摘要:保证线程安全是 Java 并发编程必须要解决的重要问题,本文和大家聊聊Java中的并发原子类,看它如何确保多线程的数据一致性。
本文分享自华为云社区《学了这么久的高并发编程,连Java中的并发原子类都不知道?这也太Low了吧》,作者:冰 河。
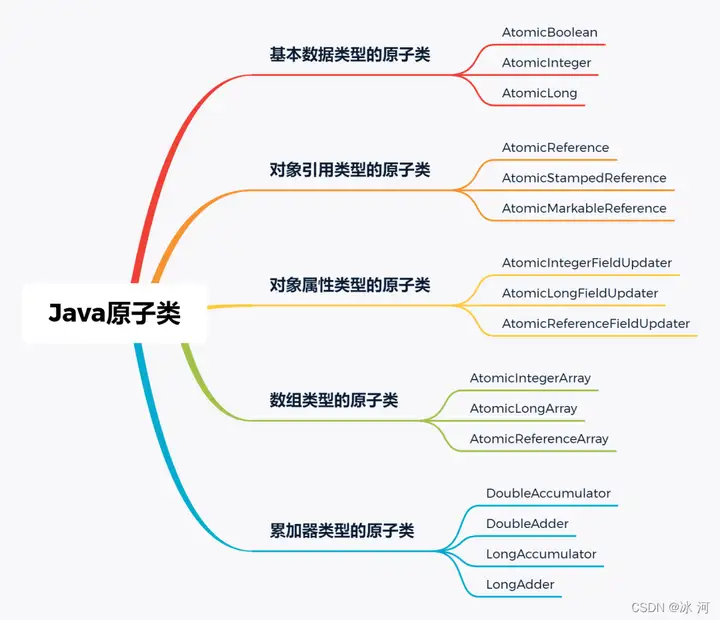
今天我们一起来聊聊Java中的并发原子类。在 java.util.concurrent.atomic包下有很多支持并发的原子类,某种程度上,我们可以将其分成:基本数据类型的原子类、对象引用类型的原子类、数组类型的原子类、对象属性类型的原子类和累加器类型的原子类 五大类。
接下来,我们就一起来看看这些并发原子类吧。
基本数据类型的原子类
基本数据类型的原子类包含:AtomicBoolean、AtomicInteger和AtomicLong。
打开这些原子类的源码,我们可以发现,这些原子类在使用上还是非常简单的,主要提供了如下这些比较常用的方法。
- 原子化加1或减1操作
//原子化的i++ getAndIncrement() //原子化的i-- getAndDecrement() //原子化的++i incrementAndGet() //原子化的--i decrementAndGet()
- 原子化增加指定的值
//当前值+=delta,返回+=前的值 getAndAdd(delta) //当前值+=delta,返回+=后的值 addAndGet(delta)
- CAS操作
//CAS操作,返回原子化操作的结果是否成功 compareAndSet(expect, update)
- 接收函数计算结果
//结果数据可通过传入func函数来计算 getAndUpdate(func) updateAndGet(func) getAndAccumulate(x,func) accumulateAndGet(x,func)
对象引用类型的原子类
对象引用类型的原子类包含:AtomicReference、AtomicStampedReference和AtomicMarkableReference。
利用这些对象引用类型的原子类,可以实现对象引用更新的原子化。AtomicReference提供的原子化更新操作与基本数据类型的原子类提供的更新操作差不多,只不过AtomicReference提供的原子化操作常用于更新对象信息。这里不再赘述。
需要特别注意的是:使用对象引用类型的原子类,要重点关注ABA问题。
关于ABA问题,文章的最后部分会说明。
好在AtomicStampedReference和AtomicMarkableReference这两个原子类解决了ABA问题。
AtomicStampedReference类中的compareAndSet的方法签名如下所示。
boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)
可以看到,AtomicStampedReference类解决ABA问题的方案与乐观锁的机制比较相似,实现的CAS方法增加了版本号。只有expectedReference的值与内存中的引用值相等,并且expectedStamp版本号与内存中的版本号相同时,才会将内存中的引用值更新为newReference,同时将内存中的版本号更新为newStamp。
AtomicMarkableReference类中的compareAndSet的方法签名如下所示。
boolean compareAndSet(V expectedReference, V newReference, boolean expectedMark, boolean newMark)
可以看到,AtomicMarkableReference解决ABA问题的方案就更简单了,在compareAndSet方法中,新增了boolean类型的校验值。这些理解起来也比较简单,这里,我也不再赘述了。
对象属性类型的原子类
对象属性类型的原子类包含:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater。
利用对象属性类型的原子类可以原子化的更新对象的属性。值得一提的是,这三个类的对象都是通过反射的方式生成的,如下是三个类的newUpdater()方法。
//AtomicIntegerFieldUpdater的newUpdater方法
public static <U> AtomicIntegerFieldUpdater<U> newUpdater(Class<U> tclass, String fieldName)
//AtomicLongFieldUpdater的newUpdater方法
public static <U> AtomicLongFieldUpdater<U> newUpdater(Class<U> tclass, String fieldName)
//AtomicReferenceFieldUpdater的newUpdater方法
public static <U,W> AtomicReferenceFieldUpdater<U,W> newUpdater(Class<U> tclass,
Class<W> vclass,
String fieldName)
这里,我们不难看出,在AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater三个类的newUpdater()方法中,只有传递的Class信息,并没有传递对象的引用信息。如果要更新对象的属性,则一定要使用对象的引用,那对象的引用是在哪里传递的呢?
