jdk7中HashMap是通过数组+链表实现的。
一、hashmap的存储原理
Map集合中的数据都是键值对形式的,例如key:"a",value:"1",而数组中的某个位置只能存储一个元素,所以为了把键和值这两种信息同时存储到一个数组位置中可以抽象出一个Entry对象,Entry中要有键和值两种属性,
数组中的每个位置其实存的都是这种Entry对象,这样就实现了把key-value同时存储到数组中的一个位置。
假设有一个长度是16的数组,要put的key "a"如何和数组下标对应起来?
有一种方案是先计算出一个hash值,在用数组长度对hash值取余,这样就会得到一个0-15之间的数字,这个数字就可以作为数组下标,这里的这个取余数就是根据hash值和数组长度计算数组下标的一种算法。
为了方便存储数组中已经put的key的hash值,可以给我们设计的entry对象中增加一个hash属性。
因为取余运算得到的结果的范围是0-15,所以必定会存在多个不同的key最终计算得到的数组下标是一样的,这就是hash冲突,为了解决这种多个不同的key需要存储在同一个数组位置的问题,我们可以给数组中这个位置存储一个链表结构,出现hash冲突时多个entry对象已链表的形式存储在数组中的同一个位置上。
为了实现链表可以给Entry对象中增加一个next属性,指向链表的下一个节点。当没有hash冲突时可以认为链表中只有一个元素,next=null。
每次put时都是创建这样的Entry对象并添加到数组中。
Entry<K,V> {
final int hash;
final K key;
V value;
Entry next;
}
给数组中某个位置的链表中插入元素时采用头插法还是尾插法?
在jdk7中采用的是头插法,因为如果使用尾插法每次插入时都需要遍历这个链表来找到链表的最后一个节点,
jdk7中采用的是(1)先把新节点添加到链表的头部,(2)再把这个新节点放到数组的原来位置上。
下面画图来演示下为什么需要这两步。

上边的图中在数组arr的下标2处已经put了一个节点1,也就是一个entry对象,因为只有一个元素所以next=null,
假设现在又put进来一个元素并且计算出的数组下标也在2处,使用头插法创建一个新节点2添加到链表的头部,就是
entry2.next=entry1,对应上边的第一步,此时就会变成下图这种效果

此时链表的头节点变成了节点2,2指向1,这是一个单向链表,通过arr[2]能访问到节点1但是没有办法访问到节点2。为了能够访问到新的头节点2,需要把链表整体向下移动,即arr[2]存储节点2
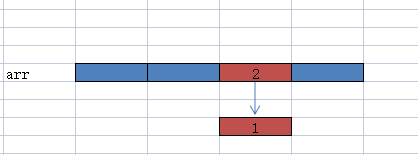
这样 通过arr[2]访问到节点2,再由entry2.next就可以遍历到1
这一步对应的是上边的第2步。这就解释了在hashmap中为什么要这样去给链表上添加新节点。
二、hashmap源码解读
2.1 构造方法
使用hashmap时一般是直接使用无参数的构造方法直接创建对象HashMap<String,String> map = new HashMap<>(); 先来看下这个无参数的构造方法
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
可以看到这个方法是调用了另一个带两个参数的构造方法,传递了连个参数,这两个参数是这个类中的常量,从注释就可以看出来这两个常量的值一个是16代表初始容量,一个是0.75代表扩容因子。
再来看下这个带参数的构造方法
public HashMap(int initialCapacity, float loadFactor) {
// 一些校验
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//给这两个成员变量赋值
this.loadFactor = loadFactor;
//这句代码说明了map刚创建出来时threshold=map的初始容量
threshold = initialCapacity;
//这个方法是一个空方法,在hashmap中没有实现
init();
}
整体来讲hashmap的构造方法中仅对两个成员变量loadFactor,threshold进行了赋值
2.2 put方法
接着来看下put方法的源码
// 这两个参数代表的是要存储的key和value
public V put(K key, V value) {
//这个table就是用来存储元素的数组
if (table == EMPTY_TABLE) {
// 第一次put时才进行初始化
inflateTable(threshold);//后边有具体分析这个方法
}
if (key == null)
//put key=null时的处理
return putForNullKey(value);
//计算hash值
int hash = hash(key);
//根据hash值计算数组下标
int i = indexFor(hash, table.length);
// 如果要存储的下标上已经有值,用for循环对这个已有的链表进行遍历
// 检查当前要put的key是否在这个链表上存在,如果存在就把value替换成新值并返回旧值,再结束
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//这个判断是看数组i位置的链表上当前节点的key是否和要put的key相等
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 这个方法真正的往table[i]处添加节点,i处有可能已经有一个链表了,也可能没有
addEntry(hash, key, value, i);//后边有具体分析这个方法
return null;
}
这个table就是用来存储元素的数组,是类中的成员变量,map刚创建出来时它就是一个空数组EMPTY_TABLE,
数组能存储的元素类型是Entry,这是hashmap中的一个内部类,其中的属性和上边存储原理中分析的类似。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
//省略其他
}
/**
* An empty table instance to share when the table is not inflated.
