python基础内容
解释器
编译器:将其他语言翻译成机器语言。
分类
编译器有两种类型,编译和解释(翻译时间点的不同)。
编译型语言:源程序交给编译器,统一编译,一次性执行
解释型语言:逐行解释每一句源代码
对比
执行速度:编译型语言执行速度快,因为直接执行可执行文件。
跨平台能力:一次编写,在任何平台都能执行的文件是可以跨平台的。编译型语言只能在编写的平台执行,而解释型语言,在不同平台上安装不同的解释器就可以实现跨平台。
Python程序设计与执行方式
-
设计目标:简单直观,开源,代码易理解,适用于短期开发
-
设计哲学:优雅、简单、明确(用一种方法,最好是只有一种方法来做一件事,越简单明确越好)
-
特点:完全面向对象、拥有强大的标准库、提供了大量的第三方模块
-
优缺点:简单易学、免费开源、面向对象、丰富的库、可扩展性;运行慢、中文资料少
-
执行程序的方式:
- 解释器 python/python3
python2.x $ python 1.py python 3.x $ python3 1.py python解释器:CPython(官方版本的C语言实现) Jython(可运行在Java平台) IronPython(可运行在.NET Mono平台) PyPy(Python实现的支持JIT即时编译)- 交互式 ipython
----------默认的python shell----------------- 直接终端运行解释器 #优缺点 适合学习或验证python语法或局部代码,但是代码不能保存,也不适合运行太大的程序。 exit()/ctrl d退出 ----------ipython-------------------- interactive 支持自动补全和自动缩进,支持bash shell命令,内置了很多有用的功能和函数 python 3.x使用的是ipython3- 集成开发环境(IDE) pycharm
---------------集成开发环境-------------------- 图形用户界面、代码编辑器、编译器/解释器、调试器
程序执行原理
程序要运行的三个核心硬件:CPU、内存、硬盘
CPU是中央处理器,负责处理数据和计算;
内存是临时存储数据,断电后数据消失,速度快,空间小,通常4/8/46/32G,直接从芯片读取
硬盘是永久存储数据,速度慢,空间大,以T为单位,例如机械式硬盘读取时磁片旋转,磁头挪动
程序执行原理
当要运行程序,操作系统让CPU把程序复制到内存,然后CPU执行内存中的程序代码。
程序要执行,首先要被加载到内存。
Python程序的执行原理
Python是解释型语言,Python程序执行过程:操作系统先让CPU把Python解释器的程序复制到内存中,解释器根据语法规则,从上到下让CPU翻译Python程序中的代码,最后CPU负责执行翻译完成的代码。
程序的作用
处理数据
变量的作用
存储数据
Python语法
python常量与变量
相当于名词部分,表示某些事物
常量
固定的量,不能改变
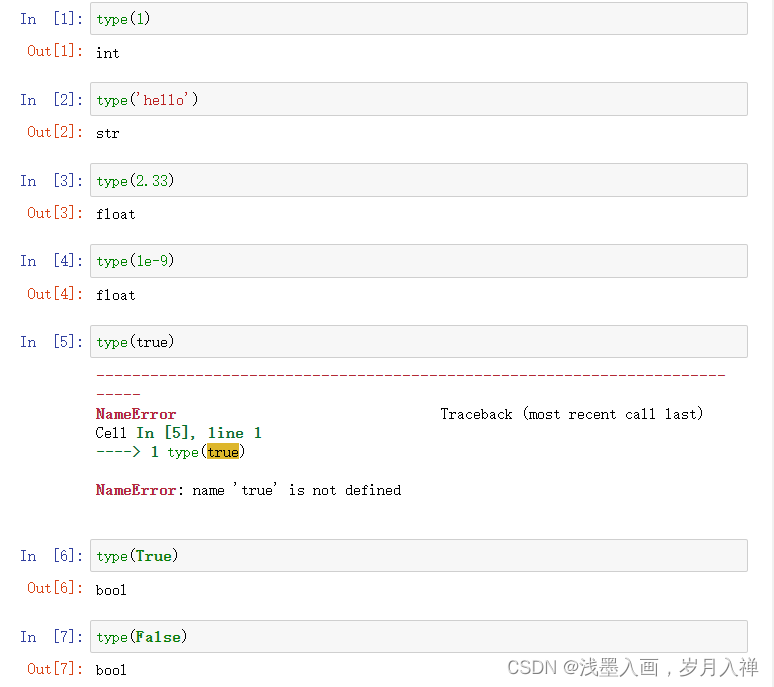
1、数字:整数和浮点数(2.333或1e-9)、虚数
2、字符串:用单引号/双引号/三引号括起来的内容
3、逻辑值:True False
type(*)查看类型
代码举例:
变量
存储不同的值表示不同的内容,可以被更改
命名规范:第一个字符:字母/下划线,由字母、下划线、数字组成,区分大小写
变量名最好表示变量意义
变量在使用前必须赋值,变量赋值后该变量才会被创建。
python运算符与函数
运算符

算术运算符:+-*/加减乘除 //整除(取整数位) %取余 两个星号是乘方,都是双目运算符
代码举例:

函数
通过关键词def定义,函数输入由函数名后括号内的参数定义,结果由return返回
参数由逗号分隔,程序中存在预先定义好的函数,如type和print
函数内有语法缩进
代码举例:

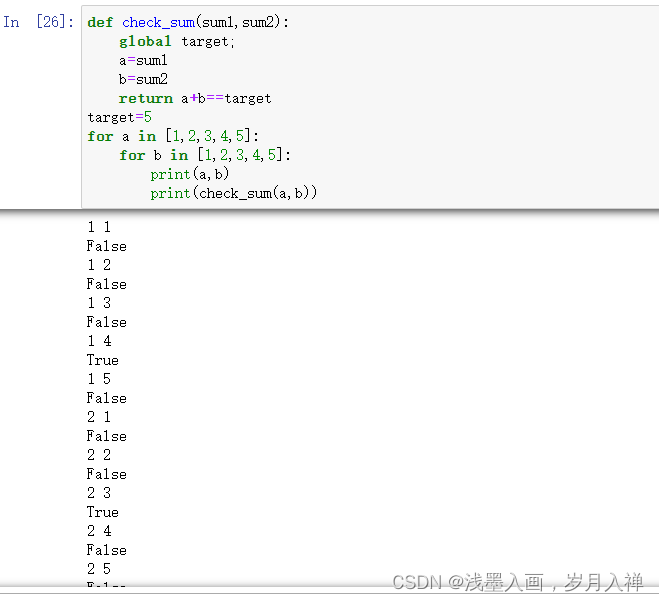
局部变量与全局变量
局部变量:只在函数内部生效的变量
全局变量:在整个代码中都生效的变量
代码举例:

控制流
if else语句、while循环语句、for in循环语句、break停止语句、continue语句,这就不用说了,但凡掌握任何一门语言都知道什么意思
代码形式:
while循环举例:
震惊,没有自增++这个东东

for in循环举例:
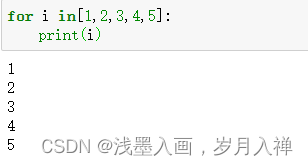
循环可以嵌套
if else语句:
代码举例:

break:停止语句
代码举例:

例题:

我的麻烦的推导过程(呜呜呜):
def Hanshu(k):
a=k
b=20-k
c=20-k+1
p=1
q=1
fenmu=1
fenzi=20
target=1
#排列组合也可以直接写在括号里面
#fenzi(20)/(fenzi(k)*fenzi(20-k))
#p循环k次,乘以0.2
#q循环20-k次,乘以0.8
#可以直接用乘方代替**
while a>0:
p=p*0.2
fenmu=fenmu*a
a=a-1
while b>0:
q=q*0.8
fenzi=fenzi*c
b=b-1
c=c-1
target=fenzi/fenmu*p*q
print(target)
Hanshu(1)
python数据结构
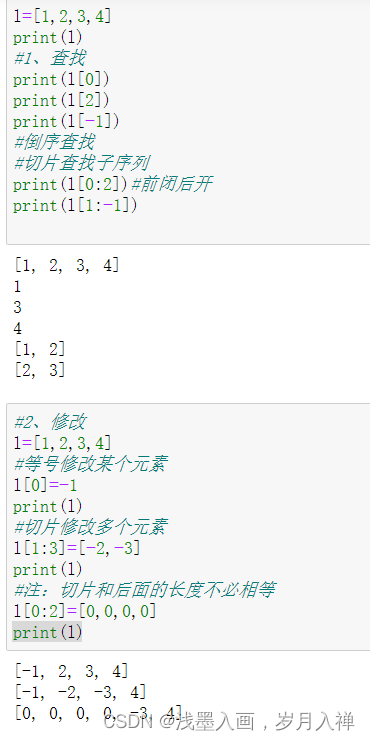
序列List
保存有序项集合的变量,用方括号创建,可以存储不同的数据类型
序列支持:增append、删del、查[]、改=
优点:1、快速向尾部添加元素 2、快速遍历所有元素 3、节省占用计算机内存空间

元组Tuple
保存有序项集合的变量,用圆括号表示
与列表特性几乎一样,但是元组无法被修改
只能查询和全部删除

字典Dict
通过键key与值value相关联,通过键迅速检索到对应的值,键必须是唯一地,通过花括号创建,通过:区分键与值,通过,分隔键值对。
字典支持增删查改。
代码实例:

集合Set
存储无序元素的集合,只考虑存在,不考虑先后顺序,不存在重复元素,通过花括号创建。
支持增删查
优点:1、支持数学集合操作2、快速检索某个元素是否在集合内3、集合内的键值不存在顺序关系

练习题
1、非常经典的一道以前做过很多次的题,用python试试吧!

我的代码:
def Hanshu(nums1,nums2):
num=[]
#序列循环查找,定义一个新序列,定义两个索引项
#如果一个序列已经全部加入,把另一个序列剩余的也加入
i=0
j=0
while True:
if i==len(nums1):
print('添加1')
num.extend(nums2[j:len(nums2)])
i=i+1
break
else:
if j==len(nums2):
print('添加2')
num.extend(nums1[i:len(nums1)])
j=j+1
break
else:
if nums1[i]<=nums2[j]:
print('添加3')
num.append(nums1[i])
i=i+1
else:
if nums1[i]>nums2[j]:
print('添加4')
num.append(nums2[j])
j=j+1
#遍历新的序列,找到最中间的一个或两个数
print(num)
middleNumber=0
if len(num)%2==0:
middleNumber=(num[int(len(num)/2)-1]+num[int(len(num)/2)])/2
else:
middleNumber=num[int((len(num)+1)/2)]
print(middleNumber)
#return middleNumber
nums1=[1,2]
nums2=[3,4]
Hanshu(nums1,nums2)
没有else if的形式,不用写分号,条件不必写括号
序列获取长度len
2、以前的一道题

我的代码:
nums=[2,7,44,11,15,12,3]
target=9
def Hanshu(nums,target):
A=[]
for i in nums:
for j in nums:
if i!=j:
if i+j==target:
A.append(i)
A.append(j)
break
if len(A)!=0:
break
print(A)
Hanshu(nums,target)
python面向对象编程
python是一种基于面向对象设计的编程语言,类和对象
根据功能定义类,产生对象,通过对象的交互实现功能。
理论部分
对象的特性:
1、每个对象都有一个独特的名字以区别于其它对象;2、有属性来描述它的某些特征;3、有一组操作,每个操作决定对象的一种行为。
在python中,对象可以是有型的,如:一个常量、一个变量、一个序列或字典;
也可以是无形的,如:一个函数;
复杂的对象可以由许多简单的对象组成,整个python程序也可以被当作一个对象。
类:
定义对象的模板。产生对象
在python中,类是一组具有相同数据和操作的对象的模板集合。
面向对象编程的特点:
抽象(只强调感兴趣的信息)、封装(只需要知道功能,不需要了解内部实现方式)、继承、多态(不同对象进行相同操作时产生的多种不同的行为方式)
使用class定义类,缩进部分构成类的主体。
使用类名和括号创建对象。
类的变量用于表示类的属性。
对象拥有与类下同等数据和操作,因此通过类创建的对象也拥有相同的变量
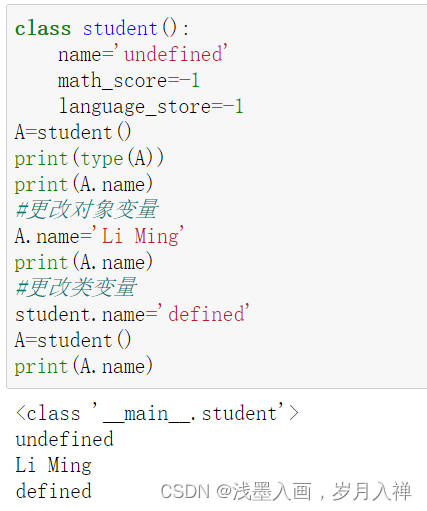
类变量与对象变量:
类变量属于类,更改类变量会影响所有后序由该类创建的对象的属性。
对象变量属于对象,更改对象变量只会影响该对象的属性值。
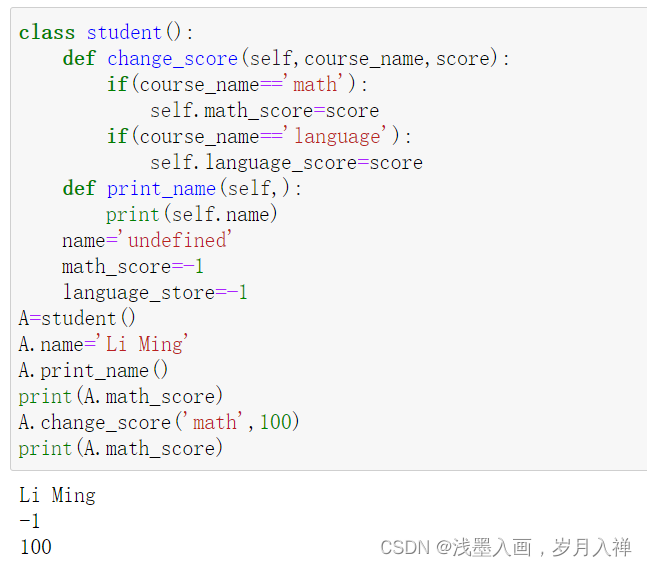
类与对象中的函数:
类函数用于表示类的操作,也叫方法,但是类函数必须有一个额外的self参数
self函数用于在类的内部指向对象本身。
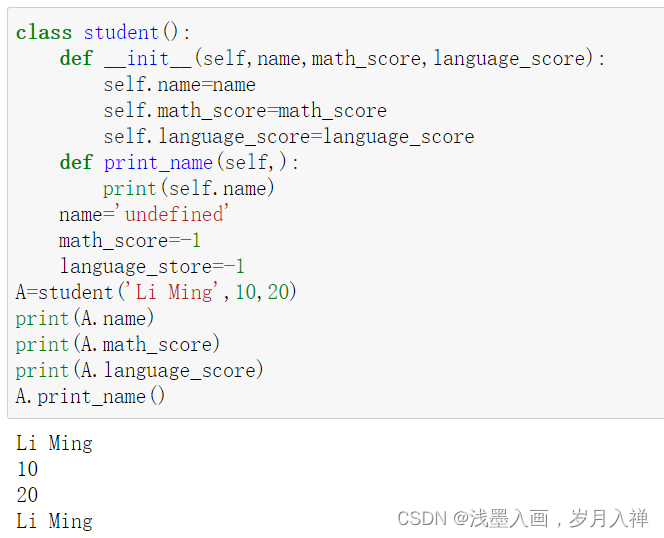
方法_init_:
专门用于初始化对象。在类创建对象时被自动调用
万物皆对象:
int有自己的方法