其实,对象的引用是在真正调用原子操作的方法时传入的。这里,我们就以compareAndSet()方法为例,如下所示。
//AtomicIntegerFieldUpdater的compareAndSet()方法 compareAndSet(T obj, int expect, int update) //AtomicLongFieldUpdater的compareAndSet()方法 compareAndSet(T obj, long expect, long update) //AtomicReferenceFieldUpdater的compareAndSet()方法 compareAndSet(T obj, V expect, V update)
可以看到,原子化的操作方法仅仅是多了一个对象的引用,使用起来也非常简单,这里,我就不再赘述了。
另外,需要注意的是:使用AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater更新对象的属性时,对象属性必须是volatile类型的,只有这样才能保证可见性;如果对象属性不是volatile类型的,newUpdater()方法会抛出IllegalArgumentException这个运行时异常。
数组类型的原子类
数组类型的原子类包含:AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray。
利用数组类型的原子类可以原子化的更新数组里面的每一个元素,使用起来也非常简单,数组类型的原子类提供的原子化方法仅仅是在基本数据类型的原子类和对象引用类型的原子类提供的原子化方法的基础上增加了一个数组的索引参数。
例如,我们以compareAndSet()方法为例,如下所示。
//AtomicIntegerArray的compareAndSet()方法 compareAndSet(int i, int expect, int update) //AtomicLongArray的compareAndSet()方法 compareAndSet(int i, long expect, long update) //AtomicReferenceArray的compareAndSet()方法 compareAndSet(int i, E expect, E update)
可以看到,原子化的操作方法仅仅是对多了一个数组的下标,使用起来也非常简单,这里,我就不再赘述了。
累加器类型的原子类
累加器类型的原子类包含:DoubleAccumulator、DoubleAdder、LongAccumulator和LongAdder。
累加器类型的原子类就比较简单了:仅仅支持值的累加操作,不支持compareAndSet()方法。对于值的累加操作,比基本数据类型的原子类速度更快,性能更好。
使用原子类实现count+1
在并发编程领域,一个经典的问题就是count+1问题。也就是在高并发环境下,如何保证count+1的正确性。一种方案就是在临界区加锁来保护共享变量count,但是这种方式太消耗性能了。
如果使用Java提供的原子类来解决高并发环境下count+的问题,则性能会大幅度提升。
简单的示例代码如下所示。
public class IncrementCountTest{
private AtomicLong count = new AtomicLong(0);
public void incrementCountByNumber(int number){
for(int i = 0; i < number; i++){
count.getAndIncrement();
}
}
}
可以看到,原子类实现count+1问题,既没有使用synchronized锁,也没有使用Lock锁。
从本质上讲,它使用的是无锁或者是乐观锁方案解决的count+问题,说的具体一点就是CAS操作。
CAS原理
CAS操作包括三个操作数:需要读写的内存位置(V)、预期原值(A)、新值(B)。如果内存位置与预期原值的A相匹配,那么将内存位置的值更新为新值B。
如果内存位置与预期原值的值不匹配,那么处理器不会做任何操作。
无论哪种情况,它都会在 CAS 指令之前返回该位置的值。(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值。)
简单点理解就是:位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只返回位置V现在的值。这其实和乐观锁的冲突检测+数据更新的原理是一样的。
ABA问题
因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供的AtomicStampedReference类和AtomicMarkableReference类能够解决CAS的ABA问题。
关于AtomicStampedReference类和AtomicMarkableReference类前文有描述,这里不再赘述。
标签:int,Java,CAS,编程,原子,并发,原子化,对象,compareAndSet From: https://www.cnblogs.com/huaweiyun/p/17286931.html