集合
集合类的特点:提供一种存储空间可变的存储模型,存储的数据容量可以随时发生改变。
1. Collection(接口):单列集合
List(接口):元素可重复
ArrayList(实现类):
LinkedList(实现类):
Set(接口):元素不可重复
HashSet(实现类):
TreeSet(实现类):
2. Map(接口):双列集合
HashMap(实现类):
Collection集合
1. Collection是单列集合的顶层接口。
2. Collection没有任何具体的实现类,创建对象时必须使用子类接口List或Set的实现类。
创建Collection集合对象的方式
- 多态的方式
- 具体的实现类,如ArrayList
public class CollectionDemo {
public static void main(String[] args) {
//创建Collection对象
Collection<String> cc = new ArrayList<>();
//添加元素 String类型
cc.add("茶碗儿");
cc.add("雀巢咖啡");
//运行结果:[茶碗儿, 雀巢咖啡]
//说明重写了toString()方法
System.out.println(cc);
}
}
Collection集合的常用方法
- boolean add() 添加元素
- boolean remove() 移除指定元素
- void clear() 清空集合
- boolean contains() 判断集合是否包含指定元素
- isEmpty() 判断集合是否为空
- int size() 获取集合的长度
Collection集合的遍历
- iterator:迭代器,集合的专用遍历方式。iterator() 返回集合中的迭代器。
- 迭代器中的方法
- E next() 返回迭代中的下一个元素。也就是获取元素的。
- boolean hasNext() 如果迭代中具有更多元素,返回true。也就是用来判断元素是否存在。
//Collection集合的遍历
public class CollectionDemo {
public static void main(String[] args) {
Collection<String> cc = new ArrayList<>();
cc.add("茶碗儿");
cc.add("雀巢咖啡");
cc.add("五香卤蛋");
Iterator<String> it = cc.iterator();
//先判断元素是否存在,再获取元素
while (it.hasNext()){
String s = it.next();
System.out.println(s);
}
}
}
运行结果:
茶碗儿
雀巢咖啡
五香卤蛋
练习:创建Collection集合,添加三个学生对象,遍历
//学生类
public class Student {
private String Name;
private int age;
public Student() {
}
public Student(String name, int age) {
Name = name;
this.age = age;
}
public String getName() {
return Name;
}
public void setName(String name) {
Name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//重写toString()
@Override
public String toString() {
return "Student{" +
"Name='" + Name + '\'' +
", age=" + age +
'}';
}
}
//测试类
public class StudentDemo {
public static void main(String[] args) {
//创建Collection集合,类型为学生类
Collection<Student> co = new ArrayList<>();
//创建学生对象
Student s1 = new Student("茶碗儿", 11);
Student s2 = new Student("花生糖", 12);
Student s3 = new Student("燕麦片", 13);
//向集合中添加元素
co.add(s1);
co.add(s2);
co.add(s3);
//获取集合中的迭代器
Iterator<Student> it = co.iterator();
//遍历集合
while (it.hasNext()){
System.out.println(it.next());
}
}
}
//运行结果
Student{Name='茶碗儿', age=11}
Student{Name='花生糖', age=12}
Student{Name='燕麦片', age=13}
List集合
特点
- List集合:有序集合,有索引,元素可重复
- 可精确控制元素的插入位置,可通过索引访问指定元素
总结
- 有序:存储和取出的元素顺序一致
- 可重复:存储的元素可重复
List集合特有方法
- void add(int index,E element) 在集合中指定位置,插入指定的元素。
- E remove(int index) 删除指定索引处的元素,返回被删除的元素。
- E set(int index,E element) 修改指定索引处的元素,返回被修改的元素。
- E get(int index) 返回指定索引处的元素。
//遍历List集合
public class ListDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("world");
for (String s : list) {
System.out.println(s);
}
}
}
//运行结果
hello
java
world
并发修改异常 ConcurrentModificationException
案例:
//判断集合里是否有元素"world",如果有,则像集合中添加元素"javaee"
public class ListDemo2 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("world");
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
if (s.equals("world")){
//通过集合对象,向集合中添加元素
list.add("javaee");
}
}
System.out.println(list);
}
}
运行结果
//并发修改异常 ConcurrentModificationException
Exception in thread "main" java.util.ConcurrentModificationException
at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1013)
at java.base/java.util.ArrayList$Itr.next(ArrayList.java:967)
at com.chawaner.test4.ListDemo2.main(ListDemo2.java:25)
并发修改异常产生的原因:
迭代器通过next()方法获取元素时会判断预期修改值和实际修改值是否相等。迭代器遍历元素过程中,如果集合对象通过add()方法修改了集合中的元素,就会导致预期修改值和实际修改值不一致。
