并发编程
粘包现象
1.粘包现象产生的本质
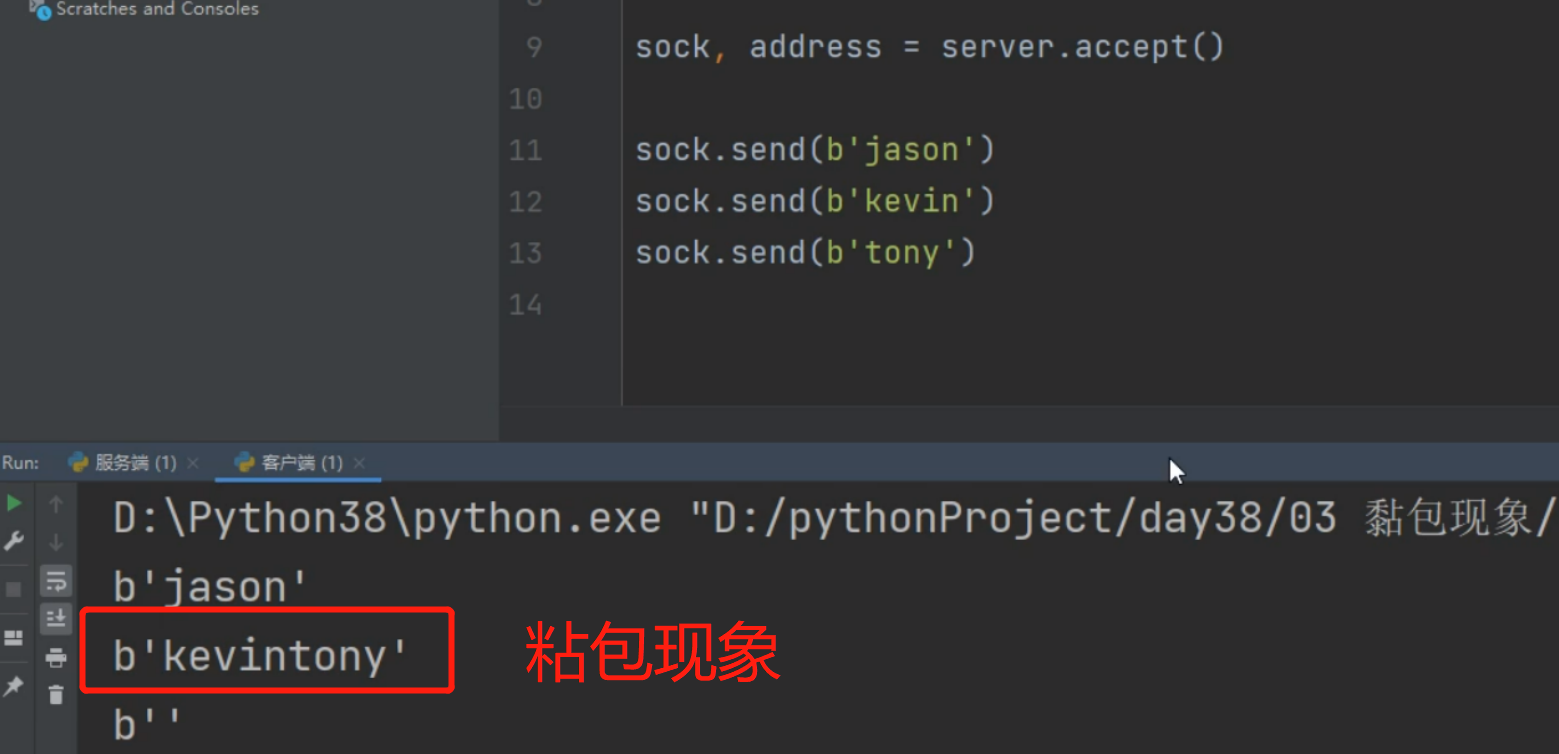
sock.send(b'jason')
data = client.recv(1024)
print(data)
对方只给了5个字符,但是后面我们返回是要返回1024个
粘包现象的产生是因为
1.TCP的特性产生的
流水协议:所有的数据类似于流水,连接在一起
触发条件是数据量很小 并且时间间隔很多,那么就会自动组织到一起
2.recv
我们不知道即将要接收的数据量多大 如果知道的话不会产生也不会产生黏包
粘包是接收长度没对上导致的
控制recv接收的字节数与之对应(你发多少字节我收多少字节)
2.粘包问题解决方案
struct模块
struct模块无论数据长度是多少 都可以帮你打包成固定长度
然后基于该固定长度 还可以反向解析出真实长度
这里利用struct模块里的
struct.pack() 方法来实现打包(将真实数据长度变为固定长度的数字)
struct.unpack() 方法解包(将该数字解压出打包前真实数据的长度)
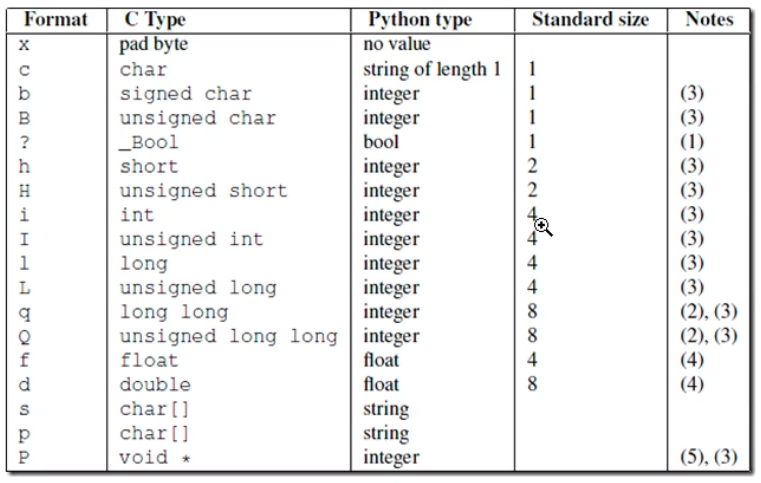
pack unpack模式参数对照表(standard size 转换后的长度)
import struct
info = '下午上课 以后可能是常态!'
print(len(info)) # 13 数据原本的长度
res = struct.pack('i', len(info)) # 将数据原本的长度打包
print(len(res)) # 4 打包之后的长度是4
ret = struct.unpack('i', res) # 将打包之后固定长度为4的数据拆包