常量也有自己的方法
format replace split upper lower
代码举例:

函数也可以看作对象,也有自己的方法
def Hanshu(a,b):
return a==b
print(Hanshu.__name__)
输出Hanshu
在线疑惑:用函数名的函数名属性???,都知道了还获取啥呢
数据结构也可以看作对象:

pop相当于删除了
其它数据结构的方法:

python程序也可以是一个对象,也有自己的数据和方法。
程序的对象变量,可以直接调用
可以判断当前运行的程序是不是程序的入口
注释
1、多行注释
"""
多行注释,三个成对引号中间
"""
# 这是单行注释
格式化输出
%s 字符串
%d 有符号十进制整数,%06d:输出的整数显示位数
%f浮点数,%.02f小数点后只显示两位
%%:输出%
a=float(input("价格:"))
b=float(input("重量:"))
print("苹果单价%.02f元/斤,购买了%.02f斤,需要支付%.02f元"%(a,b,a*b))
a=10.01
print("比例为%.02f%%"%(a))
python基础语法
1、elif
没有的else if在python中是elif
2、for in 循环
代码实例:
for i in range(5):
print(i)
for i in 'ABCDE':
print(i)
执行结果:
0
1
2
3
4
A
B
C
D
E
3、数据类型complex
python支持int float和complex三种
complex为虚数,上面没有学到

4、支持字符串拼接、截取
a='Python'
b='hello'
print(a+' '+b)
print(a[1:3])
Python hello
yt
和别的语言一样
5、元组Tuple
上面说到,元组与列表特性一样,但是元组无法被修改,
但是,虽然元组的元素不可变,但是可以包含可变对象,如list
list可以进行相加操作
另外,只有一个元素的元组,必须加逗号!!!!!!