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
2.2.1 inflateTable方法
table数组在第一次put时才进行初始化,接下来看下这个inflateTable的源码,注意调用时传递的是threshold,这个变量在构造方法中赋值成了数组的初始容量initialCapacity,所以默认情况下threshold =16
private void inflateTable(int toSize) {
// 这块的目的是找到比toSize大的最小的2的幂次方数
// 例如如果传进来15,找到的就是16,传进来16找到的就是16,传进来17找到的就是32
// 之所以要找到这个数作为table的大小是和后边根据hash获取数组的算法有关系的
int capacity = roundUpToPowerOf2(toSize);
// 给threshold重新赋值 容量*扩容因子
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
// 初始化hash种子,这个一般用不到
initHashSeedAsNeeded(capacity);
}
2.2.2 hash方法
这个方法根据传入的key计算出一个hash值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
主要是调用k的hashCode方法生成hashcode,
然后进行了一些异或和移位运算,int类型占4个字节即32位,进行这些运算是为了把hashcode的高位移动到低位参与到后边生成数组下标的算法中,最终是为了减少hash冲突即不同key算出同样的下标。
2.2.3 indexFor 计算数组下标方法
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
这个方法会得到一个 0到数组长度-1之间的数字,使用的是按位与运算,什么原理呢?
假设length=16,那转成二进制就是 0001 0000,这里只给出低8位,那么减1后就是15转成2进制0000 1111,低4为1,其余都是0
那么任何一个数和这个15按位进行与运算都只有低4位可能是1其余都是0,结果的最大值就是 8+4+2+1=15
这也解释了为什么inflateTable方法中一定要得到一个2的幂次方数类型的数组容量,只有这样减1后才能得到一个低位全是1的数;hash方法中的异或和与运算把hashcode的高位搬到低位也是为了让高位数也参与这个求下标的运算,减少冲突。
2.2.4 addEntry方法
这个方法真正的往table[i]处添加节点,i处有可能已经有一个链表了,也可能没有
void addEntry(int hash, K key, V value, int bucketIndex) {
//对当前map的size进行判断,看是否需要扩容
// 这个threshold在上边inflateTable方法中赋值成了容量*0.75(扩容因子)
// 后边这个条件表示下标i上是否有链表,如果没有即使容量的条件满足了也不会扩容,因为下标i
// 上是空的就可以直接把要put的元素放上去所以就不扩容了
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容方法,扩成table旧的长度*2
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//创建新节点
createEntry(hash, key, value, bucketIndex);
}
2.2.4 createEntry方法
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
这个方法中会创键出一个新的Entry节点,并且让newEntry.next指向table[i]处原来的节点,也就是链表头节点,然后再把newEntry放到table[i]处,这和我们在存储原理中分析的头插法两步实现是一致的。
如果table[i]处原来没有节点,那就会指向null,表示这个下标上是第一次put元素。
2.2.5 putForNullKey
这个方法用来对null key进行处理,所以hashmap中key是可以为null的。
private V putForNullKey(V value) {
// 可以看到key=null时永远是存储在0下标位置处
// 这个循环是在检查数组0下标处是否已经有链表,如果有就遍历这个链表看链表上是否有key=null的节点,
// 如果有就替换这个节点的value为新值然后返回就值。
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 把value添加到数组的0下标处。
addEntry(0, null, value, 0);
return null;
}
需要注意的是数组的0下标处放置的节点不一定都是key=null,因为其他的hash值也有可能计算出0下标,这就是上边put null时需要遍历遍历链表的原因。