print(ret[0]) # 13 又得到了原本数据的长度
info1 = '打起精神啊 下午也需要奋斗 也需要认真听 客服困难 你困我也困!!!'
print(len(info1)) # 34
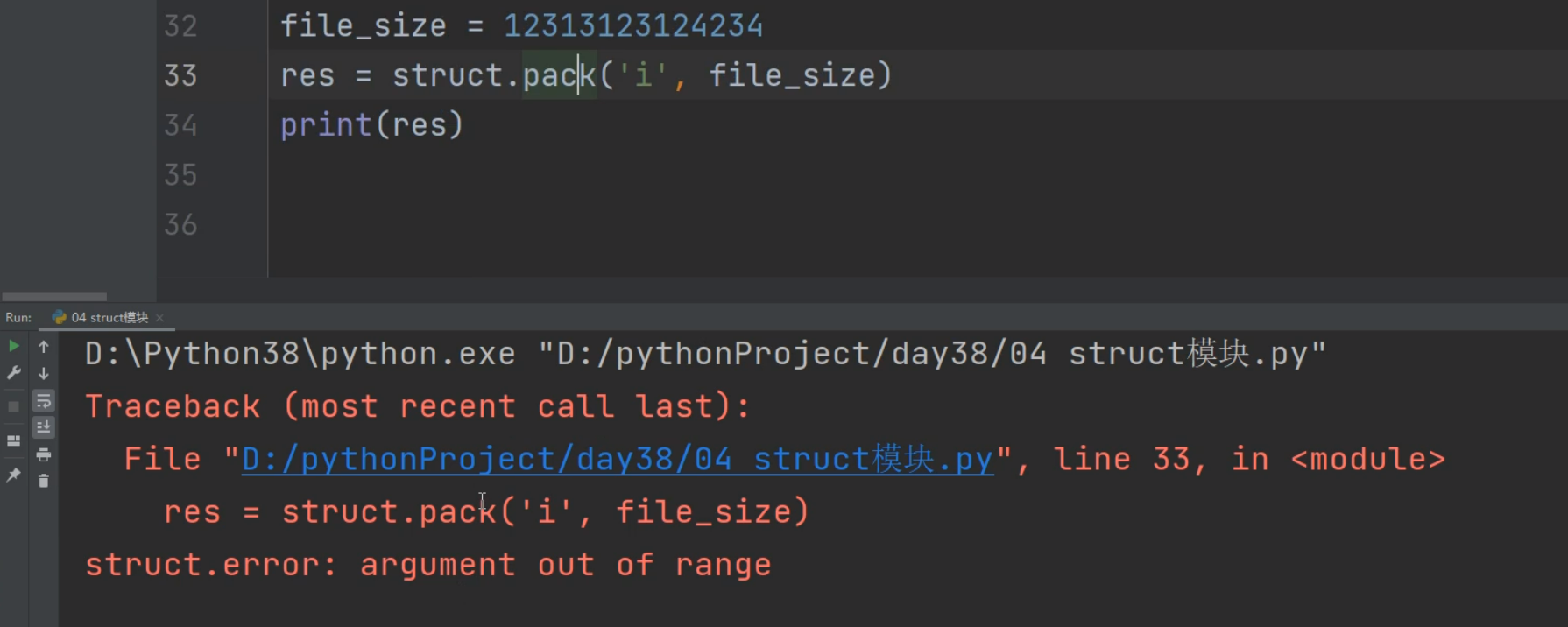
res = struct.pack('i', len(info1)) # 将数据原本的长度打包
print(len(res)) # 4 打包之后的长度是4
ret = struct.unpack('i', res)
print(ret[0]) # 34
struct模块针对数据量特别大的数字没有办法打包
粘包问题解决思路
思路
1.先将真实数据的长度制作成固定长度 4
2.先发送固定长度的报头
3.再发送真实数据
1.先接收固定长度的报头 4
2.再根据报头解压出真实长度
3.根据真实长度接收即可
终极方案
服务器端
1.先制作一个发送给客户端的字典
2.制作字典的报头
3.发送字典的报头
4.发送字典
5.再发真实数据
客户端
1.先接收字典的报头
2.解析拿到字典的数据长度
3.接收字典
4.从字典中获取真实数据的长度
5.循环获取真实数据
一、UDP协议
# 服务端
import socket
server = socket.socket(type=socket.SOCK_DGRAM)
server.bind(('127.0.0.1', 8080))
msg, address = server.recvfrom(1024)
print('msg>>>:%s' % msg.decode('utf8'))
print('address>>>:',address)