6、字典dict
上次说到,字典的键必须是唯一地,这种说法不严谨,应该说同一个字典中,键必须是唯一的。
另外:键(key)必须使用不可变类型,字典使用键值对的方式存储,具有极快的查找速度。
7、集合set
上次说到,集合是存储无序元素的,需要补充,重复元素在集合中自动被过滤,set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
代码如下:
s={1,2,3,5,3,3,5,6,2}
a=set([1,2,6,6,9,9,10])
print(s)
print(a)
{1, 2, 3, 5, 6}
{1, 2, 6, 9, 10}
8、补充说明:python中的可变数据类型和不可变数据类型
python六大数据类型分别为:数字、字符串、元组、列表、集合、字典。
其中,列表、集合和字典属于可变数据类型,可以进行更改,并且更改后物理地址不会发生改变;
数字、字符串、元组属于不可变数据类型,不可以进行更改,更改后就是一个新的对象,物理地址会发生变化。
python通过id查看内存地址。
代码示例如下所示:
不可变类型:
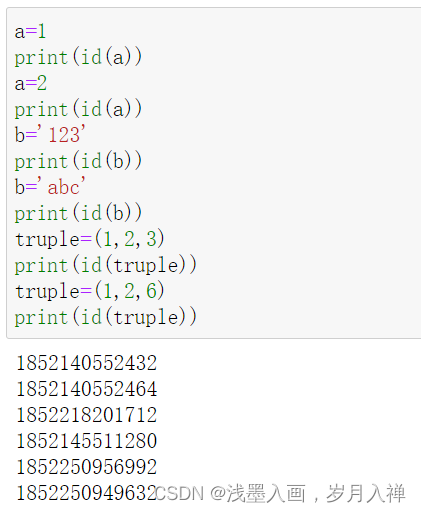
可变类型:
#序列、字典、集合
l=[1,2,3]
print(type(l))
print(id(l))
l[0]=4
print(l)
print(id(l))
d={
"123":'aaa',
"456":'bbb'
}
print(type(d))
print(id(d))
d["123"]="呵呵"
print(d)
print(id(d))
s={1,2,3}
print(type(s))
print(id(s))
s.add(10)
print(s)
print(id(s))
执行结果:
<class 'list'>
1852250983872
[4, 2, 3]
1852250983872
<class 'dict'>
1852243034048
{'123': '呵呵', '456': 'bbb'}
1852243034048
<class 'set'>
1852222727200
{10, 1, 2, 3}
1852222727200
数据结构
数字
Number类型用于存储数值。
1、数学运算math模块及常用函数
菜鸟教程
导入math
代码示例:
import math
print(math.ceil(4.1)) #返回数字的上入整数
print(math.floor(4.9)) #返回数字的下舍整数
print(math.fabs(-10)) #返回数字的绝对值
print(math.sqrt(9)) #返回数字的平方根
print(math.exp(1)) #返回e的x次幂
执行结果:
5
4
10.0
3.0
2.718281828459045
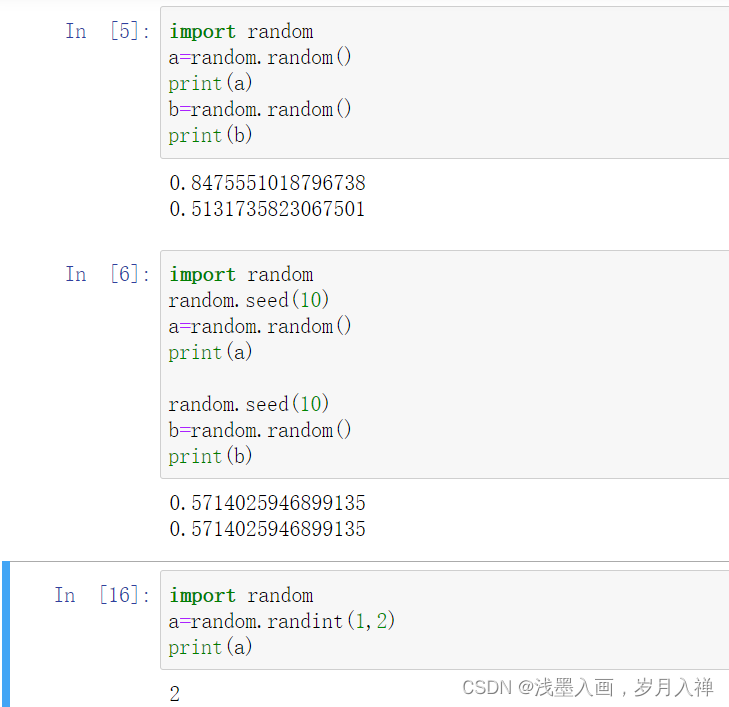
2、python随机数
导入random
1、random的random()生成一个[0,1)的实数
2、random的seed方法设置相同的种子会生成相同的随机数
3、randint(a,b)生成[a,b]的随机整数
代码示例如下:
字符串
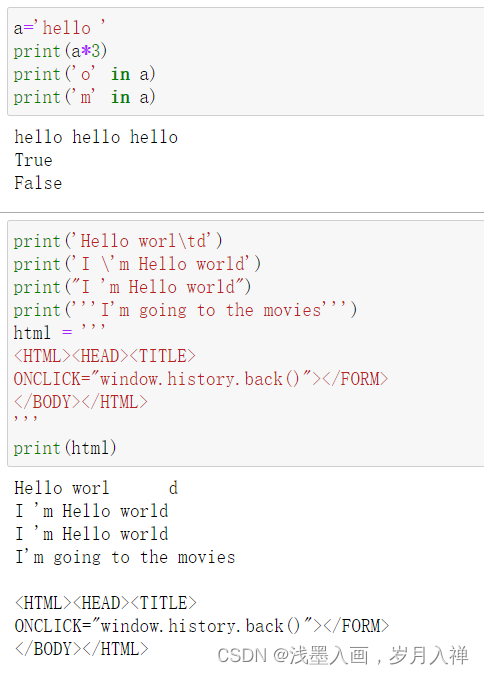
1、字符串重复输出
2、查找字符串是否包含某字符(串) in not in
上次那道包含2020的作业题用in也可以
3、单引号、双引号、三引号及转义
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
三引号:所见即所得
代码示例:
列表
1、查询
让我惊奇的是这段代码
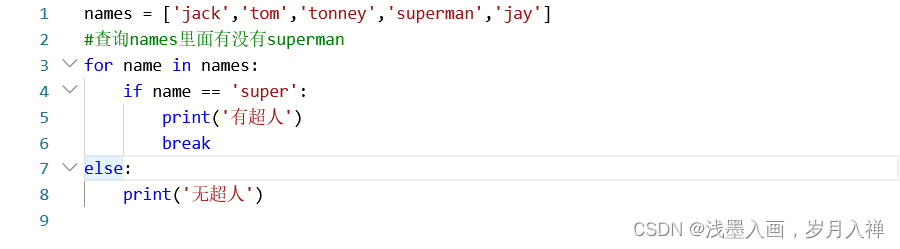
if 和else不在一个档次里面,但是这段代码的执行没有问题,遍历这个列表,有则输出然后停止,没有则打印无超人
2、添加extend函数相当于一个加号
3、修改
根据索引直接使用=赋值修改
或者:
for i in range(len(fruits)):
if '香蕉' in fruits[i]:
fruits[i] = 'banana'
break
print(fruits)
4、删除的三种方法
del和pop根据索引删除,remove根据name删除
del words[1]
words.remove('cat')
words.pop(1)
5、切片

6、sorted函数排序
list=[2, 3, 5, 8, 11, 12, 13, 14, 16, 20]
a=sorted(list)
print(a)
a=sorted(list,reverse=True)
print(a)
[2, 3, 5, 8, 11, 12, 13, 14, 16, 20]
[20, 16, 14, 13, 12, 11, 8, 5, 3, 2]
元组
1、元组步长为-1、-2是反向按照步长输出
2、list可以直接用tuple转元组

