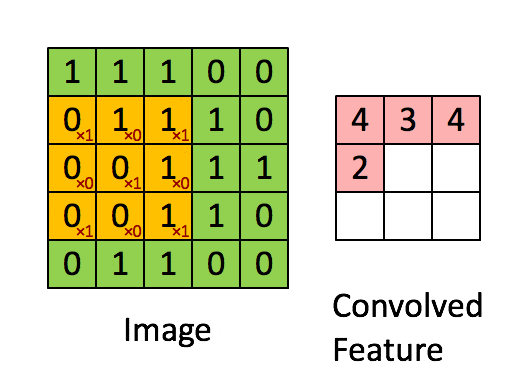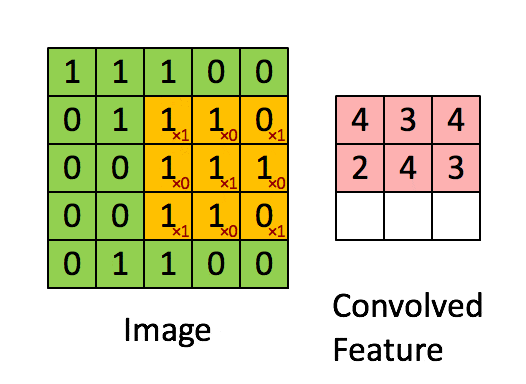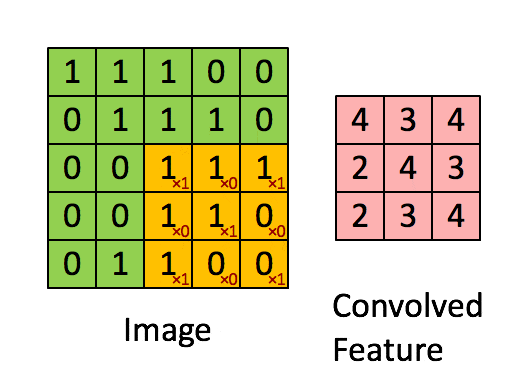
这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
在具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。如果我们设计了6个卷积核,可以理解:我们认为这个图像上有6种底层纹理模式,也就是我们用6中基础模式就能描绘出一副图像。
以下就是25种不同的卷积核的示例:

1.1.3 ReLU层(Rectified Linear Unit Layer)
这是非线性操作层,通常紧跟在卷积层之后。其目的是通过应用非线性函数如ReLU(max(0, x))来增加网络的非线性特性。
1.1.4 池化层(Pooling Layer)
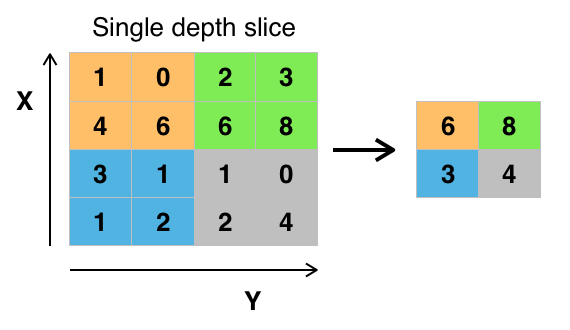
也称作下采样层,其主要功能是降低特征图的空间尺寸,从而降低模型的计算复杂性,并在一定程度上提供模型的平移不变性。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。
当图像太大时,池化层部分将减少参数的数量。空间池化也称为子采样或下采样,可在保留重要信息的同时降低数据维度,可以具有不同的类型,如最大值池化(Max Pooling),平均池化(Average Pooling),加和池化(Sum Pooling)。
最常见的是最大值池化,其将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。这种机制能够有效地原因在于,在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。池化层会不断地减小数据的空间大小,能够在一定程度上控制过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
1.1.5 全连接层(Fully Connected Layer)
在一系列的卷积层和池化层之后,全连接层被用于对之前提取的特征进行高级别的推理。在这一层中,所有的输入都被连接到每个神经元,这与传统的神经网络类似。这个部分就是最后一步了,经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果。经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。
1.1.6 输出层(Output Layer)
最后,输出层通常使用softmax激活函数进行多类分类,或使用sigmoid激活函数进行二分类。
1.2 反向传播算法推导(Backpropagation)
1.2.1 回顾DNN的反向传播算法
我们首先回顾DNN的反向传播算法。在DNN中,我们是首先计算出输出层的\(\delta^L\):$$\delta^L = \frac{\partial J(W,b)}{\partial z^L} = \frac{\partial J(W,b)}{\partial a^L}\odot \sigma{'}(zL)$$
利用数学归纳法,用\(\delta^{l+1}\)的值一步步的向前求出第l层的\(\delta^l\),表达式为:$$\delta^{l} = (\frac{\partial z^{l+1}}{\partial z{l}})T\delta^{l+1} = (W{l+1})T\delta^{l+1}\odot \sigma{'}(zl)$$
有了\(\delta^l\)的表达式,从而求出\(W,b\)的梯度表达式:$$\frac{\partial J(W,b)}{\partial W^l} = \delta{l}(a)^T$$$$\frac{\partial J(W,b,x,y)}{\partial b^l} = = \delta^{l}$$
有了\(W,b\)梯度表达式,就可以用梯度下降法来优化\(W,b\),求出最终的所有\(W,b\)的值。
现在我们想把同样的思想用到CNN中,很明显,CNN有些不同的地方,不能直接去套用DNN的反向传播算法的公式。
1.2.2 CNN的反向传播算法思想
要套用DNN的反向传播算法到CNN,有几个问题需要解决:
1)池化层没有激活函数,这个问题倒比较好解决,我们可以令池化层的激活函数为\(\sigma(z) = z\),即激活后就是自己本身。这样池化层激活函数的导数为1.