解决方案
如果需要在遍历操作中插入元素,使用for循环遍历(普通for循环,不是迭代器for),然后用集合对象操作即可。
解决方案:
public class ListDemo2 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("world");
//增强for,其实就是迭代器遍历,会出现并发修改异常
//for (String s : list) {
// if (s.equals("world")){
// list.add("javaee");
// }
//}
//使用for循环解决并发修改异常
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
if (s.equals("world")){
list.add("javaee");
}
}
System.out.println(list);
}
}
运行结果:
[hello, java, world, javaee]
列表迭代器
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
list.add("java");
//获取列表迭代器 listIterator()
ListIterator<String> it = list.listIterator();
//遍历
System.out.println("遍历集合:");
//判断下一个元素是否存在 hasNext()
while (it.hasNext()){
//获取下一个元素 next()
System.out.println(it.next());
}
//逆向遍历
System.out.println("逆向遍历集合:");
//判断前一个元素是否存在 hasPrevious()
while (it.hasPrevious()){
//获取前一个元素 previous()
System.out.println(it.previous());
}
//遍历时向集合中插入元素
while (it.hasNext()){
String s = it.next();
if (s.equals("world")){
/*通过列表迭代器,将指定的的元素插入集合;
迭代器中没有add()方法,而列表迭代器中有add()方法;
列表迭代器中的add()方法会把实际修改值赋值给预期修改值;
next()方法获取元素时判断预期修改值和实际修改值是否相等,就不会出现并发修改异常。
*/
it.add("吃饭");
}
System.out.println(list);
}
}
增强for循环
增强for简化了数组和集合的遍历
- JDK5之后出现,内部原理是包装了一个Iterator迭代器
案例:
public static void main(String[] args) {
int[] arr = {15, 45, 56, 98, 32};
//数组遍历
for (int i : arr) {
System.out.println(i);
}
System.out.println("---------------");
List<String> list = new ArrayList<>();
list.add("黑化肥发黑会挥发");
list.add("喝咖啡就大蒜");
list.add("鸡你太美接化发");
//集合遍历
for (String s : list) {
System.out.println(s);
}
}
运行结果:
15
45
56
98
32
---------------
黑化肥发黑会挥发
喝咖啡就大蒜
鸡你太美接化发
List集合存储对象的三种遍历方式
- 普通for循环遍历:带有索引的遍历方式
- 迭代器遍历:集合特有的遍历方式
- 增强for遍历:最方便的遍历方式
常见的数据结构
- 栈:先进后出(水桶)
- 队列:先进先出(管道)
- 数组:查询快,增删慢
- 查询元素通过索引定位,查询任意元素耗时相同,查询速度快
- 删除数据时,要将原始将元素删除,同时后面每个元素要前移,删除效率低
- 添加数据时,先所有元素后移一位,才能在指定位置添加元素,添加效率极低
- 链表:增删快,查询慢(都是相比数组而言)
- 链表元素被称为结点
- 结点有地址(存储位置),地址里面有数据和下一个结点的地址
- ^:结点指向空地址,表示结束
- 添加:添加到指定位置,更改前一个结点的指向,更改要添加的结点的指向到后面的节点
- 删除:更改前一个结点的指向,再删除指定结点
- 查询:从头开始查询,查询速度慢
- 哈希表:
- JDK8之前,底层采用数组+链表,即元素为链表的数组结构
- JDK8之后,在长度比较长的时候,底层实现了优化(略)
List集合子类特点:使用的时候,要考虑场景是查询还是增删
- List集合常用子类:ArrayList,LinkedList
- ArrayList:底层数据结构是数组(查询快,增删慢)
- LinkedList:底层数据结构是链表(查询慢,增删快)
基本使用案例:
public static void main(String[] args) {
//ArrayList添加元素
List<String> arr = new ArrayList<>();
arr.add("鸡你太美");
arr.add("接化发");
arr.add("耗子尾汁");
ListIterator<String> ait = arr.listIterator();
//列表迭代器遍历查询,并添加元素
while (ait.hasNext()) {
String s = ait.next();
if (s.equals("接化发")) {
ait.add("偷袭");
}
}
//增强for遍历ArrayList集合
for (String s : arr) {
System.out.println(s);
}
System.out.println("-----------------");
//LinkedList添加对象
List<Student> lin = new LinkedList<>();
Student s1 = new Student("曹操", 11);
Student s2 = new Student("刘备", 12);
Student s3 = new Student("孙权", 13);
lin.add(s1);
lin.add(s2);
lin.add(s3);
//增强for遍历集合
for (Student student : lin) {
System.out.println(student);
}
}
运行结果:
鸡你太美
接化发
偷袭
耗子尾汁
-----------------
Student{Name='曹操', age=11}
Student{Name='刘备', age=12}
Student{Name='孙权', age=13}
LinkedList特有的方法
public static void main(String[] args) {
//创建一个LinkedList
LinkedList<String> list = new LinkedList<>();
//添加元素
list.add("鸡你太美");
list.add("接化发");
list.add("混元形意太极门");
list.add("耗子尾汁");
//输出集合
System.out.println("列表:"+list);
//在列表开头插入指定元素 public void addFirst()
list.addFirst("所有人下来做核酸");
//在列表末尾添加元素 public void addLast()