3、元组包含一个元素需要加逗号,否则是字符串

4、元组也可以跟字符串一样使用+、*,像列表一样使用一些函数。
比如max min sum len count index in not in
5、元组的拆包与装包问题
#定义一个元组
t3 = (1,2,3)
#将元组赋值给变量a,b,c
a,b,c = t3
#打印a,b,c
print(a,b,c)
1 2 3
当元素个数多,但是定义的变量个数少:先把剩下的装包编程列表,加一个星号
当元素个数少,但是定义的变量个数多:报错喽
字典
1、list可以转为字典 dict方法,前提是列表中的元素都要成对出现
dict3 = dict([('name','杨超越'),('weight',45)])
print(dict3)
#{'name': '杨超越', 'weight': 45}
一些函数如下:
2、items()取键值
dict5 = {'杨超越':165,'虞书欣':166,'上官喜爱':164}
print(dict5.items())
for key,value in dict5.items():
print(key+','+str(value))
#dict_items([('杨超越', 165), ('虞书欣', 166), ('上官喜爱', 164)])
#杨超越,165
#虞书欣,166
#上官喜爱,164
3、values()取所有的值
results = dict5.values()
print(results)
#dict_values([165, 166, 164])
4、keys()取所有的键
names = dict5.keys()
print(names)
#dict_keys(['杨超越', '虞书欣', '上官喜爱'])
5、使用pop和del根据键删除
del dict1['杨超越']
dict1.pop('杨超越')
面向对象
继承
class Person:
def __init__(self,name):
self.name = name
print ('调用父类构造函数')
def eat(self):
print('调用父类方法')
class Student(Person): # 定义子类
def __init__(self):
print ('调用子类构造方法')
def study(self):
print('调用子类方法')
s = Student() # 实例化子类
s.study() # 调用子类的方法
s.eat() # 调用父类方法
'''调用子类构造方法
调用子类方法
调用父类方法
'''
JSON
json是一种轻量级数据交换格式
dumps将python对象编码为json字符串
dumps概述:
可选的参数:
sort_keys=True表示按照字典排序(a到z)输出;
indent参数,代表缩进的位数;
separators参数的作用是去掉,和:后面的空格,传输过程中数据越精简越好。
使用实例:
import json
data = [ { 'b' : 2, 'd' : 4, 'a' : 1, 'c' : 3, 'e' : 5 } ]
json = json.dumps(data, sort_keys=True, indent=4,separators=(',', ':'))
print(json)
'''[
{
"a":1,
"b":2,
"c":3,
"d":4,
"e":5
}
]
'''
loads解码json数据
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}'
text = json.loads(jsonData) #将string转换为dict
print(text)
异常处理try except finally
捕获的异常有很多种......
try:
fh = open("/home/aistudio1/data/testfile01.txt", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print('Error: 没有找到文件或读取文件失败')
else:
print ('内容写入文件成功')
fh.close()
如果data是存在的,那么如果没有是会创建的,否则抛出IO异常
finally中的内容退出try时总会执行的
try:
f = open("/home/aistudio1/data/testfile02.txt", "w")
f.write("这是一个测试文件,用于测试异常!!")
except IOError:
print('Error: 没有找到文件或读取文件失败')
finally:
print('关闭文件')
f.close()
Error: 没有找到文件或读取文件失败
关闭文件
Linux命令
pwd显示当前目录
ls显示该目录下所有文件
cd work到work目录下
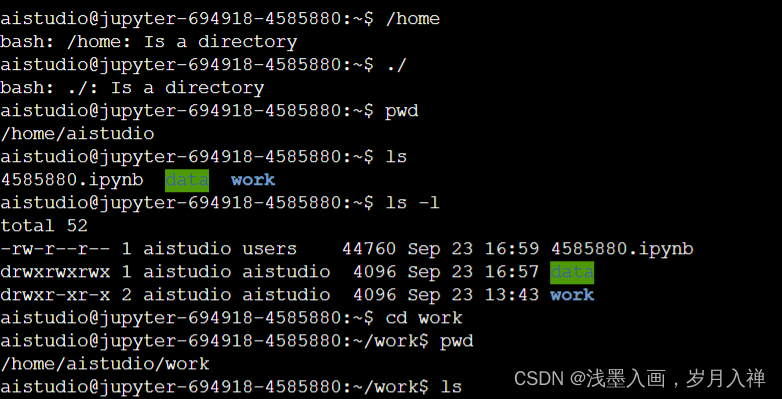
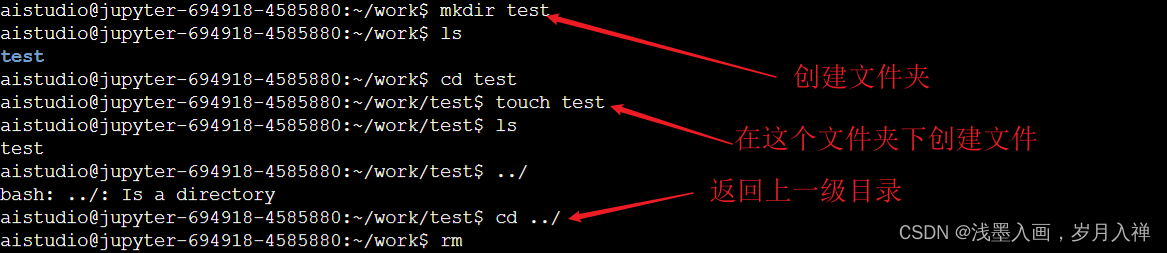
mkdir test创建test文件夹
rm -rf test强制删除
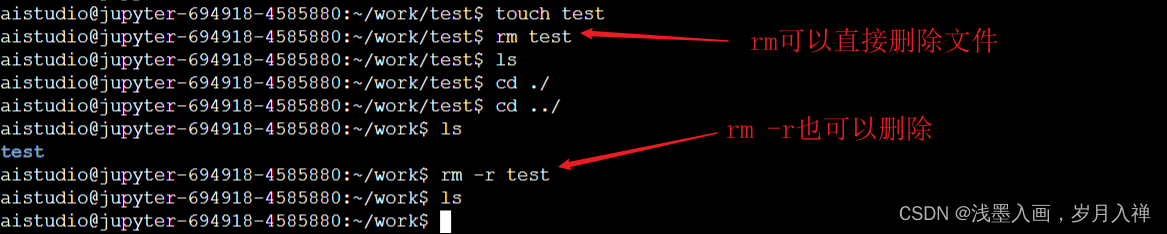
rm test也可以删除
目录一般不能删除,删除就是强制删除
rm -rf xxx删除:-r是递归处理,就是一层一层的删;-f是强制删除。
touch test创建文件