2)池化层在前向传播的时候,对输入进行了压缩,那么我们现在需要向前反向推导\(\delta^{l-1}\),这个推导方法和DNN完全不同。
3)卷积层是通过张量卷积,或者说若干个矩阵卷积求和而得的当前层的输出,这和DNN很不相同,DNN的全连接层是直接进行矩阵乘法得到当前层的输出。这样在卷积层反向传播的时候,上一层的\(\delta^{l-1}\)递推计算方法肯定有所不同。
4)对于卷积层,由于\(W\)使用的运算是卷积,那么从\(\delta^l\)推导出该层的所有卷积核的\(W,b\)的方式也不同。
从上面可以看出,问题1比较好解决,但是问题2,3,4就需要好好的动一番脑筋了,而问题2,3,4也是解决CNN反向传播算法的关键所在。另外大家要注意到的是,DNN中的\(a_l,z_l\)都只是一个向量,而我们CNN中的\(a_l,z_l\)都是一个张量,这个张量是三维的,即由若干个输入的子矩阵组成。
下面我们就针对问题2,3,4来一步步研究CNN的反向传播算法。
在研究过程中,需要注意的是,由于卷积层可以有多个卷积核,各个卷积核的处理方法是完全相同且独立的,为了简化算法公式的复杂度,我们下面提到卷积核都是卷积层中若干卷积核中的一个。
1.2.3 已知池化层的\(\delta^l\),推导上一隐藏层的\(\delta^{l-1}\)
我们首先解决上面的问题2,如果已知池化层的\(\delta^l\),推导出上一隐藏层的\(\delta^{l-1}\)。
在前向传播算法时,池化层一般我们会用MAX或者Average对输入进行池化,池化的区域大小已知。现在我们反过来,要从缩小后的误差\(\delta^l\),还原前一次较大区域对应的误差。
在反向传播时,我们首先会把\(\delta^l\)的所有子矩阵矩阵大小还原成池化之前的大小,然后如果是MAX,则把\(\delta^l\)的所有子矩阵的各个池化局域的值放在之前做前向传播算法得到最大值的位置。如果是Average,则把\(\delta^l\)的所有子矩阵的各个池化局域的值取平均后放在还原后的子矩阵位置。这个过程一般叫做upsample。
用一个例子可以很方便的表示:假设我们的池化区域大小是2x2。\(\delta^l\)的第k个子矩阵为:$$\delta_k^l =
\left( \begin{array}{ccc}
2& 8 \
4& 6 \end{array} \right)$$
由于池化区域为2x2,我们先讲\(\delta_k^l\)做还原,即变成:$$
\left( \begin{array}{ccc}
0&0&0&0 \ 0&2& 8&0 \ 0&4&6&0 \
0&0&0&0 \end{array} \right)$$
如果是MAX,假设我们之前在前向传播时记录的最大值位置分别是左上,右下,右上,左下,则转换后的矩阵为:
\[\left( \begin{array}{ccc} 2&0&0&0 \\ 0&0& 0&8 \\ 0&4&0&0 \\ 0&0&6&0 \end{array} \right) \] 如果是Average,则进行平均:转换后的矩阵为:$$
\left( \begin{array}{ccc}
0.5&0.5&2&2 \ 0.5&0.5&2&2 \ 1&1&1.5&1.5 \
1&1&1.5&1.5 \end{array} \right)$$
这样我们就得到了上一层 $\frac{\partial J(W,b)}{\partial a_k^{l-1}} \(的值,要得到\)\delta_k^{l-1}\(:\)\(\delta_k^{l-1} = (\frac{\partial a_k^{l-1}}{\partial z_k^{l-1}})^T\frac{\partial J(W,b)}{\partial a_k^{l-1}} = upsample(\delta_k^l) \odot \sigma^{'}(z_k^{l-1})\)$
其中,upsample函数完成了池化误差矩阵放大与误差重新分配的逻辑。
我们概括下,对于张量\(\delta^{l-1}\),我们有:$$\delta^{l-1} = upsample(\delta^l) \odot \sigma{'}(z)$$
1.2.4 已知卷积层的\(\delta^l\),推导上一隐藏层的\(\delta^{l-1}\)
对于卷积层的反向传播,我们首先回忆下卷积层的前向传播公式:$$ a^l= \sigma(z^l) = \sigma(a{l-1}*Wl +b^l) $$
其中\(n\_in\)为上一隐藏层的输入子矩阵个数。