2.2.5 resize 扩容方法
这个方法是对数组table进行扩容
void resize(int newCapacity) {
// 一些判断
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建一个新的数组
Entry[] newTable = new Entry[newCapacity];
//把旧数组的元素转移到新数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//重新计算 threshold
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
扩容的重点在transfer方法中
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 循环数组
for (Entry<K,V> e : table) {
// 循环链表
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这个方法的核心思想是先遍历旧数组,如果这个位置有链表就开始遍历这个链表,并计算entry元素在新数组中的下标,转移元素。所以是一个双重循环,外层循环数组内层循环链表。
特别强调的是table[i]处即使只有一个元素这也是一个只有一个元素的链表。
旧数组上一个链表上的多个元素转移到新数组后有可能在同一个数上也有可能不在,因为下标i重新计算了。
即使正好在一个树上因为用的是头插法,老数组中如果链表是 3--》2--》1,转移到新数组中就会变成
1-->2-->3,这是头插法决定的,第一个插入的节点会被不断向下移动。
三、线程安全问题
hashmap是一个非线程安全的集合,在多个线程中作为共享变量使用时会有线程安全问题。
hashmap中的线程安全问题是在扩容方法中造成的,下面来仔细分析下扩容方法中的transfer方法
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 循环数组
for (Entry<K,V> e : table) {
// 循环链表
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//位置1
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
线程安全问题只在某个下标上存多个节点的链表时出现,
在这个方法中table表示的是扩容前的旧数组,是类中的成员变量可以被多个线程共享;
e表示的是链表上当前被遍历的节点,
next表示的是下一个节点,在循环结束时e=next把e指向下一个节点。
newTable指向的是扩容后的新数组
e,next,newTable都是局部变量,在每个线程中都会有一份,而table是多个线程共享的,table刚开始指向的是旧数组,在扩容完成后table就会指向扩容后的新数组。
现在假设有一个初始容量为2的数组现在需要扩容,在它的下标1处已经存了一个有3个节点的链表,假设有两个线程同时在进行扩容,在扩容时两个线程对链表第一次循环都运行到了 上边代码位置1处,几个局部变量的情况如下图所示
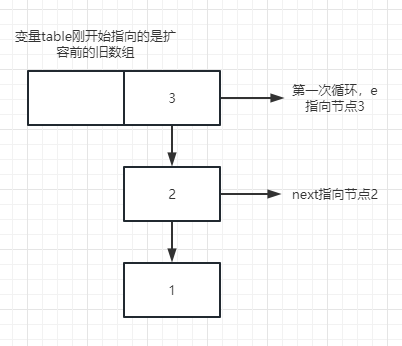
现在假设线程2卡在位置1处,线程1顺利执行完了扩容方法table就会指向新数组,假设扩容完成后这三个节点还在同一个链表上,因为头插法的缘故扩容完成后在新数组中这3个节点的顺序就会颠倒,
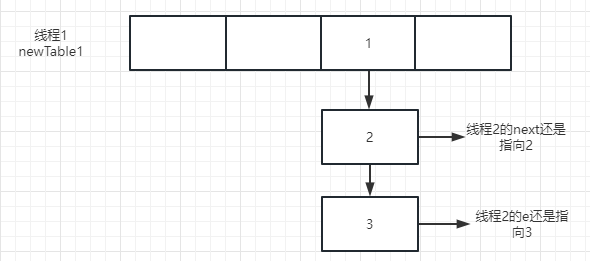
因为table已经指向了扩容后的数组,而线程2的局部变量中next,e还是以前的指向,所以看着就是next跑到了e的前边去了。
这个时候线程2恢复执行,继续完成第一次循环,就会把节点3搬到线程2的新数组newTable2中,循环完成后e=节点2,

然后开始第二次循环,next=e.next,因为e=2,所以next=2.next,即又等于3了,所以第2次循环完成后把2移到newTable2,数组变成了这样
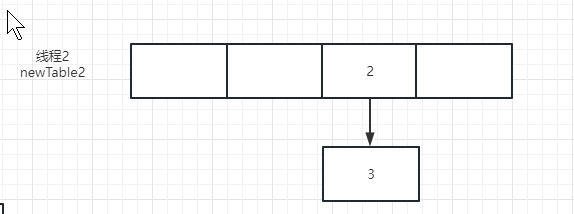
然后 e=next=3
接着开始第3此循环,next=e.next=null,等代码执行完e.next = newTable[i];后节点3的next就会指向节点2,形成一个循环链表,然后执行newTable[i] = e;把节点3放到数组中作为新的头节点,最后会变成这样结束循环

最后的结果就是线程2扩容后节点1丢了,并且给数组中放了一个循环链表,下次get或者put时如果遍历到这个循环链表就会陷入死循环中。
这就是jdk7中hashmap的线程安全问题产生的原因。
标签:key,hash,HashMap,next,链表,源码,数组,table,jdk7 From: https://www.cnblogs.com/chengxuxiaoyuan/p/17047914.html