server.sendto('我是服务端 你好啊'.encode('utf8'), address)
# 客户端
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
server_address = ('127.0.0.1', 8080)
client.sendto('我是客户端 想我了没'.encode('utf8'), server_address)
msg, address = client.recvfrom(1024)
print('msg>>>:%s' % msg.decode('utf8'))
print('address>>>:',address)
'''补充说明'''
1.服务端不需要考虑客户端是否异常退出
2.UDP不存在黏包问题(UDP多用于短消息的交互)
操作系统(并发编程)的发展史
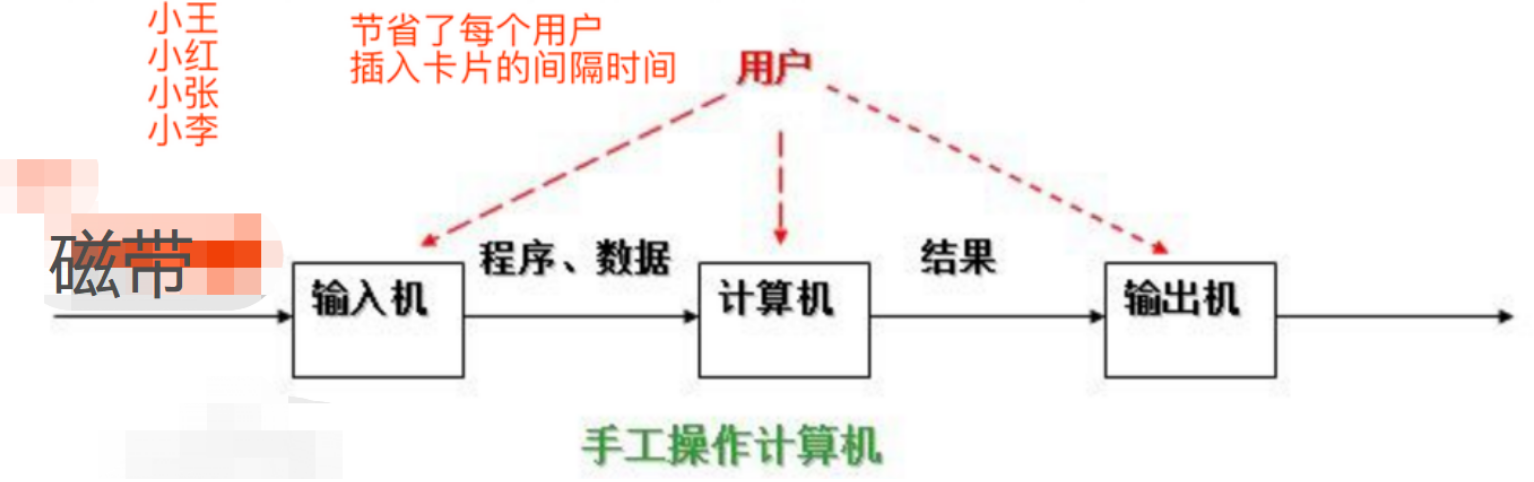
穿孔卡片
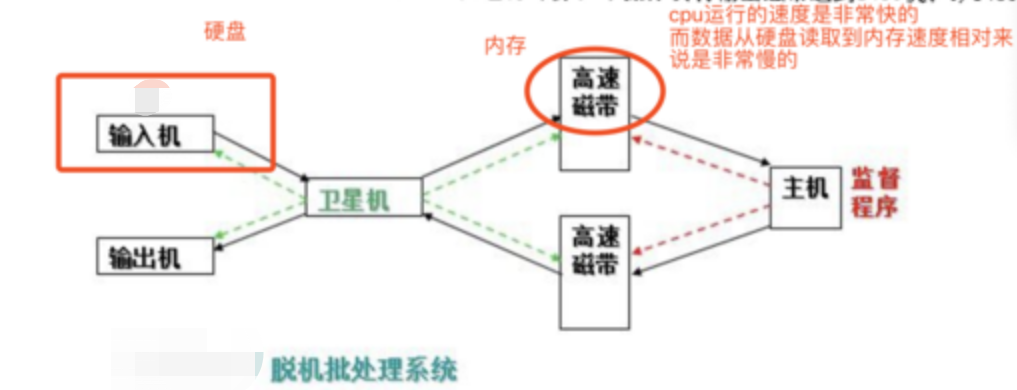
程序员将对应于程序和数据的已穿孔的纸带(或卡片)装入输入机,然后启动输入机把程序和数据输入计算机内存,接着通过控制台开关启动程序针对数据运行;计算完毕,打印机输出计算结果;用户取走结果并卸下纸带(或卡片)后,才让下一个用户上机。
手工操作方式两个特点:CPU利用率非常低,用户独占计算机
联机批处理系统
缩短录入数据的时候,让CPU连续工作的时间变长
脱机批处理系统
是现代计算机的雏形>>>提升CPU利用率
三、多道技术
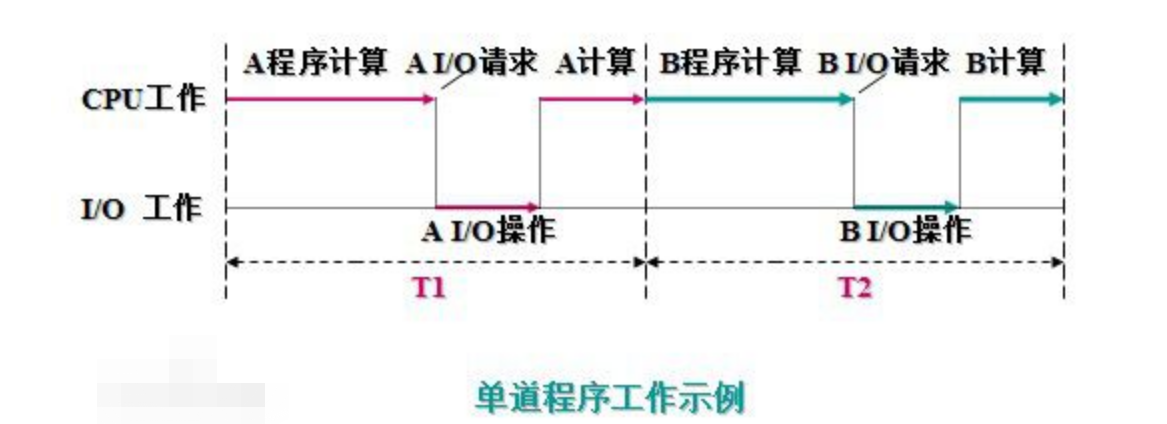
单道技术
所有的程序排队执行,总耗时是所有程序耗时之和