list.addLast("叮咚鸡");
System.out.println("首尾插入元素后的列表:"+list);
//返回列表中的第一个元素 public E getFirst()
System.out.println("返回列表第一个元素:"+list.getFirst());
//返回列表中的最后一个元素 public E getLast()
System.out.println("返回列表最后一个元素:"+list.getLast());
//移除并返回列表第一个元素 public E removeFirst()
System.out.println("移除并返回列表第一个元素:"+list.removeFirst());
//移除并返回列表最后一个元素 public E removeLast()
System.out.println("移除并返回列表最后一个元素:"+list.removeLast());
System.out.println("移除首尾元素后的列表:"+list);
}
运行结果:
列表:[鸡你太美, 接化发, 混元形意太极门, 耗子尾汁]
首尾插入元素后的列表:[所有人下来做核酸, 鸡你太美, 接化发, 混元形意太极门, 耗子尾汁, 叮咚鸡]
返回列表第一个元素:所有人下来做核酸
返回列表最后一个元素:叮咚鸡
移除并返回列表第一个元素:所有人下来做核酸
移除并返回列表最后一个元素:叮咚鸡
移除首尾元素后的列表:[鸡你太美, 接化发, 混元形意太极门, 耗子尾汁]
Set集合
- 不允许元素重复
- 没有带索引的方法,不能使用普通for循环遍历
HashSet:对集合的迭代顺序不做任何保证。就是说遍历是乱序的。
public static void main(String[] args) {
//Set集合存储字符串并遍历
Set<String> set = new HashSet<>();
set.add("混元形意太极门");
set.add("马保国");
set.add("马保国");
set.add("接化发");
//HashSet遍历不保证顺序
for (String s : set) {
System.out.println(s);
}
}
运行结果:Set集合不包含重复的元素
接化发
马保国
混元形意太极门
哈希值
- 哈希值:是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。
- Object类中有一个hashCode()方法可以获取对象的哈希值。
public class HashCodeDemo {
public static void main(String[] args) {
Student s = new Student("马保国", 69);
//Object类中有一个hashCode()方法可以获取对象的哈希值
//返回一个int类型的哈希码值
System.out.println("马保国哈希值:"+s.hashCode());
System.out.println("马保国哈希值:"+s.hashCode());
Student s1 = new Student("挖掘机", 25);
System.out.println("挖掘机哈希值:"+s1.hashCode());
}
}
运行结果:
马保国哈希值:189568618
马保国哈希值:189568618
挖掘机哈希值:666641942
- 默认使用Object类下的hashCode()方法下,同一个对象的哈希值相同,不同对象的哈希值不同。
- 重写hashCode()方法,可以使不同对象哈希值相同。
- 字符串String重写了hashCode()方法,两个不同字符串对象的哈希码值有可能相同。
//这俩字符串对象的哈希值都是:1179395
System.out.println("重地".hashCode());
System.out.println("通话".hashCode());
HashSet集合
HashSet集合的特点
- 底层数据结构是哈希表
- 对集合迭代顺序不保证,不保证存储和取出的元素顺序一致
- 没有带索引的方法,不能使用普通for循环遍历
- 不包含重复的元素
HashSet集合添加一个元素的过程
- 调用对象的hashCode()获取对象的哈希值
- 根据哈希值计算对象的存储位置
- 判断该位置是否有元素存在
- 如果没有,将元素存放到该位置
- 如果有,遍历该位置元素比较哈希值
如果哈希值不相同,存储元素到该位置
如果哈希值相同,调用equals()比较对象内容
如果内容也相同,不保存该元素
如果内容不相同,存储元素到该位置
总结:
HashSet集合添加一个元素的过程,首先要比较哈希值是否相同,哈希值不相同则保存元素;哈希值相同时,还要比较元素的内容是否相同,元素的内容不相同时才保存元素。
HashSet集合保证元素唯一性
- 要保证元素唯一性,需要重写hashCode()和equals()
哈希表
- 元素为链表的数组,默认长度为16(0-15)。
- 存储元素的时候,用元素的哈希值对16取余(%16),余数是几,就将元素存储在几的位置(每个位置都是一个链表)。
- 元素存进某个位置里的链表中,要对比这个位置里的链表中的元素的哈希值和内容(即:遵循HashSet集合的元素唯一性)。
案例
public class HashCodeDemo1 {
public static void main(String[] args) {
HashSet<Student> hs = new HashSet<>();
Student s1 = new Student("曹操", 11);
Student s2 = new Student("刘备", 12);
Student s3 = new Student("孙权", 13);
Student s4 = new Student("孙权", 13);
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
for (Student h : hs) {
System.out.println(h);
}
}
}
运行结果
Student{Name='孙权', age=13}
Student{Name='刘备', age=12}
Student{Name='曹操', age=11}
Student{Name='孙权', age=13}
这块添加重复元素成功了,说明不是同一个对象。如果不保存重复元素,需要重写Student类里面的hashCode()和equals()。如下:
public class Student {
private String Name;
private int age;
public Student() {
}
public Student(String name, int age) {
Name = name;
this.age = age;
}
public String getName() {
return Name;
}
public void setName(String name) {
Name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//重写toString方法
@Override
public String toString() {
return "Student{" +
"Name='" + Name + '\'' +
", age=" + age +
'}';
}
//重写equals方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return Name != null ? Name.equals(student.Name) : student.Name == null;