在DNN中,我们知道\(\delta^{l-1}\)和\(\delta^{l}\)的递推关系为:$$\delta^{l} = \frac{\partial J(W,b)}{\partial z^l} =(\frac{\partial z^{l+1}}{\partial z{l}})T \frac{\partial J(W,b)}{\partial z^{l+1}} =(\frac{\partial z^{l+1}}{\partial z{l}})T\delta^{l+1}$$
因此要推导出\(\delta^{l-1}\)和\(\delta^{l}\)的递推关系,必须计算\(\frac{\partial z^{l}}{\partial z^{l-1}}\)的梯度表达式。
注意到\(z^{l}\)和\(z^{l-1}\)的关系为:$$z^l = a{l-1}*Wl +b^l =\sigma(z{l-1})*Wl +b^l $$
因此我们有:$$\delta^{l-1} = (\frac{\partial z^{l}}{\partial z{l-1}})T\delta^{l} = \delta{l}*rot180(W) \odot \sigma{'}(z) $$
这里的式子其实和DNN的类似,区别在于对于含有卷积的式子求导时,卷积核被旋转了180度。即式子中的\(rot180()\),翻转180度的意思是上下翻转一次,接着左右翻转一次。在DNN中这里只是矩阵的转置。那么为什么呢?由于这里都是张量,直接推演参数太多了。我们以一个简单的例子说明为啥这里求导后卷积核要翻转。
假设我们\(l-1\)层的输出\(a^{l-1}\)是一个3x3矩阵,第\(l\)层的卷积核\(W^l\)是一个2x2矩阵,采用1像素的步幅,则输出\(z^{l}\)是一个2x2的矩阵。我们简化\(b^l都是0\),则有$$a{l-1}*Wl = z^{l}$$
我们列出\(a,W,z\)的矩阵表达式如下:$$
\left( \begin{array}{ccc}
a_{11}&a_{12}&a_{13} \ a_{21}&a_{22}&a_{23}\
a_{31}&a_{32}&a_{33} \end{array} \right) * \left( \begin{array}{ccc}
w_{11}&w_{12}\
w_{21}&w_{22} \end{array} \right) = \left( \begin{array}{ccc}
z_{11}&z_{12}\
z_{21}&z_{22} \end{array} \right)$$
利用卷积的定义,很容易得出:$$z_{11} = a_{11}w_{11} + a_{12}w_{12} + a_{21}w_{21} + a_{22}w_{22} $$$$z_{12} = a_{12}w_{11} + a_{13}w_{12} + a_{22}w_{21} + a_{23}w_{22} $$$$z_{21} = a_{21}w_{11} + a_{22}w_{12} + a_{31}w_{21} + a_{32}w_{22} $$$$z_{22} = a_{22}w_{11} + a_{23}w_{12} + a_{32}w_{21} + a_{33}w_{22} $$
接着我们模拟反向求导:$$\nabla a^{l-1} = \frac{\partial J(W,b)}{\partial a^{l-1}} = ( \frac{\partial z^{l}}{\partial a{l-1}})T\frac{\partial J(W,b)}{\partial z^{l}} =(\frac{\partial z^{l}}{\partial a{l-1}})T \delta^{l} $$
从上式可以看出,对于\(a^{l-1}\)的梯度误差\(\nabla a^{l-1}\),等于第\(l\)层的梯度误差乘以\(\frac{\partial z^{l}}{\partial a^{l-1}}\),而\(\frac{\partial z^{l}}{\partial a^{l-1}}\)对应上面的例子中相关联的\(w\)的值。假设我们的\(z\)矩阵对应的反向传播误差是\(\delta_{11}, \delta_{12}, \delta_{21}, \delta_{22}\)组成的2x2矩阵,则利用上面梯度的式子和4个等式,我们可以分别写出\(\nabla a^{l-1}\)的9个标量的梯度。