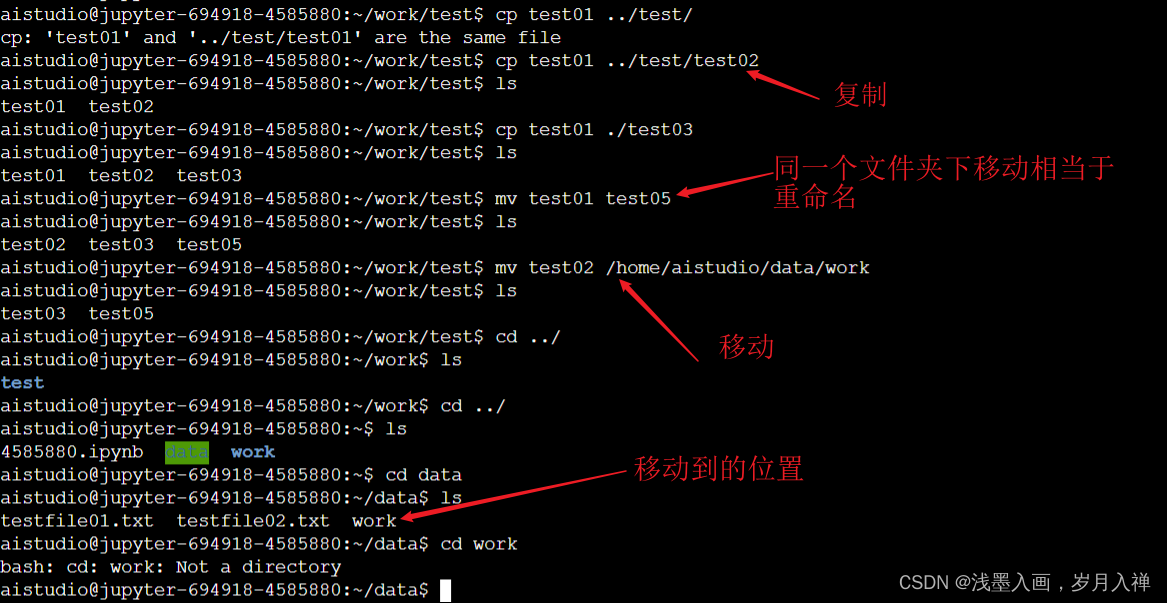
文件复制:cp test01 ./test/
cp test01 test04
移动 mv test01 test05:相当于文件重命名
mv test05 ./test/转移
.表示当前路径
压缩:
gzip
linux压缩文件中最常见的后缀名即为.gz,gzip是用来压缩和解压.gz文件的
-d或--decompress或--uncompress:解压文件;
-r或--recursive:递归压缩指定文件夹下的文件(该文件夹下的所有文件被压缩成单独的.gz文件);
-v或--verbose:显示指令执行过程。
注:gzip命令只能压缩单个文件,而不能把一个文件夹压缩成一个文件(与打包命令的区别)。
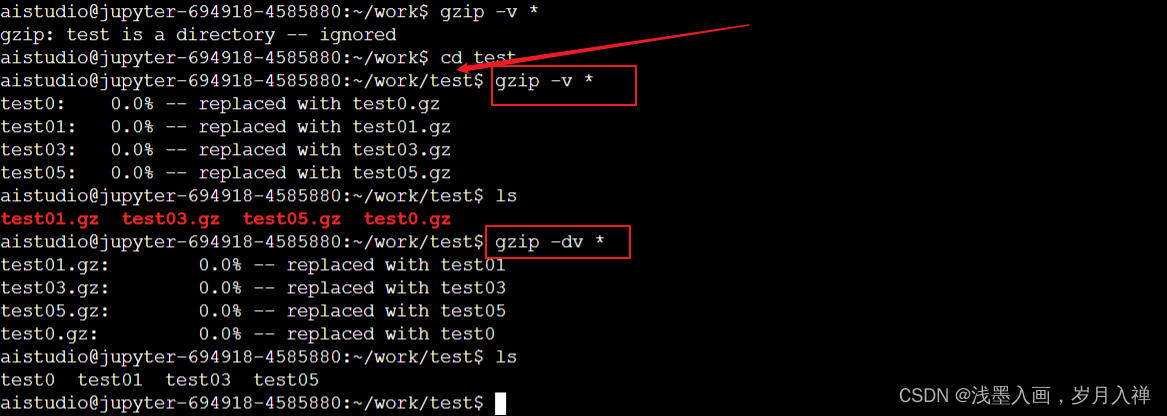
gzip -v(显示压缩过程) *(所有)
gzip只能压缩单个文件,不能压缩路径
解压缩:gzip -dv test02
-d是解压,v就是显示解压过程
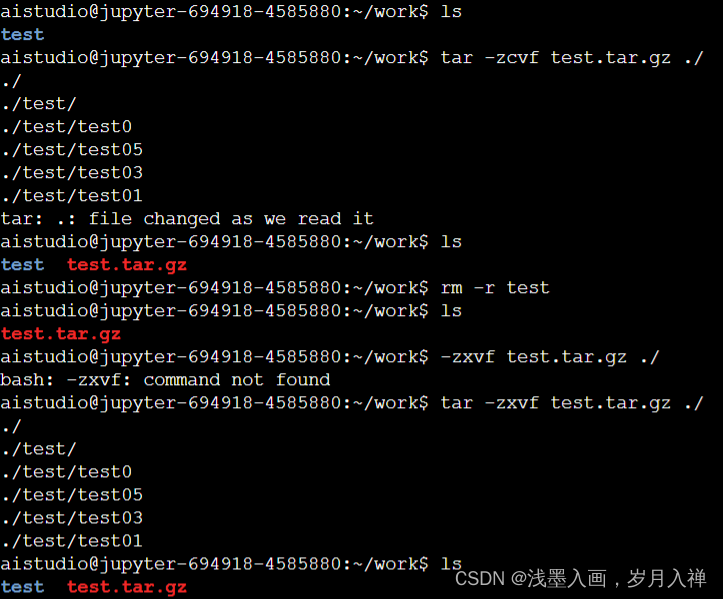
tar
在打包的同时进行压缩
tar -zcvf test.tar.zip ./
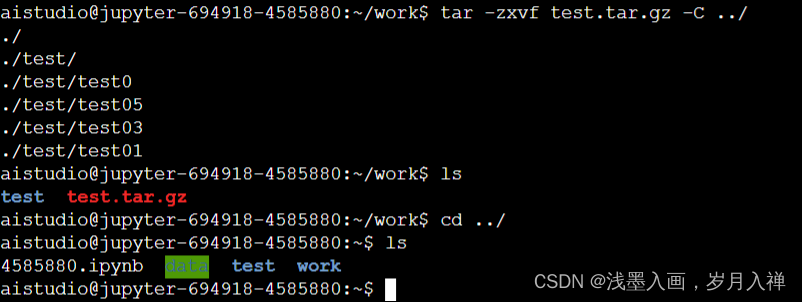
tar -zxvf test.tar.zip -C ../
解压到上一层
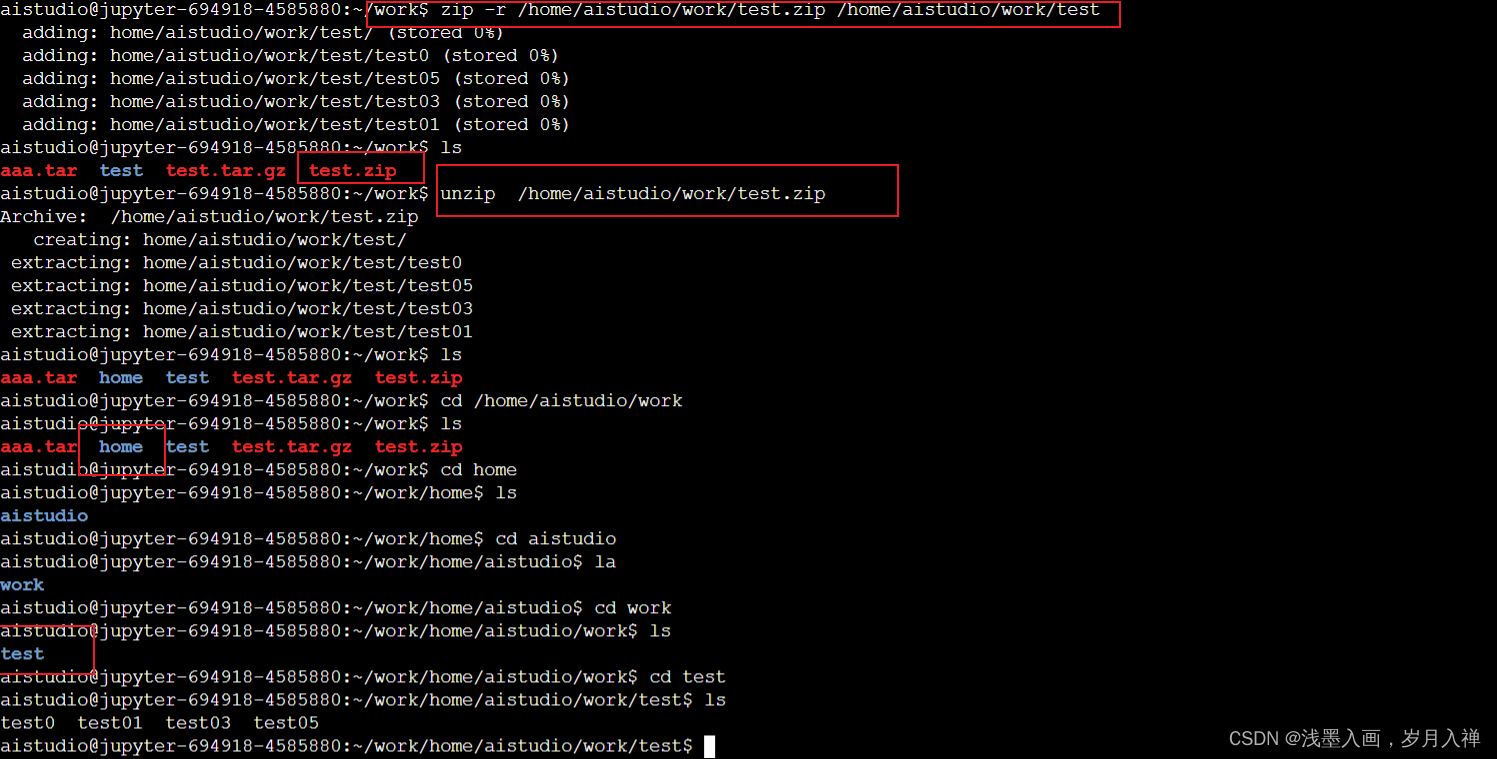
zip和unzip
zip -v test.zip test02
unzip test.zip -d ../data
上一层的data文件夹下
vi编辑:
touch test01
vi test01编辑,按下i进入输入模式(也称为编辑模式),
按下ESC 按钮回到一般模式Ø按下:wq储存后离开vi
esc shift冒号
wq!保存退出
qw不保存退出
有啥用以后再说吧,,,,,
人工智能常用python库
numpy——科学计算库
是使用Python进行科学计算的基础软件包,包含强大的N维数组对象和向量运算。
数组创建(list,tuple,初始占位符)
-
使用array函数从列表list或元组tuple中创建数组。

