目录
1. 题目
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
提示:
节点总数 <= 1000
作者:Krahets
链接:https://leetcode.cn/leetbook/read/illustration-of-algorithm/5vawr3/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2. 解题思路
这一题和之前的剑指 Offer 32 - I一样,,还是用队列实现层次遍历。需要注意的是返回结果的数据结构变化。
问题的难点在于如何在队列进出的时候分清每一层的结点。
在实际的遍历过程中,每一层的结点是集中出现的,并且存在一个时间点,队列中所有的结点都是属于一个队列的,例如题中的树:
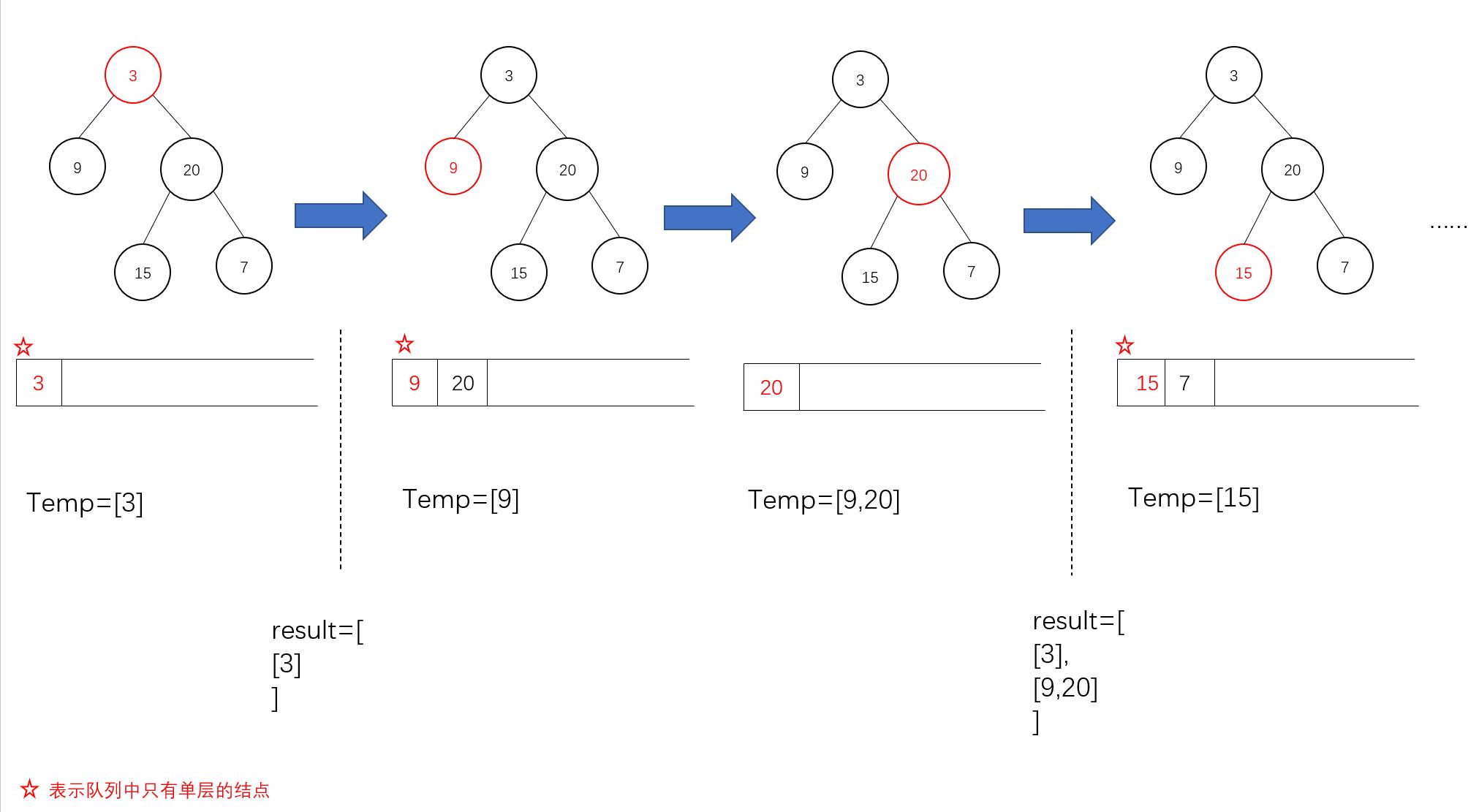
因此,可以在如图所示的特殊时间点获取队列长度,这也是当前层h的结点数,将这些结点集中在一个循环中处理,数值送入一个空列表中,子树结点进栈。当这个循环结束之后,第h层结点已经全部出队,将该层结点的值列表存入结果队列中,同时开启下一轮循环,队列中记录第h+1层的所有结点。
3. 数据类型功能函数总结
//LinkedList
LinkedList<E> listname=new LinkedList<E>();//初始化
LinkedList.add(elment);//在链表尾部添加元素
LinkedList.removeFirst();//取出链表头部元素
LinkedList.size();//获取元素个数
//ArrayList
ArrayList<E> listname=new ArrayList<E>();//初始化
ArrayList.add(elment);//在数组最后插入元素
ArrayList.stream().mapToInt(Integer::valueOf).toArray();//ArrayList<Integer>转为int[]
ArrayList.toArray();//Arraylist转为数组,适用于String--char[]
//List<List<Integer>>
List<List<Integer>> name=new ArrayList<>();//或者是 = new LinkedList<>()
//错误写法: List<List<Integer>> name=new List<List<Integer>>();
4. java代码
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result=new ArrayList<>();//最后返回的结果
LinkedList<TreeNode> queue=new LinkedList<TreeNode>();//队列
if(root==null){
return result;
}
else{
queue.add(root);
while(queue.size()!=0){
int size = queue.size();
ArrayList<Integer> temp=new ArrayList<Integer>();
while(size>0){
TreeNode node=queue.removeFirst();
temp.add(node.val);
//添加左右子树
if(node.left!=null){
queue.add(node.left);
}
if(node.right!=null){
queue.add(node.right);
}
size--;
}
result.add(temp);
//temp.clear();
}
return result;
}
}
}
5. 踩坑记录
一开始,关于每一层节点值的统计写法如下:
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result=new ArrayList<>();
ArrayList<Integer> temp=new ArrayList<Integer>();//***列表定义写在此处而不是while循环中
LinkedList<TreeNode> queue=new LinkedList<TreeNode>();
if(root==null){
return result;
}
else{
queue.add(root);
while(queue.size()!=0){
int size = queue.size();
//ArrayList<Integer> temp=new ArrayList<Integer>();//***
while(size>0){
TreeNode node=queue.removeFirst();
temp.add(node.val);
//添加左右子树
if(node.left!=null){
queue.add(node.left);
}
if(node.right!=null){
queue.add(node.right);
}
size--;
}
result.add(temp);
temp.clear();//***添加clear(),希望下次记录之前将列表清空
}
return result;
}
}
}
这样写忽略了list.add()是进行浅拷贝的,也就是说,如果使用一个列表元素每次清空的话,实际上每层的结果都指向同一个内存地址,后续在此内存地址上的操作将会改变前期的结果。最终出现[[x,y,z][x,y,z][x,y,z]]三个子列表相同的情况。
因此,应该对每一层都创建一个列表元素,从而保证每一层的列表修改不会相互影响。