比如对于\(a_{11}\)的梯度,由于在4个等式中\(a_{11}\)只和\(z_{11}\)有乘积关系,从而我们有:$$ \nabla a_{11} = \delta_{11}w_{11}$$
对于\(a_{12}\)的梯度,由于在4个等式中\(a_{12}\)和\(z_{12},z_{11}\)有乘积关系,从而我们有:$$ \nabla a_{12} = \delta_{11}w_{12} + \delta_{12}w_{11}$$
同样的道理我们得到:$$ \nabla a_{13} = \delta_{12}w_{12} $$$$\nabla a_{21} = \delta_{11}w_{21} + \delta_{21}w_{11}$$$$\nabla a_{22} = \delta_{11}w_{22} + \delta_{12}w_{21} + \delta_{21}w_{12} + \delta_{22}w_{11} $$$$ \nabla a_{23} = \delta_{12}w_{22} + \delta_{22}w_{12}$$$$ \nabla a_{31} = \delta_{21}w_{21}$$$$ \nabla a_{32} = \delta_{21}w_{22} + \delta_{22}w_{21}$$$$ \nabla a_{33} = \delta_{22}w_{22} $$
这上面9个式子其实可以用一个矩阵卷积的形式表示,即:$$
\left( \begin{array}{ccc}
0&0&0&0 \ 0&\delta_{11}& \delta_{12}&0 \ 0&\delta_{21}&\delta_{22}&0 \
0&0&0&0 \end{array} \right) * \left( \begin{array}{ccc}
w_{22}&w_{21}\
w_{12}&w_{11} \end{array} \right) = \left( \begin{array}{ccc}
\nabla a_{11}&\nabla a_{12}&\nabla a_{13} \ \nabla a_{21}&\nabla a_{22}&\nabla a_{23}\
\nabla a_{31}&\nabla a_{32}&\nabla a_{33} \end{array} \right)$$
为了符合梯度计算,我们在误差矩阵周围填充了一圈0,此时我们将卷积核翻转后和反向传播的梯度误差进行卷积,就得到了前一次的梯度误差。这个例子直观的介绍了为什么对含有卷积的式子反向传播时,卷积核要翻转180度的原因。
以上就是卷积层的误差反向传播过程。
1.2.5. 已知卷积层的\(\delta^l\),推导该层的\(W,b\)的梯度
好了,我们现在已经可以递推出每一层的梯度误差\(\delta^l\)了,对于全连接层,可以按DNN的反向传播算法求该层\(W,b\)的梯度,而池化层并没有\(W,b\),也不用求\(W,b\)的梯度。只有卷积层的\(W,b\)需要求出。
注意到卷积层\(z\)和\(W,b\)的关系为:$$z^l = a{l-1}*Wl +b$$
因此我们有:$$\frac{\partial J(W,b)}{\partial W{l}}=a *\delta^l$$
注意到此时卷积核并没有反转,主要是此时是层内的求导,而不是反向传播到上一层的求导。具体过程我们可以分析一下。
和第4节一样的一个简化的例子,这里输入是矩阵,不是张量,那么对于第l层,某个个卷积核矩阵W的导数可以表示如下:$$\frac{\partial J(W,b)}{\partial W_{pq}^{l}} = \sum\limits_i\sum\limits_j(\delta_{ij}la_{i+p-1,j+q-1})$$
假设我们输入\(a\)是4x4的矩阵,卷积核\(W\)是3x3的矩阵,输出\(z\)是2x2的矩阵,那么反向传播的\(z\)的梯度误差\(\delta\)也是2x2的矩阵。
那么根据上面的式子,我们有:$$\frac{\partial J(W,b)}{\partial W_{11}^{l}} = a_{11}\delta_{11} + a_{12}\delta_{12} + a_{21}\delta_{21} + a_{22}\delta_{22}$$