}
//重写hashCode方法
@Override
public int hashCode() {
int result = Name != null ? Name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
再看运行结果:这下就没有重复元素了
Student{Name='孙权', age=13}
Student{Name='刘备', age=12}
Student{Name='曹操', age=11}
LinkedHashSet集合
特点:有序,元素不重复
- 哈希表和链表实现的Set接口,具有可预测的迭代次序
- 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
- 由哈希表保证元素唯一,也就是说没有重复元素
案例:LinkedHashSet集合存储字符串并遍历
public class HashCodeDemo1 {
public static void main(String[] args) {
LinkedHashSet<String> lhs = new LinkedHashSet<>();
lhs.add("春天");
lhs.add("夏天");
lhs.add("夏天");
lhs.add("秋天");
lhs.add("冬天");
for (String lh : lhs) {
System.out.println(lh);
}
}
}
运行结果:有序,元素不重复
春天
夏天
秋天
冬天
TreeSet集合
特点
- 元素有序,指的不是存取的顺序,而是按照某种规则进行排序,排序方式取决于构造方法。
- TreeSet():根据元素的自然排序进行排序
- TreeSet(Comparator comparator):根据指定的比较器进行排序
- 没有带索引的方法,不能使用普通for循环遍历。
- 由于是Set集合,所以元素不重复。
案例:TreeSet集合存储整数并遍历
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<>();
ts.add(10);
ts.add(30);
ts.add(20);
ts.add(20);
ts.add(50);
ts.add(40);
for (Integer t : ts) {
System.out.println(t);
}
}
}
运行结果:自然排序(从小到大),元素不重复
10
20
30
40
50
自然排序Comparable
案例:
public class ComparableDemo {
public static void main(String[] args) {
/*存储学生对象并遍历,创建TreeSet集合使用无参构造方法
* 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序*/
TreeSet<Student> ts = new TreeSet<>();
Student s1 = new Student();
s1.setName("Tom");
s1.setAge(11);
Student s2 = new Student();
s2.setName("Carl");
s2.setAge(12);
Student s3 = new Student();
s3.setName("Bob");
s3.setAge(13);
Student s4 = new Student();
s4.setName("iKun");
s4.setAge(12);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
for (Student t : ts) {
System.out.println(t);
}
}
}
运行结果:类型转换异常,要实现自然排序,Student类要实现Comparable接口并重写compareTo()
Exception in thread "main" java.lang.ClassCastException: class com.chawaner.test5.Student cannot be cast to class java.lang.Comparable (com.chawaner.test5.Student is in unnamed module of loader 'app'; java.lang.Comparable is in module java.base of loader 'bootstrap')
at java.base/java.util.TreeMap.compare(TreeMap.java:1291)
at java.base/java.util.TreeMap.put(TreeMap.java:536)
at java.base/java.util.TreeSet.add(TreeSet.java:255)
at com.chawaner.test5.ComparableDemo.main(ComparableDemo.java:29)
修改Student类:
public class Student implements Comparable<Student>{
private String Name;
private int age;
public Student() {
}
public Student(String name, int age) {
Name = name;
this.age = age;
}
public String getName() {
return Name;
}
public void setName(String name) {
Name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//重写toString
@Override
public String toString() {
return "Student{" +
"Name='" + Name + '\'' +
", age=" + age +
'}';
}
//重写equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return Name != null ? Name.equals(student.Name) : student.Name == null;
}
//重写hashCode
@Override
public int hashCode() {
int result = Name != null ? Name.hashCode() : 0;
result = 31 * result + age;
return result;
}
//重写compareTo
@Override
public int compareTo(Student o) {
//返回0,表示添加的第二个元素跟第一个元素是同一个元素,所以只会添加第一个元素成功
return 0;
}
}
运行结果:只会添加第一个元素成功
Student{Name='Tom', age=11}
如果将compareTo方法里面的返回值改为1,则会认为第二个元素比第一个元素大,第二个元素就会添加到第二个元素后面。遍历时,就是按照元素的添加顺序输出结果
//重写compareTo
@Override
public int compareTo(Student o) {
//返回0,表示添加的第二个元素跟第一个元素是同一个元素,所以只会添加第一个元素成功.