-
能够创建具有初始占位符的函数(zeros、ones、empty)
(1)numpy.zeros(shape, dtype=float, order='C')
形状:整数或整数元组,定义数组的尺寸。
dtype(可选):数据类型,默认为numpy.float64。
顺序(可选):{‘C’, ‘F’},定义在内存中存储数据的顺序,,即行主要(C样式)或列主要(Fortran样式)
(2)numpy.ones:可以创建指定长度或者形状的全1数组
(3)empty():创建一个数组,其初始内容是随机的,取决于内存的状态

(4)arange():创建一个数组,内容是数字,可定义步长
(5)reshape():重新定义数组的形状

(6)数组的属性(维度、形状、元素个数、元素类型)

(7)补充:随机数组创建
# 创建随机数组
arr1 = np.random.rand(2,2) # 创建指定形状的数组(范围在0至1之间),2行2列
arr2 = np.random.uniform(0,10) # 创建指定范围内的一个数
arr3 = np.random.randint(0,10) # 创建指定范围内的一个整数
arr4 = np.random.normal(0.5, 0.1, (2,2)) # 给定均值/标准差/维度的正态分布
print('arr1:', arr1)
print('arr2:', arr2)
print('arr3:', arr3)
print('arr4:', arr4)
arr1: [[0.76939377 0.94558416]
[0.33003464 0.50933848]]
arr2: 3.4221046449477157
arr3: 6
arr4: [[0.37373368 0.33704847]
[0.53100015 0.51240159]]
数组计算
不用编写循环即可对数据执行批量运算。这通常叫做矢量化(vectorization)。
大小相等的数组之间的任何算术运算都会将运算应用到元素级。同样,数组与标量的算术运算也会将那个标量值传播到各个元素。
1、基本运算(加减乘除幂):行数列数相同,其中数据直接计算

2、矩阵乘法dot(第一个列数等于第二个行数)

3、单个矩阵其它运算有:求和、最大最小值及其下标、均值、转置、多维变一维
sum max min argmin argmax mean tranpose() flatten()

数组索引与切片
取数组的行(列)、某行某列的元素、一行的部分列

pandas——数据分析库
是建立在numpy基础上的高效数据分析处理库,常与numpy和matplotlib一同使用。
核心数据结构有两个。
Series-键值对(键可重复)
Series是一种类似于一维数组的对象,它由一维数组(各种numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
1、使用列表和字典实例化
2、可指定索引、获取值和索引
3、可通过索引(列表)获取单个或一组值
4、可进行加减乘除幂的运算
import numpy as np
a=['a','b','c','d','e']
b=[100,200,100,400,500]
s=pd.Series(a,index=b)
print(s)
print(type(s))
dic={'a':1,'b':2}
print(pd.Series(dic))
print(s.values)
print(s.index)
print(s[100,400])
-------------------------------------
import pandas as pd
s = pd.Series(np.array([1,2,3,4,5]), index=['a', 'b', 'c', 'd', 'e'])
print(s+s)
print(s*s)
print(s**3)
1、实例化
100 a
200 b
100 c
400 d
500 e
dtype: object
<class 'pandas.core.series.Series'>
a 1
b 2
dtype: int64
2、获取值和索引
['a' 'b' 'c' 'd' 'e']
Int64Index([100, 200, 100, 400, 500], dtype='int64')
3、通过索引获取值
100 a
100 c
dtype: object
400 d
100 a
100 c
dtype: object
4、加减乘除运算
a 2
b 4
c 6
d 8
e 10
dtype: int32
a 1
b 4
c 9
d 16
e 25
dtype: int32
a 1
b 8
c 27
d 64
e 125
dtype: int32
5、数据对齐
在算术运算中自动对齐不同索引的数据,Series 和多维数组的主要区别在于, Series 之间的操作会自动基于标签对齐数据。因此,不用顾及执行计算操作的 Series 是否有相同的标签。
obj1 = pd.Series({"Ohio": 35000, "Oregon": 16000, "Utah": 5000})
print(obj1)
obj2 = pd.Series({"California": np.nan, "Ohio": 35000, "Oregon": 16000, })
print(obj2)
print(obj1 + obj2)
Ohio 35000
Oregon 16000
Utah 5000
dtype: int64
California NaN
Ohio 35000.0
Oregon 16000.0
dtype: float64
California NaN
Ohio 70000.0
Oregon 32000.0
Utah NaN
dtype: float64
6、索引和切片
s = pd.Series(np.array([1,2,3,4,5]), index=['a', 'b', 'c', 'd', 'e'])
print(s[1:])
print(s[1:] + s[:-1])
b 2
c 3
d 4
e 5
dtype: int32
a NaN
b 4.0
c 6.0
d 8.0
e NaN
dtype: float64
DateFrame(可行列索引)
DataFrame是一个表格型的数据结构,类似于Excel或sql表,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等),DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
1、使用多维数组字典、列表字典、Series字典生成
data = {'state': ['Ohio', 'Nevada', 'Nevada'], 'year': [2000,2001, 2002], 'pop': [1.5, 2.4, 2.9]}
frame = pd.DataFrame(data)
print(frame)
print(type(frame))
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
print(pd.DataFrame(d))
执行结果:
state year pop
0 Ohio 2000 1.5
1 Nevada 2001 2.4
2 Nevada 2002 2.9
<class 'pandas.core.frame.DataFrame'>
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
2、可指定列索引顺序
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three'])
print(frame2)
执行结果:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Nevada 2.4 NaN
three 2002 Nevada 2.9 NaN
3、可以列名为索引获取值
print(d['one'])
a 1.0
b 2.0
c 3.0
dtype: float64
4、一列值的修改
frame2['debt'] = 16.5
print(frame2)
frame2['new'] = frame2['debt' ]* frame2['pop']
print(frame2)
执行结果:
year state pop debt new
one 2000 Ohio 1.5 16.5 24.75
two 2001 Nevada 2.4 16.5 39.60
three 2002 Nevada 2.9 16.5 47.85
year state pop debt new
one 2000 Ohio 1.5 16.5 24.75
two 2001 Nevada 2.4 16.5 39.60
three 2002 Nevada 2.9 16.5 47.85
Matplotlib——绘制二维图形库
是一个主要用于绘制二维图形的Python库,由各种可视化类构成,内部结构复杂。matplotlib.pylot是绘制各类可视化图形的命令字库。
1、绘制折线图(y是关于x的函数)
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-1,1,50) #等差数列
y1 = 2*x + 1
y2 = x**2
plt.figure()#生成画布
plt.plot(x,y1)
plt.figure(figsize=(7,5))
plt.plot(x,y2)
plt.show()