\[\frac{\partial J(W,b)}{\partial W_{12}^{l}} = a_{12}\delta_{11} + a_{13}\delta_{12} + a_{22}\delta_{21} + a_{23}\delta_{22} \]\[\frac{\partial J(W,b)}{\partial W_{13}^{l}} = a_{13}\delta_{11} + a_{14}\delta_{12} + a_{23}\delta_{21} + a_{24}\delta_{22} \]\[\frac{\partial J(W,b)}{\partial W_{21}^{l}} = a_{21}\delta_{11} + a_{22}\delta_{12} + a_{31}\delta_{21} + a_{32}\delta_{22} \]最终我们可以一共得到9个式子。整理成矩阵形式后可得:
\[\frac{\partial J(W,b)}{\partial W^{l}} =\left( \begin{array}{ccc} a_{11}&a_{12}&a_{13}&a_{14} \\ a_{21}&a_{22}&a_{23}&a_{24} \\ a_{31}&a_{32}&a_{33}&a_{34} \\ a_{41}&a_{42}&a_{43}&a_{44} \end{array} \right) * \left( \begin{array}{ccc} \delta_{11}& \delta_{12} \\ \delta_{21}&\delta_{22} \end{array} \right) \]从而可以清楚的看到这次我们为什么没有反转的原因。
而对于b,则稍微有些特殊,因为\(\delta^l\)是高维张量,而\(b\)只是一个向量,不能像DNN那样直接和\(\delta^l\)相等。通常的做法是将\(\delta^l\)的各个子矩阵的项分别求和,得到一个误差向量,即为\(b\)的梯度:$$\frac{\partial J(W,b)}{\partial b^{l}} = \sum\limits_{u,v}(\delta^l)_{u,v}$$
2 CNN的实现
2.1 CNN模型的封装
Model 就是我们唯一提供给用户的可以使用的类。
class Model
{
public:
Model(){}
void add_conv( uint16_t stride, uint16_t extend_filter, uint16_t number_filters, tdsize in_size );
void add_relu( tdsize in_size );
void add_pool( uint16_t stride, uint16_t extend_filter, tdsize in_size );
void add_fc( tdsize in_size, int out_size );
tdsize& output_size();
int predict();
tensor_t<float>& predict_info();
void forward( tensor_t<float>& data );
float train( tensor_t<float>& data, tensor_t<float>& label );
private:
vector<layer_t*> layers;
};
首先是构建网络结构,一套神经网络CNN 模型是由若干层网络构成,Model 里的 vector<layer_t*> layers 存了指向每一层 Layer 的指针,然后增加不同 Layer 的接口分别是 add_conv ,add_pool , add_fc ,add_relu ,不同的网络层需要的参数不一样,用户按需要自定义。

其次是训练,一次只能喂一张图片进去,需要提供输入图像和它的 label ,训练需要先将输入数据正向传播一遍然后得到此次的输出(一个10维的向量);将得到的输出再倒序一层一层求偏导反向传播回去;反向传播结束后我们就得到了每一层输入的偏导,以及每一层卷积核(或权重)的偏导;然后 fix 每一层的权重(梯度下降更改权重);最后计算误差。
//Model的train函数
float train( tensor_t<float>& data, tensor_t<float>& label )
{
forward( data );
auto res_info = layers.back()->out - label;//得到10维的向量
for ( int i = layers.size() - 1; i >= 0; i-- )