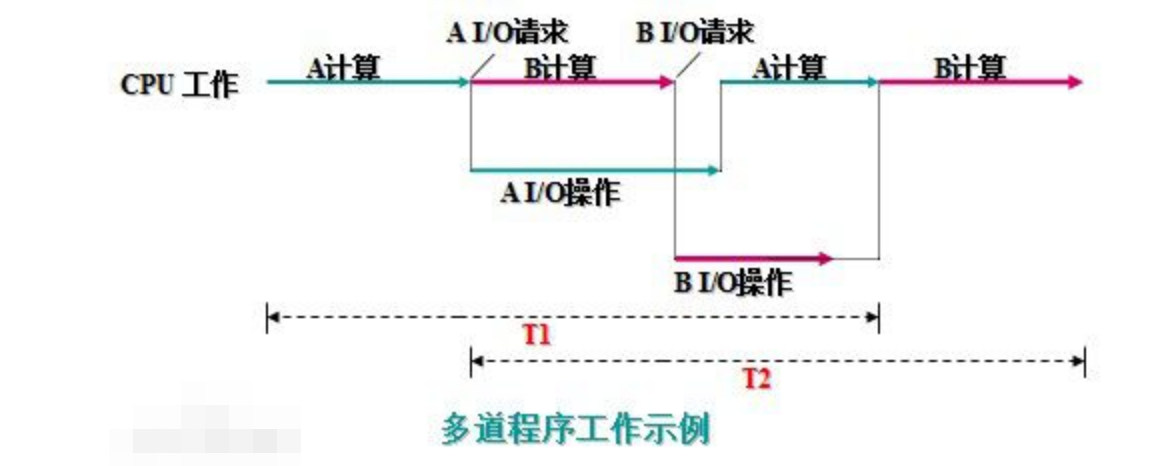
多道技术
多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
计算机利用空闲时间提前准备好一些数据,提高效率,总耗时短
切换+保存状态
CPU在俩种下会切换(去执行其他程序)
程序进入IO操作后,获取用户操作,一直等待输入,保存状态
程序长时间占有CPU,保存状态,每次切换出去的时候保存状态
例子:
做饭耗时50min
洗衣耗时30min
烧水耗时10min
单道技术:50+30+10
多道技术:50
四、进程理论
如何理解进程?
程序:一堆躺在文件上的死代码
进程:正在被运行的程序(活的)
进程的调度算法
进程调度的由来:要想要多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随时就能调度的,所以就有一些法则,如下:
先来先服务算法:争对耗时比较短的程序不友好
短作业优先调度:争对耗时比较长的程序不友好
时间片轮转法+多级反馈队列:将固定的时间均分成很多分,所有的程序公平一点
分配多次之后,如果还有程序需要运行,则将其分到下一层越往下表示程序总耗时越长,每次分的越多,但是优先级越低
额外知识
同一个程序执行两次,就会在操作系统中出现两个进程,所以我们可以同时运行一个软件,分别做不同的事情也不会混乱。
五、进程的并行与开发
并行
```python
多个进程同时执行
单个CPU肯定无法实现并行,必须要有多个CPU
例子:两者同时执行,比如赛跑,两个人都在不停的往前跑;(资源够用,比如三个线程,四核的CPU )
```
并发
多个进程看上去像同时执行就可以称之为并发
单个CPU完全可以实现并发的效果,如果是并行那么肯定也属于并发