2、绘制不同的y1、y2
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(7,5))
plt.plot(x,y1,color='red',linewidth=1)
plt.plot(x,y2,color='blue',linewidth=5)
plt.xlabel('x',fontsize=20)
plt.ylabel('y',fontsize=20)
plt.show()
l1, = plt.plot(x,y1,color='red',linewidth=1)
l2, = plt.plot(x,y2,color='blue',linewidth=5)
plt.legend(handles=[l1,l2],labels=['aa','bb'],loc='best')#图例
plt.xlabel('x')
plt.ylabel('y')
plt.xlim((0,1)) #x轴只截取一段进行显示
plt.ylim((0,1)) #y轴只截取一段进行显示
plt.show()

3、散点图
dots1 =np.random.rand(50)
dots2 =np.random.rand(50)
plt.scatter(dots1,dots2,c='red',alpha=0.5) #c表示颜色,alpha表示透明度
plt.show()
4、柱状图
x = np.arange(10)
y = 2**x+10
plt.bar(x,y,facecolor='#9999ff',edgecolor='white')#柱状图的柱有里面的颜色和外面的框框
plt.show()
x = np.arange(10)
y = 2**x+10
plt.bar(x,y,facecolor='#9999ff',edgecolor='white')
for ax,ay in zip(x,y):
plt.text(ax,ay,'%.1f' % ay,ha='center',va='bottom')#显示值
plt.show()
# plt.plot() 只有一个输入列表或数组时,参数被当做Y轴,X轴以索引自动生成
# plt.savefig() 将输出图形存储为文件,默认PNG格式,可以通过dpi修改输出质量
import matplotlib.pyplot as plt
plt.plot([3, 2, 5, 8, 10, 6])
plt.xlabel('Time')
plt.ylabel('Meter')
plt.savefig('work/graph', dpi=300)
plt.show()
#subplot在全局绘图区域中创建一个分区体系,并定位到一个子绘图区域
plt.figure()
plt.subplot(231)
plt.plot([1,2,3])
plt.subplot(232)
plt.plot([1,2,1])
plt.subplot(233)
plt.plot([2,2,1])
plt.subplot(212)
plt.plot([1,2,1,3,4,5])
# 饼图的绘制
labels = 'apple', 'banana', 'orange', 'peach'
sizes = [3, 5, 6, 2]
explode = (0, 0, 0.2, 0)
plt.pie(sizes, explode=explode, labels=labels, startangle=90)
plt.axis('equal')
plt.show()
# 直方图的绘制
np.random.seed(0)
mu, sigma = 10, 2 # 均值和标准差
a = np.random.normal(mu, sigma, size=10)
plt.hist(a, 20)
plt.title('Histogram')
plt.show()
PIL库——图像处理库
PIL库是一个具有强大图像处理能力的第三方库。图像的组成:由RGB三原色组成,RGB图像中,一种彩色由R、G、B三原色按照比例混合而成。0-255区分不同亮度的颜色。图像的数组表示:图像是一个由像素组成的矩阵,每个元素是一个RGB值。
1、读取图像并获取图像相关参数
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('F:/图片/壁纸/2000953.jpg')
plt.imshow(img)
plt.show(img)
print(img.mode)
a,b=img.size
print(img.size)
可以使用 img.show()显示图片,但是它调用的是计算机上显示图片的工具,等同于在计算机打开图片。

2、图片旋转rotate()、剪切crop()、缩放resize()、transpose左右旋转transpose(Img.FLIP_LEFT_RIGHT)、上下旋转(Img.FLIP_TOP_BOTTOM)
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('F:/图片/壁纸/2000953.jpg')
img1=img.rotate(50)
plt.imshow(img1)
plt.show(img1)
img_crop_result = img.crop((100,200,500,800))
#crop()四个参数分别是:(左上角点的x坐标,左上角点的y坐标,右下角点的x坐标,右下角点的y坐标)
plt.imshow(img_crop_result)
plt.show(img_crop_result)
#缩放,长和宽到原来的0.6倍,Image.ANTIALIAS:尽量高质量地缩放
img_resize_result = img.resize((int(a*0.4),int(b*0.4)),Image.ANTIALIAS)
plt.imshow(img_resize_result)
plt.show(img_resize_result)
#左右镜像
img_lr = img.transpose(Image.FLIP_LEFT_RIGHT)
#左右旋转
#展示左右镜像图片
plt.imshow(img_lr)
plt.show(img_lr)
#上下镜像
img_bt = img.transpose(Image.FLIP_TOP_BOTTOM)
#上下旋转
#展示上下镜像图片
plt.imshow(img_bt)
plt.show(img_bt)





#灰度化处理
gray_cat = cat.convert('L')
plt.imshow(gray_cat)
# 获取图片的基本信息
bands = cat.getbands() # 显示该图片的所有通道
print(bands)
bbox = cat.getbbox() # 获取图片左上角和右下角的坐标
print(bbox)
width, height = cat.width, cat.height # 获取图片宽度和高度
print(width, height)
# 图片粘贴操作
flower = Image.open('work/flower.jpeg')
flower.paste(dog)
plt.imshow(flower)
flower.paste(dog, (300, 300))
plt.imshow(flower)