layers[i]->calc_grads( i < layers.size() - 1 ? layers[i + 1]->grads_in : res_info );//反向传播回去,每一层的方向传播都需要下一层的偏导
for ( int i = 0; i < layers.size(); i++ )
layers[i]->fix_weights();//梯度下降更改权重
float err = 0;
for ( int i = 0; i < 10; i++ ){
float x = label(i, 0, 0) - res_info(i, 0, 0);
err += x*x ;//计算误差
}
return sqrt(err) * 100;
}
其中正向传播 forward 需要喂一张输入图片进去,然后顺序调用每一层 Layer 的 activate 。
//Model的forward函数
void forward( tensor_t<float>& data ){
for ( int i = 0; i < layers.size(); i++ )
layers[i]->activate( i ? layers[i - 1]->out : data );//调用每一层的activate需要喂上一层的输出
}
最后是预测,predict 返回正向传播完后得到答案即预测的数字是哪一个。predict_info 返回最后得到的答案向量。
//Model的predict函数
int predict(){
int ans = 0;
for( int i = 0; i < 10; i++ )
if( layers.back()->out( i, 0, 0 ) > layers.back()->out( ans, 0, 0 ) )
ans = i ;
return ans;
}
tensor_t<float>& predict_info(){
return layers.back()->out;
}
2.2 Layer的基类
为什么需要多态:可以发现不同类型的 Layer 要处理的算法不同,各自进行的计算和存的变量也不同,用到C++的多态可以方便函数的调用以及其他等方面。
Layer基类的虚函数有:activate 正向传播,calc_grads 反向传播求梯度,fix_weights 修改权重。
//layer基类代码
enum class layer_type
{
conv,
fc,
relu,
pool,
dropout_layer
};
class layer_t
{
public:
layer_type type;//layer的类别
tensor_t<float> grads_in;//输入变量的偏导
tensor_t<float> in;//输入
tensor_t<float> out;//输出
layer_t( layer_type type_, tdsize in_size, tdsize out_size ):
type( type_ ),
in( in_size.x, in_size.y, in_size.z ),
grads_in( in_size.x, in_size.y, in_size.z ),
out( out_size.x, out_size.y, out_size.z )
{
}
virtual ~layer_t(){}
virtual void activate( tensor_t<float>& in )=0; //需要传入输入变量
virtual void fix_weights()=0;
virtual void calc_grads( tensor_t<float>& grad_next_layer )=0; //需要传入输出变量的grad
};
2.3 卷积层(convolutional layer)
卷积层是CNN最核心的网络层,输入是三维的 tensor ,输出是三维的 tensor 。
//卷积层代码
class conv_layer_t: public layer_t//继承基类
{
public:
std::vector<tensor_t<float>> filters; //卷积核
std::vector<tensor_t<gradient_t>> filter_grads; //卷积核的grad
uint16_t stride; //步长
uint16_t extend_filter; //卷积核的大小
conv_layer_t( uint16_t stride, uint16_t extend_filter, uint16_t number_filters, tdsize in_size );