//返回1,则会认为第二个元素比第一个元素大,第二个元素就会添加到第二个元素后面。遍历时,就是按照元素的添加顺序输出结果。同理,返回-1则会按照倒序添加元素成功。
return 1;
}
运行结果:添加元素成功
Student{Name='Tom', age=11}
Student{Name='Carl', age=12}
Student{Name='Bob', age=13}
Student{Name='iKun', age=12}
修改compareTo(),按照年龄排序
//重写compareTo,按照年龄排序
@Override
public int compareTo(Student o) {
//从小到大排序
//当前要存储的元素 this.age,上一个元素 o.age
int num = this.age - o.age;
//从大到小排序
//int num = o.age - this.age;
return num;
}
运行结果:年龄从小到大排序,但是年龄相同的元素值保存成功了第一个
Student{Name='Tom', age=11}
Student{Name='Carl', age=12}
Student{Name='Bob', age=13}
修改compareTo(),按照年龄从小到大排序,年龄相同时,按照姓名首字母排序
@Override
public int compareTo(Student o) {
//按照年龄规则,从小到大排序
//当前要存储的元素 this.age,上一个元素 o.age
int num = this.age - o.age;
//从大到小排序
//int num = o.age - this.age;
//年龄相同时,按照姓名首字母顺序排序
//Name是个字符串,String实现了Comparable<String>,所以能直接调用compareTo(T o)实现自然排序
//三目运算,当年龄相同,按照姓名自然排序,否则按照年龄规则排序
int num2 = num == 0 ? this.Name.compareTo(o.Name) : num;
return num2;
}
运行结果:年龄从小到大排序,年龄相同时,按照姓名首字母顺序排序
Student{Name='Tom', age=11}
Student{Name='Carl', age=12}
Student{Name='iKun', age=12}
Student{Name='Bob', age=13}
再测一下姓名和年龄都相同时,能否保证元素的唯一性
public class ComparableDemo {
public static void main(String[] args) {
/*存储学生对象并遍历,创建TreeSet集合使用无参构造方法
* 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序*/
TreeSet<Student> ts = new TreeSet<>();
Student s1 = new Student();
s1.setName("Tom");
s1.setAge(11);
Student s2 = new Student();
s2.setName("Carl");
s2.setAge(12);
Student s3 = new Student();
s3.setName("Bob");
s3.setAge(13);
Student s4 = new Student();
s4.setName("iKun");
s4.setAge(12);
Student s5 = new Student();
s5.setName("Bob");
s5.setAge(13);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
for (Student t : ts) {
System.out.println(t);
}
}
}
运行结果:姓名和年龄都相同时,保证了元素的唯一性
Student{Name='Tom', age=11}
Student{Name='Carl', age=12}
Student{Name='iKun', age=12}
Student{Name='Bob', age=13}
TreeSet集合总结
- 能够按照规则排序,并且能对元素去重
- 重写compareTo方法时,要注意排序规则,按照要求的主要条件(num)和次要条件(num2)来写
比较器排序Comparator
要求:存储学生对象并遍历,创建TreeSet集合,使用带参构造方法创建学生对象
- 使用比较器Comparator按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
public class ComparatorDemo {
public static void main(String[] args) {
//TreeSet里面有一个Comparator接口,实际用的是Comparator的实现类对象
//这里使用匿名内部类的方法,使用比较器Comparator来实现排序
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
//按照年龄规则排序
//现在是在测试类里面,所以不能直接访问Student类的成员变量age,得用getAge()
int num = s1.getAge() - s2.getAge();
//按照年龄规则排序,年龄相同时,按照姓名自然排序
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
return num2;
}
});
//使用带参构造方法创建元素
Student s1 = new Student("Tom",11);