例子:一段路(单核CPU资源)同时只能过一个人,A走一段后,让给B,B用完继续给A ,交替使用,目的是提高效率。
面试时遇到的情况案例
如果听到描述一个网址非常牛逼能够同时服务很多人的话术
1.我这个网站很牛逼,能够支持14亿【并行量(高并行)】 不合理,哪有那么多CPU(集群也不现实)
2.我这个网站很牛逼 能够支持14亿【并发量(高并发)】
非常合理!!! 国内最牛逼的网站>>>:12306
并行与并发的区别
并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。 并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个session。
六、进程的三状态
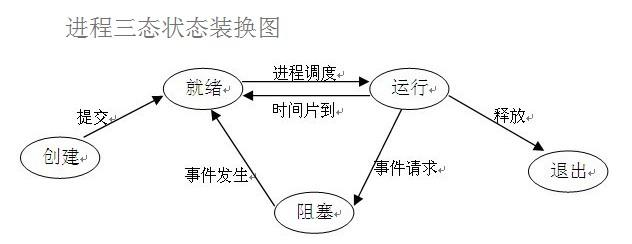
在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行和阻塞。
三种状态的解释说明
- 就绪(Ready)状态当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
- 执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
- 阻塞(Blocked)状态正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。
三种状态过程
- 所有的进程要想被运行 必须先经过就绪态
- 运行过程中如果出现了IO操作 则进入阻塞态
- 运行过程中如果时间片用完 则继续进入就绪态
- 阻塞态要想进入运行态必须先经过就绪态