point_t map_to_input( point_t out, int z );//输出的变量 out 对应的输入的范围,即此变量是输入的哪个位置作用了卷积核得来的
struct range_t
{
int min_x, min_y, min_z;
int max_x, max_y, max_z;
};
int GET_R( float f, int max, bool lim_min );
range_t map_to_output( int x, int y );//输入变量的位置 (x,y) 对应的有贡献的输出的范围
void activate( tensor_t<float>& in );
void fix_weights();
void calc_grads( tensor_t<float>& grad_next_layer );
};
首先我们在构建CNN结构时会new一个 conv_layer_t 的对象,构造函数参数有步长,卷积核大小,卷积核数量,输入tensor的大小。
//卷积核的初始化
neww( i, j, z ) = 1.0f / N * rand() / 2147483647.0; //随机的值是有讲究的,这个是CNN常用的卷积核随机初值设置
其次是正向传播,直接模拟,不赘述。
然后是反向传播,核心考虑就是 in -> out 的过程中,每一个 in 的变量贡献到不同的 out 变量有不同的系数(显然系数是卷积核里的变量值),所以反向传播时,每个 in 变量的 grad 就等于 \(\sum\) 它正向贡献到的 out 变量的 grad *贡献的系数。除了 in 变量的 grad 之外,还有每个卷积核的变量的偏导,那么这个就很简单了,同样也是等于 \(\sum\) 它正向贡献到的 out 变量的 grad *贡献的系数,显然系数是 in 中的变量值。所以对于每个 in 变量求出它正向传播时贡献的范围,然后反向求梯度即可。
//卷积层反向传播核心代码
for ( int x = 0; x < in.size.x; x++ )
for ( int y = 0; y < in.size.y; y++ ){
range_t rn = map_to_output( x, y );
for ( int z = 0; z < in.size.z; z++ ){
float sum_error = 0;
//out[i, j, k] -> in[x, y, z] 有贡献的位置
for ( int i = rn.min_x; i <= rn.max_x; i++ ){
int minx = i * stride;
for ( int j = rn.min_y; j <= rn.max_y; j++ ){
int miny = j * stride;
for ( int k = rn.min_z; k <= rn.max_z; k++ ){
//贡献的系数 -> 第k个核作用 out[ i, j, k] 对应的in区域,in[x, y, z] 的系数
int K = filters[k]( x - minx, y - miny, z );
//系数 * 偏导
sum_error += K * grad_next_layer( i, j, k );
//卷积核 grad 同理
filter_grads[k]( x - minx, y - miny, z ).grad += in( x, y, z ) * grad_next_layer( i, j, k );
}
}
}
//更新 in 的 grad
grads_in( x, y, z ) = sum_error;
}
}
最后是更新权重,每次调 fix_weight 之前已经把反向传播过了,所以 grad 已经求过了,可以直接 SGD 梯度下降法更新权重。
//卷积层更新梯度
void fix_weights() override{
for ( int a = 0; a < filters.size(); a++ )
for ( int i = 0; i < extend_filter; i++ )
for ( int j = 0; j < extend_filter; j++ )
for ( int z = 0; z < in.size.z; z++ ){
float& w = filters[a].get( i, j, z );
gradient_t& grad = filter_grads[a]( i, j, z );