Student s2 = new Student("Carl",12);
Student s3 = new Student("Bob",13);
Student s4 = new Student("iKun",12);
Student s5 = new Student("Bob",13);
//添加元素到TreeSet集合
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
//增强for遍历集合
for (Student t : ts) {
System.out.println(t);
}
}
}
运行结果:
Student{Name='Tom', age=11}
Student{Name='Carl', age=12}
Student{Name='iKun', age=12}
Student{Name='Bob', age=13}
结论:
- 自然排序:是在学生类里面,重写compareTo(T o),自定义排序规则
- 比较器排序,是在测试类里面,让集合接收一个Comparator接口的实现类对象,重写compare(T o1,T o2)方法
- 重写方法时,一定要按照 要求的主要条件(num)和次要条件(num2)来写
泛型
- 泛型<常见的:T,E,K,V>
- 本质是参数化类型
- 将类型由原来具体的参数化,在使用/调用时传入具体的类型
- 泛型的好处
- 把运行时期遇到的问题提前到了编译时期
- 避免了强制类型转换
泛型类
案例:
//定义一个泛型类,生成set/get方法
public class Generic<T> {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
//测试类
public class GenericDemo {
public static void main(String[] args) {
//根据泛型创建对象
Generic<String> g1 = new Generic<>();
//根据泛型设置信息
g1.setT("小明");
System.out.println(g1.getT());
Generic<Integer> g2 = new Generic<>();
g2.setT(12);
System.out.println(g2.getT());
}
}
运行结果:泛型类可以定义任何类型
小明
12
泛型方法
案例:
//泛型类
public class Generic {
/**
* 返回类型为传入参数的类型
* @param t
* @param <T>
*/
public <T> void show(T t) {
System.out.println(t);
}
}
//测试类
public class GenericDemo {
public static void main(String[] args) {
//根据传入的参数类型,返回相同类型的返回值
Generic g = new Generic();
g.show("小明");
g.show(12);
g.show(true);
}
}
运行结果:
小明
12
true
泛型接口
//定义一个泛型接口
public interface Generic<T> {
void show(T t);
}
//定义一个泛型接口的实现类
public class GenericImpl<T> implements Generic<T>{
@Override
public void show(T t) {
System.out.println(t);
}
}
//测试类
public class GenericDemo {
public static void main(String[] args) {
Generic<String> g1 = new GenericImpl<>();
g1.show("小明");
Generic<Integer> g2 = new GenericImpl<>();
g2.show(32);
}
}
运行结果:
小明
32
类型通配符
类型通配符:<?> 表示任意类型
类型通配符的上限:<? extends 类型> 表示的类型是当前类型或者其子类
类型通配符的下限:<? super 类型> 表示的类型是当前类型或者其父类
public class GenericDemo {
public static void main(String[] args) {
//类型通配符<?> 表示任意类型
List<?> l1 = new ArrayList<Object>();
List<?> l2 = new ArrayList<Number>();
List<?> l3 = new ArrayList<Integer>();
// 类型通配符的上限 <? extends 类型>
// 表示的类型是Number或者其子类
List<? extends Number> l4 = new ArrayList<Number>();
List<? extends Number> l5 = new ArrayList<Integer>();
// 类型通配符的下限 <? super Number>
// 表示的类型是Number或者其父类
List<? super Number> l6 = new ArrayList<Object>();
}
}
可变参数
修饰符 返回值类型方法名(数据类型...变量名){}
如:public static int sum(int...a){}
public class GenericDemo1 {
public static void main(String[] args) {
//调用可变参数方法求和
System.out.println(sum(10));