w = update_weight( w, grad );
update_gradient( grad );
}
}
2.4 全连接层(fc layer)
全连接层是 CNN 神经网络的最后一层,我们在实现的时候默认了 fc layer 是最后一层,所以在 fc layer 最后要经过 sigmoid 函数。
其实你会发现fc layer就是一个特殊的卷积层,只不过卷积核大小和输入的大小相等了而已。
2.5 其他层
其他层的实现方法都大同小异,详情请参考代码,欢迎提问。
2.6 算法优化
传统的 Stochastic Gradient Descent(SGD)用于寻找函数的局部最小值。SGD 在每次迭代时只选择一个(随机梯度下降)或一小批(小批量梯度下降)样本来估计梯度并更新模型参数。SGD 的更新规则如下:
\[W=W-η\times ∇L \] 其中:
- W 表示模型的参数。
- η 是学习率,这是一个超参数,用于控制每次参数更新的步长。
- ∇L 是损失函数 L 对模型参数 W 的梯度,这个梯度是通过在一个样本或一小批样本上计算得出的。
我们在传统的 SGD 算法上进行了优化,使用了Momentum 和 weight decay 两个 trick 优化 SGD 算法。
Momentum(动量) 主要思想是为梯度下降引入一种“惯性”效果,即权重不仅受当前梯度影响,也受过去梯度影响。具体来说,每次权重更新不仅取决于当前梯度,还取决于过去的权重更新。这种方法可以帮助优化器更快地越过平坦区域,减少学习的震荡,并更有可能找到全局最小值。
Weight Decay(权重衰减) 是一种正则化技术,用于防止模型过拟合。在训练过程中,权重衰减会对模型的权重参数进行惩罚,这通常通过在损失函数中添加一个正则化项来实现。这个正则化项是模型权重的 L2 范数(平方和)与一个衰减系数的乘积。通过这种方式,权重衰减倾向于使模型的权重尽可能小,从而减少模型复杂度,并提高其泛化能力。
同时使用这两种技术可以更快地收敛训练过程,减少过拟合,提高模型在未见过的数据上的表现。总的来说,Momentum 可以帮助 SGD 更快地收敛,而 Weight Decay 可以帮助防止模型过拟合。数学形式如下:
- 速度更新:\(v = γ \times v - η \times ( ∇L + λ * W )\)
- 权重更新:\(W = W + v\)
其中:
- v 是速度变量(动量项),
- γ 是动量系数,
- η 是学习率,
- ∇L 是损失函数的梯度,
- W 是模型权重,
- λ 是权重衰减系数。
在代码上的表现就是
float update_weight( float w, gradient_t& grad, float multp = 1 ){
w -= LEARNING_RATE * (grad.grad + grad.oldgrad * MOMENTUM) * multp + LEARNING_RATE * WEIGHT_DECAY * w;
return w;
}
void update_gradient( gradient_t& grad ){
grad.oldgrad = (grad.grad + grad.oldgrad * MOMENTUM);
}
3 模型的训练效果
训练的CNN网络结构如下
Model M;
M.add_conv( 1, 5, 10, {28, 28, 1} );
M.add_relu( M.output_size() );
M.add_pool( 2, 2, M.output_size() );
M.add_conv( 1, 3, 12, M.output_size() );
M.add_relu( M.output_size() );
M.add_pool( 2, 2, M.output_size() );
M.add_fc( M.output_size(), 10 );
3.1 训练速度
在我的笔记本上跑的速度约为 \(350.8\ 张图/秒\) (处理器Intel(R) Core(TM) i5-1035G1 CPU @ 1.00GHz 1.19 GHz)
3.2 正确率
-
2 epoch
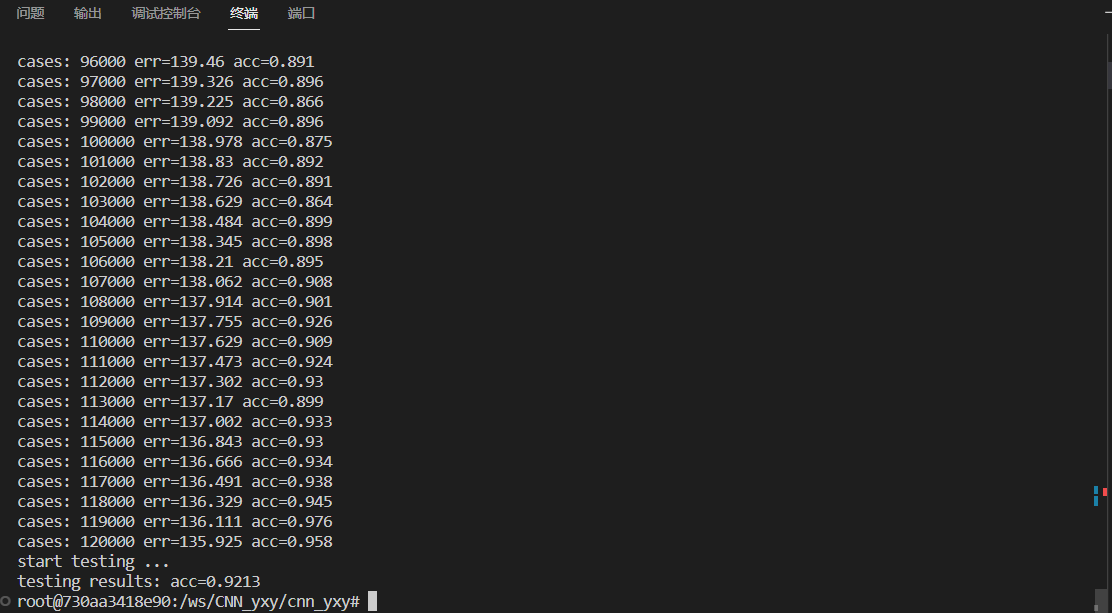
-
10 epoch
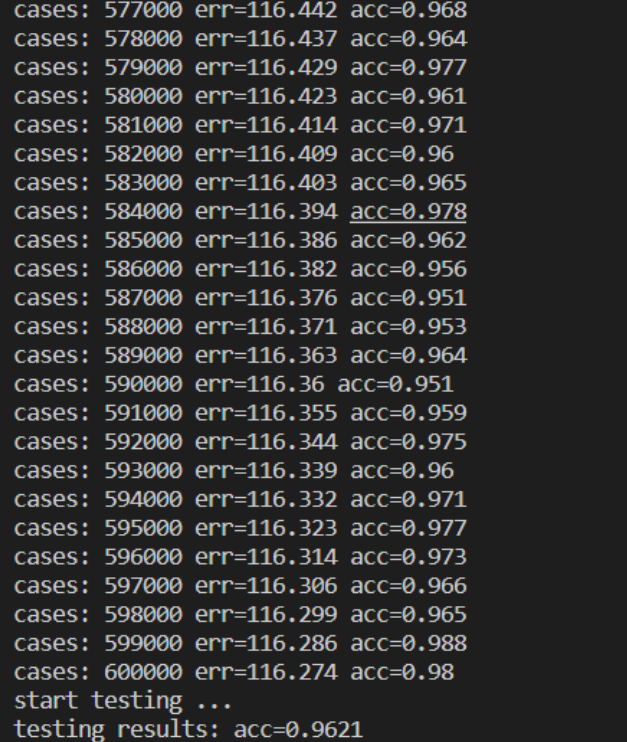
-
50 epoch
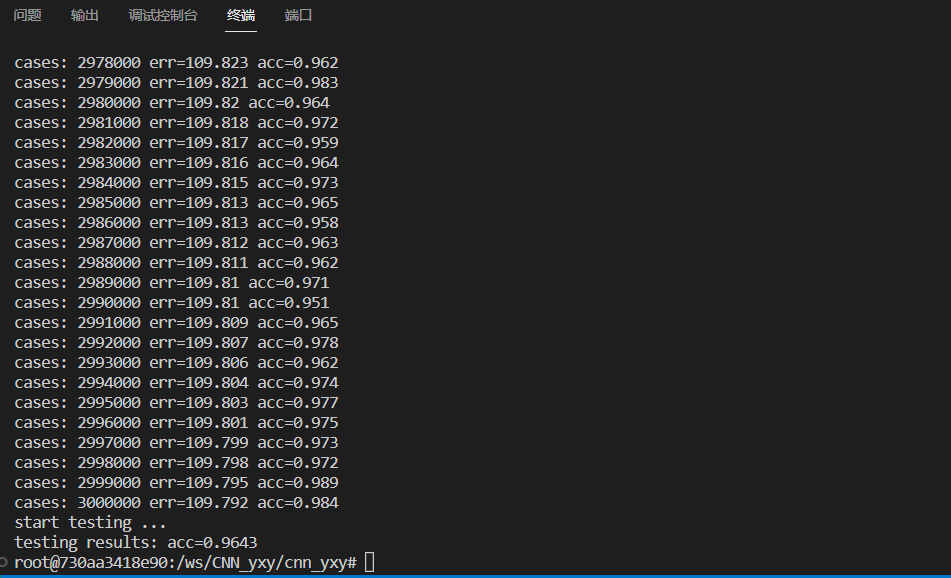
3.3 瓶颈
- 速度慢后续导致准确率上不去
- 未实现 CNN 的多通道