System.out.println(sum(10, 20));
System.out.println(sum(10, 20, 30));
}
/**
* 可变参数求和
* @param a 其实是个数组
* @return 求和结果
* 如果除了可变参数以外还有别的参数,要将可变参数放在后面
* 如:public static int sum(int b,int...a){}
*/
public static int sum(int...a){
//定义sum并初始化
int sum = 0;
//遍历数组元素,求和
for (int i : a) {
sum += i;
}
return sum;
}
}
运行结果:
10
30
60
- Arrays工具类中有一个静态方法:
- public static
List asList(T... a):返回由指定数组支持的固定大小的列表 - 返回的集合不能做增删操作,可以做修改操作
- List接口中有一个静态方法:
- public static
List of(E... elements):返回包含任意数量元素的不可变列表 - 返回的集合不能做增删改操作
- Set接口中有一个静态方法:
- public static
Set of(E... elements) :返回一个包含任意数量元素的不可变集合 - 在给元素的时候,不能给重复的元素
- 返回的集合不能做增删操作,没有修改的方法
Map集合
- public interface Map<K,V>
- K:键的类型,V:值的类型
- 将键映射到值的对象。不能包含重复的键;每个键只能映射到一个值。
public class MapDemo {
public static void main(String[] args) {
//多态的方式创建Map集合
//具体的实现类HashMap
Map<String, String> m = new HashMap<>();
m.put("001","小红");
m.put("002","小明");
m.put("002","小军");
m.put("004","小刚");
System.out.println(m);
}
}
运行结果:键不能重复。键相同的情况下,后面的元素会覆盖前面的元素。
//HashMap集合重写了toString()
{001=小红, 002=小军, 004=小刚}
Map集合的常用方法
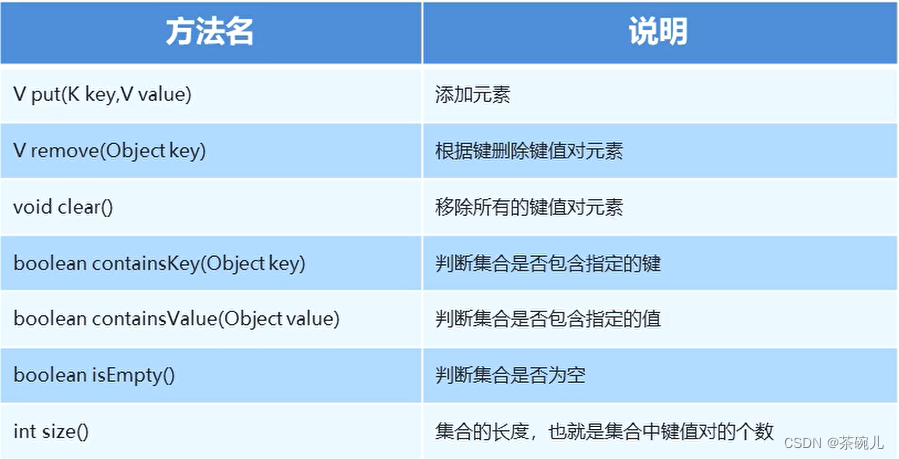
public class MapDemo {
public static void main(String[] args) {
Map<String, String> m = new HashMap<>();
//添加元素
m.put("001","小明");
m.put("002","小红");
m.put("003","小刚");
System.out.println(m);
//集合的长度
System.out.println("集合的长度:"+m.size());
//判断集合是否为空
System.out.println("集合是否为空:"+m.isEmpty());
//根据键删除元素
m.remove("001");
System.out.println("根据键001删除元素后的集合:"+m);
//判断是否包含指定的键
System.out.println("否包含键002:"+m.containsKey("002"));
//判断是否包含指定的值
System.out.println("是否包含小刚:"+m.containsValue("小刚"));
//删除所有元素
m.clear();
System.out.println("删除所有元素后的集合长度:"+m.size());
//判断集合是否为空
System.out.println("集合是否为空:"+m.isEmpty());
}
}
运行结果:
{001=小明, 002=小红, 003=小刚}
集合的长度:3
集合是否为空:false
根据键001删除元素后的集合:{002=小红, 003=小刚}
否包含键002:true
是否包含小刚:true
删除所有元素后的集合长度:0
集合是否为空:true
Map集合的获取功能
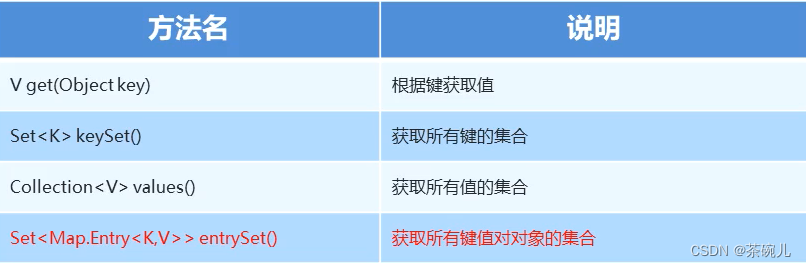
public class MapDemo {
public static void main(String[] args) {
//创建集合对象
Map<String, String> m = new HashMap<>();
//添加元素
m.put("001", "小明");
m.put("002", "小红");
m.put("003", "小刚");
//输出集合
System.out.println("集合:" + m);
//根据键获取值
System.out.println("根据键001获取值:" + m.get("001"));
//获取所有键
System.out.println("获取所有键:" + m.keySet());
//获取所有值
System.out.println("获取所有值:" + m.values());
//获取所有键值对对象,HashMap重写了toString()
System.out.println("获取所有键值对对象:" + m.entrySet());
}
}
运行结果:
集合:{001=小明, 002=小红, 003=小刚}
根据键001获取值:小明
获取所有键:[001, 002, 003]
获取所有值:[小明, 小红, 小刚]
//HashMap重写了toString()
获取所有键值对对象:[001=小明, 002=小红, 003=小刚]
Map集合的遍历
两种遍历方法
- 键找值:获取所有的键,遍历键,根据键获取对应的值
- 键值对对象找键和值:获取所有键值对对象,遍历键值对对象,根据键值对对象获取对应的键和对应的值
public class MapDemo {
public static void main(String[] args) {
/*获取所有的键,遍历键,根据键获取对应的值*/
//创建集合
Map<String, String> m = new HashMap<>();
//添加元素
m.put("001", "小明");
m.put("002", "小红");
m.put("003", "小刚");
//获取所有键
Set<String> keySet = m.keySet();
//遍历键
for (String s : keySet) {
//根据键获取对应的值
System.out.println(m.get(s));
}
}
}
运行结果:
小明
小红
小刚
public class MapDemo {
public static void main(String[] args) {
/*获取所有键值对对象,遍历键值对对象,根据键值对对象获取对应的键和对应的值*/
//创建集合
Map<String, String> m = new HashMap<>();
//添加元素
m.put("001", "小明");
m.put("002", "小红");
m.put("003", "小刚");
//获取所有键值对对象,键值对对象类型 Map.Entry<String, String>
Set<Map.Entry<String, String>> entries = m.entrySet();
//遍历键值对对象
for (Map.Entry<String, String> entry : entries) {
//根据键值对对象获取对应的键和对应的值
System.out.println(entry.getKey()+"---"+entry.getValue());
}
}
}
运行结果:
001---小明
002---小红
003---小刚
统计字符串中每个字符串出现的次数
public class MapDemo {
public static void main(String[] args) {
/*统计字符串中字符出现的次数*/
//初始化字符串
String s = "aabbbcceddeccaabeed";
//创建集合 键:字符 值:次数
Map<Character, Integer> m = new HashMap<>();
//遍历字符串,拿到每一个字符
for (int i = 0; i < s.length(); i++) {
//用拿到每一个字符作为键,到HashMap集合中去找对应的值,看返回值
char key = s.charAt(i);
//该字符出现的次数
Integer value = m.get(key);
//如果返回值为null,说明该字符在HashMap集合中不存在,是第一次出现,设置值为1
if (value == null){
//存储元素到HashMap集合中 HashMap<字符,出现次数>
m.put(key,1);
}else {//如果返回值不为null,说明该字符在HashMap集合中存在,让值+1
//该字符出现的次数+1
value++;
//重新存储,覆盖原有值(HashMap集合键的唯一性)
m.put(key,value);
}
}
//创建StringBuilder可变字符串
StringBuilder sb = new StringBuilder();
//遍历HashMap集合,得到键的值
//遍历所有键,通过建找到对应值
for (Character key : m.keySet()) {
Integer value = m.get(key);
//像字符串中添加元素
sb.append(key+"("+value+")");
}
//输出结果
System.out.println("统计字符串中字符出现的次数:" + sb.toString());
}
}
运行结果
统计字符串中字符出现的次数:a(4)b(4)c(4)d(3)e(4)
Collections工具类
Collections类是操作集合的工具类
Collections类中常用的方法
- public static void sort(List
list):将指定的列表按升序排序将指定的列表按升序排序 - public static void reverse(List<?> list):反转指定列表中元素的顺序
- public static void shuffle(List<?> list):使用默认的随机源随机排列指定的列表
public class CollectionsDemo {
public static void main(String[] args) {
//创建集合
ArrayList<Integer> arr = new ArrayList<>();
//添加元素
arr.add(20);
arr.add(10);
arr.add(30);
//输出集合
System.out.println("集合:"+arr);
//升序排序
Collections.sort(arr);
System.out.println("升序排序:"+arr);
//反转顺序
Collections.reverse(arr);
System.out.println("反转顺序:"+arr);
//随机排列
Collections.shuffle(arr);
System.out.println("随机排列:"+arr);
}
}
运行结果:
集合:[20, 10, 30]
升序排序:[10, 20, 30]
反转顺序:[30, 20, 10]
随机排列:[10, 30, 20]